Kafka分片存储、消息分发和持久化机制
Kafka 分片存储机制
Broker:消息中间件处理结点,一个 Kafka 节点就是一个 broker,多个 broker 可以组成一个 Kafka集群。
Topic:一类消息,例如 page view 日志、click 日志等都可以以 topic 的形式存在,Kafka 集群能够同时负责多个 topic 的分发。
Partition:topic 物理上的分组,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
Segment:partition 物理上由多个 segment 组成,下面有详细说明。
offset:每个 partition 都由一系列有序的、不可变的消息组成,这些消息被连续的追加到 partition中。partition 中的每个消息都有一个连续的序列号叫做 offset,用于 partition中唯一标识的这条消息。
topic 中 partition 存储分布
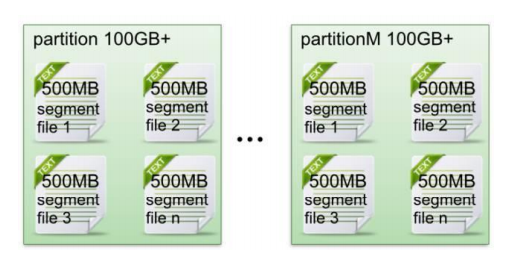
- 每个 partion(目录)相当于一个巨型文件被平均分配到多个大小相等 segment(段)数据文件中。但每个段 segment file 消息数量不一定相等,这种特性方便 old 磁盘顺序读取的速度非常快,比随机读取要快segment file 快速被删除。(默认情况下每个文件大小为 1G)
- 每个 partiton 只需要支持顺序读写就行了,segment 文件生命周期由服务端配置参数决定。
存.index和.log文件,通过索引来定位log文件中的消息
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
Kafka 消息分发和消费者 push、pull 机制
消息分发
Producer 客户端负责消息的分发
- kafka 集群中的任何一个 broker 都可以向 producer 提供 metadata 信息,这些 metadata 中包含”集群中存活的 servers 列表”/”partitions leader 列表”等信息;
- 当 producer 获取到 metadata 信息之后, producer 将会和 Topic 下所有 partition leader 保持socket 连接;
- 消息由 producer 直接通过 socket 发送到 broker,中间不会经过任何”路由层”,事实上,消息被路由到哪个 partition 上由 producer 客户端决定;比如可以采用”random”“key-hash”“轮询”等,如果一个 topic 中有多个 partitions,那么在 producer 端实现”消息均衡分发”是必要的。
- 在 producer 端的配置文件中,开发者可以指定 partition 路由的方式。
Producer 消息发送的应答机制
设置发送数据是否需要服务端的反馈,有三个值 0,1,-1
- 0: producer 不会等待 broker 发送 ack
- 1: 当 leader 接收到消息之后发送 ack
- -1: 当所有的 follower 都同步消息成功后发送 ack
request.required.acks=0
消费者 push、pull 机制
作为一个 message system,kafka 遵循了传统的方式,选择由 kafka 的 producer 向 broker push 信息,而 consumer 从 broker pull 信息。
consumer 获取消息,可以使用两种方式:push 或 pull 模式。下面我们简单介绍一下这两种区别:
push 模式
常见的 push 模式如 storm 的消息处理,由 spout 负责消息的推送。该模式下需要一个中心节点,负责消息的分配情况(哪段消息分配给 consumer1,哪段消息分配给 consumer2),同时还要监听 consumer的 ack 消息用于判断消息是否处理成功,如果在 timeout 时间内为收到响应可以认为该 consumer 挂掉,需要重新分配 sonsumer 上失败的消息。这种模式有个问题,不太容易实现我们想要的消息回放功能,因为理想情况下由 consumer 决定我到底要消费什么,而这种模式完全由 master 决定。
pull 模式
pull 模式由 consumer 决定消息的消费情况,这种模式有一个好处是我们不需要返回 ack 消息,因为当 consumer 申请消费下一批消息时就可以认为上一批消息已经处理完毕,也不需要处理超时的问题,consumer 可以根据自己的消费能力来消费消息。但这个还有一个问题,如何保证处理的消息的不会重复呢,kafka 具体做法就是增加队列的并发度(partition),可以一个 partition 对准一个 consumer。
综上,kafka 的 consumer 之所以没有采用 push 模式,是因为 push 模式很难适应消费者速率不同的消费者而且很难实现消息的回放功能,因为消息发送速率是由 broker 决定的。push 模式的目标就是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞,而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费 message。
pull 与 push 的区别
pull 技术:
客户机向服务器请求信息;
kafka 中,consuemr 根据自己的消费能力以适当的速率消费信息
push 技术:
服务器主动将信息发往客户端的技术;
