《企业网络安全建设最佳实践》读书笔记
企业网络安全建设最佳实践
张敬;李江涛;等
本书是“奇安信认证网络安全工程师系列丛书”之一,全书采用项目式、场景式的知识梳理方式,在目前网络安全背景下立足于企业用人需求,以办公网安全、网站群安全、数据中心安全、安全合规及风险管理四大模块构建完整的知识体系。
本书分为4篇。第1篇“办公网安全”,内容包含初识办公网、网络连通性保障、防火墙和访问控制技术、上网行为管理及规范、域控及域安全、恶意代码及安全准入、远程办公安全、无线局域网安全及安全云桌面等。第2篇“网站群安全”,内容包含网站和网站群架构、网站群面临的安全威胁、网站系统的安全建设及安全事件应急响应等。第3篇“数据中心安全”,内容包含数据中心架构、数据中心面临的威胁、数据中心规划与建设、数据中心安全防护与运维,以及数据中心新技术等。第4篇“安全合规及风险管理”,内容包含思考案例、项目、风险评估、等级保护、安全运维、信息安全管理体系建设及法律法规等。
本书可供网络安全工程师、网络运维人员、渗透测试工程师、软件开发工程师,以及想要从事网络安全工作的人员阅读。
没有网络安全,就没有国家安全;没有网络安全人才,就没有网络安全。
2016 年,由中央网信办、国家发展改革委、教育部等六部门联合发布的《关于加强网络安全学科建设和人才培养的意见》指出:“网络空间的竞争,归根结底是人才竞争。从总体上看,我国网络安全人才还存在数量缺口较大、能力素质不高、结构不尽合理等问题,与维护国家网络安全、建设网络强国的要求不相适应。”
网络安全人才的培养是一项十分艰巨的任务,原因有二:其一,网络安全的涉及面非常广,至少包括密码学、数学、计算机、通信工程、信息工程等多门学科,因此,其知识体系庞杂,难以梳理;其二,网络安全的实践性很强,技术发展更新非常快,对环境和师资的要求也很高。
在新时代网络安全环境下,奇安信提出并践行了网络安全的“44333”架构,即四个假设、四新战略、三位一体、三同步和三方制衡。
“四个假设”是假设系统一定有没被发现的漏洞、假设系统一定有已发现漏洞但没打补丁、假设系统已经被黑、假设一定有“内鬼”,这彻底推翻了传统网络安全中隔离、修边界的技术方法。
“四新战略”是指以第三代网络安全技术为核心的新战具、以数据驱动安全技术为核心的新战力、以零信任架构为核心的新战术、以“人+机器”安全运营体系为核心的新战法。“三位一体”是高、中、低三位能力立体联动的作战体系,低位能力相当于一线作战部队,中位能力相当于指挥中心,高位能力相当于情报中心。
“三同步”是指网络安全建设要与信息化建设同步规划、同步建设和同步运营,提供的是从顶层设计、部署实施到运营管理的一整套解决方案。
“三方制衡”是将用户、云服务商和安全公司放在一个互相制约的机制下,第三方安全公司负责查漏补缺,对云服务商形成有力制衡,在最大程度上杜绝漏洞和安全隐患,真正实现长治久安。
为落实网络安全人才的培养,奇安信相继在绵阳、青岛、苏州等地成立了人才培养基地,致力于培养具备实战能力的信息安全工程师,并将这些工程师输出到对网络安全运营服务人才需求迫切的党政机构、军工保密单位及广大企事业单位,在人才培养和用人单位之间形成闭环,为补上网络安全行业的人才缺口、提升网络安全能力贡献力量。
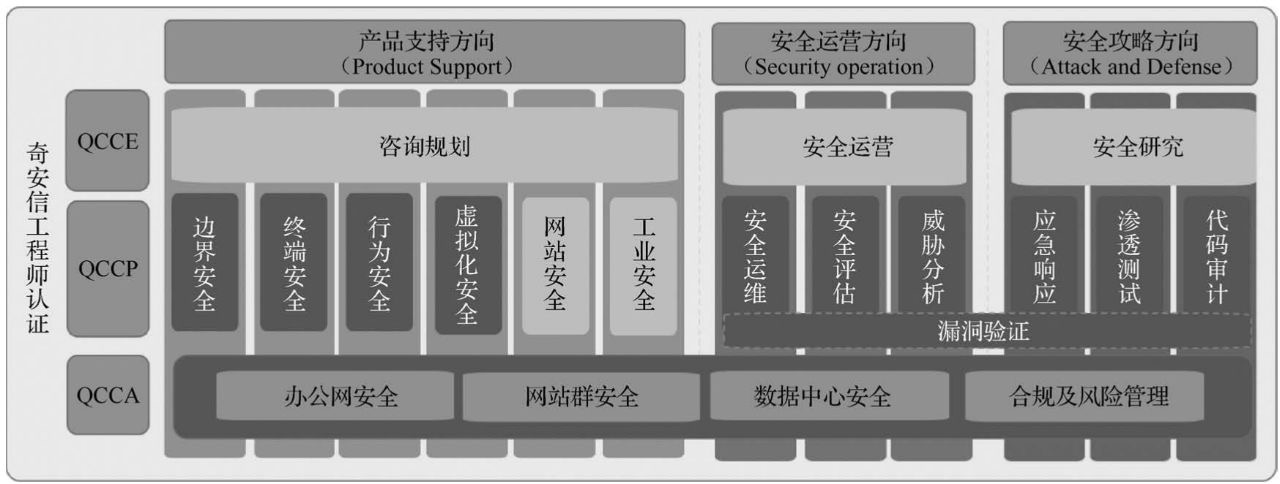
奇安信凭借多年网络安全人才培养经验及对行业发展的理解,基于国家的网络安全战略,围绕企业用户的网络安全人才需求,设计和建设了网络安全人才的培训、注册和能力评估体系—奇安信网络安全工程师认证体系(见下图)。
第1篇“办公网安全”,内容包含初识办公网、网络连通性保障、防火墙和访问控制技术、上网行为管理及规范、域控及域安全、恶意代码及安全准入、远程办公安全、无线局域网安全及安全云桌面等。
第2篇“网站群安全”,内容包含网站和网站群架构、网站群面临的安全威胁、网站系统的安全建设及安全事件应急响应等。
第3篇“数据中心安全”,内容包含数据中心架构、数据中心面临的威胁、数据中心规划与建设、数据中心安全防护与运维,以及数据中心新技术等。
第4篇“安全合规及风险管理”,内容包含思考案例、项目、风险评估、等级保护、安全运维、信息安全管理体系建设及法律法规等。
本篇旨在帮助读者理解以下概念。
1.初识办公网
● 网络及办公网的概念、网络的类型、网络的传输模式、网络的通信类型;
● OSI七层模型及每层的作用;
● 详解TCP/IP,重点掌握IP及子网掩码划分,以及TCP;
● 主机与主机间的通信原理。
2.网络连通性保障
● 路由及静态路由配置;
● 交换网络,VLAN及Trunk的相关知识;
● 网络地址转换技术;
● 实现办公网连通性建设。
3.防火墙和访问控制技术
● ACL访问控制技术;
● 防火墙及防火墙的部署配置。
4.上网行为管理及规范
● 上网行为识别技术;
● 上网行为控制技术;
● 上网行为管理产品的部署及配置。
5.域控及域安全
● 工作组和域;
● 活动目录相关知识;● Windows域的部署。
6.恶意代码及安全准入
● 恶意代码的分类及危害;
● 恶意代码防范技术,包括分析技术、特征码检测、完整性检测等;
● 企业版杀毒软件的部署及配置;
● 安全准入技术,包括802.1x、DHCP、网关型准入、ARP准入、Cisco EOU准入、H3C Portal准入。
7.远程办公安全
● VPN概述,包括L2VPN(二层VPN,如PPTP、L2TP)、L3VPN(三层VPN,如IPSec VPN、GRE VPN、MPLS VPN)、应用层VPN(如SSL VPN);
● 密码学的发展历程,包括古代加密、古典密码、近代密码、现代密码;
● 密码学技术,包括对称密码、非对称密码、混合加密、数字摘要和数字签名;
● VPN技术,包括GRE隧道、IPSec VPN、SSL VPN。
8.无线局域网安全
● 无线协议,包括802.11、802.11B.802.11B.802.11g、802.11n、802.11ac;
● 无线认证与加密,包括WEP、WPA.WPA2等;
● 企业办公无线,包括AP、AC.POE设备;
● 无线安全,包括无线的破解、无线安全部署。
2.办公网概述
办公网是计算机网络的商业应用,企业为了更加有效地办公,自行建设公司内部的计算机服务系统,将所有的办公计算机和系统进行连接,实现统一管理、文件共享等目标。例如,公司为每个员工配备计算机,员工使用这些计算机编写文档、设计产品等,完成后在公司内部的办公网络中自由地传输。在企业网中存在的最大问题是资源共享,资源共享的目的是让企业中的任何人都可以访问相应的程序、设备或数据。在公司中员工可以共享打印机的使用,这不仅降低了公司的花费,而且使打印机更容易维护。
有些企业的全部员工都集中在一个办公区域,而有些公司的员工分散在不同的办事处和工厂中,如上海的销售人员有时候需要访问北京的销售系统。这时就需要为企业办公网引入“虚拟专用网”(Virtual Private Network,VPN)的网络技术,将不同地点的网络连接成一个虚拟的内网。
2.1.2 网络的类型
1.按照网络规模分类
网络按照网络规模分类可分为广域网、城域网、局域网(校园网属于局域网)3 种,如图2-3所示。
图2-3 广域网、城域网、局域网
1)广域网
广域网(Wide Area Network,WAN)又称外网、公网,是连接不同地区局域网或城域网计算机通信的远程网。通常跨接很大的物理范围,所覆盖的范围从几十千米到几千千米,它能连接多个地区、城市和国家,或横跨大洲提供远距离通信,形成国际性的远程网络。
现在很多人认为互联网即广域网,需要注意的是,广域网和互联网并不是等同的,二者所包含的网络规模和范围都没有特定的要求。互联网上的计算机可以位于世界上的任何地方,即使天各一方、相距万里,也可以通过互联网进行通信互联网可以看作使用广域网将多个局域网连接起来形成的网络。
2)城域网
城域网(Metropolitan Area Network,MAN)的范围可覆盖一个城市。一般采用具有有源交换元件的局域网技术,传输时延较短,其传输媒介主要采用光缆,传输速率在1Gbps 以上。城域网作为城市范围的骨干网,将整个城市不同地点的主机、业务系统及局域网连接起来。
3)局域网
局域网(Local Area Network,LAN)是一种私有网络,一般在一座建筑物内或建筑物附近,如家庭、办公室或工厂。局域网被广泛用来连接个人计算机和消费类电子设备,使它们能够共享资源(如打印机)和交换信息。当局域网用于公司时,就被称为企业网络。局域网可分为小型局域网和大型局域网。小型局域网是指占地空间小、规模小、建网经费少的计算机网络,常用于办公室、学校多媒体教室、游戏厅、网吧,甚至家庭中的两台计算机也可以组成小型局域网。大型局域网主要用于企业 Internet 信息管理系统、金融管理系统等,同时负责大量终端计算机接入网络,从而构成企业办公网。
2.按照使用者分类
1)公用网
公用网是指电信公司/电信运营商(国有或私有)出资建造的大型网络,如联通、电信、移动提供的宽带、手机网络等,我们日常上网大多使用的是公用网络。
2)专用网专用网是指某个部门为满足本单位的特殊业务工作的需要而建造的网络。这类网络跟互联网通常没有直接连接或直接禁止连接,仅供部门内部使用,如电子政务外网是政府的业务专网,主要运行政务部门面向社会的专业性业务和不需要在内网上运行的业务。电子政务外网和互联网之间逻辑隔离,而电子政务内网是政务部门的办公网,与互联网物理隔离。除此之外,银行、税务、检察院、公安、法院、医疗等各个领域都有属于自己的一套专用网络。
2.1.3 网络传输模式
在数据通信中,数据在线路上的传输方式可以分为单工通信、半双工通信和全双工通信3种1.单工通信
单工通信是指信息只能单方向传输的工作方式,如家电的红外遥控器,它只能发送数据给家电,但不能接收由家电发来的数据。
单工通信是单向信道,如图 2-13 所示,发送方和接收方是固定的,发送方只能发送数据,接收方只能接收数据,数据流是单向的。
图2-13 单工通信
2.半双工通信
半双工通信是指数据可以沿两个方向传输,但是同一时刻一个信道只能单方向传输数据,又被称为双向交替通信,如图 2-14 所示。最常见的例子为对讲机,对讲机在同一时间只允许一方通话。
图2-14 半双工通信
3.全双工通信
全双工通信是指允许数据在两个方向上同时传输,其在能力上相当于两个单工通信方式的结合,如图 2-15 所示。全双工通信指可以同时进行信号的双向传输,是瞬时同步的。
图2-15 全双工通信
2.1.4 网络通信的类型
数据通信中,在网络中的通信方式可以分为单播、广播、组播3种。
1.单播
单播是主机之间“一对一”的通信模式,网络中的交换机和路由器对数据只进行转发而不进行复制,如果10个客户机需要相同的数据,则服务器需要逐一传送,重复10次相同的工作。网络中的路由器和交换机根据其目的地址选择传输路径,将 IP 单播数据传送到其指定的目的地。
单播的优点如下:
(1)服务器及时响应客户机的请求。
(2)服务器针对每个客户不同的请求发送不同的数据,容易实现个性化服务。
单播的缺点如下:
(1)服务器针对每个客户机发送数据流,服务器流量=客户机数量×客户机流量;在客户数量大、每个客户机流量大的情况下,流媒体应用服务器将不堪重负。
(2)现有的网络带宽是金字塔结构,城际、省际主干带宽仅相当于其所有用户带宽之和的5%。如果全部使用单播协议,将造成网络主干不堪重负。
2.广播
广播是主机之间“一对所有”的通信模式,网络对其中每一台主机发出的信号都进行无条件复制并转发,所有主机都可以接收到所有信息(不管是否需要),由于不用路径选择,所以网络成本可以很低。有线电视网就是典型的广播网络,电视机实际上可接收到所有频道的信号,但只将一个频道的信号还原成画面。在数据网络中也允许广播的存在,但被限制在二层交换机的局域网范围内,禁止广播数据传送到路由器,防止广播数据影响大面积的主机。
广播的优点如下:
(1)网络设备简单,维护简单,布网成本低。
(2)由于服务器不用向每个客户机单独发送数据,所以流量负载极低。
广播的缺点如下:
(1)无法针对每个客户的要求和时间及时提供个性化服务。
(2)网络允许服务器提供数据的带宽有限,客户端的最大带宽=服务总带宽。即使服务商有更大的财力配置更多的发送设备,也无法向众多客户提供更多样化的服务。
(3)广播禁止在Internet宽带上传输。
3.组播
组播是主机之间“一对一组”的通信模式,加入了同一个组的主机可以接收到此组内的所有数据,网络中的交换机和路由器只向需求者复制并转发其所需数据。主机可以向路由器请求加入或退出某个组,网络中的路由器和交换机有选择地复制并传输数据,只将组内数据传输给加入组的主机。这样既能一次将数据传输给多个有需要(组内)的主机,又能保证不影响其他不需要(未加入组)的主机的其他通信。
组播的优点如下:
(1)需要相同数据流的客户端加入相同的组共享一条数据流,节省了服务器的负载,具备广播所具备的优点。
(2)由于组播协议是根据接收者的需要对数据流进行复制并转发,所以服务器端的服务总带宽不受客户接入端带宽的限制。IP 允许有两亿六千多万个组播,所以其提供的服务可以非常丰富。
(3)组播协议允许在Internet宽带上传输。
组播的缺点如下:
(1)与单播协议相比,组播协议没有纠错机制,发生丢包错包后难以弥补,但可以通过一定的容错机制和 QoS(Quality of Service,服务质量,指一个网络能够利用各种基础技术,为指定的网络通信提供更好的服务能力)加以弥补。
(2)现行网络虽然都支持组播传输,但在客户认证等方面还需要完善,这些缺点在理论上都有成熟的解决方案,只是需要逐步推广应用到现存网络中。
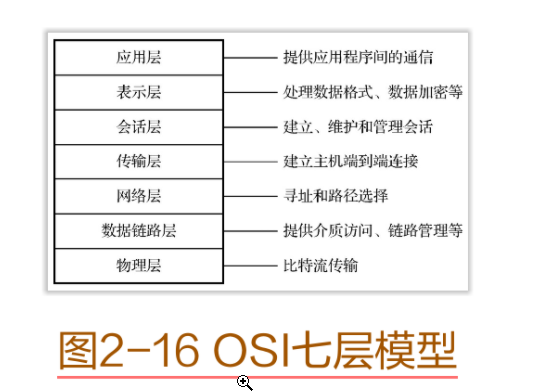
2.2 OSI七层模型
OSI 七层模型的全称是开放系统互连参考模型(Open System Interconnection Reference Model),它是由国际标准化组织(International Organization for Standardization,ISO)在20 世纪 80 年代提出的一技术的基础,也是分析、评判各种网络技术的依据。
图2-16 OSI七层模型
OSI 七层模型是一个逻辑上的定义,其是一个规范,把网络从逻辑上分为 7 层,每一层都有相对应的物理设备,如路由器和交换机等。建立七层模型的主要目的是解决不同类型网络互连时可能遇到的兼容性问题,其优点是将服务、接口和协议 3 个概念明确地区分开来,服务说明某一层为上一层提供一些什么功能,接口说明上一层如何使用下层的服务,而协议涉及如何实现本层的服务。这样各层之间具有很强的独立性,互连网络中各实体采用什么样的协议是没有限制的,只要向上提供相同的服务并且不改变相邻层的接口就可以。
OSI七层模型的基本原则简要概括如下:
● 每当需要一个不同抽象体的时候,应创建一层。
● 每一层都应该执行一个明确定义的功能。
● 每一层功能的选择应该向定义国际标准化协议的目标看齐。
● 层与层边界的选择应该使跨越接口的数据流最小。
● 层数够多,保证不同的功能在不同层中,但层数又不能太多,以免体系结构变得过于庞大。
2.2.1 OSI七层模型的介绍
1.物理层
在 OSI 七层模型中,物理层(Physical Layer)是底层,也是第一层。物理层的主要功能是:利用传输介质为数据链路层提供物理连接,实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉传输介质和物理设备的差异,使其上面的数据链路层不必考虑网络的传输介质是什么。“透明传送”表示经实际电路传送后的比特流没有发生变化。
物理层的任务就是为它的上一层提供一个物理连接,如规定使用电缆和接头的类型、所传送信号的电压等。在物理层数据没有被组织,仅作为原始的位流或电气电压处理,单位是bit(比输,到达目的地后再转化为 1、0,即模数转换与数模转换)。物理层的介质包括有线介质,如双绞线、光纤;无线介质,如无线电、微波等。
2.数据链路层
数据链路层(Datalink Layer)是 OSI 七层模型的第二层,其是控制网络层与物理层之间通信的一个桥梁。其主要功能是如何在不可靠的物理线路上进行数据的可靠传输,为了保证传输,从网络层接收到的数据被分割成特定的可被传输的帧。
数据帧是用来传输数据的结构包,它包括原始数据、发送方、接收方的物理地址(确定了帧将发送到何处)、纠错和控制信息(确保帧无差错到达)。如果在传送数据时,接收方检测到所传数据中有差错,就要通知发送方重发这一帧。该层的作用包括物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。
3.网络层
网络层(Network Layer)是 OSI 七层模型的第三层,其主要功能是将网络地址翻译成对应的物理地址,并决定如何将数据从发送方路由到接收方。网络层通过综合考虑发送优先权、网络拥塞程度、服务质量及可选路由的花费来决定从一个网络中的节点 A 到另一个网络中的节点 B 的最佳路径。简单来说就是在网络中找到一条路径,一段一段地传送,由于数据链路层保证两点之间的数据是正确的,因此源到目的地的数据也是正确的,这样一台机器上的信息就能传到另一台了,但计算机网络的最终用户不是主机,而是主机上的某个应用进程,这个过程是由传输层实现的。
4.传输层
传输层(Transport Layer)是OSI 七层模型的第四层,其主要功能是传输协议同时进行流量控制,或是基于接收方可接收数据的快慢程度调整发送速率。除此之外,传输层按照网络能处理的最大尺寸将较长的数据包进行强制分割(标记整理成有序的包)。
例如,以太网无法接收大于1500B的数据包。发送方节点的传输层将数据包分割成较小的数据片,对数据片添加序列号,以便当数据到达接收方节点的传输层时,能以正确的顺序重组,该过程被称为排序。传输层中常见的两个协议为传输控制协议(TCP)和用户数据报协议(UDP)。传输层提供逻辑连接的建立、传输层寻址、数据传输、传输连接释放、流量控制、拥塞控制、多路服用和解复用、崩溃恢复等服务。网络层把数据交给传输层后,传输层必须标识该服务是哪个进程请求的、要交给谁。
5.会话层
会话层(Session Layer)是OSI七层模型的第五层,负责在网络中的两个节点之间建立、维持和终止通信。会话层的功能包括建立通信连接、保持会话过程通信连接的畅通、同步两个节点之间的对话、决定通信是否被中断,以及通信中断时决定从何处重新发送。
你可能常常听到有人把会话层称作网络通信的“交通警察”。当通过拨号向你的 ISP (互联网服务提供商)请求连接到互联网时,ISP服务连接。若你的电话线偶然从插孔脱落,你终端机上的会话层将检测到连接中断并重新发起连接,会话层通过决定节点通信的优先级和通信时间的长短来设置通信期限。
会话层是服务提供者接口,管理用户间的会话和对话,控制用户间的连接和挂断连接,报告上层错误。正如两个人对话,对方听到了也能理解,但如果对方是外国人,他听到了我的声音,他理解了吗?他不能理解。那对于计算机网络而言,客户机发了一个请求给服务器,服务器应该能理解这个请求到底是什么。这个问题怎么样理解?这个理解有两个层次,我讲中国话,它只能懂英文,这当中应该有一个翻译,把汉语翻译成英语,而这个工作就交给表示层来做了。
6.表示层
表示层(Presentation Layer)是OSI七层模型的第六层,它是应用程序和网络之间的翻译官,在表示层,数据将按照网络能理解的方式进行格式化,这种格式化因网络的类型不同而不同,表示层管理数据的解密与加密。例如,在 Internet 上查询银行账户,使用的是一种安全连接。账户数据在发送前被加密,在网络的另一端,将接收到的数据解密。除此之外,表示层协议还对图片和文件格式信息进行解码和编码。
表示层为应用程序提供 API(Application Programming Interface,应用程序接口,使用/调用该接口去完成某个目标)负责SPI(Service Provider Interface,继承/实现的接口)与应用程序之间的通信,定义不同体系间不同的数据格式,具体说明独立结构的数据传输格式,编码/解码数据、加密/解密数据、压缩/解压数据。
7.应用层
应用层(Application Layer)是 OSI 七层模型的最高层,即第七层,它为应用程序提供服务以保证通信,但不是进行通信的应用程序本身。应用层直接和应用程序接口一起提供网络应用服务,其作用是在实现多个系统应用进程相互通信的同时,完成一系列业务处理所需的服务。其服务元素分为两类:公共应用服务元素(CASE)和特定应用服务元素(SASE)。CASE 提供基本的服务,它成为应用层中任何用户和任何服务元素的用户,主要为应用进程通信、分布系统实现提供基本的控制机制。
SASE 则要满足一些特定服务,如文卷传送、访问管理、作业传送、银行事务、订单输入等。这些将涉及虚拟终端、作业传送与操作、文卷传送及访问管理、远程数据库访问、图形核心系统、开放系统互连管理等。
共同点:
(1)OSI七层模型和TCP/IP参考模型都采用了层次结构的概念。
(2)二者都能够提供面向连接和无连接两种通信服务机制。
不同点:
(1)OSI采用的是七层模型,而TCP/IP是四层结构。
(2)TCP/IP 参考模型的网络接口层实际上并没有真正的定义,只是一些概念性描述;而 OSI 七层模型不仅分了两层,而且每一层的功能都很详尽,甚至在数据链路层又分出一个介质访问子层,专门解决局域网的共享介质问题。
(3)OSI 七层模型与 TCP/IP 参考模型的传输层功能基本相似,都是负责为用户提供真正的端对端的通信服务。二者所不同的是 TCP/IP 参考模型的传输层是建立在网络互联层基础之上的,而网络互联层只提供无连接的网络服务,所以面向连接的功能完全在TCP中实现,当然TCP/IP的传输层还提供无连接服务,如UDP,而OSI七层模型的传输层是建立在网络层基础之上的,在 OSI 七层模型中,网络层通常提供的都是无连接服务,其也可以提供一些面向连接的服务,如虚电路,它是由分组交换通信所提供的面向连接的通信服务,但传输层只提供面向连接的服务。
(4)OSI 七层模型的抽象能力高,适用于描述各种网络;而 TCP/IP 是先有协议,再建立TCP/IP模型的。
(5)OSI 七层模型的概念划分清晰,但过于复杂;而 TCP/IP 参考模型在服务、接口和协议的区别上不清楚,其功能描述和实现细节混在一起。
(6)TCP/IP 参考模型的网络接口层并不是真正的一层;OSI 七层模型的缺点是层次过多,增加了复杂性。
(7)OSI 七层模型虽然被看好,但由于没把握好时机,技术不成熟,实现困难;相反TCP/IP参考模型虽然有许多不尽如人意的地方,但还是比较成功的。
2.3.1 网络接口层
在TCP/IP参考模型中,网络接口层对应OSI七层模型的物理层和数据链路层。
1.数据帧
数据帧(Frame)传递的单位是帧,是数据链路层的协议数据单元,如图2-20所示,其包括3部分:(1)帧首部:里面有MAC地址,通过这个地址可以在底层的交换机层面顺着网线找到你的计算机。(2)帧的数据部分:包含网络层的数据、IP 数据报,即使用IP 地址定位的一个数据包。(3)帧尾部:帧首部和帧尾部包含一些必要的控制信息,如同步信息、地址信息、差错控制信息等。
2.MAC地址
MAC(Media Access Control,介质访问控制)地址也称MAC位址、硬件地址,用来定义网络设备的位置。如图2-21所示,MAC地址由48bit的十六进制数字组成,前24位叫组织唯一标志符(Organizationally Unique Identifier,OUI),是由IEEE的注册管理机构给不同厂家分配的代码。后 24 位由厂家自己分配,称为扩展标识符,同一厂家生产的网卡中MAC地址的后24位是不同的。
2.3.2 网络层
网络层又称互联网层(Internet Layer),是将整个网络体系结构贯穿在一起的关键层,几乎可以看作与 OSI 七层模型的网络层等同,负责处理主机到主机的通信,决定数据包如何交付,选择是交给网关(路由器)还是交给本地端口。
1.IP地址
IP 是英文 Internet Protocol 的缩写,表示“网际协议”,IP 地址是分配给网络中每台机器的数字标识符,其指出了设备在网络中的具体位置。相对于MAC地址,IP地址是设备的软件地址。IP 地址让一个网络中的主机能够与另一个网络中的主机通信,而不关心这些主机所属的网络是什么类型。
3.ICMP
ICMP(Internet Control Message Protocol,因特网信报控制协议)被认为是网络层的一个组成部分,用于传递差错、控制、查询报文等信息。ICMP 报文常被 IP 层或更高层协议(TCP 或 UDP)使用,如 Ping。IP 并不是一个可靠的协议,它不保证数据被送达,故保证数据送达的工作就应该由其他模块来完成,其中一个重要的模块就是 ICMP。ICMP 的消息可以分为错误消息、请求消息和响应消息。一台主机向一个节点发送一个ICMP 请求报文,如果途中没有异常(如被路由器丢弃、目标不回应 ICMP 或传输失败),则目标返回ICMP响应报文,说明这台主机存在。当传送IP数据报发生错误,如主机不可达、路由不可达等,ICMP 将会把错误信息封包,即 ICMP 差错报文,然后传送回主机,给主机一个处理错误的机会。
1)Ping
Ping(Packet Internet Groper,因特网包探索器)是用于测试网络连接量的程序。Ping发送一个ICMP回声请求消息给目的地址并报告是否收到所希望的ICMP echo(ICMP回声应答)。对于一个生活在网络上的管理员或黑客来说,Ping 命令是第一个必须掌握的DOS 命令,它所利用的原理是这样的:利用络上机器 IP 地址的唯一性,给目标 IP 地址发送一个数据包,再要求对方返回一个同样大小的数据包来确定两台网络机器是否连接相通、时延是多少。在一台计算机上向远程主机发起 Ping 连接时,可能收到的返回信息(常见)有:
