with open('data6.csv', 'r', encoding='gbk') as f:
old_data = f.read().split('\n')
del old_data[0]
processed_data = []
for i in range(len(old_data)):
if eval(old_data[i]) + 0.5 >= int(eval(old_data[i])) + 1:
processed_data.append(str(int(eval(old_data[i])) + 1))
else:
processed_data.append(str(int(eval(old_data[i]))))
title = ['原始数据', '四舍五入后数据']
new = []
for i in range(len(old_data)):
new.append([old_data[i], processed_data[i]])
with open('data6_processed.csv','w',encoding = 'gbk') as f:
f.write(','.join(title)+'\n')
for i in new:
f.write(','.join(i) + '\n')
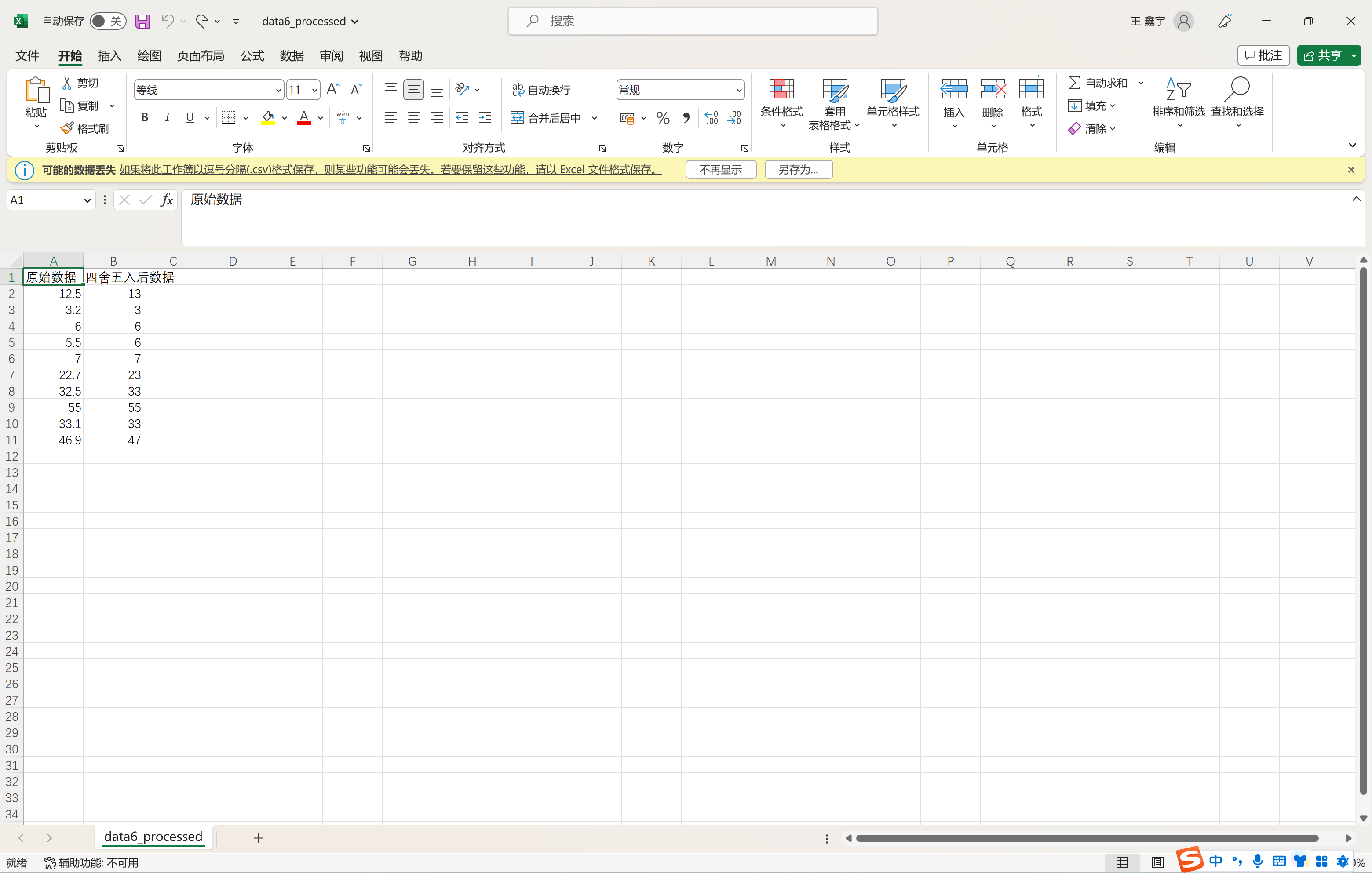
print('原始数据:')
print(old_data)
print(f'四舍五入后数据:')
print(new)
![]()
![]()
with open('data7.csv','r',encoding='gbk') as f:
data = f.read().split('\n')
del data[0]
lsta = []
lstb = []
for i in data:
lst1 = i.split(',')
if lst1[2] == 'Acting':
lsta.append(lst1)
else:
lstb.append(lst1)
lstb.sort(key=lambda x:x[-1],reverse = True)
