python导出禅道每天的bug
前言:
>有一句话是程序员是最懒的人
>
>因为公司每天都要写日报,所以自己懒得去禅道复制粘贴,就学了下python 写了个小小的爬虫,用于每天导出bug列表
>
>当然大手子就看看就好,因为python也是现学现用,所以很多不熟悉
因为很简单,所以我就简单介绍下
准备工作:
代码
- 首先是通过抓包工具获得登录的消息
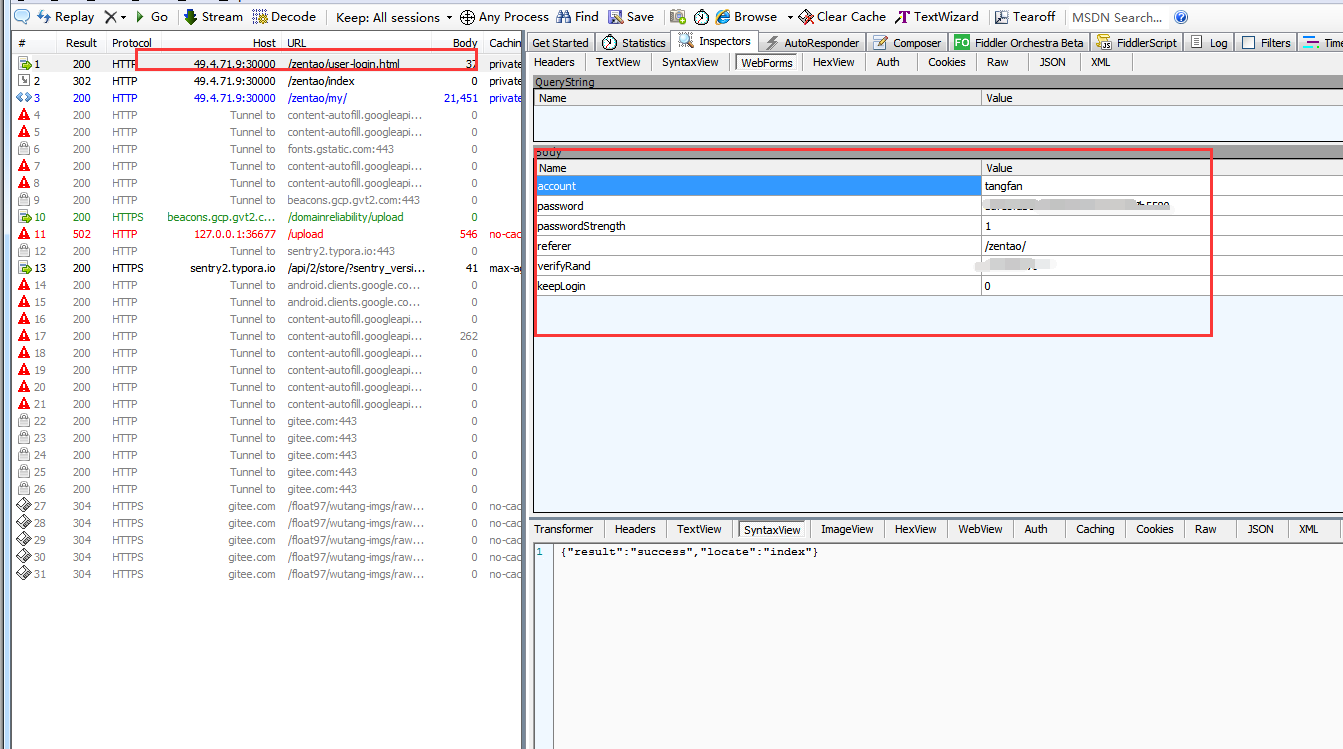
我是直接用的verifyRand加密字符串就没去自己再加密了(因为懒)
- 代码
# -*- coding: utf-8 -*-
import requests
import http.cookiejar as cookielib
from lxml import etree #XPATH获取节点
from easyxlsx import SimpleWriter #导出excel
import time
# 获取session
session = requests.session()
# 因为原始的session.cookies 没有save()方法,所以需要用到cookielib中的方法LWPCookieJar,这个类实例化的cookie对象,就可以直接调用save方法。
session.cookies = cookielib.LWPCookieJar(filename="huihuCookies.txt")
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
"referer": "/zentao/"
}
data = {
"account": "tangfan",
"password": "明文密码",
"passwordStrength": 1,
"keepLogin": 0,
"verifyRand": "加密的字符串,就直接用抓包工具获得"
}
# 登录
resp = session.post("http://49.4.71.9:30000/zentao/user-login.html", data=data, headers=header)
# print(resp.status_code)
# 导出的集合
l = []
now = time.strftime("%Y/%m/%d", time.localtime())
# 是否登录成功
if resp.status_code == 200:
session.cookies.save()
# 访问个人主页测试
# my_profile = session.get("http://49.4.71.9:30000/zentao/my-profile.html")
# 获取每天解决的bug
today_bugs = session.get("http://49.4.71.9:30000/zentao/my-dynamic.html")
# xpath语法取得今天所有的bug
today_bugs_html = etree.HTML(today_bugs.text)
content = today_bugs_html.xpath("//span[@class='timeline-text']/a")
for i in content:
li = []
li.append("1")
li.append("name")
li.append(now)
li.append(now)
li.insert(0, i.text)
l.append(li)
if len(l) > 0:
SimpleWriter(l, headers=('任务名称', '权重', '研发人员', "预计时间", "完成时间"),
bookname="C:\\Users\\Administrator\\Desktop\\公司项目\\bugs\\bugs.xlsx").export()
Stay hungry,Stay foolish

 浙公网安备 33010602011771号
浙公网安备 33010602011771号