

KDD Debiasing top 方案
这是KDD Debiasing赛道结束后各位前排大佬分享的方案,感觉看完之后获益匪浅,从中学习到了很多东西,也对RS这个领域有了更深层次的理解。同时也对领域之间的知识点的相互应用借鉴有了一些新的想法。本次记录我在学习之后的一些理解与想法,在往后希望有用。
纵观每一个方案,除了TOP5方案使用了端到端的深度学习之外,其余方法都遵循了常见的推荐系统的流程:即多路召回——(粗排)——特征工程——训练排序模型(精排),多路召回基本使用了传统的召回方法:基于内容的,基于行为的协同过滤,以及表示学习(embedding)的方法来做商品的召回,当然在这里,需要根据本次题目的具体的题目进行相应的修改,所以要有一定的思考角度;推荐系统中,我们可以思考的角度可以有商品点击的时间相关,点击顺序,方向性,用户活跃度,商品活跃度,用户商品交互特征,商品属性,用户属性,一般都可从这几个方面进行思考。下面从各个方案分别进行介绍,主要分析方案的核心思路与特点:
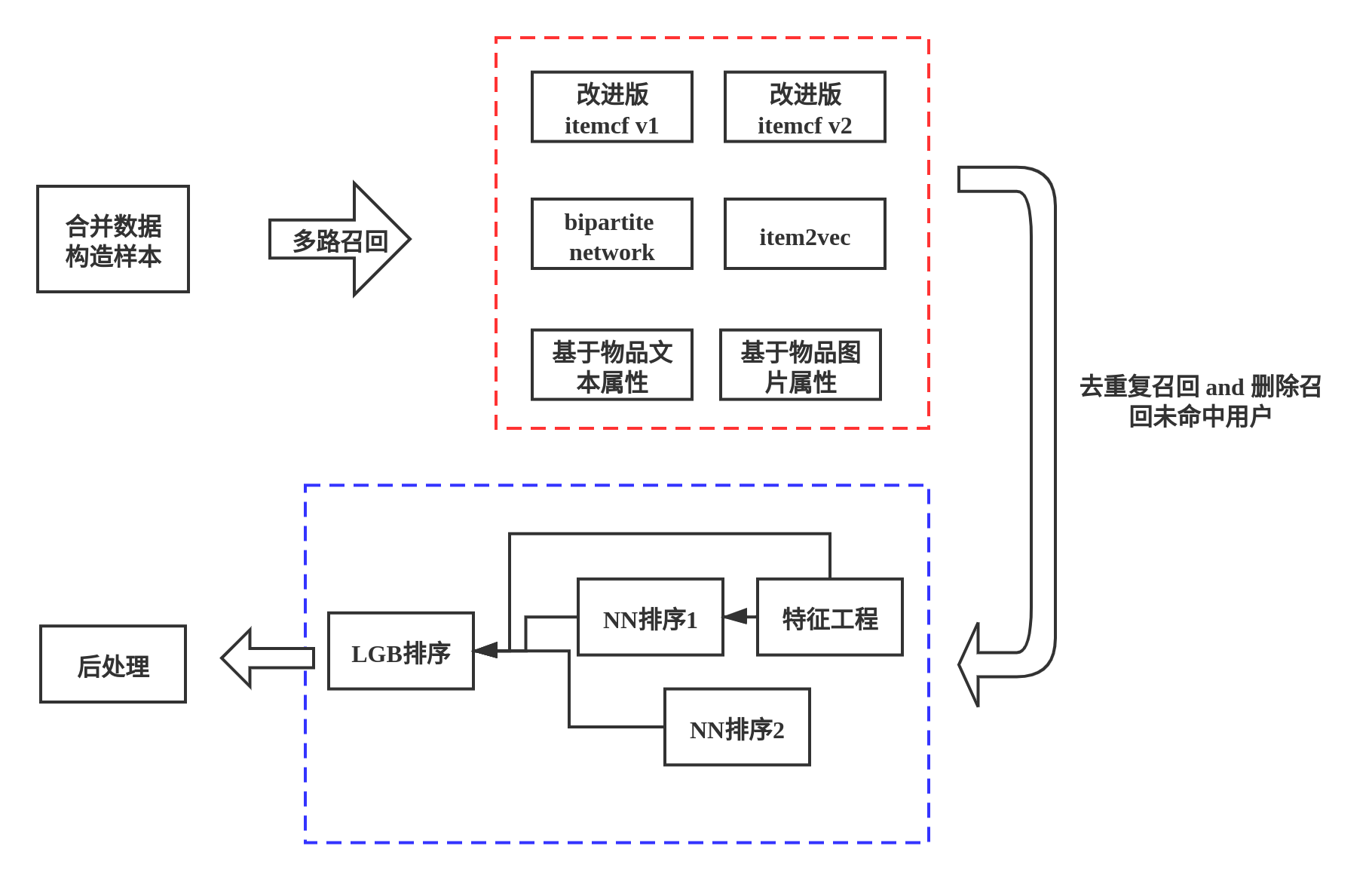
TOP13(来自LogicJake)
比较好理解,对数据集没有什么大的操作,正常按照phase分段进行操作即可,在多路召回阶段没有使用太过于复杂的召回方式,但是这里他介绍了一种比较新颖的ANN计算工具——Annoy工具,Annoy 是 Spotify 开源的一个用于近似最近邻查询的 C++/Python 工具,对内存使用进行了优化,索引可以在硬盘保存或者加载。