
机器学习-企业破产预测
企业破产预测
选题背景
企业破产是商品经济的必然产物.在社会主义商品经济条件下,企业破产也是一种客观存在的经济现象.新中国的第一部《企业破产法》已经诞生,它的实施必将促进企业努力改善经营管理,提高经济效益,保护债权人和债务人的合法权益.企业破产无疑会给社会经济造成一系列严重损失.因此,预防和控制企业破产具有重大的社会经济意义.一个有效的企业破产预测模型无论是对国家的物资,资金,劳工等部门的计划和政策,或是对投资者,企业管理者的经营管理决策都具有重大作用.
1.数据描述
1.1数据来源
数据取自台湾经济杂志 1999 年至 2009 年的数据。公司破产是根据台湾证券交易所的业务规则定义的。
1.2数据概述
数据包含了与公司是否破产有关的95个因素包括有息债务的成本、现金再投资比率、流动比率、严峻考验、利息支出/总收入、总负债/权益比、负债/总资产、有息债务/股本或有负债/权益等特征以及对应的公司是否破产的信息,数据一共有6819条。下表对于数据中相关性最高的十项数据进行展示:
|
名称 |
数据类型 |
描述 |
|
Net Income to Total Assets |
浮点型 |
净收入与总资产之比 |
|
ROA(A) before interest and % after tax |
浮点型 |
利息前ROA(A)和税后百分比 |
|
ROA(B) before interest and depreciation after tax |
浮点型 |
税后利息和折旧前的ROA(B) |
|
ROA(C) before interest and depreciation before interest |
浮点型 |
利息前ROA(C)和利息前折旧 |
|
Net worth/Assets |
浮点型 |
净值/资产 |
|
Debt ratio % |
浮点型 |
负债率% |
|
Persistent EPS in the Last Four Seasons |
浮点型 |
过去四个季度的持续每股收益 |
|
Retained Earnings to Total Assets |
浮点型 |
留存收益占总资产的比例 |
|
Net profit before tax/Paid-in capital |
浮点型 |
税前净利润/实收资本 |
|
Per Share Net profit before tax |
浮点型 |
每股税前净利润 |
2.数据分析
2.1缺失值查找data.info()
经检测未发现数据中含有缺失值,

2.2 数据集初探
def make_autopct(values):
def my_autopct(pct):
total = sum(values)
val = int(round(pct*total/100.0))
# 同时显示数值和占比的饼图
return '{p:.2f}% ({v:d})'.format(p=pct,v=val)
return my_autopct
plt.pie(label.value_counts(),labels=["没破产","破产了"],autopct=make_autopct(label.value_counts()))
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.legend()
plt.show()

我们不难发现绝大多数数据是破产了的数据,我们在挑选数据时候应该尽量把少量的破产了的数据都放入我们的训练集中这样才会有更好的效果。
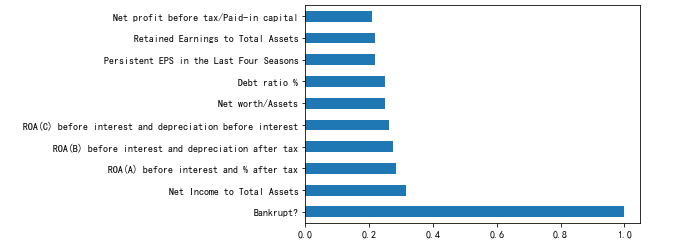
2.3 数据相关性探查data.corr()
我们大致可以找到以下几个参数,有些参数增大会导致破产概率增大,而有些参数与破产概率负相关,他们增大以后公司的破产概率会减少。而且对于数据集的初探过程中我们发现,这些标签几乎都是数值类型的连续变量,所以我们不需要对其进行转化,也不需要使用独热编码,这些数据可以直接进行训练。

