

作业总结
作业①:
要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
候选网站:豆瓣电影:https://movie.douban.com/top250
import requests from bs4 import BeautifulSoup import re,os import threading import pymysql import urllib class MySpider: def startUp(self,url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36' } self.opened = False try: self.con = pymysql.connect(host='localhost',port=3306,user='host',passwd='123456',database='mydata',charset='utf8') self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.opened = True except Exception as err: print(err) self.opened = False self.no = 0 self.Threads = [] urls = [] for i in range(10): url = 'https://movie.douban.com/top250?start=' + str(i*25) + '&filter=' print(url) page_text = requests.get(url=url,headers=headers).text soup = BeautifulSoup(page_text,'lxml') lists = soup.select("ol[class='grid_view'] li") print(len(lists)) for li in lists: rank = li.select("div[class='item'] div em")[0].text moviename = li.select("div[class='info'] div a span[class='title']")[0].text print(moviename) dir_act = li.select("div[class='info'] div[class='bd'] p")[0].text dir_act = ' '.join(dir_act.split()) try: direct = re.search(':.*:',dir_act).group()[1:-3] except: direct = "奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano " # print(direct) # print(dir_act) s = dir_act.split(':') # print(s) try: main_act = re.search(r'(\D)*',s[2]).group() except: main_act = "..." # print(main_act) pattern = re.compile('\d+',re.S) show_time = pattern.search(dir_act).group() # print(show_time) countryAndmovie_type = dir_act.split('/') country = countryAndmovie_type[-2] movie_type = countryAndmovie_type[-1] score = li.select("div[class='info'] div[class='star'] span")[1].text # print(score) count = re.match(r'\d+',li.select("div[class='info'] div[class='star'] span")[3].text).group() # print(score,count,quote) img_name = li.select("div[class='item'] div a img")[0]["alt"] try: quote = li.select("div[class='info'] p[class='quote'] span")[0].text except: quote = "" # print(img_name) img_src = li.select("div[class='item'] div a img[src]")[0]["src"] path = 'movie_img\\' + img_name + '.jpg' # print(img_name,img_src,path) print(rank, '2', moviename, '3', direct, '4', main_act, '5', show_time, '6', country, '7', movie_type, '8', score, '9', count, '10', quote, '11', path) try: self.insertdb(rank,moviename,direct,main_act,show_time,country,movie_type,score,count,quote,path) self.no += 1 except Exception as err: # print(err) print("数据插入失败") if url not in urls: T = threading.Thread(target=self.download,args=(img_name,img_src)) T.setDaemon(False) T.start() self.Threads.append(T) # print(len(li_list)) def closeUp(self): if self.opened: self.con.commit() self.con.close() self.opened = False def download(self,img_name,img_src): dir_path = 'movie_img' if not os.path.exists(dir_path): os.mkdir(dir_path) # for img in os.listdir(movie_img): # os.remove(os.path.join(movie_img,img)) file_path = dir_path + '/' + img_name + '.jpg' with open(file_path,'wb') as fp: data = urllib.request.urlopen(img_src) data = data.read() # print("正在下载:" + img_name) fp.write(data) # print(img_name+ "下载完成") fp.close() def insertdb(self,rank,moviename,direct,main_act,show_time,country,movie_type,score,count,quote,path): if self.opened: self.cursor.execute("insert into movies(rank,moviename,direct,main_act,show_time,country,movie_type,score,count,quote,path)values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (rank,moviename,direct,main_act,show_time,country,movie_type,score,count,quote,path)) else: print("数据库未连接") url = 'https://movie.douban.com/top250' myspider = MySpider() myspider.startUp(url) myspider.closeUp() for t in myspider.Threads: t.join()
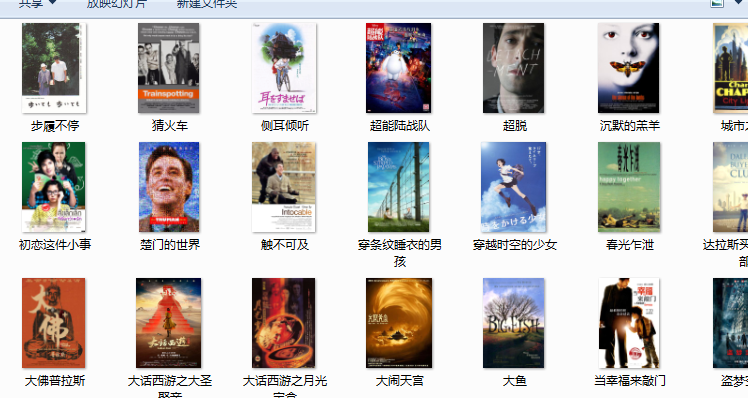