● 连接建立成功:Reply from 192.168.1.1:bytes=32 time<1ms TTL=128。
● 目标主机不可达:Destination host unreachable。
● 请求时间超时:Request timed out。
● 未知主机名:Unknown host abc。
2)Tracert
Tracert(跟踪路由)是路由跟踪实用程序,用于确定 IP 数据包访问目标所采取的路径。Tracert 的工作原理是:用 IP 生存时间(TTL)字段和 ICMP 错误消息来确定从一个主机到网络上其他主机的路由。Tracert发送一个TTL是1的IP数据包到目的地,当路径上的第一个路由器收到这个数据包时,它将 TTL 减 1 变为 0,所以该路由器会将此数据包丢掉,并送回一个ICMP time exceeded的消息(包含IP包的源地址、IP包的所有内容及路由器的IP地址),Tracert收到这个消息后就可以确认这个路由器存在于该路径上,接着Tracert送出一个TTL是2的数据包,发现其他路由器,Tracert每次都将送出的数据包的 TTL 加 1,直到某个数据包抵达目的地。当数据包到达目的地后,该主机不会送回ICMP time exceeded消息,而会收到ICMP port unreachable的消息,这是因为Tracert通过UDP 数据包向不常见的大端口类
2)TCP的三次握手
三次握手(Three-way Handshake)是指建立一个 TCP 连接时,需要客户端和服务器端发送3个包以确认连接的建立,如图2-30所第一次握手:Client(客户)将标志位 SYN 置为 1,随机产生一个值 seq=x,并将该数据包发送给Server(服务器),Client进入SYN_SENT状态,等待Server确认。
第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位 SYN 和 ACK 都置为 1,ack=x+1,随机产生一个值 seq=y,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
第三次握手:Client收到确认后,检查ack是否为x+1,ACK是否为1,如果正确,则将标志位ACK置为1,ack=y+1,并将该数据包发送给Server,Server检查ack是否为y+1,ACK 是否为 1,如果正确,则连接建立成功,Client 和 Server 进入 ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
3)TCP的四次挥手
四次挥手(Four-way Wave Hand)就是指断开一个 TCP 连接时,需要客户端和服务器端发送4个包以确认连接的断开,如图2-31所示。 图2-31 四次挥手
由于 TCP 连接是全双工的,因此每个方向都必须单独进行关闭,这一原则是当发送方完成数据发送任务后,发送一个 FIN 报文给接收方,来表示已完成对接收方的数据发送,接收方会回应一个确认信息告知发送方,它已知道发送方无数据发送。但是在这个TCP连接上接收方能够发送数据,直到接收方也发送了FIN。这时发送方回应确认信息,最终断开TCP连接。首先进行关闭的一方将执行主动关闭,另一方则执行被动关闭。
第一次挥手:Client 发送一个 FIN,用来关闭 Client 到Server 的数据传送,Client 进入FIN_WAIT_1状态。
第二次挥手:Server 收到 FIN 后,发送一个 ACK 给 Client,确认序号为收到序号+1 (与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给
Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
3.UDP
传输层的第二个协议是用户数据报协议(User Datagram Protocol,UDP),其是一个不可靠、无连接协议,适用于那些不想要 TCP 的有序性或流量控制功能,而宁可自己提供这些功能的应用程序,如图2-32所示。UDP被广泛应用于那些一次性的基于客户机/服务器类型的“请求/应答”查询应用(如 DNS 服务),以及那些及时交付比精确交付更加重要的应用,如传输语音或视频。
2.3.4 应用层
1.应用层介绍
应用层的任务是通过应用进程间的交互来完成特定网络应用。应用层协议定义的是应用进程间的通信和交互规则。不同的网络应用需要不同的应用层协议。端口号的作用就是将应用层映射到传输层,如图2-33所示。DNS在进行区域传输的时候使用TCP,其他时候则使用 UDP,使用 TCP 的应用层协议有 SMTP、TELNET、HTTP、FTP、DNS。使用UDP的应用层协议有DNS、TFTP、RIP、BOOTP、DHCP、SNMP、IGMP。在互联网中应用层协议很多,如域名系统(DNS)、支持万维网应用的 HTTP,以及支持电子邮件的 SMTP 等。应用层协议是为了解决某一类应用问题,通过位于不同主机中的多个应用进程之间的通信和协同工作来完成的。这种通信必须遵守严格的规则,其定义如下:
● 应用进程交换的报文(应用层的数据单元是报文),如请求报文和响应报文。● 各种报文类型的语法,如报文中的各个字段及其详细描述。
● 字段的语义,即包含在字段中的信息含义。
● 进程何时、如何发送报文,以及对报文进行响应的规则。
1.路由概念
1)路由器
路由器工作在 OSI 七层模型中的第三层,即网络层。它的主要目的是在网络之间提供路由选择,进行分组转发。路由器是一种硬件设备,如图3-2所示,是支持互联网的基础骨干系统。
图3-2 路由器
2)路由
路由(routing)是指分组从源地址到目的地址时,决定端到端路径的网络范围的进程。路由工作在 OSI 七层模型网络层的数据包转发设备。路由器通过转发数据包来实现网络互连。路由器通常连接两个或多个由 IP 子网或点到点协议标识的逻辑端口,至少拥有1个物理端口。所谓“路由”,是将数据报文从一个子网转发到另一个子网的行为。
3)路由表
为了完成“路由”的工作,在路由器中保存着各种传输路径的相关数据,即路由表(routing table)。路由表是一个存储在路由器或联网计算机中的电子表格或数据库。路由表存储着指向特定网络地址的路径。路由表建立的主要目的是为了实现路由协议和静态路由选择,如在Windows系统中的路由表,如图3-3所示。
图3-3 Windows系统中的路由表
路由器的工作方法如下:
(1)查询路由表,依据目标IP地址转发。
(2)路由表通过动态路由协议、静态路由协议等进行填充。
2.路由分类及选路
主机A想要通过路由器与主机B进行通信,路由器上必须要有到达主机A 和主机B的路由才能完成双方的数据转发。一旦路由器的一个接口与一台网络设备相连,路由器就会学习到该设备所在网段的路由,这是直连路由。除此之外,还有静态路由和动态路由两种路由协议来获取路由,静态路由有直连路由、默认路由;动态路由包括 RIP、EIGRP (思科私有)、OSPF、IBGP、ISIS 等。在网络中,通往目的地的路径有很多条,具体走哪一条路径主要基于度量值和管理距离。
度量值(metric)代表距离,用来在寻找路由时确定最优路由路径。每一种路由算法在产生路由表时,会为每一条通过网络的路径产生一个数值(度量值),最小的值表示最优路径。度量值的计算可以只考虑路径的一个特性,但更复杂的度量值是综合了路径的多个特性产生的。通常影响路由度量值的因素有线路延迟、带宽、线路使用率、线路可信度、跳数、最大传输单元。
管理距离是指一种路由协议的路由可信度。每一种路由协议按可靠性从高到低依次分配一个信任等级,这个信任等级就叫管理距离,如表3-1所示。
3.静态路由
静态路由通常是指由网络管理员为实现路由在路由器上手工添加的路由信息,是实现数据包转发的最简单的方式。静态路由适用于小型网络在这样的网络中,管理员可以清楚地了解网络的结构,便于设置正确的路由信息。同时小型网络中的路由条目不会太多,便于后期维护。其特点如下:
(1)手动配置
静态路由是由管理员根据实际情况手动配置的,路由器不会自动生成。静态路由中包括目标节点或目标网络的IP地址,还要包括下一跳地址。
(2)路由路径相对固定
因为静态路由是手动配置的,所以每个配置的静态路由在本地路由器上的路径基本不变。当网络的拓扑结构或链路状态发生变化时,静态路由也不会自动改变,需要管理员手动修改。
(3)永久存在
因静态路由是手动配置的,所以一旦创建成功,一般来说会在路由表中永久存在,除非管理员删除它、路由中指定的接口关闭或下一跳地址不可达。
(4)不可通告性
静态路由在默认情况下是私有的,不会通告给其他路由器,当在一个路由器上配置某一条静态路由后,其不会被通告到网络中相连的其他路由器上。
(5)单向性
静态路由是具有单向性的,也就是说它仅为数据提供沿着下一跳的方向进行路由,不提供反向路由,所以如果想实现双向通信,就必须配置回程路由,如图3-4所示。
4.默认路由
默认路由(default route)是一种特殊的静态路由,当路由表中与 IP 数据包的目的地址之间没有匹配的表项时,路由器能够使用默认路由。如果没有默认路由,则目的地址在路由表中没有匹配表项的数据包将被丢弃。当设置了默认路由后,如果 IP 数据包中的目的地址在路由表中找不到路由,则路由器会选择默认路由 0.0.0.0,匹配 IP 地址时,0 表示通配符,任何值都是可以的,所以 0.0.0.0 和任何目的地址匹配都会成功,从而实现默认路由要求的效果。默的 IP 地址和子网掩码改成0.0.0.0和0.0.0.0。
当数据包到达一个知道如何到达目的地址的路由器时,这个路由器会根据最长匹配原则选择有效路由。子网掩码匹配目的 IP 地址且位数最多的网络会被选择。默认路由在某些场景(如末端网络)下极其有效,使用默认路由可以大大减少对路由器的配置,降低路由器对路由表的维护工作量,从而降低路由器的性能消耗,提升网络性能。
1
3.2 交换网络
3.2.1 交换网络的介绍
交换机也叫交换式集线器,其基于 MAC(网卡的介质访问控制地址)识别能完成封装转发数据包功能的网络设备。交换机对信息进行重新生成,并经过内部处理后转发至指定端口,具备自动寻址能力和交换作用,它是一个扩大网络的器材,能为网络提供更多的连接端口,以便连接更多的计算机。交换机的工作原理如下:
(1)交换机根据所收到数据帧中的源 MAC 地址建立该地址同交换机端口的映射,并将其写入MAC地址表中。
(2)交换机将数据帧中的目的 MAC 地址同已建立的 MAC 地址表进行比较,以决定由哪个端口进行转发。
(3)如果数据帧中的目的 MAC 地址不在 MAC 地址表中,则向所有端口转发,这一过程称为泛洪。
(4)广播帧和组播帧向所有端口转发。
3.2.3 交换机的接口模式
在 802.1Q 中定义 VLAN 帧后,将接口分为 Access 接口和 Trunk 接口,下面分别进行介绍。
1.Access接口
Access 接口是交换机上用来连接用户主机的接口,其只能接入链路,仅允许唯一的VLAN ID通过本接口,该VLAN ID与接口的默认VLAN ID相同,Access接口发往对端设备的以太网帧永远是不带标签的帧,如图3-11所示。
图3-11 Access接口对报文的处理
2.Trunk接口
Trunk 接口是交换机上用来和其他交换机连接的接口,其只能连接干道链路,允许多个VLAN的帧(带Tag标记)通过。默认的VLAN ID为VLAN 1,可以进行修改,如图3-12所示。1)关于Trunk(干道/干线)
(1)Trunk 一般用于交换机与交换机之间,或者交换机与路由器之间(配置单臂路由的时候)
(2)Trunk有dot1q和ISL两种封装形式。
图3-12 Trunk接口对报文的处理
2)关于dot1q和ISL的区别
(1)ISL是思科私有的,dot1q是公有的。
(2)ISL会在原始帧前加26字节,在帧尾加4字节,所以有时也被称作封装。dot1q会在原始帧内部添加4字节,所以有时也被称作标记。
(3)ISL最多支持1000个VLAN,dot1q最多支持4096个VLAN。
(4)ISL对语音的支持不好,dot1q对语音(QoS)的支持比较好。
(5)dot1q中有Native VLAN的概念,ISL中没有。
3.3.2 动态转换
动态转换是指将内部网络的内部本地地址转换为外部全局地址时,外部全局地址来自一个地址池,所有被授权访问 Internet 的私有 IP 地址可随机转换为任何指定的合法外部全局地址,如图 3-15 所示。也就是说,只要指定哪些内部地址可以进行转换,以及用哪些合法地址作为外地址,就可以进行动态转换。动态转换可以使用多个合法外部地址集。
图3-15 动态转换
1)动态转换的工作原理
(1)在NAT网关上配置动态转换后,内部地址池与外部地址池映射。
(2)在某一时刻,如果内部主机 10.1.1.1 需要访问外部主机 15.1.1.1 上的 HTTP 服务,则内部主机的数据包被发送到外部主机。
(3)NAT 网关在收到内部主机通往外部主机的数据包时,会从外部地址池中选择一个未使用的地址,将内部主机 10.1.1.1 的源地址转换为选定的外部地址,发送出去。然后 NAT 网关记录内部本地地址和内部全局地址的对应关系,并将这种关系写入 NAT 映射表中。
(4)外部主机收到166.1.1.1(经过NAT)的请求,进行应答。
(5)NAT 网关收到外部主机数据包时,检查 NAT 映射表,如果存在,则按照规则将数据包的目的地址修改为内部地址 10.1.1.1,然后进行转换;如果不存在,则会丢弃或拒绝数据包。
2)主要配置
3.3.3 端口多路复用
端口多路复用(Port Address Translation,PAT)是指改变数据包的源端口并进行端口转换,即端口地址转换。采用端口多路复用方式,内部网络的所有主机均可共享一个合法外部 IP 地址实现对 Internet 的访问,从而可以最大限度地节约 IP 地址资源,同时可隐藏网络内部的所有主机,有效避免了来自 Internet 的攻击。因此,网络中应用最多的就是端口多路复用方式,如图 3-16 所示,端口多路复用还可以通过被转换的地址是源地址还是目的地址而分为源地址转换(Source Network Address Translation,SNAT)和目的地址转换(Destination Network Address Translation,DNAT)。
4.1 需求概述
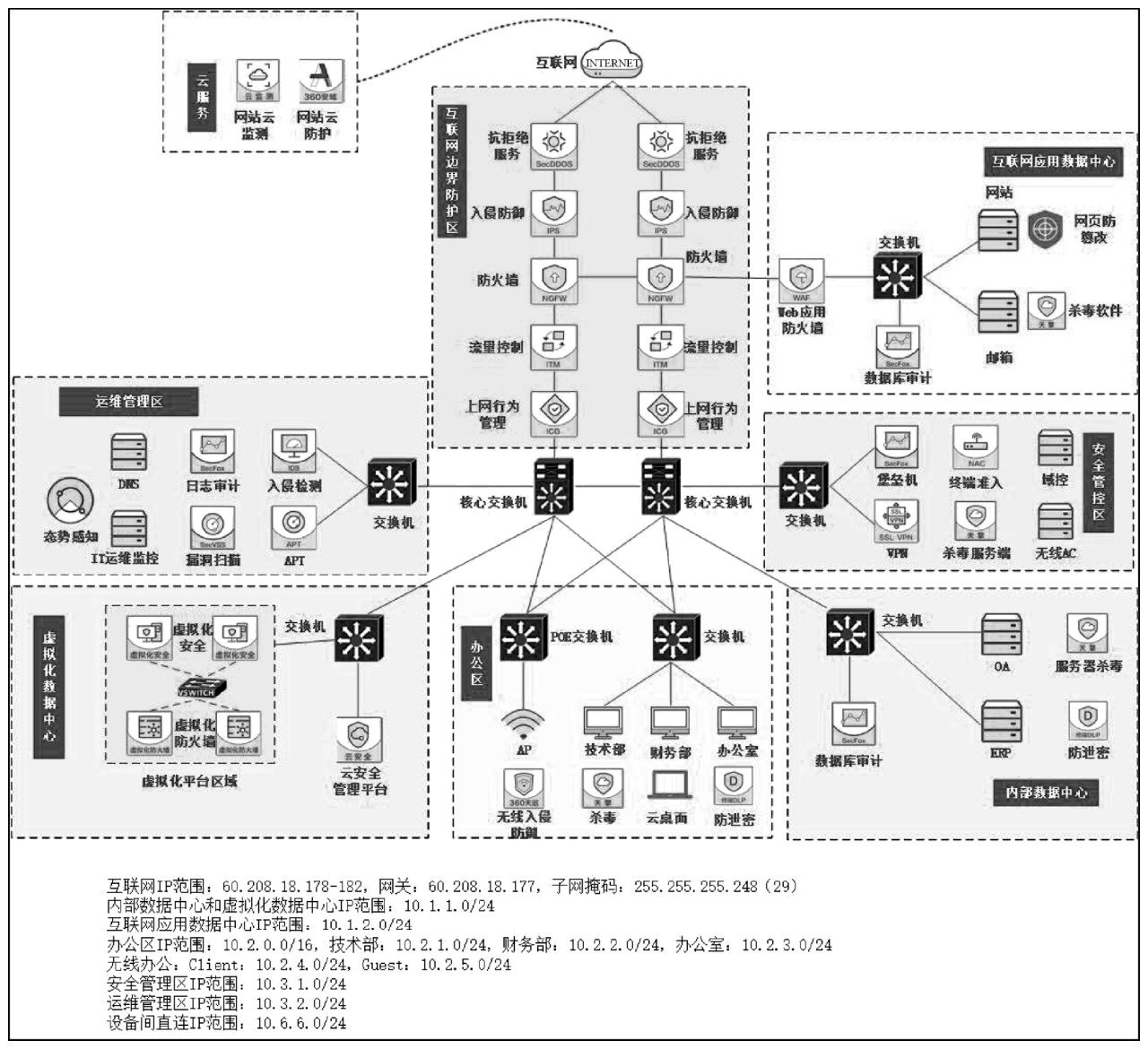
通过对第 3 章的学习,我们完成了办公网的初步建设,实现了办公网的连通性,在整个办公网内可以相互访问。这其中存在较大的安全隐患,比如,任意 IP 可以登录网站服务器,对网站服务器进行攻击;任意 IP 可以访问财务部,对财务部进行攻击;一旦内网中某台计算机感染了“勒索病毒”,则可以通过网站服务器的 445 端口进行传播等。解决这一问题的关键技术就是访问控制,访问控制是网络安全防范和保护的主要策略,它的主要任务是保证网络资源不被非法使用和访问,如图4-1所示。通过对本章的学习主要解决办公网如下问题:
(1)技术部与财务部不能相互访问,从而保障财务部的安全。
(2)技术部、财务部不能访问办公室,但办公室可以访问技术部、财务部。
(3)仅允许办公室可以访问网站服务器的 3389 端口,便于远程管理,其他部门不允许访问。
(4)内网所有IP仅能访问网站服务器的80端口,其他端口关闭。
4.2 访问控制技术
访问控制是明确什么角色的用户能访问什么类型的资源。使用访问控制可以防止用户对计算资源、通信资源或信息资源等进行未授权访问,是一种针对越权使用资源的防御措施。未授权访问包括未经授权的使用、泄露、修改、销毁信息,以及发布指令等,在访问控制中存在以下几个概念:
(1)客体(object):规定需要保护的资源,又称为目标(target)。
(2)主体(subject):是一个主动的实体,规定可以访问该资源的实体(通常指用户或代表用户执行的程序),又称为发起者(initiator)。
(3)授权(authorization):规定可对该资源执行的动作,如读、写、执行或拒绝访问。
访问控制的基本模型如图4-2所示。访问是主体对客体实施操作的能力,以某种方式限制或授予主体的这种能力。授权是指主体经过系统鉴作的权限。在实际网络配置中,主要是在核心交换机和防火墙两个位置配置访问控制策略。

4.2.1 ACL介绍
1.ACL分类
ACL 是一种基于包过滤的控制技术,其在路由器、三层交换机中被广泛采用。ACL对数据包的源地址、目的地址、端口号及协议号等进行检查,并根据数据包是否匹配ACL规定的条件来决定是否允许数据包通过。
华为将ACL分为基本ACL和高级ACL。
(1)基本ACL(2000~2999):只能匹配源IP地址。
(2)高级ACL(3000~3999):可以匹配源IP地址、目标IP地址、源端口、目标端口等三层和四层的字段。
思科将ACL分为标准ACL和扩展ACL。
(1)标准ACL(1~99或1300~1999):匹配源地址的所有IP数据包。
(2)扩展 ACL(100~199 或 2000~2699):匹配源地址和目标地址、源端口和目标端口等字段。
4.3.1 防火墙介绍
防火墙是指设置在不同网络(如可信任的企业内部网和不可信的公共网)或网络安全域之间的一系列部件的组合。它是不同网络或网络安全域间信息的唯一出口,能根据企业的安全政策控制(允许、拒绝、监测)网络的信息流,是保护用户资料与信息安全的一种技术,且本身具有较强的抗攻击能力。
随着防火墙技术的不断发展,其功能越来越丰富。防火墙最基础的两大功能依旧是隔离和访问控制。隔离功能就是在不同信任级别的网络之间砌“墙”,而访问控制就是在墙上开“门”并派驻守卫,按照安全策略来进行检查和放行。
1.防火墙的作用
防火墙的主要作用通常包括以下几点:
1)提供基础组网和访问控制
防火墙能够满足企业环境的基础组网和基本的攻击防御需求,可以实现网络连通并限制非法用户发起的内外攻击,如黑客、网络破坏者等,禁止存在安全脆弱性的服务和未授权的通信数据包进出网络,并对抗各种攻击。
2)网络地址转换
防火墙可以作为部署NAT(Network Address Translation,网络地址转换)的逻换ISP(Internet Service Provider,互联网服务提供商)时带来的重新编址的麻烦。
3)记录和监控网络存取与访问
作为单一的网络接入点,所有进出信息都必须通过防火墙,所以防火墙可以收集关于系统网络使用和误用的信息并做出日志记录。通过防火墙可以很方便地监视网络的安全性,并在异常时给出报警提示。
4)限定内部用户访问特殊站点
防火墙通过用户身份认证(如 IP 地址等)来确定合法用户,并通过事先确定的完全检查策略来决定内部用户可以使用的服务及可以访问的网站。
5)限制暴露用户点
利用防火墙对内部网络的划分,可实现网络中网段的隔离,防止影响一个网段的问题通过整个网络传播,限制了局部重点或敏感网络安全问题对全局网络造成的影响,保护一个网段不受来自网络内部其他网段的攻击,从而保障网络内部敏感数据的安全。
6)虚拟专用网
部分防火墙还支持具有 Internet 服务特性的企业内部网络技术体系—虚拟专用网络(Virtual Private Network,VPN)。通过 VPN 将企事业单位在地域上分布在世界各地的局域网或专用子网有机地联成一个整体。
2.安全域的概念
随着网络系统规模逐渐扩大,结构越来越复杂,组网方式随意性增强,缺乏统一规划,扩展性差;网络区域之间的边界不清晰,互连互通没有统一控制规范;业务系统各自为政,与外网之间存在多个出口,无法统一管理;安全防护策略不统一,安全防护手段部署原则不明确;对访问关键业务的不可信终端接入网络的情况缺乏有效控制。针对这类问题,提出安全域这一概念:安全域是一种思路、方法,它通过把一个复杂巨系统的安全保护问题分解为更小的、结构化的、区域的安全保护问题,按照“统一防护、重点把守、纵深防御”的原则,实现对系统分域、分级的安全保护,如图4-9所示。
图4-9 安全域
网络安全域是指同一系统内根据信息的性质、使用主体、安全目标和策略等要素的不同来划分的不同逻辑子网或网络,每一个安全域内部有相同的安全保护需求,互相信任,具有相同的安全访问控制和边界控制策略,并且相同的网络安全域共享一样的安全策略。
安全域是为方便管理而划分的逻辑区域,一般这个逻辑区域会被定义一个类可读的名称,如办公内网,通常认为是可信任的。一些厂家定义名称为“trust”的安全域。而互联网,一般认为是不可信任的,则定义名称为“untrust”的安全域。另一些防火墙厂家会将内网安全域名称
4.3.2 防火墙的部署
防火墙接口支持串联(路由模式、交换模式)和旁路模式。
1.路由模式
防火墙通常使用路由模式(内网接口和外网接口都工作在路由模式),作为内网的出口网关部署在内网与外网之间。内网和外网不在同一个网段,如图4-10所示。
防火墙允许内网使用私有IP地址,内网用户通过NAT后访问外网。防火墙可以通过单链路连接互联网,也可以配置多链路方式提高链路的可靠性。
图4-10 路由模式
2.交换模式墙接口工作在二层,不需要配置 IP 地址。交换模式下部署防火墙不需要改变原有网络的结构。适用于需要增加网络安全防护,但不希望改变原有网络结构的情况,防火墙通常部署在内网和出口路由器之间。
1)接入VLAN场景
基于接口划分 VLAN 时,需要绑定 VLAN 和接口,用户主机被划分到其连接接口绑定的VLAN下。接入VLAN场景,接口的交换模式支持Access和Trunk。
(1)模式为 Access:链路类型为 Access 的接口只能属于某一个 VLAN,接收和发送本VLAN内的报文,一般用于连接终端PC。
(2)模式为Trunk:链路类型为Trunk的接口可以接收和发送多个VLAN的报文,一般与交换设备的Trunk接口对接。
2)透明桥接场景
桥(Bridge)模式下,用户将两个或两个以上的物理接口绑定在同一个桥,桥透明接入用户网络。桥可以通过绑定桥接口配置 IP 地址,管理员可以通过桥接口管理防火墙。如图 4-11 所示,防火墙通过桥方式透明接入用户网络,保护 VLAN10 和 VLAN20 的子网。PC1或PC2可以通过同网段桥接接口IP管理防火墙。
3)虚拟线路桥接场景
虚拟线路桥只能绑定两个物理接口,虚拟线路桥不能绑定桥接口,如图 4-12 所示。从绑定虚拟线路桥的一个物理接口进入的流量只能被转发到该虚拟线路桥的另一个接口。其他接口流量不能被转发到虚拟线路桥中。内网用户可以通过虚拟线路桥直接访问内网服务器。
图4-12 虚拟线路桥接
4)聚合接口场景
聚合接口可以将防火墙的多个物理接口进行汇聚绑定,逻辑上变为一个接口,为防火墙同其他设备之间提供冗余和高效的连接方式,同时能够扩展链路带宽。
3.旁路模式
接口旁路模式主要用于实现监控功能,完全不需要改变用户的网络环境,通过把设备的监听口连接在交换机的镜像口上实现对流量的检测,检测完成后所有镜像流量都会被丢弃,如图 4-13 所示。这种模式对用户的网络环境完全没有影响,旁路设备故障不会对业务链路造成影响。接口旁路模式下支持安全防护、在安全策略中引用各种高级功能的安全配置文件对镜像的流量进行检测,检测到匹配安全策略的流量和攻击流量则生成日志,并进行日志统计和分析。
5.1 需求概述
1.合规需求
网络安全法第二十一条:“国家实行网络安全等级保护制度。网络运营者应当按照网络安全等级保护制度的要求,履行下列安全保护义务,保障网络免受干扰、破坏或者未经授权的访问,防止网络数据泄露或者被窃取、篡改:……(三)采取监测、记录网络运行状态、网络安全事件的技术措施,并按照规定留存相关的网络日志不少于六个月。”
网络安全等级保护:“应在网络边界、重要网络节点进行安全审计,审计覆盖到每个用户,对重要的用户行为和重要安全事件进行审计。”
2.安全需求
除此之外,互联网的高速发展在为学习、工作、生活等提供便利的同时,也滋生了网络恶搞、诽谤中伤、侵犯隐私、色情泛滥、企业敏感信息泄露等问题,对国家安定、社会和谐、企业效率、青少年成长、网络安全等提出了严峻的挑战。
3.办公效率需求
为了在日益激烈的竞争中获得优势,由于未加管理的互联网应用会大大降低员工的工作效率,企业必须不断开发新产品,改善服务质量,提高工作效率,降低运营成本。根据图 5-1 所示的数据显示,在工作时间(即周一至周五的 8:问活动中有大量跟工作无关,很多时间用在了即时通讯、网络购物、网络下载、视频播放、网络游戏、社交网络、安全软件、电子邮件、办公OA和金融理财。在高度网络化的现代办公环境里,办公室可能成为“舒适的网吧”,人力资源在无形中浪费巨大。
5.3 上网行为管理的部署
上网行为管理产品的部署模式分为串联部署和旁路镜像部署,企业通常采用串联部署的方式。串联部署可以实现对特定行为进行阻断,而旁路镜像部署仅能起到监测作用。
5.3.1 串联部署
串联部署方式如图 5-2 所示。串联部署方式能实现对每一种网络应用的精确控制,完整审计所有上网数据。在实际配置中,串联部署分为网桥模式和网关模式两种。 图5-2 串联部署方式
1.网桥模式
这种模式以透明网桥方式接入网络,部署到企业或部门的网络出口位置,无须改动用户网络结构和配置。
(1)单网桥部署:上网行为管理系统提供一个内网口和一个外网口,作为网桥接入到要管控网络的出口处,是最普遍的部署模式。
(2)多网桥部署:当企业拥有两个互联网出口,且企业内部不同子网需要通过不同的互联网出口连接互联网时,上网行为管理系统可提供双入双出、双网桥的部署模式,通过一台设备即可同时管控两条链路内的用户互联网行为。
