机器学习基础概念及思想
| 机器学习(machine learning,ML)是一类强大的可以从经验中学习的技术。 通常采用观测数据或与环境交互的形式,机器学习算法会积累更多的经验,其性能也会逐步提高。
-
引言
以唤醒词识别器为例:
![]()
利用机器学习算法,我们不需要设计一个“明确地”识别唤醒词的系统。 相反,我们只需要定义一个灵活的程序算法,其输出由许多参数(parameter)决定,然后使用数据集来确定当下的“最佳参数集”,这些参数通过某种性能度量方式来达到完成任务的最佳性能。
那么到底什么是参数呢? 参数可以被看作旋钮,旋钮的转动可以调整程序的行为。 任一调整参数后的程序被称为模型(model)。 通过操作参数而生成的所有不同程序(输入-输出映射)的集合称为“模型族”。 使用数据集来选择参数的元程序被称为学习算法(learning algorithm)。
在机器学习中,学习(learning)是一个训练模型的过程。 通过这个过程,我们可以发现正确的参数集,从而使模型强制执行所需的行为。 换句话说,我们用数据训练(train)模型。 -
机器学习组件
可以用来学习的数据(data);
如何转换数据的模型(model);
一个目标函数(objective function),用来量化模型的有效性;
调整模型参数以优化目标函数的算法(algorithm)。 -
数据
①数据集由一个个样本组成,大多遵循独立同分布。样本也叫做数据点或者数据示例,通常每个样本由一组称为特征(features,或协变量(covariates))的属性组成。
②当每个样本的特征类别数量都是相同的时候,其特征向量是固定长度的,这个长度被称为数据的维数(dimensionality)。然而,并不是所有的数据都可以用“固定长度”的向量表示。与传统机器学习方法相比,深度学习的一个主要优势是可以处理不同长度的数据。
③一般来说,越多的数据,工作越容易。但还需要正确的数据,否则只会“Garbage in,Garbage out".比如,如果用“过去的招聘决策数据”来训练一个筛选简历的模型,那么机器学习模型可能会无意中捕捉到历史残留的不公正,并将其自动化。 然而,这一切都可能在不知情的情况下发生。 因此,当数据不具有充分代表性,甚至包含了一些社会偏见时,模型就很有可能有偏见。 -
目标函数
用来衡量"学习"的效果。我们通常定义一个目标函数,并希望优化它到最低点。 因为越低越好,所以这些函数有时被称为损失函数(loss function,或cost function)。 但这只是一个惯例,我们也可以取一个新的函数,优化到它的最高点。 -
优化算法
当我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。 深度学习中,大多流行的优化算法通常基于一种基本方法–梯度下降(gradient descent)。 简而言之,在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。 -
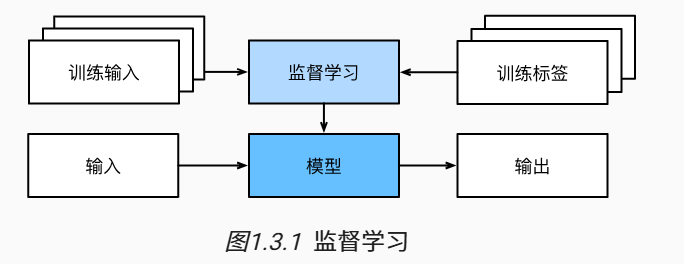
监督学习
监督学习的学习过程一般可以分为三大步骤:
①从已知大量数据样本中随机选取一个子集,为每个样本获取真实标签。有时,这些样本已有标签(例如,患者是否在下一年内康复?);有时,这些样本可能需要被人工标记(例如,图像分类)。这些输入和相应的标签一起构成了训练数据集;
②选择有监督的学习算法,它将训练数据集作为输入,并输出一个“已完成学习的模型”;
③将之前没有见过的样本特征放到这个“已完成学习的模型”中,使用模型的输出作为相应标签的预测。
![]()
-
回归学习
回归(regression)是最简单的监督学习任务之一。当标签取任意数值时,我们称之为回归问题,此时的目标是生成一个模型,使它的预测非常接近实际标签值。 -
分类
分类问题希望模型能够预测样本属于哪个类别(category,正式称为类(class))。 例如,手写数字可能有10类,标签被设置为数字0~9。 最简单的分类问题是只有两类,这被称之为二项分类(binomial classification)。回归是训练一个回归函数来输出一个数值; 分类是训练一个分类器来输出预测的类别。
分类问题的常见损失函数被称为交叉熵(cross-entropy)。
层次分类:分类可能变得比二项分类、多项分类复杂得多。 例如,有一些分类任务的变体可以用于寻找层次结构,层次结构假定在许多类之间存在某种关系。 因此,并不是所有的错误都是均等的。 人们宁愿错误地分入一个相关的类别,也不愿错误地分入一个遥远的类别,这通常被称为层次分类(hierarchical classification)。
在动物分类的应用中,把一只狮子狗误认为雪纳瑞可能不会太糟糕。 但如果模型将狮子狗与恐龙混淆,就滑稽至极了。 层次结构相关性可能取决于模型的使用者计划如何使用模型。 例如,响尾蛇和乌梢蛇血缘上可能很接近,但如果把响尾蛇误认为是乌梢蛇可能会是致命的。 因为响尾蛇是有毒的,而乌梢蛇是无毒的。 -
标签问题
