第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
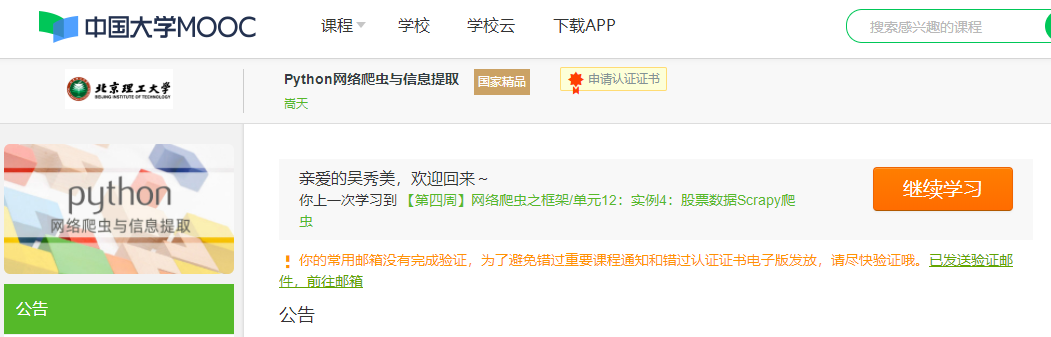
3.学习完成第0周至第4周的课程内容,并完成各周作业
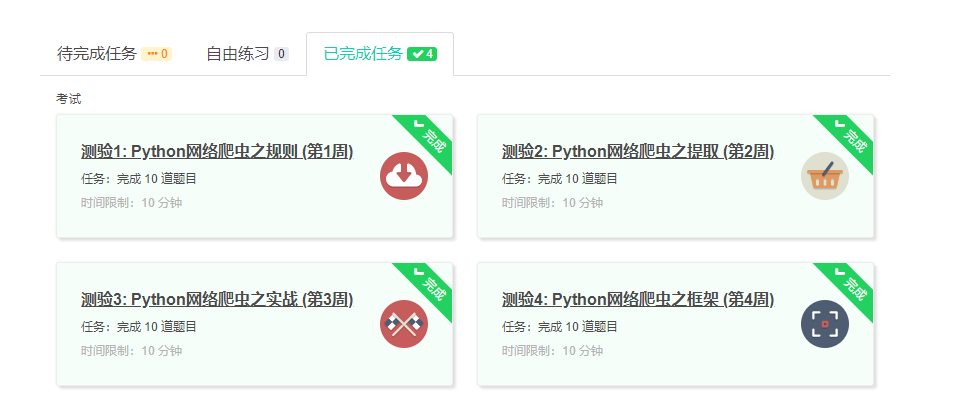
4.提供图片或网站显示的学习进度,证明学习的过程。

5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
近期,在“中国大学生MOOC”网站上学习北京理工大学嵩天老师的《Python网络爬虫与信息提取》这一课程,刚开始接触时会感觉很陌生,看视频学习也是力不从心,虽然认真听课了,但是并不能真正理解它。庆幸的是,自己并没有因此而停下脚步,终于找到了学习的一些方法。因为网络爬虫所要用到的思维逻辑与我们平时的思维逻辑有所不同,其显得更抽象,所以学习网络爬虫,一定要打好基础,要把基础理解透彻,从基本抓起,多动手、多动脑、不懂就问,平时也要主要积累和做好相关笔记。这样,在以后的运用当中,就能比较得心应手了。
学习网络爬虫的起步就是学习它的方法规则,如果把它学得好的话,在学习后面的时候就比较容易理解了。老师在第一周的网络爬虫之规则里给我们讲了三个大点,分别是:Requests库入门、网络爬虫的“盗亦有道”、Requests库网络爬虫的五个实例。在初学的这一周里,我明白了网络爬虫也是存在问题的,比如性能骚扰、法律风险、隐私泄露等。网络爬虫也存在限制,比如来源审查:判断User-Agent进行限制,它用来检查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问;发布公告:Robots协议,它是告知所有爬虫网站的爬取策略,要求爬虫遵守。第二周讲的是网络爬虫之提取,主要讲述的是Beautiful Soup库入门、信息组织与提取方法和中国大学排名爬虫的实例。Beautiful Soup库是解析、遍历、维护“标签树”的功能库,它也叫beautiful soup4或bs4。Beautiful Soup库有bs4的HTML解析器、lxml的HTML解析器、lxml的XML解析器、html5lib的HTML解析器这四种解析器。Beauti fulSoup类的基本元素是<p class="title""> .... </p>,基本元素:Tag(标签,最基本的信息组织单元,分别用<>和</ >标明开头和结尾)、Name(标签的名字, <>../p>的名字是'p' ,格式: <tag> .name)、Attributes(标签的属性,字典形式组织,格式: <tag> . attrs)、NavigableString(标签内非属性字符串, <..</>中字符串,格式: <tag> . string)、Comment(标签内字符串的注释部分,- 种特殊的Comment类型)。信息提取一般方法有完整解析信息的标记形式,再提取关键信息;无视标记形式,直接搜索关键信息。第三周学习了网络爬虫之实战,讲了Re库入门、淘宝商品比价定向爬虫和股票数据定向爬虫的实例。Re库是Python的标准库,主要用于字符串匹配,调用方式:import re。第四周就进入例如网络爬虫之框架,老师介绍了Scrapy爬虫框架、Scrapy爬虫基本使用、股票数据Scrapy爬虫实例。应用Scrapy爬虫框架主要是编写配置型代码,它的使用步骤:先创建一个工程和Spider模板,然后编写Spider,接着编写Item Pipeline,最后才是优化配置策略。
经过这一阶段的学习,我觉得自己对于《Python网络爬虫与信息提取》这一课程已经有了一个初步的了解,可能还有很多概念现在还是比较模糊,但是我相信,再后续老师的讲课中,我可以更好地接收老师传授的知识和理解掌握一些比较抽象的知识点。总之一句话,在学习《Python网络爬虫与信息提取》中,一定要多动手,不要老是转牛角尖。有时候只要肯动手,编译错了再改。你会发现慢慢地就能够找到答案了。而且也能从中学习到很多东西,常言道失败是成功之母。只要不怕失败,不断的钻研、尝试,总会能够把困难解决的。在学习网络爬虫的过程中会遇到许多困难与挫折。但通过自己的努力,最终能克服种种的困难。所得到的成就感是无法用言语去形容的。从中学到的坚韧精神对于我今后的生活也有很大的影响。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号