2.网关模式
这种模式支持多出口网络,可以同时配置联通、电信等多条线路。多出口环境下同时支持静态 IP 接入和 ADSL 拨号接入。将设备部署在网关处,起到隔离内网、外网和NAT/路由的作用,需要为设备配置内网 IP 地址和外网 IP 地址。上网行为管理系统在网关模式下,支持 DNAT 功能,可将内网 IP 地址或特定端口映射到互联网,从而使公网主机能够访问特定的内网服务器。
6.1.1 工作组和域
Windows Server 有两种网络环境:工作组和域。默认为工作组环境,如图6-1所示。
工作组网络也称为“对等式”网络。因为网络中每台计算机的地位是平等的,并且它们的资源及管理分散在每台计算机上,所以工作组环境的特点就是分散管理。在工作组环境中,每台计算机都有自己的“本机安全账户数据库”,称为SAM 数据库。SAM 数据库是干什么用的呢?平时我们登录计算机时,输入账户和密码,计算机就会去 SAM 数据库验证,如果输入的账户存在SAM 数据库中,则 SAM 数据库会通知系统允许登录。SAM 数据库默认存储在 C:/WINDOWS/system32/config 文件夹中,这便是工作组环境中的登录验证过程。
有这样一种应用场景:某公司有 200 台计算机,我们希望某台计算机上的账户 Bob 可以访问每台计算机内的资源或可以在每台计算机上登录。那么在工作组环境中,我们必须要在这200台计算机的各个SAM数据库中创建Bob账户。一旦Bob想要更换密码,则必须要更改200次。如果该公司有5000台计算机或上万台计算机该怎么办呢?这便是域环境可以简单实现的应用场景。
域网实现的是主-从管理模式,通过一台域控制器集中管理域内用户账户和权限,账户信息保存在域控制器内,共享信息分散在每台计算机中。在域环境下,资源的访问有较严格的管理,至少有一台服务器负责每一台连入网络的计算机和用户的验证工作,像一个单位的门卫一样,这台服务器称为“域控制器(Domain Controller,DC)”。域控制器中包含这个域的账户、密码及属于这个域的计算机等信息构成的数据库。当计算机连入网络时,域控制器首先要鉴别这台计算机是否属于这个域,用户使用的登录账户、密码是否正确。如果以上信息有一样不正确,则域控制器就会拒绝这个用户从这台计算机登录。不能登录,用户就不能访问服务器上有权限保护的资源,从而在一定程度上保护了网络上的资源,而工作组只是进行本地计算机信息与安全的认证。
6.1.2 域管理的好处
域管理的好处有如下几点:(1)方便管理。权限管理比较集中,管理人员可以较好地管理计算机资源。
(2)安全性高,有利于企业的一些保密资源的管理。比如,一个文件只能让某一个人看,或者指定的人员可以看,但不可以删、改、移等。
(3)方便对用户操作进行权限设置,可以分发、指派软件等,实现网络内的软件一起安装。
(4)使用漫游账户和文件夹重定向技术,个人账户的工作文件及数据等可以存储在服务器上统一进行备份、管理,用户的数据更加安全、有保障。
(5)方便用户使用各种资源。
(6)SMS(System Management Server)能够分发应用程序、系统补丁等,用户可以选择安装,也可以由系统管理员指派自动安装,并能集中管理系统补丁(如 Windows Updates),不需要每台客户端服务器都下载同样的补丁,从而节省了大量网络带宽。
(7)资源共享。用户和管理员可以不知道他们所需要的对象的确切名称,但是他们可能知道这个对象的一个或多个属性,他们可以通过查找对象的部分属性在域中得到一个与所有已知属性相匹配的对象列表,通过域使得基于一个或多个对象属性来查找一个对象变成可能。
(8)集中管理。域控制器集中管理用户对网络的访问,如登录、验证、访问目录和共享资源。域的实施通过提供对网络上所有对象的单点管理进一步简化了管理。因为域控制器提供了对网络上所有资源的单点登录,管理员可以登录到一台计算机来管理网络中任何计算机上的管理对象。在Windows NT网络中,当用户一次登录一个域服务器后,就可以访问该域中已经开放的全部资源,而无须对同一域进行多次登录,但在需要共享不同域中的服务时,对每个域都必须登录一次,否则无法访问未登录域服务器中的资源或无法获得未登录域的服务。
(9)可扩展性。在活动目录中,通过将目录组织成几个部分存储信息,从而允许存储大量对象。因此,目录可以随着组织的增长而一同扩展,允许用户从一个具有几百个对象的小的安装环境发展成拥有几百万对象的大型安装环境。
(10)安全性。域为用户提供了单一的登录过程来访问网络资源,如所有他们具有权限的文件、打印机和应用程序资源。也就是说,只要用户具有对资源的合适权限,用户可以登录一台计算机来使用网络上另外一台计算机上的资源。域通过对用户权限合适的划分,确定了只有对特定资源有合法权限的用户才能使用该资源,从而保障了资源使用的合法性和安全性。
(11)可冗余性。每个域控制器保存和维护目录的一个副本。在域中创建的每一个用户账户都会对应目录的一个记录。当用户登录到域中的计算机时,域控制器将按照目录检查用户名、口令、登录限制以验证用户。当存在多个域控制器时,它们会定期相互复制目录信息,域控制器间的数据复制,促使用户信息发生改变时(如用户修改了口令),可以迅速地复制到其他域控制器上,从而当一台域控制器出现故障时,用户仍然可以通过其他域控制器进行登录,保障了网络的顺利运行。
6.2.2 域和域控制器
域,是由网络管理员定义的一组计算机集合,实际上就是一个计算机网络。在这个网络中,至少有一台计算机被管理员指定为存储网络中全部对象的相关信息,这台计算机称为域控制器。在域控制器中保存着整个网络的用户账户及目录数据库,即活动目录。对网络的管理和控制。例如,管理员可以在活动目录中为每个用户创建域用户账户,使他们可登录域并访问域的资源。同时管理员可以控制所有网络用户的行为,如控制用户能否登录、在什么时间登录、登录后能执行哪些操作等。而域中的客户计算机要访问域的资源,则必须先加入域,并通过管理员创建的域用户账户登录域,才能访问域资源。
安装了活动目录的计算机称为域控制器。在第一次安装活动目录时,安装活动目录的那台计算机就成为域控制器,简称“域控”。域控制器存储着目录数据并管理用户域的交互关系,其中包括用户登录过程、身份验证和目录搜索等。一个域可以有多个域控制器。为了获得高可用性和容错能力,规模较小的域只需两个域控制器,一个实际使用,另一个用于容错性检查。规模较大的域可以使用多个域控制器。
6.2.3 域树和域林
1.域树
当配置多个域的网络时,如在 system.com 域下有 Beijing.system.com 和 Shanghai.system.com两个域空间,应该将其配置为域树的形式。如图6-2所示就是一棵域树,最上层的域名为 system.com,是该域的根域(Root Domain),也称为父域。下面的 Beijing.system.com 和 Shanghai.system.com是根域的子域。
图 6-2 中的域树符合 DNS 域名的命名规则,其名称空间是连续的,也就是子域中包含父域的域名。这是判断两个域是否属于同一棵域树的重要条件。整棵域树共享一个活动目录,即整棵域树内只有一个活动目录,不过这个活动目录是分布在不同域中的,每一个域只存储和本地域相关的配置,但在整体上形成一个大的分布式活动目录数据库。
图6-2 域树
2.域林
如果网络的规模比域树还要大,例如,它包括多棵域树,每一棵域树都有自己唯一的命名空间,则被称为域林。
整个域中存在一个根域,这个根域是域林中最先安装的域。如图 6-3 所示,sys.com是第一个存在的域,即根域,这个域林名为 sys.com。当在创建域林时,每一棵域树的根域与林根域之间双向的、转移性的信任关系都会自动被创建起来,因此每一棵域树中的每一个域内的用户,只要拥有权限,就可以访问其他任何一棵域树内的资源,也可以到其他任何一棵域树内的计算机登录。
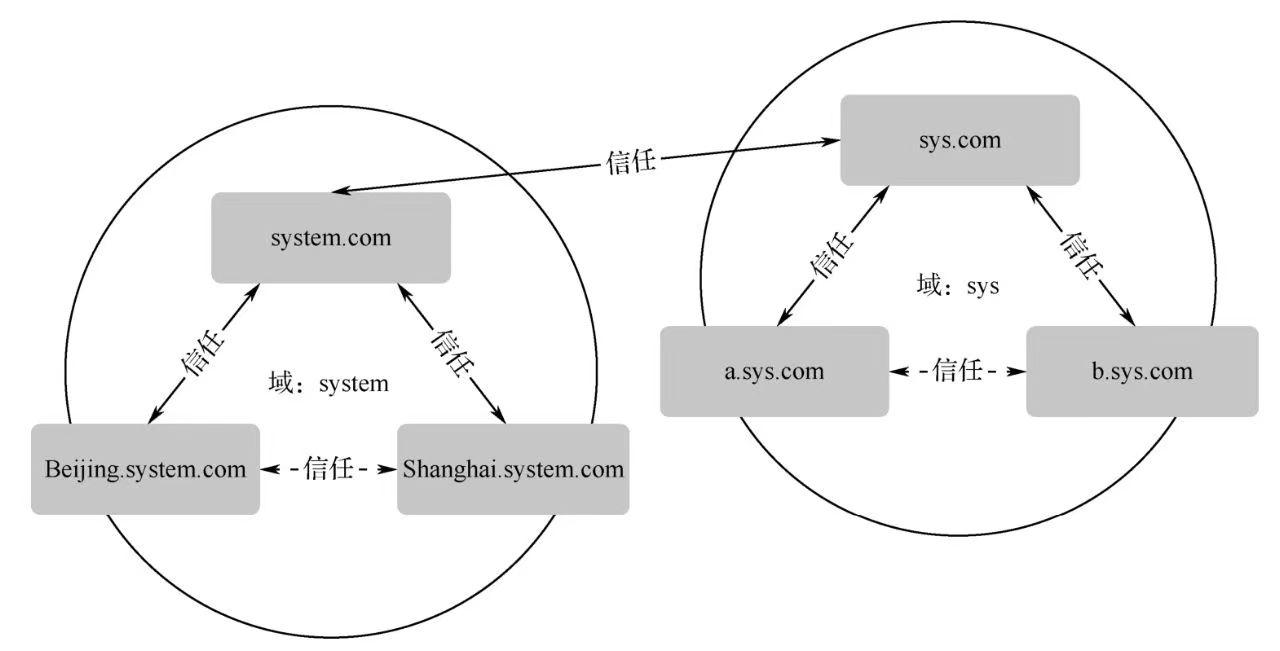
3.域间信任
两个域之间必须创建信任关系(Trust Relationship),才可以访问对方域内的资源。而任何一个新域加入域树后,这个域会自动信任其前一层父域,同时父域也会自动信任这个新子域,并且这些信任关系具备双向传递性(Two-way Transitive)。由于这个信任工作通过Kerberos Security Protocol 来完成,因此也被称为Kerros Trust。图6-4中Beijing.system.com 和 system.com 相互信任,而system.com 又与 Shanghai.system.com 相互信任。Beijing.system.com 和 Shanghai.system.com也会自动建立起双向信任关系,称为隐形的信任关系(Implicti Trust)。因此只要拥有适当权限,这个新域的用户便可访问其他域内的资源,同理其他域内的用户也可以访问这个新域内的资源。
1.恶意代码的分类
恶意代码分类的标准主要是代码的独立性和自我复制性,独立的恶意代码是指具备一个完整程序所应该具有的全部功能,能够独立传播、运行的恶意代码,这样的恶意代码不需要寄宿在另一个程序中。非独立恶意代码只是一段代码,必须嵌入某个完整的程序中,作为该程序的一个组成部分进行传播和运行。对于非独立恶意代码,自我复制过程就是将自身嵌入宿主程序的过程,这个过程也称为感染宿主程序的过程。对于独立恶意代码,自我复制过程就是将自身传播给其他系统的过程。如图7-2所示,图中称为“病毒”的恶意代码是同时具有寄生和感染特性的恶意代码,称为狭义病毒。习惯上,把一切具有自我复制能力的恶意代码统称为病毒。为和狭义病毒相区别,将这种病毒称为广义病毒。 图7-2 恶意代码的分类
1)后门
后门是某个程序的秘密入口,通过该入口启动程序,可以绕过正常的访问控制过程,因此,获悉后门的人员可以绕过访问控制过程,直接对资源进行访问。后门已经存在很长一段时间,原先的作用是程序员开发具有鉴别或登录过程的应用程序时,为避免每一次调试程序时都需输入大量鉴别或登录过程中需要的信息,通过后门启动程序的方式来绕过鉴别或登录过程。
2)逻辑炸弹
逻辑炸弹是包含在正常应用程序中的一段恶意代码,当某种条件出现,如到达某个特定日期、增加或删除某个特定文件等,将激发这一段恶意代码,执行这一段恶意代码将导致非常严重的后果,如删除系统中的重要文件和数据、使系统崩溃等。历史上不乏程序设计者利用逻辑炸弹讹诈用户和报复用户的案例。
3)特洛伊木马
特洛伊木马也是包含在正常应用程序中的一段恶意代码,一旦执行这样的应用程序,将激发恶意代码。这一段恶意代码的功能主要在于削弱系统的安全控制机制,如在系统登录程序中加入后门,以便黑客能够绕过登录过程直接访问系统资源;将共享文件的只读属性修改为可读写属性,甚至允许黑客通过远程桌面这样的工具软件控制系统。
4)病毒
这里的病毒是狭义上的恶意代码类型,单指那种既具有自我复制能力,又必须寄生在其他应用程序中的恶意代码。它和后门、逻辑炸弹的最大不同在于自我复制能力,通常情况下,后门、逻辑炸弹不会感染其他实用程序,而病毒会自动将自身添加到其他应用程序中。
5)蠕虫
从病毒的广义定义来说,蠕虫也是一种病毒,但它和狭义病毒的最大不同在于自我复制过程,病毒的自我复制过程需要人工干预,无论是运行感染病毒的实用程序,还是打开包含宏病毒的邮件,都不是由病毒程序完成的。蠕虫能够完成下述步骤:
(1)查找远程系统:能够通过检索已被攻陷系统的网络邻居列表或其他远程系统地址列表找出下一个攻击对象。
(2)建立连接:能够通过端口扫描等操作过程自动和被攻击对象建立连接,如 Telnet连接等。
(3)实施攻击:能够自动将自身通过已经建立的连接复制到被攻击的远程系统,并运行。
6)Zombie
Zombie(俗称僵尸)是一种秘密接管其他连接在网络上的系统,并以此系统为平台发起对某个特定系统的攻击功能的恶意代码。其主要用于定义恶意代码的功能,并没有涉及该恶意代码的结构和自我复制过程。
静态分析技术就是在不执行二进制程序的条件下,利用分析工具对恶意代码的静态特征和功能模块进行分析的技术。该技术可以找到恶意代码的特征字符串、特征代码段等,由于恶意代码从本质上说是由计算机指令构成的,因此根据分析过程是否考虑构成恶意代码的计算机指令的语义,可以把静态分析技术分成以下两种:
(1)基于代码特征的分析技术。在基于代码特征的分析过程中,不考虑恶意代码的指令意义,而是分析指令的统计特性、代码的结构特性等。比如,在某个特定的恶意代码中,这些静态数据会在程序的特定位置出现,并且不会随着程序副本而变化,所以完全可以使用这些静态数据和其出现的位置作为描述恶意代码的特征。语义的分析技术要求考虑构成恶意代码的指令含义,通过理解指令语义建立恶意代码的流程图和功能框图,进一步分析恶意代码的功能结构。
采用静态分析技术来分析恶意代码最大的优势是可以避免恶意代码执行过程对分析系统的破坏。但是其本身存在以下两个缺陷:
① 由于静态分析本身的局限性,导致出现问题的不可判定。
② 绝大多数静态分析技术只能识别出已知病毒或恶意代码,对多态变种和加壳病毒则无能为力。无法检测未知的恶意代码是静态分析技术的一大缺陷。
2)动态分析技术
动态分析技术是指恶意代码执行的情况下,利用程序调试工具对恶意代码实施跟踪和观察,确定恶意代码的工作过程,对静态分析结果进行验证。根据分析过程中是否需要考虑恶意代码的语义特征,将动态分析技术分为以下两种:
(1)外部观察技术。外部观察技术是指利用系统监视工具观察恶意代码运行过程中系统环境的变化,通过分析这些变化判断恶意代码功能的一种分析技术。
① 通过观察恶意代码运行过程中系统文件、系统配置和系统注册表的变化就可以分析恶意代码的自启动实现方法和进程隐藏方法:由于恶意代码作为一段程序在运行过程中通常会对系统造成一定影响,有些恶意代码为了保证自己的自启动功能和进程隐藏功能,通常会修改系统注册表和系统文件,或者会修改系统配置。
② 通过观察恶意代码运行过程中的网络活
3.权限控制技术
恶意代码要实现入侵、传播和破坏等必须具备足够权限。首先,恶意代码只有被运行才能实现其恶意目的,所以恶意代码进入系统后必须具有运行权限。其次,被运行的恶意代码如果要修改、破坏其他文件,则必须具有对该文件的写权限,否则会被系统禁止。另外,如果恶意代码要窃取其他文件信息,其必须具有对该文件的读权限。
权限控制技术通过适当控制计算机系统中程序的权限,使其仅仅具有完成正常任务的最小权限,即使该程序中包含恶意代码,该恶意代码也不能或不能完全实现其恶意目的。通过权限控制技术来防御恶意代码的技术主要有以下两种。
1)沙箱技术
沙箱技术是指系统根据每个应用程序可以访问的资源,以及系统授权给该应用程序的权限建立一个属于该应用程序的“沙箱”,限制恶意代码运行。每个应用程序及操作系统和驱动程序都运行在自己受保护的“沙箱”中,不能影响其他程序的运行,也不能影响操作系统的正常运行。沙箱技术实现的典型实例就是由加州大学伯克利实验室开发的一个基于 Solaris 操作系统的沙箱系统。该系统首先为每个直用程序建立一个配置文件,在配置文件中规定了该应用程序可以访问的资源和系统赋予的权限。当应用程序运行时,通过调用系统底层函数解释执行,系统自动判断应用程序调用的底层函数是否符合系统的安全要求,并决定是否执行。
2)安全操作系统
恶意代码要实现成功入侵的重要一环,就是其必须使操作系统为其分配系统资源。如果能够合理控制程序对系统的操作权限,则程序对系统可能造成的破坏将被限制。安全操作系统具有一套强制访问控制机制,它首先将计算机系统划分为3个空间:系统管理空间、用户空间和保护空间。其次将进入系统的用户划分为不具有特权的普通用户和系统管理员两类。系统用户对系统空间的访问必须遵循以下原则:
(1)系统管理空间不能被普通用户读写,
而用户空间包含用户的应用程序和数据,可以被用户读写。
(2)保护空间的程序和数据不能被用户空间的进程修改,但可以被用户空间的进程读取。
(3)一般通用的命令和应用程序放在保护空间内,供用户使用。由于普通用户对保护空间的数据只能读不能写,从而限制了恶意代码的传播。
(4)在用户空间内,不同用户的安全级别不同,恶意代码只能感染同级别用户的程序和数据,限制了恶意代码的传播范围。
4.完整性技术
完整性技术就是通过保证系统资源,特别是系统中重要资源的完整性不受破坏,来阻止恶意代码对系统资源的感染和破坏。运用校验和法检查恶意代码有3种方法:
(1)在恶意代码检测软件中设置校验和法。对检测的对象文件计算其正常状态的校验和并将其写入被查文件或检测工具中,然后进行比较。
(2)在应用程序中嵌入校验和法。将文件正常状态的校验和写入文件本身,每当应用程序启动时,比较现行校验和与原始校验和,实现应用程序的自我检测功能。
(3)将校验和程序常驻内存。当应用程序开始运行时,自动比较检查应用程序内部或别的文件中预留保存的校验和。
校验和法能够检测未知恶意代码对目标文件的修改,但存在两个缺点:①校验和法实际上不找文件的变化,并且即使发现文件发生了变化,也既无法将恶意代码消除,又不能判断所感染的恶意代码类型;②校验和法常被恶意代码通过多种手段欺骗,使之检测失效,而误判断文件没有发生改变。在恶意代码对抗与反对抗的发展过程中,还存在其他一些防御恶意代码的技术和方法,如常用的有网络隔离技术和防火墙控制技术,以及基于生物免疫的病毒防范技术、基于移动代理的恶意代码检测技术等。
7.2 安全准入
7.2.1 安全准入概述
企业通过部署安全准入控制,主要解决传统网络的如下问题:
● 网络被随意接入,无法定位身份:企业网络可以被外部设备随意接入,外部病毒极易入侵,对企业网络安全造成巨大威胁。
● 非法外联不可控:终端连接互联网的方式众多,私接无线网卡、无线WiFi、4G手机代理等方式均可以绕过内网的监控直接连接外网,向外部敞开大门。
● 终端安全性无法保障:企业人员多,终端数量多,无法保障每台终端是否安装了补丁、防病毒软件等。
● 移动U盘随意使用,导致数据泄密:企业对移动存储介质无法管控,造成U盘泄密事件时常发生,无法跟踪管理。
随着互联网的普及和电子商务技术的飞速发展,越来越多的员工、客户和合作伙伴希望能够随时随地接入公司的内部网络,访问公司的内部资源。很多人通过将终端的3389端口映射出去或在终端上安装TeamViewer等软件接入,但接入用户的身份可能不合法,远端接入主机可能不够安全,这些都为公司内部网络带来了安全隐患。
针对这一问题,可使用虚拟专用网络(Virtual Private Network,VPN)技术来解决。VPN 通过在公用网络上建立专用网络进行加密通信,在企业网络中有广泛应用。VPN 网关通过对数据包的加密和数据包目的地址的转换来实现远程访问。VPN 可通过服务器、硬件、软件等多种方式实现。
8.1 VPN概述
VPN 按照层次可以分为 L2VPN (二层 VPN,如 PPTP、L2TP)、L3VPN (三层VPN,如IPSec VPN、GRE VPN、MPLS VPN)、应用层VPN(如SSL VPN)。
PPTP(Point to Point Tunneling Protocol):点对点隧道协议。该协议是在PPP的基础上开发的一种新的增强型安全协议,支持多协议虚拟专用网,可以通过密码验证协议(PAP)、可扩展认证协议(EAP)等方法增安全性,也可以使远程用户通过拨入 ISP、通过直接连接Internet或其他网络安全地访问企业网。
L2TP:工业标准的Internet隧道协议。其功能大致和PPTP类似,例如,同样可以对网络数据流进行加密。不过也有不同之处,如PPTP要求网络为IP网络,L2TP要求面向数据包的点对点连接;PPTP 使用单一隧道,L2TP 使用多隧道;L2TP 提供包头压缩、隧道验证,而PPTP不支持。
IPSec(Internet Protocol Security):由Internet Engineering Task Force (IETF) 定义的安全标准框架,用于提供公用和专用网络的端对端加密和验证服务。IPSec 是一套比较完整成体系的VPN技术,其规定了一系列的协议标准。
GRE 是 VPN(Virtual Private Network)的第三层隧道协议,即在协议层之间采用了一种被称为Tunnel(隧道)的技术。
MPLS VPN是一种基于MPLS技术的IP-VPN,根据PE(Provider Edge)设备是否参与VPN路由处理又细分为二层VPN和三层VPN,一般而言,MPLS/BGP VPN指的是三层VPN。
SSL VPN指的是基于安全套层协议(Security Socket Layer,SSL)建立远程安全访问通道的 VPN 技术,它是近年来兴起的 VPN 技术,其应用随着 Web 的普及和电子商务、远程办公的兴起而迅速发展。
部分运营商还提供VPDN,VPDN的全称
为Virtual Private Dialup Network,又称为虚拟专用拨号网,是 VPN 业务的一种,是基于拨号用户的虚拟专用网业务,即以拨号接入方式上网,是利用 IP 网络的承载功能结合相应的认证和授权机制建立起来的安全虚拟专用网,也是近年来随着 Internet 的发展而迅速发展起来的一种技术。严格来说,VPDN 也属于二层 VPN,但其网络构成和协议设计与其他 L2VPN 有很大不同。在 IP 报文进行封装时,VPDN方式需要封装多次,第一次封装使用L2TP,第二次封装使用UDP。
IPSec VPN和SSL VPN是目前流行的两类Internet远程安全接入技术,它们具有类似的功能特性,但也存在很大不同。
8.2.1 密码学的发展历程随着信息化和数字化社会的发展,人们对信息安全和保密的重要性认识不断提高,而在信息安全中起着举足轻重作用的密码学也就成为信息安全课程中不可或缺的重要部分,密码学以研究秘密通信为目的,即对所要传送的信息采取一种秘密保护,以防止第三者对信息的窃取。密码学早在公元前400年就已经产生,人类使用密码的历史几乎与使用文字的时间一样长。密码学的发展过程可以分为以下4个阶段。
1.古代加密方法
古代加密方法大约起源于公元前 400 年,斯巴达人发明了“塞塔式密码”,即把长条纸螺旋形地斜绕在一个多棱棒上,将文字沿棒的水平方向从左到右书写,写一个字旋转一下,写完一行再另起一行从左到右写,直到写完。纸条上的文字消息杂乱无章无法理解,这就是密文,但将它绕在另一个同等尺寸的棒子上后,就能看到原始的消息。这是最早的密码学技术。我国古代也早有以藏头诗、藏尾诗、漏格诗及绘画等形式,将要表达的真正意思或“密语”隐藏在诗文或画卷中特定位置的记载,一般人只注意诗或画的表面意境,而不会去注意或很难发现隐藏其中的“话外之音”。
如《水浒传》中梁山为了拉卢俊义入伙,“智多星”吴用和宋江便生出一段“吴用智赚玉麒麟”的故事来,利用卢俊义正为躲避“血光之灾”的惶恐心理,口占四句卦歌:
芦花丛里一扁舟,
俊杰俄从此地游。
义士若能知此理,
反躬难逃可无忧。
暗藏“卢俊义反”四字。结果,成了官府治罪的证据,终于把卢俊义“逼”上了梁山。更广为人知的是唐伯虎写的“我爱秋香”:
我画蓝江水悠悠,
爱晚亭上枫叶愁。
秋月溶溶照佛寺,
香烟袅袅绕经楼。
2.古典密码
古典密码的加密方法一般是文字置换,使用手工或机械变换的方式实现。古典密码系统已经初步体现出近代密码系统的雏形,其比古代加密方法复杂,变化较小。古典密码学主要有两大基本方法:
置换密码(又称易位密码):明文中的字母保持相同,但顺序被打乱了。
代替密码:将明文中的字符替换为密文中的另一种字符,接收者只要对密文做反向替换就可以恢复出明文。
(1)置换密码示例:列置换密码(矩阵置换密码)
明文:ming chen jiu dian fa dong fan gong
密钥:yu lan hua
去掉密钥重复字母:yulanh,得出矩阵列数为6,将明文按行填充矩阵。
得到密钥字母顺序:653142。
按列(依顺序)写出矩阵中的字母。
密文:giffg hddno njngn cuaao inanmeiog。
解密:加密的逆过程。
(2)代替密码示例:恺撒(Caesar)密码
在罗马帝国时期,恺撒大帝曾经设计过一种简单的移位密码,用于战时通信。这种加密方法就是将明文的字母按照顺序,向后依次递推相同的字母,就可以得到加密的密文,而解密的过程正好和加密的过程相反。例如,明文 battleonSunday 密文wvoogzgiNpiyvt(将字母依次后移 5 位)。如果令各字母分别对应于整数,则恺撒加密方法实际上是进行了一次数学取模为 26 的同余运算,即其中 m 是明文对应的数据,c是与明文对应的密文数据,k 是加密用的参数,也叫密钥。比如,battleonSunday 对应数据序列为 0201202012051514192114040125,若取密钥 k 为 5,则得密文序列为0706252517102019240019090604。我们也可以用数字来代替字母进行信息传递,也方便用数学变换和计算机编程进行加密与解密。
3.近代密码
美国利用计算机轻松破译了日本的紫密密码,使日本在中途岛海战中一败涂地。1943年,在获悉山本五十六将于4月18日乘中型轰炸机,由6架战斗机护航,到中途岛视察时,罗斯福总统决定截击山本,山本乘坐的飞机在去往中途岛的路上被美军击毁,山本坠机身亡,日本海军从此一蹶不振。密码学的发展直接影响了第二次世界大战的战局。
密码编码和密码破译的斗争是一种特殊形式的斗争,这种斗争的一个重要特点是其隐蔽性。无论是使用密码的一方,还是破译密码的一方,他们的工作都在十分秘密地进行。特别是,对于他们工作的最新进展更是严格保密。当一方改进了自己的密码编码方法时,他不会公开所取得的进展;当另一方破译了对方的密码时,他也不会轻易泄露破译成果和使用破译所取得的情报,以便能长期获取情报并取得更有价值的信息。密码战线上的斗争是一种无形的、不分空间和时间的、隐蔽的战争。无数历史事实证明,战争的胜负在很大程度上依靠密码...