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。 举个例子,人们在技术博客上贴的标签,比如“机器学习”“技术”“小工具”“编程语言”“Linux”“云计算”“AWS”。 一篇典型的文章可能会用5~10个标签,因为这些概念是相互关联的。 关于“云计算”的帖子可能会提到“AWS”,而关于“机器学习”的帖子也可能涉及“编程语言”。 -
搜索
①以网络搜索为例,目标不是简单的“查询(query)-网页(page)”分类,而是在海量搜索结果中找到用户最需要的那部分。 搜索结果的排序也十分重要,学习算法需要输出有序的元素子集。
②可能的解决方案:为集合中的每个元素分配相应的相关性分数,然后检索评级最高的元素。谷歌搜索引擎背后最初的秘密武器就是这种评分系统的早期例子,但它的奇特之处在于它不依赖于实际的查询。 在这里,他们依靠一个简单的相关性过滤来识别一组相关条目,然后根据PageRank对包含查询条件的结果进行排序。 如今,搜索引擎使用机器学习和用户行为模型来获取网页相关性得分,很多学术会议也致力于这一主题。
11.推荐
①推荐系统(recommender system),它的目标是向特定用户进行“个性化”推荐。
②在某些应用中,客户会提供明确反馈,表达他们对特定产品的喜爱程度。 例如,亚马逊上的产品评级和评论。 在其他一些情况下,客户会提供隐性反馈。 例如,某用户跳过播放列表中的某些歌曲,这可能说明这些歌曲对此用户不大合适。 总的来说,推荐系统会为“给定用户和物品”的匹配性打分,这个“分数”可能是估计的评级或购买的概率。 由此,对于任何给定的用户,推荐系统都可以检索得分最高的对象集,然后将其推荐给用户。
12.序列学习
如果输入是连续的,模型可能就需要拥有“记忆”功能。 比如,我们该如何处理视频片段呢? 在这种情况下,每个视频片段可能由不同数量的帧组成。 通过前一帧的图像,我们可能对后一帧中发生的事情更有把握。 语言也是如此,机器翻译的输入和输出都为文字序列。
再比如,在医学上序列输入和输出就更为重要。 设想一下,假设一个模型被用来监控重症监护病人,如果他们在未来24小时内死亡的风险超过某个阈值,这个模型就会发出警报。 我们绝不希望抛弃过去每小时有关病人病史的所有信息,而仅根据最近的测量结果做出预测。
序列学习需要摄取输入序列或预测输出序列,或两者兼而有之。 具体来说,输入和输出都是可变长度的序列,例如机器翻译和从语音中转录文本。
①标记与解析:输入和输出数量基本相同。这涉及到用属性注释文本序列。例如,我们可能想知道动词和主语在哪里,或者可能想知道哪些单词是命名实体。 通常,目标是基于结构和语法假设对文本进行分解和注释,以获得一些注释。下面是一个非常简单的示例,它使用“标记”来注释一个句子,该标记指示哪些单词引用命名实体。 标记为“Ent”。
![]()
②自动语音识别:输出比输入短得多。它的挑战在于,与文本相比,音频帧多得多(声音通常以8kHz或16kHz采样)。
③文本到语音:输出比输入长得多。 虽然人类很容易识判断发音别扭的音频文件,但这对计算机来说并不是那么简单。
④机器翻译:在语音识别中,输入和输出的出现顺序基本相同。 而在机器翻译中,颠倒输入和输出的顺序非常重要。 换句话说,虽然我们仍将一个序列转换成另一个序列,但是输入和输出的数量以及相应序列的顺序大都不会相同。 比如下面这个例子,“错误的对齐”反应了德国人喜欢把动词放在句尾的特殊倾向。
序列学习的应用还有:确定用户阅读网页的顺序,确定下一轮对话
12.无监督学习
无监督学习没有十分具体的目标。数据不含有目标。
例如:
①聚类问题:没有标签的情况下,给数据分类。如给定一组用户的网页浏览记录,将具有相似行为的用户聚类。
②主成分分析:找到少量的参数(主成分)来准确的体现数据的线性相关属性。如裁缝们已经开发出了一小部分参数,这些参数相当准确地描述了人体的形状,以适应衣服的需要。
③因果关系和概率图模型:确定数据之间的原因。例如,如果我们有关于房价、污染、犯罪、地理位置、教育和工资的人口统计数据,我们能否简单地根据经验数据发现它们之间的关系?
④生成对抗性网络:为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。潜在的统计机制是检查真实和虚假数据是否相同的测试。
13.深度学习
(1)发展: 其一,随着互联网的公司的出现,为数亿在线用户提供服务,大规模数据集变得触手可及; 另外,廉价又高质量的传感器、廉价的数据存储(克莱德定律)以及廉价计算(摩尔定律)的普及,特别是GPU的普及,使大规模算力唾手可得。机器学习和统计的关注点从(广义的)线性模型和核方法转移到了深度神经网络。 这也造就了许多深度学习的中流砥柱,如多层感知机 (McCulloch and Pitts, 1943) 、卷积神经网络 (LeCun et al., 1998) 、长短期记忆网络 (Graves and Schmidhuber, 2005) 和Q学习 (Watkins and Dayan, 1992)


①
本文来自博客园,作者:壹枝小鹿,转载请注明原文链接:https://www.cnblogs.com/wwtyssy/p/18826380

 浙公网安备 33010602011771号
浙公网安备 33010602011771号