corr_mat=data.corr()['Bankrupt?'].apply(np.abs).sort_values(ascending=False)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
corr_mat[:11].plot(kind='barh')
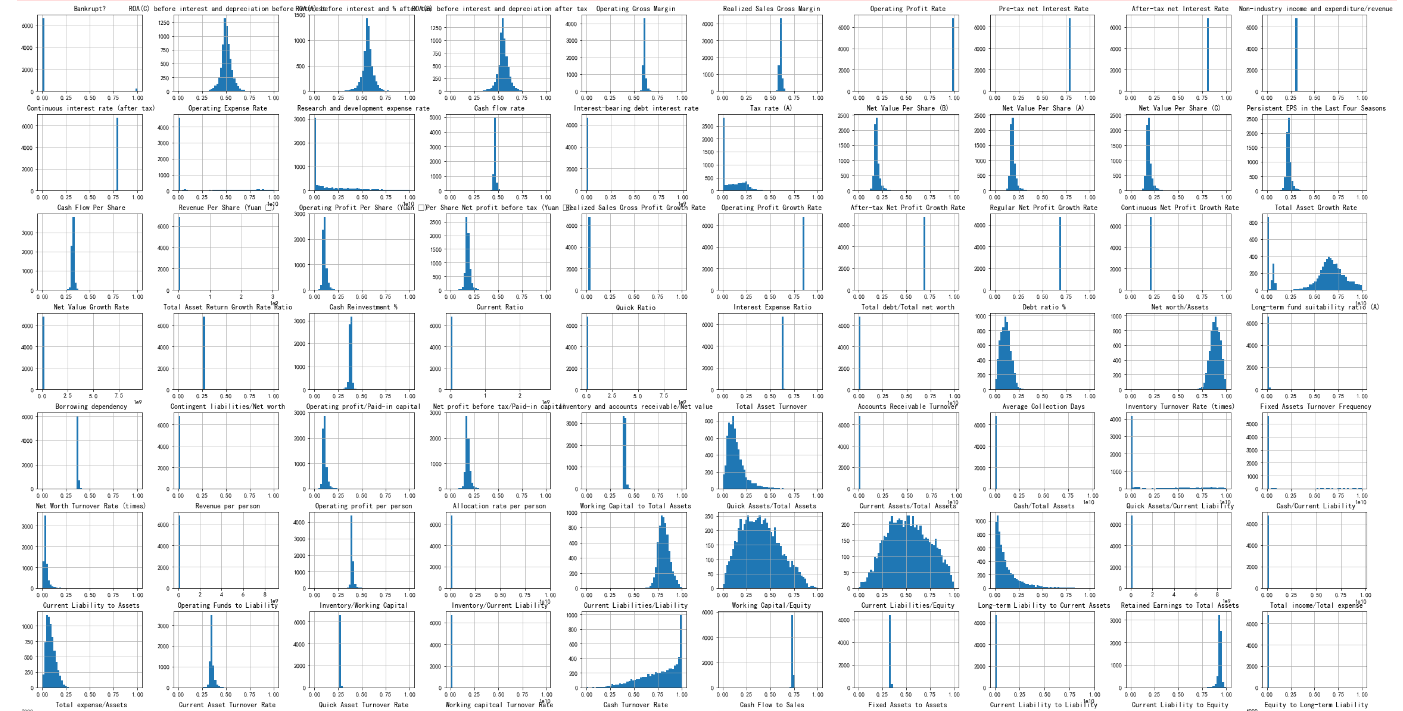
2.4 变量直方图
简单观察变量分布,以上观测图是把变量分成50桶以后得出的结果。变量分布未见明显异常,基本上符合高斯分布。
data.hist(bins = 50, figsize = (40, 30))
plt.show()
2.5探索性数据分析
train_describe_std = data.describe().loc['std',:]
extreme_cols = train_describe_std[train_describe_std>10000].index.values
regular_cols = [col for col in data.columns[:-1] if col not in extreme_cols]

发现不同变量之间的量纲相差比较大,有的是十的若干次倍,而有的却连1都没有到,所以需要进行归一化处理。
3.研究问题:
通过6819条数据来探求公司破产可能与哪些因素有关,并且能够通过这些因素来判断一个公司在未来是否具有破产风险,本质上预测一个公司的破产是一种“分类任务”,最根本的任务就是找到特征与公司破产之间的关系。
4.研究方法
分类本身是一个监督学习的范畴,所以本实验选用监督学习中常用的分类器来进行模型预测,在一定的评估方法下通过网格搜索匹配最佳参数的方式来选择最优评估器。这四个模型分别是逻辑回归、补充朴素贝叶斯分类、随机森林和支持向量机。这四种模型的解释性都是比较强的且在二分类问题上都有用武之地。
5.方法流程
5.1数据归一化处理
我们观察到不同标签的数据的量纲不同,需要对数据进行归一化处理,这样做可以加快了梯度下降求最优解的速度,可以让逻辑回归,支持向量机这些模型更快。
from sklearn.preprocessing import MinMaxScaler
minmax = MinMaxScaler(feature_range=(0, 1))
X_train = minmax.fit_transform(X_train)
X_test = minmax.transform(X_test)
5.2 数据集划分
使用网格搜索进行五折交叉验证的方式来进行数据划分,本实验选用全部数据进行训练。
5.3 训练器
sklearn中已经封装了逻辑回归、高斯朴素贝叶斯分类、随机森林和支持向量机这些算法,但我们知道参数不可能适配所有的数据集,所以我们使用网格搜索来匹配参数,并且人为地根据模型复杂程度和数据集学习曲线来判断学习情况,并得出相应结果。
6.数据划分细节
1.采用train_test_split来进行划分,但是在划分前需要先打乱数据,因为在对数据预览的过程中发现,数据前半部分的破产企业的资料较多,后半部分的破产资料较少,所以要先乱序。设置test_size为0.2表示测试集占原来数据量的20%,训练集则占原来数据集的80%。
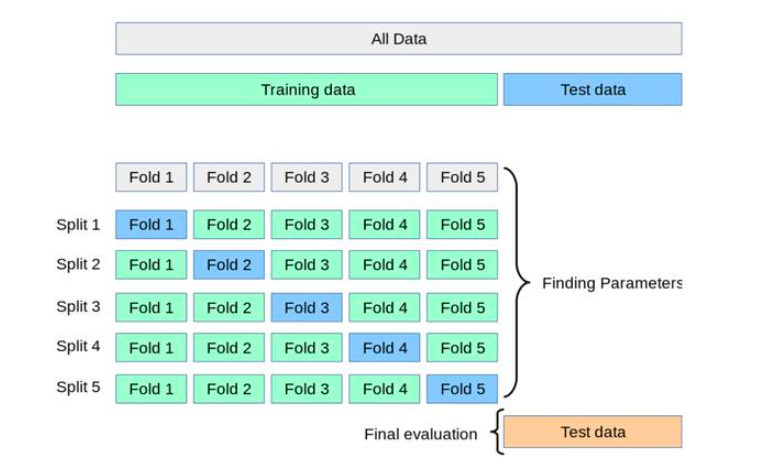
2.决策树、随机森林和支持向量机因为参数较多,需要使用网格搜索,而网格搜索GridSearchCV带有交叉验证的参数,我们设置五折交叉验证来进行训练。示意图如下[1]
# set seed for reproducibility
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
data=shuffle(data)
# train-test split
X_train, X_test, y_train, y_test = train_test_split(data.iloc[:, 1:], data.iloc[:, 0], test_size=0.20)