2.非对称密码
在非对称密码中,解密的密钥与加密的密钥不一致。用公钥加密,用私钥解密;或者用私钥加密,用公钥解密。主要的密码算法包含RSA.Elgamal、背包算法、Rabin、D-H、ECC(椭圆曲线加密算法)等。非对称密码学的特点如下:
(1)使用非对称密码技术时,用一个密钥加密的东西只能用另一个密钥来解密。
(2)非对称加密是安全的。
(3)因为不必发送密钥给接收者,所以非对称加密情况下不必担心密钥被中途截获。
(4)需要分发的密钥数目和参与者的数目一样。
(5)非对称密码技术没有复杂的密钥分发问题。
(6)非对称密码技术不需要事先在各参与者之间建立关系及交换密钥。
(7)非对称密码技术支持数字签名和不可否认性。
(8)非对称加密速度相对较慢。
(9)非对称加密会造成密文较长。
3.混合加密
通过上面的对比可知,对称密码加密速度快,非对称密码安全。如果要对一个大文件进行加密,通常会用对称密码对明文进行加密,用非对称密码对对称密码的密钥进行加密。这种方式即为混合加密。
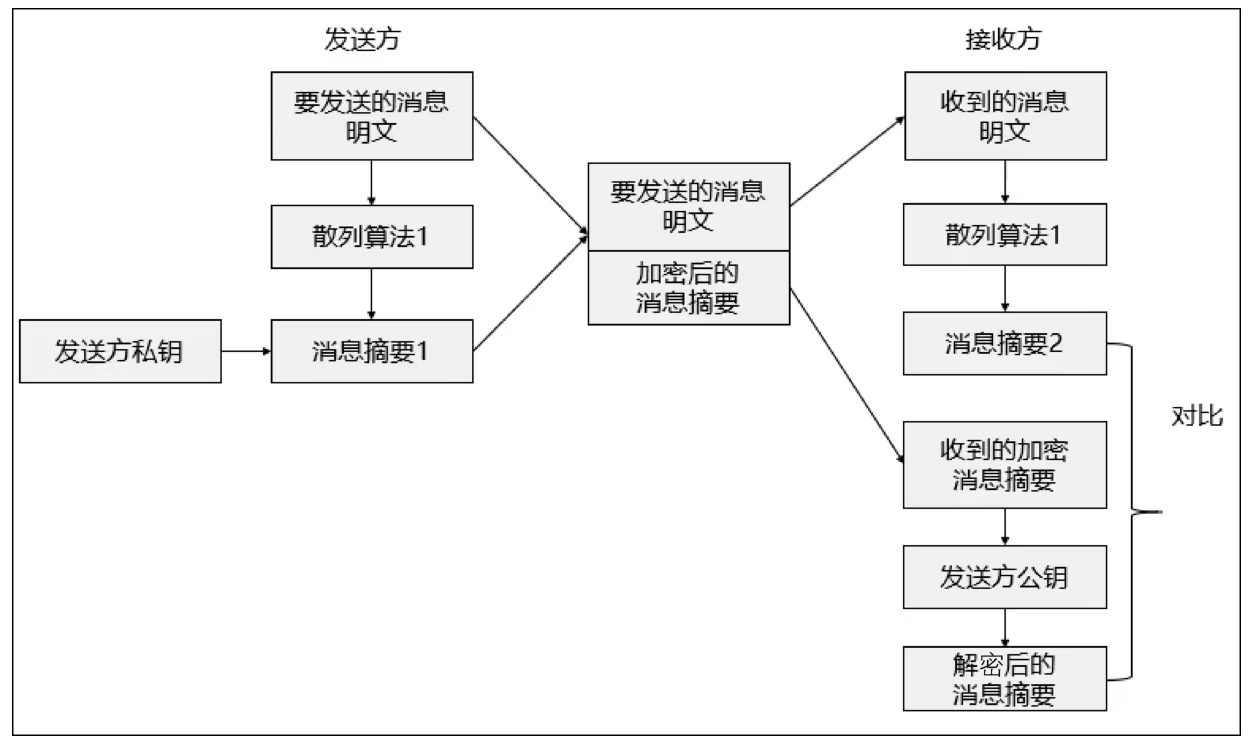
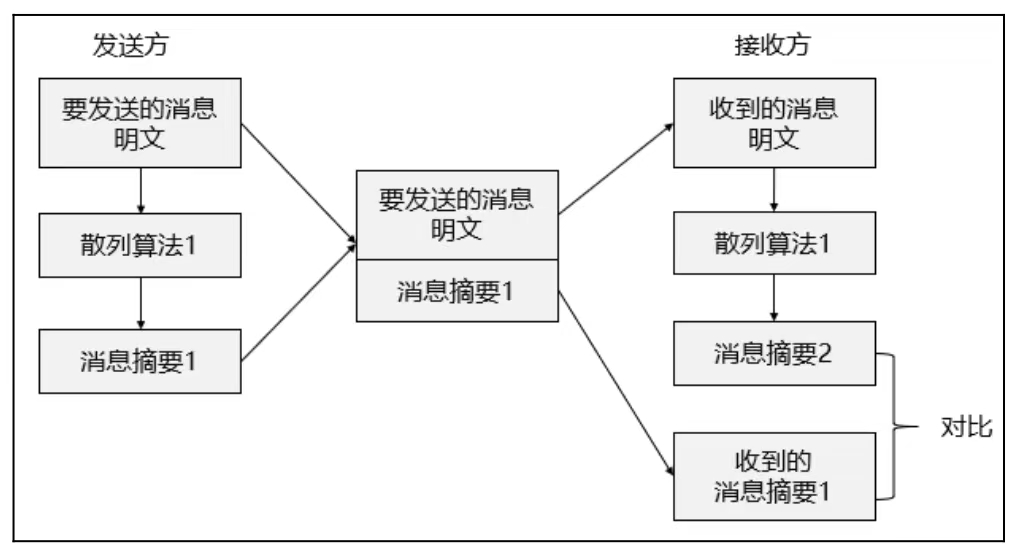
4.散列算法1)数字摘要
有很多协议使用校验位和循环冗余校验(Cyclic Redundancy Check,CRC)函数来检测位流从一台计算机传送到另一台计算机时是否被更改,但校验位和循环冗余校验通常只能检测出无意的更改。如果消息被入侵者截获,在更改之后重新计算校验值,这样接收方永远也不会知道位流被篡改。为了实现这种保护,需要采用散列算法来检测有意或无意对数据的未授权更改。Hash(哈希)函数(也称为散列函数):输入可以是任何长度消息,通过一个单向运算产生一个定长输出。这个输出被称为 Hash 值(散列值,也称为哈希摘要),其特点如下。
(1)Hash值应是不可预测的。
(2)Hash函数是单向函数,不可逆。
(3)Hash函数具有确定性(唯一性),对于输入x应该总是产生相同的输出y。
(4)寻找任何(x,y)对使得H(x)=H(y)。
(5)对任何给定分组x,寻找不等于x的y,使得H(y)=H(x),在计算上不可行(弱无碰撞)。
散列的种类见表8-1。
表8-1 散列的种类
为保证数据在传输过程中的完整性,如图
8.3 VPN技术
8.3.1 GRE
GRE 是一种隧道协议,从技术上来看也是一种 VPN,因为其实现相对比较简单,本章通过GRE 实验来简单理解 VPN。路由封装(GRE)最早是由Cisco 提出的,目前已经成为一种标准,被定义在RFC1701、RFC1702及RFC2784中。简单来说,GRE用来从一个网络向另一个网络传输数据包。GRE 并不是一个安全的隧道方式,但我们可以使用某种加密协议对GRE进行加密,如GRE和IPSec协议共同使用。GRE的工作原理如图8-3所示,在原始数据包前封装 GRE 包头,再封装公网 IP,形成最终的数据包从隧道起点发出去。对端即隧道终点,也需要配置GRE。
8.3.2 IPSec VPN
1.概述
IPSec VPN 是一种三层隧道协议。三层隧道是指把各种网络协议直接装入隧道协议中,形成的数据包依靠第三层协议进行传输。IPSec 是一种由 IETF 设计的端到端的、确保基于 IP 通信的数据安全性机制。它为 Internet 上传输的数据提供了高质量、基于密码学的安全保证。IPSec VPN的工作模式如图8-5所示。
“安全联盟”(IPSec 术语,常简称为 SA)是构成 IPSec 的基础。SA 是两个通信实体经协商建立起来的一种协定。它们决定了用来保护数据包安全的IPSec协议、转码方式、密钥及密钥的有效存在时间等。任何 IPSec 实施方案始终会构建一个 SA 数据库(SADB),由它来维护IPSec协议用来保障数据包安全的SA记录。
图8-5 IPSec VPN的工作模式
SA是单向的。如果两个主机(A和B)正在通过ESP进行安全通信,那么主机A就需要一个SA,即SA(out),用来处理外发的数据包;另外还需要一个不同的SA,即SA (in),用来处理进入的数据包。主机 A 的 SA(out)和主机 B 的 SA(in)将共享相同的加密参数(如密钥)。SA还是“与协议相关”的,每种协议都有一个SA。如果主机A和主机 B 同时通过 AH 和 ESP 进行安全通信,那么每个主机都会针对每一种协议来构建一个独立的SA。
2.IPSec组成
针对 Internet 的安全需求,IETF(互联网工程任务组)于 1998 年 11 月颁发了 IP 层安全协议 IPSec。它不是一个单独的协议,而是一个协议框架。IPSec 是 IP 安全协议标准,是在 IP 层为 IP 业务提供保护的安全协议标准,其基本目的就是把安全机制引入 IP协议。IPSec在IPv6中必须支持,在IPv4中则是可选的。协议框架如图8-6所示。
图8-6 IPSec协议框架
1)ESP
封装安全载荷协议(Encapsulating Security Payload,ESP)是一种 IPSec 协议,用于对IP协议在传输过程中进行数据完整性度量、来源认证、加密及防回放攻击。可以单独使用,也可以和 AH 一起使用。在 ESP 头部之前的 IPV4、IPV6 或拓展头部,应该在 Protocol (IPV4)或Next Header(IPV6、拓展头部)部分中包含50,表示引入了ESP协议。
ESP 通常使用 DES、3DES、AES 等加密算法对要保密的用户数据进行加密,然后封装到一个新的 IP 包头中。使用 MD5、SHA 实现数据完整性验证。加密是 ESP 的基本功能,而身份认证、数据完整性、防止重放攻击都是可选的。
ESP有两种模式:隧道模式和传输模式。隧道模式将发送的整个数据报文作为一个数据整体来处理,在整段数据前加上新的 IP 进行传输,不修改原报文。对于传输模式而言,需要拆解报文,对原报文的数据部分进行处理,加上 ESP 头部后,再装上原报文的IP部分。
3.工作模式
IPSec VPN有两种工作模式,分别是隧道模式和传输模式。
(1)隧道模式
隧道模式保护所有 IP 数据并封装新的 IP 头部,不使用原始 IP 头部进行路由。在IPSec头部前加入新的IP头部,源IP地址和目的IP地址为IPSec peer地址,并允许RFC 1918(私有地址)规定的地址参与 VPN 穿越互联网。
(2)传输模式
传输模式保护原始IP头部后面的数据,在原始IP头部和payload间插入IPSec头部(ESP 或 AH)。通常,传输模式应用于两台主机之间的通信,或者一台主机和一个安全网关之间的通信。在隧道模式和传输模式下的数据封装形式如图 8-16 所示,图中 data 为原IP报文。
.3.3 SSL VPN
1.概述
越来越多的企业通过 Internet 来满足员工、客户及合作伙伴的各种通信需求,允许他们随时随地访问企业内部的资源,这势必将企业的内部网络暴露在可被攻击的环境下,所以需要提供一种安全接入机制来保障通信及敏感信息的安全。SSL VPN 凭借着简单易用的安全接入方式、丰富有效的权限管理,跨平台、免安装、免维护的客户端等特点迅速普及开来,如图8-17所示 图8-17 部署SSL VPN设备
通过部署SSL VPN设备到网络,可以实现从互联网中各种不同类型设备经过VPN加密连接到公司内网,对登录用户做权限划分,使之只能访问权限内的业务,提高网络的安全性。SSL VPN是以HTTPS为基础的VPN技术,它利用SSL协议提供的基于证书的身份认证、数据加密和消息完整性验证机制,为用户远程访问企业内部网络提供了安全保障。SSL VPN 是一种低成本、高安全性、简便易用的远程访问解决方案,具备相当大的发展潜力。
2.SSL协议
安全套接字层(Secure Sockets Layer,SSL)协议是位于计算机网络体系结构的传输层和应用层之间的套接字(Socket)协议的安全版本,可为基于公网的通信提供安全保障。SSL协议广泛应用于电子商务、网上银行等领域。SSL VPN使用的就是SSL协议。
SSL可使客户端与服务器之间的通信不被攻击者窃听,并且远程客户端通过数字证书始终对服务器(SSL VPN 网关)进行认证,还可选择对客户端进行认证。SSL 目前有三个版本:2、3、3.1。常用的是第3版。
1)SSL协议的三个特性
(1)保密性:在握手协议中定义了会话密钥后,所有消息都被加密。
图8-18 SSL的位置
(2)鉴别:可选的客户端认证和强制的服务器端认证。
(3)完整性:传送的消息包括消息完整性检查(使用MAC)。
SSL的位置如图8-18所示,SSL介于应用层和TCP层之间,应用层数据不再直接传递给传输层,而是传递给 SSL 层,SSL 层对从应用层收到的数据进行加密,并增加自己的SSL头。
2)SSL的工作原理
握手协议是客户机和服务器用 SSL 连接通信时使用的第一个子协议,握手协议包括客户机与服务器之间的一系列消息。SSL中最复杂的协议就是握手协议。该协议允许服务器和客户机相互验证,协商加密和MAC算法及保密密钥,用来保护在SSL记录中发送的数据。握手协议是在应用程序的数据传输之前使用的。每个握手协议包含以下3个字段:
(1)Type:表示10种消息类型之一。
(2)Length:表示消息长度字节数。
(3)Content:与消息相关的参数。
3)SSL的总结
(1)SSL协议的优点。
① 提供较高的安全性保证:SSL 利用数字证书及其中的 RSA 密钥对提供数据加密、身份验证和消息完整性验证机制,为基于 TCP 协议可靠连接的应用层协议提供安全性保证。
② 支持各种应用层协议:由于 SSL 位于应用层和传输层之间,所以可为任何基于TCP可靠连接的应用层协议提供安全性保证。
③ 部署简单:基于SSL的应用是最普通的B/S架构,用户只需要使用支持SSL协议的浏览器,即可通过SSL以Web的方式安全访问外部的Web资源。
(2)SSL协议的安全性。
通过在SSL服务器端配置AAA认证方案,可确保仅合法客户端可以安全地访问服务器,禁止非法客户端访问服务器。通过在 SSL 服务器端申请本地证书,客户机导入服务器的本地证书,可确保客户端所访问的服务器是合法的,而不会被重定向到非法服务器上。客户端与服务器之间交互的数据通过使用服务器端本地证书中所带的 RSA 密钥进行加密或数字签名,加密保证了传输的安全性,签名保证了数据的完整性,从而实现了对设备的安全管理。
(3)IPsec VPN的不足。
IPsec VPN比较适合固定连接,对访问控制要求不高的场合,无法满足用户随时随地以多种方式接入网络、对用户访问权限进行严格限制的需求。这导致其存在一些不足:部署IPsec VPN网络时,需要在用户主机上安装客户端软件;无法检查用户主机的安全性;访问控制不够细致;在复杂的组网环境中,IPsec VPN部署困难。
3.SSL VPN
SSL VPN 为远程访问解决方案而设计,不提供站点到站点的连接,主要提供基于Web 的应用程序的安全访问,用户通常不需要在桌面上安装任何特殊的客户端软件。SSL协议位于传输层上,用于保障在Internet上基于Web的通信安全,这使得SSL VPN可以穿透NAT设备和防火墙运行。用户只需要使用集成了SSL协议的Web浏览器就可以接入VPN,实现随时随地地访问企业内部网络,且无须任何配置。与 IPSec VPN 相比,SSL VPN 技术具有组网灵活性强、管理维护成本低、用户操作简便等优点,更加符合越来越多移动式、分布式办公的需求。SSL VPN的典型组网架构如图8-24所示。
本篇摘要
本篇旨在帮助读者理解以下概念:
1.网站和网站群架构
● 网站架构演化历史,详细了解网站的架构。
● HTTP协议,包括HTTP报文、请求方法及状态码等。
● 网站架构的核心组成,包括操作系统、数据库、中间件及Web应用程序的内容。
2.网站群面临的安全威胁
● 安全威胁,包括数据窃取、挂马、暗链、DDoS、钓鱼等。
● 攻击流程,包括信息收集、漏洞扫描、漏洞利用、权限提升等内容。
● 其他漏洞利用手段,包括 SQL 注入漏洞、上传及解析漏洞、框架漏洞、逻辑篡改漏洞等。
3.网站系统的安全建设
● Web代码的安全建设,包括安全开发生命周期、代码审计。
● Web业务的安全建设,包括各类业务逻辑漏洞。
● Web IT架构安全建设,包括WAF、网页防篡改、抗DDOS、云监测、云防护、数据库审计。
4.安全事件应急响应● 应急响应介绍,包括应急响应分类、分级。
● 信息安全事件的处理流程。
● 信息安全事件的上报流程。
● 应急响应部署与策略,包括应急工作目标及建立应急项目小组。
● 应急响应具体实施,包括准备阶段、检测阶段、抑制阶段、根除阶段、恢复阶段、跟踪阶段、总结。
● Web应急响应关键技术,包括Windows应急响应、Linux应急响应。
11.1 网站架构演化历史
1991年8月6日,蒂姆·伯纳斯·李在alt.hypertext新闻组上贴了万维网项目简介的文章。这一天也标志着因特网上万维网公共服务的首次亮相。在 30 年的时间里,互联网的世界发生了巨大变化,至今,全球有近一半的人口使用互联网,人们的生活因为互联网而产生了巨大种趋势还在加速。因为互联网,我们的世界正变得越来越小。
在互联网跨越式发展的进程中,电子商务火热的市场背后却是不堪重负的网站架构,某些 B2C 网站逢促销必死机几乎成为一种规律,而中国铁路总公司电子客票官方购票网站的频繁故障和操作延迟更将这一现象演绎得淋漓尽致,当然现在已经做得很好了。那大型网站有哪些特点呢?
高并发:需要面对高并发用户,大流量访问,Google 日均页面访问量为 35 亿人次,日均IP访问数为3亿个,微信在全球月活跃用户数首次突破10亿大关,天猫一天的交易额为2135亿元人民币,交易峰值达到49.1万笔每秒。
高可用:7×24小时不间断提供服务。大型网站的死机一般会成为焦点,如2010年百度域名被黑客劫持事件、“双 11”淘宝死机事件、12306 网站并发数过高的死机事件、微博流量明星死机事件。
海量数据:大型网站的用户基数大是其特点之一,如新浪微博月活跃用户为 5 亿个左右,百度收录的页面有数百亿个之多。
用户分布广:许多大型网站的服务用户分布在全国各地,甚至全球范围。在国内有南北网络差异,导致不同地域的用户会选择不同的运营商访问网站。在全球该问题更突出,使得很多大型网站在全球各地都会部署数据中心来提高网站访问速度。
安全问题突出:网络安全已经成为每个小型或大型网站的头等大事,网站被入侵、数据泄露已经成为互联网网站每日话题,屡见不鲜。
1.网站发展初期
所有大型网站都是由小型网站发展而来的,起初都要先解决某一个或某一类问题,由于访问人数不多,所以只需要单台服务器即可满足需求。一个小型网站一般由应用服务器中应用程序、文件、数据库即可组成,如图 11-1 所示。最常见的是操作系统采用Linux、网站程序采用PHP、数据库采用MySQL的方式组合,此组合方式简单而高效。
图11-1 初始阶段的网站架构
随着业务的发展,用户的增加会导致网站访问速度越来越慢、数据存储得越来越多,单台服务器无法满足当前的业务量。为了解决当前问题,可以给服务器增加内存、硬盘等硬件,但单台服务器总有瓶颈。需要考虑让应用程序服务器、文件服务器、数据库服务器三者分离开,使其各司其职,充分发挥自己的优势。如图 11-2 所示,应用程序服务器更需要强大的 CPU 和内存,文件服务器需要更大的硬盘,数据库服务器需要更大的硬盘和内存。这样做的好处是让不同的服务器承担不同的角色,将其自身的能力发挥到极致,对于企业来说也是节约成本的一种方式。
图11-2 应用程序服务器、文件服务器、数据库服务器分离
网站的开发最终要服务于用户,如淘宝要服务于客户浏览商品、购买商品,Google要服务于客户搜索资料。并不是所有的商品都是“爆款”,根据二八定律,80%的用户都在访问 20%的数据,对于数据来说,读取和写入的也是 20%的商品的数据。可以总结为大部分浏览都集中在了小部分数据上,那么是否可以提高对这些数据的访问速度?在计算机中,内存的访问速度是最高的,是否可以将访问量大的数据放到内存中?答案是肯定的,如图11-3所示。
图11-3 使用缓存改善网站性能
网站的缓存分为两种:本地缓存、远程缓存。从速度上说,本地缓存要快于远程缓存,因为不需要发送网络请求。远程缓存的优势在于内存大,缓存数据多,可以持久化;本地缓存的优势在于速度快,但内存小,缓存的数据有限制,且不可持久化,如遇计算机故障造成关机重启,数据便会消失。使用缓存后可以减小数据库服务器的压力,减少了读写次数。但如果访问量基数足够大,应用程序服务器本身处理这些HTTP请求便已经到达瓶颈,数据缓存便起不到作用。
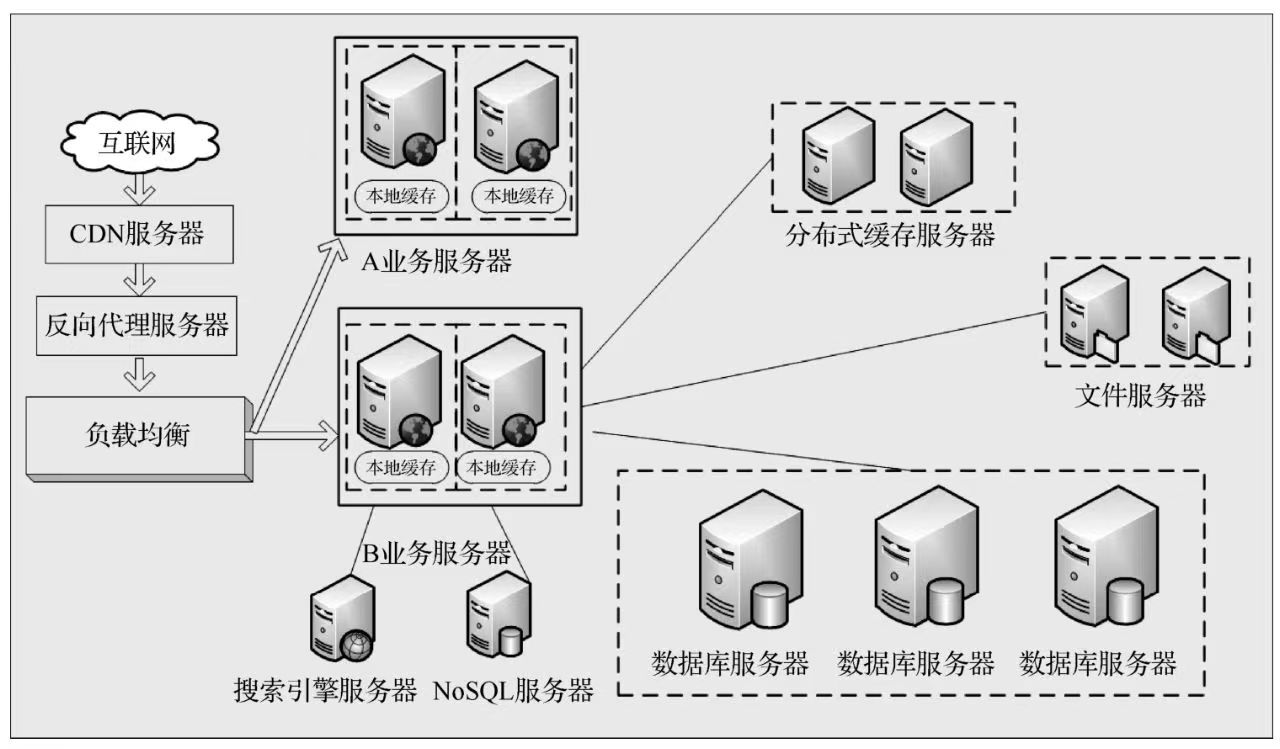
2.网站发展中期
当用户基数足够大,单台服务器应对困难时,有两种解决方法:单台服务器性能再次提升;使用集群。通常解决高并发问题的手段是使用集群,将所有的服务器进行集群部署,使用负载均衡策略对服务器收到的请求做负载控制。当用户数再次增加时,只需要将新服务器加入集群即可,这解决了服务器再次成为网站瓶颈的问题,如图11-4所示。
图11-4 应用服务器集群
在网站中数据库的操作可以分为增、删、改、查(Insert、Delete、Update、Select),增、删、改是写入操作,查询是读取操作。大多数互联网业务中,往往读多写少,这时数据库的“读操作”会首先成为数据库的瓶颈。这时,如果希望能够线性地提升数据库的读性能,消除读写锁冲突,提升数据库的写性能,可以采用读写分离架构。要实现“读写分离”,就要解决主从数据库数据同步的问题,在主数据库写入数据后要保证从数据库中的数据也要同步更新。通过设置主从数据库实现“读写分离”,主数据库负责“操作”,从数据库负责“读操作”。根据压力情况,从数据库可以部署多个,以提高“读”的速度,借此来提高系统总体性能。数据库读写分离如图11-5所示。
前面介绍的是针对网站自身的性能优化方法,但随着用户群的增加,来自不同区域的用户访问网站时的速度和体验是截然不同的。跨运营商访问会导致访问速度变慢,影响用户体验,最终导致用户流失,网站便失去了存在的价值。如果要优化用户体验,提高网站访问速度,可以采用CDN和反向代理方式,如图11-6所示。
CDN 其实就是很多服务器都有的静态资源备份,当用户请求时,通过主服务器对用户的IP进行地址判断,选择离用户最近的服务器,并且将最近的IP返回给用户,让用户去请求这个 IP 的服务器。反向代理与 CDN 的区别是:CDN 要部署到运营商机房;反向代理则部署在网站的中心机房。两者的目的都是减少用户访问等待时间,让客户更快地看到网站内容,同时也减轻了服务器压力。
图11-5 数据库读写分离
反向代理是指用代理服务器来接收 Internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 Internet 上请求连接的客户端,此时代理
服务器对外就表现为一个反向代理服务器。反向代理可以实现负载均衡,提高访问速度,提供安全保障等效果。
图11-6 使用反向代理和CDN加速网站响应
网站服务器进行分布式处理,随着业务的增长,文件系统和数据库系统同样需要做分布式处理。文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点(可简单地理解为一台计算机)相连。分布式文件系统的设计基于客户机/服务器模式,一个典型的网络可能包括多个供多用户访问的服务器。分布式数据库是网站数据库拆分的最后阶段。在数据库中经常出现单表数据量巨大的情况,此时需要数据库的分库和分表(有水平切分和垂直切分的分别)。使用分布式文件系统和分布式数据库系统如图11-7所示。
图11-7 使用分布式文件系统和分布式数据库系统
使用 NoSQL 的原因在于:传统的数据库扩展性较差,虽然关系数据库很强大,但是它不能很好地应付所有的应用场景。例如 MySQL 的扩展性差(需要复杂的技术来实现),大数据量场景下IO压力大,表结构更改困难。
NoSQL 数据库种类繁多,但是都有一个共同的特点,即都去掉了关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。在架构的层面上无形之中带来了可扩展的能力。同时NoSQL数据库均具有非常好的读写性能,尤其是在大数据量的情况下同样表现优秀。
使用NoSQL和搜索引擎如图11-8所示。
图11-8 使用NoSQL和搜索引擎
3.网站发展现状
大型网站业务种类多,为了更好地应对复杂的业务场景,需要将网站的功能用不同的子产品开发。这样做的主要目的是降低功能之间的耦合度和发布困难的问题。各个子产品各自开发、独立部署,其中某一子产品的升级并不会影响网站的整体功能,如图11-9所示。
例如,根据业务属性进行垂直切分,划分为产品子系统、购物子系统、支付子系统、评论子系统、客服子系统、接口子系统(对接如进销存、短信等外部系统)。根据业务子系统等级进行划分,可分为核心系统和非核心系统,核心系统包括产品子系统、购物子系统和支付子系统,非核
心系统包括评论子系统、客服子系统和接口子系统。
图11-9 子产品各自开发独立部署
业务拆分、数据库拆分、文件系统拆分会导致整个系统变得难以维护,如图11-10 所示。每个应用系统都需要连接数据库、访问文件系统,这会导致数据库连接资源不足,造成拒绝服务。
图11-10 分布式服务
此时需要采用一些面向对象的开发思路,将所有的应用系统进行归类总结,将业务进行抽象,把相同的业务提取出来,这些可复用的功能抽象为公共业务,使业务系统功能更为专注。网站优化到这里,便可以解决大部分遇到的问题。网站是随着业务的发展而发展的,所有的改变、优化都是为了更好地服务客户。
11.2 网站群架构演化历史
互联网技术的发展越来越迅速,网站的概念已经被越来越多的人所熟悉。那么网站群是什么?从字面意思来看,就是网站的群集。网站群是通过统一标准、统一规范、统一规划,建立在统一技术架构基础之上的若干个能互相共享信息按照一定的隶属关系组织在一起,既可以统一管理又可以独立管理自成体系的网站集合。现有网站体系的封闭性往往限制了网站的进一步发展,门户网站和子网站往往是隔绝的,不能进行有效的信息共享,各网站成了一个个信息孤岛。主要存在问题有:
(1)自上而下的统一的数据规范标准及数据交换大多通过手工方式或第三方系统(如 FTP、邮件方式等)进行,这不但增加了上报人员的工作量,而且经常导致信息报送不及时,造成网站信息不准确和数据丟失。
(2)大量的数据资源处在既希望进行数据共享,又希望有特定的权限体系进行控制的两难境地。
(3)多个应用系统间相互独立,没有统一用户管理,导致使用不便,增加了管理难度。
(4)信息资源组织分类不合理,未建立统一的目录结构体系,缺乏统一管理,造成信息资源利用率低。
1.网站群发展历史
第一代:自然网站群。例如某省政府建立了自己的网站,随后其下属单位也陆续建设各自网站,最后在省政府的网站上将每个下属单位的网站链接到一起。此阶段网站群的特点是未经规划,自然形成,各自独立。
第二代:从网站的栏目、页面风格等方面进行整体规划,统一或分批实施,但各网站的关系仍然在一个平面上,没有隶属关系,且各个网站相互独立,信息不能共享。此阶段网站群的特点是外表统一,信息孤立,无法统一管理。
第三代:整合网站群。因业务需要,要将分散在不同物理位置的独立网站整合在一起,实现信息共享。这样形成的网站群存在很大的缺陷,信息不能充分共享,不能统一管理,不能统一升级网站后台,不能做到整个网站群的联合全文检索。
第四代:利用网站群内容管理系统,统一规划、统一实施或分步实施,以解决第三代网站群存在的缺陷。此阶段网站群的特点是所有的网站都运行在同一个网站群内容管理平台上,可以统一管理、数据集中存储和智能化,解决了前几代网站群维护困难且成本高的问题。
第五代:动态内容管理。动态内容管理产品突破了传统内容管理产品只能建设信息发布型网站的局限性,结合安全智能表单技术,推出新时期构建服务型政府网站的集成化内容管理平台,在解决传统的网站采编发管理、站群管理的基础上,提供丰富的个性化在线服务构建功能与公众交互功能,完整地满足政府门户网站中信息发布、在线服务与政民互动的要求。
第六代:集约化网站群。集约化网站群是指基于顶层设计的,技术统一、功能统一、结构统一、资源向上归集的,一站式、面向多服务对象、多渠道(PC 网站、移动客户端、微信、微博等)、多层级、多部门政府门户网站集群平台,由多个构建在同一数据体系上的门户网站群构成。引入“权限集”的权限管理方式来应对日趋复杂的网站群权限管理需求。
2.网站群建设四项基本原则
安全性:网站群的建设要充分考虑系统在运营环境下的网络安全,系统的各个组成部分必须采取有效的措施,以防止网络的非法入侵。除网络安全外,还要采用故障检测、告警和处理机制,以及完整的冗余备份机制,确保整个系统的安全可靠运行。
可靠性:在考虑技术先进性的同时,还要从系统结构、技术措施、设备性能、系统管理及维护等方面入手,确保系统运行时的可靠性和稳定性。采用故障检查、告警和处理机制,保证数据不因意外情况而丢失或损坏。
