爬的没意识了--1
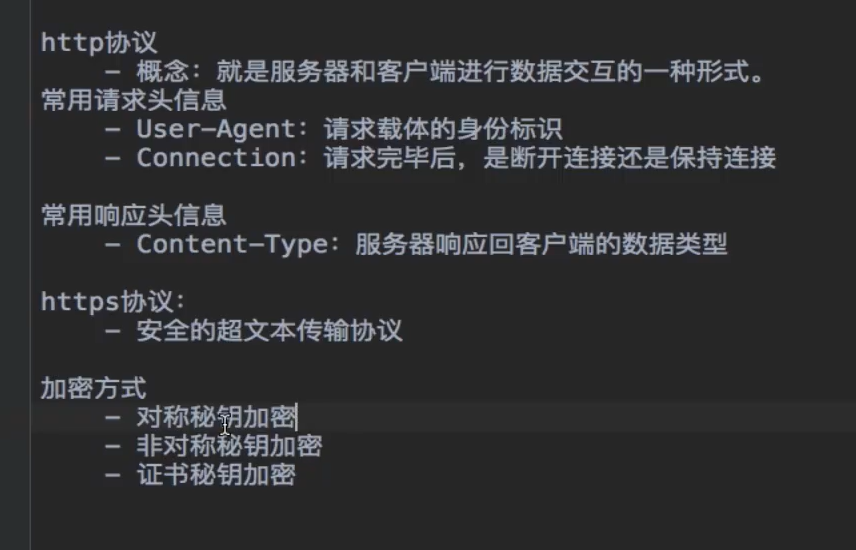
https的相关的理解操作
三种联系的方法:1.直接传,2.公钥+私钥,3.对应的证书
基于网络请求的模块
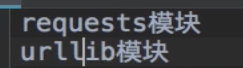
关于requests模块的作用

是属于在python里面原装的
掌握了requests就相当于掌握了爬虫的半壁江山
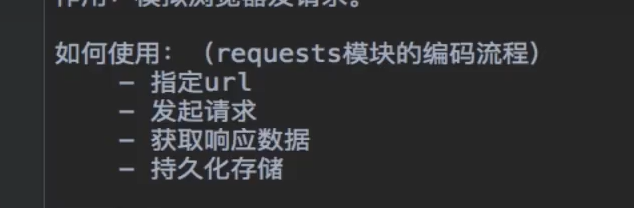
手动在python里面添加requests
