


MySQL集群故障转移的时候在基于python的客户端连接层自动failover实现
1,keepalived或者类似于VIP的机制
2,服务发现机制
这些方案可以完成应用程序对集群的故障转移访问,但是前者存在经典的脑裂问题;后者还是稍显太重量级了。另外为了解决这个问题,新引进的中间件本身的可靠性也是一个问题。对于MySQL一直没有类似于Redis/MongoDB集群下,通过类似于rediscluster或者jedis这种友好的访问方式,如果在集群自动故障转移后,连接层可以通过配置化实现数据库集群故障转移的识别,根本就不需要上述的两种中间件,那是最好不过的了。截至目前位置,没有一个很好的实现库。
最开始是尝试了官方的mysql-connector-python,https://github.com/mysql/mysql-connector-python/blob/master/lib/mysql/connector/__init__.py
看了下代码,实现还是很感人的,基本上可以认为就是个摆设,MySQL故障转移的实现逻辑极其简单:
按照连接串中的优先级priority倒叙排序,依次向下找节点,如果没找到,继续向下找下一个节点,轮训完成之后再找不到可用节点就报错。
看起来是没有问题的,其实细想一下,真的还不敢用。
1,尝试连接主节点的时候,没有一个尝试次数,任何时候连接不上主节点,直接跳转到下一个节点,这样很容易在网络抖动的时候误判。
2,连接主节点的时候,没有进行可写性判断,只要找到第一个可用节点,就算是成功,如果在主节点,从节点接管之后,这种实现没有问题,一旦原始主节点重新加入集群,此时(主节点是只读的)就是把原始主节点当做最优先级的节点进行写入,所以这里缺少一个节点读写属性的判断。
不过还是想走白嫖路线,又去找pymysql库,然后发现竟然有人跟我有一模一样的想法,真的志同道合了,想法还是非常好的:https://github.com/PyMySQL/PyMySQL/issues/470
然后作者并不打算实现这一功能,也阐述了原因,pymysql侧重于连接的实现,故障转移的功能应该在连接池层实现,可以基于pymysql在连接池层实现节点可用性判断
Such a feature should be implemented in "connection pool", and this project focus on "connection". You can build connection pool on top of this project. Having higher level connection pool allows user can select low level driver. For example, mysqlclient and PyMySQL.
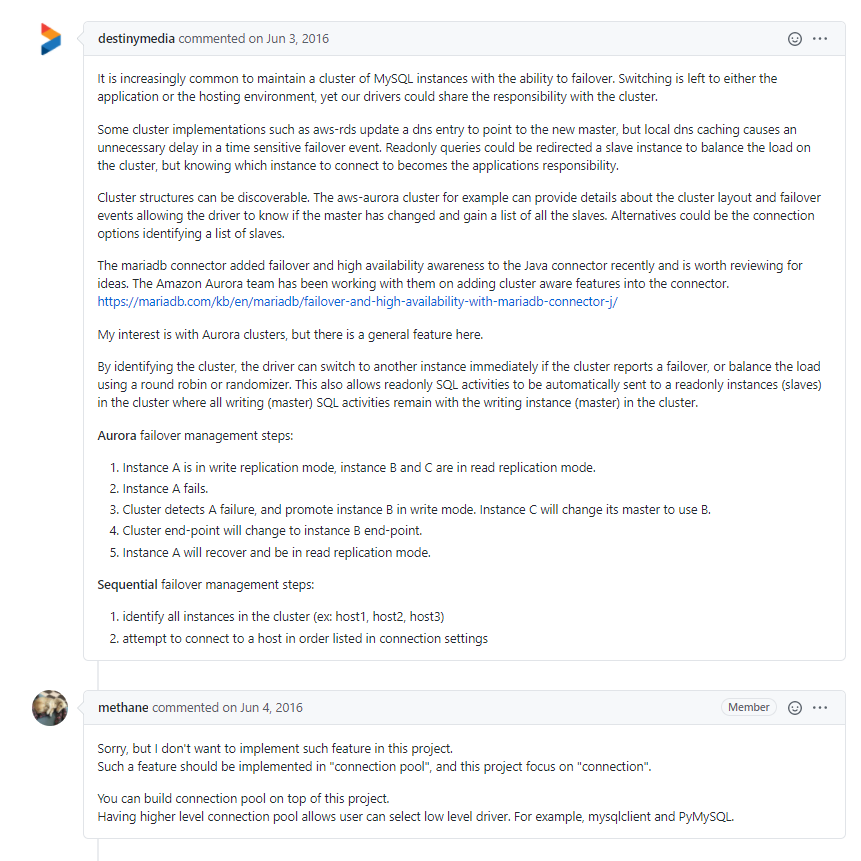
很早之前就有过这个想法,应该来说并不复杂,假设MySQL集群可以自动增确地完成故障转移,客户端访问集群的大概步骤如下
0,正常情况下按照mysql connector的实现,按照优先级找可写节点
1,异常情况下,对于failover的监测:增加主节点不可用之后探测次数以及sleep的时间,防止误判
1.1,到达测探次数之后,按照proprity,再依次找下一个节点
1.2,按照优先级,拿到第一个可达节点,且属性为可写,说明MySQL服务端故障转移完成
1.3,找到一个可用实例后,清理连接池中缓存的连接,重新初始化连接池
3,如果宕机的主节点重新加入集群,此时再应用程序端的配置文件中,其priority是最高的,因此不但要按照优先级判断,也需要判断其是否可读写属性
4,如果从节点宕机,但是主节点正常,可以把只读连接池(如果有的话)清空,按照其priority继续向下找可用实例,否则直接执向主节点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号