
SQLServer中的执行计划缓存由于长时间缓存对性能造成的干扰
本文出处:http://www.cnblogs.com/wy123/p/7190785.html
(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误进行修正或补充,无他)
先抛出一个性能问题,前几天遇到一个生产环境性能极其低下的存储过程,开发人员根据具体的业务逻辑和返回的数据量,猜测到这个存储过程的执行应该不会有这么慢。
当时意识到可能是执行计划缓存的问题,因为当前这个存储过程的写法还是比较遵守参数化SQL的规范的(如果是动态即席查询SQL就不会有问题了)
有意思的是,开发人员提供的相关参数,跟缓存的计划编译的参数竟然是一模一样的,这也是本文重点要表达的重点。
于是去查询当前服务器上缓存的执行计划的到底是怎么样的,缓存这个执行计划的时间,以及缓存的这个执行计划编译时候的参数。
在查询到对应存储过程缓存的执行计划之后,发现其执行计划,确实跟当前直接带入参数执行SQL的执行计划有很大的差异。
当然该问题不完全与Parameter Sniffing完全一致,因此暂不讨论Parameter Sniffing问题。
执行计划由于已经被缓存了起来,当前查询也命中了先前执行计划的缓存,但缓存的这个执行计划对目前的查询来说并可能不是最(相对)优化的,
毕竟该执行计划已经缓存了超过1天的时间了。
那么,缓存的执行计划到底适不适合当前语句的执行?如果不适合于当前语句的执行,又该怎么处理,类似问题从长远看,该怎么避免?
特定语句的执行计划缓存信息
参考如下sql,查询出来某些指定语句的执行计划缓存信息。
SELECT st.Text, SUBSTRING( st.Text, (qs.statement_start_offset/2)+1, ((CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(st.Text) ELSE qs.statement_end_offset END - qs.statement_start_offset)/2)+1 ), qp.query_plan, qs.plan_handle, qs.sql_handle, DB_NAME(st.dbid) as dbname, qs.creation_time, qs.last_execution_time, getdate() as currenttime, qs.execution_count, qs.last_worker_time, qs.last_physical_reads, qs.last_logical_reads, qs.last_elapsed_time FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as st OUTER APPLY sys.dm_exec_query_plan(qs.plan_handle) as qp WHERE 1=1 and st.text like '%模糊匹配存储过程中具体标记性的sql文本%' order by creation_time desc
对于类似如下的查询结果,从查询到的结果中可以看出,直接打开query_plan的xml,可以看到这个存储过程中的语句的执行计划情况,当前我这里仅仅是一个示例

对于当前这个缓存的执行计划的编译参数,可以将query_plan的xml信息复制出来,用notepad++之类的文本编辑器格式化之后显示,查询器编译时候的参数,
参考截图,在xml信息的最后面一部分,或者可以直接按照关键字搜索ParameterList,就可以找到编译执行计划时候的具体的参数值了。
在ParameterList的子节点中column就是参数,ParameterCompiledValue的值就是编译执行计划的值。
这样一来,就可以确定,缓存的执行计划在编译的时候的参数与当前运行的参数是否存在较大的差异,以及缓存的执行计划是在什么生成的,缓存了多久。

对于一开始提到的问题,结果就是当前执行的存储过程中的语句,其执行计划已经被缓存超过了一天,因为尚未带到触发“重编译”的条件,该缓存继续保留在内存中。
鉴于数据库中的数据是不断变化的,当时编译的执行计划,在当前时间来看,即便是参数完全一致,也不一定适用于当前的查询,性能问题也因此产生。
为什么会编译出来一个与当前完全不一致的执行计划,并且缓存到目前为止还没有被清理?