7.度量指标
对于这种样本量非常悬殊的二分类问题不能以accuracy也就是准确率作为唯一的判别标准,因为对于我们的实验目的来说,我们是要尽可能找出那些可能有破产风险的公司,所以我们要参考混淆矩阵,综合查全率查准率来进行定夺,必要时还可以绘制P-R曲线或者ROC曲线进行分析。本实验所采用score是roc-auc分数。
8.性能评价
8.1性能评价
模型的性能评价将从以下两个部分进行,学习能力、泛化能力。
学习能力是关于训练得到的模型关于训练样本集的预测能力。训练误差就是拿模型对训练集预测的结果与数据实际对应的结果进行比较,计算损失。
泛化能力指的是学习到的模型关于未知样本的预测能力。由于泛化误差难以估计,一般以测试花茶评价模型的泛化能力。泛化误差就是拿模型对测试集预测的结果与数据实际对应的结果进行比较,计算损失。[2]
所以本实验采用网格搜索来最优化模型性能和在限定值内调整参数。
8.2 参数调优:
8.2.1 对于逻辑回归我们进行网格搜索参数如下:
params = {'C': [1, 10, 100, 1000],
'class_weight': ['balanced', None],
'max_iter': [10000, 100000]}
log_model = GridSearchCV(LogisticRegression(), params, scoring = 'roc_auc', verbose = 1)
log_model.fit(X_train, y_train)
8.2.2 对于支持向量机我们进行网格搜索参数如下:
params = {'C': [1, 10, 100, 1000],
'kernel': ['linear', 'rbf'],
'gamma': [0.001, 0.0001],
'class_weight': ['balanced', None]}
8.2.3 对于补充朴素贝叶斯我们进行网格搜索参数如下:
params = {'alpha': [0.001, 0.01, 0.1, 1, 5, 10, 20]}
nb_model= GridSearchCV(ComplementNB(), params, scoring = 'roc_auc', verbose=1,cv=5)
8.2.4 对于随机森林我们进行网格搜索参数如下:
params = {'criterion': ['gini', 'entropy'],
'max_depth': [10, 50, 100, None],
'max_features': ['auto', None],
'n_estimators': [50, 100, 150]}
9.实验结果分析
9.1 逻辑回归结果分析
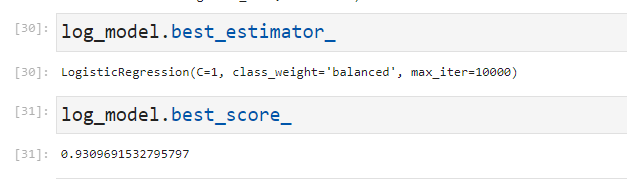
最优参数是C=1,class_weight=”balanced”,max_iter=10000,我们将选用这个训练器进行预测,我们使用这样一个score是auc-roc分数(以下模型都是如此)但是还没有结束,我们还需要检查混淆矩阵的相关参数来评估模型好坏:
混淆矩阵和真正例率、假正例率、真负例率、假负例率如下:

roc曲线如下:
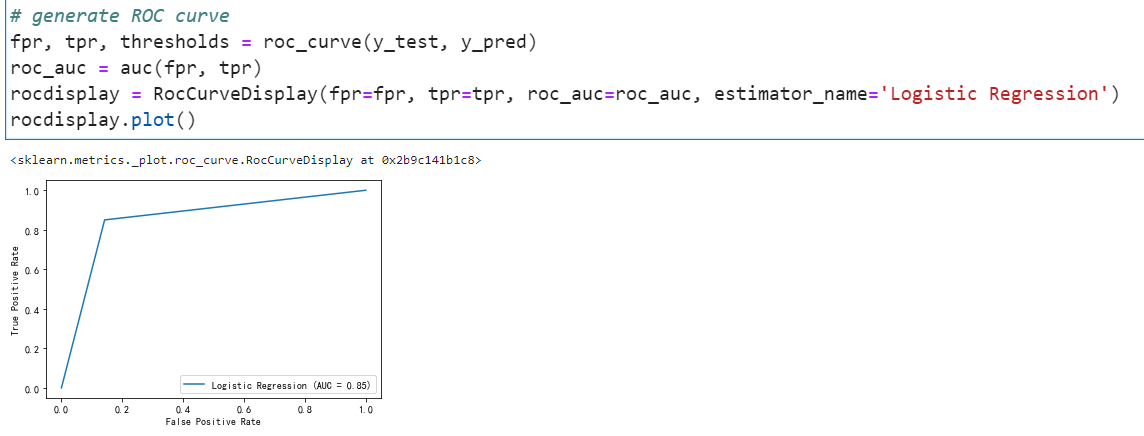
P-R曲线如下:

结论:不难看出在测试集上accuracy马马虎虎只有0.84,在那些真正破产=1的公司中,它的误报率很高,精确度也很低。不过好在他的召回率还蛮令人满意,基本上本来如果会破产的百分之七十多都能被找出来,这点还是不错的。
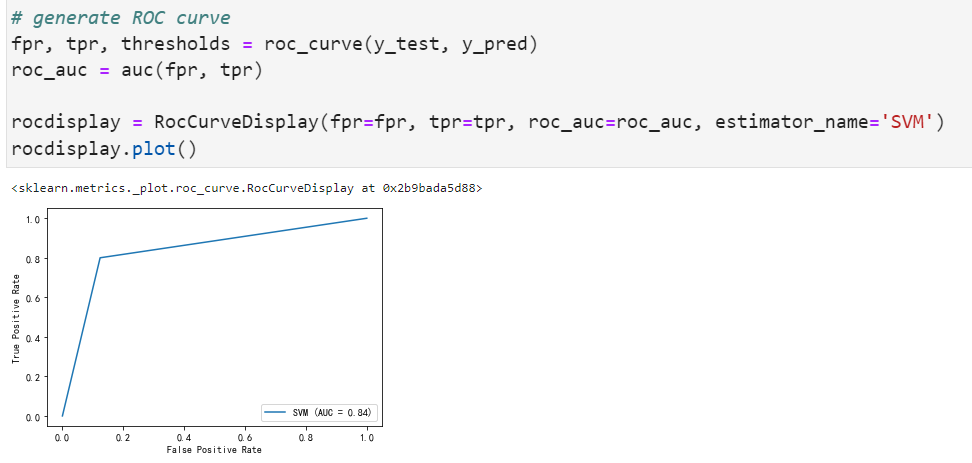
9.2 SVM结果分析
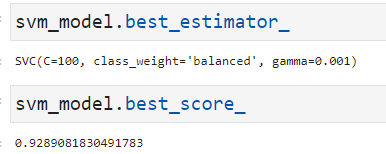
最优参数是C=100,class_weight=”balanced”,gamma=0.001.