可扩展性:采用跨平台的软件设计,支持多种操作系统、多种数据库,保证系统的平滑迁移,能充分保护现有的软硬件投资。避免由于系统在建设初期没有充分考虑系统的可扩展性而当系统规模增长到一定程度之后,性能出现严重下降,缺乏可扩展性而再次付出巨额二次开发费用。
标准开放性:整个支撑平台系统应该采用开放式结构,符合国际标准、工业标准和行业标准,以适应业务的发展和扩充。系统整体能够融合新技术,便于维护,具有灵活扩展能力。
3.网站群建设目的
构建网站群的目的主要是解决站点群管理统一权限分配、统一导航和检索、消除“信息黑洞”和“信息孤岛”;将已有的职能部门联系起来,使得同一个组织内各个站点之间不再孤立;打破主站和子站的界限,消除信息孤岛,实现数据交换、共享;减少重复投资,提高资源利用率,减少网络安全隐患。
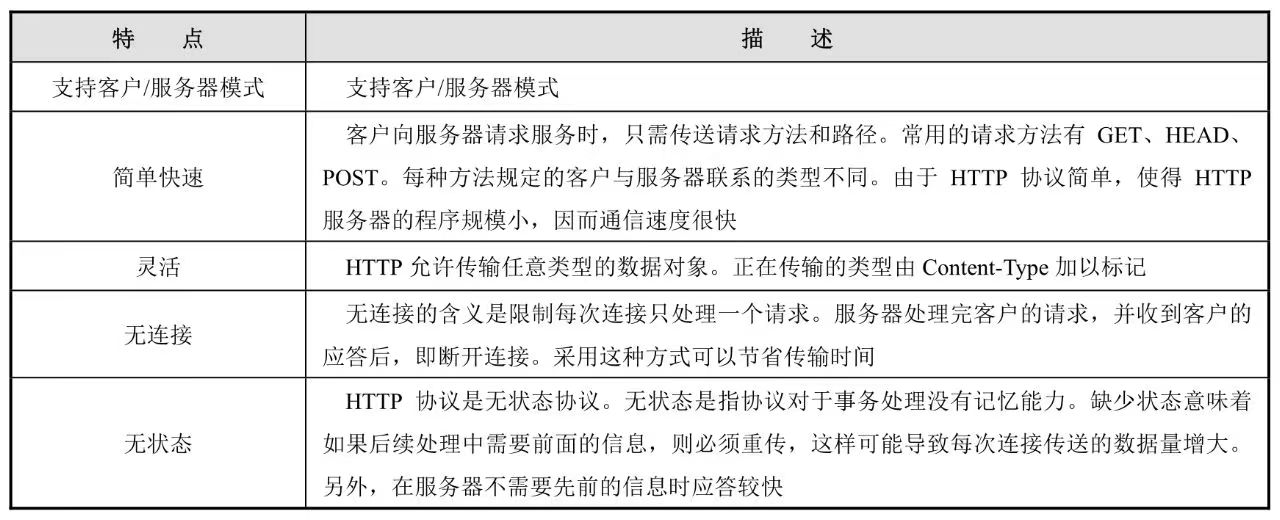
11.3 HTTP协议
HTTP(超文本传输协议)是一个属于应用层的面向对象的协议,其具有简捷、快速的特点适用于分布式超媒体信息系统。它于 1990 年被提出,经过多年的使用与发展,不断地得到完善和扩展。目前在WWW 中使用的是HTTP/1.1。HTTP 协议的主要特点如表11-1所示。
表11-1 HTTP协议的主要特点
HTTP 是一个基于请求与响应模式的、无状态的、应用层的协议,常基于 TCP 的连接方式,HTTP/1.1 版本中给出一种持续连接的机制,绝大多数 Web 开发都是构建在HTTP协议之上的Web应用。
11.4 网络架构核心组成
如图 11-14 所示,一个简单的网站是由 Web 中间件、Web 应用程序、文件系统、数据库组成的,以上所有的内容都运行在操作系统之上,只是它们所对应的功能有所不同。
图11-14 简单网站的构成
操作系统:管理硬件资源和软件资源的计算机程序,同时也是计算机系统的内核与基石。操作系统需要处理如管理与配置内存、决定系统资源供需的优先次序、控制输入与输出设备、操作网络与管理文件系统等基本事务。操作系统还提供一个让用户与系统交互的操作界面,用户可通过操作系统的用户界面输入命令,操作系统则对命令进行解释,驱动硬件设备,实现用户需求。
数据库:数据库(data base)实际上就是一个文件集合,是一个存储数据的仓库,本质就是一个文件系统,数据库按照特定的格式把数据存储起来,用户可以对所存储的数据进行增、删、改、查等操作。
Web 中间件:又称 Web 服务器,一般指网站服务器,是指驻留于因特网上的某种类型的计算机程序,可以向浏览器等 Web 客户端提供文档,也可以放置网站文件,让全世界的用户浏览;可以放置数据文件,让全世界的用户下载。目前主流的三个 Web 服务器是Apache、Nginx和IIS。
Web 应用程序:一种可以通过 Web 访问的应用程序。Web 应用程序的一个最大好处是用户可以很容易地访问应用程序。用户有浏览器即可,不需要再安装其他软件。
文件系统:操作系统用于明确存储设备(常见的是磁盘,也有基于NAND Flash的固态硬盘)或分区上的文件的方法和数据结构,即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。
11.4.2 数据库
数据库在网站建设中有非常重要的作用,它能将最新的内容展现给浏览者,同时也存储了网站的很多数据,如用户信息、交易信息、产品信息和商家信息等。
1.数据库简介
数据库(DataBase)是按照数据结构来组织、存储和管理数据的仓库,是存储在一起的相关数据的集合,其优点主要体现在以下几个方面:
(1)减小数据的冗余度,节省数据存储空间;
(2)具有较高的数据独立性和易扩充性;
(3)实现数据资源的充分共享。
早期比较流行的数据库模型有 3 种,分别为层次式数据库、网络式数据库和关系型数据库。而在当今的互联网中,最常用的数据库模型主要有两种,即关系型数据库和非关系型数据库。
非关系型数据库也被称为 NoSQL 数据库,NoSQL 的本意是“Not Only SQL”,NoSQL 的产生并不是要彻底地否定非关系型数据库,而是作为传统关系型数据库的一个有效补充,NoSQL 数据库在特定的场景下可以发挥出难以想象的高效率和高性能。随着Web 2.0网站的兴起,传统的关系型数据库在应付Web 2.0网站及超大规模和高并发的微博、微信、SNS类型的Web 2.0纯动态网站方面已经显得力不从心,暴露出很多难以克服的问题,NoSQL(非关系型)数据库就是在这样的情景下诞生的,并得到了非常迅速的发展,常见的非关系型数据库有Memcached、Redis、MongoDB等。
网络数据库和层次数据库很好地解决了数据的集中和共享问题,但是在数据独立性和抽象级别上仍有很大的欠缺。用户对这两种数据库进行存取时,依然需要明确数据的存储结构,指出存储路径,而关系型数据库可以较好地解决这些问题。
关系型数据库模型中,把复杂的数据结构归结为简单的二元关系(即二维表格形式)。Oracle 在数据库领域上升到了霸主地位,形成每年高达数百亿美元的庞大市场,常见的关系型数据库有Oracle、MySQL、SQLServer、Postgre SQL和DB2。


如图11-58所示是数据库的查看界面。下面介绍一些关系型数据库术语。
图11-58 数据库的查看界面
表:用于存储数据,它以行列式方式组织,可以使用 SQL 从中查询、修改和删除数据。表是关系数据库的基本元素。
记录:记录是指表中的一行,在一般情况下,记录和行的意思是相同的。
字段:字段是表中的一列,在一般情况下,字段和列所指的内容是相同的。
关系:关系是一个从数学中来的概念,在关系代数中,关系是指二维表,表既可以用来表示数据,又可以用来表示数据之间的联系。
索引:索引是建立在表上的单独的物理结构,基于索引的查询使数据获取更为快捷。索引是表中的一个或多个字段,索引可以是唯一的,也可以是不唯一的,主要看这些字段是否允许重复。主索引是表中的一列和多列的组合,作为表中记录的唯一标识。外部索引是相关联的表的一列或多列的组合,通过这种方式来建立多个表之间的联系。视图:视图是一个真实表的窗口,视图不能脱离表。视图和表的区别是:表是实际存在的(需要存储在计算机中,占用存储空间);视图是虚拟表(仅存储真实表的视图表现形式),它用于限制用户可以看到和修改的数据量,以简化数据的表达。
存储过程:存储过程是一个编译过的 SQL 程序。在该过程中,可以嵌入条件逻辑、传递参数、定义变量和执行其他编程任务。如图 11-59 所示为查询 student 表数据数量的存储过程。
4)Redis
当前数据库大多分为关系型数据库和非关系型数据库,而 Redis 是非关系型数据库的典型代表。Redis 是一个 key-value 存储系统,不只 Redis,所有的非关系型数据库都是key-value存储系统。虽然Redis是key-value存储系统,但是Redis支持的value存储类型是非常多的,如字符串、链表、集合和有序集合等。
Redis 的优势主要在性能和并发两方面。当然,Redis 还具备可以做分布式锁等其他功能,但是如果只是为了分布式锁这些其他功能,完全可用其他中间件代替,如Zookpeer,并非必须使用Redis。
性能:当遇到需要执行耗时特别久且结果不频繁变动的 SQL 时,适合将运行结果放入缓存。这样,后面的请求就会去缓存中读取结果,使得请求能够迅速得到响应。
并发:在并发的情况下,所有请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用Redis做缓冲操作,让请求先访问Redis,而不是直接访问数据库。
Redis与其他key-value缓存产品相比有以下3个特点:① Redis 支持数据持久化,可以将内存中的数据保存在磁盘中,重启时可以再次加载使用。
② Redis不仅支持简单的key-value类型的数据,还支持List、Set、Zset、Hash等数据结构的存储。
③ Redis支持数据的备份,即master-slave模式下的数据备份。
(1)Redis的优点
① 性能极高。Redis读的速度是110000次/秒,写的速度是81000次/秒。
② 丰富的数据类型。Redis 支持二进制案例的 Strings、Lists、Hashes、Sets 及Ordered Sets数据类型操作。
③ 原子性。Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
④ 丰富的特性。Redis还支持 publish/subscribe、通知、Key过期等特性。
(2)Redis的缺点
① 由于是内存数据库,所以,单台机器存储的数据量和机器本身的内存大小有关。虽然Redis本身有Key过期策略,但还是需要提前预估和节约内存。如果内存占用过快,则需要定期删除数据
② 如果进行完整重同步,则需要生成 rdb 文件并进行传输,这会占用主机的 CPU,并消耗现网的带宽。不过 Redis 2.8 版本中已经有部分重同步功能,但还是有可能有完整重同步的,如新上线的备机。
Key过期通知让客户端可以通过订阅频道来接收那些以某种方式改动了 Redis 数据集的事件,如Redis数据库中Key过期事件也是通过订阅功能实现的。
(3)Redis未授权漏洞的危害
Redis在默认情况下会绑定在0.0.0.0:6379。如果没有采取相关的安全策略,如添加防火墙规则、避免其他非信任来源 IP 访问等,则会使 Redis 服务完全暴露在公网上。在没有设置密码认证(一般为空)的情况下,任意用户在访问目标服务器时都可以在未授权的情况下访问Redis及读取Redis的数据。攻击者在未授权访问Redis的情况下,利用Redis自身提供的 config 命令,可以进行文件的读写等操作。攻击者可以成功地将自己的 SSH公钥写入目标服务器/root/.ssh文件夹下的authotrized_keys文件中,进而可以使用对应的私钥直接通过SSH服务登录目标服务器。
危害可以总结为以下3点。
① 攻击者无须认证即可访问内部数据,可能导致敏感信息泄露,黑客也可以恶意执行Flushall来清空所有数据;
② 攻击者可通过EVAL执行lua代码,或通过数据备份功能向磁盘写入后门文件;
③ 最严重的情况:如果Redis以root身份运行,则黑客可以给root账户写入SSH公钥文件,直接通过SSH登录受害服务器。
(4)Redis安全加固(见表11-8)
表11-8 Redis安全加固
12.1.3 网站DDoS
DDoS 攻击随着互联网的快速发展日益猖獗,从原来的几 MB、几十 MB,到现在的几十GB、几十TB,形成了一个很大的利益链。DDoS攻击利用庞大的僵尸网络,同时对同一目标发起攻击,造成网络堵塞,致使目标网站或网络不可访问。DDoS 攻击是“冰冻三尺非一日之寒”,黑客通过长时间渗透互联网服务器,如网站服务器、数据库服务器、网络摄像头、网络路由器等,积累到一定数量后,便可以发起DDoS攻击。现在的DDoS攻击越来越国际化,我国已经成为仅次于美国的第二大 DDoS 攻击受害国,来自海外的DDoS攻击源占比也越来越高。
市场化势必带来成本优势,现在各种在线 DDoS 平台、“肉鸡”交易渠道层出不穷,使得攻击者能以很低的成本发起规模化攻击。拒绝服务主要分为两种:一种是网络层的DDoS攻击,即攻击者通过使用工具或僵尸网络对网站发动 SYN Flood 攻击、TCP Flood攻击、ICMP Flood 攻击、UDP Flood 攻击、Smurf 攻击、Land 攻击等大流量的攻击方式,堵死用户网站出口带宽,导致用户和网站服务器间无法进行请求和响应交换,无法访问网站。最具代表性的是2016年10月21日美国主要DNS服务商Dyn遭遇大规模DDoS攻击导致断网事件。另外一种拒绝服务是应用层的CC攻击,黑客只需要通过工具或僵尸网络模拟正常用户请求方式,发送少量网站访问请求,就会导致网站服务器进行大量响应,从而消耗网站服务器的 CPU、内存、端口、连接等资源,资源消耗殆尽时,就无法为正常的访问用户提供服务。
12.2 威胁的攻击流程
12.2.1 信息收集
1.信息收集介绍
信息收集的主要目的是指黑客为了更加精准有效的实施网络攻击而进行的探测目标所有相关信息的行为。
信息收集的行为分为主动信息收集和被动信息收集,主动信息收集是指直接和目标进行交互,从而拿到目标信息,缺点是交互过程会被目标主机记录,从而留下痕迹。被动信息收集是指不的物理信息、社会工程等间接方式获取目标主机的信息。
收集的信息包括网络信息(域名、IP 地址、网络拓扑)、系统信息(操作系统版本、开放的各种网络服务版本)、用户信息(用户标识、组标识、共享资源、即时通信软件账号、邮件账号)等。信息收集是情报机构获取可靠、高价值信息资源的一种重要方式。
2.踩点介绍
1)踩点概念
踩点指的是预先到某个地方进行考察,为后面正式到这个地方开展工作做准备,比如,去商场购物,可能通过某种形式,获得商场别人不知道而自己已经知道的最新信息。获得信息的过程就叫作踩点,即尽可能多地收集关于目标网络的信息以找到多种入侵组织网络系统方法的过程。
2)踩点过程
① 搜集目标和所在网络的基础信息。
② 测试所使用操作系统各类型、版本、运行的平台软件,以及Web服务的版本等。
③ 使用诸如whois、DNS查询、网络和组织查询等工具。
④ 找到能够进一步发起攻击的安全漏洞。
3)踩点目的
① 踩点使攻击者能够了解组织完整的安全架构。
② 通过IP地址范围、网络、域名、远程访问点等信息,可以缩小攻击范围。
③ 攻击者能够建立自己的相关目标组织安全性弱点的信息数据库,以便采取下一步的入侵行动。
④ 攻击者可以描绘出目标组织的网络拓扑图,分析最容易进入的攻击路径。
4)踩点方法
① 通过搜索引擎进行信息收集。
② Nmap扫描命令。
③ 网络查点。
④ 漏洞扫描。
⑤ 信息数据库与共享。
5)信息收集总结
① 确定要攻击的网站后,用 whois 工具查询网站信息、注册时间、管理员联系方式。
② 使用nslookup、dig工具进行域名解析以得到IP地址。
③ 查询得到的IP地址的所在地。
④ 通过google搜集一些敏感信息,如网站目录、网站的特定类型文件。
⑤ 对网站进行端口、操作系统、服务版本的扫描,用 nmap-sV-O 命令即可实现,更详细的信息可以用nmap-a命令。
⑥ 在得到了目标的服务器系统、开放端口及服务版本后,使用 Openvas/Nessus 进行漏洞挖掘。
⑦ 将搜集到的所有信息进行筛选,得出有用的信息,并认真做好记录。
3.网络扫描
网络扫描是一种自动化程序,用于检测远程最基本的工作,攻击者正是利用各种漏洞入侵系统的。我们可以借助自动化的扫描工作,在攻击者之前发现漏洞问题,并给予相应的修正程序。网络扫描是根据对方服务所采用的协议,在一定时间内,通过自身系统对对方协议进行特定读取、猜想验证、恶意破坏,并将对方直接或间接的返回数据作为某指标的判断依据的一种行为。
网络扫描获取的信息:发现存活主机、IP 地址,以及存活主机开放的端口;发现主机的操作系统类型和系统结构;发现主机开启的服务类型;发现主机存在的漏洞。
1)网络扫描的主要技术
(1)ICMP Echo 扫描:Ping 的实现机制,在判断一个网络上主机是否开机时非常有用。向目标主机发送ICMP Echo Request数据包(type 8),等待回复的ICMP Echo Reply包(type 0)。如果能收到,则表明目标系统可达,否则表明目标系统已经不可达或发送的包被对方设备过滤掉。ICMP Echo扫描的相关信息见表12-1。
(2)Non-Echo 扫描:发送一个 ICMP TIMESTAMP REQUEST(type 13)或 ICMP ADDRESS MASK REQUEST(type 13),看是否可以突破防火墙。
(3)ICMP Sweep扫描:在ICMP Echo的基础上,通过并行发送,同时探测多个目标主机,以提高探测效率。
表12-1 ICMP Echo扫描的相关信息
(4)Broadcast ICMP扫描:将ICMP请求包的目的地址设为广播地址或网络地址,则可以探测广播域或整个网络范围内的主机。缺点是只适用于 UNIX/Linux 系统,Windows系统会忽略这种请求包;容易引起广播风暴。
2)网络嗅探
嗅探是指利用计算机的网络接口截获目的地为其他计算机的数据报文的一种技术。网络嗅探工作在网络的底层,攻击者通过读取未加密的数据包来获取信息,把网络传输的全部数据记录下来。
通常在同一个网段的所有网络接口都有访问在物理媒体上传输所有数据的能力,而每个网络接口都还应该有一个硬件地址,该硬件地址不同于网络中存在的其他网络接口的硬件地址,同时每个网络至少还有一个广播地址(代表所有的接口地址),在正常情况下,一个合法的网络接口应该只响应以下两种数据帧:
(1)帧的目标区域具有和本地网络接口相匹配的硬件地址。
(2)帧的目标区域具有“广播地址”。
sniffer(嗅探器)几乎和 internet 有一样久的历史。sniffer 是一种常用的收集有用数据的方法,这些数据可以是用户的账号和密码,也可以是一些商用机密数据等。随着Internet 电子商务的日益普及,Internet 的安全也越来越受到重视。sniffer 工作在网络环境中的底层,它会拦截所有正在网络上传送的数据,并且通过相应的软件处理,可以实时分析这些数据的内容,进而分析所处的网络状态和整体布局。值得注意的是:sniffer 是极其安静的,它是一种消极的安全攻击。通常sniffer所要关心的内容可以分成几类:
● 口令。
● 金融账户。
● 偷窥机密或敏感的信息数据。
● 窥探低级的协议信息。
12.2.2 漏洞扫描
漏洞扫描是指基于漏洞数据库,通过扫描等手段对指定的远程或本地计算机系统的安全脆弱性进行检测,发现可利用漏洞的一种安全检测(渗透攻击)行为。基于网络的漏洞扫描,就是通过远程检测目标主机 TCP/IP 不同端口的服务,记录目标主机给予的回答。用这种方法来了解目标主机的各种信息,获得相关信息后,与网络漏洞扫描系统提供的漏洞库进行匹配,如果满足匹配条件,则视为漏洞存在。还有一种方法就是通过模拟黑客的进攻手法,对目标主机系统进行攻击性的安全漏洞扫描。
实现方法如下:
1)漏洞库的匹配方法就是它所使用的漏洞库。漏洞库包含各种操作系统的各种漏洞信息,以及如何检测漏洞指令。通过采用基于规则的匹配技术,即根据安全专家对网络系统安全漏洞、黑客攻击案例的分析和系统管理员对网络系统安全配置的实际经验,可以形成一套标准的网络系统漏洞库,然后在此基础上构成相应的匹配规则,由扫描程序自动进行漏洞扫描工作。
2)插件(功能模块)技术
插件是由脚本语言编写的子程序,扫描程序可以通过调用它来执行漏洞扫描,检测出系统中存在的一个或多个漏洞。添加新的插件就可以使漏洞扫描软件增加新的功能,扫描出更多的漏洞。插件编写规范化后,甚至用户自己都可以用 perl、c 或自行设计的脚本语言编写的插件来扩充漏洞扫描软件的功能。这种技术使漏洞扫描软件的升级维护变得相对简单,而专用脚本语言的使用也简化了编写新插件的编程工作,使漏洞扫描软件具有很强的扩展性,所使用的技术如下:
● 主机扫描:确定在目标网络上的主机是否在线。
● 端口扫描:发现远程主机开放的端口及服务。
● OS识别技术:根据信息和协议栈判别操作系统。
● 漏洞检测数据采集技术:按照网络、系统、数据库进行扫描。
● 智能端口识别、多重服务检测、安全优化扫描、系统渗透扫描。
● 多种数据库自动化检查技术、数据库实例发现技术。
● 多种DBMS的密码生成技术:提供口令爆破库,实现快速的弱口令检测。
Web 应用程序漏洞利用已经成为目前黑客渗透攻击最主流的攻击手段,尤其是目前网络环境中针对该种类型的扫描工具相当丰富,比较出名的工具像商业版的Acunetix Web Vulnerability Scanner、IBM公司的AppScan等,其他免费或开源的Web应用程序漏洞扫描工具更是数不胜数,而这些工具都可以通过傻瓜式的操作实现对目标 Web 应用程序的安全性扫描并给出扫描报告。
除此之外还有专门硬件级的漏洞扫描设备,可以通过 IP 地址段批量反查域名。内网穿透扫描可进行主机漏洞扫描、Web 漏洞扫描、弱密码扫描等,可以广泛用于扫描数据库、文件系统、邮件系统、Web 服务器等平台。通过部署漏洞扫描系统,能够降低与缓解主机中漏洞造成的威胁与损失,快速掌握主机中存在的脆弱点。
12.3.1 SQL注入漏洞
1.SQL注入简介
SQL 注入攻击是 Web 安全领域最常见的攻击方式,SQL 注入攻击的本质是把用户输入的数据当作代码执行。现在 SQL 注入对于网络安全从业人员和开发人员来说,是非常熟悉的,其第一次出现是在 1998 年著名黑客杂《Phack》第 54 期上,名为 rfp 的黑客发表了一篇名为“NT Webs Technology Vulnerabilities”的文章。SQL注入的危害主要有数据库信息泄露、网页篡改、网站挂马、传播恶意软件、数据库被恶意操作、服务器被远程控制、安装后门、破坏硬盘数据、瘫痪系统。SQL 注入的利用和 Web 开发语言无关,也与数据库的类型无关。无论是 Java、PHP、Asp、Golang,还是 Oracle、SQL Server、MySQL、Access 都有可能出现 SQL 注入漏洞。下面以 PHP+MySQL 环境为例来说明SQL注入。PHP后台代码如图12-19所示。
2.SQL注入分类
SQL 注入的原理如此简单,但其延伸出的类型花样多变,按照查询条件变量类型分为整型注入、字符型注入。按照数据提交的方式分为 GET 型注入、POST 型注入、Cookie注入、HTTP头部注入等;按照执行效果分为布尔注入、时间盲注、报错注入、联合查询注入等。总体来说花样繁多、眼花缭乱,但万变不离其宗,归根到底还是 SQL 语句的闭合及利用。下面介绍几种SQL注入类型:
(1)整型注入:当后台 SQL 语句的可控参数对应的查询字段为整型时,被称为整型注入,如:
"select title,context from news where id=1;".
(2)字符型注入:当后台 SQL 语句的可控参数对应的查询字段为字符型时,被称为字符型注入,如:
"select title,context from news wherid='1';".
(3)GET型注入:可控的URL参数在GET请求中称为GET型注入,例如:
"http://www.any.com/new.php?id=1".
(4)POST型注入:可控的URL参数在POST请求中称为POST型注入,如图12-20所示。
图12-20 POST型注入
(5)Cookie注入:可控的参数在Cookie,如图12-21所示。
图12-21 Cookie注入
(6)布尔注入:很多情况下,页面上不显示插入 SQL 语句执行的结果,导致没法直接看到数据库信息。计算机中所有的数据都是由 0、1 两个数来组成的,0 和 1 是两种状态,本质是高电平与低电平,但也可以理解为阴与阳、对与错、真与假,总之是对立面。在页面显示时也会有两种状态,一种是正常显示,另一种是非正常显示,那么我们就可以使用对、错两种状态来判断插入的 SQL 执行结果,如“http://
www.any.com/news.php?id=1’ and ascii(database(),1,1)=114%23”。
ascii(substr(database(),1,1))>114条件的对错决定了where条件的对错,从而决定了页面显示的正常与否,也就是页面正常条件为真,页面异常条件为假,ascii 函数代码是取database的第一个字符的ascii码与114比对,正确说明database的第一位ascii是 114,也就是字母 r,如果不是 114,便继续与其他 ascii 数字比对,直到比对出所有字符为止,这就是布尔注入。
(7)时间盲注:时间盲注的原理与布尔注入相同,主要是为了解决页面不显示 SQL语句回显内容及布尔盲注无效果时的问题。看一个实例:“http://www/any.com/news.php?id=1’ and (if(ascii(substr(database(),1,1))=114,sleep(10),1))%23”。其核心代码还是比较 ascii 码,正确时执行 sleep(10),这样页面就会 10s 后刷新,反之立刻刷新,从而根据页面的响应时间来判断ascii的正确性,直到比对出所有字符为止。
1.XSS简介
跨站脚本攻击是客户端脚本安全中的头号大敌,XSS在OWASP TOP 10榜单中多次位列榜首,可见该漏洞的重要性。跨站脚本的英文全称为 Cross Site Script,正常缩写是CSS,但为了和html样式的CSS区别,命名为XSS。
XSS 攻击是一种针对 Web 前端的攻击,它的代码大部分由 JavaScript 组成,也就是说JavaScript能完成的事情,XSS攻击都能做到,如窃取Cookie、网站钓鱼、蠕虫等。到底什么是XSS?
