《推荐系统:产品与算法解析》读书笔记
《推荐系统:产品与算法解析》
王超
66个笔记
对本书的赞誉
-
爱因斯坦曾说过:“所有困难的问题,答案都在更高层次。”本书就是对这一理念的践行。对于如何做好“推荐”这件事,作者并没有单从技术本身求解答案,还从信息分发的本质带你溯本求源,找到真正的破局之道。强烈推荐大家入手这本书,提高我们认知推荐系统的思维层次。
第1章 产品创新引领的供给侧变革
-
正如传播学权威Marshall Mcluhan在《理解媒介:论人的延伸》(Understanding Media: The Extensions ofMan)一书中所述,人们常常过于关注内容本身,而忽略了媒介在传播内容中的重要性。事实上,媒介即讯息,在媒介约定的范式下对内容进行理解和创作,其根本特性不在于内容,而在于媒介。回顾推荐产品的发展历程,其诸多变革也是在产品经理洞察到这一点后从媒介层面发起的,例如从图文到短视频、从短视频到微视频等。因此,本节将基于我对媒介变迁趋势的几点理解,来推演推荐系统未来的发展方向,并讨论从业者在这一趋势中应承担的社会责任。
第2章 技术创新引领的供给侧变革
-
若想让机器像人脑一样理解与创作,就必须做好内容理解与生成的技术。以文字和视频这两种推荐产品中常见的媒介为例,本节将介绍自然语言处理(natural language processing,NLP)和计算机视觉(computer vision,CV)这两大技术流派的发展脉络。在具体介绍前,先列举生活中常见的一些内容理解与生成任务。
-
以文字和视频媒介为例,内容理解任务主要包括文本理解、视频理解与多模态理解。文本理解是NLP领域中的基础任务,主要包括语义理解、情感分析和文本分类等,常常被用在资讯推荐等场景中产生基础特征。视频理解则是在CV领域中理解图像的基础上将视频看作由多帧图像组成的序列,来处理如视频跟踪、视频分类等任务。多模态理解需要同时处理文本、视频等不同模态,以完成以文本搜索视频等任务。
-
在内容理解的基础上更进一步,就是对内容的生成。在文本生成任务中,对NLP领域产生深远影响的是机器翻译任务,除机器翻译之外,还包括自动问答等单模态任务和图像描述这种看图说话的多模态任务。在视频生成任务中同样也有单模态和多模态两种形式,常见的单模态任务是视频风格转换任务,而多模态任务则是通过文本描述生成视频,近年来随着Pika等产品的推广逐渐为人们所熟知。在大模型技术成为真正意义上的主流技术前,NLP和CV领域在完成上述任务时所采用的技术范式大相径庭。本节先回溯CV和NLP领域的几个重要的发展阶段,只有理解了这些技术流派的演进历程,才能更好地理解大模型范式的优势。
-
2.1.1 从人工特征到CNN结构在CV领域的发展历程中,如何更好地模拟人类大脑视觉皮层一直是贯穿其中的主题。接下来,我们从CV领域的诞生说起,简单介绍其在大模型时代到来之前的发展路径。
-
2.模拟大脑视觉的CNN时代20世纪60年代,David Hubel和Torsten Wiesel在研究时发现,人脑初级视觉皮层中包括两种不同类型的细胞:只对特定位置特定方向有强烈反应的简单细胞、对方向敏感但对位置不敏感的复杂细胞。这项研究也帮助二人获得了1981年的诺贝尔生理学或医学奖。20世纪80年代,日本科学家福岛邦彦将人类视觉系统的思想引入人工神经网络之中,提出了作为CNN雏形的新认知机(neocognitron)。简单来说,neocognitron是一个7层的网络结构,如图 2-1所示,具有以下几个主要特点。[插图]图2-1 neocognitron结构● 模拟视觉皮层。neocognitron分别定义了S层和C层,分别对应人脑初级视觉皮层中的简单细胞和复杂细胞。其中,S层负责提取如边缘、角点等局部特征,而C层负责对特征进行空间汇总,实现平移、缩放等操作时的不变性。● 局部连接。如果使用一般的神经网络,一般是将图像打平成一维向量,再叠加全连接层,这样每一个隐层节点需要与所有输入节点进行交互。neocognitron中的神经元只与其局部感受野中的上一层神经元相连接,即只关注原始图像的一小部分,这样可以减少网络参数,降低计算量。● 权值共享。如果使用一般的神经网络,同一个隐层节点与不同输入节点间的权重是不同的。在neocognitron中,S层的神经元被分成多个子集,每个子集共享权重,从而可以提取相同的特征。
-
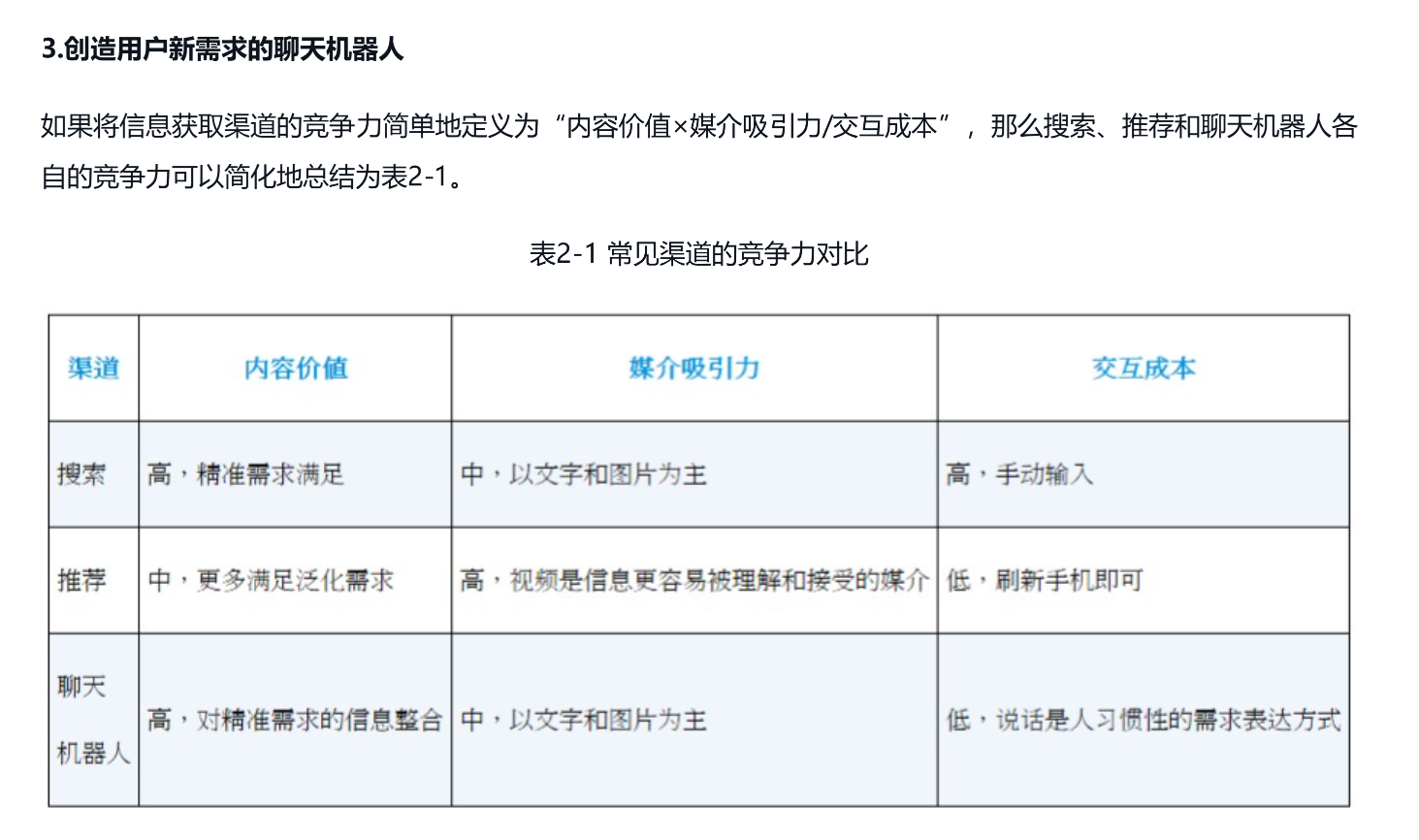
在不断增加模型的层数使得网络变得更深,但网络越深,往后的梯度就越容易消失,越容易出现模型性能退化的现象。于是在2015年,“Deep Residual Learning for Image Recognition”论文中提出了具有残差连接思想的残差网络(residual network,ResNet)。如图2-2所示,输入数据[插图]需要经过两条通路,一条是正常的多层神经网络 的通路[插图],另一条则是使用恒等映射(identity mapping)直接连接到输出的捷径(shortcut)[插图],这就使[插图]只需要学习输出值与原始值的残差,从而解决了模型性能退化的问题。
-
自AlexNet之后,CNN已经逐渐成为图像理解的关键组件。下面,我们将以视频分类为例,来探讨在图像的空间信息上增加时间维度后如何对多帧图像间的时空关系进行建模,以深入理解视频内容。● 启发式的帧融合方式。2014年的“Large-Scale Video Classification with Convolutional Neural Networks”论文中基于经典的CNN进行建模,根据融合的先后顺序提出了单帧(single frame)、后融合(late fusion)、前融合(early fusion)及缓慢融合(slow fusion)4种融合方式。● 双流结构。这类方法从空间流(spatial stream)和时间流(temporal stream)两个角度进行建模,空间流是将单帧图像经过CNN进行图像分类,而时间流则是先对多帧图像提取光流(optical flow)特征,再经过CNN进行分类,最后将这两个分类预估值进行融合。
-
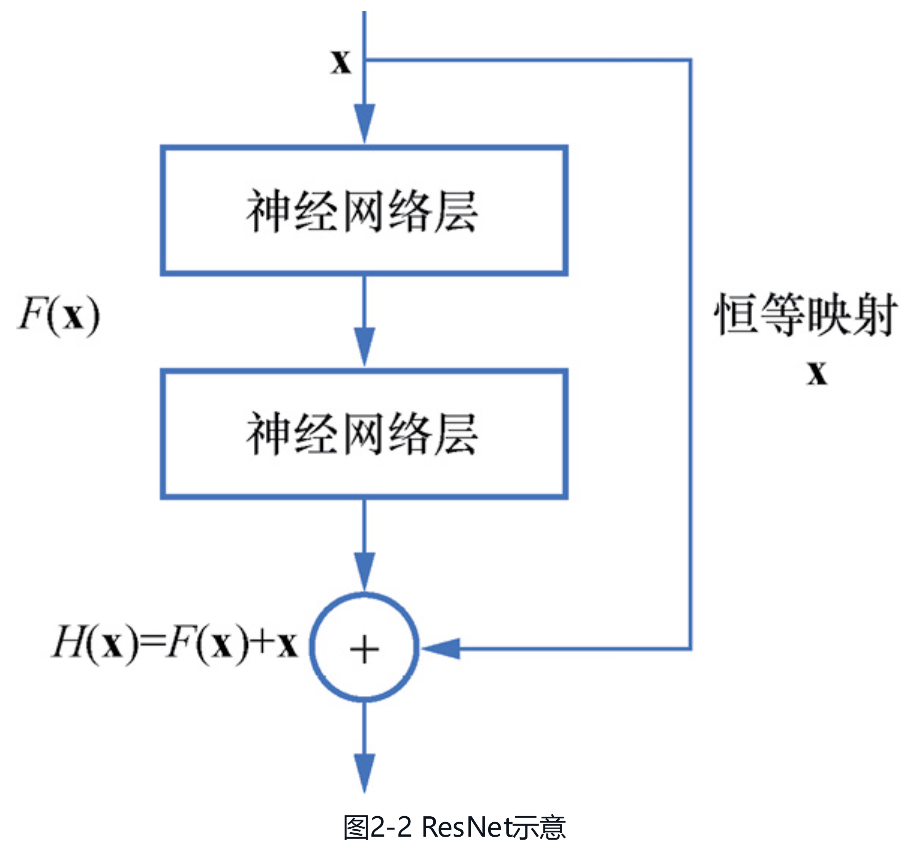
(1)统计语言模型。进入21世纪后,统计语言模型(statistical language model,SLM)一度非常流行。SLM用客观世界中已存在的大量语料来进行各种分布的统计,并从统计学角度对整个句子的概率分布进行估计,轻松打败了打磨数十年的基于规则的专家系统。具体来说,假设一句话有[插图]个词[插图],这句话的概率就可以表示为公式(2.1):[插图](2.1)其中,最后一项是条件概率[插图],可以通过同时出现[插图]这[插图]个词的统计次数除以同时出现 [插图]这[插图]个词的统计次数得到。可以想象,因为实际应用中训练语料有限,所以这种统计方式会面临统计稀疏性的问题。于是,通过马尔可夫假设对联合概率进行简化的n-gram(n元语法)模型被提出,它假设第n个词的出现概率只与其前面n-1个词相关,从而缓解了稀疏性问题。然而,作为一个统计模型,n元语法模型没有泛化能力,例如“猫在卧室里走”和“狗在房间内跑”这两个句子虽然相似度比较高,但由于其中完全相同的词很少,因此n元语法模型便会得出两个句子极不相似的结论。(2)词向量。为了让语言模型具有更好的泛化性,在2003年的 “A Neural Probabilistic Language Model”论文中提出了神经网络语言模型(neural network language model,NNLM)。NNLM通过一个线性映射和一个非线性隐层连接,在给定前[插图]个词的条件下,输出第[插图]个词的条件概率。同时,NNLM还提出了一个“副产品”—词的分布式语义表示,即可以使用一个[插图]维的向量来表示一个词,也称为词向量。接着,在10年之后的2013年,“Efficient Estimation of Word Representations in Vector Space”论文中对NNLM中词向量的概念进行了强化,并通过比NNLM更高效的方式进行训练,这就是著名的word2vec模型,训练方式主要包括以下两种,如图2-3所示。● CBOW。连续词袋模型(continuous bag of words),使用周围的词来预测中间的词。这种方式与NNLM比较像,都是输入若干词来预测一个词,但NNLM是输入左侧的词预测当前词,而CBOW是输入左右两侧的词预测当前词。以“我明天去海南旅游”这个句子为例,NNLM使用“我”“明天”“去”“海南”来预测“旅游”,CBOW则使用“我”“明天”“海南”“旅游”来预测“去”。● Skip-gram。跳字模型,与CBOW相反,Skip-gram使用中间的词来预测周围的词。还是以“我明天去海南旅游”这个句子为例,使用“去”来预测“明天”和“海南”,就是窗口为1的Skip-gram,而使用“去”来预测“我”“明天”“海南”“旅游”,就是窗口为2的Skip-gram。
-
此外,word2vec还可以通过以下两种方式进一步加速训练。● 层次化softmax(hierarchical softmax),即将原来扁平化的[插图]个词建成一棵哈夫曼树,相当于将原本的一次[插图]分类问题转换成[插图]次二分类问题。● 噪声对比估计(noise contrastive estimation,NCE),通过负采样(negative sampling)的方式,对每个正样本采样[插图]个负样本,从而将原本的一次[插图]分类问题转换成[插图]次二分类问题。当然,word2vec也存在不少问题。例如,CBOW对多个词只是简单地取了平均,虽然计算快但难免粗糙;又如不论是CBOW还是Skip-gram,都没有考虑位置信息,而在自然语言处理中,位置信息是比较重要的。
-
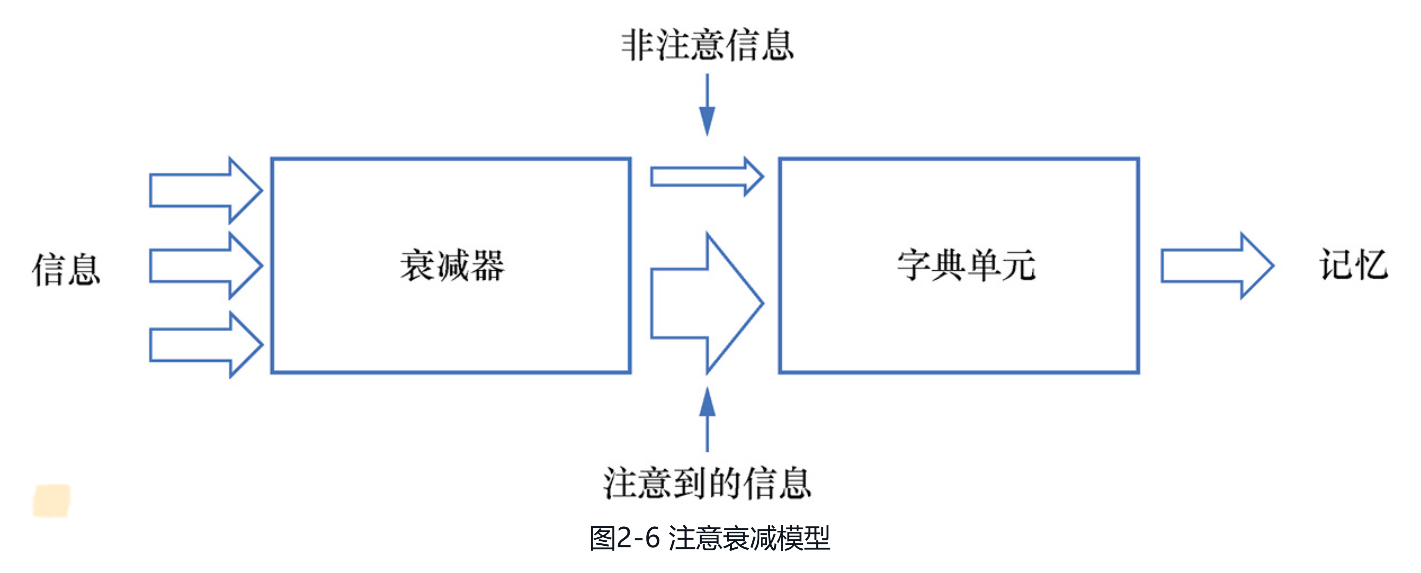