看上去与逻辑回归并没有差很多,混淆矩阵和真正例率、假正例率、真负例率、假负例率如下:

roc曲线如下:
P-R曲线如下:
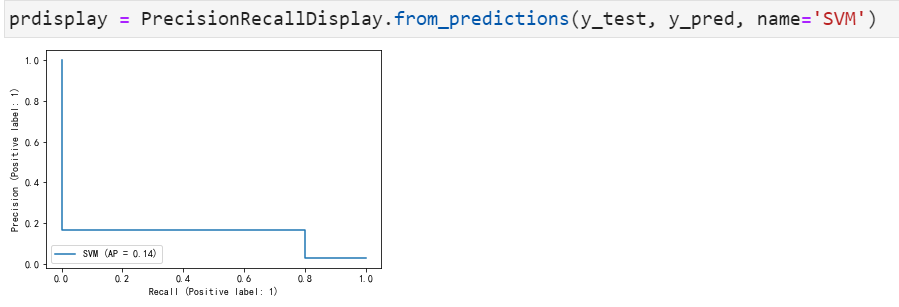
结论: 即使应用了性能最好的超参数,SVM模型在这个不平衡的数据集上也表现不好。这一模型的误报率很高,在真正破产的公司中,准确率仅为14% ,耗时巨长,与逻辑回归相比并无明显优势。
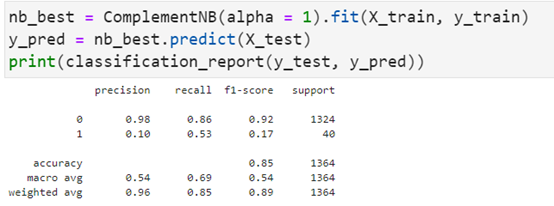
9.3 补充朴素贝叶斯结果分析
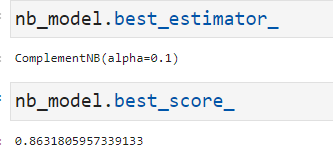
理论上补充朴素贝叶斯对这种不平衡的数据集效果良好,但是就此分数而言似乎不理想。最优参数为alpha=0.1
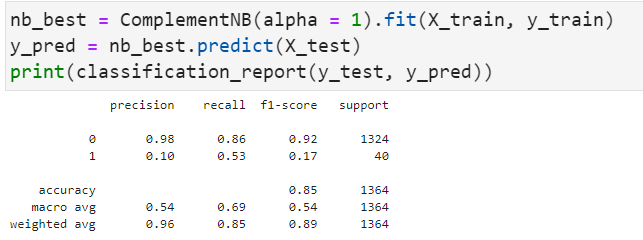
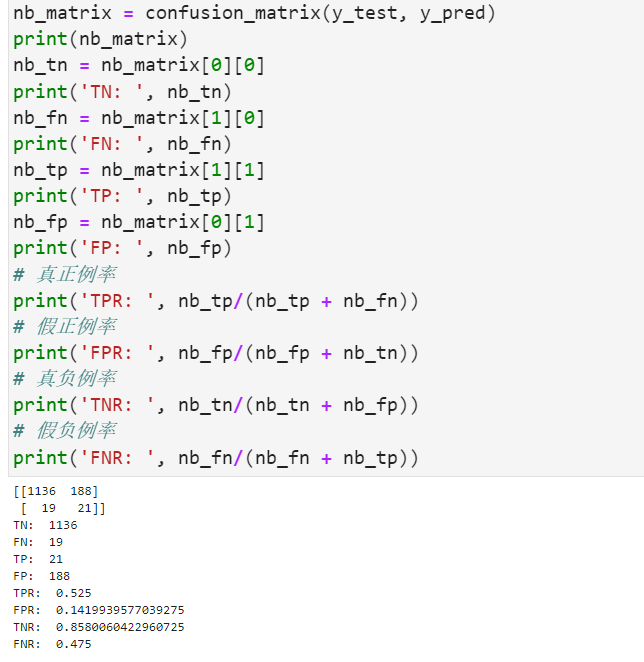
可能这种模型还是过于简单了,混淆矩阵和真正例率、假正例率、真负例率、假负例率如下:
roc曲线如下:
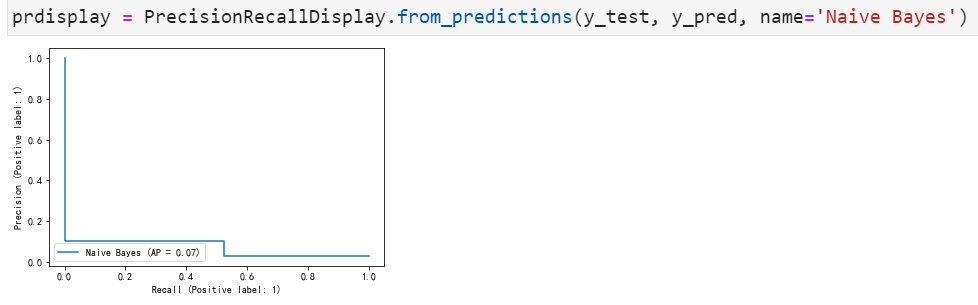
P-R曲线如下:
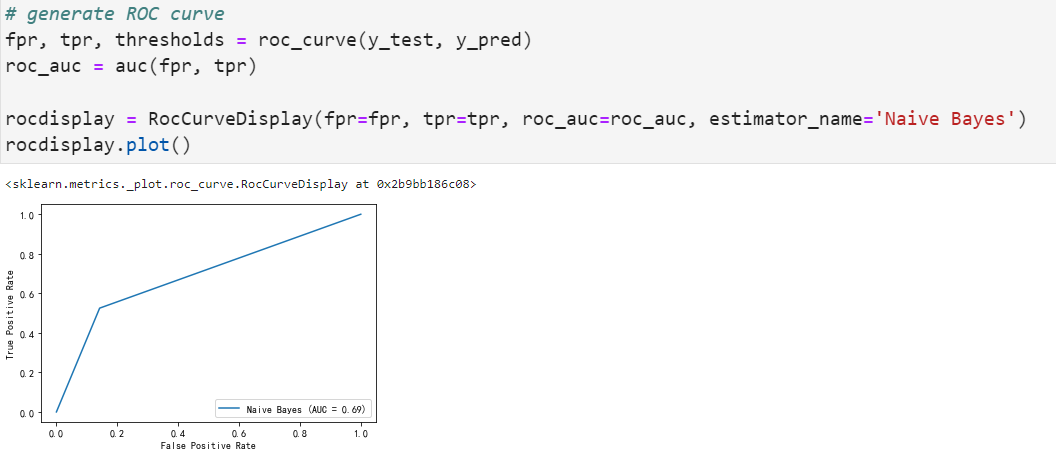
朴素贝叶斯模型的精度与支持向量机和逻辑回归模型一致,与其他模型一样,在真正破产=1的公司中,该模型的精度较低,而且这模型预测能力方面有明显低于前两者模型的表现。
9.4 随机森林结果分析
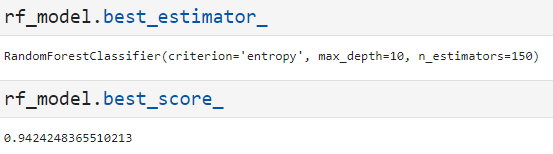
作为强学习器的随机森林还是表现出了非常高的水平。最优参数为criterion为信息熵,最大深度为10,基训练器为150,下面我们对其具体分类展开分析。
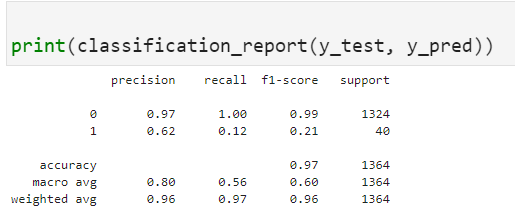
它与之前的所有机器学习算法不同的是它对于破产=1的这部分数据拟合的精确度要更高而且高了近四成。
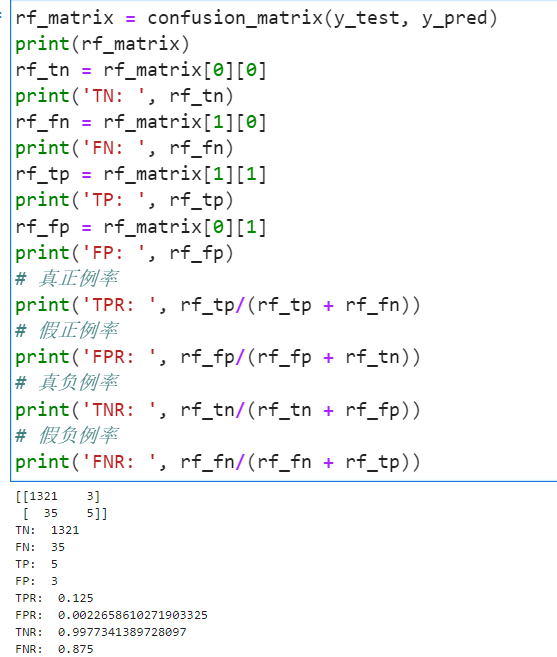
auc曲线如下:
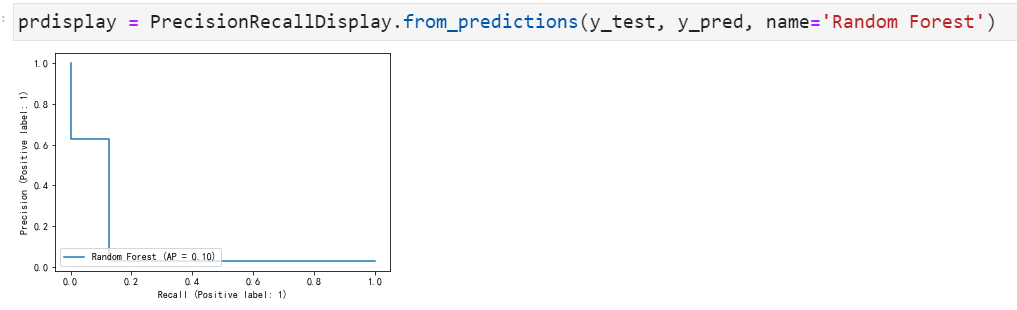
P-R曲线如下:
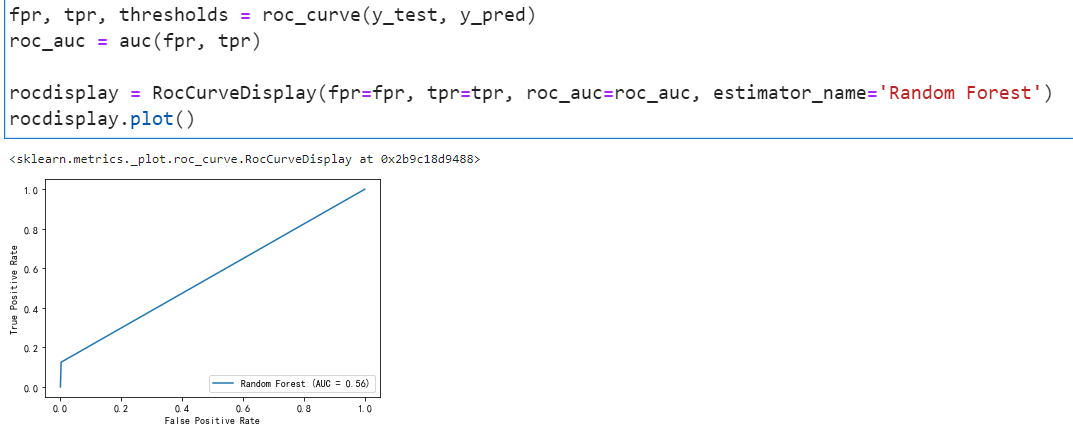
结论: 与之前预测的模型一样,该模型在识别消极因素方面仍表现良好,但识别正例的能力却糟糕透顶。测试集中的大多数正例因素在最终模型中未被正确地识别这是实验前所未曾设想的,即使“准确性”指标很高,模型也没有真正发挥其识别少数群体的功能。
10.总结
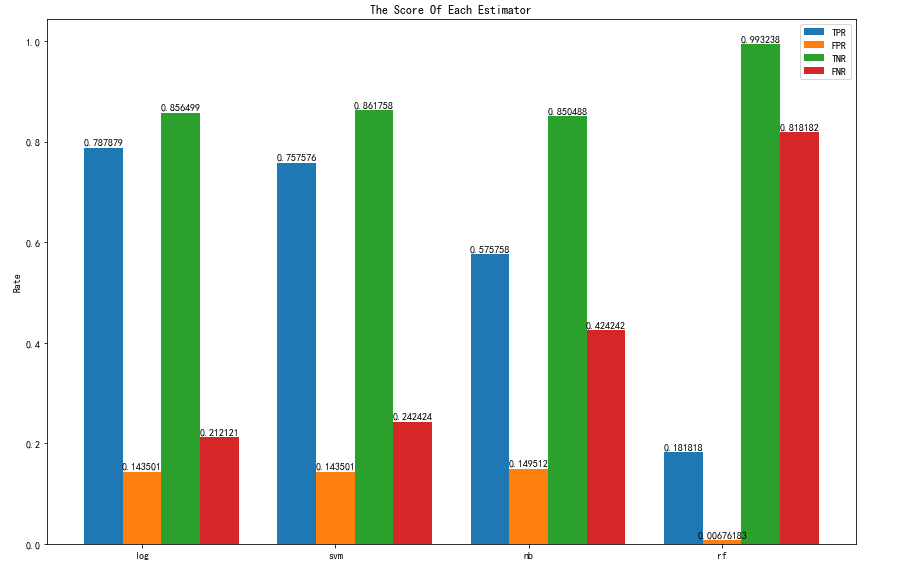
这四种模型在这个数据集上的表现都很差。给定破产的完整数据集的比例(低于96%),我认为这些模型的性能差可能是由于数据集(和样本)不平衡造成的。我还想尝试对少数群体的样本进行过采样/有意加权,以便用更多的少数群体样本来训练模型,但这些都还只是停留在猜想阶段,对于这种非平衡数据集还是需要好的模型和好的数据增强的方式来学习。这应该不是学习器的错,是数据集拆分或者采样的艺术吧。
估计公司破产的风险对债权人和投资者来说非常重要,也是金融经济学的重要学科。因此,破产预测是一个重要的研究领域。近年来,人工智能和机器学习方法在企业破产预测方面取得了可喜的成果。因此,本研究使用四种机器学习算法,即逻辑回归、扩充朴素贝叶斯、随机森林、支持向量机来预测企业破产。这些数据是从1999年到2009年的《台湾经济杂志》上收集的,公司破产的定义是根据台湾证券交易所的业务规定而定的[3]。
关键词:经济学、企业破产预测、机器学习、模型选择
11.全部代码
- #!/usr/bin/env python
- # coding: utf-8
- # In[1]:
- import pandas as pd
- import sklearn
- import numpy as np
- import matplotlib.pyplot as plt
- get_ipython().run_line_magic('matplotlib', 'inline')
- # In[2]:
- data=pd.read_csv("data.csv")
- data.shape
- # In[3]:
- data.info()
- # In[4]:
- label=data.loc[:,"Bankrupt?"].copy()
- #data.drop(columns=["Bankrupt?"],inplace=True)
- # In[5]:
- def make_autopct(values):
- def my_autopct(pct):
- total = sum(values)
- val = int(round(pct*total/100.0))
- # 同时显示数值和占比的饼图
- return '{p:.2f}% ({v:d})'.format(p=pct,v=val)
- return my_autopct
- plt.pie(label.value_counts(),labels=["没破产","破产了"],autopct=make_autopct(label.value_counts()))
- # 解决中文显示问题