简单来说,先将商品的向量表示建立索引,然后用用户的向量表示寻找近似的最相似商品。Annoy 稍微牺牲了相似度计算的准确度,却极大地提高了查找速度。
排序阶段,自定义了一种排序模型,使用两种深度模型做一次特征提取,计算得到初步的预测概率特征,然后与其余构造的特征一起放入LGB模型,做最后的点击概率预测。我觉得这个方案的最大创新点就是在排序阶段,除了使用人工构造的特征,还利用LSTM处理序列的特性,利用深度学习网络做了一次特征的提取。深度学习可能会得到人为无法构造的特征。
后处理,对高频次商品做惩罚。
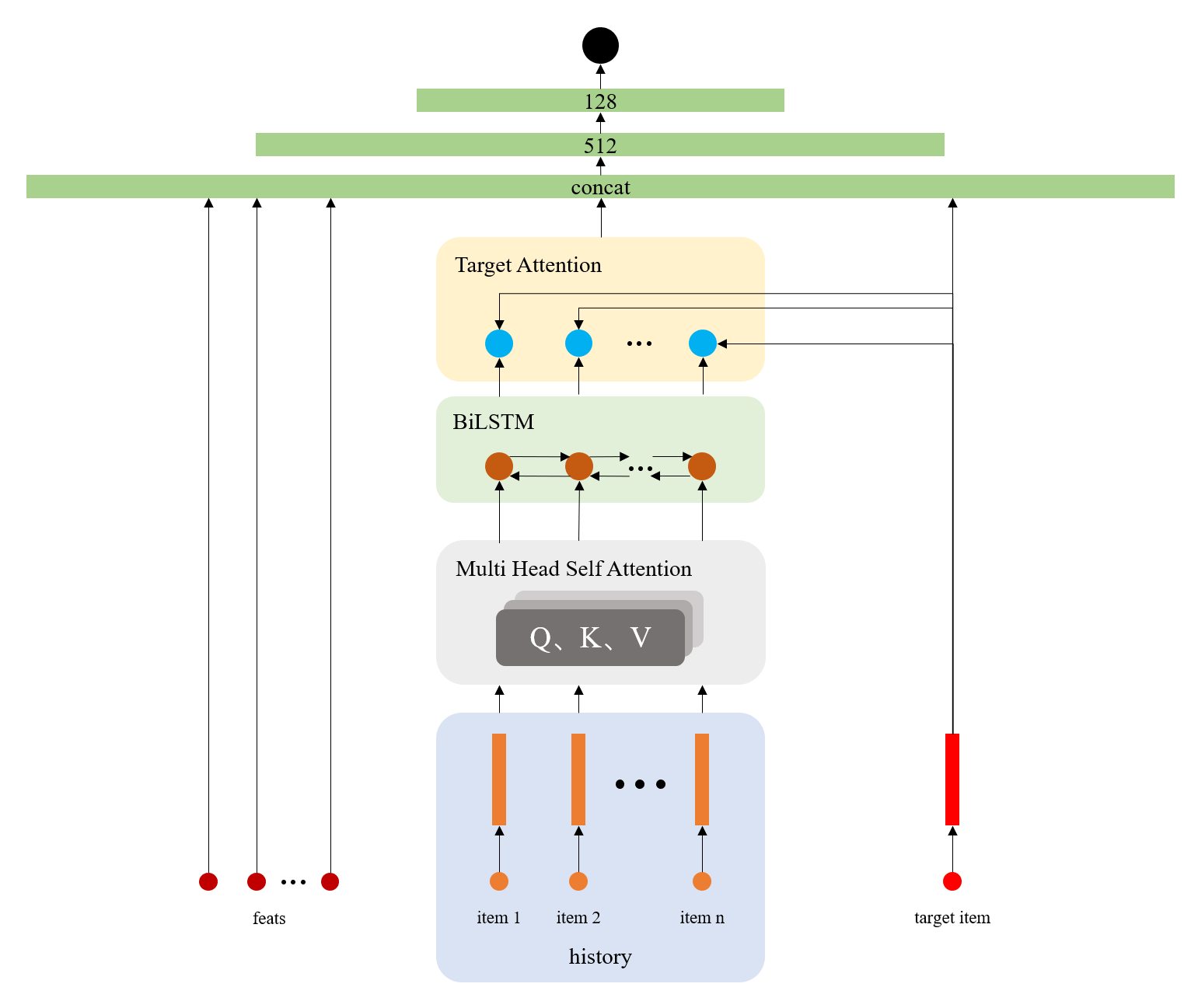
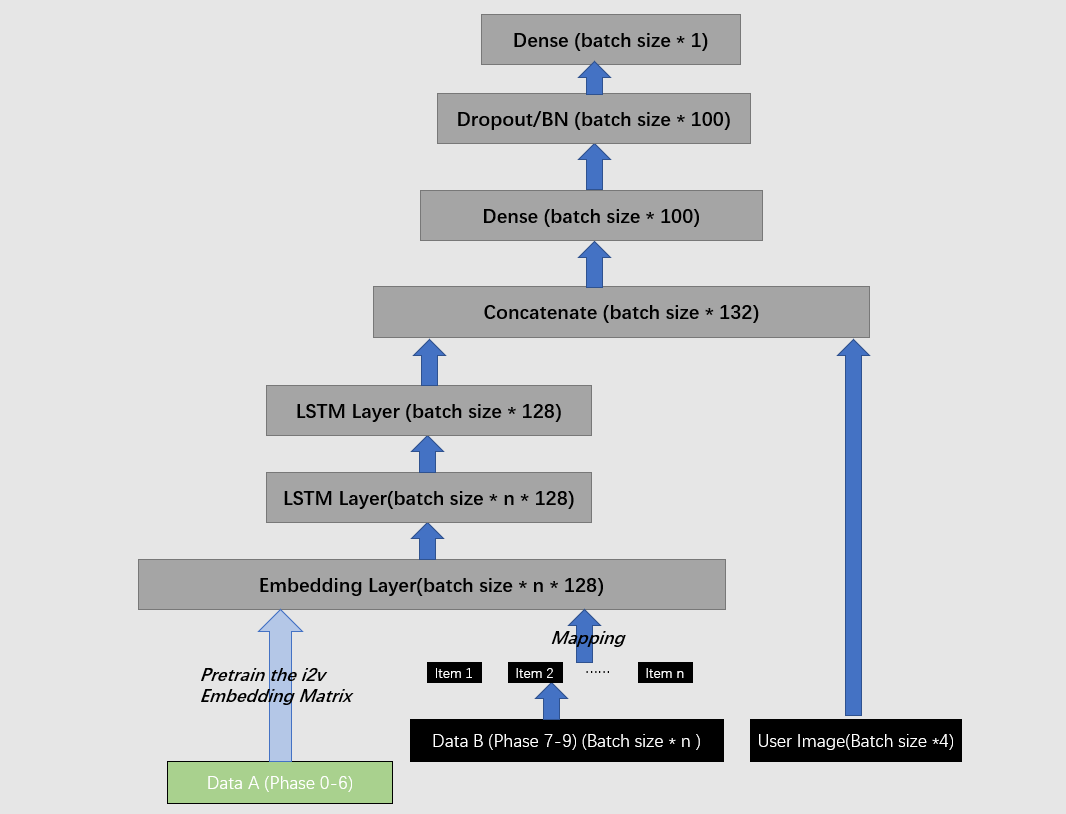
TOP10(来自蘑菇先生)
可以分析得到此为序列推荐场景任务,针对这个点,起使我们可以对应查询到很多的资料论文解决这个场景下的任务;该方案对数据的使用做了一定的处理,通过分析观察到不同阶段之间训练集会有一定的重叠,那么不妨使用全量数据来对当前阶段进行训练,但是要注意的是,对这种含有时间的数据,一定要注意是否会发生数据的穿越,所以有一个关键点:
- 对每个用户,根据测试集中的q-time,将q-time之后的数据过滤掉,防止user的行为穿越。
- 对1) 中过滤后的数据,进一步,把不在当前阶段出现的item的行为数据过滤掉,防止item穿越。