lsta.sort(key=lambda x:x[-1],reverse = True)
info = lsta + lstb
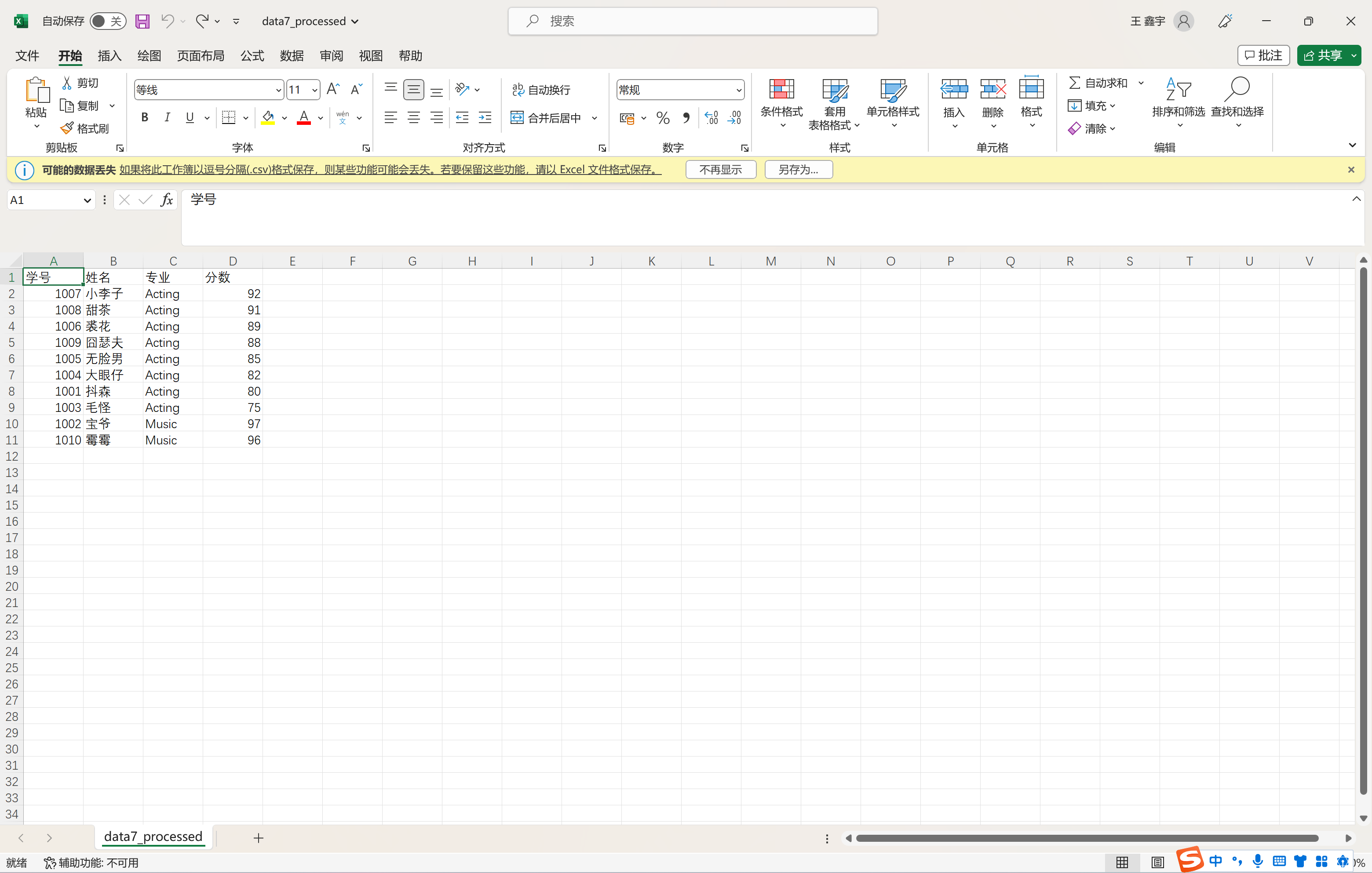
title = ['学号','姓名','专业','分数']
with open('data7_processed.csv','w',encoding='gbk') as f:
f.write(','.join(title)+'\n')
for items in info:
f.write(','.join(items)+'\n')
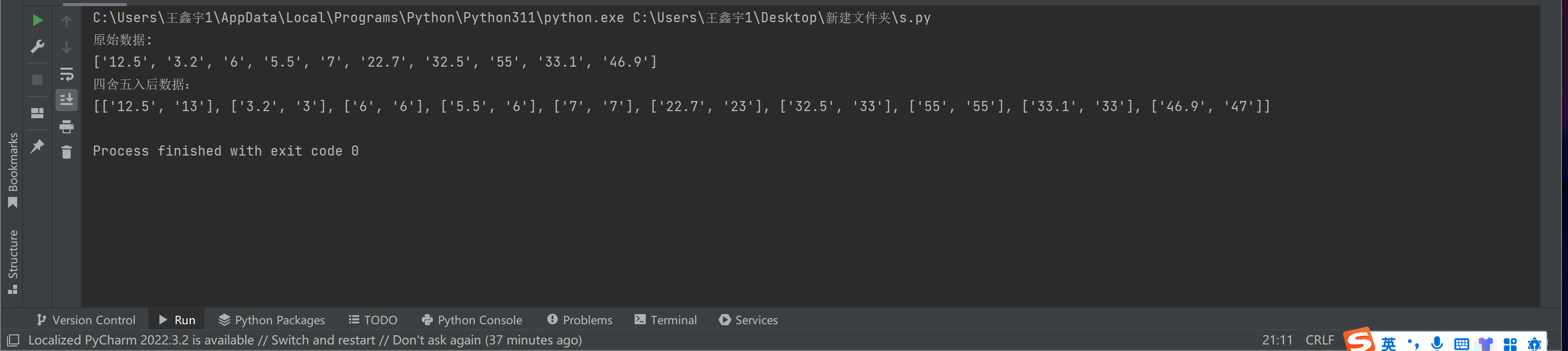
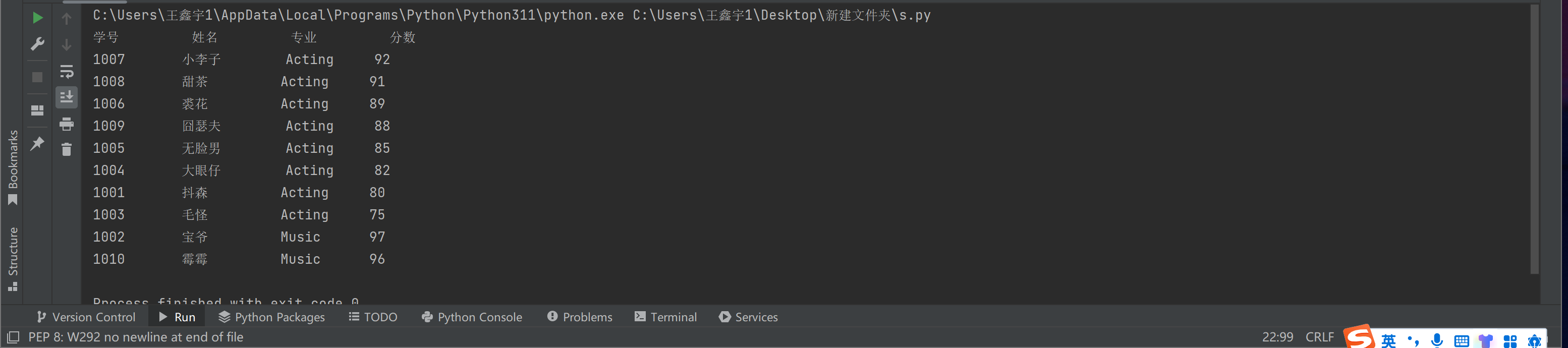
print('{:<10}'.format(title[0]),'{:<10}'.format(title[1]),'{:<10}'.format(title[2]),'{:<15}'.format(title[3]))
for i in info:
print('{:<10}'.format(i[0]),'{:<10}'.format(i[1]),'{:<10}'.format(i[2]),'{:<15}'.format(i[3]))
![]()
![]()
with open('hamlet.txt','r',encoding='utf-8')as f:
data = f.read()
data1 = f.readlines()
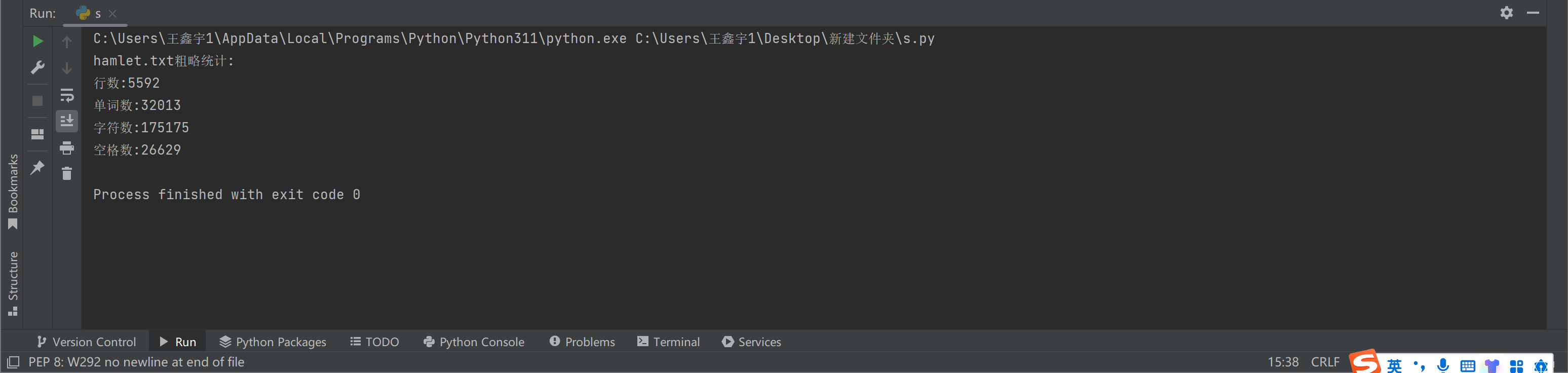
print('hamlet.txt粗略统计:')
print(f'行数:{len(data.splitlines())}')
print(f'单词数:{len(data.split())}')
print(f'字符数:{len(data)}')
print(f'空格数:{data.count(" ")}')
data2 = []
for i in range(len(data1)):
data2.append('{}'.format(i+1)+'.'+data1[i]+'\n')