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['axes.unicode_minus'] = False
- plt.legend()
- plt.show()
- # In[6]:
- import seaborn as sns
- sns.heatmap(data.corr())
- # In[7]:
- corr_mat=data.corr()['Bankrupt?'].apply(np.abs).sort_values(ascending=False)
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['axes.unicode_minus'] = False
- corr_mat[:11].plot(kind='barh')
- # In[8]:
- data.hist(bins = 50, figsize = (40, 30))
- plt.show()
- # In[9]:
- train_describe_std = data.describe().loc['std',:]
- extreme_cols = train_describe_std[train_describe_std>10000].index.values
- regular_cols = [col for col in data.columns[:-1] if col not in extreme_cols]
- # In[10]:
- data.mean().sort_values()
- # In[11]:
- data.describe()
- # In[12]:
- # set seed for reproducibility
- from sklearn.utils import shuffle
- from sklearn.model_selection import train_test_split
- data=shuffle(data)
- # train-test split
- X_train, X_test, y_train, y_test = train_test_split(data.iloc[:, 1:], data.iloc[:, 0], test_size=0.20)
- # In[13]:
- from sklearn.preprocessing import MinMaxScaler
- minmax = MinMaxScaler(feature_range=(0, 1))
- X_train = minmax.fit_transform(X_train)
- X_test = minmax.transform(X_test)
- # In[14]:
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.linear_model import LogisticRegression
- from sklearn.naive_bayes import ComplementNB
- from sklearn.svm import SVC
- from sklearn.model_selection import GridSearchCV
- from sklearn.model_selection import cross_val_score
- from sklearn.model_selection import train_test_split
- from sklearn.feature_selection import SelectPercentile
- from sklearn.metrics import classification_report
- from sklearn.metrics import average_precision_score
- from sklearn.metrics import precision_recall_curve
- from sklearn.metrics import confusion_matrix
- from sklearn.metrics import roc_curve
- from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, roc_curve, RocCurveDisplay, auc, PrecisionRecallDisplay
- # ## 逻辑回归
- # In[53]:
- LogisticRegression().get_params()
- # In[ ]:
- params = {'C': [1, 10, 100, 1000],
- 'class_weight': ['balanced', None],
- 'max_iter': [10000, 100000]}
- log_model = GridSearchCV(LogisticRegression(), params, scoring = 'roc_auc', verbose = 1)
- log_model.fit(X_train, y_train)
- # In[49]:
- log_model.best_estimator_
- # In[50]:
- log_model.best_score_
