

性能分析之TCP全连接队列占满问题分析及优化过程(转载)
前言
在对一个挡板系统进行测试时,遇到一个由于TCP全连接队列被占满而影响系统性能的问题,这里记录下如何进行分析及解决的。
理解下TCP建立连接过程与队列
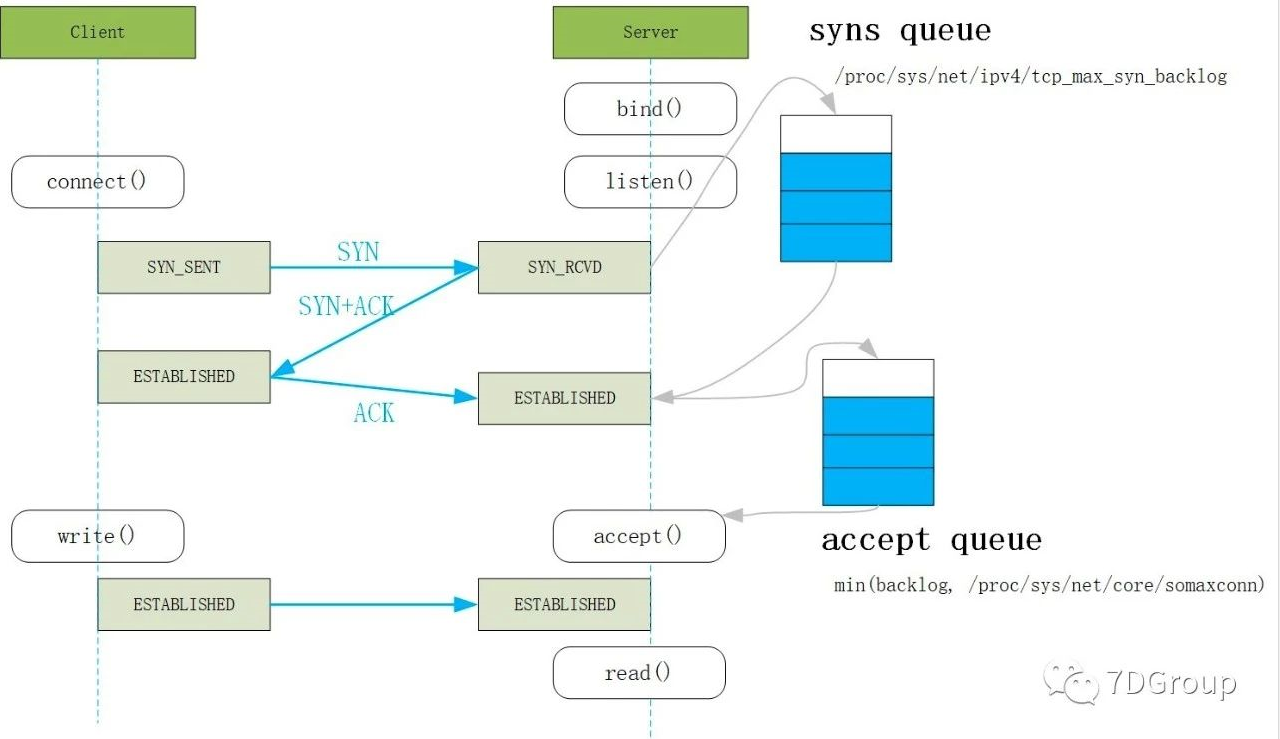
从图中明显可以看出建立 TCP 连接的时候,有两个队列:syns queue(半连接队列)和accept queue(全连接队列),分别在第一次握手和第三次握手。
半连接队列: 保存 SYN_RECV 状态的连接。
控制参数:
-
半连接队列的大小:min(backlog, 内核参数 net.core.somaxconn,内核参数tcp_max_syn_backlog).