with open('hamlet_with_line_number.txt','w',encoding='utf-8') as f:
for i in data2:
f.write(','.join(data2)+'\n')
![]()
def is_valid(n):
ls = []
for i in range(10):
ls.append(str(i))
t = str(n)
if len(t)!=18:
return False
else:
i = 0
while i <17:
if t[i] not in ls:
return False
break
else:
i+=1
else:
if t[17] in ls or t[17]=='X':
return True
else:
return False
with open('data9_id.txt','r',encoding = 'utf-8') as f:
data = f.readlines()
data.remove('姓名,身份证号码\n')
data1 = [i.strip('\n').split(',') for i in data]
for i in data1:
if is_valid(i[1]):
continue
else:
data1.remove(i)
data2=sorted(data1,key=lambda x:(x[1][6:13]))
for i in data2:
nl = 2023 - int(i[1][6:10])
i.append(nl)
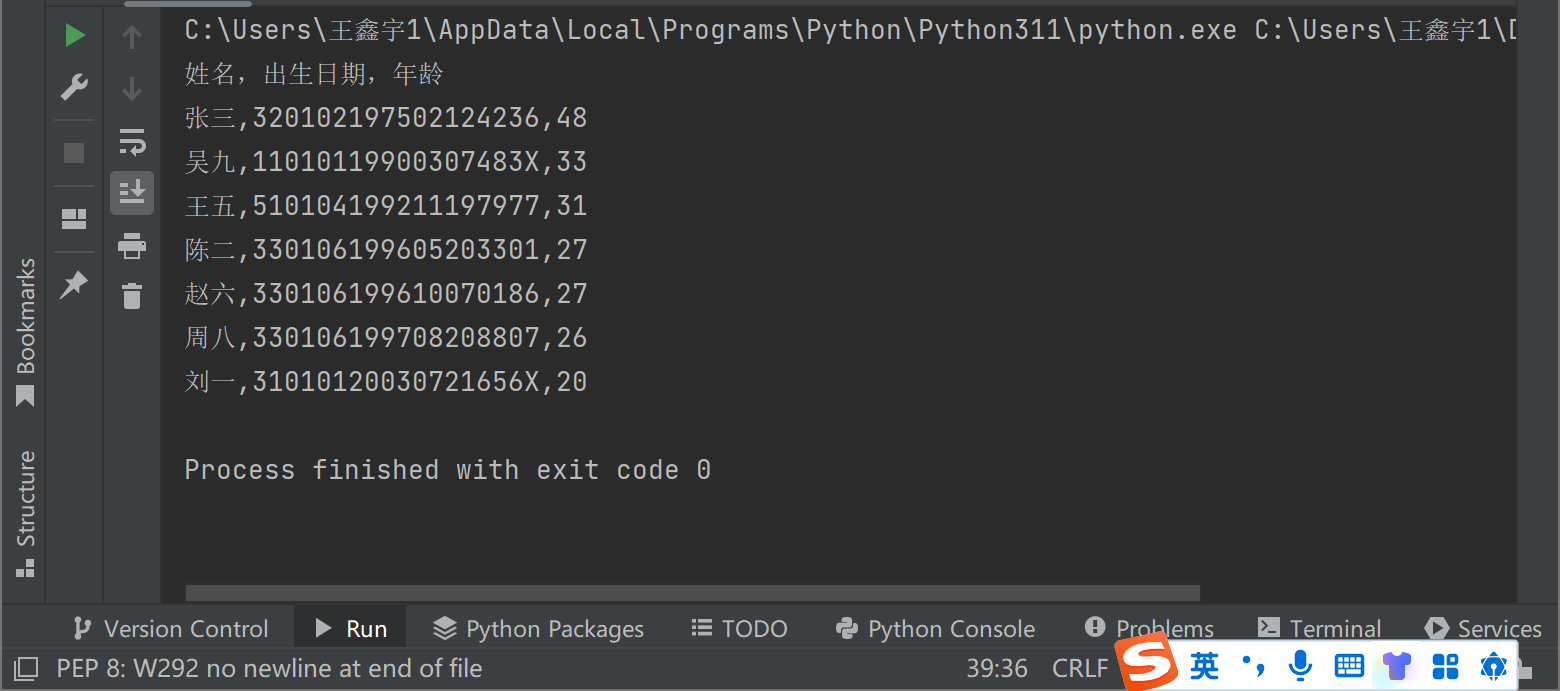
print('姓名,出生日期,年龄')
for a,b,c in data2:
print('{},{},{}'.format(a,b,c))
![]()
with open('data10_stu.txt','r',encoding = 'utf-8') as f:
data = f.readlines()
data1 = [i.strip('\n').split(',') for i in data]
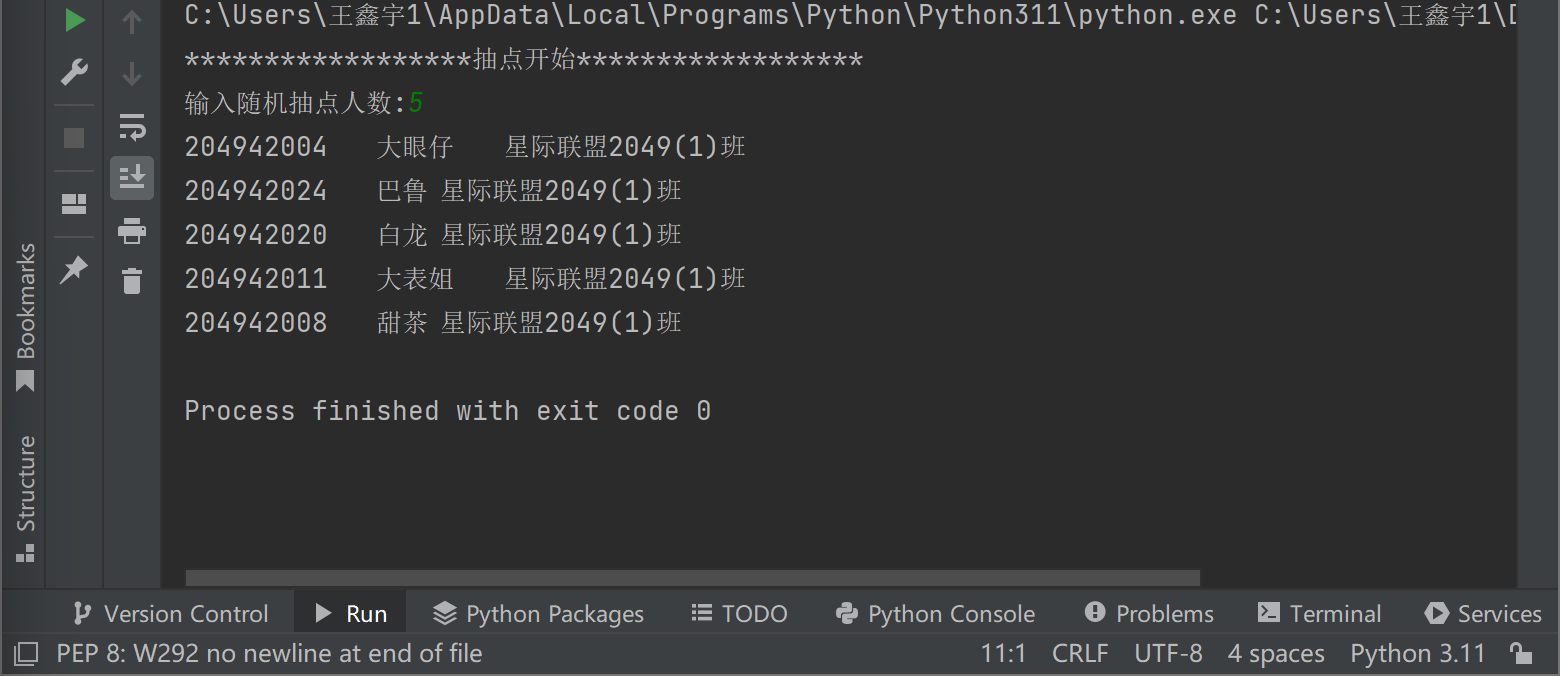
