

badou30_day02_课堂笔记
1.从海量数据内容挖掘价值,来提升用户点击率、购买率、留存、观看时间、完播率。
2.数据+(算法+策略)
3.一个进程来做的mapreduce,默认输入一个block块(128mb),map方法一次只处理一条数据(input split)---》环形缓冲区,达到80mb,会溢写(flush)在磁盘上,会自动分区----》分发到reduce。
4.map的个数有split大小影响(逻辑切分)Math.max(minSize,Math.min(maxSize,blockSize))。 block(物理)--->split(逻辑)
5.正则的包:re, p = re.compile(r '\w+') :只匹配单词。
6.foreach:加强for循环。
7.序列化。先删除再创建--worddrive。hadoop比较稳定,比较慢。
8.shuffle中最耗时的地方:网络IO,磁盘IO,(数据传输)(数据IO),hadoop数据必须落磁盘,spark数据会落在缓存中。
9.进程是资源分配的最小单位。线程是执行任务的最小单位。spark是多线程。同一个进程中数据是可以共享的。进程的启动耗时间,spark中的进程当数据全部执行完才释放。
10.reduce中不会出现两个key一样的,key是唯一的,所以可以达到去重的目的。
11.伪代码---》真代码(百度)。
12.数据倾斜。
13.hive的底层全部是mapreduce。
14.100g的数据,每一行一个数,如何用mr去求max?会分成多个block,随机生成1w个key(0,1w)【需要key做分发,要不会发生数据倾斜,单台机器内存也接受不了】,再分发到多个reduce,相同的key会分发到一个reduce中,每个reduce中平均有100m数据;如果不随机的话会发生数据倾斜,一台机器处理的数据会很多(如100g)。每个reduce中找最大值,当前一共有1w个数(最大值)--part-r-00000------>再一次mapreduce,如何分发到一个reduce上:一个key。
15.序列化:数据做压缩,方便传输,json,proto,picke。 map到reduce的传输过程:就是序列化传输。
16.反序列化:读取序列化数据的过程。
17.分区partition:有多少个分区就有多少个reducer进程,mrreduce底层会根据hash(key)自动做分区,默认map输出1GB就输出一个reduce。
18.基于mr找出两个用户的共同好友,有谁?单向好友,双向好友
easyrec
19.默认一个block对应一个split
20.求平均,可以改combiner的输出格式,但是求中位数的时候不能用combiner,reduce和combiner的计算逻辑可以不一样。
21.combiner相当于,同一个block里的简单reducer过程。
22.combiner 执行规则默认环形缓冲区溢写文件大于等于3才会执行?
23.全局排序只有一个reduce。一个reduce见到所有数据,应该怎样设计key,打到唯一一个key上。
24combiner做全局排序的好处在哪?希尔排序,每个block基本有序,局部有序,再进行归并排序,reduce做归并排序,从而减少了reduce的压力,降低时间复杂度。进行分区
25判断数据长度是不是比判断数据大小要容易些,跑得更快
MapReduce 是一种分布式计算框架,常用于处理大规模数据集。MapReduce 框架可以有效地进行数据采样。以下是一些基于 MapReduce 的数据采样实践建议: 1. 利用 MapReduce 的 Map 阶段进行采样。 在 MapReduce 框架中,Map 阶段是向每个数据块应用相同函数以生成键值对的阶段。因此,可以通过在 Map 阶段对数据进行采样来减少数据量。具体做法是将输入数据块中的每个记录映射到一个随机值,然后根据随机映射值进行采样。例如,可以使用以下 map 函数: ```python def sample_map(record): rand_num = random.random() # 随机数 if rand_num < 0.1: yield rand_num, record # 注意返回的顺序,随机数应该在 key 的位置 ``` 这个函数向每个记录添加一个随机数,并根据这个随机数返回记录,如果随机数小于 0.1,则返回记录。 2. 利用 MapReduce 的 Reduce 阶段进行采样。 在 MapReduce 框架中,Reduce 阶段是将具有相同键的值组合在一起的阶段。