-
net.ipv4.tcp_max_syn_backlog:能接受 SYN 同步包的最大客户端数量,即半连接上限;
-
tcp_syncookies:当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
accept队列-全连接队列:保存 ESTABLISHED 状态的连接。
控制参数:
-
全连接队列的大小:min(backlog, /proc/sys/net/core/somaxconn),意思是取backlog 与 somaxconn 两值的最小值,
net.core.somaxconn定义了系统级别的全连接队列最大长度,而 backlog 只是应用层传入的参数,所以 backlog 值尽量小于net.core.somaxconn; -
net.core.somaxconn(内核态参数,系统中每一个端口最大的监听队列的长度); -
net.core.netdev_max_backlog(每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目); -
ServerSocket(int port, int backlog) 代码中的backlog参数;
-
文件句柄;
-
net.ipv4.tcp_abort_on_overflow= 0,此值为 0 表示握手到第三步时全连接队列满时则扔掉 client 发过来的 ACK,此值为 1 则说明握手到第三步时全连接队列满时则返回 reset 给客户端。
系统概况
系统的整体架构比较简单,只有一个挡板服务,业务功能主要是接受业务数据写入日志文件,并加了 35 ms的延时等待,没有复杂的运算等业务逻辑。
开始第一次压测
以 6000 线程并发,加 1 秒的等待,对挡板服务发起压力,压测结果如下:
PS:应客户要求,为了模拟真实业务场景,用较大并发进行测试。
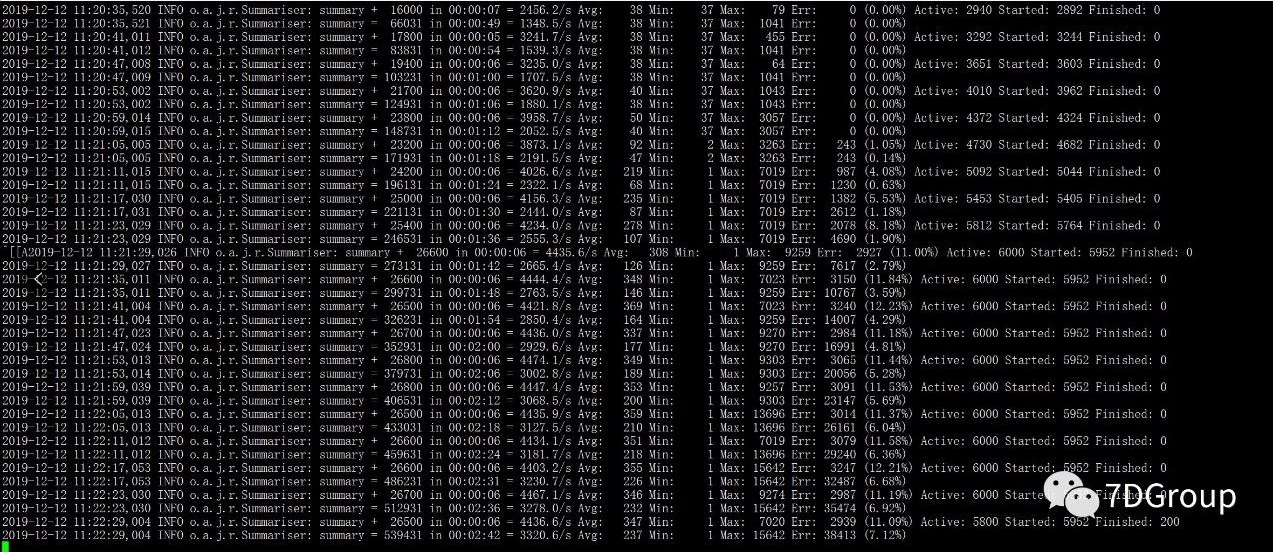
通过上图可以看出,当系统吞吐量也就是 TPS 达到 3800 左右的时候,系统开始出现部分请求失败,继续压一段时间后,报错没有减少,且有增多的趋势。这是什么原因导致的呢,接着我也观察了下,系统的资源使用情况,发现CPU也不是很高,那可以先排除系统CPU资源的问题。

这时候,我们一定要记住,当出现请求事务大量失败的时候,一定要先看以下具体的错误信息,在继续往下面分析,而不是进行盲目的猜测,这里要提一下高楼老师经常强调的证据链,一定要根据详细的错误信息指向进行下一步分析,不能根据猜测进而通过修改一些参数,或者增加系统资源来解决问题。
以下是具体的报错信息:

看到报错信息后,发现有大量的 “Connection reset” 错误,导致这种错误的原因就是服务端因为某种原因关闭了 Connection,而客户端仍然在读写数据,此时服务器会返回复位标志 “RST”,也就是刚才提到的 `“java.net.SocketException: Connection reset”。参考 Oracle 的相关文档,看到这么一段话,原文如下:
By contrast, an abortive close uses the RST (Reset) message. If either side issues an RST, this means the entire connection is aborted and the TCP stack can throw away any queued data which has not been sent or received by either application.
