
http协议请求报文与响应报文分析
什么是HTTP协议:
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到
不断地完善和扩展。目前在WWW中使用的是HTTP/1.0的第六版,HTTP/1.1的规范化工作正在进行之中,而且HTTP-NG(Next Generation of HTTP)的
建议已经提出。
HTTP协议的主要特点可概括如下:
1.支持客户/服务器模式。
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。
由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3.灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
5.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能
导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
HTTP协议的URL
HTTP(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方式,HTTP1.1版本中给出一种持续连接的机制,
绝大多数的Web开发,都是构建在HTTP协议之上的Web应用。
HTTP URL (URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息)的格式如下:
http://host[":"port][abs_path]
http表示要通过HTTP协议来定位网络资源;host表示合法的Internet主机域名或者IP地址;port指定一个端口号,为空则使用缺省端口80;abs_path
指定请求资源的URI;如果URL中没有给出abs_path,那么当它作为请求URI时,必须以“/”的形式给出,通常这个工作浏览器自动帮我们完成。
举个例子:
1、输入:www.guet.edu.cn
浏览器自动转换成:http://www.guet.edu.cn/
2、http:192.168.0.116:8080/index.jsp
HTTP报文分析
在HTTP连接中报文分为请求(request)和响应(response)两种。每种报文在HTTP首部都有不同的字段来标识不同的用途。
报文结构如下:

1.请求报文:
HTTP协议使用TCP协议进行传输,在应用层协议发起交互之前,首先是TCP的三次握手。完成了TCP三次握手后,客户端会向服务器发出一个请求
报文。一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成。
请求报文的格式如下图抓包所示:

前三行为请求行,其余部分称为request-header。请求行中的method表示这次请求使用的是get方法。请求方法的种类比较多,如option,get,
post,head,put,delete,trace等,常用的主要是get,post。Get表示请求页面信息,返回页面实体;post是请求服务器将指定文档作为请求的
url中的从属实体,简单说,我们常用的在网页中填写表单然后申请等动作就是使用了post方法,填写用户名密码登录站点就使用了post方法,如下图:
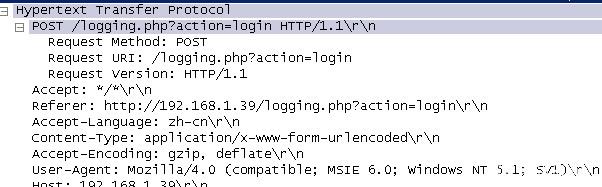
方法之后是URI,表示请求的页面地址,图中的“/”表示服务器的根目录。之后是表示http的版本。
请求行之后是请求首部。首部常见的部分有如下几个:
Accept:请求的对象类型。如果是“/”表示任意类型,如果是指定的类型,则会变成“type/”。
Accept-Language:使用的语言种类。
Accept-Encording:页面编码种类。
Accept-Charset:页面字符集。
User-Agent:提供了客户端浏览器的类型和版本。
Host:连接的目标主机,如果连接的服务器是非标准端口,在这里会出现使用的非标准端口。
Connection:对于HTTP连接的处理,keep-alive表示保持连接,如果是在响应报文中发送页面完毕就会关闭连接,状态变为close。
说到这里,需要解释以下字符集和编码的区别。字符集通常对应着一种语言,将语言中的所有字符集合起来就可以视为一种字符集,这样我们
可以看出,中文并非是一种字符集,因为中文无法使用一些字符来进行表示;而编码则是将字符转换为计算机所能识别的2进制数的一种方式,例
如常说的unicode,UTF-8,ANSI等等,我们在访问一些国外网站会出现乱码的原因就是因为我们浏览器所使用的编码与页面所使用的编码不能
互相识别。我们常说的BIG5和GB2312都是编码。
2. 响应报文:
当收到get或post等方法发来的请求后,服务器就要对报文进行响应。同样,响应报文也分为两部分。前两行称为状态行,状态行给出了服务
器的http版本,以及一个响应代码。响应代码是服务器根据请求进行查找后得到的结果的一种反馈,共有5大类。分别以1、2、3、4、5开头。
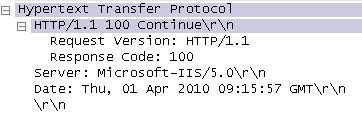
1**表示接收到请求,继续进程,在发送post后可以收到该应答。
2**表示请求的操作成功,在发送get后返回。
3**表示重发,为了完成操作必须进一步动作。
4**表示客户端出现错误。
5**表示服务器出现错误。
其余部分称为应答实体。
其中的server表示服务器软件版本,date标注了当前服务器的时间,connection标明连接关闭,抓包可以发现在响应返回后服务器向客
户端发出fin包单向关闭了连接。Expires表示在某个时间以前可以不用重新缓存该页面,而cache-control表示对页面是否进行缓存。Pragma
的参数no-cache表示对页面不进行缓存。而content-type表示了应答请求后返回的内容类型。Content还有内容长度和内容语言以及内容编
码三个项,其中内容长度只有在请求报文中的connection值为keep-alive时才会用到。
3. Cookie:
cookie是一种类似缓存的机制,它保存在一个本地的文本文件中,其主要作用是在发送请求时将cookie放在请求首部中发送给服务器,服
务器收到cookie后查找自己已有的cookie信息,确定客户端的身份,然后返回相应的页面,cookie的方便之处在于可以保持一种已登录的状态,
例如:我们注册一个论坛,每次访问都需要进行填写用户名和密码然后登录。而使用了cookie后,如果cookie没有到达过期时间,那么我们只需
在第一次登录时填写信息然后登录,以后的访问就可以省略这一步骤。
在HTTP协议中,cookie的交互过程是这样的:首先是三次握手建立TCP连接,然后客户端发出一个http request,这个request中不包含
任何cookie信息。
当服务器收到这个报文后,针对request method作出响应动作,在响应报文的实体部分,加入了set-cookie段,set-cookie段中给出
了cookie的id,过期时间以及参数path,path是表示在哪个虚拟目录路径下的页面可以读取使用该cookie,将这些信息发回给客户端后,客
户端在以后的http request中就会将自己的cookie段用这些信息填充。

如果用户在连接中通过了服务器相应的认证程序,服务器会添加一个cdb_auth到set-cookie中,这个段表示了客户端的认证信息,而客户
端以后在访问过程中也会将cdb_auth信息写入自己的cookie字段。服务器每次收到http request后读取cookie,然后根据cookie的信息返
回不同的页面。例如,没有通过认证的客户端在request中不会有cdb_auth,因此服务器读取cookie后,不会将通过认证的客户端的页面返回
给该客户端。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号