13.1 Web代码安全建设
13.1.1 安全开发
SDL(Security Development Lifecycle,安全开发生命周期)由微软公司最早提出,是一种专注于软件开发的安全保障流程。以实现保护最终用户为目标,其在软件开发流程的各个阶段引入安全和隐私问题。它是一个逐渐完善的体系,并将软件安全的考虑与实施方法集成在软件开发的任何一个阶段,包括但不仅限于需求分析、设计、编码、测试和维护。
自 2004 年起,SDL 就成为微软公司的计划和强制施行政策,其核心理念就是将安全考虑集成在软件开发的每一个阶段:需求分析、设计、编码、测试和维护。从需求、设计到发布产品的每一个阶段都增加了相应的安全活动与规范,以减少软件中漏洞的数量并将安全缺陷降低到最少。SDL 是侧重于软件开发的安全保证过程,旨在开发出安全的软件应用。
SDL大致包括以下七个阶段。
(1)安全培训:安全意识+安全测试+安全开发+安全运维+安全产品。
(2)需求分析:确定安全需求和投入占比,寻找安全嵌入的最优方式。
(3)系统设计:确定设计要求,分析攻击面,威胁建模。
(4)实现:使用标准的工具,弃用不安全的函数,静态分析(安全开发规范+代码审计)。
(5)验证:黑白盒测试,攻击面评估。
(6)发布:安全事件响应计划,周期性安全评估。
(7)响应:应急响应,BUG跟踪。
安全培训是 SDL 的核心概念。软件由设计人员设计,代码由开发人员编写。大部分软件本身的安全漏洞也由设计及编码人员引入,所以对软件开发过程中的技术人员进行安全培训至关重要。在设计阶段造成的安全缺陷后期修复成本和时间都相对较高。STRIDE威胁建模的创始人之一Taha Mir曾说过“Safer Applications Begin With Secure Design”,即安全应用从安全设计开始。相应的,微软 SDL 也提出了若干核心安全设计原则,并提出如攻击面最小化、STRIDE 威胁建模等多种方法辅助安全人员对软件进行安全设计。培训内容应包括以下方面:
(1)安全设计:包括减小攻击面、深度防御、最小权限原则、服务器安全配置等。
(2)威胁建模:概述、设计意义、基于威胁建模的编码约束。
(3)安全编码:缓冲区溢出(针对 C/C++)、整数算法错误(针对 C/C++)、XSS/CSRF(对于Web类应用)、SQL注入(对于Web类应用)、弱加密。
(4)安全测试:安全测试和黑盒测试的区别、风险评估、安全测试方法(代码审计、fuzz等)。
13.2 Web业务安全建设
13.2.1 业务安全介绍
随着“互联网+”的发展,经济形态不断发生演变。众多传统行业逐步融入互联网并利用信息通信技术及互联网平台进行着频繁的商务活动,这些平台(如银行、保险、证券、电商、P2P、O2O、游戏、社交、招聘、航空等)由于涉及大量的金钱、个人信息、交易等重要隐私数据,成为黑客攻击的首要目标,业务逻辑漏洞主要是开发人员业务流程设计的缺陷,不仅限于网络层、系统层、代码层等。登录验证的绕过、交易中的数据篡改、接口的恶意调用等,都属于业务逻辑漏洞。目前业内基于这些平台的安全风险检测一般采用常规的渗透测试技术(主要基于OWASP Top10),而常规的渗透测试往往忽视这些平台存在的业务逻辑层面风险,而业务逻辑风险往往危害更大,会造成非常严重的后果。
13.2.2 业务安全测试理论
1.业务安全测试概述
业务安全测试通常是指针对业务运行的软硬件平台(操作系统、数据库、中间件等),业务系统自身(软件或设备)和业务所提供的服务进行安全测试,保护业务系统免受安全威胁,以验证业务系统符合安全需求定义和安全标准的过程。
本书所涉及的业务安全主要是系统自身和所提供服务的安全,即针对业务系统中的业务流程、业务逻辑设计、业务权限和业务数据及相关支撑系统,以及后台管理平台与业务相关的支撑功能、管理流程等方面的安全测试,深度挖掘业务安全漏洞,并提供相关整改修复建议,从关注具体业务功能的正确呈现、安全运营角度出发,增强用户业务系统的安全性。
传统安全测试主要依靠基于漏洞类型的自动化扫描检测,辅以人工测试,来发现如SQL 注入、XSS、任意文件上传、远程命令执行等传统类型的漏洞,这种方式往往容易忽略业务系统的业务流程设计缺陷、业务逻辑、业务数据流转、业务权限、业务数据等方面的安全风险。过度依本身,不与业务数据相关联,很难发现业务层面的漏洞,企业很可能因为简单的业务逻辑漏洞而蒙受巨大损失。
2.业务安全测试模型
业务安全测试模型要素如图13-23所示。
图13-23 业务安全测试模型要素
(1)前台视角:业务使用者(信息系统受众)可见的业务及系统视图,如平台的用户注册、充值、购买、交易、查询等业务。
(2)后台视角:管理用户(信息系统管理、运营人员)可见的业务及系统视图,如平台的登录认证、结算、对账等业务。
(3)业务视角:业务使用者(信息系统受众)可见的表现层视图,如 Web 浏览器、手机浏览器展现的界面及其他业务系统用户的UI界面。
(4)系统视角:业务使用者(信息系统受众)不可见的系统逻辑层视图。
在面对不同用户的不同业务时,通过深入了解用户业务特点、业务安全需求,应切实地根据客户业务系统的架构,从前、后视角,业务视角与系统视角划分测试对象,根据实际情况选择白灰盒或黑盒的手段进行业务安全测试。
13.3.1 Web应用防火墙
1.Web应用防火墙介绍
Web 应用越来越丰富的同时,Web 服务器以其强大的计算能力、处理性能及蕴含的较篡改、网页挂马等安全事件,频繁发生。2017年,CNCERT 监测发现我国约 2 万个网站被篡改,较 2016年的约 1.7 万增长了20.0%多,其中被篡改的政府网站有618个,较2016年的467个增长约32.3%,如图13-31所示。
企业等用户一般采用防火墙作为安全保障体系的第一道防线,但是在现实中依然存在一些问题,由此产生了 WAF (Web 应用防护系统)。Web 应用防护系统(Web Application Firewall,WAF)代表了一类新兴的信息安全技术,用于解决诸如防火墙一类传统设备束手无策的 Web 应用安全问题。与传统防火墙不同,WAF 工作在应用层,对Web应用防护具有先天的技术优势。基于对Web应用业务和逻辑的深刻理解,WAF对来自 Web 应用程序客户端的各类请求进行内容检测和验证,确保其安全性与合法性,对非法的请求予以实时阻断,从而对各类网站站点进行有效防护。一款合格且优秀的 WAF 通常应具备以下功能:
(1)防止常见的各类网络攻击,如SQL注入、XSS、CSRF、网页后门等。
(2)防止各类自动化攻击,如暴力破解、撞库、批量注册、自动发帖等。
(3)阻止其他常见威胁,如爬虫、0 DAY 攻击、代码分析、嗅探、数据篡改、越权访问、敏感信息泄露、应用层DDoS、盗链、越权、扫描等。
13.3.3 抗DDoS
DDoS(分布式拒绝服务)通常是指黑客通过控制大量互联网上的机器(通常称为僵尸机器),在瞬间向一个攻击目标发动潮水般的攻击。大量的攻击报文,导致被攻击系统的链路阻塞、应用服务器或网络防火墙等网络基础设施资源耗尽,无法为用户提供正常业务访问。
如图 13-34 所示,黑客借助多台计算机或一个僵尸网络,向目标主机发起 DDoS 攻击,比以前更大规模地进攻受害者,从而成倍地提高攻击威力和效果;通过大量合法的请求占用大量网络资源,以达到瘫痪网络的目的,使系统无法响应正常用户的业务请求;通过向服务器提交大量请求,使服务器超负荷。
1.拒绝服务的手段
1)死亡之ping(ping of death)
如执行ping-l65535 192.168.1.1,系统会提示Badvalue for option-l,valid range is from 0 to 65500,现在绝大多数操作系统已经进行了漏洞修补。
2)SYN泛洪(SYNflood)
专门针对TCP的3次握手过程中两台主机间初始化连接握手进行攻击。
攻击方利用虚假源地址向服务器发送 TCP 连接请求,服务器回复 SYN+ACK 数据包。由于发送请求的源地址是假地址,服务器不会得到确认,服务器一般会重试发送SYN+ACK,并等待一段时间(大约 30 秒至 2 分钟)后丢弃这个连接,在等待的时间内服务器处于半连接状态,会消耗资源。当大量虚假 SYN 请求到来时,会占用服务器的大量资源,从而使得目标主机不能向正常请求提供服务。
3)UDP泛洪攻击者发送大量伪造源IP 地址的小 UDP 数据包。只要用户开一个 UDP 端口提供相关服务,就可以针对该服务进行攻击。
4)Land攻击
Land攻击由黑客组织Rootshell发现,攻击目标是TCP三次握手,利用一个特别打造的 SYN 包,其源地址和目的地址(相同)都被设置成某一个服务器地址进行攻击,这将导致接收服务器向它自己的地址发送SYN+ACK消息,结果这个地址又发回ACK消息并创建一个空连接,每一个这样的连接都将保留,直到超时。在 Land 攻击下,许多 UNIX将崩溃,NT主机变得极其缓慢(大约持续五分钟)。
5)Smurf攻击
攻击者向子网的广播地址发送一个带有特定请求,如 ping 的包,并且将源地址伪装成要攻击的主机地址。子网上所有主机都回应广播包的请求,向被攻击主机发送应答,使得网络的带宽下降,严重情况会导致受害主机崩溃。
6)SYN变种攻击
SYN变种攻击是指发送伪造源IP地址的SYN数据包,但数据包不是64字节而是上千字节。这种攻击会造成防火墙错误锁死,消耗服务器资源,从而阻塞网络。
7)TCP混乱数据包攻击
发送伪造源 IP 地址的TCP 数据包,TCP 头部的TCPFlags 部分混乱,会造成防火墙错误锁死,消耗服务器资源,从而阻塞网络。
8)泪滴攻击(分片攻击)
泪滴(Teardrop)攻击是利用TCP/IP协议的漏洞进行DoS攻击的方式。
攻击者向目的主机发送有重叠偏移量的伪造 IP 分片数据包,目的主机在重组含有偏移量重叠的数据包时会引起协议栈崩溃。
9)IP欺骗DoS
攻击者向目的主机发送大量伪造源IP地址(合法用户,已经建立连接)、RST置位的数据包,致使目的主机清空已经建好的连接,从而实现DoS。
10)针对Web Server的多连接攻击
通过控制大量“肉鸡”同时访问某网站,造成网站无法正常处理请求而瘫痪。
11)针对Web Server的变种攻击
通过控制大量“肉鸡”同时连接网站,不发送 GET 请求而是发送乱七八糟的字符,绕过防火墙的检测,从而造成服务器瘫痪。
12)CC攻击
CC 攻击的原理是攻击者控制某些主机不停地发大量数据包给对方服务器,造成服务器资源耗尽,直到宕机崩溃。其主要用来攻击页面,每个人都有这样的体验:当一个网页访问的人数特别多的时候,打开网页的速度就慢了,CC 就是模拟多个用户(多少线程就是多少用户)不停地进行访问那些需要大量数据操作(就是需要大量 CPU 时间的操作)的页面,造成服务器资源浪费,CPU 长时间处于满载状态,直至网络拥塞,正常的访问被中止。
2.拒绝服务技术防御
1)按攻击流量规模分类分别从流量大小和攻击协议两个方面说明防御方法,当攻击流量小于 1000Mb/s 且在服务器硬件与应用承受范围之内时,攻击并不影响业务,可以利用操作系统的防火墙进行防御(如 iptables),或者使用 DDoS 防护应用实现软件层防护。当攻击流量大于1000Mb/s 时,可能影响相同机房的其他业务,此时也可以利用操作系统的防火墙进行防御(如iptables),或者使用DDoS防护应用实现软件层防护,除此之外还可以修改对外服务 IP,例如,高负载 Proxy、集群外网 IP、CDN 高防 IP、公有云 DDoS、防护网关 IP等。如果攻击流量属于超大规模,甚至流量大于机房出口,此时已经影响相同机房的所有业务或大部分业务,则需要联系运营商检查分组限流配置部署情况并观察业务恢复情况。
当攻击流量为syn/fin/ack等tcp协议包时,需要设置预警阈值和响应阈值,根据流量大小和影响程度调整防护策略和防护手段,逐步升级。当攻击流量为udp/dns query等udp协议包时,可以根据业务协议制定一份tcp协议白名单。如果遇到大量udp请求,则可以不经产品确认或延迟与产品确认,直接在系统层面/HPPS或清洗设备上丢弃udp包。当攻击流量为http flood/CC等需要与数据库交互的攻击时,一般会导致数据库或webserver负载很高,或者连接数过高,在限流或清洗流量后可能需要重启服务才能释放连接数,因此更倾向于在系统资源能够支撑的情况下调大支持的连接数。相对来说,这种攻击防护难度较大,对防护设备性能消耗也很大。
2)按攻击流量协议分类
(1)syn/fin/ack 等 tcp 协议包:设置预警
阈值和响应阈值,前者开始报警,后者开始处理,根据流量大小和影响程度调整防护策略和防护手段,逐步升级。
(2)udp/dns query 等udp协议包:对于大部分游戏业务来说,都是TCP 协议的,所以可以根据业务协议制定一份tcp协议白名单,如果遇到大量udp请求,则可以不经产品确认或延迟跟产品确认,直接在系统层面/HPPS或清洗设备上丢弃udp包。
(3)http flood/CC 等需要跟数据库交互的攻击:这种一般会导致数据库或 Webserver负载很高,或者连接数过高,在限流或清洗流量后可能需要重启服务才能释放连接数,因此更倾向于在系统资源能够支撑的情况下调大支持的连接数。相对来说,这种攻击防护难度较大,对防护设备性能消耗很大。
(4)其他:icmp 包可以直接丢弃,先在机房出口以下各个层面做丢弃或限流策略。现在这种攻击已经很少见,对业务破坏力有限。
4.部署方式
1)单机串联部署
抗 DDoS 系统接入机房核心交换机前端防护,核心交换机下所有主机进入防护区。连接方式:将ISP(运营商)分配的光纤接入抗DDoS系统设备的出口,再将抗DDoS系统产品的设备出口接到下层核心交换机,被保护主机可置于核心交换机下。部署方式如图13-37所示。
图13-37 单机串联部署
2)双机热备部署
为了保证网络的高可用性与高可靠性,抗 DDoS 系统提供了双机热备功能,即在同一个双机热备模式采用了两种工作模式,主-主模式和主-从模式。两种模式详细介绍如下。
(1)主-主模式
主-主模式即让两台抗拒绝服务产品同时工作,当任意服务器发生故障,如接口及连线故障、意外宕机、关键进程失败、性能下降、CPU 和内存负载过大等情况,另外一台抗拒绝服务产品能够平滑地接替该抗拒绝服务产品的工作,并保持连接,实现负载均衡。
(2)主-从模式
正常情况下主抗拒绝服务产品处于工作状态,另一个抗拒绝服务产品处于备份状态。当主抗拒绝服务产品发生意外宕机、网络链路故障、硬件故障等情况时,从抗拒绝服务产品自动进行切换工作状态,从抗拒绝服务产品代替主抗拒绝服务产品正常工作,从而保证了网络的正常使用。切换过程不需要人为操作或其他系统的参与。如图13-38所示。
图13-38 双机热备部署主-从模式
3)多机热备部署
集群型抗 DDoS 系统依靠多台抗拒绝服务产品实现防护带宽及防护能力的增加,目前可支持多台抗拒绝服务产品形成集群,抵御大的攻击流量。首先在交换机的相应端口设置端口聚合,
或者直接设置路由器完成端口聚合,分别接入抗拒绝服务系统,每个抗拒绝服务系统接入一路数据(入口和出口)。部署方式如图13-39所示。
4)旁路部署
随着网络的高速发展,抗拒绝服务系统(抗 DDoS 系统)为防御海量 DDoS 攻击,提高网络的稳定性,推出了旁路部署解决方案。
抗 DDoS 系统旁路牵引模式,根据净化后回注流量的不同,分为两种部署模式:回流模式和注入模式。旁路系统由抗DDoS系统和流量分析器组成。抗DDoS系统对潜在流量进行彻底检测,去除攻击流量,转发过滤后的纯净流量。流量分析器则对网络流量进行分析,将与受保护IP有关的异常流量信息通知抗DDoS系统。
图13-39 多机热备部署
在进行旁路部署时,为了增加检测的高效性,提高对攻击流量的防御,抗 DDoS 系统除了单台部署外,也支持集群模式部署,同时也支持回流与注入模式下的集群部署。
5)旁路回流部署
抗 DDoS 系统回流模式下,系统在处理过流量之后,将纯净流量再次从原路发回网络。从抗DDoS系统发回的流量直接送至下层设备,否则核心路由器和抗DDoS系统产品之间会形成流量的无线循环。部署方式如图13-40所示。
6)旁路注入部署
注入模式:抗拒绝服务系统处理流量之后,将纯净流量直接注入下层设备,如图 13-41所示。采用此种模式,考虑下层设备的不同,有两种不同的配置:
若下层设备为交换机,则抗拒绝服务系统将自动解析目标主机的 MAC 地址,并将纯净流量直接发送至该主机。
若下层设备为路由器,则需要在抗拒绝服务产品上设置下层路由器的地址(下一跳地址),若是集群则每台设备都要独立设置。
2)信息安全等级保护要求
《信息安全等级保护管理办法》 要求组织对信息系统分等级实行安全保护,其中明确要求计算机信息系统创建和维护受保护客体的访问审计跟踪记录。数据库审计本身就是一个信息安全防范问题,政府机关、医院等重要的信息系统属于三级,属于公安机关强制性信息安全防护要求等级。
(1)等级保护三级基本要求
① 应提供覆盖到每个用户的安全审计功能,对应用系统的重要安全事件进行审计。
② 应保证无法单独中断审计进程,无法删除、修改或覆盖审计记录。
③ 审计记录的内容至少应包括事件的日期、时间、发起者信息、类型、描述和结果等。
④ 应提供对审计记录数据进行统计、查询、分析及生成报表等功能。
(2)等级保护三级测评要求
① 应设置安全审计员,询问应用系统是否有安全审计功能、对事件进行审计的选择要求和策略是什么、对审计日志的保护措施有哪些。
② 应检查主要应用系统,查看其当前审计范围是否覆盖到每个用户。
③ 应检查主要应用系统,查看其审计策略是否覆盖系统内重要的安全相关事件,如用户标识与鉴别、访问控制的所有操作记录、重要用户行为、系统资源的异常使用、重要系统命令的使用等。
④ 应检查主要应用系统,查看其审计记录信息是否包括事件发生的日期与时间、触发事件的主体与客体、事件的类型、事件成功或失败、身份鉴别事件中请求的来源、事件的结果等内容。
⑤ 应检查主要应用系统,查看其是否为授权用户浏览和分析审计数据提供专门的审计分析功能,并能根据需要生成审计报表。
⑥ 应检查主要应用系统,查看其是否能够对特定事件指定实时报警方式。
⑦ 应测试主要应用系统,可通过非法终止审计功能或修改其配置,验证审计进程是否受到保护。
⑧ 应测试主要应用系统,在应用系统上试图产生一些重要的安全相关事件,查看应用系统是否对其进行了审计,验证应用系统安全审计的覆盖情况和记录情况与要求是否一致。
⑨ 应测试主要应用系统,试图非授权删除、修改或覆盖审计记录,验证安全审计的保护情况与要求是否一致。
等级保护是公安部、国家保密局等多个权威部门联合制定的国家信息安全标准,也是目前推广最为广泛、对国家信息安全影响最大的安全标准。推动等级保护对于促进信息化健康发展,保障各行各业体制改革,维护公共利益、社会秩序和国家安全具有重要意义。
2.数据库审计产品概述
数据库审计产品对审计和事务日志进行审查,从而跟踪各种对数据库操作的行为。一般审计主要记录对数据库的操作及改变、执行该项目操作的人,以及其他属性。这些数据库被记录到数据库审计独立平台中,并且具备较高的准确性和完整性。针对数据库活动或状态进行取证检查时,审计可以准确地反馈数据库的各种变化,给分析数据库的各类正常、异常、违规操作提供证据。
数据库安全审计系统由基础层、引擎层、业务层和接口管理层组成,如图 13-43 所示。其中,基础层和引擎层共同构成合理的后台架构,该架构可概括为“一库”“二机制”“三平台”“四引擎”。
图13-43 数据库安全审计系统
数据库审计产品作为全业务审计系统,支持各种数据库操作方案、网络操作方式。如图13-44所示,包括基于客户端的链接审计、基于ODBC/JDBC等的链接访问、本地操作、网络操作等。
3.部署方案为了完全不影响数据库系统的自身运行与性能,数据库安全审计系统应支持采用旁路监听模式,具体可分为核心交换机网络监听模式和集中管理平台部署模式。
图13-44 数据库审计产品
1)核心交换机网络监听模式
通过在核心交换机上设置端口镜像模式或采用 TAP 分流监听模式,使安全审计引擎能够监听到所有用户通过交换机与数据库进行通信的全部操作。具体部署结构如图 13-45所示。
图13-45 核心交换机网络部署结构
2)集中管理平台部署模式
在大型审计项目集中管理中,过去无法实现对数据库审计设备或防统方系统的集中管理、维护、监控、预警,审计中心很难得到有效的汇总报告,设备出现故障无法及时准确定位,权限分散的管理模式使管理维护成本居高不下,数据库审计系统提供了数据库审计或防统方集中管理和技术手段,彻底解决了大型数据库审计项目或大型区域医疗防统方系统面临的部署、管理、监控、预警及日志方面的问题。
14.1 应急响应介绍
什么是应急响应?一般来说,应急响应机制是由政府或组织推出的针对各种突发事件而设立的各种应急方案,通过该方案使损失程度降低到最小。应急响应系统是指为应对突发事件,由一定的(作业实施)要素按特定的组织形式构成,以实现社会系统安全保障功能为目的的统一整体。随着近年来越来越多大型企业逐渐实现办公环境,甚至生产环节的网络化,部分企业已经建立起企业级的应急响应机制和应急响应系统。
应急响应的主体通常是公共部门,如政府部门、大型机构、基础设施管理经营单位或企业等。应急响应所处理的问题通常为突发公共事件或突发重大安全事件。应急响应所采取的措施通常为临时性的应急方案,属于短期的针对性较强的处置措施。应急响应的首要目的是减小突发事件所造成的损失,包括财产损失和企业的经济损失,以及相应的社会不良影响等。应急响应方案是一项复杂而体系化的突发事件应急方案,包括预案管理、应急行动方案、组织管理、信息管理等环节。其相关执行主体包括应急响应相关责任单位、应急指挥人员、应急响应工作实施单位、事件发生当事人。
互联网面临的主要安全风险有以下几种:
(1)计算机病毒事件:病毒指编制者在计算机程序中插入的破坏计算机功能或数据、影响计算机使用且能够自我复制的一组计算机指令或程序代码。
(2)蠕虫事件:指网络蠕虫,其表现形式为,内、外部主机遭受恶意代码破坏或从外部发起对网络的蠕虫感染。
(3)木马事件:指通过特定的程序(木马程序)来控制另一台计算机。木马通常有两个可执行程序:一个是控制端,另一个是被控制端。
(4)僵尸网络事件:指采用一种或多种传播手段,将大量主机感染 bot 程序(僵尸程序)病毒,从而在控制者和被感染主机之间所形成的一个可一对多控制的网络。
(5)域名劫持事件:指通过攻击域名解析服务器(DNS),或伪造域名解析服务器的方法,把目标网站域名解析到错误的地址,从而达到使用户无法访问目标网站的目的。
(6)网络仿冒事件:指不法分子在互联网上仿冒知名电子交易站点(如银行或拍卖网站)的网页,诱使用户访问假站点,骗取用户的账户和密码等信息,从而窃取钱财。
(7)网页篡改事件:指攻击者已经获取了网站的控制权限,将网页篡改为非本网站的页面。
(8)网页挂马事件:指攻击者已经获取了网站的控制权限,在网站上插入恶意代码,以实现针对所有访问者进行木马攻击事件。
(9)拒绝服务攻击事件:拒绝服务攻击即攻击者想办法让目标机器停止提供服务,是黑客常用的攻击手段之一。
(10)后门漏洞事件:指攻击者已经获取了网站或服务器权限,为实现长久控制的目的,在网站或服务器上留下可再次进入的后门程序。
(11)非授权访问事件:指没有经过预先同意,就使用网络或计算机资源,例如,有意避开系统访问控制机制,对网络设备及资源进行非正常使用,或者擅自扩大权限,越权访问信息。主要有以下几种形式:假冒、身份攻击、非法用户进入网络系统进行违法操作、合法用户以未授权方式进行操作等。
(12)垃圾邮件事件:指未经用户许可(与用户无关)就强行发送到用户邮箱中的任何电子邮件。
(13)其他网络安全事件:指其他未在上述中定义的网络安全事件。
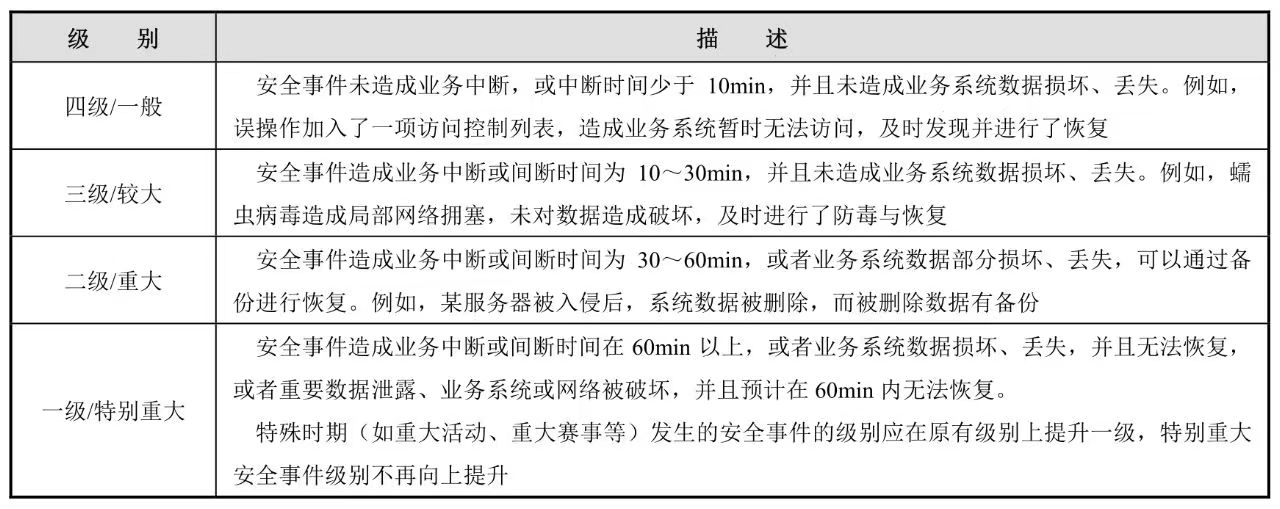
根据网络与信息安全突发事件的可控性、严重程度和影响范围,一般将其分为四个级别:四级/一般、三级/较大、二级/重大、一级/特别重大(见表14-1)。
14.2 信息安全事件处理流程