翻译过来也就是说:
如果任何一方发出RST,这意味着整个连接被中止,TCP栈可以丢弃任何没有被任何应用程序发送或接收的队列数据。
这样的话,问题就很明显了,接下来看下 TCP 连接队列的溢出数据统计情况,命令为:“netstat -s”
# 查看TCP半连接队列溢出:
netstat -s | grep LISTEN
# 查看TCPaccept队列溢出:
netstat -s | grep overflow 
通过反复敲命令,可以看出这个 overflow 的值一直在增加,那么这个现象说明 server 的TCP 全连接队列的确是满了。这时候应该想到的是,全连接队列已经溢出了,下一步就应该看一下,全连接队列的占用情况,命令为:
参数说明:
-
Recv-Q:全连接当前长度
-
Send-Q:如果连接不是在建立状态,则是当前全连接最大队列长度
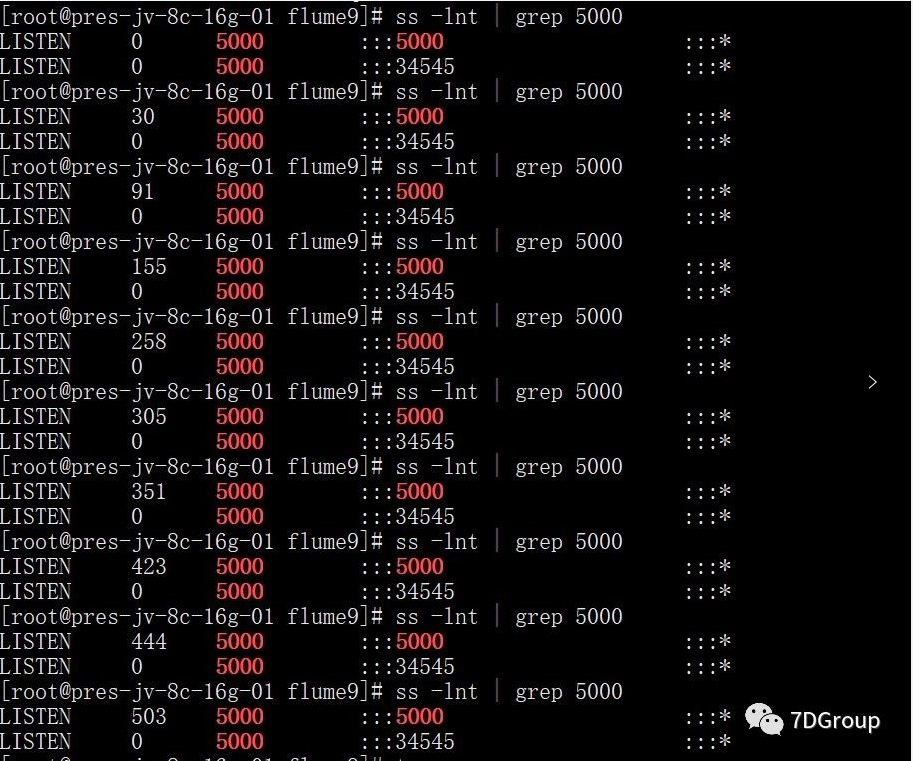
从上图第三列的 Send-Q 可以看出,5000 端口服务的全连接队列最大为 50,而 Recv-Q 为当前使用了多少。在压测过程中,查看指定端口的 TCP 全连接队列使用情况,如下:

上图可以看出,全连接队列几乎已经被占满,那么最终可以确定问题所在了。找到原因后,现在只要增大全连接队列的长度就可以了。
通过上面介绍的全连接队列中,我们知道全连接队列的大小为 backlog 和 somaxconn 的最小值,那么来看下 somaxconn 的取值。

可以看出 somaxconn 的值是很大的,那就只有通知开发,增加应用代码中的 backlog 的值来加大全连接队列的长度。
调大backlog值为5000后,再次进行压测