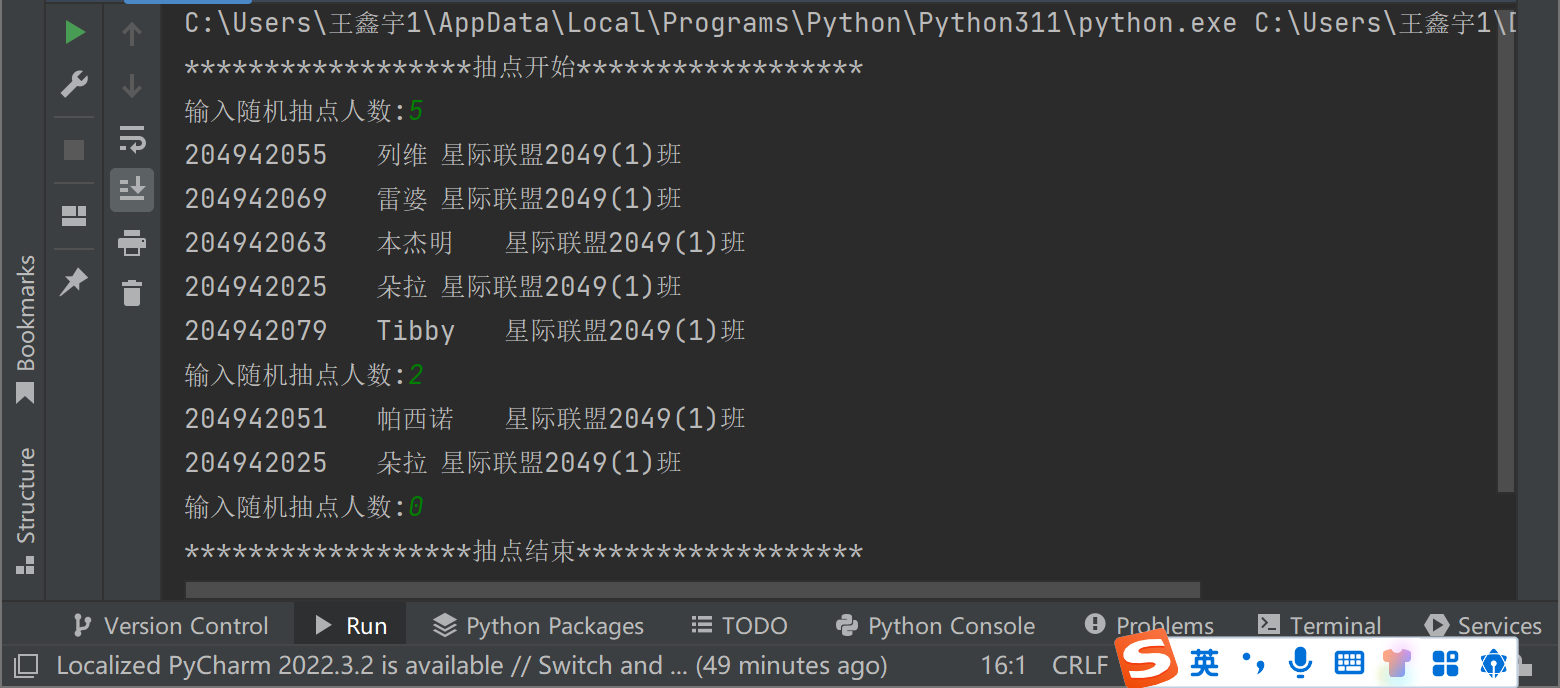
print('{:*^40}'.format('抽点开始'))
n = int(input('输入随机抽点人数:'))
import random
x = list(range(len(data1)))
t = random.sample(x,n)
for i in t:
for j in data1[i]:
print(j)
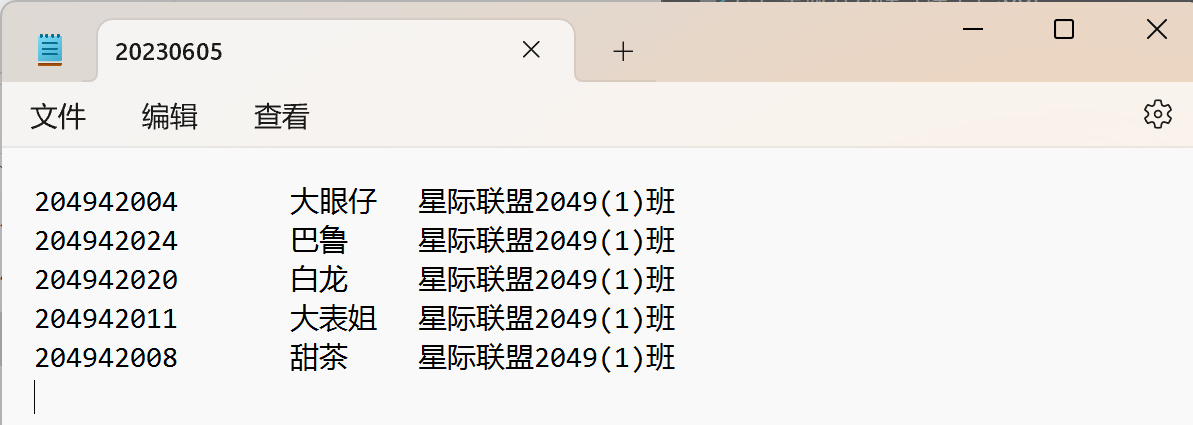
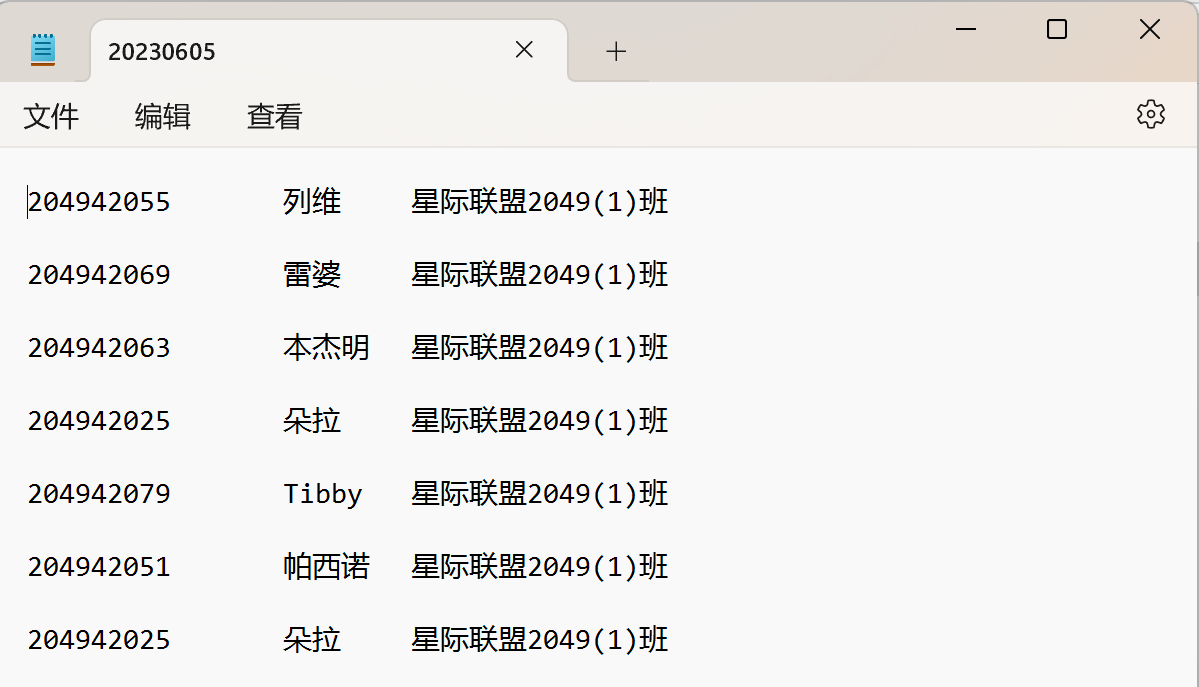
with open('20230605.txt','w',encoding='utf-8') as f:
for i in t:
f.write(','.join(data1[i])+'\n')
![]()
![]()
with open('data10_stu.txt','r',encoding = 'utf-8') as f:
data = f.readlines()
data1 = [i.strip('\n').split(',') for i in data]
print('{:*^40}'.format('抽点开始'))
n = int(input('输入随机抽点人数:'))
d= []
while n!=0:
import random
x = list(range(len(data1)))
t = random.sample(x,n)
for i in t:
d.append(data[i])
for j in data1[i]:
print(j)
n = int(input('输入随机抽点人数:'))
else:
print('{:*^40}'.format('抽点结束'))
with open('20230605.txt','w',encoding='utf-8') as f:
for i in d:
f.write(''.join(i)+'\n')
![]()
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号