
商品评价判别,文本分类——学习笔记
FASTTEXT(Facebook开源技术)
二分类任务,监督学习。
自然语言
NLP自然语言处理
步骤:
- 语料Corpus:好评和差评
- 分词Words Segmentation:基于HMM构建dict tree
-
构建词向量Construct Vector:
one-hot独热编码
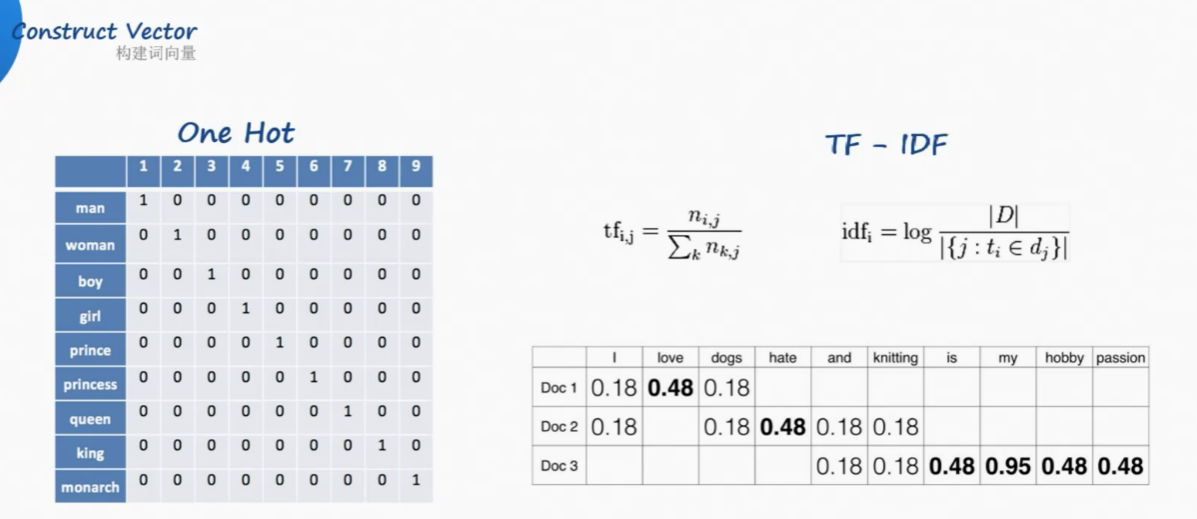
但是汉语中词太多了,独热编码的词向量随着词库中词汇的增长,会变得非常大。
而且one hot没法判断顺序
Google开山之作:TF-IDF(term frequency–inverse document frequency)
解决了频率和特殊性的关系。TF即词频(Term Frequency),IDF即逆向文档频率(Inverse Document Frequency)。
TF(词频)就是某个词在文章中出现的次数,此文章为需要分析的文本。为了统一标准,有如下两种计算方法:
(1)TF(词频) = 某个词在文章中出现的次数 / 该篇文章的总次数;
(2)TF 词频 = 某个词在文章中出现的次数 / 该篇文章出现最多的单词的次数;
IDF(逆向文档频率)为该词的常见程度,需要构建一个语料库来模拟语言的使用环境。
IDF 逆向文档频率 =log (语料库的文档总数 / (包含该词的文档总数+1));
如果一个词越常见,那么其分母就越大,IDF值就越小。
但还是有词向量长度的问题。
- 将vector每一个元素由整形改为浮点型,变为整个实数范围的表示
- 将原来稀疏的巨大维度压缩嵌入到一个更小维度的空间
word2vec
将独热编码当作输入,经过神经网络,判断one hot输出的是什么词

但是并没有关心输出的词是什么。隐藏层,100个隐藏神经元,100个权重。
而是将神经网络过程中的该层的权重作为了词向量。vector。
最终100维,

Fast-Text
天生用来分类,直接将构建词向量和模型(SVM、决策树、神经网络方法)集合,直接输出label类别标签。
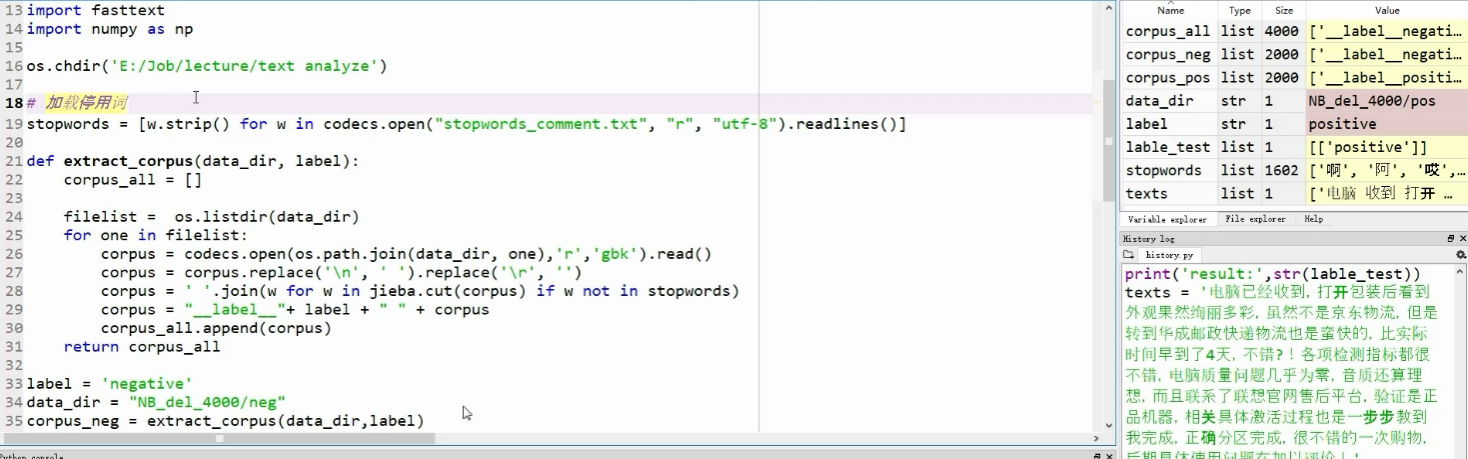
加载停用词:细节在于:问号、叹号包含人类情绪,要保留下来。

分词后结果:


两种训练模式:
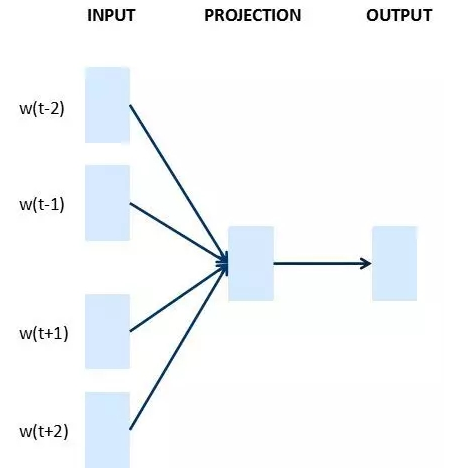
Skip-gram:当前词预测上下文

【参考】
不懂word2vec,还敢说自己是做NLP? - 自然语言处理-炼数成金-Dataguru专业数据分析社区 http://www.dataguru.cn/article-13488-1.html
FastText:快速的文本分类器 - 不忘初心~ - CSDN博客 https://blog.csdn.net/john_bh/article/details/79268850
谷歌最强 NLP 模型
BERT(Bidirectional Encoder Representations from Transformers)
BERT介绍 - triplemeng的博客 - CSDN博客 https://blog.csdn.net/triplemeng/article/details/83053419

 浙公网安备 33010602011771号
浙公网安备 33010602011771号