个人猜测有两个原因,不过也不完全确定,
一是基于当时的数据分布情况(统计信息)得到的一个执行计划,可能当时本身的统计信息就不是准确的,但是有没有外界因素促使执行计划重编译
二是当时编译的执行计划本身就是不合理的,执行计划的编译与多种因素相关,甚至是内存压力也会导致无法编译出来一个相对较优的执行计划,
SQL Server执行计划的生成,并不一定总是“最高效”的,只是相对高效的,在内存压力小的时候编译出来的执行计划,可能与内存压力大的时候编译出来的执行计划存在差异
其实第一条猜测的原因存在一定的自相矛盾,
后者的可能性更大,因为如果导致重编译的因素没有发生变化,同样的参数,当前执行也会跟缓存的执行计划一样,如果存在导致重编译的因素,那么缓存的执行计划本身也要被清理掉。
更何况如果缓存了某一个较少概率出现的参数,或者类似于产生parameter sniff的参数问题(当然parameter sniff问题就另当别论),影响甚至就更大。
如下截图是某生产环境服务器上的,可以看到,在业务存储过程或者SQL语句的执行计划缓存,多的可以缓存了超过20天,另外还有缓存的超过了3天,4天的。
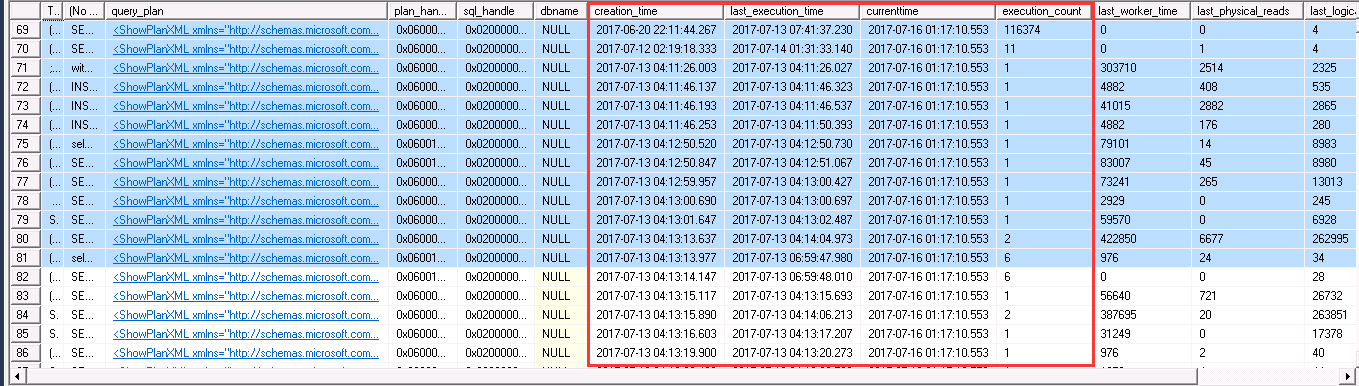
据观察,SQL Server在对待执行计划缓存的内存占用,是轻易不会去清理的,可以认为这部分内存(相对于数据缓存)的要求优先级是比较高的,
也就是说在data cache面临较大压力的时候(PLE可以低到一分钟之内),部分执行计划依然被缓存的好好的。
很可惜,在某些情况下,缓存的执行计划,非但没有提供更好的性能,反倒是因为不适用于当前的查询,拖慢了性能。
执行计划缓存的基础知识
1,什么是执行计划缓存
SQL Server查询引擎接收到sql语句之后,首先会对其进行语法,语义的解析,然后进行编译,之后生成执行计划,对于可满足缓存的要求的sql语句,SQLServer会对其进行缓存。
2,执行计划缓存的作用
减少SQL的编译频率,SQLServer接收到存在执行计划缓存的SQL语句的时候,可以直接使用缓存的执行计划进行执行,避免解析之后再编译造成的资源上和时间上的消耗。
3,当前执行计划缓存占用的空间
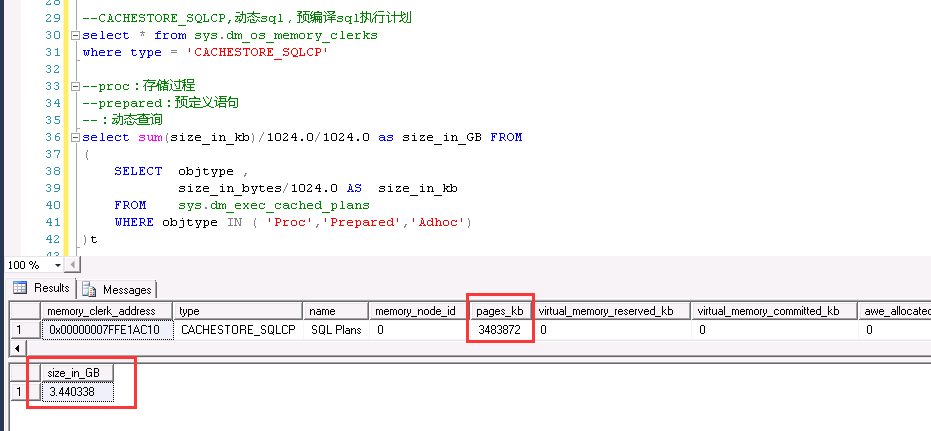
参考如下SQL,可以使用sys.dm_os_memory_clerks或者sys.dm_exec_cached_plans 来查询执行计划缓存已经占用的空间。
