
训练模型用GCP,推理服务放阿里云?聊聊AIGC时代的多云自由

AIGC 浪潮下,我团队面临一个新难题:我们想用 Google Cloud 强大的 TPU 训练模型,又想用阿里云为国内用户提供低延迟的推理服务。这个看似两全其美的想法,在传统单云架构下几乎是天方夜谭。这让我开始反思一个核心问题:我们是否必须与某家云厂商深度绑定,从而放弃选择更优方案的权利?
传统单云模式的困局
All-in 一家云厂商的模式,很快就让我们陷入了被动的困局。
-
严重的厂商锁定:业务一旦深度使用某云的专有服务,就像被焊死在平台上,迁移成本高到无法想象。
-
失去成本主动权:我们只能被动接受一家厂商的定价,完全无法享受市场竞争带来的价格红利。
-
限制业务上限:无法为业务的不同模块,选择不同云上最优的解决方案,只能被迫将就,牺牲性能或体验。
我的破局点:构建一个统一的应用管理层
我多年的梦想,就是能像用个人电脑一样使用云计算,只关心我的应用,不关心底层是哪家厂商的服务器。这个梦想,正通过一个统一的云操作系统变为现实。它的核心思想,是在所有云厂商之上,构建一个以 Kubernetes 为内核的抽象层,将底层复杂的云资源,变成可以随时替换的标准化资源池。
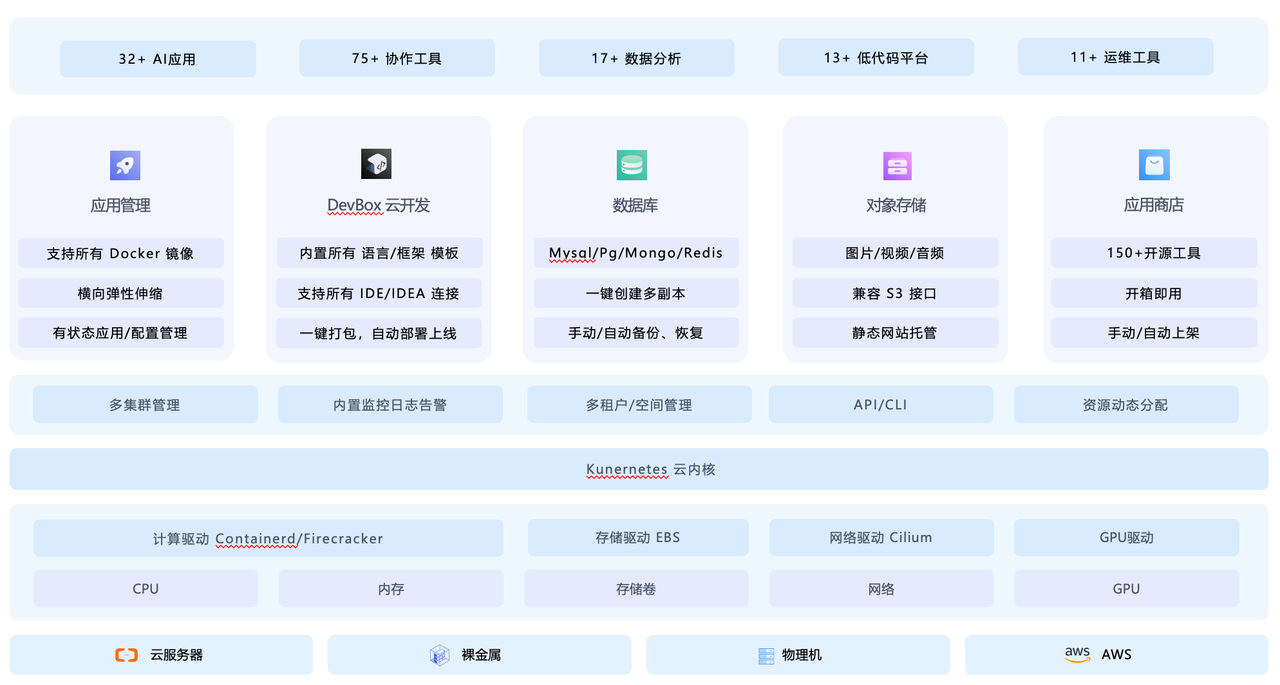
我是如何实现真正的多云自由的
我选择用 Sealos 来实践这个理念,它通过几个关键步骤,让多云部署和管理变得出奇地简单。
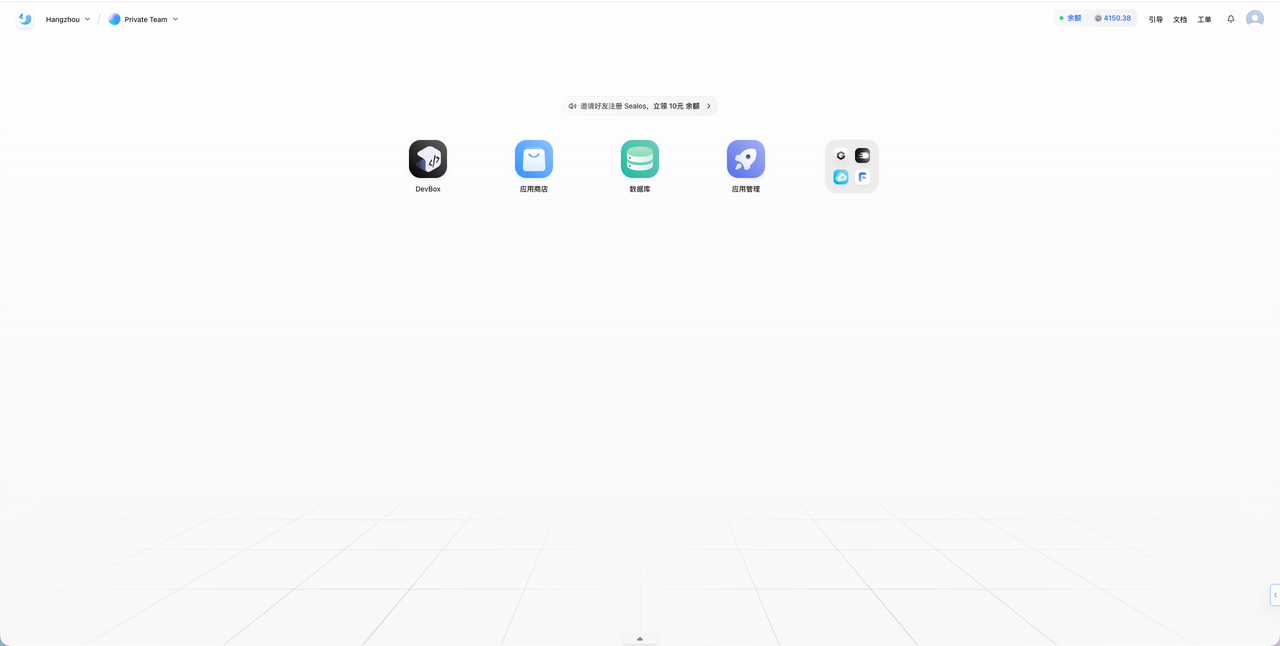