作业②:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
候选网站:https://www.shanghairanking.cn/rankings/bcur/2020
School.py
import os import urllib import scrapy from ..items import SchoolItem from bs4 import UnicodeDammit class MySpider(scrapy.Spider): name = "mySpider" headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} url = "https://www.shanghairanking.cn/rankings/bcur/2020" def start_requests(self): url = MySpider.url self.no = 1 yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): try: dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) data = dammit.unicode_markup selector = scrapy.Selector(text=data) lis = selector.xpath("//td[@class='align-left']") for li in lis: suffix = li.xpath("./a[position()=1]/@href").extract_first() # 单个学校网站后缀 school_url = "https://www.shanghairanking.cn/"+suffix req = urllib.request.Request(school_url, headers=MySpider.headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup msg = scrapy.Selector(text=data) rank = msg.xpath("//div[@class='rank-table-rank']/a/text()").extract_first() print(rank) name = msg.xpath("//div[@class='univ-name']/text()").extract_first() city = li.xpath("//td[position()=3]/text()").extract_first() officalUrl = msg.xpath("//div[@class='univ-website']/a/text()").extract_first() info = msg.xpath("//div[@class='univ-introduce']/p/text()").extract_first() pic_url = msg.xpath("//td[@class='univ-logo']/img/@src").extract_first() mfile = str(self.no) + ".jpg" self.download(pic_url) self.no += 1 item = SchoolItem() item["rank"] = rank.strip() if rank else "" item["name"] = name.strip() if name else "" item["city"] = city.strip() if city else "" item["officalUrl"] = officalUrl.strip() if officalUrl else "" item["info"] = info.strip() if info else "" item["mfile"] = mfile.strip() if mfile else "" yield item link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first() if link: url = response.urljoin(link) yield scrapy.Request(url=url, callback=self.parse) except Exception as err: print(err) def download(self, url): if (url[len(url) - 4] == "."): ext = url[len(url) - 4:] else: ext = "" req = urllib.request.Request(url, headers=self.headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("./6.2_picture/"+ str(self.no) + ext, "wb") fobj.write(data) fobj.close()
pipelines.py
import os import pymysql class SpiderPipeline: def open_spider(self, spider): if not os.path.exists("./6.2_picture"): os.mkdir('./6.2_picture') print("opened") try: self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("DROP TABLE IF EXISTS school") # 创建表 self.cursor.execute("CREATE TABLE IF NOT EXISTS school(sNo INT PRIMARY KEY," "schoolName VARCHAR(32)," "city VARCHAR(32)," "officalUrl VARCHAR(256)," "info VARCHAR(512)," "mfile VARCHAR(32))") self.opened = True self.count = 0 except Exception as err: print(err) self.opened = False def close_spider(self, spider): if self.opened: self.con.commit() self.con.close() self.opened = False print("closed") def process_item(self, item, spider): try: if self.opened: self.cursor.execute( "insert into school (sNo,schoolName,city,officalUrl,info,mfile) values( % s, % s, % s, % s, % s, % s)", (item["rank"], item["name"], item["city"], item["officalUrl"], item["info"], item["mfile"])) except Exception as err: print(err) return ite
Settings.py
ITEM_PIPELINES = { 'spider.pipelines.SpiderPipeline': 300, }
Item.py
class SchoolItem(scrapy.Item): rank = scrapy.Field() name = scrapy.Field() city = scrapy.Field() officalUrl = scrapy.Field() info = scrapy.Field() mfile = scrapy.Field()
作业③:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
候选网站: 中国mooc网:https://www.icourse163.org

 浙公网安备 33010602011771号
浙公网安备 33010602011771号