push 模式的目标就是尽可能以最快的速率传递消息。
Kafka 持久化
概述
Kafka 大量依赖文件系统去存储和缓存消息。对于硬盘有个传统的观念是硬盘总是很慢,这使很多人怀疑基于文件系统的架构能否提供优异的性能。实际上硬盘的快慢完全取决于使用它的方式。设计良好的硬盘架构可以和内存一样快。
在 6 块 7200 转的 SATA RAID-5 磁盘阵列的线性写速度差不多是 600MB/s,但是随即写的速度却是100k/s,差了差不多 6000 倍。现在的操作系统提供了预读取和后写入的技术。实际上发现线性的访问磁盘,很多时候比随机的内存访问快得多。
为了提高性能,现代操作系统往往使用内存作为磁盘的缓存,现代操作系统乐于把所有空闲内存用作磁盘缓存,虽然这可能在缓存回收和重新分配时牺牲一些性能。所有的磁盘读写操作都会经过这个缓存,这不太可能被绕开除非直接使用 I/O。所以虽然每个程序都在自己的线程里只缓存了一份数据,但在操作系统的缓存里还有一份,这等于存了两份数据。
基于 jvm 内存有以下缺点:
- Java 对象占用空间是非常大的,差不多是要存储的数据的两倍甚至更高。
- 随着堆中数据量的增加,垃圾回收回变的越来越困难,而且可能导致错误
基于以上分析,如果把数据缓存在内存里,因为需要存储两份,不得不使用两倍的内存空间,Kafka 基于JVM,又不得不将空间再次加倍,再加上要避免 GC 带来的性能影响,在一个 32G 内存的机器上,不得不使用到 28-30G 的内存空间。并且当系统重启的时候,又必须要将数据刷到内存中( 10GB 内存差不多要用 10 分钟),就算使用冷刷新(不是一次性刷进内存,而是在使用数据的时候没有就刷到内存)也会导致最初的时候新能非常慢。
基于操作系统的文件系统来设计有以下好处:
- 可以通过 os 的 pagecache 来有效利用主内存空间,由于数据紧凑,可以 cache 大量数据,并且没有 gc 的压力
- 即使服务重启,缓存中的数据也是热的(不需要预热)。而基于进程的缓存,需要程序进行预热,而且会消耗很长的时间。(10G 大概需要 10 分钟)
- 大大简化了代码。因为在缓存和文件系统之间保持一致性的所有逻辑都在 OS 中。以上建议和设计使得代码实现起来十分简单,不需要尽力想办法去维护内存中的数据,数据会立即写入磁盘。
总的来说,Kafka 不会保持尽可能多的内容在内存空间,而是尽可能把内容直接写入到磁盘。所有的数据都及时的以持久化日志的方式写入到文件系统,而不必要把内存中的内容刷新到磁盘中。
日志数据持久化特性
写操作:通过将数据追加到文件中实现
读操作:读的时候从文件中读就好了
优势
✓读操作不会阻塞写操作和其他操作(因为读和写都是追加的形式,都是顺序的,不会乱,所以不会发生阻塞),数据大小不对性能产生影响;
✓ 没有容量限制(相对于内存来说)的硬盘空间建立消息系统;
✓ 线性访问磁盘,速度快,可以保存任意一段时间!
文件存储结构
topic 在逻辑上可以被认为是一个 queue。每条消费都必须指定它的 topic,可以简单理解为必须指明把这条消息放进哪个 queue 里。为了使得 Kafka 的吞吐率可以水平扩展,物理上把 topic 分成一个或多个partition,每个 partition 在物理上对应一个文件夹,该文件夹下存储这个 partition 的所有消息和索引文件。
每一个partition目录下的文件被平均切割成大小相等(默认一个文件是500兆,可以手动去设置)的数据文件,
每一个数据文件都被称为一个段(segment file),但每个段消息数量不一定相等,这种特性能够使得老的segment可以被快速清除。
默认保留7天的数据。
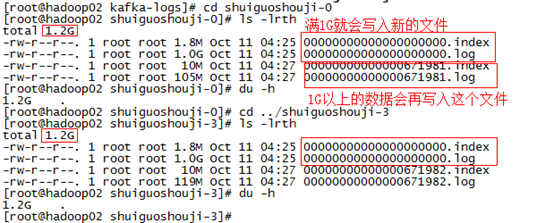
首先00000000000000000000.log文件是最早产生的文件,该文件达到1G(因为我们在配置文件里面指定的1G大小,默认情况下是500兆)
之后又产生了新的0000000000000672348.log文件,新的数据会往这个新的文件里面写,这个文件达到1G之后,数据就会再往下一个文件里面写,
也就是说它只会往文件的末尾追加数据,这就是顺序写的过程,生产者只会对每一个partition做数据的追加(写)的操作。

上图的左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……,那么为什么在index文件中这些编号不是连续的呢?这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
其中以索引文件中元数据3,497为例,其中3代表在右边log数据文件中从上到下第3个消息(在全局partiton表示第368772个消息),其中497表示该消息的物理偏移地址(位置)为497。
kafka 日志分为 index 与 log,两个成对出现;index 文件存储元数据(用来描述数据的数据,这也可能是为什么 index 文件这么大的原因了),log 存储消息。索引文件元数据指向对应 log 文件中 message的迁移地址;例如 2,128 指 log 文件的第 2 条数据,偏移地址为 128;而物理地址(在 index 文件中指定)+ 偏移地址可以定位到消息。
因为每条消息都被 append 到该 partition 中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效
率比随机写内存还要高,这是 Kafka 高吞吐率的一个很重要的保证)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号