
第一次作业——结合三次小作业
作业一:UniversityRanking
代码: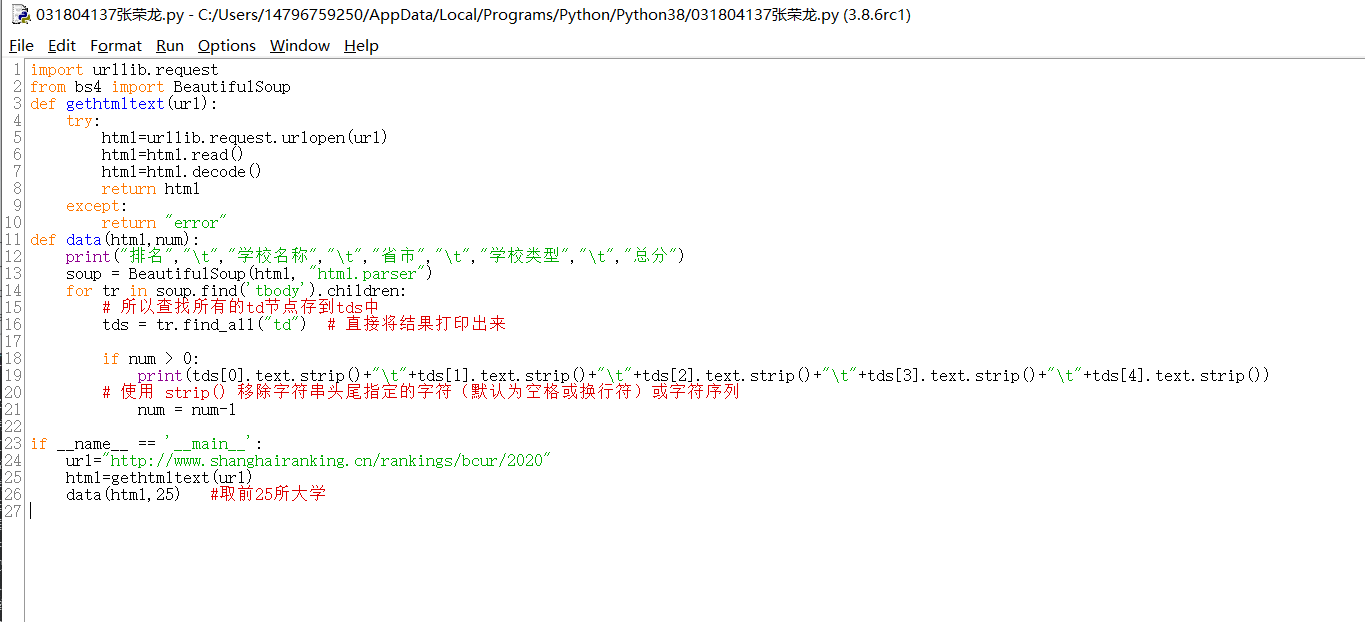
结果截图:

心得体会:这第一次的作业就是爬取大学排名,我个人认为这是刚接触爬虫时用来练习的最好实例了。在练习这个之前,还专门去mooc学了点爬虫视频,受益匪浅。
简述流程为:
步骤1:利用IDLE简单测试爬取的网页
步骤2:浏览器上查看网页信息
步骤3:从网页中获取HTML文本
步骤4:提取网页信息并存入合适的数据结构
步骤5:利用数据结构输出结果
作业二:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码:
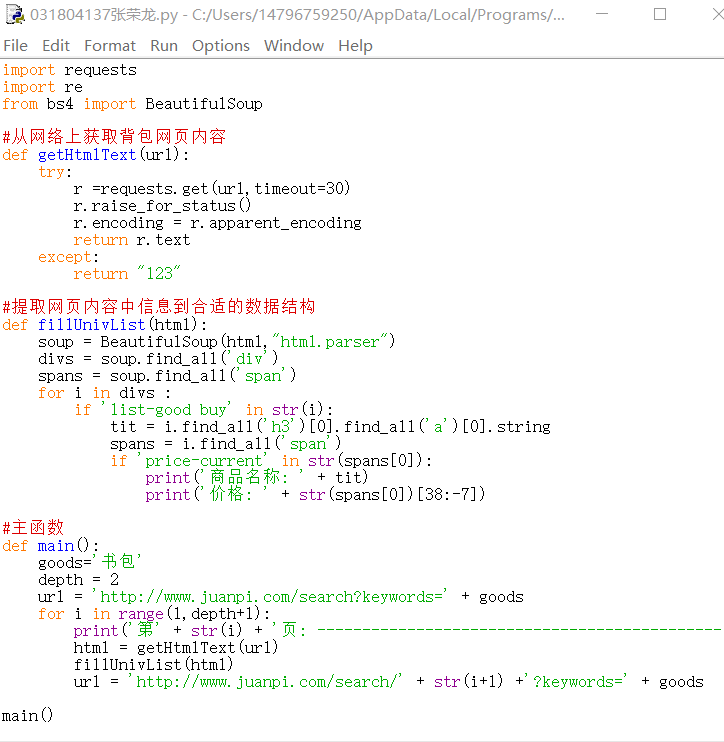
结果截图:
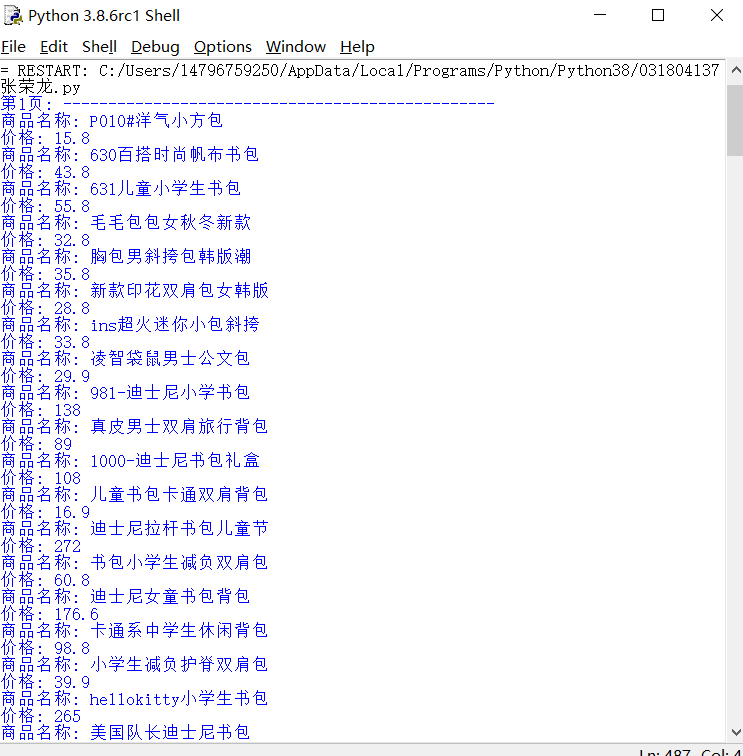
心得体会:愉快地开始第二次作业,我爬取的是卷皮网上的商品。这题主要在接口方面处理了挺久的,一开始不懂接口,后面专门查资料才勉强弄清楚,这次的接口所需携带的参数看上去很多,但实际上必须要提交的参数就两个,即商品名称和当前页码的偏移量。总之全程还是可以的。
作业三:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
代码:
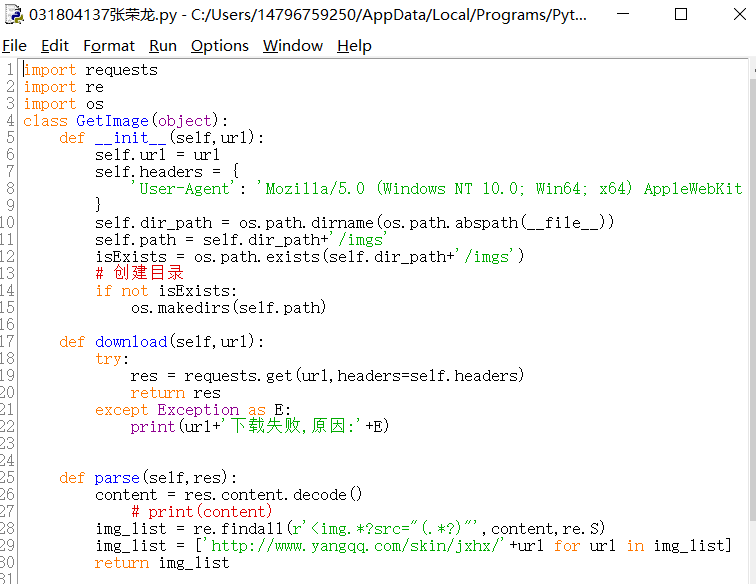

结果截图:
心得体会:我用的是自选网址,实现这一网址上的图片下载。这题还是挺简单的,安装模块后新建代码文件,写代码之后在文件上鼠标右键运行就可以得到结果了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号