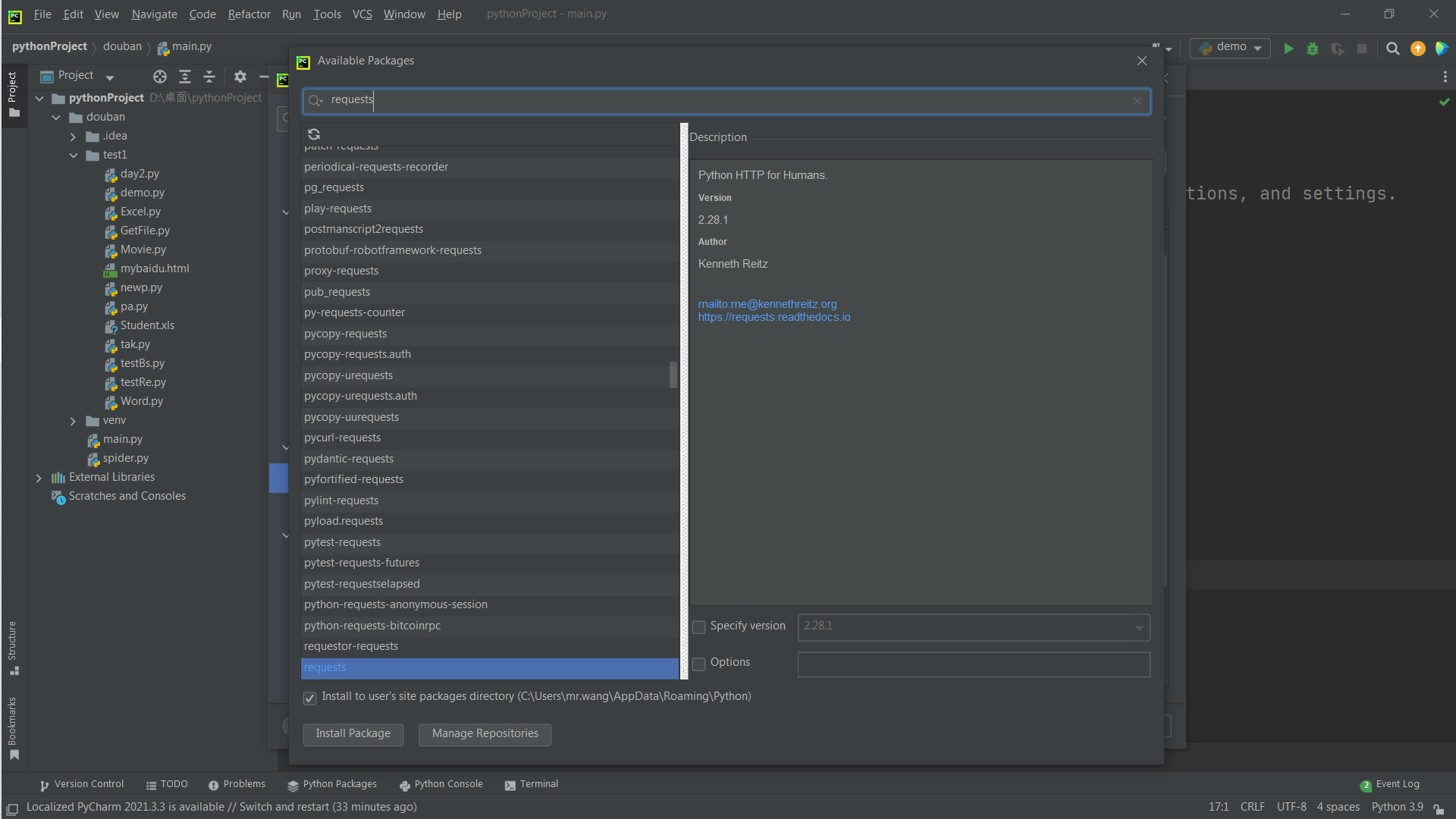
这样就搭建好了环境
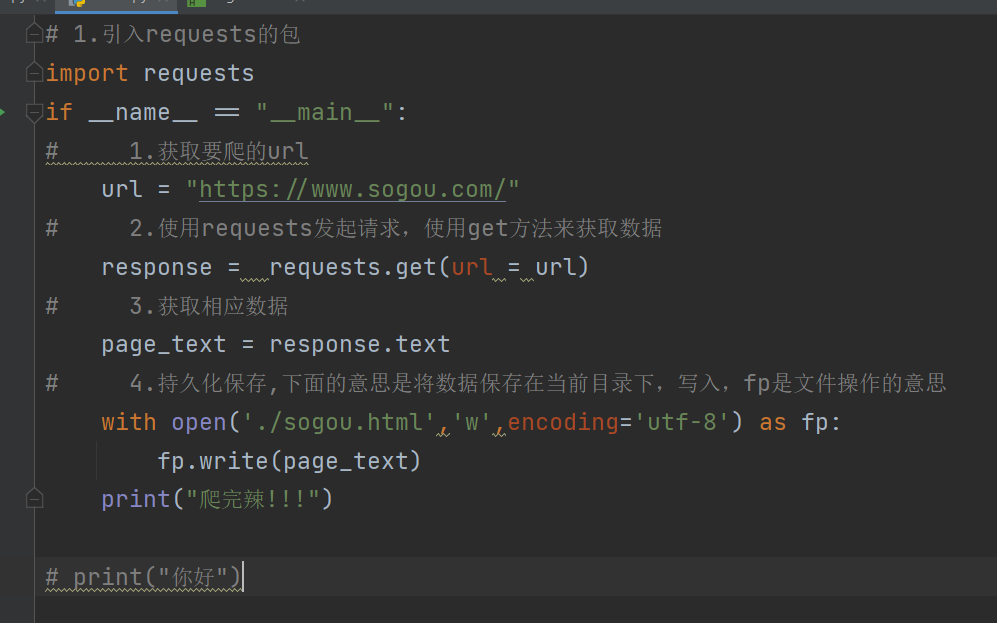
超级简单的爬虫

可以将你爬过来的代码转换成正常的样子
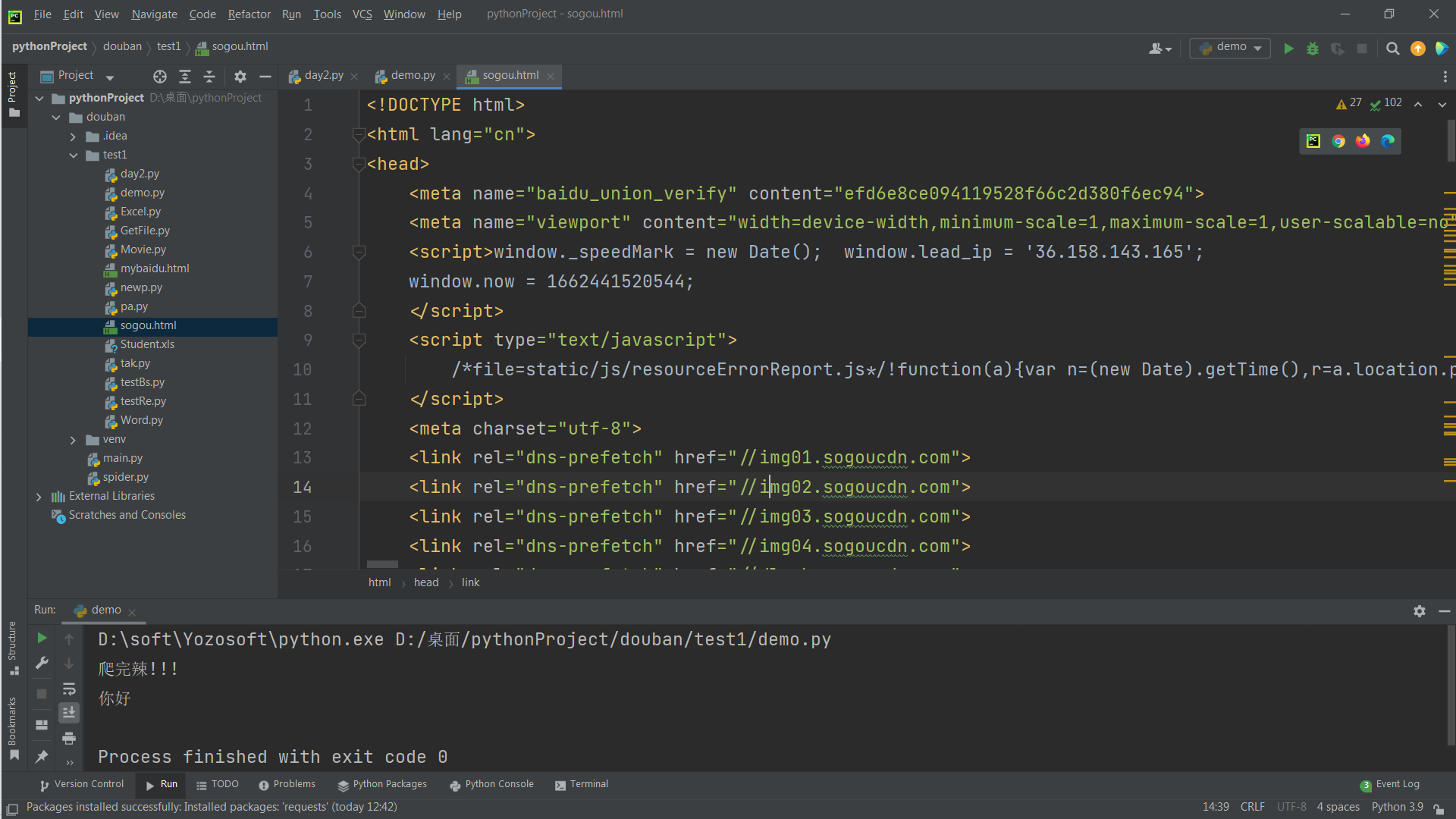
之前长这样
一.项目查找搜索后的界面
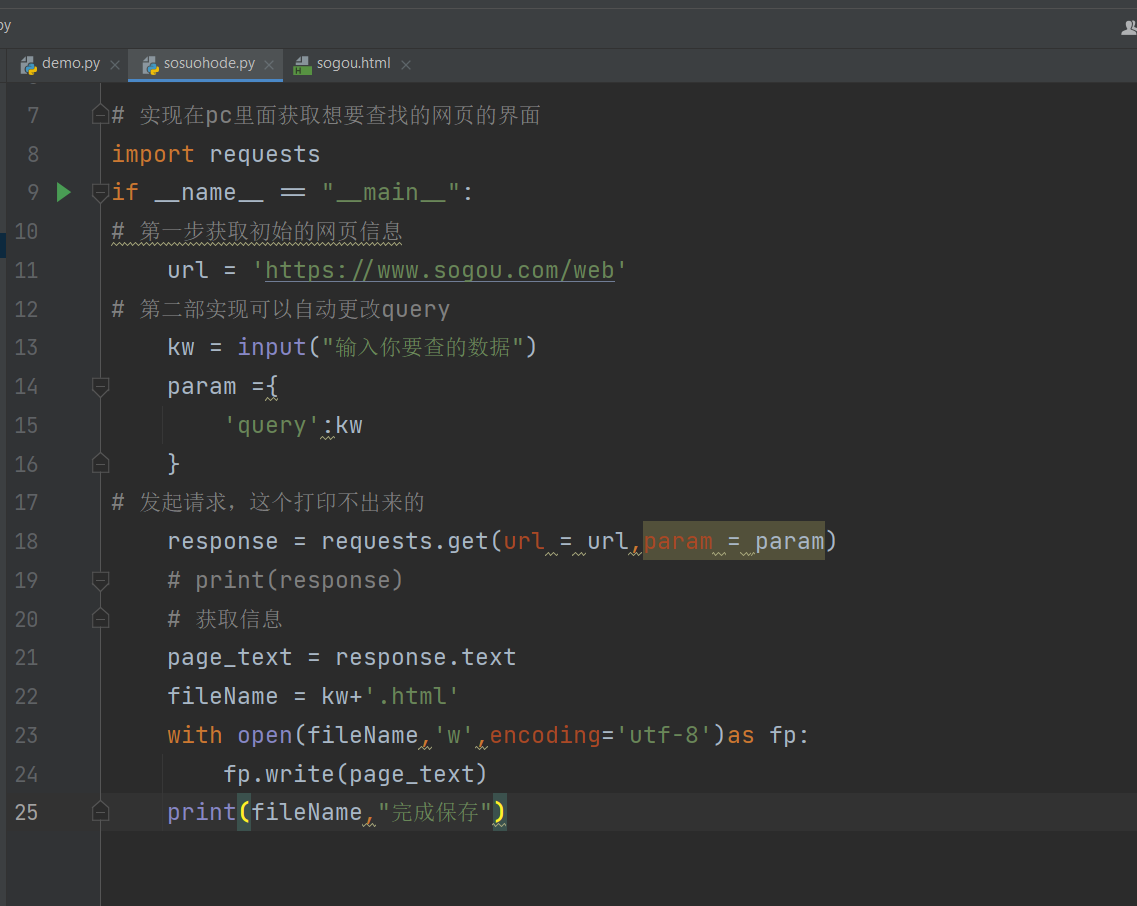
UA伪装:将自己的一个地址伪装成一个浏览器,这样就不会被网站给拒绝访问

所以咱们爬的时候要将这个放到我们的浏览器里面去