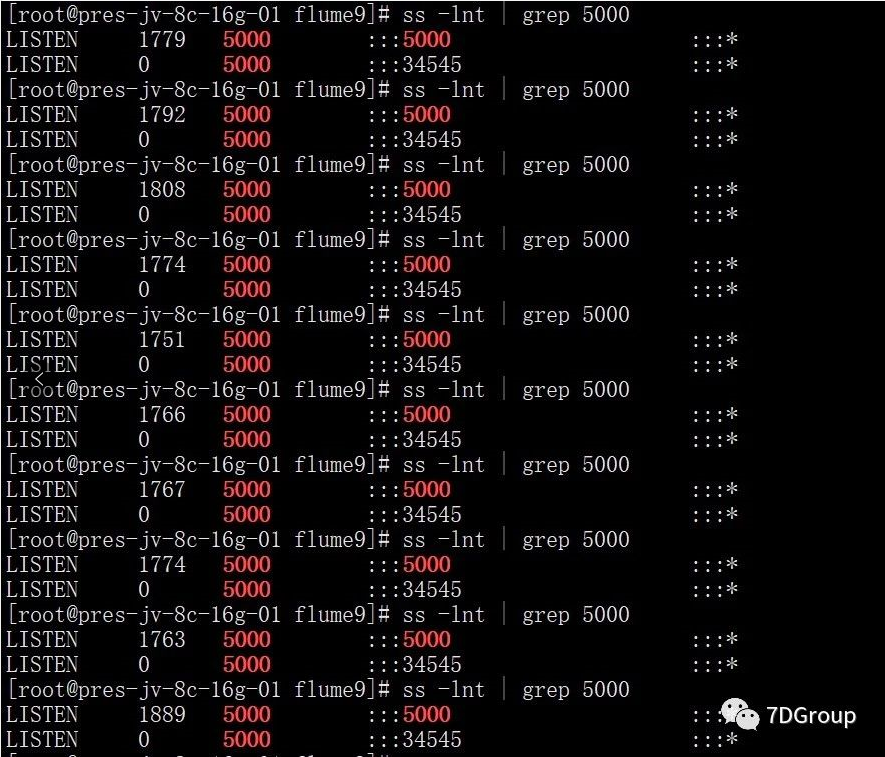
调整后的全连接队列如下图所示:
继续以 6000 并发对系统发起压力,测试结果如下:

从上面的测试结果数据看出,已经没有错误请求了,再次查看TCP全连接队列的使用情况,Recv-Q的值也变得很大,但是仍小于 5000,这也说明之前的 50 的确太小,导致全连接队列被占满,最终影响系统性能,出现大量请求失败,到此,由 TCP 连接队列满导致的问题解决。
但是仔细看上面的 JMeter 的测试结果数据,发现当系统并发达到 4600 多后,再继续加大线程,系统的响应时间开始大幅度的增加,TPS增加趋势变缓,可以看出来此时系统仍存在瓶颈。
发现仍问题后,接着往下分析。系统没有报错,响应时间变长,导致系统吞吐量增长速度变慢。这时应该清楚的是,接下来该看什么。首先查看系统CPU使用情况,发现并不是很高,说明不是系统资源不够用而引起的问题。因为挡板服务本身没有什么业务逻辑,只是加了 35 ms的延时,那么如果响应时间变慢了,那么多半是由于网络传输出现阻塞导致。
所以使用命令:
netstat -ano | grep 10.231.44.249:5000 | grep ESTABLISHED | more
看下网络队列情况:
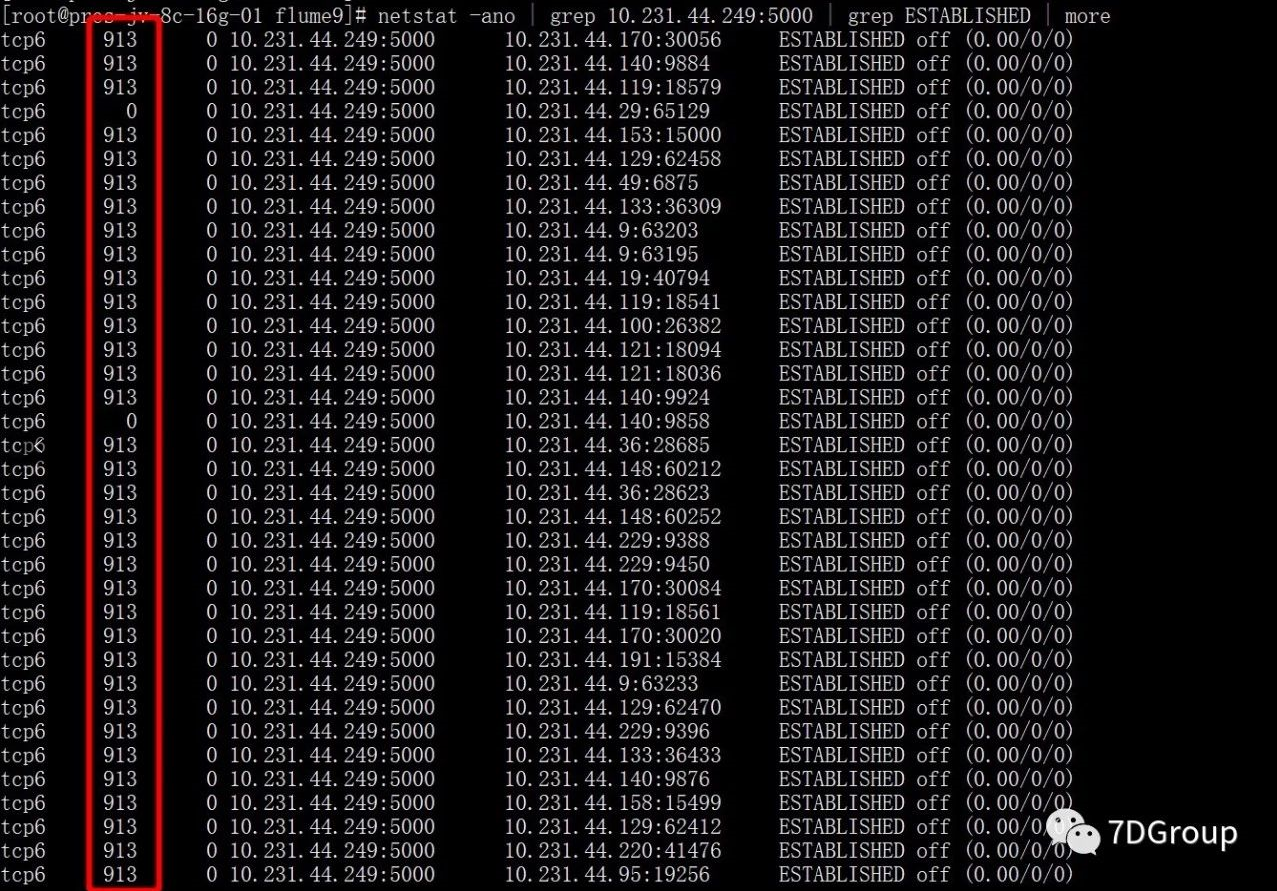
参数说明:
-
Send-Q:发送队列中没有被远程主机确认的 bytes 数;
-
Recv-Q:指收到的数据还在缓存中,还没被进程读取,这个值就是还没被进程读取的
-
bytes;一般是CPU处理不过来导致的。