对每个阶段,经过上述步骤后得到筛选后的针对该阶段的全量训练数据,会作为多路召回模型的输入进行训练和召回。
召回阶段,还是使用了常见的召回方法,user-cf、item-cf、swing、bi-graph,但是都对其进行了一定的改进,都在其中加入了用户的活跃度或者商品的热度(这是根据本赛题特性——发掘出现频次少的商品)后面一种召回方法我觉得很新颖,针对序列推荐场景下的一种模型——SR-GNN,这种模型天然适用于这种场景,但是使用原始论文的效果不佳,在这里对网络进行了很大的改进,主要有:物品嵌入初始化,缺失物品属性的补全,带有节点权重的消息传播改造,加入位置编码,序列级别的嵌入表征,损失函数的改造。改造后的效果,比其他几种方法还要好。从这里我们可以看出,在使用原始论文方法的时候,我们还要分析现有场景的特点,进行相应的改造,才能发挥出最大的效果。
每一种召回得到200个召回商品,这里又有一个关键点,那就是召回之后进行一次粗排,保证对低频物品的倾向性。上述处理完之后,进行多路找回融合,这个我之前也思考过,我尝试了将各路召回的商品打分直接进行相加,但是一个问题就是,不同方法没有可比性,在这个方案中给出了解决方法:对每一种方案进行最大最小归一化再相加合并。
TOP6(来源于OTTO公众号)
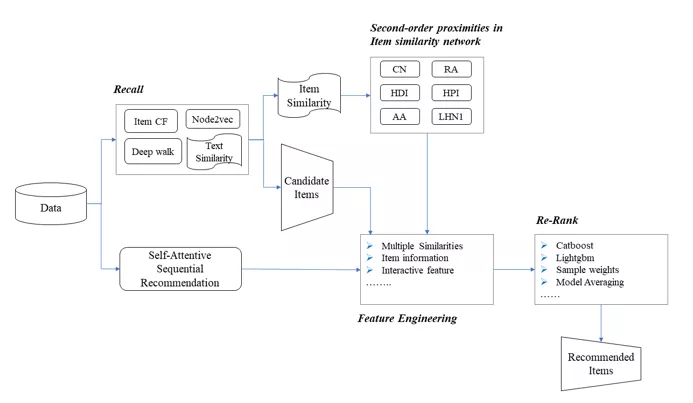