注意力机制具有看不见又摸不着的特质,有关注意力机制的研究起源于心理学领域,并为后续其在机器学习领域的 发展提供了灵感。以下就是注意力机制在心理学研究中所经历的主要发展阶段。● 早期的注意力研究。研究者开始对注意力的概念进行定义和分类,例如William James在他的著作《心理学原理》(The Principles of Psychology)中就尝试描述了注意力的概念。● 认知心理学阶段。随着认知心理学的兴起,人们开始使用更精细的实验方法来研究注意力,这些方法如视觉搜索任务和双耳分听实验。这些研究揭示了注意力中一些基本的特性,如注意力资源的有限性和选择性。● 神经心理学阶段。随着脑成像技术的发展,研究者开始直接观测大脑在进行注意力任务时的活动模式。例如,科学家们发现前额叶皮层和后顶叶皮层在注意力控制中扮演了重要角色,这些区域在人们转换或维持注意力焦点时会变得活跃。在上述发展阶段中,更为人们所熟知的主要是认知心理学阶段的几个实验,其中,著名的双耳分听实验是由ColinCherry在1953年进行的。实验中分别给受试者的左耳、右耳输入不同的信息,要求他们更专注于其中一个声源,并大声复述所听到的信息(称为追随)。经过实验发现,受试者能够较容易追随出追随耳听到的信息,而对非追随耳,受试者只能判断男声或女声,却说不出听到的具体信息。这种现象被称为鸡尾酒会效应,即在嘈杂的酒会上,虽然有很多人在说话,但我们只能聚焦其中一个人说的话。为了解释这种现象,在1958年,英国心理学家Donald Broadbent提出了注意过滤器模型,如图2-5所示。图中的感觉记忆只用于短暂地保存输入信息,然后过滤器根据刺激的物理特性(如音调、语速等)识别注意到的信息,并将其输入探测器对信息进行更高阶的加工,最后将加工后的信息存入记忆之中。
-
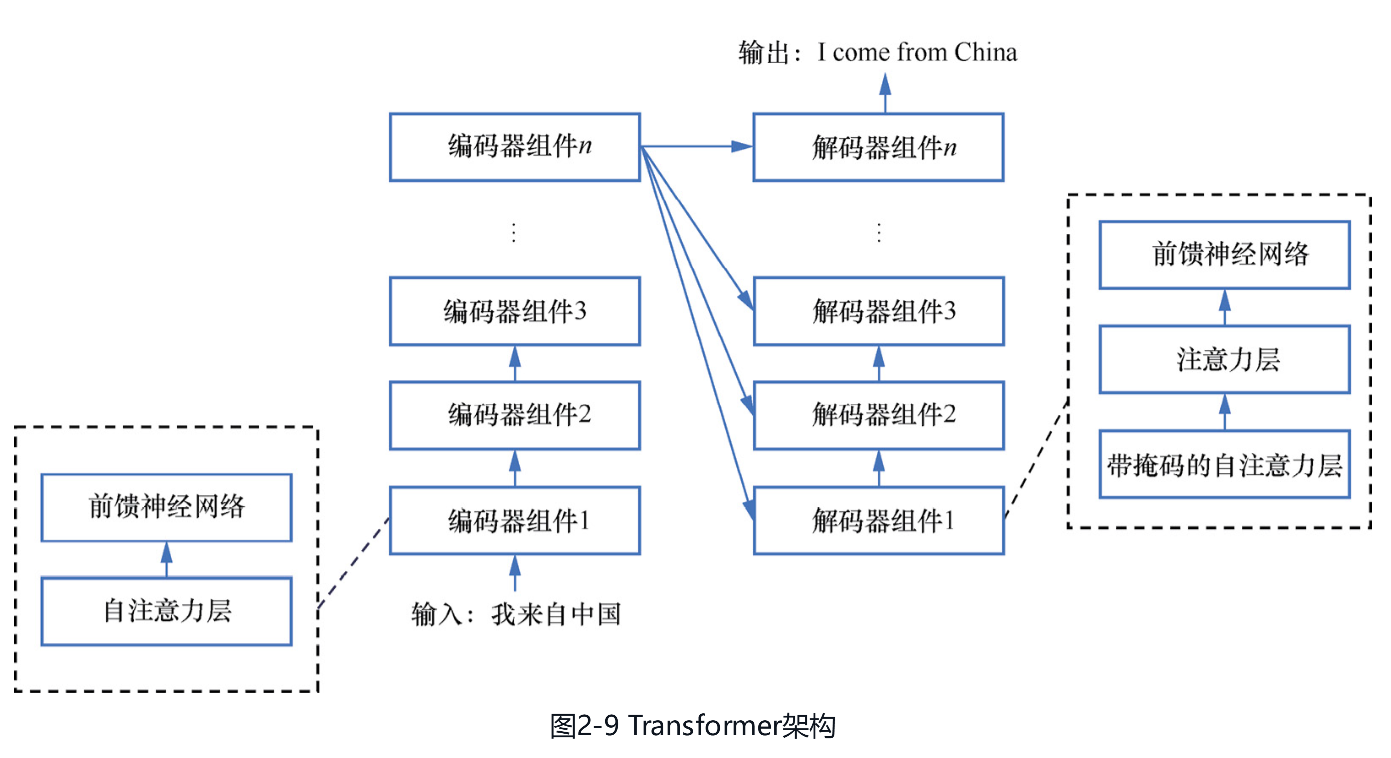
2.让注意力机制爆红的Transformer机器学习领域的研究者们一直以来并没有将研究重心放在注意力机制上,直到其在NLP的机器翻译任务中成功落地。这里将首先介绍机器翻译的编码器—解码器(encoder-decoder)结构和注意力机制在其中的首次落地,然后介绍让注意力机制真正火遍全球的Transformer模型。(1)机器翻译中的注意力机制。2014年的“Learning Phrase Representations using RNN Encoder-Decoder forStatistical Machine Translation”论文中将机器翻译问题建模成一个由源序列到目标序列的生成问题,并提出了编码器—解码器框架。编码器—解码器的整体架构如图2-7所示,编码器负责将输入的不定长源序列[插图]编码成一个中间向量[插图],解码器负责将中间向量[插图]解码成不定长的目标序列[插图]。为了更好地建模不定长序列,图中的编码器和解码器所使用的都是RNN。编码器—解码器的架构一经提出,便成为此后大多数机器翻译模型的标配。 [插图]图2-7 编码器—解码器的整体架构在这个编码器—解码器框架中,编码器把输入信息压缩到一个固定长度的向量中,一定程度上造成了模型表达能力出现瓶颈。为了解决这一问题,在2015年的“Neural Machine Translation by Jointly Learning to Align andTranslate”论文中首次将注意力机制引入了NLP领域。如图2-8所示,这篇论文在编码器和解码器中间增加了一层注意力机制。以从中文到英文的机器翻译问题为例,源序列“我来自中国”是[插图],经过编码器输出得到[插图],目标序列“I come from China”是[插图],中间的隐层状态是[插图]。那么时间步[插图]下的[插图]就可以表示为[插图],其中函数f可以是RNN等网络结构,[插图]通过公式(2.2)的注意力机制来计算以丰富第[插图]个词的表示,F是一个相似度函数用于计算[插图]和h的相似度。
-
2.Transformer在CV的应用既然仅基于注意力的Transformer能够取代CNN和RNN,那么,将CV和NLP的模型迁移到Transformer上就成为一个趋势。当Transformer在NLP领域提出后,在CV领域也出现了不少Transformer的实践,例如以下两个。● Vision Transformer。2021年的“An Image is Worth 16×16 Words: Transformers for Image Recognitionat Scale”论文中提出了视觉Transformer(Vision Transformer,ViT),率先将Transformer应用到了CV之中。如图2-11所示,ViT的思路很简单,就是想办法将图像变成句子,然后直接套用BERT。具体来说,首先将图像分割成编号为从1到[插图]的[插图]个小块(patch),把它们看成[插图]个词,并在前面增加一个特殊的[class]标记,类似BERT的[CLS]标记,用于表示整个图像。然后将每个patch映射成一个向量,再加上该位置的位置编码,就可以得到一个词的表示。再将得到的[插图]个向量输入Transformer编码器,就可以像BERT一样,将[class]标记在最后一层输出的向量经过一层多层感知机并进行图像分类了。
-
2.2.3 自回归、生成对抗和扩散范式下的内容生成2022年8月,在美国科罗拉多州的艺术博览会上,由Midjourney生成的绘画作品《太空歌剧院》一举夺魁,使得AIGC技术开始为人们所熟知。同年12月,OpenAI又发布了知识面宽广的聊天机器人ChatGPT,更是提升了人们 对AIGC领域的想象和期待。本节将从技术角度出发,介绍近年来在内容的智能创作领域比较常用的自回归、生成对抗网络和扩散模型这3大类范式。
-
(1)基于自回归的GPT。在Transformer问世后不久,OpenAI在2018年的“Improving LanguageUnderstanding by Generative Pre-Traning”论文中就发布了基于Transformer解码器的生成式预训练Transformer(generative pre-trained Transformer,GPT)模型。不过,与BERT采用自编码范式以更好地服务搜索任务不同,GPT的设计目标是优化生成式任务,因此采用的是自回归范式,从而在创作能力上具备了差异化优势。随着2019年参数和训练语料更多的GPT-2发布,OpenAI逐渐发现,在阅读理解、机器翻译和开放式问答等任务上,GPT-2可以在完全不进行微调的情况下,使模型能力随参数量增加而增强。这就给人们带来了一个启发,如果参数规模继续扩大,是否有可能出现更令人惊喜的效果呢?事实上,令人惊喜的效果在2020年真的出现了。OpenAI在“Language Models are Few-Shot Learners”论文中提出了GPT-3模型,一方面它的参数量是GPT-2的116倍,达到了惊人的1750亿个;另一方面,GPT-3直接取消了微调阶段,转而提出了语境学习(in-contextlearning)这种更简洁的学习方式。
-
AIGC技术在智能创作领域(如内容撰写和图像生成中)已经展示了其巨大潜力,它能够大幅降低内容的创作成本。不过,除了这一明确的价值,更引人关注的问题是,AIGC技术到底是与人协同创作,还是终将会替代人类去创作呢?为了讨论这一点,我们先回顾一下在大模型技术成熟之前,历史上曾经出现过的应用AIGC技术的一些先例。● 新闻。美联社在2013年与Automated Insights公司达成合作,是最早将新闻生产的部分工作交给AI完成的机构之一。之后很多公司纷纷跟进,使用AI来对新闻稿件进行辅助创作。但是通过AI较难生成有深度的新闻稿件,因此一般只在如体育、财经等快讯场景中有所应用。
-
视频。在2015年上映的电影《速度与激情7》中,片方为了让已逝去的Paul Walker在荧幕上“复活”,花费了高昂的成本。随着技术的进步,如今只需简单录一些视频,就可以让更逼真的数字人代替主播和视频作者,生成令很多用户难以分辨真假的视频内容。
-
音乐。2023年5月,视频网站上出现了一位“AI孙燕姿”,能够生成许多经典歌曲的孙燕姿版翻唱,很快就获得了大量关注。● 照片。2023年7月,一款名为妙鸭相机的产品基于前文介绍的扩散模型,用少量照片就可以生成与本人相仿的照片。由于这款产品具备了一定的实际效用,例如生成证件照,因此一时间让人们认为它将取代线下照相馆,成为未来写真照的主流。● 电影。2023年7月,一款由AI生成的电影预告片《创世纪》(Trailer: Genesis)在社交媒体上引起了轰动,因为这个具有专业级视觉效果的视频仅花费了作者7小时和125美元。在上述示例中,虽然有些应用因技术尚未成熟而逐渐消失,但也有很多技术如语音合成和直播数字人等,不仅大幅提升了创作者的效率,同时也在感知层面上逐渐缩小了与人类的差距,所以正在得到越来越多的应用。于是,这一趋势开始让很多人认为,随着技术的创新,AI终将从辅助人类创作转变为替代人类创作。
-
然而从我个人视角来判断,虽然AIGC可以使创作变得更加高效,但是如果以AI为主体来进行创作,恐怕并不能使人们产生真正的共情。毕竟,内容的价值在很大程度上取决于它与人类情感的连接,而这并非是技术能完全决定的。
-
不过问题的关键在于,即便在人们知晓某一作品是由AI创作后就立刻使它失去流行的可能性,随着AIGC技术逐渐掌握人类情感的表达方式,又有多少人能轻易分辨出内容的真伪呢?所以,AIGC技术在大众领域的传播可能已经呈现出不可阻挡的趋势,它并不会轻易受到我所在意的艺术原真性的影响。
-
(1)对广告行业的革新。由于ChatGPT这类基于提示词生成文本的应用天然适用于广告创意文案的生成,因此在传统广告营销场景,很容易变革人们手工撰写文案的方式,例如在2020年获得了GPT-3的内测资格后,Jasper公司使用GPT-3为客户创作广告文案、标语等内容。
-
不过正如广告史上知名的文案撰稿人之一—Claude Hopkins所说,“成功的推销员很少是能言善辩的,他们几乎没有演说的魅力可言,有的只是对消费者和产品的了解以及朴实无华的品性和一颗真诚的心。广告文案亦是如此。”所以就我个人理解,若想应用类GPT的技术生成真正能赢得人们信任的广告文案,还是要深耕于产品所在的行业。
-
(2)变革服务效率的革新。随着ChatGPT等内容生成产品推出按调用量付费的模式,只要单次调用API的收益能超过其成本,就势必会让这类技术快速大规模地铺开。因此,在智能客服、智能问诊、数字人等机构化的服务行业中,尽管AIGC技术还做不到在全流程上取代人工,例如数字人还不足以完成口红试色等任务,但在规则性较强的局部环节势必会替代人,整体以人机协同的方式来提供服务。
-
考虑到创新的一大特点在于,不被人注意时才更可能成功,所以在人人都关注大模型的时代,只有找到他人不选择走的路,才能通过避免同质化竞争获得长远发展。
-