可以看出图中标红列的数据不为 0,通过上面的解释可以判断出是系统 CPU 处理不过来了,但是CPU也没有被充分使用,那为什么会出现这种情况呢。接下我们就该看一下,CPU 在做什么。
这里使用阿里的开源工具 arthas(arthas的安装及使用这里不过多介绍了),看下挡板服务是否存在线程的资源争用或者阻塞等,发现结果如下,存在大量的线程状态为 BLOCKED
命令:thread | grep BLOCKED

命令:thread -b
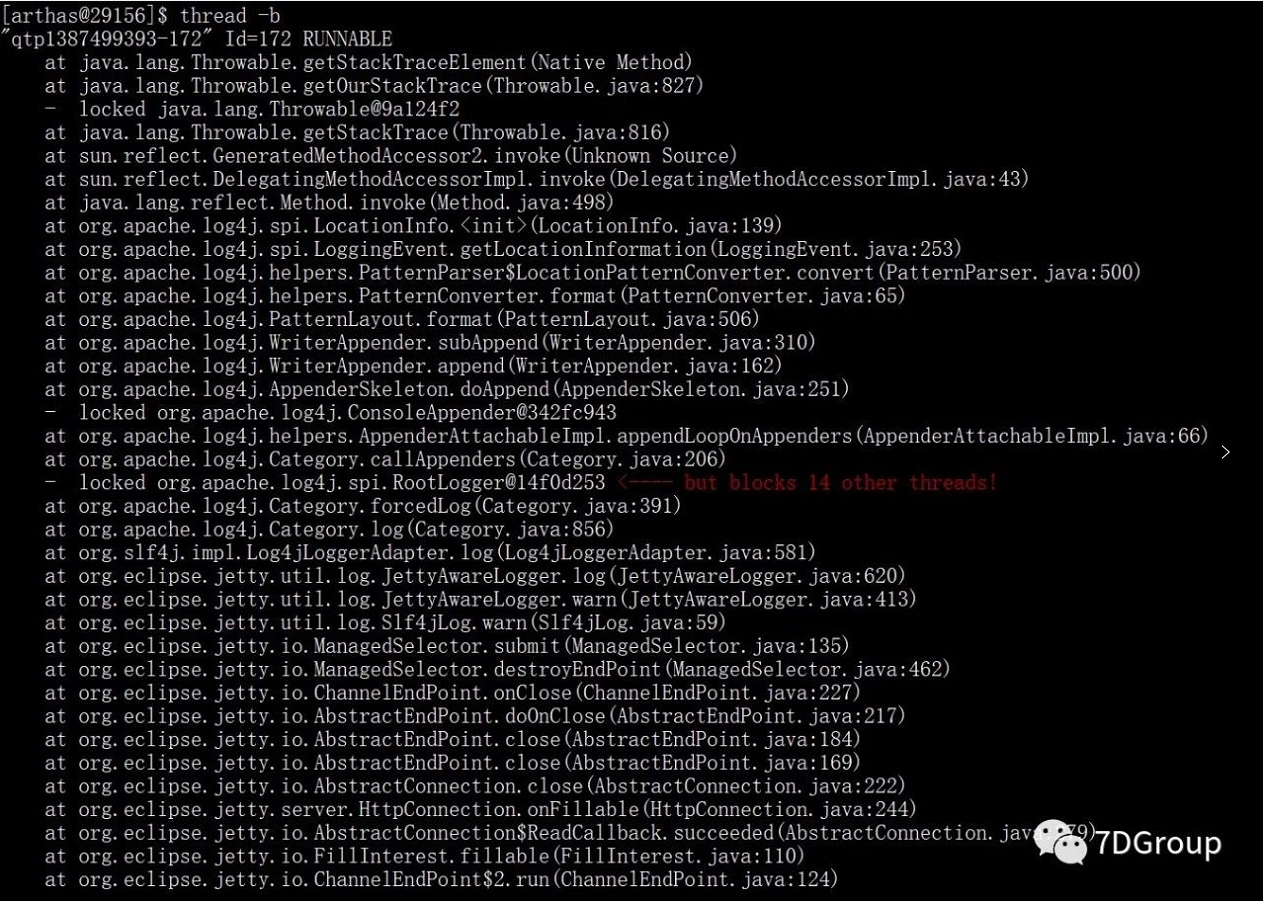
看到具体的线程栈信息后,问题就比较明显了,是一个写日志的锁导致出现线程阻塞,严重影响系统的处理能力。
为了快速的验证是写日志导致的,调整日志级别为 ERROR,再次发起压力,看问题是否解决,测试结果如下:
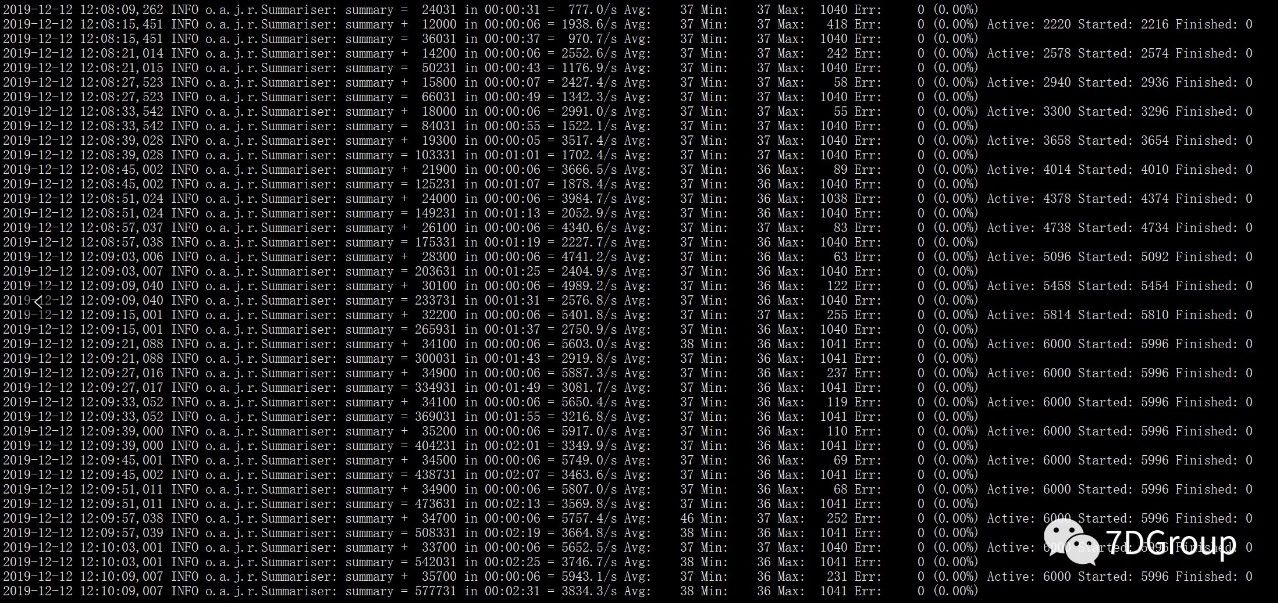
调整日志级别后,系统的响应时间保持在 37 ms左右,吞吐量有了大幅度的提升,问题解决。
小结
通过上面的分析案例,需注意以下几点:
-
压测时,如果出现请求大量失败时,记住一定要先解决报错,在进行下一步的分析;
-
进行性能分析时,一定要找到相应的证据链一步一步的往下分析,而不是盲目的猜测,通过修改参数及加大资源配置来解决问题;
-
响应时间长,TPS上不去这种问题,一定要对时间进行拆分拆解,找到时间具体慢在哪里,再进行进一步的分析优化。
转自:https://mp.weixin.qq.com/s/Bjjrk85MTTSiHoECNIWEaw
多学一点:
一、查看当前系统下所有连接状态的数
netstat -n|awk '/^tcp/{++S[$NF]}END{for (key in S) print key,S[key]}'