因此,可以利用 Reduce 阶段对数据进行采样,从而使数据更均匀地分布在每个 Reduce 任务中。产生样本的方法是在 Map 阶段使用划分函数,将输入数据划分为多个分区,并在 Reduce 阶段仅选择一个分区进行处理。以下是实现采样的一个示例 reduce 函数: ```python def sample_reduce(key, values): yield values[random.randint(0, len(values) - 1)] ``` 这个 reduce 函数从所有传入的值中随机选择一个进行处理。 利用以上建议进行 MapReduce 的数据采样可以大大减少数据量,从而使计算更加高效。通过合理地选择划分函数和采样函数,可以在保留有代表性的样本的同时避免数据偏差。
26.先曝光(展示),后点击。
27.区域热点划分,将经纬度相近的划分到一个堆。区域划分之后,如何找热门。-----点击次数
28.对于一些有明显划分逻辑的类,不需要聚类。
29.难在何时要去做聚类。
30.cos业务逻辑:每个人打分标准不一样。
31.求距离需先归一化:量纲不一样,(大数吃小数)
32.归一化:就是将这一个维度的数据映射到一个固定的数值范围内,剔除量纲的影响。【0,1】等间距缩放,业界大多用归一化。
33.数据标准化:默认数据服从正态分布。数值在值域上的分布。把数据转化一个正态分布。
34.归一化需要两个mr,最后一个只需要map
35.标准化需要3gemr,抽样和全量的概念,先采样再计算均值和标准差。
36.1个reduce相等于一个单机操作。
37. String lines = line.toString()
if(random.ranint(0,1000) == 1){
context.write(1,lines)
}
38.随机这种本来就不确定,就算是特别随机也可能抽在一个地方.随机给一个,再算一轮。
39.reduce计算新的聚类中心。
40.面对不同的推荐场景,没有统一的好的推荐算法,需要工程师的经验以及技术,去对数据+业务理解。nlp和cv都是做前期数据处理的
41.在做需求的时候需要分析数值具备的是绝对差异还是相对差异,如果是相对差异就用cos,绝对就用欧式,偏好、兴趣这样的特征差异值是用cos距离,客观数据用欧式。
42.cos可以叫做相似度,1-cos作为距离。
43.身高体重差异通常使用欧式距离。欧式距离是指两个向量之间的距离,即模长差的平方和的平方根。在身高体重差异的情况下,我们可以将身高和体重看作是两个特征,计算它们之间的欧式距离来衡量它们之间的差异。相反,余弦相似度(cosine similarity)通常用于衡量文本和图像之类的非数值特征之间的相似度。
在推荐系统中,用于计算物品相似度的常用方法有欧式距离和余弦相似度(Cosine Similarity)。 欧式距离是指两个物品向量之间的距离,可以表示为两个向量差的平方和的平方根,也就是: $$ sim(i_1,i_2) = \sqrt{\sum_{k=1}^{n}(i_{1,k}-i_{2,k})^2} $$ 其中,$i_1$和$i_2$表示两个物品向量,$n$为向量维度。欧式距离的值越小,则两个物品越相似。 Cosine Similarity指两个物品向量之间的夹角余弦值,可以表示为两个向量点积与两个向量的范数之积的比值,也就是: $$ sim(i_1,i_2) = \frac{\sum_{k=1}^{n}(i_{1,k}\cdot i_{2,k})}{\sqrt{\sum_{k=1}^{n}(i_{1,k})^2} \cdot \sqrt{\sum_{k=1}^{n}(i_{2,k})^2}} $$ 利用Cosine Similarity计算物品相似度,可以将用户评分向量映射到高维空间中,根据向量之间的夹角余弦值来确定物品之间的相似性。对于稀疏的评分矩阵或者高维度的物品向量,Cosine Similarity比欧式距离更加适用。 通常情况下,我们会使用相似度矩阵来表示物品之间的相似度关系,相似度矩阵中的每个元素表示对应物品之间的相似度,通过计算欧式距离或Cosine Similarity来填充相似度矩阵,进而用于协同过滤等推荐算法的实现中。
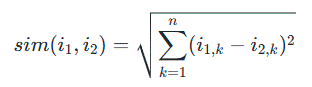
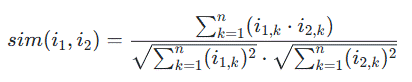

 浙公网安备 33010602011771号
浙公网安备 33010602011771号