--CACHESTORE_SQLCP,动态sql,预编译sql执行计划 select * from sys.dm_os_memory_clerks where type = 'CACHESTORE_SQLCP' --proc:存储过程 --prepared:预定义语句 --Adhoc:动态查询 select sum(size_in_kb)/1024.0/1024.0 as size_in_GB FROM ( SELECT objtype , size_in_bytes/1024.0 AS size_in_kb FROM sys.dm_exec_cached_plans WHERE objtype IN ( 'Proc','Prepared','Adhoc') )t
如下是某服务器上的执行计划缓存信息,两者查询出来的结果基本上一致。
4,执行计划缓存可最大占用的空间
执行计划占用的内存空间是一种称之为Stolen Memory的内存类型,Stolen Memory包括执行计划缓存,以及Session实时计算所需要的内存,比如排序,聚合计算,hash join等等。
SQL Server中Stolen Memory的分配有一个公式,在SQL Server 2005 SP1之后,大概如下
如果Target Mermory(也即SQL Server可用的最大内存空间)
1)不超过8GB的情况下:Stolen Memory = Target Mermory * 75%
2)如果Target Mermory在8GB~64GB之间:Stolen Memory = 8 * 75% + (Target Mermory - 8)*50%
3)如果Target Mermory大于64GB时:Stolen Memory = 8 * 75% + (64 - 8)*50% + (Target Mermory - 64)*25%
可见,随着最大可用内存的增加,Stolen Memory并不是线性递增的,而是增加程度趋于减少(增加程度的导数是减少的)
另外在SQL Server之后的版本中也在控制Stolen Memory的最大可用内容量,具体参考《SQL Server 2012 实施与管理实战指南》+ 这里。
需要注意的是,执行计划缓存可最大占用的空间仅仅是Stolen Memory的一部分,并不是Stolen Memory的全部。
那么问题就来了,这里可以认为,执行计划缓存可最大占用的空间是无法直接控制的,
如果SQL Server的Target Mermory越大,Stolen Memory也就越大,Stolen Memory越大,执行计划缓存可用的内存空间就越大,
虽然执行计划有老化清理机制,但个人感觉还不够灵活,或者说可控不强(现在才明白,其他关系型数据库,开放出来很多可配置的参数的作用了,当然不是说可以随意配置,想改就改)
执行计划缓存占用的内存空间越大,真的就越好吗?或者说,SQL Server服务器的内存供给的越大,性能就会一定越好?