自然高效的交流方式。移动互联网时代,产品功能不断堆砌的结果是一个过于复杂的触屏交互,使用户很难轻松找到所需。相比之下,聊天作为人类主要的交流方式,不仅自然高效,而且对大多数人几乎没有学习成本,例如电影《她》(Her)中的场景就展示了一个可能的未来。人与机器之间完全通过语音对话来进行交流,从而让人在潜意识中和拟人化的机器间建立起一种更深层次的情感连接。这种连接一旦建立,用户可能就不愿再回到传统的交互方式了。
第3章 从产品视角看需求侧增长
-
综合3种网络拓扑下的价值公式可以看出,推荐产品的演进过程本质上就是网络效应在不断增强的过程,因此,未来谁能在产品中构建出更加紧密稳定的连接关系,谁就能在网络效应的助力下获得更长久的竞争优势。此外,不同于人们习惯性地认为社交产品一定具有更强的网络效应,以连接用户为理念的算法分发产品其实比强马太效应的社交产品具有更高的网络价值,也就是说,网络效应并不仅仅由产品类型决定,更多还是取决于产品的设计理念和实现的精细程度。
-
不难想象,由于临界点理论过于激进,许多产品误以为只需烧钱就能到达临界点,且到达临界点后就可以高枕无忧。于是,借助资本的力量来催熟产品的模式就屡见不鲜了。事实上,这种急于求成的过程中隐藏着许多误区,本节将介绍常见的误区和应对思路。1.产品是否真的有强网络效应网络效应描述的是用户从网络中获得的价值会随用户数增加而增加的特性,因此,如果一个产品不具备强网络效应,那么在其初始阶段价值较低的情况下,想达到用户规模的临界点就需要很长的时间,而如果产品试图通过烧钱来加速这一过程,就可能适得其反,在获客成本增加和用户质量下降的情况下加速产品的衰败。因此在大力推动增长之前,首先需要确认的是,你的产品真的具有强网络效应吗?以下就列举网络效应的常见误区。(1)规模效应与网络效应。与网络效应作用在需求端不同,规模效应作用在供给端,指的是通过变革供给效率和扩大供给规模来摊薄固定成本。例如,特斯拉一再降价的底气就来自它领先的汽车制造技术给产品带来的强定价优势。在推荐产品中,有很多产品就是仅具备规模效应而不具备网络效应的。例如,对总线型拓扑的传统媒体产品来说,由于它们服务于单个用户的边际成本会随用户规模的扩大而降低,因此这类产品具有较强的规模效应,不过3.2.1节曾讨论过,由于用户获得的价值并不会随用户数的增加而增加,因此,这类产品是不具备网络效应的。(2)羸弱的数据网络效应。数据网络效应的特性是随着用户增多和训练样本的增多,算法模型的效果越变越好,进而让每个用户获得的价值也会随用户数的增加而增加。不过,熟悉算法的读者可能会有这样的疑问,在训练样本已经很多的情况下,再增加训练样本真的会让模型的效果有质变吗?这里就以一个网络效应很弱的算法产品为例来说明。假设有一款这样的产品,对于新用户,它主要推荐热门内容;对于老用户,它主要推荐和历史行为相关的内容。那么从数据的角度来看,由于这两类样本在历史上已经出现过很多次了,因此对模型效果的改善并没有太大的增益,于是我们就可以推断,在新用户贡献的新样本对老用户没有明显的助力时,这类产品的网络效应实际上是相当弱的。
-
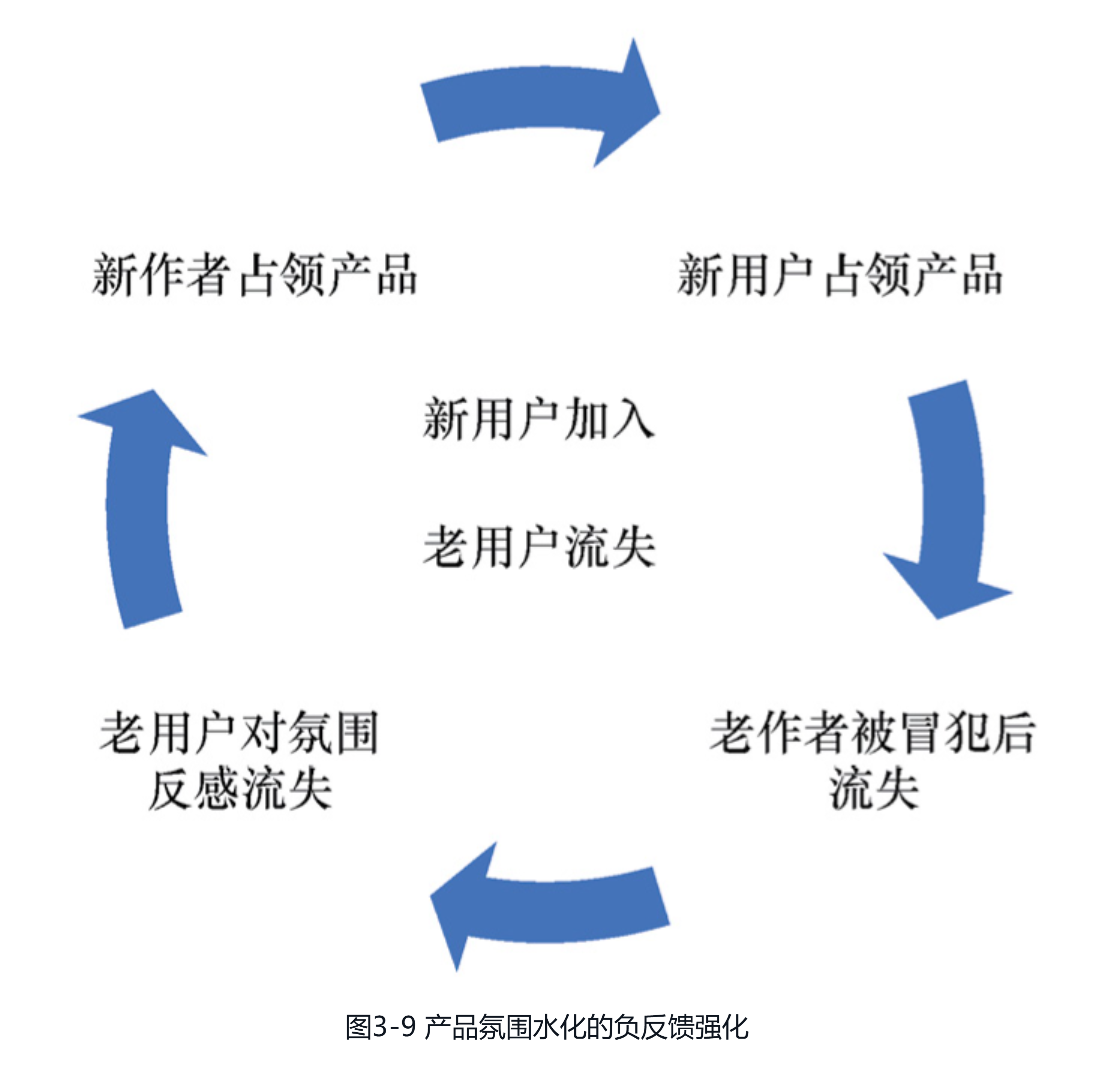
2.忽视网络负外部性网络效应也被称为“网络的正外部性”,这是因为每一位新用户的加入都会为其他用户带来正向的价值。不过,正如“反者道之动”的道理,势必会存在一股反向的力量去平衡网络效应,这就是“网络的负外部性”。举例来说,当用户规模超出系统容量时,由于新用户的加入会加剧系统中的拥堵,因此会降低其他用户的价值。因此,尽管产品具备网络效应,但如果盲目地加快突破临界点的速度,就会在网络的正外部性和负外部性同时增强的情况下,触发一些始料未及的隐患。而如果没有处理好这些隐患,就会在网络的负外部性压制住网络效应的情况下,使产品过早地到达增长的饱和点,从而限制了更大的发展空间。接下来,这里就举一个推荐产品中网络负外部性不断被强化的例子。如图3-9所示,假设在推荐产品快速扩张时,引入了一些与产品氛围不相符的新用户,且产品在策略和设计上未能做好优雅的隔离,那么,这些新用户的评论就有可能冒犯老作者,并导致他们离开。接着,随着老作者流失及新作者生产的内容令老用户反感,老用户也会逐渐流失。于是,当新用户和新作者逐渐占领产品,产品就会在新用户加入与老用户流失的共同作用下,陷入增长停滞的状态。
-
3.急功近利的结网过程除了网络的负外部性,由于很多产品在构建网络效应时过于急切,希望将产品中的各方尽快编织到一张紧密连接的网中,因此结网过程本身也存在不少急功近利的误区。以促成用户和作者关注关系的建立过程为例,考虑到关注率通常会比较低,一些产品在急于求成的情况下就容易过度干预,例如,在用户每次打开产品时引导用户自动关注一些他们不感兴趣的作者,进而在用户使用产品时又强迫用户阅读这些作者的内容等。显然,这种方式非但不能实现网络效应,反而会加剧网络的负外部性,逼迫用户更早离开产品。那么,应如何正确地构建网络效应呢?简单来说,就是“弱者道之用”,产品需要更温和地激发用户之间真正的关注需求,逐步形成供需匹配的正反馈。例如,可以先通过强化关注率目标的策略,将那些更能吸引关注度的作者逐步加大力度地推荐给用户,进而,在用户的关注需求真正被激发之后,再激励更多有关注潜力的新作者加入。当然,这种方式从节奏上可能会慢很多,但它比强行凑对的方式会健康很多,只是更需要耐心罢了。更具体地,关于如何培育具有强网络效应的社区型产品,本书在10.1节中将呈现更具体的思考,感兴趣的读者可以进一步了解。
第6章 A/B测试是增长的银弹吗
-
6.1 A/B测试的原理和优势早在2000年左右,谷歌等强调数据驱动的公司就已经广泛应用A/B测试。2010年,谷歌在论文“OverlappingExperiment Infrastructure: More, Better, Faster Experimentation”(本章简称“论文”)中给出了一个利用分层机制来保证实验流量高可用的经典方案,考虑到后续大部分A/B测试平台是基于这篇论文来建设的,本节将基于这篇论文及实践中的一些经验,简述A/B测试的原理和优势。
-
尽管分层正交的实现看起来可能很复杂,但其实用一个随机性很强的哈希函数就能完成,论文中给出了4种常用的哈希方法,如公式(6.1)~公式(6.4)所示。方法1:按用户ID哈希。[插图](6.1)方法2:按Cookie哈希。[插图](6.2)方法3:按Cookie日期哈希。[插图](6.3)方法4:直接随机。[插图](6.4)其中,按用户ID哈希和按Cookie哈希适用于运营用户的场景,按Cookie日期哈希适用于需要考虑节假日影响的场景,而直接随机则适用于运营流量的场景。此外,为了处理哈希冲突的问题,论文中会按照固定的优先级顺序(用户ID、Cookie、Cookie日期和随机)来分配流量,以确保流量分配的一致性。
-
2.A/B测试的可靠性保证当然,A/B测试自身的可靠性非常重要。如果没有良好的可靠性保证,误将波动看作正向推全,就会导致实验结果的虚假繁荣,从而产生比“拍脑袋”决策更糟糕的后果。在谷歌的论文及实践中,一般有以下6种方法可以提高实验的可靠性。(1)基于假设检验的统计置信度。当单个实验的流量较少时,可能导致统计结果不可信,这时就需要类似t检验的假设检验方法了,其大致流程是,依据想改变的敏感度的期望值[插图](如期望观测到时长有2%的变化值)和样本标准差[插图],在给定的统计置信度(通常设定为95%)和统计功效(通常设定为80%)下,算出至少需要的样本数。同时,为了进一步增加实验的可信度,还可以运行一组同质的A/A实验,通过其结果来了解实验的随机噪声水平。(2)设置空转期。除样本规模外,A/B测试还需要设定一个与实验期有相同流量但尚未开启实验的空转期,以确保实验组与对照组真正可比。在实践中,可以先空转若干天再开始实验。还有一种相对高效的做法是直接开始实验,然
-
后对命中实验的用户回溯之前若干天的空转数据。(3)设置长期反转实验。考虑到用户可能会因感到新奇而在进入实验组后表现得更活跃,所以在实验推全后需要设置足够长的反转期,以了解实验在稳定后真实的长期效果。当发现有些场景下反转期实验效果与实验期效果差异较大并且有逐步劣化的趋势时,如果无法进行有效归因,那么比较稳妥的方式就是将对应的推全回滚,避免对用户体验造成负面影响。(4)只观测生效条件下的影响。有些实验仅在特定请求条件下才会被触发,例如某种人群或某种场景下。考虑到确定触发条件需要在线计算,常用的做法是在对照组中也记录下可触发的流量,然后仅对比实验组中被触发流量和对照组中可被触发的流量之间的差异。通过仅关注有效条件下的实验效果,可以避免有效流量较小导致的观测稀释问题。(5)实验收益来源的归因与拆解。实验推全前,应该对收益来源仔细归因以避免错判,例如某实验全局时长上涨3%,但策略生效的A场景时长只上涨了1%,此时就需要分析清楚收益来源,因为很可能是实验设置有问题,例如代码问题对未生效场景造成了影响,才看似产生了收益。(6)重视消融实验。如果实验变量较多,通常还需要采用消融实验来定位收益来源,例如一个有5处改动的实验能带来2.7%的时长收益,但推全需要新增100台机器,而在对这些改动消融后,发现其中的2处改动能带来2.1%的时长收益,并且推全只需14台机器,那么这2处更具性价比的改动就是此次实验收益的主要来源,更适合推全。为了说明反转实验的必要性,下面举一个形象的例子。如图6-2所示,收益逐渐上升的虚线代表的是优化长期收益的健康实验,例如推荐了一些高质量且个性化的内容,收益先上升再下降的实线代表的是优化短期收益的短视实验,例如推荐低俗的内容。显然,如果A/B测试只观测了较短时间且没有设置反转实验,就很容易得出急功近利的短视实验更好的错误结论。
-
6.1.2 A/B测试的优势张小龙曾说:“产品就像一个生物,有它自然的进化之道。最重要的,是制定好产品的内在基因的竞争策略,让竞争策略在进化中自行演化为具体的表现形态”。从这番话中不难看出,在产品激烈竞争的环境中,谁拥有更快的迭代速度,谁就具有更强的生存优势,因此,作为一种能帮助产品快速迭代和进化的工具,基于分层正交机制的A/B测试很快就流行了起来。1.高效率的产品演化机制在设定好可量化的优化目标后,当成百上千组A/B测试同时运转起来时,人们就无须依靠直觉或个人偏好来做决策了。A/B测试通过让实验数据说话来确保决策过程的客观和公正:哪组实验的效果更好就推全哪组。显然,这种方法不仅可以帮决策者快速找到更优方案,减少他们在产品细节处所耗费的精力,同时也增强了一线人
-
员的话语权,从而在决策机制上降低了对经验主义的依赖。需要注意的是,论文中并没有提到产品中应选取哪些优化指标,但实际上这个问题非常重要,如果选错了,那么产品演化的结果可能会越来越糟糕。6.2.1节将详细讨论这一问题。