此方案,与前两个方案有很大的不同,方案很大一部分都在使用表示学习——即学习用户和商品的embedding,方案着重学习商品的embedding,并以此计算得到商品的相似度,所以方案主要以构建商品相似性网络为主,并且使用图结构尤为很多,利用图的特性,还进行商品的二阶相似度的深层次发掘。感觉和之前两种方案相比,难度相对大了一点,而且对机器性能有一定的要求,基于图的算法,需要构建很大的商品关系网络。后续有机会还是想加深一些理解。
TOP1(来源于OTTO公众号)
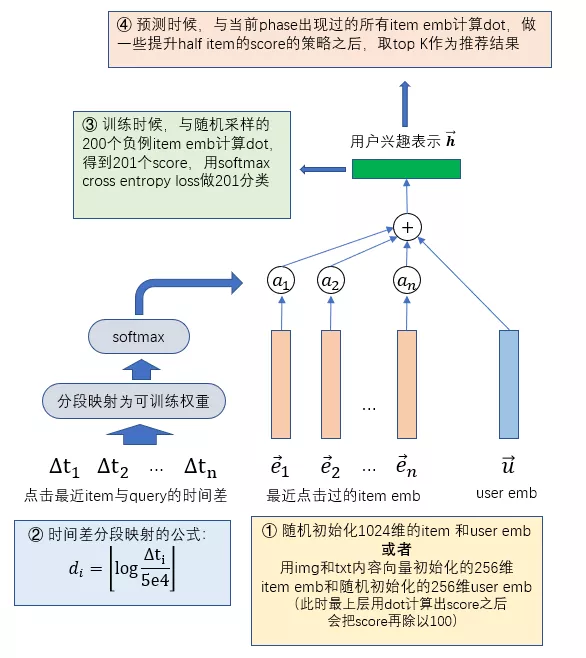
纯深度学习在推荐系统上的应用,端到端的最大程度体现,暴力完美的解决了问题,在阅读完之后,感觉解决问题尽然如此之快,在将商品与用户的相关embedding输入之后,直接暴力计算点击概率,将召回与排序合二为一,简单明了,不过在实现过程中,加入了attention机制
同样的,方案最后加入了后处理,提高低频次物品的曝光率。
Reference
TOP13赛后总结
TOP10方案
TOP6方案
TOP5方案
用链路预测算法来计算二阶相似性
干货 | 一文读懂 ANN
SR-GNN
Bipartite graph/network学习
浅谈Attention机制的理解
浅梦-一文梳理RS中embedding
浅梦-RS主流召回方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号