领导组接收到任务单后,分析判断事件分类及分级启动应急预案,协调相关小组人员进行应急响应。在国内发生特别重大突发公共事件,以及召开重要会议、重大国事活动等特殊重要时期,没有发生三级以上重大业务系统安全事件时,按照“三级/较大”级别安全事件的处理要求和流程做好应急准备;当发生或可能发生三级以上重大业务系统安全事件时,各工作小组应根据本预案,按高一级别安全事件的处理要求和流程进行各项应急处理。安全事件处理流程如图14-1所示。
图14-1 安全事件处理流程
安全事件的输入/输出包括任务单、客户授权书、应急处置报告模板、安全事件记录报告、应急处置报告。
14.5 网络安全应急响应具体实施
为最大限度科学、合理、有序地处置网络安全事件,采纳了业内通常使用的PDCERF 方法学(最早于 1987 年由美国宾夕法尼亚匹兹堡软件工程研究所在“关于应急响应”的邀请工作会议上提出),将应急响应分成准备(Preparation)、检测(Detection)、抑制(Containment)、根除(Eradication)、恢复(Recovery)、跟踪(Follow-up)6 个阶段的工作,并根据网络安全应急响应总体策略对每个阶段定义适当目的,明确响应顺序和过程。
14.5.1 准备阶段
准备(Preparation)阶段是应急响应事的第一个阶段,是处于事件未发生与已发生时间的中间点上。因此这个阶段更多的是“未雨绸缪”,在其他阶段更多的是“亡羊补牢”。该阶段准备的充分与否,直接决定了在事件真正发生时处理的效率和结果。准备阶段主要做两件事情:及时备份、准备应急响应工具包。备份指系统备份、数据备份等,在进行安全检测时,通过将最近保存的备份信息与当前信息进行比对,能够快速、准确地发现系统变更和异常。应急响应工具包是指在发生信息安全应急响应事件时可以协助工作人员完成应急工作或提高应急效率的工具集合。工具包中应当包含Windows、Linux、UNIX等系统的应急工具。工具包的管理应遵循两个原则:①及时更新;②可信任。及时更新保证技术前沿,防止技术壁垒。可信任指工具无病毒、木马等,往往要求存储介质为只读。
14.5.2 检测阶段
在检测阶段首先确认入侵事件是否发生,如真发生,则评估造成的危害、范围及发展速度,以及事件会不会进一步升级;然后根据评估结果通知相关人员进入应急流程。检测阶段主要包括事件类型、事件影响范围、受影响系统、事件发展趋势、安全设备等。
网络安全事件的分类主要参考中央网信办发布的《国家网络安全事件应急预案》。网络安全事件分为有害程序事件、网络攻击事件、信息破坏事件、信息内容安全事件、设备设施故障、灾害性事件和其他网络安全事件等。
(1)有害程序事件分为计算机病毒事件、蠕虫事件、特洛伊木马事件、僵尸网络事件、混合程序攻击事件、网页内嵌恶意代码事件和其他有害程序事件。
(2)网络攻击事件分为拒绝服务攻击事件、后门攻击事件、漏洞攻击事件、网络扫描窃听事件、网络钓鱼事件、干扰事件和其他网络攻击事件。
(3)信息破坏事件分为信息篡改事件、信息假冒事件、信息泄露事件、信息窃取事件、信息丢失事件和其他信息破坏事件。
(4)信息内容安全事件是指通过网络传播法律法规禁止信息,组织非法串联、煽动集会游行或炒作敏感问题并危害国家安全、社会稳定和公众利益的事件。
(5)设备设施故障分为软硬件自身故障、外围保障设施故障、人为破坏事故和其他设备设施故障。
(6)灾害性事件是指由自然灾害等其他突发事件导致的网络安全事件。
(7)其他网络安全事件是指不能归为以上分类的事件。
14.5.3 抑制阶段
应急抑制分为物理抑制、网络抑制、主机抑制和应用抑制 4 个层次的工作内容,在发生信息安全事件时,应根据对事件定级结果,综合利用多个层次的抑制措施,保证抑制工作的及时有效。
1)物理抑制
(1)切断网络连接:关闭网络设备或切断线路,避免安全事件在网络之间扩散。
(2)提高物理安全级别:实施更为严格的人员身份认证和物理访问控制机制。
(3)环境安全抑制:主要针对环境安全的威胁因素,例如,发生火灾时关闭防火门、启用消防设备和防火通道、启动排烟装置、切断电源,发生水灾时启用排水设备、关闭密封门,发生电力故障时启用UPS和备用发动机等。
2)网络抑制
(1)网络边界过滤:对路由器等网络边界设备的过滤规则进行动态配置,过滤包含恶意代码、攻击行为或有害信息的数据流,切断安全事件在网络之间的传播途径。
(2)网关过滤:对防火墙、WAF、DDoS 防护系统等网关设备的过滤规则进行动态配置,阻断包含恶意代码、攻击行为或有害信息的数据流进入网关设备保护的网络区域,有效实施针对信息安全事件的网络隔离。
(3)网络延迟:采用蠕虫延迟和识别技术,限制恶意代码在单位时间内的网络连接,有效降低蠕虫等恶意代码在网内和网间的传播速度,减小蠕虫事件对受保护网络系统的影响范围。
(4)网络监控:提高网络入侵检测系统、专网安全监控系统的敏感程度和监控范围,收集更为细致的网络监控数据。
3)主机抑制
(1)系统账户维护:禁用主机中被攻破的系统账户和攻击者生成的系统账户,避免攻击者利用这些账户登录主机系统,进行后续破坏。
(2)提高主机安全级别:实施更为严格的身份认证和访问控制机制,启用主机防火墙或提高防火墙的安全级别,过滤可疑的访问请求。
(3)提高主机监控级别:提高主机入侵检测系统、主机监控系统的敏感程度和监控范围,收集更为细致的主机监控数据。
4)应用抑制
(1)应用账户维护:禁用被攻破的应用账户和攻击者生成的应用账户,避免攻击者利用这些账户登录应用服务,进行后续破坏。
(2)提高应用安全级别:针对应用服务,实施更为严格的身份认证和访问控制机制,提高攻击者攻击应用服务的难度。
(3)提高应用监控级别:提高应用入侵检测和监控系统的敏感程度及监控范围,收集更为细致的应用服务监控数据。
(4)关闭应用服务:杜绝应用服务遭受来自网络的安全事件影响,或避免应用服务对外部网络环境产生影响。
抑制阶段的操作要严格按照抑制处理方案中的内容执行,并依据《系统变更管理办法》获得用户授权。
14.5.4 根除阶段
根除阶段是指在抑制阶段的基础上,根据事件产生的根本原因,给出清除危害的解决方案的阶段。可以从以下几个方面入手:系统基本信息、网络排查、进程排查、注册表排查、计划任务排查、服务排查、关键目录排查、用户组排查、事件日志排查、Webshell 排查、中间件日志排查、安全设备日志排查等。根除阶段的实施有一定风险,在于系统升级或打补丁时可能造成系统故障,所以要做好备份工作。如图14-2所示为根除阶段的流程图。
图14-2 根除阶段的流程图
在信息安全事件被抑制之后,进一步分析信息安全事件,找出事件根源并将其彻底清除。对于单机事件,根据各种操作系统平台的具体检查和根除程序进行操作;针对大规模爆发的带有蠕虫性质的恶意程序,要根除各个主机上的恶意代码,则是一项艰巨的任务。
确定根除方案,协助用户检查分析所有受影响的系统是否被入侵,根据所收集的信息,确定根除方案。应急根除分为物理根除、单机根除和网络根除3个层次。为了保证彻底从受保护网络系统中清除安全威胁,针对不同类型的安全事件,综合采取不同层次的根除措施。
1)物理根除
(1)统一采用严格的物理安全措施:例
如,针对关键的物理区域,统一实施基于身份认证和物理访问控制机制,实现对身份的鉴别。
(2)环境安全保障:主要针对环境安全的威胁因素,例如,使用消防设施扑灭火灾,更换出现故障的电力设备并恢复正常的电力供应,修复网络通信线路,修复被水浸湿的服务器等。
(3)物理安全保障:加强视频监控、人员排查等措施,最大限度地减少对受保护信息系统可能造成威胁的人员和物理因素。
2)单机根除(包括服务器、客户机、网络设备及其他计算设备)
(1)清除恶意代码:清除感染计算设备的恶意代码,包括文件型病毒、引导型病毒、网络蠕虫、恶意脚本等,清除恶意代码在感染和发作过程中产生的数据。
(2)清除后门:清除攻击者安装的后门,避免攻击者利用该后门登录受害计算设备。
(3)安装补丁和升级:安装安全补丁和升级程序,但必须事先进行严格的审查和测试,并统一发布。
(4)系统修复:修复由于黑客入侵、网络攻击、恶意代码等信息安全事件对计算设备的文件、数据、配置信息等造成的破坏,如被非法篡改的系统注册表、信任主机列表、用户账户数据库、应用配置文件等。
(5)修复安全机制:修复并重新启用计算设备原有的访问控制、日志、审计等安全机制。
3)网络根除
(1)所有单机根除:对受保护网络系统中所有的服务器、客户机、网络设备和其他计算设备进行上述单机根除工作。
(2)评估排查:对受保护网络系统中所有计算设备进行评估排查,测试是否仍然存在被同种信息安全事件影响的单机。
(3)网络安全保障升级:对网络中的安全设备、安全工具进行升级,使其具备对该安全事件的报警、过滤和自动清除功能,如向防火墙增加新的过滤规则、向入侵检测系统增加新的检测规则等。
14.5.5 恢复阶段
恢复阶段的主要任务是把被破坏的信息彻底还原到正常运作状态。确定使系统恢复正常的需求和时间表、从可信的备份介质中恢复用户数据,打开系统和应用服务,恢复系统网络连接,验证恢复系统,观察其他扫描、探测等可能表示入侵者再次侵袭的信号。一般来说,要成功恢复被破坏的系统,需要维护干净的备份系统,编制并维护系统恢复的操作手册,并且在系统重装后需要对系统进行全面的安全加固。如图 14-3 所示是恢复阶段工作流程图。
图14-3 恢复阶段工作流程图
完成安全事件的根除工作后,需要完全恢复系统的运行过程,把受影响系统、设备、软件和应用服务还原到其正常的工作状态。如果在抑制过程中切换到备份系统,则需要重新切换到已完成恢复工作的原系统。恢复工作应该十分小心,避免出现误操作导致数据丢失或损坏。恢复工作中如果涉及国家秘密信息,须遵守保密主管部门的有关要求。恢复工作分为五个阶段,即系统恢复阶段、网络恢复阶段、用户恢复阶段、抢救阶段和重新部署/重入阶段。
1)系统恢复阶段
负责恢复关键业务需要的服务器及应用程序的阶段称为系统恢复阶段。系统恢复过程完成的标志是数据库已经可用、用户的数据通信链路已经重新建立、系统操作用户也已经开始工作。网络和用户恢复与系统恢复是同步进行的。
2)网络恢复阶段
在网络恢复阶段,负责安装通信设备和网络软件,配置路由及远程访问系统,恢复数据通信,部署设置网络管理软件和网络安全软件等,恢复受灾系统的网络通信能力。
3)用户恢复阶段
当系统和网络就绪之后,在本阶段,使用抢救出来的记录及备份存储的数据和信息,尽快恢复数据库。
4)抢救阶段
抢救行动与其他灾难恢复工作同步进行,包括收集和保存证据,评估数据中心和用户操作区环境的恢复可行性及花费,抢救数据、信息和设备并转移到备份区域。
5)重新部署/重入阶段
根据灾难恢复计划中定义的工作职能,使系统、网络和用户重新部署到原有的或新的设施中,并把应急状态下的服务级别逐步切换回正常服务级别。
(1)明确风险:明确在恢复过程中,可能给用户系统带来的风险,并告知用户,获得用户同意后再进行实施。
(2)重建系统、数据备份:将需要重建的系统数据进行完整备份并导出,备份包括每个软件的版本信息,业务系统中的源代码、数据库结构(表结构、存储过程、视图、索引、函数等)、业务运作数据、系统配置参数、日志文件等;对于软件的版本信息,打开软件查看并记录业务系统中的源代码,进行压缩后复制,复制后解压,然后进行病毒查杀确保没有木马后门,利用数据库管理软件将数据库的结构和业务数据导出,并分析数据有没有被攻击者修改过,修改系统的配置参数,将相关的日志文件压缩后复制,复制完成后解析,进行病毒查杀,确保备份的数据没有被攻击者修改过。
(3)安装新操作系统:在另一台服务器上新建一个新的操作系统,操作系统的文件要经过hash比对,确保是官方正版系统。
(4)配置基线及访问控制:在新操作系统中进行基线配置,做好相应的安全策略和访问控制策略,安装相应的防护软件。
(5)数据恢复:进行应用和数据恢复,并恢复原有的系统配置。数据恢复成功后进行上线前测试,不成功则分析原因并解决。
(6)上线测试:恢复完成后进行测试,确保业务系统正常运行、配置与原有系统的配置一致,测试完成后上线。
(7)应急演练:开展重建系统的应急演练工作,并进行记录。
14.5.6 跟踪阶段
在业务系统恢复后,需要整理一份详细的事件总结报告,包括事件发生及各部门介入处理的时间线及事件可能造成的损失,为客户提供安全加固优化建议。回顾、总结梳理应急响应事件的过程信息,提高应急响应小组的技能,以应对类似场景。同时跟进系统,确认系统没有被再次入侵。跟踪阶段主要包括调查事件原因、输出应急响应报告、提供安全建议、加强安全教育、避免同类事件再次发生。
14.5.7 应急响应总结
回顾并整理已发生信息安全事件的各种相关信息,尽可能地把所有情况记录到文档中,发生重大信息安全事件时,应急响应小组应当在事件处理完毕后一个工作日内,将处理结果上报给甲方备案。通过对信息安全事件进行统计、汇总及任务完成情况总结,不断改进信息安全应急响应预案。针对本次应急响应特点对单位的网络或信息安全提出加固建议,必要时指导和协助客户实施,提高服务器、网络设备、网络安全设备的安全性,满足总体安全目标
第3篇 数据中心安全
本篇摘要
本篇旨在帮助读者理解以下概念:
1.数据中心架构
● 数据中心概念,什么是数据中心、数据中心发展历程;
● 数据中心组成,包括物理环境、存储、网络、业务、数据。
2.数据中心面临的威胁
● 可用性威胁,包括自然灾害、断电、网络安全、病毒、误操作等;
● 机密性威胁,包括窃听、社会工程学、入侵、身份冒用等;
● 完整性威胁,包括误操作、入侵等。
3.数据中心规划与建设
● 数据中心规划,包括需求分析、设计原则、网络架构规划、安全域划分;
● 服务器虚拟化,包括虚拟化介绍、VMware虚拟化、虚拟化安全;
● 数据中心高可用性建设,包括接入层面的 LACP、路由层面的 VRRP、容灾备份等。
4.数据中心安全防护与运维
● 安全防御体系概述,包括边界防御体系、纵深防御体系;
● 安全管理与运维,包括安全管理、IT运维管理、安全运维;● 数据中心常用的安全产品,包括 IPS、IDS、漏洞扫描、堡垒机、数据防火墙、DLP防泄密。
5.数据中心新技术
● SDN技术;
● VXLAN技术。
15.2 数据中心发展历程
15.2.1 数据中心产生
1945 年,美国生产了第一台全自动电子数字计算机“埃尼阿克”(ENIAC,电子数字积分器和计算器),它是美国奥伯丁武器试验场为了满足计算弹道需要而研制成的。这台计算机于1946年2月交付使用,共服役9年。它采用电子管作为计算机的基本元件,每秒可进行5000次加减运算。它使用了18000只电子管,10000只电容,7000只电阻,体积为3000立方英尺,占地170平方米,重量达30吨,是一个名副其实的庞然大物,这个庞然大物就被业界看作数据中心的雏形和鼻祖(见图15-1)。
图15-1 数据中心的雏形15.2.2 存储数据中心
到了 20 世纪 60 年代,数据中心最关注的是存储计算能力,可能一台小型机就可以做成一个数据中心,是最小规模的数据中心。存储数据中心的功能单一,仅仅用于一些电子文档和数据的存档与管理,主要应用于国防领域和科研领域,如图15-2所示。
图15-2 存储数据中心
15.2.3 计算数据中心
20世纪80年代,随着计算需求的增加和服务器价格的下降,微机市场呈现出一片繁荣的景象,数据中心逐渐以计算能力为引导,此时建立的数据中心主要包含一些零零散散的服务器和存储产品,有些统一放置,有些则各自为战,如图15-3所示。
随着虚拟化技术的稳定发展与逐步成熟,传统数据中心的模式带来的效率利用低下的劣势慢慢地凸显出来,故虚拟化数据中心产生与使用也越来越广泛。虚拟化数据中心是将各类物理 IT 资源进行整合并在逻辑上进行虚拟化处置,屏蔽了不同物理设备的异构性;基于标准接口的物理资源虚拟化为逻辑上的计算资源,形成了虚拟资源池,可以对资源进行动态的调度和弹性的扩容,大大提升了服务器资源利用率,同时也降低了数据中心的运营成本,如图15-5所示。
图15-5 虚拟化数据中心
2.云数据中心
云数据中心是在虚拟化数据中心基础上提供更细化的服务体系,以云计算为基础建设的;这一阶段主要以服务作为 IT 的核心,可以基于租户的需求提供对应的 API 接口,对其提供各种二次开发等定制化服务,满足租户的个性化需求。云数据中心与云计算具有相同的特点,包括资源共享、弹性调度、服务可扩展、按需分配、高速运算、高可用与冗余、自动化管理,如图15-6所示。
云数据中心以云计算为基础建设,这里不得不提一下云计算;有人说云计算带来了第三次 IT 革命,它改变了人们获取信息、资源的方式,使我们进入了一个崭新的 IT 时代。对于云计算,业界并没有形成统一认可的说法。在这里总结为:云计算是一种能为用户提供自动化、可伸缩、即需即供的各类不同计算资源的 IT 服务能力。云数据中心以云计算为基础,它拥有与云计算相同的特点,与传统数据中心相比,云数据中心拥有3个特征:
● 更加规模化、标准化、标准化。
● 建设成本更低,承载的业务更多。
● 管理的高度自动化。
图15-6 云数据中心
1)云数据中心机房结构
为满足云计算服务弹性的需要,云计算机房采用标准化、模块化的机房设计架构。模块化机房包括集装箱模块化机房和楼宇模块化机房。集装箱模块化机房在室外无机房场景下应用,减轻了建设方在机房选址方面的压力,帮助建设方将原来半年的建设周期缩短到两个月,而能耗仅为传统机房的 50%,可适应沙漠炎热干旱地区和极地严寒地区的极端恶劣环境。楼宇模块化机房采用冷热风道隔离、精确送风、室外冷源等领先制冷技术,可适用于大中型数据中心的积木化建设和扩展。
2)云数据中心网络系统
(6)资源整合原则:在保障安全的前提下安全域的划分要有利于实现 IT 资源的整合,充分实现IT资源的共享和复用。
安全域的划分除了遵循上述根本原则外,还要根据业务逻辑、地域与管理模式、业务特点进行划分。
3.安全域服务的内容
安全域的划分与边界整合,主要包括业务信息系统的系统调研、将 IT 要素进行逻辑划分、安全域的边界整合;安全的防护策略设计,信息系统和安全域的保护等级定级、安全域防护策略与规范的制定;安全域的防护改造,进行差距分析、提出相应的改造方案、改造实施;安全域的管理制度设计,设计安全域的管理、审计制度、设计安全审计指标体系、设计信息系统审计检查表。
4.安全域划分原理
以业务为中心,流程为导向。从各种业务功能、管理、控制功能出发,梳理其数据流,刻画构成数据流的各种数据处理活动/行为,分析数据流、数据处理活动的安全需求;规范和优化系统结构。基于业务信息系统的结构,根据目标和安全需求进行安全域防护策略设计和优化;有效地控制信息安全风险。基于业务系统外部环境、总体安全防护策略要求进行防护规范设计;符合相关标准、要求(如 SOX、COSO、ISO 27001、网络安全等级保护、企业标准)。
5.安全域划分依据
导致安全需求、安全策略差异化的因素考虑,一般包括现状结构、威胁、目标要求等。不同安全域基本类型具有不同的差异化因素。
6.规划安全域的意义
规划安全域的意义如下:
● 规划有效的安全保障(技术)体系。
● 系统新、改、扩建的依据、规范。
● 明确安全措施的需求和策略。
● 检查和评估的基础。
● 持续安全保障方法。
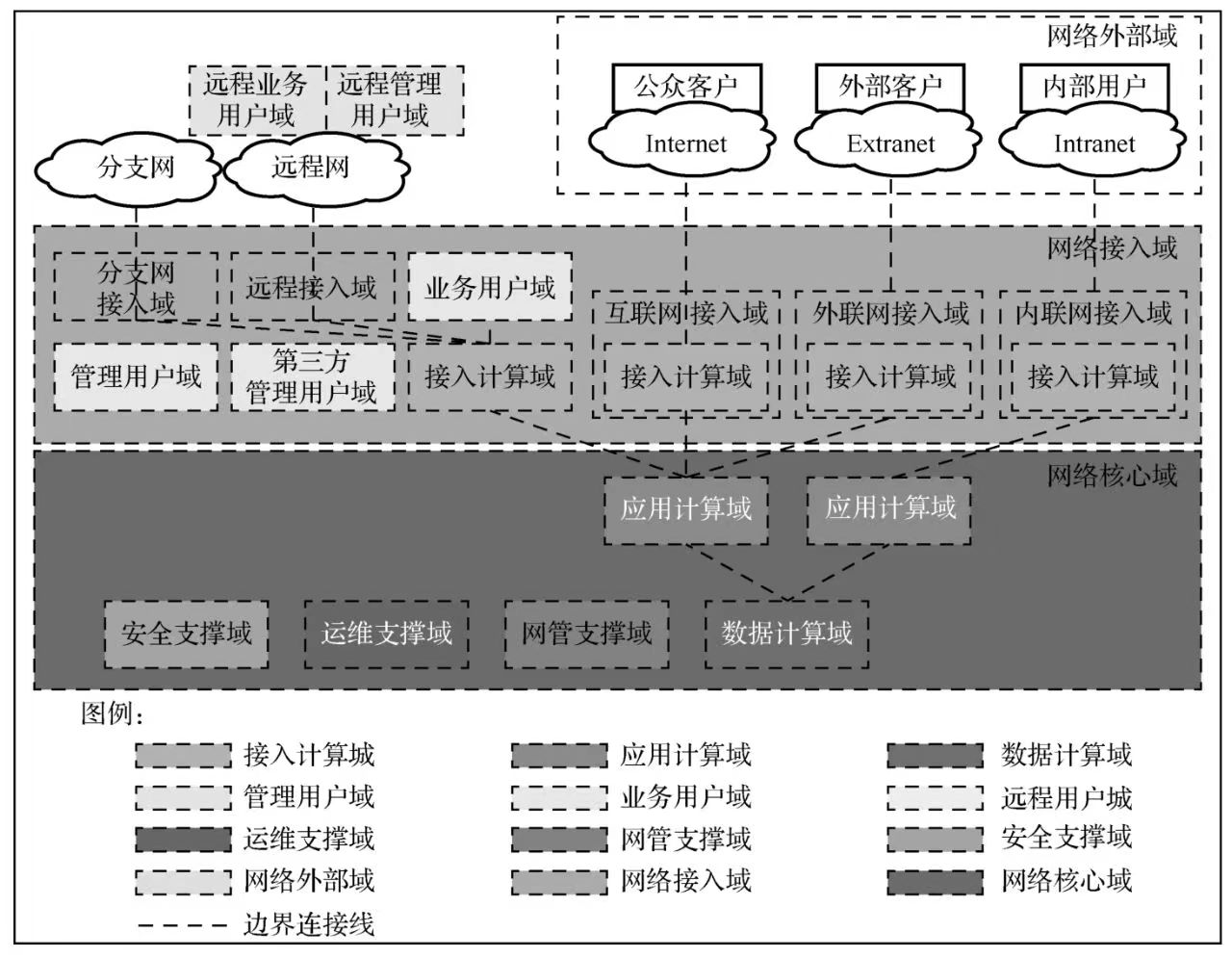
7.安全域通常划分的元素
在进行安全域划分时,包括的 IT 元素有:主机、设备、终端,业务系统,进程、线程,人员,物理环境,IT流程等。
8.安全域通常划分的种类
安全域在划分过程中一般分为 4 种:用户域、计算域、支撑域、网络域。以这 4 种安全域再进行扩展,如图17-1所示。
图17-1 安全域划分
每种安全域的颜色均不同,其中用户域为黄色,计算域为红色,支撑域为蓝色,网络域为绿色,颜色越深表示级别越高,重要程度越重要。
(1)用户域:由多个进行存储、处理和使用数据信息的终端组成,通过接入方式是否相同与能够访问的数据是否相同进行划分。
(2)计算域:由局域网中多台服务器/主机等计算资源组成,数据的产生、计算、存储都依靠该区域,因数据的重要性及计算、存储要求都不相同,数据中心会有多个计算域,且在物理位置上相近或相邻。
(3)支撑域:由用于辅助运维人员日常工作的管理系统/资源组成,按照具备的功能特点进行划分。
(4)网络域:由连接不同安全域之间的网络组成,根据连接的两个安全域之间承载的数据大小和重要程度进行划分。
9.安全域划分的方法
以业务为中心,根据业务运行流程,先拆分、再整合,最后配合网络架构和应用需求统一划分,如图17-2所示。
图17-2 安全域划分
首先,要对目标实体的业务、具体服务和网络架构这三个层面进行拆分,每个层面结合业务逻辑进行细化。
其次,具体以 Web 业务应用为例,根据业务数据流,垂直拆分业务服务模块。根据业务逻辑,区分不同的业务数据流组。水平分割,不同的业务数据流组应划分为不同的VLAN,进行逻辑隔离。
最后,针对不同业务组、业务服务模块、业务网元、网络架构之间的对应关系,通过数据流把它们串联起来,识别每个环节的风险,每个环节配置相应的安全策略;最后结合安全域防护手段、目标和规范,形成最终的安全域划分。
以下为某企业在进行安全域明细划分的案例,如图17-3所示。
如何基于安全域的应用制定安全改造方案?
整理需求:整理安全需求、汇总所需的安全服务。
总体设计:将安全服务在信息系统内部、外部进行分配,支撑安全域设计。
详细设计:运维支撑域、网管支撑域、网络域、计算域、用户域设计,落实到具体产品、技术、服务。如以企业网站群为例,根据不同的 Web 业务数据流,垂直拆分业务服务模块。根据业务逻辑,区分不同业务数据流组。水平分割,不同的业务数据流组应划分为不同的VLAN,进行逻辑隔离。
边界安全访问控制:不同的安全域具备不同的安全防护等级与策略,安全域间的关系是边界安全,安全域间的策略即边界安全访问控制。
图17-3 企业在进行安全域明细划分
典型行业的安全域划分案例,如图17-4、图17-5所示。
17.2 服务器虚拟化
1.虚拟化
虚拟化是一种行为或动作,它的核心原理是对物理硬件层计算资源进行抽象,最终形成一个统一的资源池。然后将这个资源池所拥有的计算能力进行处理,使之实现在延展/收缩前后数量元素虚拟为多个或将多个 IT元素虚拟成一个(多个)的技术都是虚拟化技术的展现。近年来,虚拟化技术在各个方面都有着非常迅猛的发展,常见的虚拟化包括服务器虚拟化、网络虚拟化、存储虚拟化、应用虚拟化等,我们在这里主要讲述服务器虚拟化。
2.服务器虚拟化
服务器虚拟化又称主机虚拟化,是指把一台物理服务器的资源抽象为逻辑资源,把服务器虚拟成多台相互隔离的虚拟服务器。服务器虚拟技术可以将一个物理服务器虚拟成若干个虚拟机使用,虚拟机并非真正的机器,从功能上看,它又可以看作独立的服务器,CPU、内存、存储、I/O 设计及 vSwitch 等支撑其正常运行。通过将物理服务器资源分配到多个虚拟机,同一物理平台能够同时运行多个相同或不同类型的操作系统的虚拟机,作为不同的业务和应用的支撑。
3.网络虚拟化
该技术主要包括网络产品的虚拟化,各个厂家都有自己的虚拟化方法和理念,其中网络产品的虚拟化以及扁平化的组网方式在网络虚拟化中的应用在前面已经讲过,在组网时网络组件都是以虚拟化的形式体现的,如虚拟防火墙、虚拟路由器、虚拟 IPS、虚拟防病毒系统等。
4.存储虚拟化
存储虚拟化是将实际的物理存储实体与存储的逻辑表示分离开,通过建立一个虚拟抽象层,将多种或多个物理存储设备映射到一个单一的逻辑资源池中。这个虚拟层向用户提供统一接口,向下隐藏了存储的物理实现,屏蔽了具体物理存储设备的物理特性,呈现给用户的是逻辑设备,用户对逻辑设备的管理和使用是经过虚拟存储层映射的。
5.应用虚拟化
应用虚拟化是将应用程序和操作系统解耦合,为应用程序提供了一个虚拟的运行环境。在这个环境中,不仅包括应用程序的可执行文件,还包括它所需要的运行环境。应用虚拟化是把应用对底层的系统和硬件的依赖抽象出来,应用虚拟化技术原理是基于应用/服务器计算架构,采用类似虚拟终端的技术,把应用程序的人机交互逻辑与计算逻辑隔离开来。在用户访问一个服务器虚拟化后的应用时,用户计算机只需要把人机交互逻辑传送到服务器端,服务器端便可为用户开设独立的会话空间,应用程序的计算逻辑在这个会话空间中运行,把变化后的人机交互逻辑传送给客户端。
17.2.1 为什么使用服务器虚拟化
很多组织都拥有自己的数据中心,业务系统及支撑其服务能力的服务器数量非常庞大,按照传统的部署方式,每一个新业务系统的上线,都要重新部署新的服务器支撑,每个业务系统服务水平需求增加时,也要部署新的服务器进行扩容,这将导致如下的一些问题。