-
6.2 滥用A/B测试时的增长困境虽然基于A/B测试的数据运营体系有其价值,但通常并不能带着产品引领创新的新方向,换言之,虽然A/B测试可以帮助产品在当前的山峰上越爬越高,但通常并不能用来发现一座新的山峰。本节将讨论如果盲目依赖A/B测试,会在哪些增长问题上遇到瓶颈,从而错失弥足珍贵的创新机会。6.2.1 难以优化留存等长期目标现有的A/B测试框架只能观测相对短期的数据表现,因此如果没有对产品信念的坚持,就很难等到长期结论开花结果的那一天。例如,在纸媒时代常常存在一个规律:杂志在改版后的头几个月往往骂声一片,但几个月后新版就会使发行量显著上升。接下来,本节将探讨在基于A/B测试选取优化目标时,为何要优化留存这种长期目标,以及优化时该注意哪些常见的陷阱。1.死于安乐的短期目标优化资源诅咒(resource curse)是一个经济学概念,它描述了一种现象:很多资源丰富的国家和地区非但没能实现经济繁荣,反而出现了腐败和寻租活动盛行、内战频繁等现象。其实,同样的逻辑也适用于推荐产品,在产品鼎盛时期往往并不重视产品的生死留存,而是倾向优化更能变现的指标,但这样在过度地竭泽而渔后,就会使产品出现生死留存的问题。以下是3个优化目标设计不当的例子。(1)优化用户画像的准确率。在深度学习还未盛行的时代,脱胎于展示广告的人群定向一度非常流行,那么构建精准的用户画像是不是一个好的优化目标呢?显然不是。首先用户画像是否准确和业务好不好没太大关系,其次用户画像根本就没有作为评估标准的真值,例如问一个用户有没有学习的需求,一般人会说有,但真正推荐的话并不会有多少人感兴趣。(2)优化分发量。分发量当然是一个可实现的优化目标,但在准确维度上存在明显的问题。首先,分发量指标本身需要去除无效分发的水分,例如观看时长很短也算分发的话,那么“标题党”的内容显然会增多。其次,分发量的增多并不意味着用户一定会满意。所以分发量并不是一个容易和留存真正挂钩的代理指标。(3)优化人均时长。类似地,优化人均时长其实也存在问题。首先,如果只观测短期数据的话,分发物理时长较长的内容(如电影)肯定可以提升该指标,但显然长期来看并不一定对产品有益。其次,人均指标更容易优化那些容易提升指标的重度用户,并在不知不觉中驱赶体验已经不好的新用户。久而久之,产品DAU等真正核心的指标就会下降,即使所有策略的实验收益看起来都不错。
-
2.生于忧患的留存优化说到底,正如同人类所有行为的源头不过“求存”两字,为了避免优化短期目标时“死于安乐”的资源诅咒现象,推荐系统也只有“生于忧患”,坚定地以关乎产品生死的用户留存和作者留存为优化目标,才能不被各类虚假繁荣的错误目标所控制。更具体地,若想基于A/B测试来优化留存,至少需要重视以下4点。(1)更重视流失用户的反馈。第二次世界大战中有一个著名的幸存者偏差问题,当时Abraham Wald教授发现盟军返航的飞机中,机翼的弹孔最多,发动机的弹孔最少,于是提出了一个看似与直觉相悖的建议,即加强发动机的防护。提出这个建议的原因在于,机翼被频繁击中后能安全返航,说明机翼并非导致飞机坠毁的关键部位,相反,那
-
些弹孔较少的发动机才是中弹后生还概率大大降低的原因。不难理解,推荐产品中的重度用户就好比空战中幸存的飞机,如果在A/B测试中过于关注由他们主导的总时长等指标,就会因忽略轻度用户和流失用户的反馈而落入幸存者偏差的误区。事实上,由于用户在流失时不会给出任何反馈,因此在A/B测试的指标设计上需要格外关注留存率相关的细分指标。类似策略迭代中的问题,幸存者偏差同样也存在于产品侧,不少产品经理在迭代功能时也习惯从自身体验出发,提出一些对流失用户并不重要的改进,这是缺乏同理心和产品认知的表现。正如乔布斯所说,虚心若愚,产品经理需要保持对用户的同理心,并虚心向用户请教,这样才能真正对产品的痛点保持敏感。(2)将推荐功能产品化。早期很多产品对推荐系统的定位都属于锦上添花,例如雅虎就在首页预留了一个推荐模块,并借助首页流量为其导流。这么做虽然能迅速提升推荐模块的流量,但并不足以真正优化推荐系统,毕竟不放手,孩子是不会主动长大的。如果真有好的机会就应将推荐系统独立地产品化,这样才能通过用户反馈的留存信号找到其核心价值,从而真正实现健康发展。(3)不要错把代理指标当成优化目标。对推荐产品来说,虽然本质的目标是要优化留存,但由于留存较难直接建模,且其缓慢变化的过程又与A/B测试快速迭代的特性有所冲突,因此人们往往会把留存目标转换成一个可以直接求解的代理指标来优化。问题就在于,转换的过程中有时会本末倒置,错把代理指标的优化当作衡量产出的标准。其实,与其费劲将单一代理指标优化到极致,不如使大多数代理指标的效果都足够好,这就是很多系统的生存之道。推荐产品中留存的优化也类似,只要找到多个正向的代理指标,并面向留存进行有效的多目标融合,通常就能取得不错的效果。14.2节将系统介绍这类方法的技术实现。此外,如果产品能找到直接优化留存的办法,自然更好。受启发于每一步都放眼终局去做取舍的AlphaGo,推荐系统中目前也有不少采用强化学习方法来优化留存的前沿探索,4.2节和13.3节会介绍相关的主流技术实现。(4)完善A/B测试中留存的观测方式。即使找到了优化留存的方案,但由于留存提升本质上是一个缓慢微弱的过程,因此想要在更擅长观测短期变化的A/B测试框架下观测到显著的留存变化,就对A/B测试的流程提出了更高的要求。这里给出3类观测留存时的典型问题和对应的可能解决办法,我们相信结合具体产品的特性还会有更优的观测方法。● 留存变化缓慢。不同于分发量等指标的变化更为显著,留存往往在观测时长较短时很难有变化,因此可以通过增加观测周期、扩大小流量占比等方式来提升实验结果的显著性,以便能更置信地观测到留存变化。● 对作者侧留存的忽视。在按用户来分流的平台中只能观测用户留存变化,若想优化作者侧留存,就需要精心设计按内容和作者维度来分流的实验机制。● 对传播途径的切断。分流会直接切断内容传播所依赖的关系链,所以如果是实验传播性质比较强的策略,需要设计在小流量中能保留传播关系链的实验机制,否则很难观测到推全后的真正影响。6.2.2 难以反向优化出新市场所谓“反者道之动,弱者道之用”,当事物发展到极限时,通常会出现反向的趋势,而那些看似柔弱的新事物,如果我们能理解并适应这一趋势,更好地运用“道”的力量,就有可能使它们成长为平衡原有事物的另一极。在本节中,我们就来介绍实践上述道家思想的反制型创新,并讨论为何在A/B测试驱动的运营体系中,人们容易错失反制型创新机会。
-
1.与巨头博弈时的反制型创新在推荐产品的创新方法中,反制型创新正是对“反者道之动”思想很好的实践,其核心理念在于,如果你的新产品正与市场巨头竞争,并且认识到正面对抗没有胜算,就应设法从市场巨头的核心优势的反面去发现机会。一旦找到这样的机会,就坚决地对其进行反向的优化,从而确保竞争者在担心遏制你会削弱自己的情况下,不轻易对你采取行动。为了加深对这一方法的理解,这里给出几个反制型创新的案例。(1)把视频变短的抖音。通常来说,优化时长可以增加用户黏性并提升留存指标,所以在YouTube的经典论文“Deep Neural Networks for YouTube Recommendations”中提出了优化单次展示下观测时长的问题后,很多产品都照着去做,于是出现了推荐视频越来越长的趋势,YouTube也并不例外。在这个背景下,内容时长不到15秒的抖音横空出世,其不仅凭借快节奏的内容快速流行,还让当时其他以长视频为主的视频产品很难对其进行遏制,因为一旦这么做就会瓦解自己在长视频作者侧积累多年的生态优势,成本高昂。这也是之后bilibili和YouTube等产品对类抖音产品比较谨慎的原因之一,不是不会,而是成本太高。(2)把单价变低的拼多多。类似于内容型产品优化单次展示时长的做法,电商产品优化单次展示下的变现价值也是一种很常见的做法,例如阿里巴巴就通过一系列技术创新和产品升级,逐渐将交易效率优化到极致。然而,在阿里巴巴高交易效率的优势背后,也隐藏着对低购买力用户不友好的风险,于是拼多多采用了反制型创新的做法,不仅通过超低单价的商品来吸引低购买力的用户,还在自己体量相对较小的情况下发起了补贴大战。
-
显然,拼多多这样的做法让阿里巴巴非常难受。阿里巴巴如果也选择降低客单价,不仅有可能失去这些年努力争取到的高端用户和商家,还会因规模更大而要在相同的补贴力度下付出更高的成本。所以阿里巴巴无法真正发力去遏制拼多多,只能无奈地看着拼多多逐渐涨到了如今的体量。(3)以阅后即焚为特色的Snapchat。Facebook于2012年上市,同年10月用户数突破10亿关口,成为全球社交产品的王者。面对Facebook的碾压,一款名为Snapchat的产品却在2011年6月上线后,不仅轻松活了下来,还在2017年在纽交所顺利上市。究其背后原因,就在于Snapchat采用了与Facebook完全相反的产品设计策略。众所周知,Facebook是一款让人们依赖它来分享自己生活的产品,虽然这没什么短板,但Snapchat敏锐地洞察到,这种努力让自己看起来更完美的分享方式并不适合只是想随意交流的年轻人。于是,Snapchat创新地推出了“阅后即焚”的设计,可以在发布内容后自动销毁,解放了年轻人的天性,并因此赢得了他们的青睐。
-
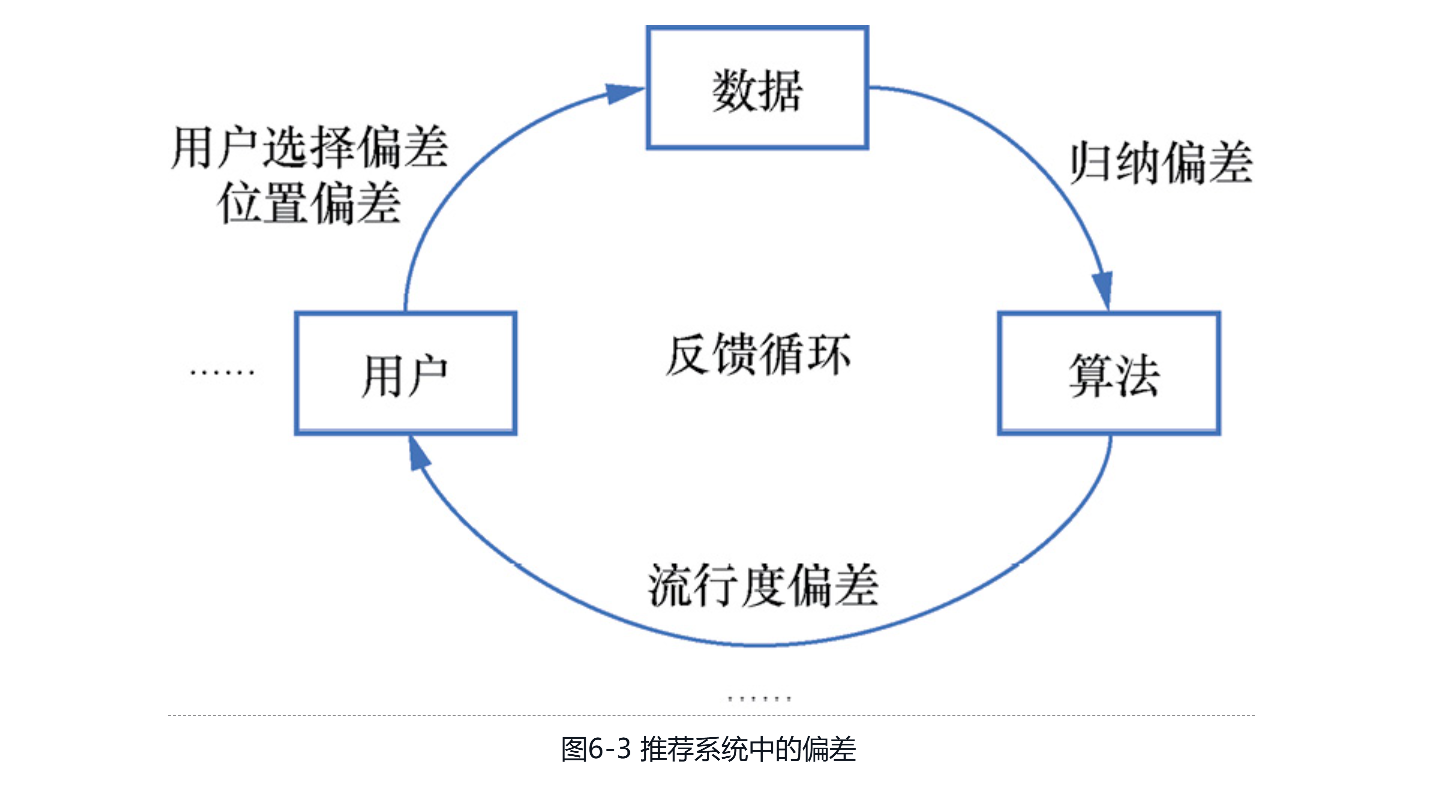
2.被A/B测试低估的反制型创新为何很多习惯于数据驱动的产品,无法实现反制型创新这样看似明显的突破呢?原因就在于,通过数据驱动方法来评估新产品的价值时,很容易得出此类创新的收益有限的结论,甚至推断出负向的错误结论。本节将以市场调研和A/B测试为例,介绍反制型创新常常被低估的原因。(1)市场调研中的样本选择偏差。如果没有对创新的深刻认识,就无法对全新事物进行有效的调研。正如汽车大王Henry Ford所言:“如果我当年去问顾客他们想要什么,他们肯定会告诉我‘一匹更快的马’。”同样的道理,在现有用户群体下对反制型创新进行事无巨细的调研,就容易出现样本选择的偏差,并导致调研结果对创新产品的低估。例如,当奈飞线上DVD租赁业务的订阅用户数破百万时,引起了当时门店租赁巨头百视达的注意。当百视达请研究机构做线上租片的市场调研时,连续两次低估了奈飞的潜力。第一次调研结论是线上租片市场最多只能容纳360万用户,相较于百视达5000万的用户而言不值得考虑。第二次调研结论是线上租片用户仍然喜欢在门店租片,且线上订阅用户的取消比例高、利润低。显然,这都是在选错调研对象后产生的错误结论。于是,在百视达一再低估线上租片的潜力后,于2010年宣布破产。(2)A/B测试时的推荐系统偏差。如图6-3所示,由于推荐算法会通过推荐内容来影响用户的未来行为,而这些行为又会反过来限制推荐算法训练数据的分布,因此就会形成一个被称为反馈循环(feedback loop)的闭环。这个闭环不断运转,带来的用户选择偏差、位置偏差、归纳偏差和流行度偏差等会被逐步放大,并带来对新用户推荐偏向高热的内容、对老用户推荐偏向“信息茧房”等一系列问题。