- # In[15]:
- log_best = LogisticRegression(C=1, class_weight='balanced', max_iter=10000).fit(X_train, y_train)
- y_pred = log_best.predict(X_test)
- print(classification_report(y_test, y_pred))
- # In[16]:
- log_matrix = confusion_matrix(y_test, y_pred)
- print(log_matrix)
- log_tn = log_matrix[0][0]
- print('TN: ', log_tn)
- log_fn = log_matrix[1][0]
- print('FN: ', log_fn)
- log_tp = log_matrix[1][1]
- print('TP: ', log_tp)
- log_fp = log_matrix[0][1]
- print('FP: ', log_fp)
- # 真正例率
- print('TPR: ', log_tp/(log_tp + log_fn))
- # 假正例率
- print('FPR: ', log_fp/(log_fp + log_tn))
- # 真负例率
- print('TNR: ', log_tn/(log_tn + log_fp))
- # 假负例率
- print('FNR: ', log_fn/(log_fn + log_tp))
- # In[17]:
- ax=sns.heatmap(log_matrix,annot=True,fmt='.20g')
- ax.set_title("log_matrix")
- ax.set_xlabel("predict")
- ax.set_ylabel("true")
- # In[18]:
- # generate ROC curve
- fpr, tpr, thresholds = roc_curve(y_test, y_pred)
- roc_auc = auc(fpr, tpr)
- rocdisplay = RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=roc_auc, estimator_name='Logistic Regression')
- rocdisplay.plot()
- # In[19]:
- prdisplay = PrecisionRecallDisplay.from_predictions(y_test, y_pred, name='Logistic Regression')
- # # svc
- # In[20]:
- SVC().get_params()
- # In[65]:
- params = {'C': [1, 10, 100, 1000],
- 'kernel': ['linear', 'rbf'],
- 'gamma': [0.001, 0.0001],
- 'class_weight': ['balanced', None]}
- # In[66]:
- svm_model = GridSearchCV(SVC(), params, scoring = 'roc_auc', cv=5,verbose = 1)
- # In[67]:
- svm_model.fit(X_train, y_train)
- # In[70]:
- svm_model.best_estimator_
- # In[71]:
- svm_model.best_score_
- # In[21]
- svm_best = SVC(C=100, class_weight='balanced', gamma=0.001, kernel='linear').fit(X_train, y_train)
- # In[22]:
- y_pred = svm_best.predict(X_test)
- # In[23]
- print(classification_report(y_test, y_pred))
- # In[24]:
- svm_matrix = confusion_matrix(y_test, y_pred)
- print(svm_matrix)
- svm_tn = svm_matrix[0][0]
- print('TN: ', svm_tn)
- svm_fn = svm_matrix[1][0]
- print('FN: ', svm_fn)
- svm_tp = svm_matrix[1][1]
- print('TP: ', svm_tp)
- svm_fp = svm_matrix[0][1]
- print('FP: ', svm_fp)
- # 真正例率
- print('TPR: ', svm_tp/(svm_tp + svm_fn))
- # 假正例率
- print('FPR: ', svm_fp/(svm_fp + svm_tn))
- # 真负例率
- print('TNR: ', svm_tn/(svm_tn + svm_fp))
- # 假负例率
- print('FNR: ', svm_fn/(svm_fn + svm_tp))