肯定不是,一开始提到的问题就归因于此,正是因为Stolen Memory尚未得到内存压力,执行计划缓存就一直存储在内存中,但是存储的相对较久的执行计划,并非适合于当前的查询。
5,关于即席查询(ad hoc)SQL的配置
这一点根本文关系不大,简单提一下,对于ad hoc,也即动态sql,因为其参数是拼凑在SQL语句中的,很有可能每次都发生变化,类似SQL的执行计划就没有必要缓存了,
对即席工作负载进行优化之后,第一次执行的时候仅存储一个执行计划的“存根”而不是存储整个执行计划,只有相同参数的SQL执行超过一次只有才缓存下来整个完整的执行计划。
--开启 optimize for ad hoc workloads sp_CONFIGURE 'show advanced options',1 reconfigure go sp_CONFIGURE 'optimize for ad hoc workloads',1 reconfigure go

这一点配置的意义何在?内存对数据库来说是很重要的资源,如果Stolen Memory各项内存使用都可以配置,在尽可能满足Stolen Memory的基础上,更多更久地缓存数据才是王道。
如果解决潜在可能过期的执行计划
上述分析说明,在Stolen Memory尚未感受到内存压力,或者是执行计划清理机制尚未清理老化的执行计划缓存的时候,执行计划缓存是依旧保存在内存中的。
但是这种缓存的执行计划,因为是语句编译的时候的数据进行生成的计划,是不一定适合于当前查询的,或者是对于当前查询不是最优化的。
这就需要,在某些情况下,需要人为地清理执行计划缓存。
SQL Server提供了一个系统功能DBCC FREEPROCCACHE去清理执行计划缓存,参数是上文提到的具体的执行计划句柄(plan_handle),不加参数就全清了,注意一下即可。
-- Remove the specific plan from the cache.清除特定的执行计划 DBCC FREEPROCCACHE (0x060006001ECA270EC0215D05000000000000000000000000); GO
对于DBCC FREEPROCCACHE去清理执行特定计划缓存,此种方式仅可以用来应急使用。
如果经常发生类似问题,于情于理,我个人觉得是说不过去的,绝对是DBA该负得起的责任。
更多的时候,已经缓存过一段时间的执行计划,哪些是本应该被清理的,那些是可以继续缓存使用的?这一点很难主观地来界定。
甚至也没有有效的参考信息,因为你不知道3天之前编译的那个执行计划,缓存了三天之后,对于当前的查询,是不是依旧是最(较)优化的。
这一点可以在实践中根据具体的情况进行探索,比如可以根据生成实践,清理超过1天的执行计划缓存,或者把实践这个阈值设置的大一点,但是不建议太长,比如三天五天的
个人认为,既然执行计划能够缓存,那么被清理之后,依然能够缓存,但是清楚之后重编译的执行计划,之准确性上会有更大的提高,一次重编译的代价也是值得的。
理想情况下,一个执行计划编译之后,能够缓存(重用执行计划)一天,相对来说也是比较理想的了。
当然,这里是不包括“采用with recompile语句存储过程的重编译或者option(recompile)基于语句的重编”来避免执行计划缓存的。
执行计划缓存本是处于节约资源与提高性能方面的考虑,只不过是凡事都具体两面性,有利必有弊。
正常情况下,也不建议采用with recompile或者option(recompile)来强制编译存储过程或者SQL语句,大多数时候遵循好规范即可。