-
2.被A/B测试低估的扩散型创新从图6-5中不难看出,非线性的扩散型创新就好比是“士别三日”的吴下阿蒙,在产品还没有被大众接受的早期,它在现有人群中并不会显现出明显的收益。因此,当大公司用A/B测试这种更注重短期收益的评估方法来做判断时,就可能会忽视此类创新的潜力。接下来就通过推荐系统中的两个例子,来探讨A/B测试为何容易低估扩散型创新。[插图]图6-5 创新的S形曲线(1)打破用商边界的电商直播。直播起初主要分布在娱乐和游戏等行业中,在淘宝和抖音等产品先后将其和电商场景结合后,给用户带来了全新的购物体验。不过,电商直播的早期,敢在短视频产品中购物的用户并不多。因此,假设有一个A/B测试通过随机抽样用户来迭代直播电商策略,在产品早期的实验收益显然要远低于在直播媒介普及后的收益。(2)基于熟人关系的微信视频号。在抖音全屏沉浸的体验基础上,微信视频号通过在样式和策略上强化朋友点赞信号,给用户带来了更新颖的视频观看体验。于是,随着用户留存的提升和点赞习惯的养成,有朋友点赞的视频也就越来越多了。因此,假设有一个A/B测试的实验基于点赞关系来进行推荐,那么它在点赞习惯普及后所取得的效果就会比产品早期点赞稀疏时显著得多。3.如何孵化扩散型创新从上述介绍可以看出,如果大公司没有找准契合产品的种子用户,仅通过随机抽样现有用户来做A/B测试,很难敏锐洞察到扩散型创新的价值。说到底,如果想要真正拥有这种创新能力,还需要产品经理对用户需求有足够深刻的洞见。接下来,将对如何孵化扩散型创新给出一些关键举措供参考。(1)重视早期采用者的意见。大多数产品会具有一定的价值,所以真正困难的一步是从创新先驱者向早期采用者过渡的阶段。事实上,如果产品仅打动了创新先驱者,但未能打动早期采用者,说明产品并不具备向大众传播的价值。此时若是硬要通过资本来强势推广,很容易在拔苗助长后留下一地鸡毛。举一个正向的小红书的例子。虽然它起初定位是做一款主打购物攻略的媒体型产品,但当小红书的早期采用者开始在产品上分享购物心得后,小红书就敏锐地意识到,原来她们的核心诉求并不仅是浏览内容,还希望与他人分享和交流。于是,小红书就根据意见领袖们的反馈,重新将产品与市场打磨到契合,并逐步发展为今天很受欢迎的一款社区型产品。(2)对创新临界点的感知。当产品经过早期采用者的认可并扩散到早期大众后,产品的上行趋势就已经不太可能被阻挡了。更具体地说,当竞争赛道中有10%以上的用户开始使用某款产品时,它其实就已经接近高速增长的临界点。因此,很多企业虽然不急于做最早的创新者,但一定会在合适的时机入局,并通过大力投入来争取自己能第一个到达临界点。不过,并非所有的产品在突破临界点后都会有快速攀升的趋势,这要取决于产品到底是不是一个真正的好产品,以及它是否具备网络效应。关于这一点已经在3.2节中有过详细探讨。总体来说,要打造一款真正具有创新的产品,坚持产品原则第一性,数据反馈第二性,长远来看更加合理。
第7章 瞬息万变的新闻推荐
-
新
-
洞察到新闻场景需要平衡探索和善用后,雅虎先采用了一个偏探索的统计模型基线,其大体流程如下。● 步骤1:将每篇新文章的点击率初始化为某个较高的数值,确保新文章有机会在开始时就被探索到。● 步骤2:统计最近5分钟窗口内的展示和点击量,并累计之前的统计结果以得到文章全局的点击率,如公式(7.1)所示。[插图](7.1)● 步骤3:在接下来的5分钟内,显示最受欢迎的文章,并基于公式(7.1)每5分钟更新一次文章的受欢迎程度。简单思考后就会发现,上述直观上可行的探索方法在实际场景中并不奏效,因为很多新闻一开始时的点击率可能并不高,但其中有些会在获得关注后快速爆发,同时也有些会在热度下降后迅速衰减。因此,如果采用步骤2中的方式来统计点击率,不仅会将早期低点击率的内容提前淘汰,错失有潜力的待爆发内容,也会过度善用,持续推荐已陷入衰退期的内容,浪费资源。2.ε贪婪策略考虑到新闻类内容动态性极强、呈现非稳态分布的特点,这时能想到的一个朴素的策略就是[插图]贪婪策略,它通过保留比例为[插图]的一部分流量来做无偏探索,以随时评估所有内容在当下的表现,然后将剩余流量拿来做善用,例如选择在探索时点击率最高的内容。事实上,当雅虎基于[插图]贪婪策略取代原先的统计模型基线后,就取得了不错的效果,由于在4.1.2节中已经阐述过原因,这里不再赘述。总体来说,类似雅虎今日新闻的对普适优质内容做探索的场景,正是适合[插图]贪婪策略发挥作用的场景,所以当后人盲目借鉴雅虎的经验将其应用在一些内容质量良莠不齐且个性化需求较强的场景时,或多或少达不到预期效果。
-
3.非稳态分布场景的UCB1变体古典MAB问题中假定环境稳定,即每个臂的奖励分布是已知并且固定的,因此,UCB1等Bandit策略会倾向于先在初期进行更激进的探索,再逐渐过渡到稳定的善用。然而,考虑到雅虎新闻场景环境是未知且不断变化的,很容易在UCB1几乎准备善用时又出现一些新的高奖励臂。于是,雅虎对UCB1策略进行了改良,提出了一种更适应环境动态变化的B-UCB1策略。总体来说,它主要包括如下两点改进。● 动态奖励估计。尽管在新闻场景中,内容点击率的波动非常大,但这种波动通常和时间有关,所以雅虎采用了时间序列模型中的动态伽马泊松模型(DGP模型)来预估点击率,即通过DGP模型中的参数[插图]来更新UCB1公式[插图]中的[插图],这样就更好地适应了新闻点击率随时间变化的特点。● 奖励分布的不确定性处理。B-UCB1通过引入奖励的方差来度量环境动态变化时的不确定性,并将其纳入上界置信区间的计算中,以鼓励对不确定性高的臂进行探索。同时,为了避免臂在选择次数过少时探索项的取值过大,公式中也通过min操作做了一些确保稳定性的微调,具体如公式(7.2)所示。
-
4.EXP3算法在非稳态分布问题中存在一类特殊的对抗场景,如股票交易场景,奖励就是由对抗性环境决定的。对这类场景,也有一些经典的算法,例如由Auer提出的EXP3算法(exponential-weight algorithm for exploration andexploitation)等。下面给出EXP3算法的简单介绍,它在每一轮迭代中主要包含以下3个步骤。● 步骤1:从先前计算的分布[插图]中采样选择一个臂[插图]。● 步骤2:根据观测到的奖励[插图]估算所有臂的预估奖励,[插图],其中[插图],[插图]表示第[插图]个臂在[插图]时刻获得的点击数,[插图]表示臂[插图]的累计奖励。● 步骤3:根据预估奖励和探索参数来更新概率分布[插图],其中,预估奖励[插图]和探索参数[插图]越大,臂被选中的概率就越大。不难看出,EXP3和UCB1的主要区别在于,尽管每轮只能观测到所选臂[插图]的点击数[插图],但EXP3仍然以指数加权的形式为每个臂更新了奖励的估计值[插图],这就使它对环境的变化更为灵敏。不过,尽管EXP3在处理对抗性问题时表现良好,但由于EXP3不仅没有利用新闻场景点击率分布的时序特性,还引入了实际并不存在的对抗环境假设,因此在处理雅虎新闻场景时就没有B-UCB1表现理想了。实际上这也说明,如果一个经典算法不能适用于业务场景,那么一个朴素但适合业务的算法往往会有更好的表现。
-
7.2.3 让特征动起来的树模型7.2.2节中介绍的Laser模型通过让模型动起来,以分钟级的频率来完成对信号的捕获,本节中介绍的基于梯度提升决策树(gradient boosting decision tree,GBDT)的方案则通过让特征动起来,以秒级的频率实现对信号的近实时捕获。可以想象,这种方案奏效的关键在于,既需要特征侧能捕获信号的动态变化,也需要模型侧具备足够的表达能力。本节从GBDT模型的特点说起,介绍动态特征方案的细节。1.GBDT的模型特点由于logistic回归等模型不具备对浮点数特征足够强的表达能力,因此雅虎在引入实时动态特征的展示广告场景中选择了表达能力更强的GBDT。为了更好地理解为何选择树模型来捕获信号的动态变化,本节简要介绍GBDT的特点。(1)提升法(boosting)。监督学习中,偏差方差权衡(bias-variance tradeoff)描述的是,如果模型过于复杂,会因为对噪声过度敏感而导致高方差的过拟合问题,而如果模型过于简单,又会因假设错误而导致高偏差的欠拟合问题。为了找到平衡,集成学习是一种常用的方法,其中就包括GBDT所采用的提升法和各类算法比赛中常用的装袋法(bagging)。装袋法的思路是先找到一组低偏差且有差异的强学习器,再通过求平均值的方式来降低方差,在对性能没有要求的比赛中更常见。与之相反,提升法采用低方差的弱学习器,并通过串行的方式来逐步降低偏差,在性能开销较小的情况下更受业界的欢迎。(2)决策树。GBDT采用决策树这种弱学习器作为它的基模型,从而在一定程度上决定了GBDT模型的特性。首先,树模型可以看作一组易解释的规则集,通过特征重要度、SHAP等工具就可以方便地进行白盒分析。其次,不同于logistic回归等线性模型需要手工构造特征来提升模型的表达能力,树模型不仅擅长处理连续值特征,也可以自动进行特征选择和组合,所以使用GBDT模型通常并不需要借助太多的特征工程。(3)梯度。受启发于AdaBoost,GBDT也采用了前向逐步累加的迭代方式,只不过将弱学习器的优化目标从最小化加权分类误差率改为拟合之前加性模型预测结果的残差。GBDT中每棵树的训练主要包括如下3个步骤。● 步骤1:基于当前学习器的预测结果和实际值,求得损失函数下学习器的梯度下降方向,如公式(7.4)所示。[插图](7.4)● 步骤2:用一棵新的决策树来拟合梯度下降方向[插图],得到第[插图]棵决策树的参数,如公式(7.5)所示。[插图](7.5)● 步骤3:利用线搜索方法最小化损失函数[插图],以找到合适的梯度学习率权重,如公式(7.6)所示。[插图](7.6)2.基于GBDT特性的特征工程通过对GBDT特性的介绍可以看出,它在采用决策树作为基模型后,不仅具有了树模型可解释性强和对浮点数特征友好的优点,同时也引入了不擅长处理高维稀疏特征的缺点。所以,该如何发挥GBDT擅长处理动态特征的优势,
-