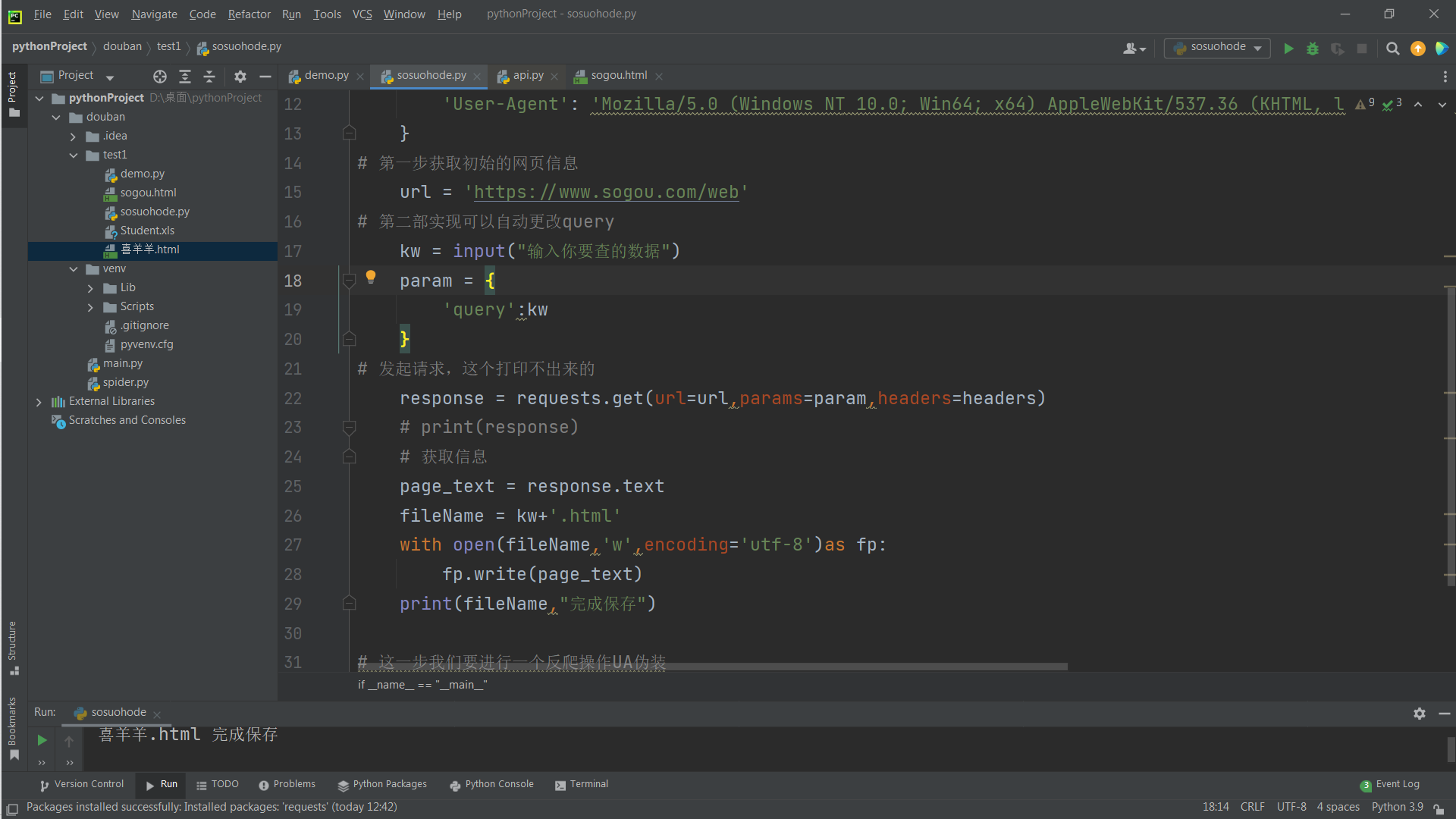
爬取成功
之前把那个params的s忘记打了一直报错
# -*- codeing = utf-8 -*-
# @Time : 2022/9/6 14:03
# @File :sosuohode.py
# @Software: PyCharm
# 实现在pc里面获取想要查找的网页的界面
import requests
if __name__ == "__main__":
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.27'
