

Django多表操作
本文目录:
一、一对多操作
#创建模型分析
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
注意:关联字段与外键约束没有必然的联系(建管理字段是为了进行查询,建约束是为了不出现脏数据)
#案例models.py
from django.db import models # Create your models here. class Book(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32,null=True) price = models.DecimalField(max_digits=5, decimal_places=2) publish_date = models.DateField() # 新增或者删除字段(写一个属性/注释掉) # default 指定默认值 # null 这个字段你可以为空 # xxaa=models.CharField(max_length=32,null=True) # 一对多的关系一旦确立,关联关系写在多的一方 publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE) # 多对多的关系需要创建第三张表(自动创建第三张表) authors=models.ManyToManyField(to='Author') def __str__(self): return self.name class Author(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) age = models.IntegerField() # unique=True 唯一性约束 author_detail = models.OneToOneField(to='AuthorDatail',to_field='nid',on_delete=models.CASCADE) # author_detail = models.ForeignKey(to='AuthorDatail',to_field='nid',unique=True,on_delete=models.CASCADE) class AuthorDatail(models.Model): nid = models.AutoField(primary_key=True) # BigIntegerField 大整形 # telephone = models.BigIntegerField() # birthday = models.DateField() addr = models.CharField(max_length=64,unique=True) class Publish(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) city = models.CharField(max_length=32) # EmailField :邮箱格式,EmailField用在admin中 email = models.EmailField()
#再在工程路径下创建test.py文件
一对一增加:
import os if __name__ == '__main__': os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day82.settings") import django django.setup() from app01 import models # 一对多增加 # publish:可以传一个publish对象 publish=models.Publish.objects.get(pk=1) print(publish.name) # ret=models.Book.objects.create(name='西游记',price=88,publish_date='2018-09-12',publish=publish) # publish_id 传一个id ret=models.Book.objects.create(name='三国演义',price=32,publish_date='2018-07-12',publish_id=publish.pk) print(type(ret.publish)) # 就是当前图书出版社的对象 print(ret.publish) print(type(ret.publish_id)) print(ret.publish.pk) print(ret.publish_id)
生成的表如下:
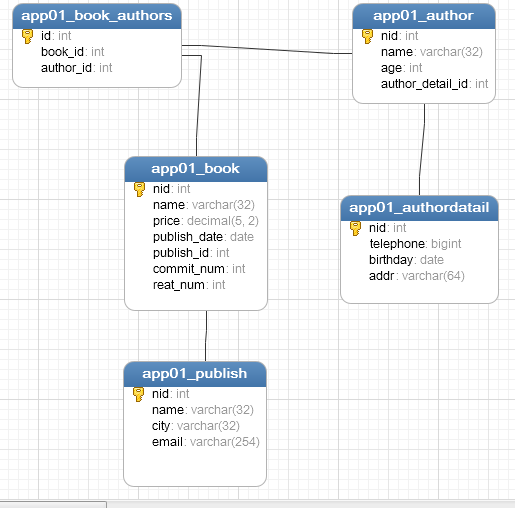
注意事项:
1.表的名称myapp_modelName,是根据模型中元数据自动生成的,也可以覆写为别的名称
2.id字段时自动添加的
3.对于外键字段,Django会在字段上添加“_id”来创建数据库的列名
4.这个例子中create table SQL语句使用PsetgreSQL语法格式,要注意的是Django会根据setting中指定的数据库类型来使用相应的sql语句
5.定义好模型后,你需要高数django_使用_这学模型,你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加models.py所在应用的名称
6.外检字段ForegnKey有一个null=True的设置(它允许外键接受空值null),你可以赋给它空值None
一对一修改:
#一对多修改 #book=models.Book.objects.get(pk=3) #book.publish_id=2 #book.publish=出版社对象 #book.save() #ret=models.Book.objects.filter(pk=2).update(publish=publish对象) #ret=models.Book.objects.filter(pk=2).update(publish_id=2)
一对一增加:
# 一对一增加 # authordetail=models.AuthorDatail.objects.create(addr='南京') # author=models.Author.objects.create(name='恩公',age=17,author_detail=authordetail) # author=models.Author.objects.create(name='小猴',age=16,author_detail_id=authordetail.pk)
多对多新增:
# 给红楼梦这本书添加两个作者(lqz,egon) book = models.Book.objects.get(pk=1) # 相当于拿到了第三张表 # 往第三章表中添加纪录(问题来了?要传对象还是传id),都支持 # book.authors.add(1,2) lqz = models.Author.objects.get(pk=1) egon = models.Author.objects.get(pk=2) # book.authors.add(lqz,egon)


book = Book.objects.filter(name='红楼梦').first() egon=Author.objects.filter(name='egon').first() lqz=Author.objects.filter(name='lqz').first() # 1 没有返回值,直接传对象 book.authors.add(lqz,egon) # 2 直接传作者id book.authors.add(1,3) # 3 直接传列表,会打散 book.authors.add(*[1,2]) # 解除多对多关系 book = Book.objects.filter(name='红楼梦').first() # 1 传作者id book.authors.remove(1) # 2 传作者对象 egon = Author.objects.filter(name='egon').first() book.authors.remove(egon) #3 传*列表 book.authors.remove(*[1,2]) #4 删除所有 book.authors.clear() # 5 拿到与 这本书关联的所有作者,结果是queryset对象,作者列表 ret=book.authors.all() # print(ret) # 6 queryset对象,又可以继续点(查询红楼梦这本书所有作者的名字) ret=book.authors.all().values('name') print(ret) # 以上总结: # (1) # book=Book.objects.filter(name='红楼梦').first() # print(book) # 在点publish的时候,其实就是拿着publish_id又去app01_publish这个表里查数据了 # print(book.publish) # (2)book.authors.all()