(1)集成多个弱学习器的信号,建模长尾个性化需求。由于GBDT擅长将多个专注于捕获不同模式的弱学习器互补地集成起来,因此可以先构建多个不同视角的子模型来捕获业务中的弱信号,再基于GBDT集成学习的特点,将这些弱学习器的输出综合为一个强学习器。以新闻推荐场景为例,我们可以先构建出一些表征用户和新闻长尾相关性的子模型,例如基于神经网络模型的语义相关性、基于统计信息的行为相关性等,再将这些模型输出的浮点数特征交给GBDT集成学习。(2)构造实时动态特征,建模新闻的实时信号。如果业务中确实存在很多高维稀疏特征,例如用户ID和新闻ID,还有一个简单的解决办法,就是当稀疏特征被触发时,不再将它本身作为特征,而是将它的点击次数、展示次数和点击率等统计量作为特征,这样就把高维稀疏的静态特征压缩成一个低维稠密的动态特征了。通过这种压缩方式,不仅使特征更适合GBDT处理,更关键的是,让特征动起来要比让模型动起来容易,这样就可以更灵敏地应对各种实时场景。以新闻推荐场景为例,可以将新闻ID特征转变为该新闻在不同时间窗口、不同人群下的各种实时统计量,再利用GBDT集成学习的能力来整合这些特征,就能取得比较好的效果。
第8章 获取信息的资讯推荐
-
8.1.1 对推荐产品崛起的迟钝相较于技术驱动的搜索而言,推荐系统更偏向产品思维,需要对用户需求的变化保持高度的敏感。尽管谷歌在技术上领先,但在产品和生态环节相对较弱,因此在移动互联网时代到来后,未能敏锐预见到推荐产品即将爆发的趋势。本节将简要回顾这一过程。1.移动端推荐产品崛起的趋势起初,包括谷歌新闻和雅虎新闻在内的PC端推荐产品,其变革的对象主要是传统报业。因此,从当年这些产品的视角看,对于在小小手机屏幕上打造的应用是否会冲击到PC端产品,他们是存疑的:用户真的会改变习惯,放弃阅读PC端大屏幕上的新闻推荐产品,转而在手机小屏幕上消费内容吗?事实上,从以下几个方面来推断,答案是肯定的。(1)用户在手机上消费需求的增加。手可以说是人类与外界交互时最灵活也最闲不下来的器官,再加上手机设计得足够便携,很容易使用户养成在闲暇时间使用手机的习惯。以中国互联网络信息中心发布的数据为例,到2022年底,不仅手机上网的用户数量达到了10.65亿,用户每周的在线时长也达到了26.7小时。(2)新闻内容不足以满足用户的全部需求。雅虎新闻的惨痛教训已经告诉我们,即使用户对新闻内容的需求永远存在,且雅虎的推荐算法做得也很不错,但毕竟新闻只是内容品类中的一小部分,因此,如果仅靠每天为数不多的新闻热点作为内容供给,新闻产品无法让用户停留太久。
-
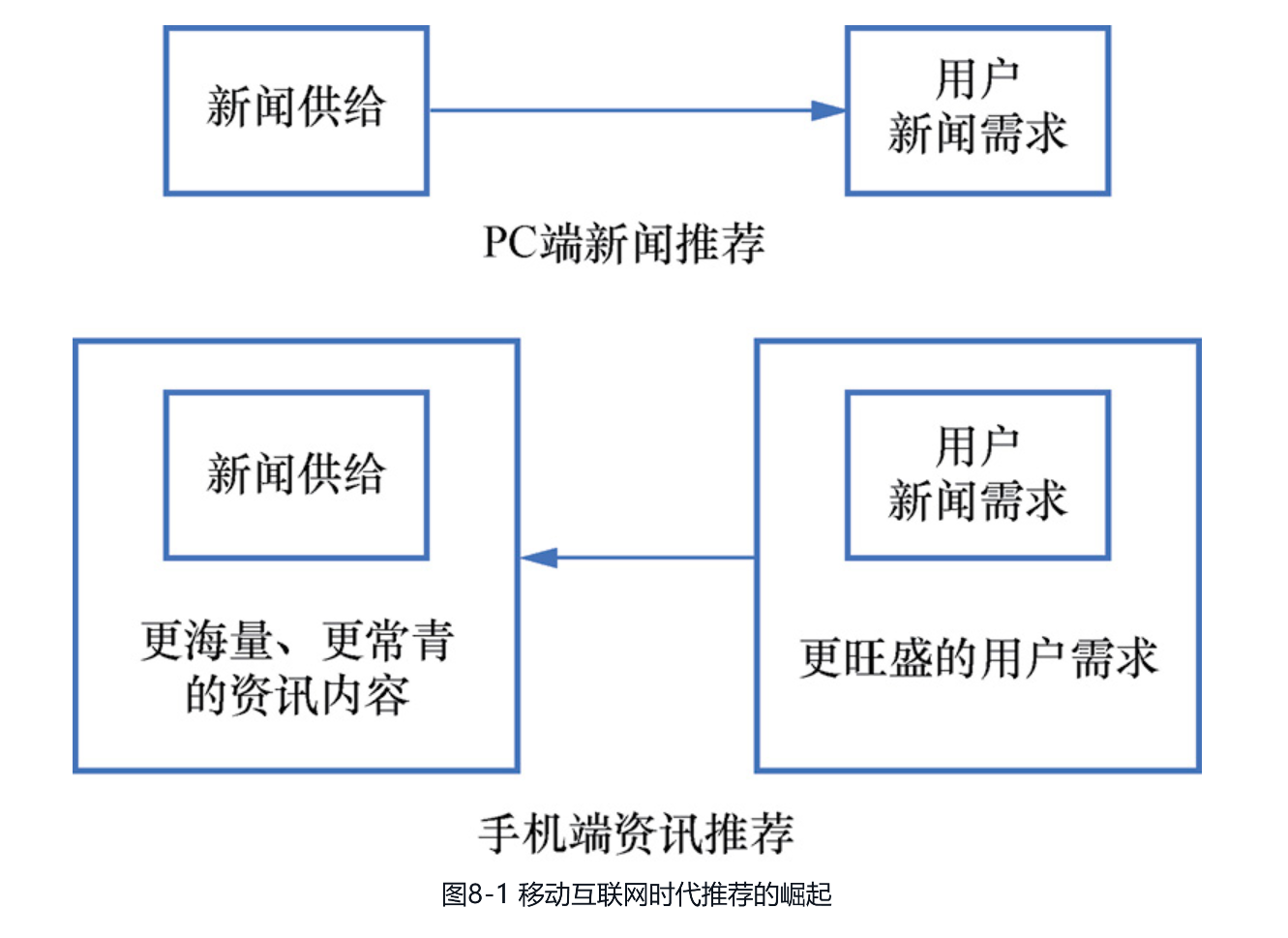
(3)需求增加倒逼供给侧变革。既然新闻无法满足用户在手机上的旺盛需求,那么势必会倒逼供给侧变革,例如,在用户使用手机相对放松的状态下,短微视频、图文结合等新的内容形式开始逐渐流行。一方面,这些消费轻松的内容对专业性的要求没新闻那么高,每个人都可以尝试创作;另一方面,这些内容又属于具有较长时效性的常青内容,所以在这两个因素的共同作用下,内容供给开始变得越来越丰富。总体来说,如图8-1所示,移动互联网时代不仅激发出了更旺盛的用户需求,也在供给侧催生了许多新媒介,这才使供需两端在大幅增长后,让推荐真正释放出它的价值。于是,像今日头条这类重视推荐的产品取代不重视推荐的传统新闻产品,也就成了时代发展的必然趋势。
-
一提到索引,大家常常想到倒排索引,但这已经是字面匹配时代的架构了。8.1.2节介绍了语义匹配的主流建模方法后,用户和内容都表示成了向量,这时面对动辄上亿量级的候选,该如何做到效果上接近于无损全库遍历,同时性能上满足在线的耗时要求呢?本节就来探讨近似最近邻检索(approximate nearest neighbor search,ANN检索)问题中3类主流的检索架构。1.基于树的ANN检索作为一家技术范的音乐推荐公司,Spotify并不希望用打标签加倒排索引的粗放方式来推荐音乐,而是希望利用深度学习模型来优雅地解决问题,于是,如何为用户向量高效地匹配音乐向量,便成了线上工程实践中一个关键环节。在多番尝试后,Spotify成功创新出了一种名为Annoy的树索引方式,并在2015年9月将它开源后,引发了业界对深度学习召回方向的研究浪潮。具体来说,Annoy的思路并不算太复杂,在建立索引时,Annoy首先会从待划分的空间中随机选择两个点,并以此生成一个将数据分为两部分的超平面。然后,在这个划分的子空间内进行递归迭代,直到数据被划分为一棵二叉树,其中底层叶节点存储原始数据,中间节点记录超平面信息。之后对索引进行查询就是一个从根节点不断往叶节点遍历的树查找过程了。在Annoy开源之前,业界主流的ANN检索算法主要是局部敏感哈希(locality sensitive hashing, LSH)等传统算法,Annoy作为一种通过空间层次划分来剪枝候选范围的树算法,由于相较于LSH方法具有以下两点明显的优势,因此一经开源就立刻受到了业界的广泛欢迎。(1)和数据分布更为契合。Annoy的空间划分方式是结合数据分布进行的,它在每一步都会结合数据分布来创建超平面,从而将数据均匀地分布在子空间中。LSH对空间的划分方式则是随机而独立的,和数据分布无关,所以可能会导致一些区域过度拥挤,而其他区域则完全空缺。(2)更精准的扩召回手段。即使两个点足够近,在分治时仍然有可能被错分开,所以各类ANN检索算法都会实现一些扩召回的策略。相较于LSH动辄需要增加[插图]个指纹来扩召回,Annoy通过全局优先队列的方式在多棵索引树下跨树选优,可以更好地平衡扩召回时的计算复杂度。2.基于图的ANN检索正如11.2.1节中将要介绍的,真实世界的很多网络都具有小世界网络(NSW)特性,即虽然整体的聚簇程度较高,但由于捷径和枢纽节点的存在,任意两点间的路径长度都比较短,因此真实世界里信息的传递速度才会比树结构快。那么可以想象,如果基于小世界网络来建立索引,可能只需要更少量的跳转就可以找到近邻了。那么具体该如何构建这种具有捷径性质的图索引呢?“Growing Homophilic Networks Are Natural NavigableSmall Worlds”一文给出了经典的NSW算法,它基于11.2.1节中BA模型偏好依附的原理,每次仅加入一个节点并让它和最近的k个点进行连接,从而让整个网络逐步生长。可以发现,在这种构建方式下捷径主要诞生在网络生长的早期,因为这时的节点还比较少,所以即使距离很远的情况下也更有可能会建立连接。2018年,“Efficient and robust approximate nearest neighbor search using Hierarchical Navigable SmallWorld graphs”论文提出了对NSW做改进的层次化NSW(hierarchical NSW,HNSW)算法,是迄今检索效率较高的ANN检索算法之一。如图8-11所示,HNSW在建立索引阶段会基于跳表的思想对
-
NSW做分层,然后在索引查询阶段按照图中箭头的方向,先在上层节点遍历到局部最小值,再逐层从该节点切换到较低层,直到在底层得到检索结果。显然,由于在顶层的图中HNSW节点更少,更容易产生能够快速接近目标节点的长距离捷径,因此检索效率就比NSW有了进一步提升。
第三部分 社交和社区推荐
-
第三部分 社交和社区推荐第三部分将探讨在满足用户需求的维度上与资讯推荐有本质区别的两种产品—社交推荐和社区推荐,以及在缺乏社交关系的场景中应如何通过协同过滤算法来模拟社交网络。(1)社交推荐(第9章)。人作为一种社会性生物,在社交时更追求归属感和认同感,而不仅仅是资讯推荐所带来的信息价值。而且,不同于人和内容的单向匹配,社交推荐更强调人和人之间的双向匹配。基于这两点核心差异,社交推荐和资讯推荐便存在本质上的区别。(2)社区推荐(第10章)。除了满足用户获取信息的需求和结交同好的社交需求,社区产品还可以通过激发用户的内容创作来满足用户自我实现的需求。因此,作为一种兼顾多元需求的产品,社区推荐在构建方式上和其他推荐产品有较大的差异。(3)协同过滤(第11章)。在从复杂网络视角讨论社交网络的特性后,将讨论如何在传统算法主导的推荐产品中更积极地引入人的智慧,从而在内容质量理解和优质内容传播等维度上实现更贴近社交推荐的效果。
第9章 永远年轻的社交产品
-
第9章 永远年轻的社交产品纵观社交网络的发展史,它几乎一直处在风口浪尖上,毕竟每个人都会老去,而年轻人又总想用上更流行的社交产品,因此新产品只要能洞察用户心理、找到差异并设法突围就有机会。这也正是社交赛道能一直保持活力的根本原因。本章将先整体介绍社交产品优化的关键,再以Facebook取代Myspace、Hinge与Tinder的差异化竞争为例,介绍社交推荐中产品和策略常见的优化手段。
-
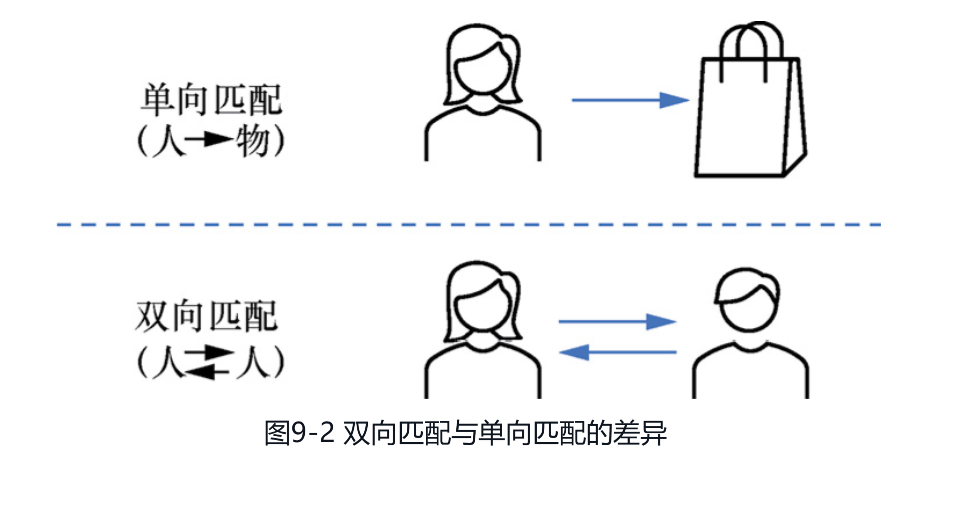
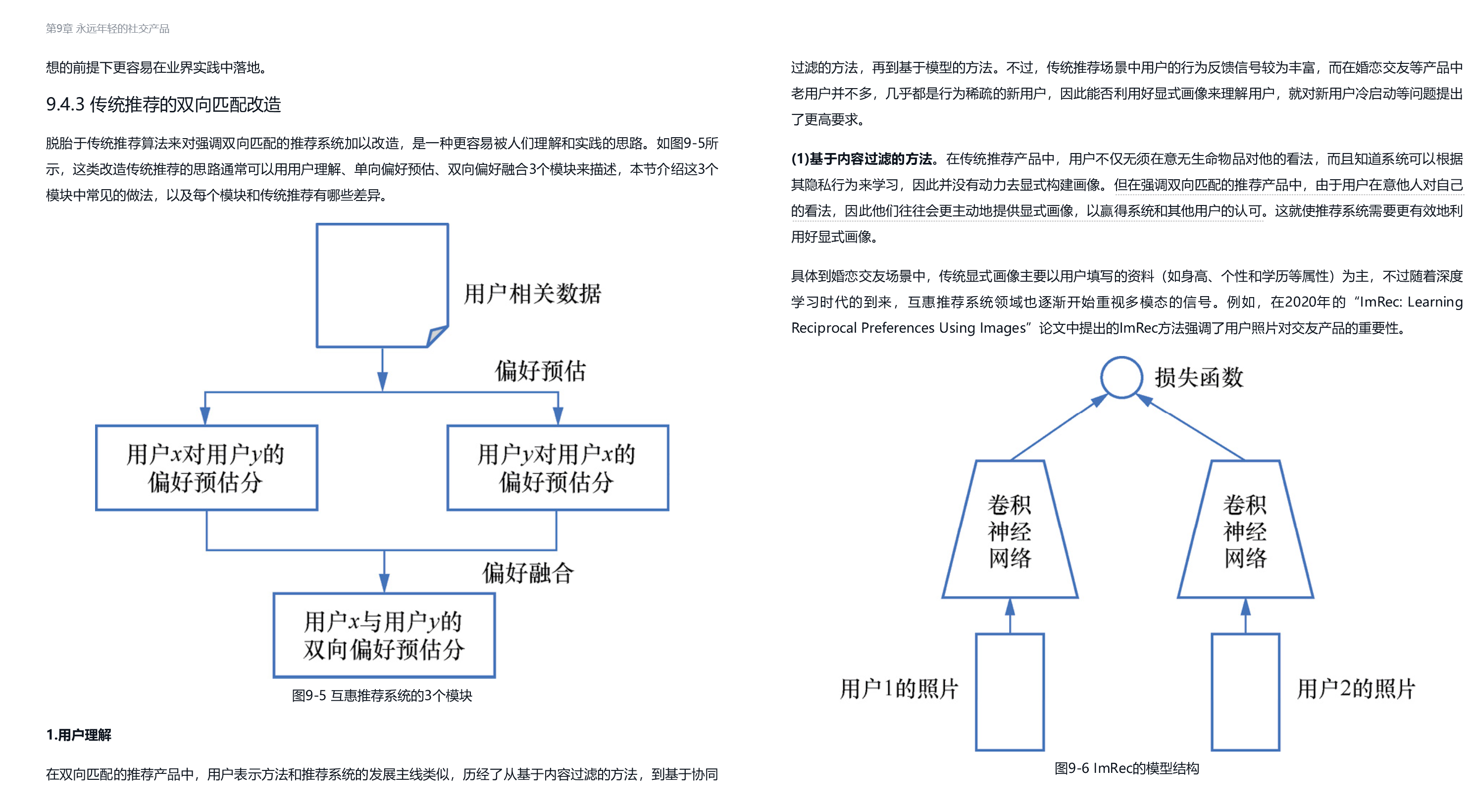
9.1 社交推荐中优化的关键社交产品对用户的效用主要分为两类,一类是体现社交产品核心价值的社交效用,即产品在帮用户维护社交关系,并赢得他人认同和尊重方面的价值,例如帮助用户设计炫酷的主页来展示自己,帮用户推荐其内容来赢得朋友的点赞;另一类是交流信息时所携带的内容效用,即产品帮用户获取信息、提升认知水平的价值,例如用户可以在朋友圈中浏览自己感兴趣的新闻资讯。本节将从这两类效用的视角出发,介绍优化社交产品的整体思路。9.1.1 强化社交效用时的原则如图9-1所示,社交产品中通常先有关系的建立,再有内容的交流来巩固关系,所以内容更多的是帮用户社交的辅助工具,而非产品的主要目标。于是,社交推荐就与以获取信息为目标的资讯推荐有了本质区别,这一区别主要体现在以下两点。[插图]图9-1 先有关系,再有内容的社交推荐1.提高社交效率,而非获取信息的效率资讯推荐的目标是帮助用户获取信息,而社交推荐的目标则是帮助用户获得社交资本,建立并维系社交关系。因此,与资讯推荐更加关注阅读时长、点击率等内容型产品指标不同,社交推荐更关注与关系建立和维系相关的社交产品指标。于是,体现到推荐算法和产品的设计理念上,就和人们所熟悉的传统信息检索范式有所不同。(1)产品设计:挖掘社交需求。从产品设计角度来看,要更深层次地满足用户的社交需求,就需要深入理解用户在社交时的需求,通常来说,这主要包括与他人建立和保持关系的情感交流需求,以及在社交环境中展示自己并获得影响力的竞争和自我表现需求。针对前者,产品应以强化用户间的参与和交流为目的来设计产品功能,例如提供表情包、神评等更加有趣的互动方式。针对后者,产品应设法提供让用户赢得点赞数等社交资本的机制和工具,并通过对社交资本的流动性刺激来避免社交资本的固化。(2)算法设计:强化社交效用。在社交产品中,人们为了获得社交资本常常会付出很大的努力,因此,在类似朋友圈这种兼具内容效用和社交效用的产品中,为了缓解用户在竞争彼此注意力时所带来的信息过载问题,就需要有高效的推荐算法来维持产品的社交效率。一种有效的策略是优先推荐亲密朋友的内容,以避免过于强调内容效用而走向媒体化,而关于这一策略具体的实现细节,将在9.4.1节中以Facebook的信息流推荐为例来进行探讨。2.双向匹配,而非单向匹配包括资讯推荐等很多场景的推荐都是一个从人到物单向匹配的过程,但在社交推荐场景中,无论是关系的建立还是维护,本质上都是一个双向匹配、双向奔赴的过程,如图9-2所示。在学术界中,一般会将这类问题称为互惠推荐(reciprocal recommendation),其产品理念在于,不仅要保证匹配双方都对结果满意,还要尽量帮助每个人都匹配成功。下面是两个典型的产品案例。