- # In[25]:
- ax=sns.heatmap(svm_matrix,annot=True,fmt='.20g')
- ax.set_title("svm_matrix")
- ax.set_xlabel("predict")
- ax.set_ylabel("true")
- # In[26]:
- # generate ROC curve
- fpr, tpr, thresholds = roc_curve(y_test, y_pred)
- roc_auc = auc(fpr, tpr)
- rocdisplay = RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=roc_auc, estimator_name='SVM')
- rocdisplay.plot()
- # In[27]:
- prdisplay = PrecisionRecallDisplay.from_predictions(y_test, y_pred, name='SVM')
- # # 补充朴素贝叶斯
- # In[81]:
- params = {'alpha': [0.001, 0.01, 0.1, 1, 5, 10, 20]}
- nb_model= GridSearchCV(ComplementNB(), params, scoring = 'roc_auc', verbose=1,cv=5)
- # In[83]:
- nb_model.fit(X_train, y_train)
- # In[85]:
- nb_model.best_estimator_
- # In[86]:
- nb_model.best_score_
- # In[28]:
- nb_best = ComplementNB(alpha = 1).fit(X_train, y_train)
- y_pred = nb_best.predict(X_test)
- print(classification_report(y_test, y_pred))
- # In[29]:
- nb_matrix = confusion_matrix(y_test, y_pred)
- print(nb_matrix)
- nb_tn = nb_matrix[0][0]
- print('TN: ', nb_tn)
- nb_fn = nb_matrix[1][0]
- print('FN: ', nb_fn)
- nb_tp = nb_matrix[1][1]
- print('TP: ', nb_tp)
- nb_fp = nb_matrix[0][1]
- print('FP: ', nb_fp)
- # 真正例率
- print('TPR: ', nb_tp/(nb_tp + nb_fn))
- # 假正例率
- print('FPR: ', nb_fp/(nb_fp + nb_tn))
- # 真负例率
- print('TNR: ', nb_tn/(nb_tn + nb_fp))
- # 假负例率
- print('FNR: ', nb_fn/(nb_fn + nb_tp))
- # In[30]:
- ax=sns.heatmap(nb_matrix,annot=True,fmt='.20g')
- ax.set_title("nb_matrix")
- ax.set_xlabel("predict")
- ax.set_ylabel("true")
- # In[31]:
- # generate ROC curve
- fpr, tpr, thresholds = roc_curve(y_test, y_pred)
- roc_auc = auc(fpr, tpr)
- rocdisplay = RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=roc_auc, estimator_name='Naive Bayes')
- rocdisplay.plot()
- # In[32]:
- prdisplay = PrecisionRecallDisplay.from_predictions(y_test, y_pred, name='Naive Bayes')
- # # 随机森林
- # In[92]:
- params = {'criterion': ['gini', 'entropy'],
- 'max_depth': [10, 50, 100, None],
- 'max_features': ['auto', None],
- 'n_estimators': [50, 100, 150]}
- # In[93]:
- rf_model = GridSearchCV(RandomForestClassifier(), params, scoring = 'roc_auc', verbose=1,cv=5)
- # In[94]:
- rf_model.fit(X_train, y_train)
- # In[95]:
- rf_model.best_estimator_
- # In[96]:
- rf_model.best_score_
- # In[33]:
- rf_best = RandomForestClassifier(criterion= 'entropy', max_depth= 10, max_features= None, n_estimators= 150).fit(X_train, y_train)
- # In[34]
- y_pred = rf_best.predict(X_test)
- # In[35]:
- print(classification_report(y_test, y_pred))
- # In[36]:
- rf_matrix = confusion_matrix(y_test, y_pred)
- print(rf_matrix)
- rf_tn = rf_matrix[0][0]
- print('TN: ', rf_tn)
- rf_fn = rf_matrix[1][0]
- print('FN: ', rf_fn)
- rf_tp = rf_matrix[1][1]
- print('TP: ', rf_tp)
- rf_fp = rf_matrix[0][1]
- print('FP: ', rf_fp)
- # 真正例率
- print('TPR: ', rf_tp/(rf_tp + rf_fn))
- # 假正例率
- print('FPR: ', rf_fp/(rf_fp + rf_tn))
- # 真负例率
- print('TNR: ', rf_tn/(rf_tn + rf_fp))
- # 假负例率
- print('FNR: ', rf_fn/(rf_fn + rf_tp))
- # In[37]:
- ax=sns.heatmap(rf_matrix,annot=True,fmt='.20g')
- ax.set_title("rf_matrix")
- ax.set_xlabel("predict")
- ax.set_ylabel("true")
- # In[38]:
- fpr, tpr, thresholds = roc_curve(y_test, y_pred)
- roc_auc = auc(fpr, tpr)
- rocdisplay = RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=roc_auc, estimator_name='Random Forest')
- rocdisplay.plot()
- # In[39]:
- prdisplay = PrecisionRecallDisplay.from_predictions(y_test, y_pred, name='Random Forest')
- # In[40]:
- df=pd.DataFrame([[log_tp/(log_tp + log_fn),log_fp/(log_fp + log_tn),log_tn/(log_tn + log_fp),log_fn/(log_fn + log_tp)],
- [svm_tp/(svm_tp + svm_fn),log_fp/(svm_fp + svm_tn),svm_tn/(svm_tn + svm_fp),svm_fn/(svm_fn + svm_tp)],
- [nb_tp/(nb_tp + nb_fn),nb_fp/(nb_fp + nb_tn),nb_tn/(nb_tn + nb_fp),nb_fn/(nb_fn + nb_tp)],
- [rf_tp/(rf_tp + rf_fn),rf_fp/(rf_fp + rf_tn),rf_tn/(rf_tn + rf_fp),rf_fn/(rf_fn + rf_tp)]])
- # In[41]:
- df.index=['log','svm','nb','rf']
- df.columns=['TPR','FPR','TNR','FNR']
- df
- # In[42]:
- x = np.arange(len(df))
- width = 0.2
- fig, ax = plt.subplots(figsize=(12,8))
- rects1 = ax.bar(x - width, df['TPR'], width, label='TPR')
- rects2 = ax.bar(x , df['FPR'], width, label='FPR')
- rects3 = ax.bar(x +width, df['TNR'], width, label='TNR')
- rects4 = ax.bar(x + width*2, df['FNR'], width, label='FNR')
- ax.set_ylabel('Rate')
- ax.set_title('The Score Of Each Estimator')
- ax.set_xticks(x, df.index)
- ax.legend()
- ax.bar_label(rects1, padding=2)
- ax.bar_label(rects2, padding=2)
- ax.bar_label(rects3, padding=2)
- ax.bar_label(rects4, padding=2)
- fig.tight_layout()
- plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号