多对多关系其它常用API:
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[]) book_obj.authors.clear() #清空被关联对象集合 book_obj.authors.set() #先清空再设置
二、基于对象的跨表查询
删除、修改及清空操作:
# 红楼梦这本书egon这个作者删掉 # book.authors.remove(2) # book.authors.remove(egon,lqz) # book.authors.remove(1,2) # book.authors.remove(*[1,2]) # book.authors.remove(*[lqz,egon]) # 修改红楼梦这本书的作者为lqz和egon # 清空(清空这本的所有作者记录) # book.authors.clear() # book.authors.add(1,2) # book.authors.set(*[6,]) #这样不行 # book.authors.set([6,]) #需要这样传 # lqz=models.Author.objects.get(pk=2) # set 必须传一个可迭代对象 # book.authors.set([lqz,]) #需要这样传
1.一对多查询(publish与book)
# 一对多 # 查询红楼梦这本书的出版社名字(正向,按字段) # book=models.Book.objects.get(pk=1) # 出版社对象 book.publish # print(book.publish.name) # 查询北京出版社出版的所有书名(反向查询按 表名小写_set.all()) # publish=models.Publish.objects.get(pk=1) # 结果是queryset对象 # books=publish.book_set.all() # for book in books: # print(book.name) # 查询以红开头的 # books=publish.book_set.all().filter(name__startswith='红') # for book in books: # print(book.name)
正向查询(按字段:publish)
# 查询主键为1的书籍的出版社所在的城市 book_obj=Book.objects.filter(pk=1).first() # book_obj.publish 是主键为1的书籍对象关联的出版社对象 print(book_obj.publish.city)
反向查询(按表名:book_set)
publish=Publish.objects.get(name="苹果出版社") #publish.book_set.all() : 与苹果出版社关联的所有书籍对象集合 book_list=publish.book_set.all() for book_obj in book_list: print(book_obj.title)
2.一对一查询
# 一对一查询 # 补充一个概念:正向 反向 # 正向:关联关系在当前表中,从当前表去另一个表 # 反向:关联关系不在当前表,从当前表去另一个表 # 查询lqz作者的地址(正向查询,按字段) # lqz=models.Author.objects.filter(name='lqz').first() # # 作者详情对象 # print(lqz.author_detail.addr) # 查询地址为上海的,作者的名字(反向查询,按表名小写) # authordetail=models.AuthorDatail.objects.filter(addr='上海').first() # 拿到的是作者对象authordetail.author # print(authordetail.author.name)
3.多对多查询
# 红楼梦这本书所有的作者(正向 字段) # book=models.Book.objects.get(pk=1) # # book.authors.all()拿到所有的作者,是一个queryset对象 # authors=book.authors.all() # for author in authors: # print(author.name) # 查询egon写的所有书(反向 表名小写_set.all()) # egon=models.Author.objects.get(pk=2) # 拿到的是queryset对象 # books=egon.book_set.all() # for book in books: # print(book.name)
三、基于双下划线的查询
一对一
# 查询lqz作者的名字,地址(正向查询,按字段) # ret=models.Author.objects.filter(name='lqz').values('name','author_detail__addr') # print(ret) # 查询地址为上海的作者的名字(反向,按表名小写) # ret=models.AuthorDatail.objects.filter(addr='上海').values('addr','author__name','author__age') # print(ret.query) # print(ret)
一对多
#查询红楼梦这本书的出版社的名字(正向 按字段) # ret=models.Book.objects.filter(name='红楼梦').values('name','publish__name') # print(ret) # 查询北京出版社出版的所有书的名字(反向 按表名小写) # ret=models.Publish.objects.filter(name='北京出版社').values('book__name') # print(ret)
多对多
# 红楼梦这本书所有的作者名字(正向 按字段) # ret=models.Author.objects.filter(book__name='红楼梦').values('name') # print(ret) # ret=models.Book.objects.filter(name='红楼梦').values('authors__name') # print(ret) # egon出版的所有书的名字(反向 表名小写) # ret=models.Book.objects.filter(authors__name='egon').values('name') # print(ret) # ret=models.Author.objects.filter(name='egon').values('book__name') # print(ret) # 查询北京出版社出版过的所有书籍的名字以及作者的姓名 # ret=models.Publish.objects.filter(name='北京出版社').values('book__name','book__authors__name') # print(ret) # ret=models.Book.objects.filter(publish__name='北京出版社').values('name','authors__name') # print(ret) # ret=models.Author.objects.filter(book__publish__name='北京出版社').values('book__name','name') # print(ret) # 地址是以北开头的作者出版过的所有书籍名称以及出版社名称 # ret = models.AuthorDatail.objects.filter(addr__startswith='北').values('author__book__name', # 'author__book__publish__name') # print(ret) ret=models.Book.objects.filter(authors__author_detail__addr__startswith='北').values('name','publish__name') print(ret.query) ret=models.Author.objects.filter(author_detail__addr__startswith='北').values('book__name','book__publish__name') print(ret.query)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号