-
9.4.2 稳定婚配假设下的GS算法如9.3.3节所述,Hinge倾向于量化真实世界中的约会能否成功,而不是应用程序内的参与度,所以这一产品理念也体现在其所采用的推荐算法中。本节就来介绍Hinge在“最契合”(most compatible)功能中曾采用的推荐算法,以及在实践这一算法时的关键问题。1.GS算法简述稳定婚配问题(stable marriage problem)又被称为稳定匹配问题,它的问题描述是:在一个由相同数量的男性和女性组成的社区中,无法让每个人的配偶都恰好是其最中意的选择,所以希望能找出一种稳定的配对方案,使得不存在双方都觉得对方比原配好,进而各自丢下原配去重新配对。1962年,数学家David Gale和Lloyd Shapley对这个问题给出了一种被称为Gale-Shapley算法(GS算法)的解法。简单来说,这个算法的主要步骤如下。● 步骤1:在第一轮中,每位未订婚的男性都向他最喜欢的女性求婚,然后每位女性会接受她最喜欢的追求者,并与他暂时订婚,同时拒绝其他追求者。● 步骤2:在接下来的每一轮中,上一轮被拒绝的男性会在未表白过的女性中选择一个最中意的去表白,然后每位女性继续从中选择最满意的一个订婚并拒绝其他追求者。可以看出,这里的订婚是暂时的,它保留了已订婚女性在遇到更好选择时更换配偶的权利,因此GS算法也被称为延迟接受(deferred acceptance)算法。● 步骤3:因为订婚的暂时性,所以每轮过后都会有一些单身男性找到配偶,同时也会有已经订婚的男性重新变成单身,于是该算法一直迭代,直到所有的男性都被接受为止。通过如下方式,可以简单证明GS算法的结果是稳定的。首先,假设男士A和女士1各自有自己的配偶女士2和男士B,但双方都觉得对方比目前的配偶好,那么根据GS算法的逻辑,男士A肯定在之前向女士1表白过,所以如果女士1当时没有选择接受男士A,就意味着女士1认为男士B比男士A好,显然,这与结果矛盾,因此,证明了GS算法结果的稳定性。2.GS算法落地时的关键问题按照报道中Hinge的说法,由于在最契合功能的早期测试中GS算法显著提升了用户约会成功的可能性,因此GS算法后续就被应用在Hinge线上的主要模块中。不过由于Hinge并没有公开具体实现,这里根据个人理解来讨论在落地GS算法时的几个关键点。(1)如何获取用户偏好。GS算法是在已知用户偏好的前提下寻找稳定匹配的一种机制,所以,如果要想在实际业务中落地GS算法,还是需要优先解决如何知晓用户偏好的问题。对线上产品来说,由于用户不可能给平台主动提供排序,因此需要平台去训练一个表达用户偏好的模型。可想而知,如果预估的优化目标找错了或者不能预估准确,即使GS算法设计得再精巧也无济于事。(2)GS算法的在线复杂度。当有了用户的偏好模型后,把预测模块嵌入GS算法的机制流程里,就可以在不引入用户的情况下让平台先帮用户来度过糟糕的约会了。不过需要注意的是,在参与者数量巨大的场景中,通过一轮轮迭代的GS算法的复杂度比较高,所以需要结合产品特性进行相应处理以降低在线计算的复杂度,例如将用户按城市和偏好来分组。(3)如何处理匹配的不平等。虽然GS算法能得到稳定的匹配解,但稳定并不意味着完美,例如大家可能会觉得,男性追求女性的方案是不是对女性更有利呢?事实上,这种方案是在稳定的前提下对女性最为不利的方案,其原因在于,作为主动方的男性是按其偏好顺序来进行表白的,而女性总是在被动地接受,所以随着迭代轮数的增加,男性会通过逐渐降低自己的要求来逼近他能追求到的女性的上限,那么对女性来说就不公平了。
第10章 春耕秋收的社区产品
-
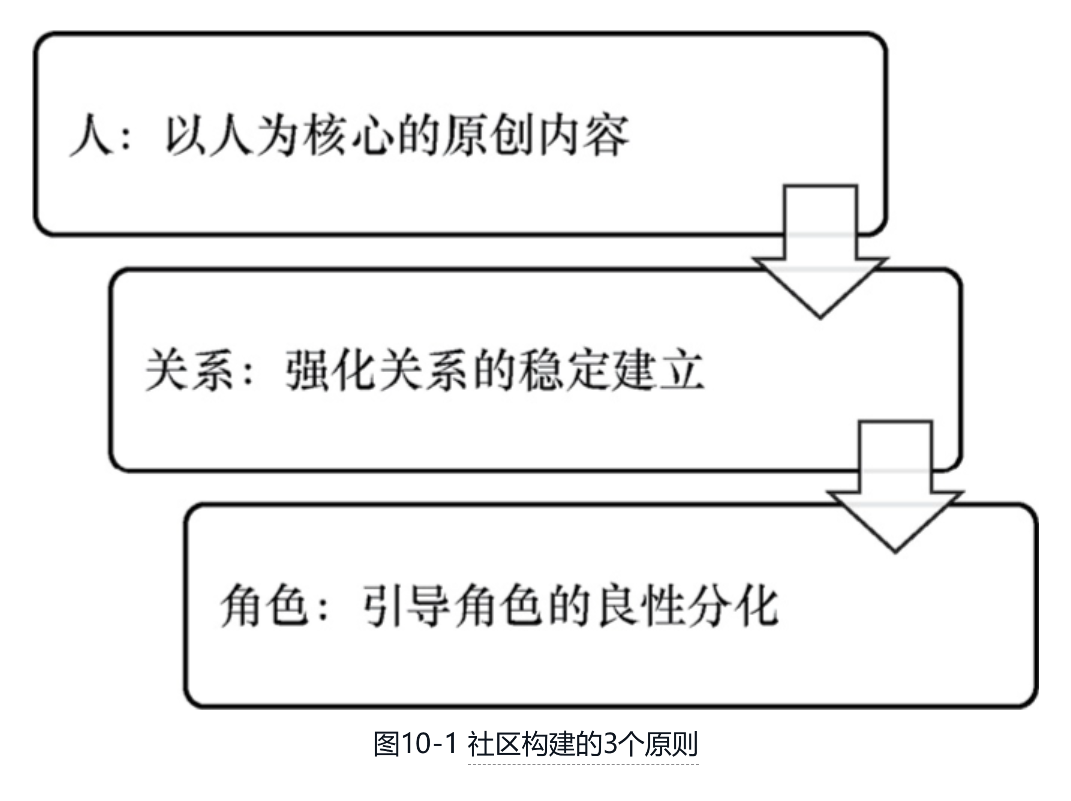
第10章 春耕秋收的社区产品虽然很多垂类如今已经是社区型产品在主导,例如虎扑取代了新浪体育,小红书取代了导购媒体等,但这些社区产品的成长过程大多有一个共性,即在耕耘了很多年之后才厚积薄发。因此,对很多急着从媒体向社区转型的产品来说,还是需要认真理解本章的内容,以了解社区产品需要耐心经营的原因及差异化的推荐方法。10.1 社区产品的培育原则社交产品中先有社交关系的建立再有内容的交流来巩固关系,社区产品则正好反过来,它是先有优质的内容创作者再有关系的建立来激励创作。这一差异决定了社区产品和社交产品的根本不同,即社区产品中最宝贵的资产是内容的创作者,所有强化关系的手段本质上都是为了服务好创作者而存在的。因此,社区从一个只具有内容效用偏媒体向的产品,逐步构建出关注关系和社区角色,并发展为一个兼具内容效用和社交效用的产品,确实需要时间和耐心,事实上,这也是本章标题中“春耕秋收”的原因。为了能在漫长的过程中确保产品方向不走偏,本节将重点介绍图10-1所示的3个原则,以避免产品陷入急功近利的误区。
-
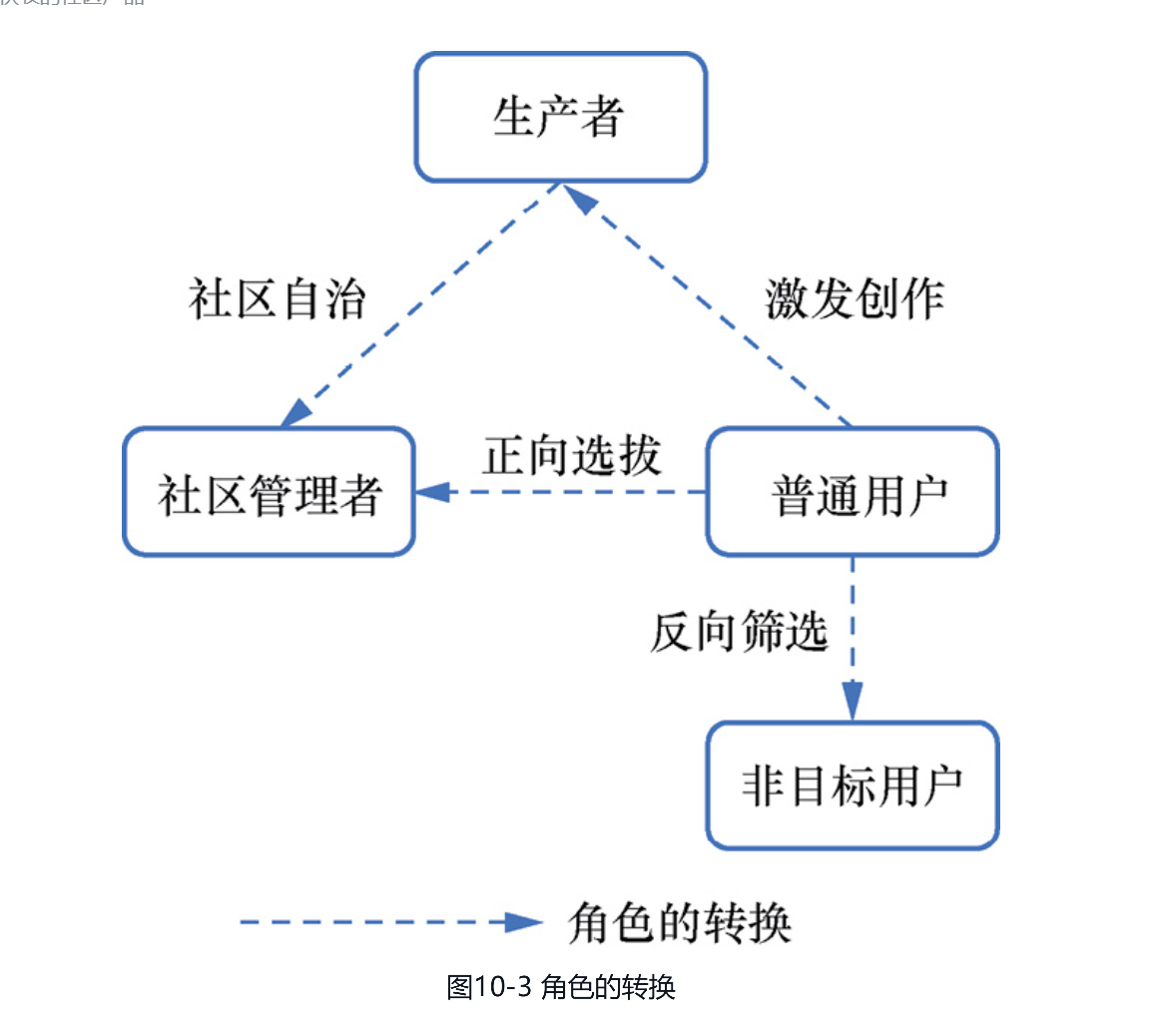
10.1.3 引导角色的良性分化PC时代的产品只需建立与其他产品交换价值的超链关系就能在开放生态中生存下来,移动互联网时代由于产品缺乏超链,它们就像被封闭在孤岛上,因此只有设法实现自给自足的生态,才能得以安全地生存。实现生态自我循环的关键就在于,产品能培育出多种不同的生态角色。本节将探讨在社区产品中引导角色良性分化的两种机制。1.显性的角色塑造机制自然生态系统中角色在短时间内固定,例如生产者不会突然转换为分解者,分解者也不会突然转换为消费者,而用户产品的角色通常由用户偏好所决定,因此在适合的产品机制的引导下,就可以将普通用户转换为其他各类角色,如图10-3所示。接下来具体讨论几类角色转换的产品手段。
-
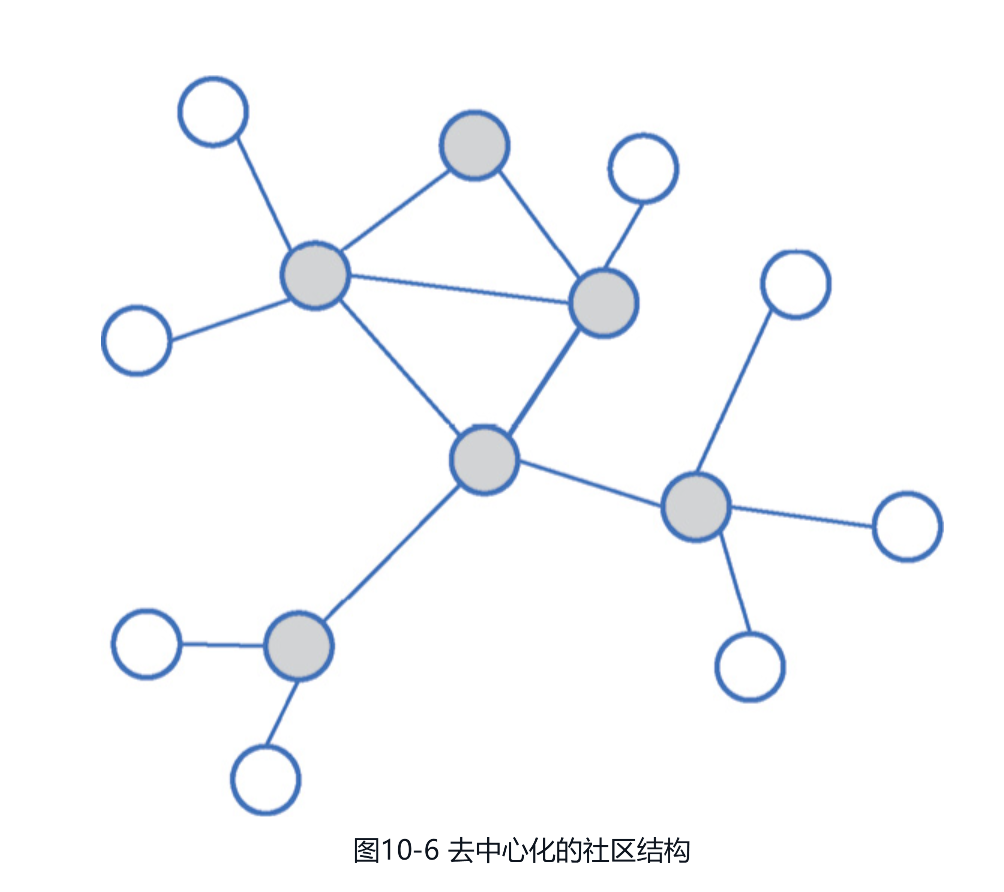
2.更弹性的角色生长机制虽然上文介绍的显性的角色塑造机制看似巧妙,且效果通常会比较显著,但常常容易出现一个问题,即社交资本(如社交货币、关注数、管理者权限等)一旦被发放,就难以被有效收回,于是随着时间的推移,不少老社区在激励新用户的能力上大为减弱,进而引发社区老化和扩张乏力等问题。为了提早规避这类问题,出现了比显性角色塑造机制更为理想的更具弹性的角色生长机制,这类机制的目的在于促使社区演化出图10-6所示的去中心化的社区结构,并通过去中心化结构的以下两点特性来避免日后出现社区老化等问题。[插图]图10-6 去中心化的社区结构(1)看似松散的包容性。因为去中心化的社区看似没有中心,所以社区文化通常会更为多元化和具有包容性,从而在避免社区氛围老化的前提下,可以更好地激励新用户去赢取社交资本,进而实现社区的扩张。(2)实则鲁棒的张力。虽然去中心化的社区看似结构松散,没有明显的强中心,但也有很多图10-6中所示的灰色节点表示的弱中心在维持社区秩序。这样,在每个用户都能被社区影响后,就使社区具备了形散而神聚的自组织能力,不容易出现社区氛围老化等问题。那么,具体该如何演化出这种具有去中心化结构的社区呢?其实,考虑到社区老化的根源在于马太效应,首先,需要有意识地通过平权分发来激励潜在角色的生长;其次,不断监测并调整运营策略,以激活社交资本的流动性。接下来,介绍两种可能的策略,更具体的细节还需要结合产品的特性和现状来设计。● 基于策略手段生长。闻道有先后,如果后进入者更适合承担产品中的关键角色,就可以设计出一种能将其选拔出来的优化目标,并通过强化该目标来隐性地给予扶持。同时在过程中也需要根据反馈来持续调整,以激发社区的活性。例如,在作者粉丝数和用户关注数较少时更强调关注率,以缓解马太效应,并确保新作者和新用户能融入到社区中。● 基于运营手段挖掘。如果产品在运营时能快速分辨出社区中的关键用户,那么在社区扩张等特殊时期就可以临时赋予其一定的影响力,并在运营诉求完成后回收影响力。可以想象,这类手段对运营的要求会比较高。当有了从普通用户中涌现出来的关键角色后,考虑到他们要么是领域专家,要么具有比较强的人格魅力,社区借助他们的影响力去以点带面地发力运营,通常可以更高效地维持社区运营的效率,下面给出两种可能的策略供参考。● 基于运营手段来经营。与其通过强硬的管理手段来管理用户,不如通过标杆用户的示范作用来影响用户。例如设法提供一定的激励手段,让普通用户了解社区鼓励什么样的行为,通常就可以润物细无声地影响普通用户的行为了。● 基于策略手段来强化。在机器学习模型中,通常会等权重地看待每一条用户样本,所以如果想强化关键角色的自治作用,就可以设法强化关键角色样本在学习过程中的权重,以影响模型的推荐偏好。
-