ESTABLISHED 38
TIME_WAIT 1000
二、看下我系统上默认的SYN队列大小
[root@log]# cat /proc/sys/net/ipv4/tcp_max_syn_backlog
262144
定义SYN队列大小:
echo 4096 > /proc/sys/net/ipv4/tcp_max_syn_backlog --定义是php配置的两倍,大于php的就行
三、看下我系统上默认的TIME_WAIT队列大小
cat /proc/sys/net/ipv4/tcp_max_tw_buckets
1000
定义TIME_WAIT的大小:
echo 4096 > /proc/sys/net/ipv4/tcp_max_tw_buckets
四、修改backlog参数
Kernel会为LISTEN状态的socket维护两个队列,一个是SYN RECEIVED状态,另一个是ESTABLISHED状态,而backlog就是这两个队列的大小之和。
当前Linux版本使用上面说法,有两个队列:具有由系统范围设置指定的大小的SYN队列 和 应用程序(也就是backlog参数)指定的accept队列。
五、查看系统默认数量:
cat /proc/sys/net/core/netdev_max_backlog
定义队列的数据包的最大数目
echo "4096" > /proc/sys/net/core/netdev_max_backlog #在每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
六、nginx 配置参数优化:
有代理就设置在代理上:没有代理就直接设置在web应用上(或者两个都设置)
upstream js_sdk {
#ip_hash;
server ******* weight=1 max_fails=3 fail_timeout=10s;
server ******* weight=1 max_fails=3 fail_timeout=10s;
keepalive 1000;
}
server {
listen 80 default backlog=1024;
listen 443 ssl default backlog=1024;
七、php优化:(-1 表示没有使用系统的 backlog )
vim /usr/local/php/etc/php-fpm.conf
listen.backlog = 2048 #每一个端口最大的监听队列的长度,需要配置nginx配置文件使用,如下(暂时只更改这里)
八、linux内核参进行优化:
vim /etc/sysctl.conf
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 4096 #对于还未获得对方确认的连接请求,可保存在队列中的最大数目。如果服务器经常出现过载,可以尝试增加这个数字。
net.core.somaxconn = 4096 #定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数。backlog需要设置这个
使用命令使之生效:sysctl -p
转自:https://blog.csdn.net/u010917150/article/details/95621873

 浙公网安备 33010602011771号
浙公网安备 33010602011771号