(1)成本太高:每次新增购买服务器,都有不小的成本投入,与之配备的数据中心空间、机柜、网线等都会产生更多额外的成本。下每个业务系统至少配置一个服务器,单机的可用性差,在进行维护和升级时都要停机,业务中断,如果配置为双机模式,成本会更高。
(3)可管理性差:数量众多,难以管理,每个业务需求的变更可能都要投入大量的人力资源。
(4)部署难度大:如果一个业务系统以十台服务器进行集群化部署,那操作系统、数据库、业务应用软件的部署次数都是至少十次,部署难度不难想象。
(5)资源浪费:据调研结果,传统的业务系统所在服务器资源日常使用率都在20%~30%,大多时候都是处于闲置状态,这是为应对业务高峰期服务能力所做的准备,且其在闲置状态运行会消耗电量,制冷也需要额外的电量,无论是在经济上还是环保上都不是我们想看到的结果。
(6)兼容性存在问题:在进行应用迁移时,新的服务器未必可以兼容原有的系统。
17.2.2 虚拟化和虚拟机
这里说的虚拟化,指的是服务器虚拟化。服务器虚拟化主要表现在操作系统层面,让一台物理计算机并发运行多个操作系统,这种虚拟化功能的机制被称为 VMM(Virtual Machine Monitor),也常被称作 Hypervisor。Hypervisor 架构(服务器虚拟化架构)分为两种:寄居架构和裸金属架构。
大家可能使用过VMware workstation或Microsoft Virtual PC这种虚拟机,在使用虚拟机的过程中不需要对物理硬盘进行分区,也不影响原有硬盘上的系统、数据和已经安装的软件,在虚拟机中运行的操作系统与应用都是独立的,这种虚拟机具备以下的特征。
(1)兼容性:与所有标准的 x86 计算机都兼容,可以使用虚拟机在 x86 物理计算机上运行所有的相同软件。
(2)隔离性:在安装多个虚拟机时,虚拟机之间是相互隔离的,互不影响。
(3)封装:虚拟机将整个运算环境封装起来。所以虚拟机实质上是一个软件容器,将一整套虚拟硬件资源、操作系统及应用程序封装到一个软件包内,使得虚拟机具备超乎寻常的可移动性且易于管理。
(4)独立性:独立于底层硬件而运行,可以为虚拟机配置与底层硬件上存在的物理组件完全不同的虚拟组件,也可以安装不同类型的操作系统(如Windows和Linux等)。
VMware workstation就是寄居架构,这种架构的Hypervisor被当成一个应用或服务来使用,需依托在操作系统上运行。当然,这种架构的缺陷也很明显,如果所依托的操作系统出现故障,上面承载的虚拟机也就无法正常使用,所以这种架构的虚拟化产品只适用于个人用户,很难在企业市场上有所作为。而我们在企业中常用的 VMware 的 vCenter server和微软的Hyper-V都是使用裸金属架构,它是将Hypervisor直接安装在硬件上的,将所有硬件源进行资源接管,此架构的性能与物理主机基本相当,这是寄居架构难以比拟的。但裸金属架构的虚拟化产品为了保持稳定性及微内核,不会将太多硬件驱动都放入,所以兼容性上有一定的缺陷。虚拟化的两种架构如图17-6所示。
图17-6 虚拟化的两种架构
虚拟机包含的文件如下:
●.vmx—虚拟机配置文件(文本)。
●.nvram—虚拟机BIOS文件(二进制)。
●.vmdk—虚拟磁盘描述文件(仅描述信息,非常小)。
●-flat.vmdk—虚拟磁盘数据文件(实际数据)。
●-rdm.vmdk—裸设备映射虚拟磁盘文件。
●.vswp/vmx-*.vswp—vmkernel swap文件,也称为虚拟机交换文件。
●.vmtx—模板的配置文件(文本)。
●.vmsd/.vmsn/-delta.vmdk—虚拟机快照文件及磁盘delta数据文件。
●.log—虚拟机日志文件。
●.vmss—挂起状态文件。
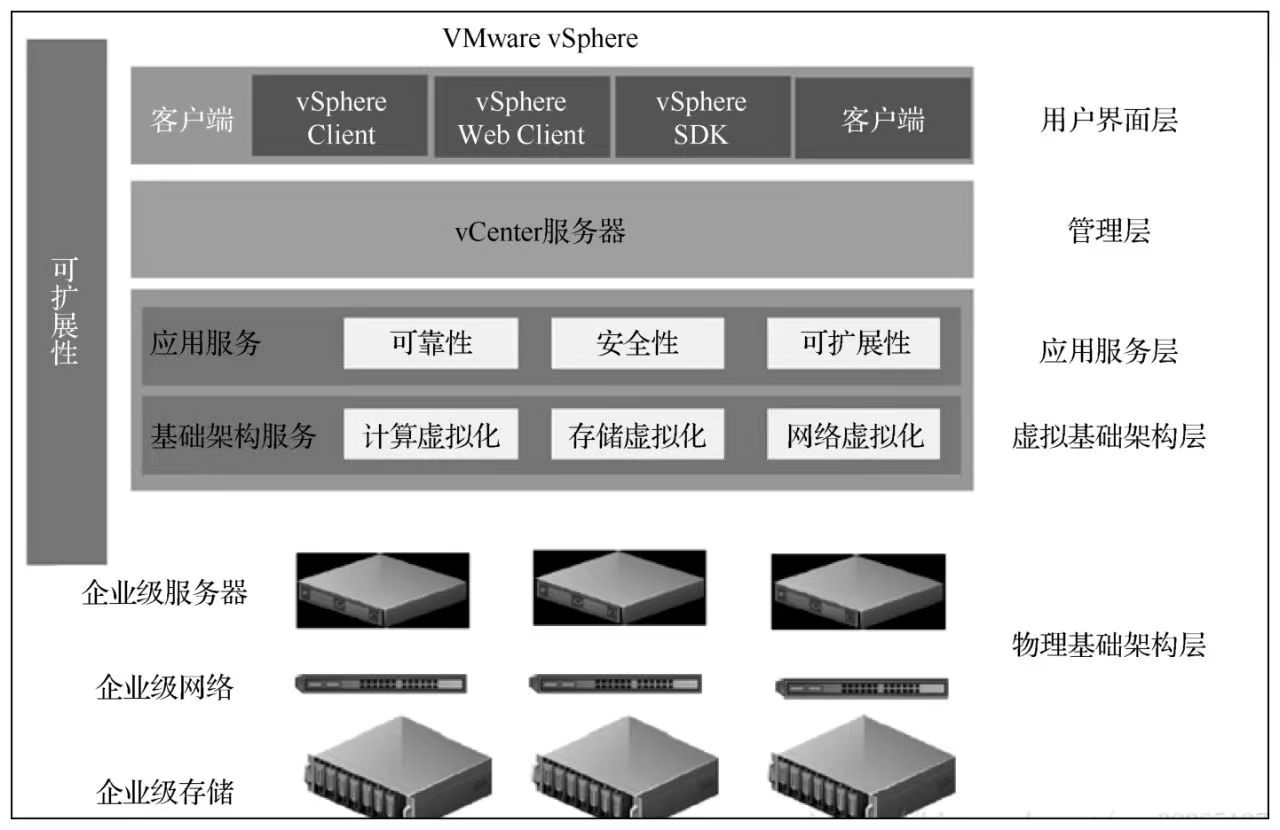
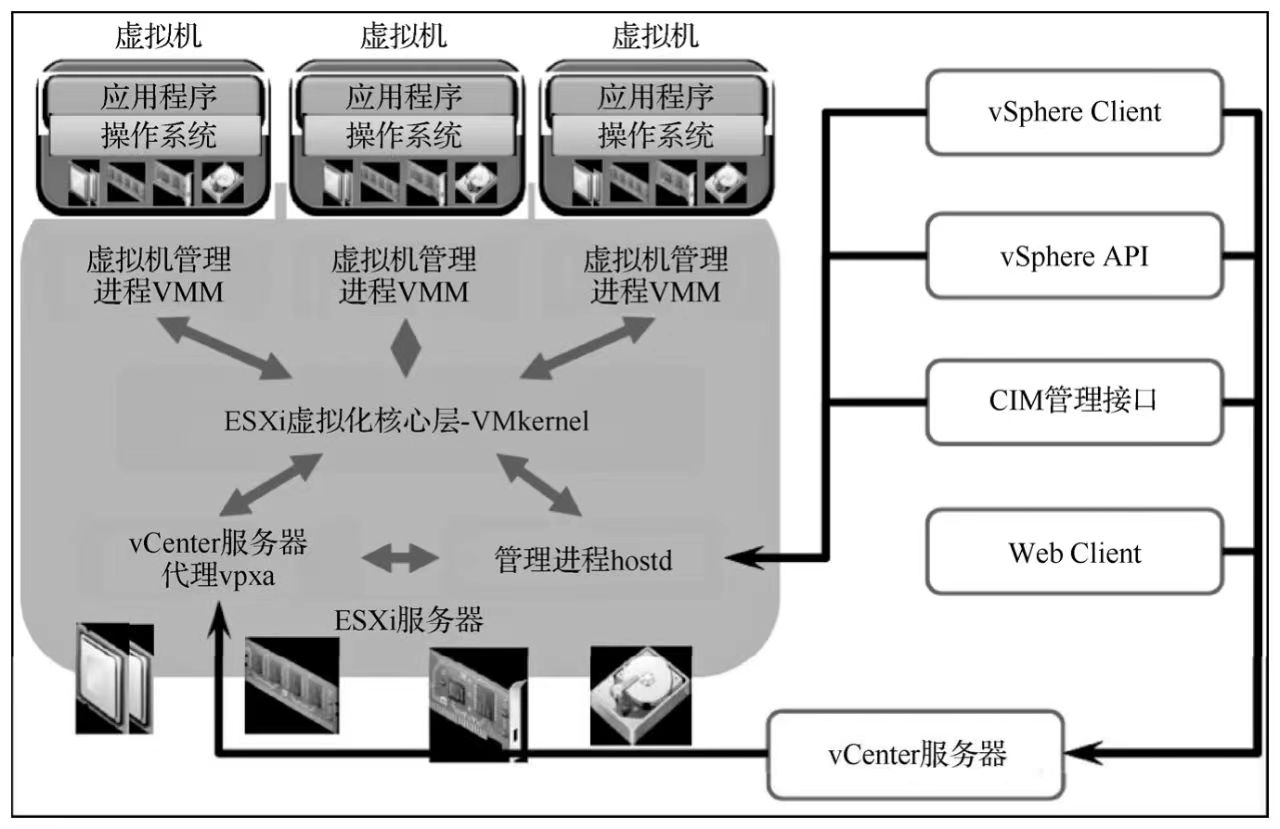
17.2.4 虚拟化安全
1.虚拟化面临的威胁
虚拟机自身的安全问题如下。虚拟机逃逸:指的是攻击者突破虚拟化管理平台,获得宿主机操作系统管理权限并控制宿主机运行其他虚拟机的情况。发生虚拟机逃逸事件时可能会导致攻击者攻击同一宿主机上其他的虚拟机或控制这一宿主机上的所有虚拟机对外发起攻击的情况。
虚拟机嗅探:同一物理机上的虚拟机之间默认没有进行特殊隔离处置,攻击者可以利用简单的数据探测手段获取虚拟机网络中的所有数据进行分析。
虚拟化管理平台的安全问题如下。
虚拟化管理平台部署在裸机上,提供创建、运行和消除虚拟服务器的能力,主机层的虚拟化能通过多种虚拟化模式完成,包括操作系统级虚拟化、半虚拟化、基于硬件的虚拟化。其中Hypervisor作为该层的核心,安全性应重点加以保护。Hypervisor是在虚拟化环境中的元操作系统,可以访问服务器上包括磁盘和内存在内的所有物理设备,不但协调硬件资源的访问,也可以在各个虚拟机之间进行防护。当服务器启动并执行 Hypervisor时会加载所有虚拟机客户端的操作系统并分配给每台虚拟机适当的计算资源。Hypervisor实现了操作系统和应用程序与硬件层的隔离,这有效地减轻了软件对硬件设备及驱动的依赖性。由于 Hypervisor 可以控制在服务器上运行的虚拟机,它自然成为攻击的首选目标。Hypervisor与底层、虚拟机交互都是通过API进行调用的,所以API的安全也是防护Hypervisor的核心。
2.虚拟化安全解决方案
虚拟机的防护手段如下。
(1)虚拟机自身保护:在虚拟化管理平台上或 Hypervisor 中部署统一的虚拟防火墙和IPS/IDS等系统,用于保护所有的虚拟机。
(2)虚拟机隔离技术:对同一物理机上的虚拟机可以基于安全域的概念对各个虚拟机进行逻辑或物理隔离,也可以基于虚拟机用户、业务逻辑和租户等属性进行更细粒的隔离。
(3)虚拟机迁移:保证虚拟机在某些物理机发生故障时可快速地切换至另外的物理机中,保证业务连续性,也可以实现负载均衡,提升系统整体性能。虚拟机的迁移不只是简单地让虚拟机进行转移,还需要保证虚拟机在新的环境中拥有和之前完全一致的逻辑环境,包括逻辑的网络环境、安全策略和服务质量等,在这个迁移的过程中要保证是无感知的,这对虚拟化管理平台的迁移组件的成熟度要求很高。
(4)虚拟机补丁管理:虚拟机也需进行日常的补丁修复,虚拟机之庞大数量使得传统的单线操作非常耗费时间,这就需要虚拟化管理系统支持虚拟机补丁的批量升级。补丁管理也不是一件简单的事情,需要进行补丁分析、安装、复查等操作,这对流程的管理和技术人员的能力也提出了具体要求。
Hypervisor提出的三种保护机制如下。
(1)虚拟防火墙:一般运行在 Hypervisor 中,可以是 Hypervisor 的一个进程,也可以是一个带有安全功能的虚拟交换机。
(2)访问控制,根据安全策略的要求,对资源的请求许可进行控制,规避非法或未授权的访问。
(3)虚拟化漏洞扫描:针对虚拟化管理平台进行漏洞扫描是加强虚拟化安全的重要手段,主要包括 Hypervisor 的安全漏洞扫描和配置管理,虚拟机承载操作系统的漏洞扫描和虚拟化环境中的第三方应用软件的漏洞扫描。
17.3.2 网络层面
网络层面是从网络架构和协议上实现,主要包括物理/逻辑架构上链路、节点的冗余,二层/三层(接入层面和路由层面)网络的负载与冗余,协议上的冗余/负载等高可用手段,以及架构、网络、协议上的快速自动恢复机制。
1.接入层面
1)链路聚合控制协议(LACP)
链路聚合控制协议(Link Aggregation Control Protocol,LACP)是指将多个物理端口汇聚在一起,形成一个逻辑端口,以实现出/入流量吞吐量在各成员端口的负荷分担,交换机根据用户配置的端口负荷分担策略决定网络封包从哪个成员端口发送到对端的交换机。当交换机检测到其中一个成员端口的链路发生故障时,就停止在此端口上发送封包,并根据负荷分担策略在剩下的链路中重新计算报文的发送端口,故障端口恢复后再次担任收发端口。链路聚合在增加链路带宽、实现链路传输弹性和工程冗余等方面是一项很重要的技术。
如图17-13 所示,SW1 与SW2 之间有三条物理链路,假设每条链路的带宽为1000M。通过链路聚合将三条物理链路捆绑在一起成为一条逻辑链路,从而实现增加链路带宽的目的。
图17-13 链路聚合
通过 LACP 模式链路聚合后,会将链路为活动链路和非活动链路。只有活动链路才会转发数据,非活动链路作为备份链路,不转发数据。假设通过 LACP 模式聚合后,前两条链路为活动链路,最一条链路为非活动链路,那么当前链路可提供的最大带宽为3000M,实际带宽为2000M。当其中一条活动链路出现故障时,LACP会自动启用非活动链路,从而保障链路的带宽及稳定性。
2)生成树协议(STP)
生成树协议(Spanning Tree Protocol,STP)是一种工作在OSI网络模型中的第二层(数据链路层)的通信协议,基本应用是防止交换机冗余链路产生的环路,用于确保以太网中无环路的逻辑拓扑结构,从而避免了广播风暴大量占用交换机的资源。简单来说,在实际物理网络中,交换网络是存在物理环路的,如图17-14所示(PC1与PC2通信,PC1的流量到达SW1后,SW1转发给了SW2,SW2又将流量转发给了SW1,依次循环)。网络环路会直接导致网络瘫痪,为了解决这一问题,在交换网络中采用生成树协议,以实现“物理有环,逻辑无环”。
3)虚拟路由冗余协议(VRRP)
在网络中,主机是通过设置默认网关来与外部网络联系的。如图17-17所示,主机将数据包发送给网关,再由网关发送给外部的网络,从而实现主机与外部网络的通信。但是当网关坏掉时,主机与外部的通信会立即中断。要解决网络中断的问题,可以依靠再添加网关的方式解决,不过由于大多数主机只允许配置一个默认网关,此时需要网络管理员进行手工干预网络配置,才能使得主机使用新的网关进行通信。为了更好地解决网络中断的问题,网络开发者提出了 VRRP,它既不需要改变组网情况,也不需要在主机上做任何配置,只需要在相关路由器上配置极少的几条命令,就能实现下一跳网关的备份,并且不会给主机带来任何负担。
虚拟路由冗余协议(Virtual Router Redundancy Protocol,VRRP)是由IETF提出的解决局域网中配置静态网关出现单点失效现象的路由协议,1998 年已推出正式的 RFC2338协议标准。VRRP 广泛应用在边缘网络中,它的设计目标是支持特定情况下 IP 数据流量转移失败也不会引起混乱,允许主机使用单路由器,以及即使在实际第一跳路由器使用失败的情形下仍能够维护路由器间的连通性。
6.双活数据中心
1)双活数据中心
双活的英文词是Active-Active,双活数据中心就是建立两个能够同时提供业务服务的数据中心,是相对于传统的主备模式(Active-Standby)提出的。一个真正的双活方案应该涵盖基础设施、中间件、应用程序各个层次,如图17-22所示。
在主备数据中心模式中,主数据中心承担用户的业务,在其出现故障时,备数据中心接管业务需要一定时间,可能会出现中断的情况。且备数据中心在不接管业务时只做备份,造成了极大的浪费。双活数据中心的建设比建设主备数据中心的方式更具可靠性,双数据中心同时对外提供业务生产服务的双活模式,两个数据中心是对等的、不分主从、并可同时部署业务,可极大地提高资源的利用率和系统的工作效率、性能,让客户从容灾系统的设备中获得最大的价值。数据中心双活又分为:同城双活、异地双活。
图17-22 双活数据中心2)数据中心双活的建设要求
双活数据中心的建设要满足三个条件,第一个是应用双活,就是业务和数据库实现双活。第二个是支撑的网络需要双活,两个数据中心的网络都能够被客户进行业务接入。第三个是数据要双活,两个数据中心的数据都能被独立使用。
3)双活数据中心的优点
充分利用资源,避免了一个数据中心常年处于闲置状态而造成浪费,通过资源整合,“双活”数据中心的服务能力是双倍的。其中一个数据中心出现故障,而另一个数据中心可以正常工作,对于用户来说是无感知的。
4)双活数据中心常用技术
在双活数据中心建设时,应用最为广泛的思想和技术就是负载均衡,无论是网络层、主机层还是应用层,负载均衡都非常活跃。
链路负载均衡支持数据中心前端双活网络,如图17-23所示。通过数据中心前端分布式双活技术,用户能快速访问“距离最近”的可用数据中心相对应的业务,提高服务响应速度,提升用户访问体验,最常用的技术就是通过域名发布,通过 DNS 智能解析的链路负载均衡完成 DNS 重定向,将请求牵引到某个数据中心,解决了第一步即引导数据中心前端广域网用户访问适当的数据中心的问题。基于DNS的流量管理机制主要完成DNS解析请求的负载均衡、服务器状态监控、用户访问路径优化。用户访问应用时,域名解析请求将由链路负载均衡负责处理,通过一组预先定义好的策略,将最接近用户的节点地址提供给用户,使其可以得到快速的服务。
服务器HA技术。高可用性集群(High Availability Cluster,HA Cluster)是以减少服务器中断时间为目的实现故障屏蔽的服务器集群技术,主要包括可靠性和容错性两方面。在这种高可用集群环境下,若某台服务器出现故障导致服务中断,预先设定的接管服务器会自动接管相关应用并继续对用户提供服务,具有更高的可用性、可管理性和更优异的可伸缩性。HA Clusters是可用于“热备模式容灾”的集群技术。
数据库双活备份技术。双活数据库备份技术在源数据库端实时读取交易日志数据,捕获数据的变化部分并暂存到队列中,然后将变化的数据经过压缩和加密后通过网络传送到目的地。在目的数据库端,变化的数据被还原为标准的 SQL 语句提交到目的库实现修改数据的备份功能。这个备份过程是双向复制的,即可以从目的端向源端数据库做类似的复制。双活数据库备份技术能够支持灵活的拓扑复制结构(包括单向、双向、点对多点、集中和分级等方式),如图17-25所示。
图17-25 双活数据库备份技术
分布式双活存储技术。存储分布式双活解决方案基于存储虚拟化技术实现,用于数据中心内、跨数据中心和在数据中心之间进行信息虚拟化、访问、共享和迁移。本地联合提供站点内信息基础架构的透明协作;分布式联合提供跨远距离两
个位置的读/写访问能力。随着技术的不断发展,存储分布式双活技术逐步成熟,为实现分布式双活数据中心打下了良好的基础。存储分布式双活方案承载于一个硬件与软件虚拟化平台,作为基于存储虚拟化的解决方案,可实现本地和分布式数据中心存储。通过部署存储分布式双活技术,跨数据中心实现了统一的逻辑存储映像,进而支撑分布式双活数据中心业务实现。
7.两地三中心
两地三中心指的是在同城双活数据中心的基础上,建立异地灾备数据中心的一种容灾方案,这一方案兼具高可用性和灾难备份的能力,图17-26为建设两地三中心解决方案的示意图。
图17-26 建设两地三中心解决方案
基于统一存储多级跳复制技术建立两地三中心,基于统一存储多级跳复制技术,并结合专业的容灾管理软件实现数据的两地三中心保护。该方案在生产中心、同城灾备中心和异地灾备中心分别部署华为OceanStor统一存储设备,通过异步远程复制技术,将生产中的数据复制到同城灾备中心,再到异地灾备中心,实现数据的保护方案原理组网如图 17-27所示。若生产中心发生灾难,可在同城灾备中心实现业务切换,并保持与异地灾备中心的容灾关系;若生产中心和同城灾备中心均发生灾难,可在异地灾备中心实现业务切换。
图17-27 方案原理组网
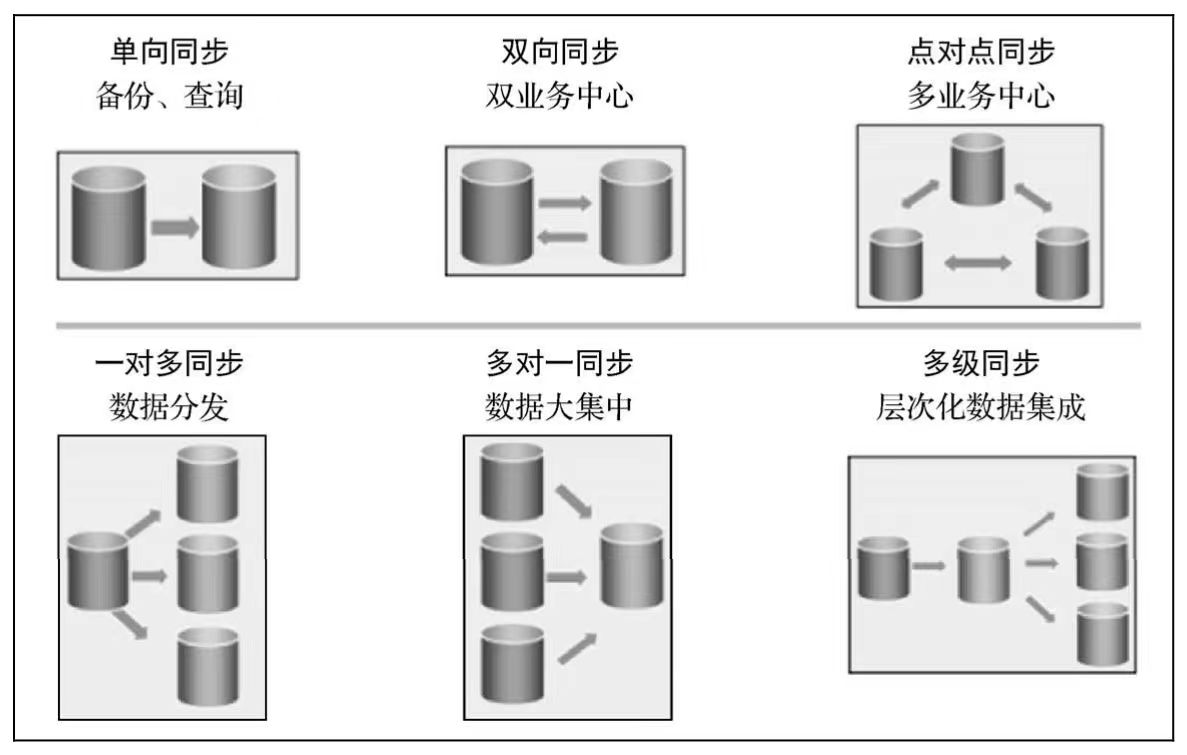
18.1 安全防御体系概述
18.1.1 边界防御体系
传统的边界防御体系,主要进行边界隔离防护,从最开始的防火墙、IPS 到 UTM、下一代防火墙等产品,边界防御体系就是将攻击阻截在外部,在网络边界上解决安全问题,部署比较简单;但弱点也非常明显,即黑客一旦渗透进内部,便可长驱直入。
18.1.2 纵深防御体系
纵深防御体系采用一个多层级、纵深的安全措施来保障信息系统的安全。因为信息系统的安全不是仅仅依靠一两种技术或简单的安全防御设施就能实现的,必须在多个层次、不同的技术框架区域中建立保障机制,才能最大限度地降低风险,应对攻击并保护信息系统的安全。这好比在城堡外围建设了几层防御,城堡又分为外城和内城,内部重要设施还配备专职守卫,攻击者必须一层层地攻击进来才能接触到最核心的数据。
18.2 安全管理与运维
18.2.1 安全管理
信息安全管理作为组织完成的管理体系中的一个重要环节,它构成了信息安全具有能动性的部分,是指导和控制组织关于信息安全风险的相互协调的活动。信息安全管理体系(Information Security Management System,ISMS)是组织整体管理体系的一个部分,是组织在整体或特定范围内建立信息安全方针和目标,以及完成这些目标所用方法的体系。
1.信息安全管理的作用
信息安全管理是组织整体安全管理重要、固有的组成部分;信息安全管理是信息安全技术的融合剂,保障各项技术措施能够发挥作用;信息安全管理可预防、阻止或减少信息安全事件的发生。
2.安全管理原则
以组织资产为核心,对资产的有效识别和授权使用促进对当前组织目标的持续改进和调整,使资产的保密性、可用性、完整性得到有效保障。以业务发展战略为基础,落实到最终的目标是实现组织义务连续性的保障。采取技术与管理并重的策略,即运用的安全技术想要达到预想的效果,必然需要管理手段的支撑。
3.信息安全管理体系建设过程
攻击和防御的视角是非对称的,企业在信息安全保障的工作中本身就处于被动的地位。同时,2003 年出台的《关于加强信息安全保障工作的意见》中提出坚持管理与技术并重的指导思想,这对企业信息安全提出了更高的要求。信息系统承载于数据中心,凸显出数据中心的安全运维工作的重要性。
预防与及时的响应成为了安全运维工作的当务之急,安全威胁暴露的时间越短,发现得越快,对企业造成的影响就越小,通过建立安全运维管理体系,有效地结合管理和技术手段,尽可能地降低安全威胁的发现时间和响应时间,成为企业减少安全隐患所带来的损失的最重要举措。
信息安全管理体系建设过程如下。
规划与建立:根据当前数据中心提供的业务和近期的发展目标制定总体战略和目标,对数据中心的信息资产实施风险评估,评估资产面临的威胁、产生威胁的可能性和概率以及任何信息安全事件对信息资产的潜在影响,选择相关的控制措施进行管控。
实施与运行:通过风险评估确定所识别信息资产的信息安全风险及处理信息安全风险的决策,形成信息安全要求。选择和实施控制措施以降低风险。
监视与评审:组织需要根据组织政策和目标,监控和评估绩效来维护和改进 ISMS,并将结果报告给管理层进行审核。根据这些监测区域的记录,提供验证证据,以及纠正、预防和改进措施的可追溯性。
维护与改进:持续改进信息安全管理系统的目的是提高实现保护信息机密性、可用性和完整
性目标的可能性,持续改进的重点在于寻求改进的机会,而不是假设现有的管理活动足够好或尽可能好。
安全是动态的,无常的,持续不断的发现问题并改进安全管理体系是保障持续安全的重要手段,这种方式与通用的 PDCA (plan-do-check-act)模型一般无二。该模型也称为戴明环,由美国质量管理专家戴明提出,在该模型中,按照 P-D-C-A 的顺序依次进行,这样运行一次可以看作管理上的一个完整周期,每运行一次,管理体系就优化升级一次,进入下一个更完善的周期,通过不断循环获得持续改进,如图18-1所示。
18.2.2 IT运维管理
所谓IT运维管理,是指各组织IT部门采用相关的方法、手段、技术、制度、流程和文档等方式,对 IT 软硬件运行环境、IT 业务系统、IT 业务流程、IT 运维人员进行的综合管理。IT 运维服务人员工作的一个普遍现象是“很忙碌,坐不下”,每个 IT 运维服务人员都很忙碌,在各个业务部门间解决和处理问题,就像“救火员”一样。虽然如此忙碌,但业务人员还是经常抱怨“找不到人”“解决问题太慢”等。IT 运维服务人员的工作始终得不到业务部门的认可,而且工作量也难以量化。
在云数据中心现有的服务模式中,各种对租户提供的服务都需要即插即用,IT 运维工作繁重程度的增加及对 IT 资产数量的激增监控对运维人员来说会是一个更大的挑战。让运维人员进行部分的解放是数据中心做 IT 运维建设时必须要考虑的一个问题,数据中心需要维护的 IT 资源种类繁多,且大多数的产品都不属于一个厂商,此时就需要一套管理系统对这些IT资源进行集中、统一的管理与监控,该系统被称作IT运维管理系统。典型的IT运维管理平台架构如图18-2所示。
图18-2 典型的IT运维管理平台架构
IT运维管理系统的主要特性如下。
资源统一管理与展示:全方位IT 资产管理,可以统一管理各类的IT 资源,包括网络设备、安全设备、服务器、存储设备、虚拟化系统、数据库、中间件、应用系统等。资产配置管理,在资产的变更管理、事件管理与问题管理等流程实现对所有IT资源的统一管理。统一展示,统一的视图可以查看所有IT资源的使用情况、物理连接关系、资源关联关系、是否存在故障等。集中
式管理,打破原有不同分类单独管理的限制,可以进行关联管理。
运维自动化:对发现的故障将报警信息按照等级呈现并通过邮箱、短信等方式通知负责人。
服务可量化:服务流程管理,需要建立服务管理体系使运维工作得以实现规范化、流程化、服务化,通过量化的方式对资源进行合理调配,提升工作效率,提高客户满意度。SLA 监控与预警,通过建立服务质量 SLA 促使服务质量的提升,让客户参与进行指导与跟踪,会让服务过程更加的饱满,更加有效地提高客户满意度。服务质量评估,结合自身行业特性,参考已构建的一套专业化的服务质量评价管理系统,通过服务质量评价报告实现对服务质量的持续控制与改进。IT资源监控示意图如图18-3所示。
图18-3 IT资源监控示意图
业务系统示意图如图18-4所示。
图18-4 业务系统示意图流量分析示意图如图18-5所示。
图18-5 流量分析示意图
告警信息展示示意图如图18-6所示。
图18-6 告警信息展示示意图
网络设备监控示意图如图18-7所示。
图18-7 网络设备监控示意图
存储设施监控示意图如图18-8所示。
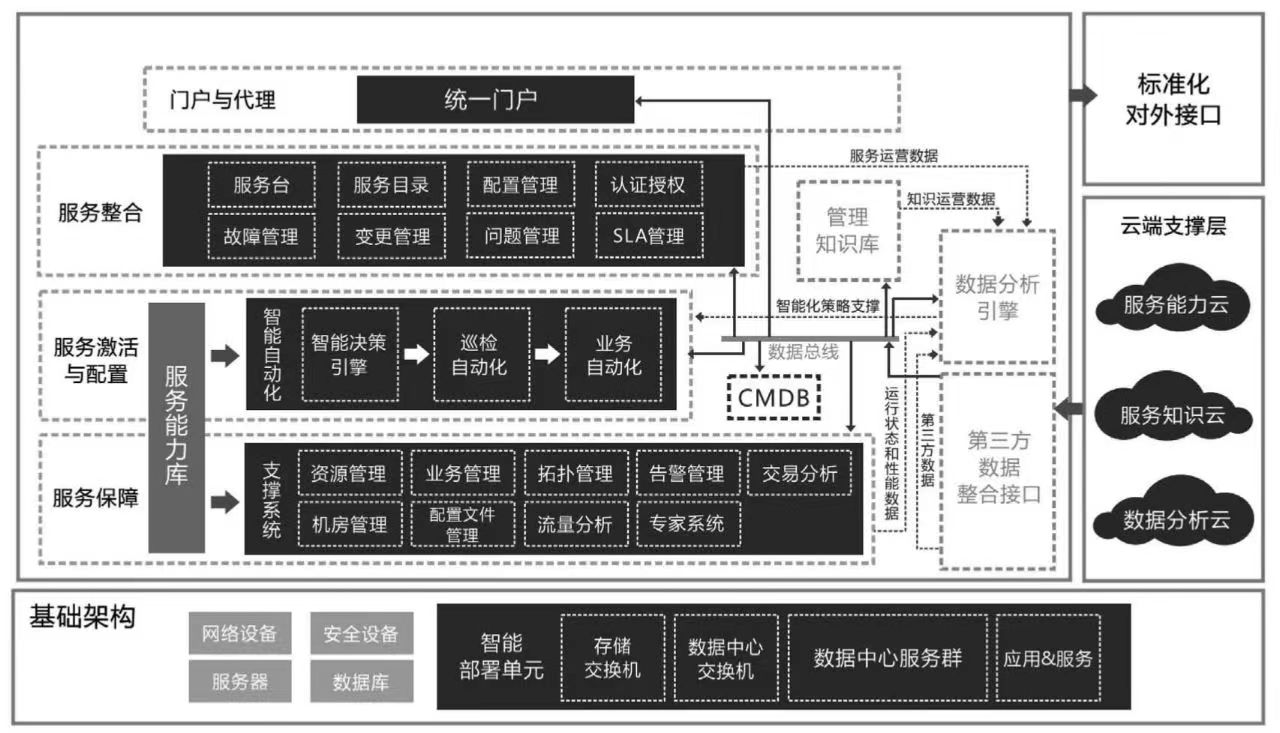
18.2.3 安全运维与运营
安全运维在整个 IT 运维工作中起到关键作用,安全运维工程师的日常工作主要包括:按照已经制定的信息安全管理体系和标准工作,防范黑客入侵并进行分析和防范,通过运用各种安全产品和技术,进行安全制度建设与安全技术规划、日常维护管理、信息安全检查、审计系统账号管理与系统日志检查等工作。
安全运营是近几年业内的热点话题,但什么是安全运营?安全运营到底都干些什么?有没有明确的定义和工作范围?在这里我们不妨先看在IT行业大家都比较清晰的概念“运维”,运维简而言之就是保障信息系统的正常运转,使其可以按照设计需求正常使用,通过技术保证产品提供更高质量的服务。而“运营”一字之差的差异在于,运营要持续地输出价值,通过已有的安全系统、工具来生产有价值的安全信息,把它用于解决安全风险,从而实现安全的最终目标。这是由于安全的本质依然是人与人的对抗,为了实现安全目标,企业通过人、工具(平台、设备),发现安全问题、验证问题、分析问题、响应处置、解决问题并持续迭代优化的过程,可称为安全运营。人、数据、工具、流程,共同构成了安全运营的基本元素,以发现威胁为基础,以分析处置为核心,以发现隐患为关键,以推动提升为目标通常是现阶段企业安全运营的主旨。只有这样充分结合人、数据、工具、流程,才有可能实现安全运营的目标。不管是基于流量、日志、资产的关联分析,还是部署各类安全设备,都只是手段,安全运营最终还是要能够清晰地了解企业自身安全情况、发现安全威胁、敌我态势、规范安全事件处置情况,提升安全团队整体能力,逐步形成适合企业自身的安全运营体系,并通过成熟的运营体系驱动安全管理工作质量、效率的提高。
自适应安全架构(Adaptive Security Architecture,ASA)是Gartner于2014年提出的面向下一代的安全体系,云时代的安全服务应该以持续监控和分析为核心,覆盖防御、检测、响应、预测四个维度,可自适应于不同基础架构和业务变化,并能形成统一安全策略以应对未来更加隐秘、专业的高级攻击,如图18-15所示。防御,包括预防攻击的现有策略、产品和进程。
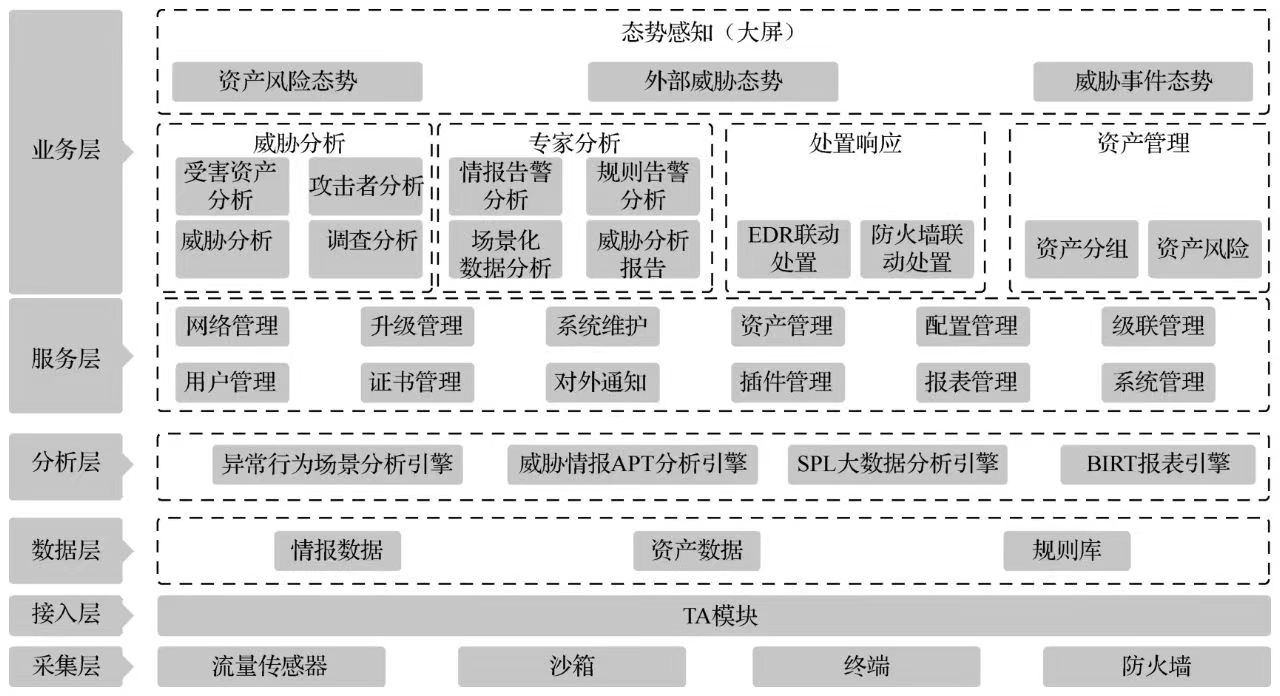

 浙公网安备 33010602011771号
浙公网安备 33010602011771号