- 首先,我在不同云上构建了统一的运行底座,彻底屏蔽了底层差异。 我用一条
sealos run命令,就在阿里云和 GCP 的服务器上,分别快速安装了生产级高可用 Kubernetes 集群。无论底层是哪家云,我面对的都是完全相同的 Sealos 桌面和应用管理界面,操作体验完全一致。
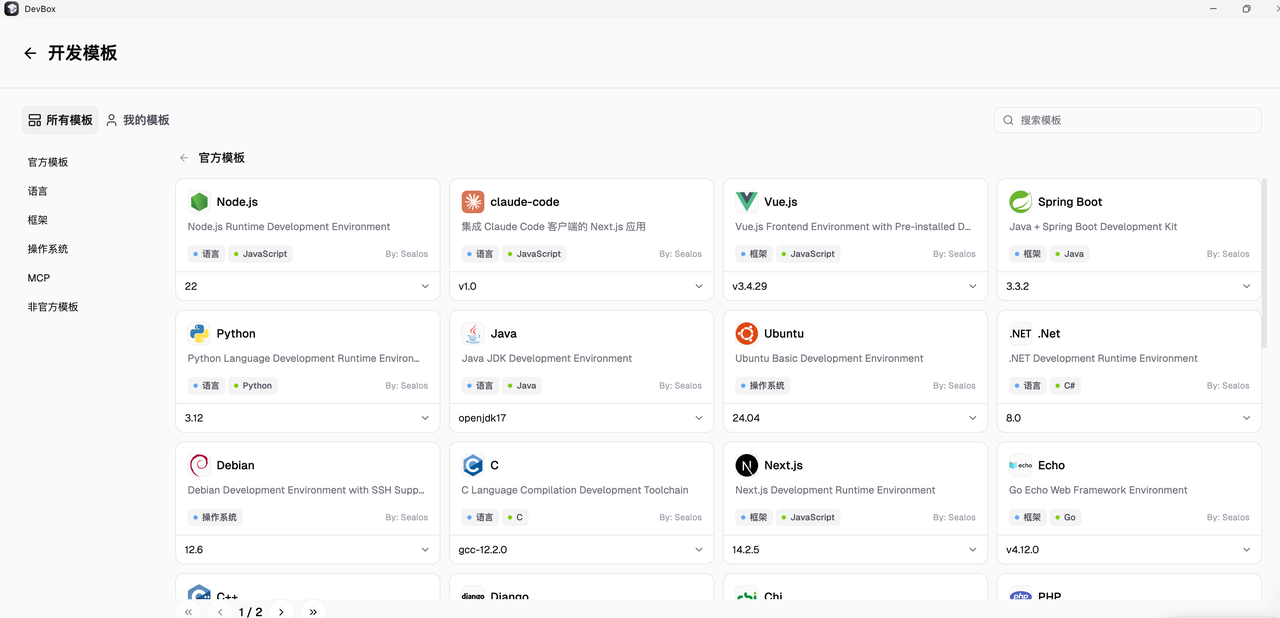
- 接着,我将应用打包成标准格式,实现了跨云的一键迁移。 我的应用,无论是用 DevBox 开发后一键发布的,还是用 App Launchpad 部署的,最终都变成了标准的 OCI 镜像。这意味着从阿里云迁移到 GCP,我不需要改一行代码,只需在新的集群上用相同方式点击几下重新部署即可。
- 最后,我将 AIGC 工作流拆分部署,实现了业务优势的最大化。 我在 GCP 集群的 Sealos 上部署了计算密集型的模型训练任务,充分利用其 TPU 优势。同时,我在阿里云集群的 Sealos 上部署了延迟敏感的推理服务,为国内用户提供了最佳访问体验,整个过程就像在同一台电脑的不同文件夹里操作一样简单。
写在最后
所以,是时候停止纠结“哪家云最强”这种问题了。更高级的玩法,是建立自己的统一应用平台,不再被任何一家厂商绑定。
我的终极目标,就是把强大的云厂商,从我们必须依附的“房东”,降级为可随时替换、标准化的计算资源供应商。
在 AIGC 这个算力为王的时代,这种灵活调度的能力,才是我掌握在自己手中的真正战略主动权。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号