}
# 第一步获取初始的网页信息
url = 'https://www.sogou.com/web'
# 第二部实现可以自动更改query
kw = input("输入你要查的数据")
param = {
'query':kw
}
# 发起请求,这个打印不出来的
response = requests.get(url=url,params=param,headers=headers)
# print(response)
# 获取信息
page_text = response.text
fileName = kw+'.html'
with open(fileName,'w',encoding='utf-8')as fp:
fp.write(page_text)
print(fileName,"完成保存")
# 这一步我们要进行一个反爬操作UA伪装
二.爬取百度翻译
获取整个页面的部分信息【即翻译出来的那一部分】
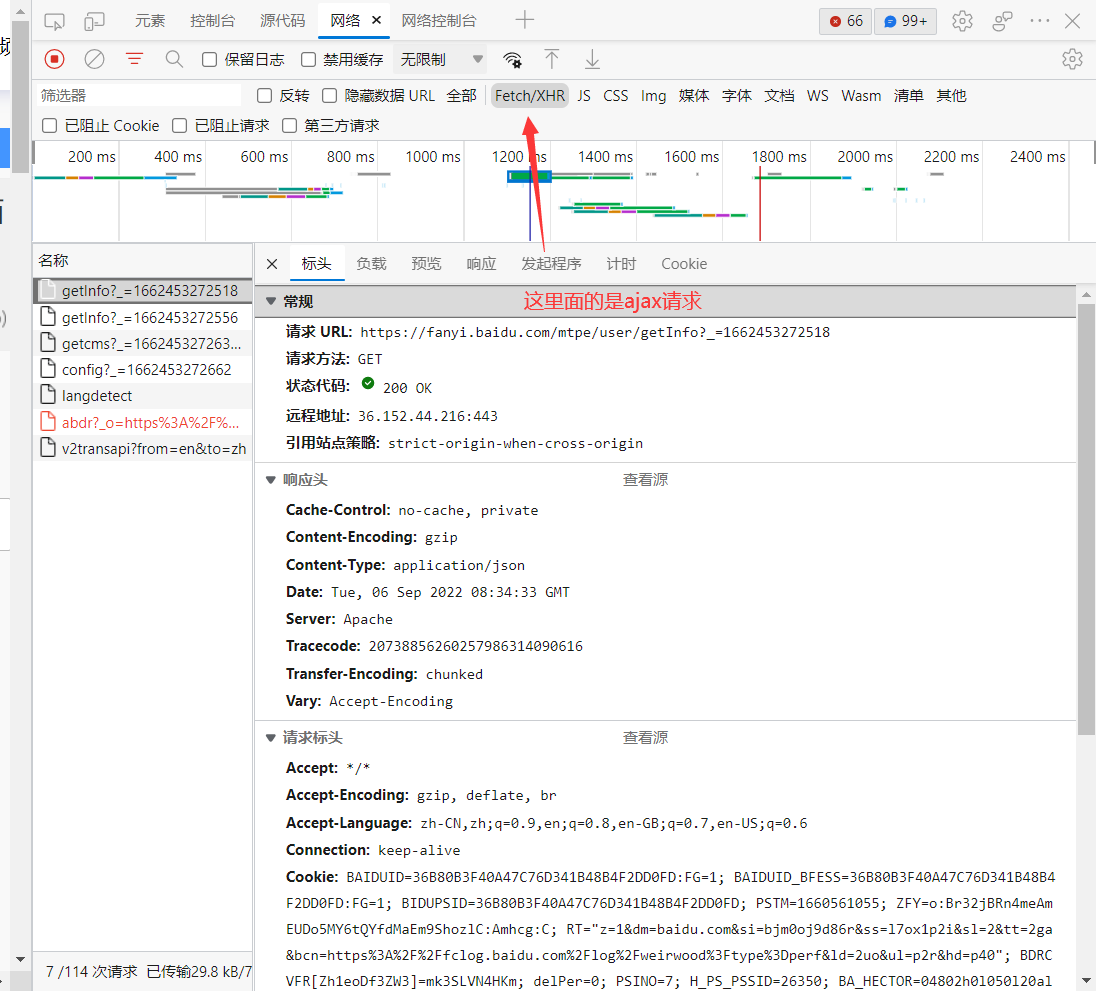
全部里面就是全部的请求
具体代码
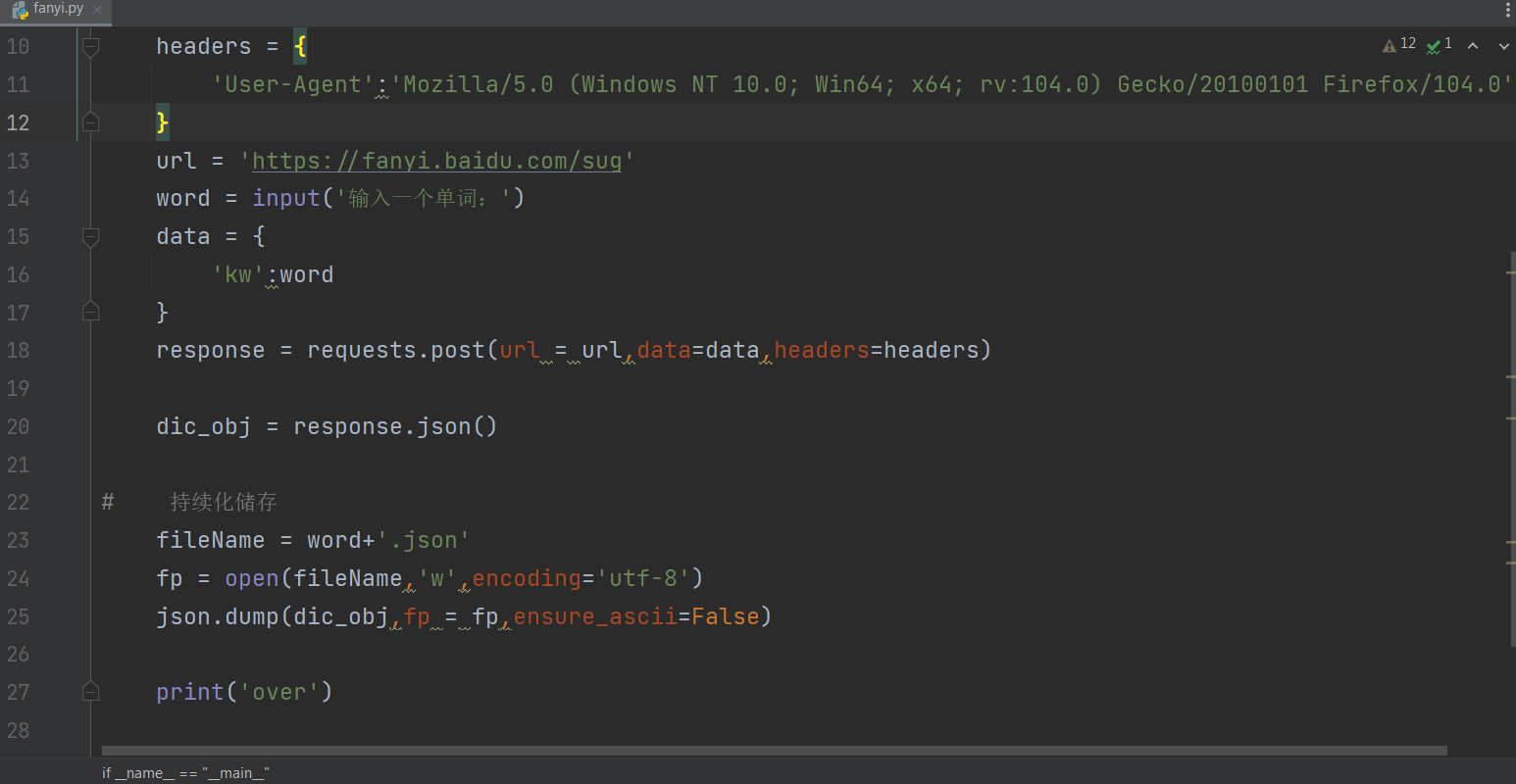
这样子就可以只获取需要的部分