10.2.3 从创作工具向社区转型如果仅做好滤镜技术和创作路径,Instagram只能算是一个在Facebook等平台上分享照片的好用工具。考虑到工具容易被取代,Instagram逐步向社区方向转型,通过让用户在Instagram中获得关系连接和社区认同而留存。本节将介绍Instagram在向社区转型的过程中所采用的3种具体方法。1.做减法,去掉转发的原创生态在Instagram刚开始发展的时候,人们总是将它和Twitter进行对比,并劝说Kevin Systrom增加一个转发按钮,这样,优质的内容就更容易在短期走红。不过Kevin Systrom却洞察到,转发会分流本该属于创作者的社交资本,这对于生态中真正优质的原创作者不公平,因此并没有采纳这个建议。于是,不同于其他社区中用户经常被八卦新闻和时事热点所打扰,Instagram为那些更适应点赞和关注机制的小而美创作者争取到了更好的生存和发展空间。所以,虽然从短期来看去除转发功能弱化了社区氛围,但从长远来看,这种去繁就简的发展哲学显然更为健康,值得很多贪多求全的产品借鉴。2.通过互动来强化关系的建立传统UGC产品如贴吧和Reddit等,通常会采用按主题来硬分流用户的模式,这虽然在一定程度上保护了社区氛围,但也使产品被拆分成了一个个孤岛,不仅难以提升用户和创作者间关系建立的效率,也难以形成产品整体的网络效应和社区文化。于是,Instagram采用了和Facebook类似的信息流推荐模式,以促成用户和创作者间更多关系的建立。在选择推荐算法的优化目标时,考虑到抓用户新鲜感的点击信号难以为创作者沉淀更稳定的社交资本,Instagram倾向于将关注和点赞等互动信号当作算法的优化目标。随着关注数逐渐成为平台上社交资本的象征,人们开始更加积极地争相创作,Instagram生态的繁荣也就不难理解了。3.摄影师们的示范性创作Kevin Systrom对于滤镜的最初灵感就是从模拟照片显影技术中获得的,因此他设计出来的滤镜自然更容易受到摄影师们的喜爱,例如,一位喜欢哈苏相机的摄影师Cole Rise就是Kevin Systrom的忠实用户,他不仅发自内心地认可滤镜功能,让Kevin Systrom意识到了滤镜的潜在价值,之后还帮助Instagram设计了很多滤镜。从10.1.3节中借助标杆用户的示范作用来运营社区的角度看,摄影师这个群体作为产品的关键用户是非常合适的,因为对一种全新的媒介来说,无论从技法上还是从情感和视角上,都需要有人能手把手地指导用户来创作,而摄影师正好非常善于“用图片讲故事”。因此,Instagram在挑选产品的种子用户时邀请了很多在Twitter上有大量关注者的优秀摄影师,这才让Instagram得以在众多功能相似的产品中脱颖而出。综上,不难看出,Instagram所采用的社区培育思路与10.1节介绍的构建社区的3个原则是高度一致的。事实上,小红书、bilibili等社区都采用了相似的思路,这里不再详述。
-
大多数推荐产品会基于复杂算法来整合反馈信号,这样虽然信息获取效率高,但也容易陷入反馈闭环所形成的信息茧房中。于是,Reddit为了更能表达出当下的潮流和用户群体的偏好,采用了简单健壮的投票机制。本节就简要介绍这类机制的特点。1.强化反对票的社区自治从社区产品保护创作者的角度看,创作者只需要喜欢他的受众,因此,如今很多产品都奉行点赞文化,要么只在一个很深的入口提供点踩功能,要么干脆只提供点赞功能。然而,如果在内容质量良莠不齐的产品中不允许负反馈,其实错失了阻断网络负外部性的合理时机,于是Reddit设计了一个投票功能,如图10-10所示,通过将投票数设定为点赞数和点踩数的差值,巧妙隐去了点踩数,这样就在阻止低质量内容传播的同时,避免了对创作者积极性的打击。[插图]图10-10 Reddit的热门页投票功能示意2.强化集体智慧的投票排序投票作为一种综合多个用户偏好以形成最终决策的机制,在政治、经济等众多领域中有广泛的应用。对社区产品来说,由于投票不仅能缓解算法过拟合所导致的信息茧房,也使社区易于形成大众喜闻乐见的氛围,因此常常被应用在热门内容的排序中。从图10-10中就可以看出,Reddit的热门页中以鼓励大众参与讨论的接地气的内容为主。虽然不清楚Reddit目前具体的实现细节,但在Reddit曾经开放的源代码中可以看到它之前的实现方式。以热门页排序为例,在点赞数[插图]比点踩数[插图]多的情况下,Reddit的排序实现如公式(10.1)所示:[插图](10.1)不难看出,这个公式基本上以投票信号为主导。虽然公式初看上去非常简单,但由于把握住了以下3个关键的产品特性,因此整体看体现的是一种比较健壮的机制。(1)避免争议。让点赞数upvote减去点踩数downvote,这对获得大量赞成和反对意见的有争议的话题会具有重大影响,因为它们的排名通常会比仅获得点赞数的话题靠后,这样就弱化了有争议的话题所带来的运营风险,也减少了网络霸凌现象的发生。(2)弱化马太效应。通过采用以10为底的对数变换手段,较早的投票相较于较晚的投票就会更具分量,例如,前10票的权重与第11至第101票的权重是相同的。这样,由于后来选票的价值越来越小,因此避免了持续积累权重的马太效应,从而使用户有持续发新帖的动力。(3)保持时效性。公式(10.1)中的第二项旨在帮助最近发帖的得分高于以前发帖的得分,其中date是帖子发布的时间,而1134028003是Reddit开始运行的时间,即2005年8月12日上午7:46,45000则是12.5小时对应的秒数,意思是每当时间流逝12.5小时,帖子得分就会减少1分。综上,Reddit在即将到来的爆炸性话题与稍旧但仍流行的话题之间取得了平衡,例如,如果要使一篇3天前发布的文章的排名比刚发布的文章靠前,它的投票数就必须超过近60万,这样对于那些一定时间内存在争议的帖子来说,不太容易被排到前面,因此避免了Reddit成为一个激进、偏少数派想法展示的平台。3.灵活配置的多种排序方式正如社会选择理论中孔多塞悖论(Condorcet paradox,也称投票悖论)和阿罗不可能定理(Arrow’s
-
impossibility theorem)所揭示的,其实并不存在一个能完美满足所有用户个体偏好的群体决策方法,因此,与其讨论如何设计一个完美的投票机制,倒不如多提供几种不同的投票机制。如图10-11所示,Reddit在基于算法排序的Best(最佳)方式外,开放了包括Hot(热的)、New(新的)、Top(历史头部)、Controversial(有争议的)和Rising(有潜力的)等多种排序方式供用户选择。
第13章 和电视竞争的短视频推荐
-
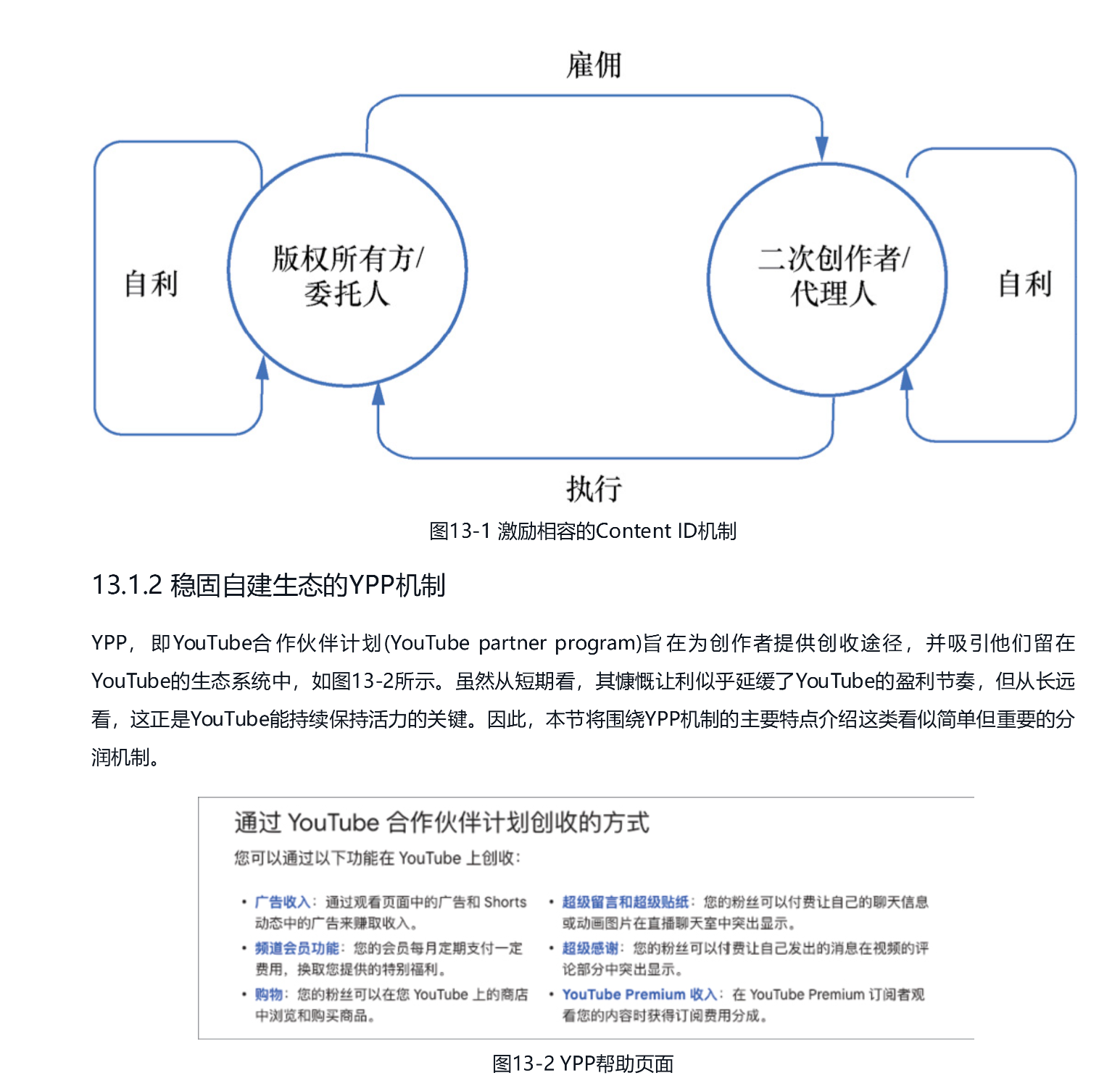
13.1.2 稳固自建生态的YPP机制YPP,即YouTube合作伙伴计划(YouTube partner program)旨在为创作者提供创收途径,并吸引他们留在YouTube的生态系统中,如图13-2所示。虽然从短期看,其慷慨让利似乎延缓了YouTube的盈利节奏,但从长远看,这正是YouTube能持续保持活力的关键。因此,本节将围绕YPP机制的主要特点介绍这类看似简单但重要的分润机制。[插图]图13-2 YPP帮助页面首先,YPP机制的显著特点在于其高比例的广告分润,不夸张地说,尽管如今广告分润的模式已经屡见不鲜,但大
-
多数内容平台提供的分润方式没有YouTube那么有诚意,这才使YouTube的内容生态成了抵御风险的强大屏障。根据YPP帮助页面中提供的信息,YouTube主要的收益分润方式有以下两种。● 观看页创收模块。观看页广告通常在视频的播放前、播放中和播放后阶段展示,极适合投放与视频内容高度相关的精准广告,再加上13.1.3节将介绍的TrueView机制的加持,使得该模块具有很高的变现效率。此外,由于这部分收入可精准归因到特定的创作者,因此当YouTube将55%的广告净收入慷慨回馈给创造这部分收入的创作者时,立即赢得了创作者的理解和信任。● Shorts创收模块。类似于许多图文或微视频产品,Shorts中的广告位通常穿插在内容之间,所以无法准确归因到某个创作者。不过,与很多无法归因时就选择少给创作者分润的产品不同,YouTube仍然按观看时长和次数等的占比来大致归因,并慷慨地将其中45%的广告净收入回馈给创作者。其次,除广告变现模式外,YouTube还提供了诸如关注者付费、电商、Premium收入等多种变现方式,其中每一种变现模式都会从创作者的角度来考虑。以运营用户的Premium模式为例,虽然Premium会员用户多了之后,创作者的广告收入会有所降低,但YouTube仍会按观看时长归因,以将Premium会员收入以高比例分配给创作者,所以这种模式并不会对创作者产生不利的影响。综上可以看出,创作者在YouTube平台上的回报还是不错的,所以即使TikTok等新兴平台不断涌现,创作者和为其提供协助的MCN机构(multi-channel network)也不愿放弃YouTube这个高回报率且经营多年的平台,这才使YouTube在面对如TikTok这样的关键竞争者时,仍有足够的时间去补齐其他方面的短板。
第16章 真金白银的电商推荐技术
-
在这一生态理念下,GMV已经不再是电商产品最关键的优化目标,而成交量往往会更关键。举例来说,让用户购买10件50元的商品所产生的价值高,还是购买1件1000元的商品的价值高呢?事实上,只要这10件商品可以给用户留下平台商品物美价廉的印象,那么答案就是前者。因为当用户对平台产生信任后,待日后再消费其他高价商品时,就有可能倾向于选择该平台。因此,推荐算法具体该如何做也就很清晰了,那就是弱化传统电商产品对短期GMV优化的依赖,在多目标的权衡中更重视对成交量的优化,并借此来撬动用户留存的提升。于是,商业产品和用户产品的推荐技术在这一刻便殊途同归了,即首要关心的目标并不是在内容供给和用户需求不变时通过优化供给和需求的匹配效率以提升产品当下的规模,而是以用户、创作者和商家为本,通过优化他们的体验和留存来提升产品未来的潜力。
来自微信读书
于是,这一趋势开始让很多人认为,随着技术的创新,AI终将从辅助人类创作转变为替代人类创作。
然而从我个人视角来判断,虽然AIGC可以使创作变得更加高效,但是如果以AI为主体来进行创作,恐怕并不能使人们产生真正的共情。毕竟,内容的价值在很大程度上取决于它与人类情感的连接,而这并非是技术能完全决定的。
不过问题的关键在于,即便在人们知晓某一作品是由AI创作后就立刻使它失去流行的可能性,随着AIGC技术逐渐掌握人类情感的表达方式,又有多少人能轻易分辨出内容的真伪呢?所以,AIGC技术在大众领域的传播可能已经呈现出不可阻挡的趋势,它并不会轻易受到我所在意的艺术原真性的影响。
因此,在智能客服、智能问诊、数字人等机构化的服务行业中,尽管AIGC技术还做不到在全流程上取代人工,例如数字人还不足以完成口红试色等任务,但在规则性较强的局部环节势必会替代人,整体以人机协同的方式来提供服务。
考虑到创新的一大特点在于,不被人注意时才更可能成功,所以在人人都关注大模型的时代,只有找到他人不选择走的路,才能通过避免同质化竞争获得长远发展。(卖铲的?)
既然仅基于注意力的Transformer能够取代CNN和RNN,那么,将CV和NLP的模型迁移到Transformer上就成为一个趋势。当Transformer在NLP领域提出后,在CV领域也出现了不少Transformer的实践
北大硕士真是商业、心理、哲学、语言、算法,真是啥都会。
主动、被动(流媒体,推流),过去P[B之类系统的交互设计本质都是搜索


 浙公网安备 33010602011771号
浙公网安备 33010602011771号