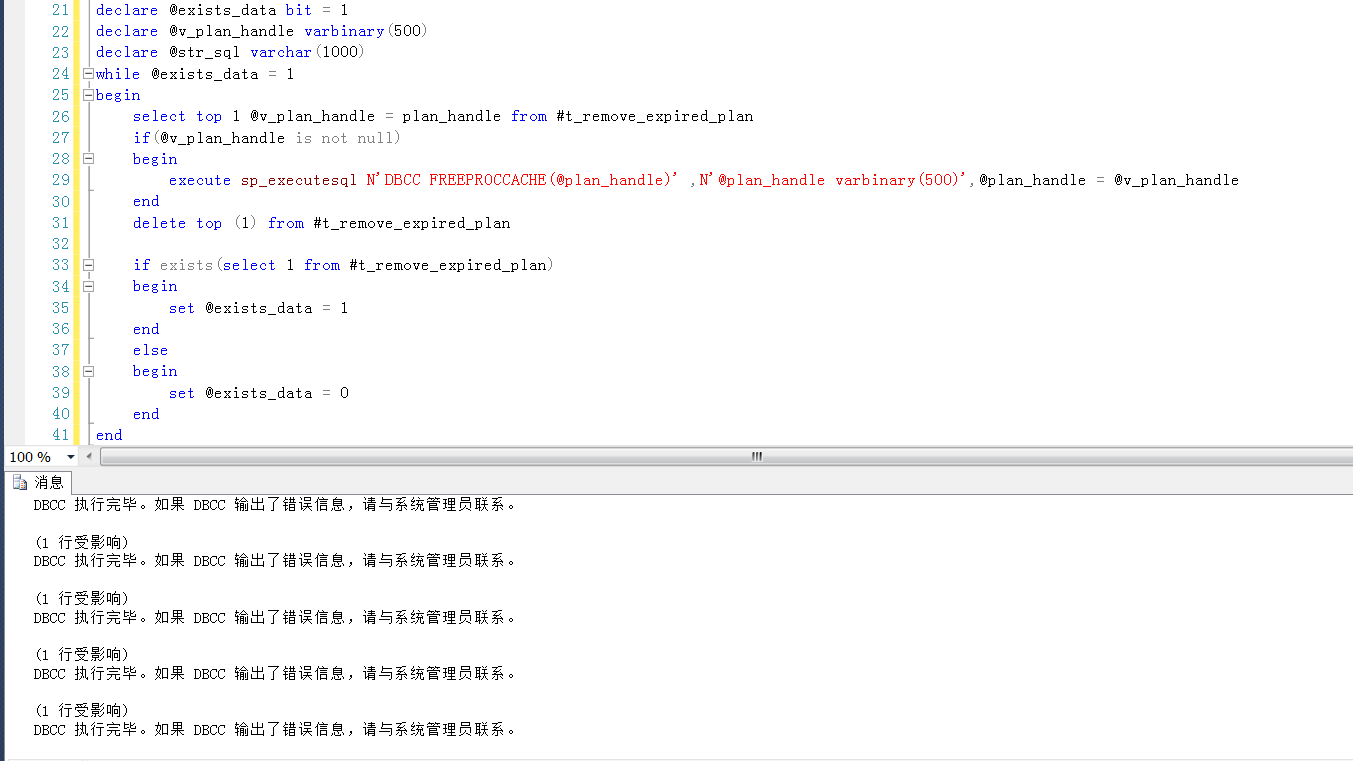
大概想了一下,使用类似如下SQL,采用动态执行DBCC FREEPROCCACHE的方式,可以达到预期的目的。
当然,执行方式,执行时间,时间阈值可以根据具体情况进行调整。
注意 execute sp_executesql的方式执行sql语句,变量类型不支持max类型的参数,因此定义的参数变量类型是varbinary(500)
if object_id('tempdb..#t_remove_expired_plan') is not null drop table #t_remove_expired_plan GO create table #t_remove_expired_plan ( id int identity(1,1), plan_handle varbinary(500) ) GO insert into #t_remove_expired_plan (plan_handle) select qs.plan_handle from sys.dm_exec_query_stats qs where creation_time< dateadd(hh,-24,getdate()) GO declare @exists_data bit = 1 declare @v_plan_handle varbinary(500) declare @str_sql varchar(1000) while @exists_data = 1 begin select top 1 @v_plan_handle = plan_handle from #t_remove_expired_plan if(@v_plan_handle is not null) begin execute sp_executesql N'DBCC FREEPROCCACHE(@plan_handle)' ,N'@plan_handle varbinary(500)',@plan_handle = @v_plan_handle end delete top (1) from #t_remove_expired_plan if exists(select 1 from #t_remove_expired_plan) begin set @exists_data = 1 end else begin set @exists_data = 0 end end
总结:
执行计划缓存原本是为了减少编译SQL带来的资源以及时间上的消耗,在可存在可重用的执行计划缓存的情况下提高SQL的执行效率
对于老化的缓存计划的处理方式,SQL Server有自己的清理机制,但是仍旧缺乏一定的灵活性。
但是在某些特殊情况下,对于性能问题,缓存的执行计划可能会干扰到当前SQL的执行效率,
可能会存外部环境没有问题(服务器资源,CPU,IO,内存,网络等),SQL本身写法也没有问题,也不会出现缺少索引等情况,但是执行效率达不到预期的情况下,
这时就好考虑是不是缓存的执行计划导致当前SQL采用了不合理的执行方式。
微软的平台,一直以来本着简单易容,快速上手的特点,对用户做了大量的封装(屏蔽),在个性化的可配置化上,与其他数据库尤其是开源产品相比显得有些不足。
不过可以通过间接的方式,来达到类似于“可配置化”的目的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号