json.dump()方法就是将python获取到的数据转换成json字符串的形式,当然要使用这个方法首先要这个获取到的是json格式的才行
三.爬取豆瓣电影
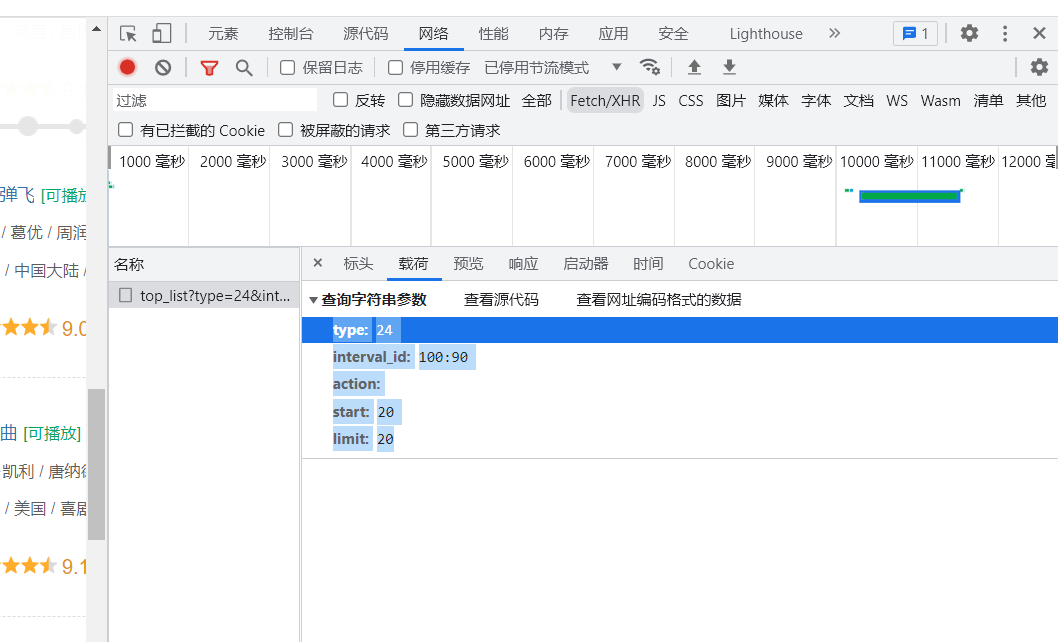
参数数据所在的位置
10
# -*- codeing = utf-8 -*-
# @Time : 2022/9/6 21:10
# @Name : 王星
# @File :doban.py
# @Software: PyCharm
import requests
import json
if __name__=='__main__':
# 放入地址【指的是刷新的时候弹出来的地址】
url = 'https://movie.douban.com/j/chart/top_list'
param = {
'type':'24',
'interval_id':'100:90',
'action':'',
'start':'20',
'limit':'20'
}
header = {
'User-Agent':'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 104.0.0.0Safari / 537.36'
}
response = requests.get(url=url,params=param,headers=header)
# 因为数据是json格式的
list_data = response.json()
fp = open('./doban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
print("over!!!!!!")
爬取豆瓣的代码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号