


计算机编码
本节内容
- 编码与解码
- 编码简史
- Unicode与UTF-8
- 文件编码
- Web编码
- Python编码
一、编码与解码
说明二点:
- 计算机中数据使用二进制010101110表示,存储、网络传输都是二进制
- 字符即有意义的符号,在计算机中可以理解为:(二进制 ,编码规则)
编码:人类有意义字符->计算机二进制。例如:'a' ASCII 编码为:1100001
解码:计算机二进制->人类有意义字符
二、编码简史
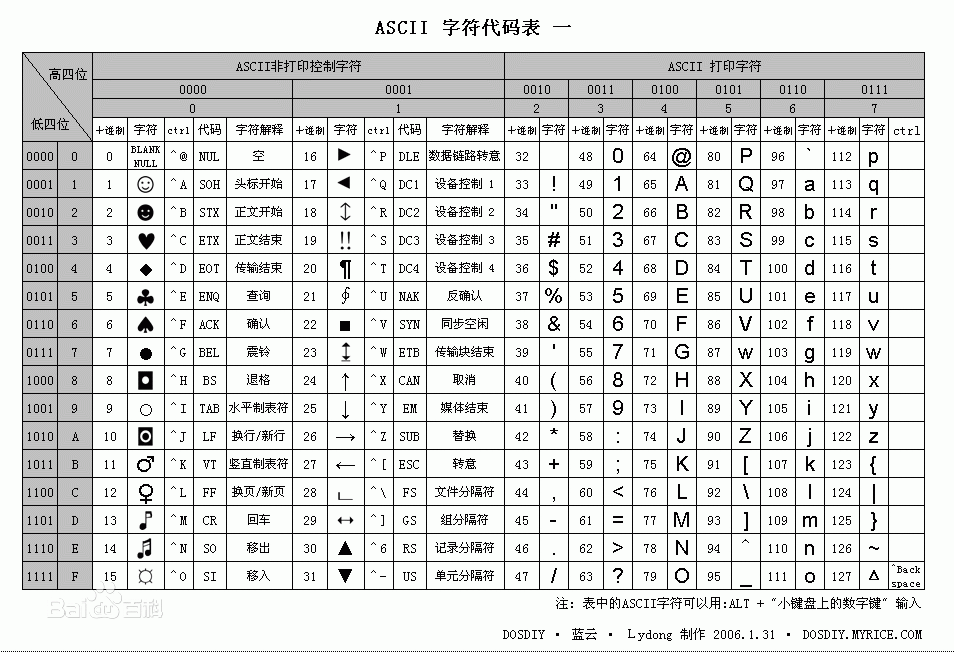
ASCII
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
GB2312->GBK->GB18030
用于解决中文编解码问题
- 1980年中国发布《信息交换用汉字编码字符集》-GB2312
- 1995年中国发布《汉字编码扩展规范》—(GBK)与GB 2312兼容,同时在字汇一级支持ISO/IEC10646—1和GB 13000—1的全部中、日、韩(CJK)汉字,共计20902字。
- 2000,2005分别发布两个版本 GB18030-2000、GB18030-2005
Unicode
所谓的"统一码"、"万国码",即一套编码体系解决地球所有符号的编码(有没有甲骨文:-) )问题。1990研发,1994正式发布。
三、Unicode与UTF-8
全球字符统一编码:ISO给出解决方案Unicode,所有字符必须用双字节,未来可以扩展UCS-4编码(4字节)。但仅规定符号的二进制代码,没有规定如何存储和传输编码规则。Unicode与ASCII编码兼容,与GBK等编码之间不兼容,需要转码表。
UTF-8
UTF-8是Unicode的实现方式之一
UTF-8的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) --------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面,还是以汉字“严”为例
- 编码过程:
已知“严”的Unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
- 解码过程:
如果一个字节的第一位是 0 ,则说明这个字节对应一个字符,取后7位,即为Unicode编码
如果一个字节的第一位1,那么连续有多少个 1,就表示该字符占用多少个字节;去掉标识位(首字节 (N*1 0)],其他字节 [10] )组合即为Unicode编码
四、文件编码
文件写入(文件编码)
- 转码:内存中的字符(二进制,编码规则)->待保存的硬盘文件字符(二进制,编码规则)
- 确定字节序:有些编码需要确定字节序:'奎' ,'乙' (594E,4E59)是按照高->低位存还是低->高位存
文件读取(文件解码)
- 硬盘文件(二进制,编码规则,[字节序])依次读取,得到文件字符(二进制,编码规则)
- 转码:文件字符->内存字符
注:Windows 文本文件四种文件编码
ANSI:Windows 自带编码系统,默认:中文为GBK,英文为ASCII
Unicode:字节序(FF FE) + Unicode编码,例如:'严' Unicode编码为:254E,那么保存文件后:FF FE 25 4E。即默认为little endian
Unicode big endian:FE FF + Unicode编码,例如:'严'保存后:FE FF 4E 25
UTF-8: EF BB BF + UTF-8编码,例如:'严'保存后: EF BB BF E4 B8 A5。
注:文件编码只是一种规则,不存在UTF-8比UTF-16保存的文件就小
Little endian和Big endian
Unicode码可以采用UCS-2格式直接存储。以汉字”严“为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格“(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式(Windows 默认Unicode存放方式)。
BOM
BOM:Byte order Mark,就是上文说的字节序,说明文件编码。一般写在文件头部。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。
Windows就是使用BOM来标记文本文件的编码方式的。'严':Windows UTF-8编码格式保存的文件内容为: ef bb bf e4 b8 a5
五、Web编码
明确一点,HTTP 协议是不支持中文的,参见 RFC 1738
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed],
and reserved characters used for their reserved purposes may be used unencoded within a URL." “只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于 URL。”
URL 编码
- 中文一般采用UTF-8编码,IE不勾选国际化设置,URL采用GBK(取本地操作系统)
请求参数编码
- 取网页编码格式,没有设置取默认URL编码(UTF-8)
网页编码
网页即文件,服务器生成一个文件有一个存储编码,浏览器使用相应编码(网页文件中)解码才能显示正常
六、Python编码
Python内部符号编码格式为Unicode。
#-*- coding=gbk -*-
#一、编码:字符变二进制
s = "春节"
a = s.encode("gb2312")
print(a) #b'\xb4\xba\xbd\xda'
a = s.encode("utf-8")
print(a) #b'\xe6\x98\xa5\xe8\x8a\x82'
#解码:二进制变字符串
# print(a.decode("gb2312")) # UnicodeDecodeError: 'gb2312' codec can't decode byte 0xe6 in position 0: illegal multibyte sequence
print(a.decode("utf-8")) # 春节
#二、文件
# with open('春节.txt','w') as f: #文件不指定编码默认为ansi
# f.write(s)
#文件内容:
# c2 b4 c2 ba c2 bd c3 9a 。默认编码格式ANSI,中文就是gbk(win95之前是gb2312)。至于为什么有C2隔开。。不清楚
with open("春节utf.txt",'w',encoding='utf-8') as f: #e6 98 a5 e8 8a 82
f.write(s)
#三、源代码文件
#源代码保存为utf-8,但文件指定为 gbk解析 报错 SyntaxError: encoding problem: gbk with BOM
#PyCharm 做了处理,如果修改头部 #-*-文件解析格式-*- 那么相应文件保存格式为:文件解析格式。两者保持一致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号