

数据库记录
数据库:
关系型数据库是“表”的集合,“表”是“记录”的集合。
数据模型三要素:
数据结构、数据操作、数据约束(完整性规则的集合(遵守的约束条件))。
分布式数据库
透明性表现:分片透明、分配透明(复制透明、位置透明)、映像透明(模型透明)。
三级模式/两级映像:
·用户级--> 外模式(反映了数据库系统的用户观)
· 概念级--> 概念模式(反映了数据库系统的整体观)
·物理级 --> 内模式(反映了数据库系统的存储观)
视图:
视图对于了”数据库系统三级模式/两级映像”中的外模式,重建视图即是修改“外模式”及“外模式/模式映像”,实现了数据的逻辑独立性。
日志检查点:
日志中添加检查点,可以提高故障恢复的效率。
SQL语句
Alter:
对已存在的列进行修改(添加列、删除列、修改列的属性)
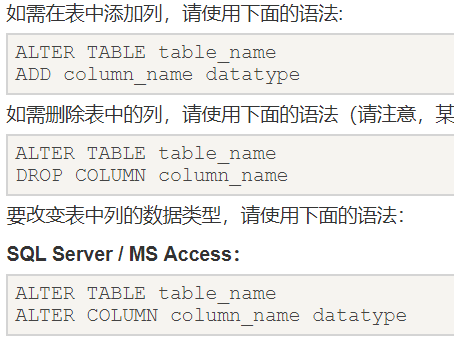
(图片截从菜鸟教程)
SELETE :
Select xxx from table_name where xxxxxxx;
SELETE TOP:
返回符合条件的一定数量的值:
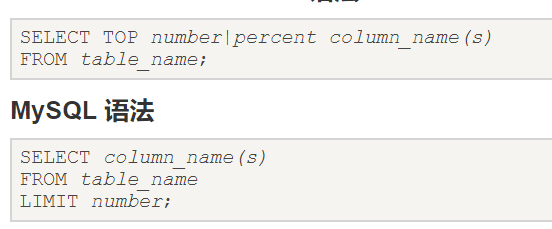
(图片同上)
SELECT DISTINCT:
返回非重复值(对列表元素返回单一的、非重复的、但包含列中所有元素)

(同上)
REVOKE:
收回用户对表数据的权限:
REVOKE <权限功能> (表项) on <表名> from <用户> [RESTRICT][CASCADE]
·其中PUBLIC 表示所有用户
如:收回用户ZHAO对学生表(STUD)中学号(xh) 的修改权限
REVOKE UPDATE (xh) on STUD FROM ZHAO.
Delete:
Delete from table_name where xxxxxxxx;
Update:
Update table_name set column=value where xxxxx;
Insert into:
Insert into table_name(column1,column2,...) values column1=xxx,column2=xxxx,...;
GroupBy:
对数据库所查询的元素进行分组(重生成一个列表)
Count:
返回符合条件的记录数
数据库设计
·需求分析(完成数据流图DFD和数据字典:用于描述企业的业务流程以及所需的数据)、概念设计(用E-R图或UML图:描述企业应用中的实体及其联系)、逻辑设计(指设计关系模式及相关视图)、物理设计(指设计数据的物理组织,如索引)
·概念结构设计阶段:在需求分析的基础上,依照需求分析的信息要求,对用户信息加以分类、聚集、概括,建立信息模型。分析抽象->设计局部视图->合并取消冲突->修改重构消除冗余
数据库约束:
参照完整性约束:
数据表中引用的实体,必须在其他表中存在,不允许引用不存在的实体。
主键约束:
在每个表中的每一行数据,定义一个唯一的标识符。
关系完整性约束:
域完整性(某一属性的输入值不能是无效值)、实体完整性、用户定义完整性、参照完整性。
关系数据库的查询语句:
域关系演算、元组关系演算、关系代数。
关系代数:
R*S,将R中元组与S中元组一一重新组合。
б表示选择关系,从数据表中选择符合条件的元组;
除:R÷S:找到与RS相同属性的列C,在关系R中再找寻包含C的所有值对应的列值
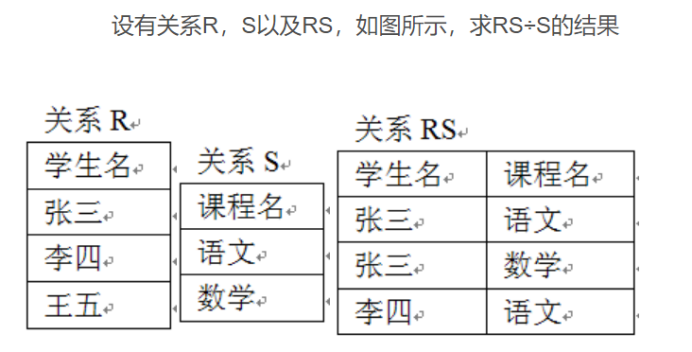
(百度的图片)
RS÷S={张三}
左外连接:
R与S的连接在加上R的所有元组。
右外连接:
R与S的连接再加上R的所有元组。
全外连接:
“左外连接”与“右外连接”的组合。
无损连接:
R1∩R2->R1-R2(R2-R1)即(),即可判断分解后的关系符合无损连接。
范式:
1NF:
表中的每一列都符合原子性,属性不可再分割(如家庭情况(3口人、江西)->>家庭人口(3人)、所在地(江西),故“家庭情况”便不符合原子性)。
2NF:
在1NF的基础上,所有非主属性都不存在对主码的部分函数依赖。
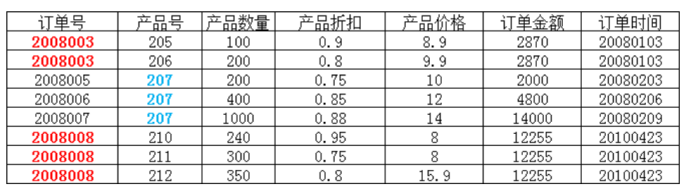
(百度的图片)
如图,订单金额便与订单号相关,而与产品号无关,而主码是:(订单号、产品号)。
3NF:
在2NF的基础上,不存在非主属性对非主属性的直接依赖
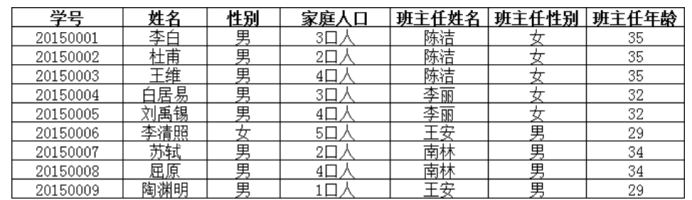
(百度的图片)
如图,“班主任性别”、“班主任年龄”直接依赖于“班主任姓名”。故不属于3NF。
BCNF:
满足BCNF条件有:所有非主属性对每一个候选键都是完全函数依赖; 所有的主属性对每一个不包含它的候选键,也是完全函数依赖;没有任何属性完全函数依赖于非候选键的任何一组属性。
·函数依赖的每个左部都包含码。
4NF:
表中的属性无多值依赖()
事务:
脏读:
事务已修改但还未提交的数据。
不可重复读:
事务多次读取同一数据,但其他事务在此过程中修改了数据,导致读取的数据不一致。
幻影现象:
事务在修改数据时(设计数据表中的全部行),另一事务插入了数据,导致修改的事务发现有未修改的数据。
丢失修改:
T1和T2对同一数据做修改,T2提交的结果破坏了T1的结果,导致T1的结果丢失。
事务并发执行:
判断事务并发执行正确性的准则是:满足可串行化调度。
要保证并发事务的正确执行,采用两端锁协议(2PL)。
事务锁:
排它锁(X锁):事务T对数据加入排它锁,标明T正在写入操作,其他事务不能再对该数据进行加锁(读写),直到事务T释放该数据,解锁。
共享锁(S锁):事务T对数据加入共享锁,T可以读取数据,但不能添加排它锁,其他事务可以对数据添加共享锁进行读取数据,但不能添加排它锁。
事务结束语:
COMMIT(WORK):用于事务对数据库操作完成后,对数据库所做的更新进行提交。
ROLLBACK (WORK):用于事务执行过程中失败时,对数据库已做的更新进行撤销。
·其中,WORK可省略。
事务调度:
指事务的执行次序。
两段锁协议:
·保证并行事务的可串行化,有效利用资源。
·第一阶段,对数据进行加锁,加锁过程中,不能有解锁;
·第二阶段,对数据进行解锁,解锁过程中,不能再进行加锁。
·两段锁协议并不能避免死锁。
事务ACID属性:
·原子性(atomicity):一个事务是不可分割的,事务要么都做,要么都不做。
·一致性(consistency):事务前后的数据完整性必须保持一致。
即事务的操作符合逻辑性(数据总量不变)
·持久性(durability):事务对数据的更新一旦完成(即事务一经提交),便不可更改。
NoSql的CAP理论:
C(Consistency):一致性
A(Avaiability):可用性
P(Partition tolerance):分区容错性
NoSql四大分类:
键值存储数据库、列存储数据库、文档型存储数据库、图数据库。
并行数据库
要求尽可能的并行执行所以的数据库操作,从而在整体上提高数据库系统的性能。
三种基本的体系结构:
·共享内存结构
·多个处理器,一个全局共享的内存(主存储器)、多个磁盘存储;
·在系统中,所有内存和磁盘均由处理器共享。
·共享磁盘结构
·具有多个独立内存(主存储器)的处理器、多个磁盘存储;
·没有直接的信息交换,处理器可以读取所有的磁盘信息
·无共享结构
·具有独立的处理器,独立的内存(主存储器)、独立的磁盘存储;
·处理器使用自己的内存独立处理自己的数据。
数据仓库与数据挖掘
数据仓库:
·数据仓库是一个面向主题的、集成的、不可更新的、随时间不断变化的数据集合。(实时收集的历史性数据集合)
·数据组织是基于多维模型的,由一个事实表和多个维度表组成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号