
#Python函数
一、函数介绍
在我们以往的学习编程的过程当中,碰到的最多的两张编程方式或者说编程方法:面向过程和面向对象。其实不管是哪一种,其实都是编程的方法论而已。但是现在有一种更古老的编程方式:函数式编程,以它的不保存的状态,不修改变量等特性,重新进入我们的视野。
- 面向对象 --->类 ---->class
- 面向过程 --->过程--->def
- 函数式编程-->函数--->def
二、函数定义
我们上初中那会也学过函数,即:y=2x,说白了,这里面总共就两个变量x和y,x是自变量,y是因变量(因为x变而变),y是x的函数。自变量的取值范围,叫做这个函数的定义域。
说了这么多,我们还是来讲讲,编程中的函数定义吧!!!
1、函数定义:
def test():
"the funcation details"
print("in the test funcation")
return 0
def #定义函数的关键字
test #函数名
() #定义形参,我这边没有定义。如果定义的话,可以写成:def test(x): 其中x就是形式参数
"the funcation details" # 文档描述(非必要,但是强烈建议你为你的函数添加详细信息,方便别人阅读)
print #泛指代码块或者程序逻辑处理
return #定义返回值
2、过程定义:
#定义过程
def test_2():
"the funcation details"
print("in the test funcation")
注:从上面两个例子看出来,函数和过程,无非就是函数比过程多了一个return的返回值,其他的也没什么不一样。
3、两者比较:
#定义函数
def test_1():
"the funcation details"
print("in the test funcation")
return 0
#定义过程
def test_2():
"the funcation details"
print("in the test funcation")
a = test_1()
b = test_2()
print(a)
print(b)
#输出
in the test funcation
in the test funcation
#输出返回值
0
#没有return ,返回为空
None
小结:不难看出,函数和过程其实在python中没有过多的界限,当有return时,则输出返回值,当没有return,则返回None
三、使用函数原因
至此、我们已经了解了函数,但是我们为啥要用函数啊,我觉的我们以前的那种写法挺好的呀!其实不然,我给使用函数总结 了两点好处:
- 代码重复利用
- 可扩展性
- 保持一致性
1、代码重复利用
我们平时写代码的时候,最讨厌的就是写重复代码,这个无疑是增加我们的工作量,所以代码重用性是非常有必要的。下面我们就举个简单的例子吧,使用函数和不使用函数的区别。
①优化前
#假设我们编写好了一个逻辑(功能),用来打印一个字符串
print("高高最帅")
#现在下面有2个函数,每个函数处理完了,都需要使用上面的逻辑,那么唯一的方法就是拷贝2次这样的逻辑
def test_1():
"the funcation details"
print("in the test1")
print("高高最帅")
def test_2():
"the funcation details"
print("in the test2")
print("高高最帅")
那么假设有n个函数,我们是不是也要拷贝n次呐?于是,我们就诞生了下面的方法
②优化后
def test():
print("高高最帅")
def test_1():
"the funcation details"
print("in the test1")
test()
def test_2():
"the funcation details"
print("in the test2")
test()
2、可扩展,代码保持一致性
#代码逻辑变了
def test():
print("高高一直都很帅")
def test_1():
"the funcation details"
print("in the test1")
test()
def test_2():
"the funcation details"
print("in the test2")
test()
注:如果遇到代码逻辑变了,用以前拷贝n次的方法,那什么时候拷贝完啊,而且中间有遗漏怎么办,如果用了函数,我们只需要改这个函数的逻辑即可,不用改其他任何地方。
四、返回值
之前在day3-函数介绍中提到了return关键字,但是那个只是提到,并没有详细的介绍的return关键字的用法,下面我们就来详细的阐述一下。
1、return作用
return其实有两个作用:
- 需要用一个变量来接受程序结束后返回的结果
- 它是作为一个结束符,终止程序运行
def test():
print("in the test_1")
return 0
print("the end") #结果中没有打印
x = test()
print(x)
#输出
in the test_1 #第一次打印
0 #结果返回值
注:从上面的代码可以看出,return 0后面的代码就不执行了,只执行return前面的代码;变量x接受了test()函数结束后的返回结果
2、返回多个值
上面我们试了返回一个常量值,或者说一个对象值,下面我们来试试,不返回值,或者说返回多个值得情况
# __auther__ == zhangqigao
def test_1():
print("in the test_1")
def test_2():
print("in the test_2")
return 0
def test_3():
print("in the test_3")
return 1,"hello",["qigao","shuaigao"],{"name":"qigao"}
x = test_1()
y = test_2()
z =test_3()
print(x)
print(y)
print(z)
#输出
in the test_1
in the test_2
in the test_3
None #x的值
0 #y的值
(1, 'hello', ['qigao', 'shuaigao'], {'name': 'qigao'}) #z的值
从上面的例子可以看出:
- 没有定义,返回值数=0,返回:None
- 只定义了1个返回值,返回值=1 ,返回:定义的那个值,或者说定义的那个object
- 定义了2个以上,返回值 > 1,返回:1个元组(tuple)
提问:这边我们不经意的要问,为什么要有返回值?
因为我们想要想要这个函数的执行结果,这个执行结果会在后面的程序运行过程中需要用到。
五、有参数函数调用
在此之前,我们演示的函数都是没有带参数的,下面我们就来说说带参数的函数。在讲之前,我们先来说一下,什么是形参,什么是实参吧!
- 形参:指的是形式参数,是虚拟的,不占用内存空间,形参单元只有被调用的时才分配内存单元
- 实参:指的是实际参数,是一个变量,占用内存空间,数据传递单向,实参传给形参,形参不能传给实参
代码如下:
def test(x,y): #x,y是形参
print(x)
print(y)
test(1,2) #1和2是实参
#输出
1
2
1、位置参数
从上面的例子可以看出,实际参数和形式参数是一一对应的,如果调换位置,x和y被调用的时,位置也会互换,代码如下:
def test(x,y):
print(x)
print(y)
print("--------互换前-----")
test(1,2)
print("--------互换后-----")
test(2,1)
#输出
--------互换前-----
1
2
--------互换后-----
2
1
那有些同学会说,那我多一个或者少一个参数,总归没事了吧!那我看看行不行呢?
①多一个参数
def test(x,y):
print(x)
print(y)
print("--------多一个参数----")
test(1,2,3)
#输出
--------多一个参数----
Traceback (most recent call last):
File "D:/PycharmProjects/pyhomework/day3/函数_带参数.py", line 8, in <module>
test(1,2,3)
TypeError: test() takes 2 positional arguments but 3 were given #test()函数需要传两个实参,你传了三个实参
②少一个参数
def test(x,y):
print(x)
print(y)
print("--------少一个参数----")
test(1)
#输出
--------少一个参数----
Traceback (most recent call last):
File "D:/PycharmProjects/pyhomework/day3/函数_带参数.py", line 8, in <module>
test(1)
TypeError: test() missing 1 required positional argument: 'y' #没有给y参数传实参
事实证明:多传一个参数或者少传一个参数都是不行的。
2、关键字参数
到这边有些小伙伴不经意的要说,像这种位置参数,有点死,我不想这么干,万一我传错了咋办,对吧!OK,没有问题,下面我们就来讲讲关键字传参。
关键字传参不需要一一对应,只需要你指定你的哪个形参调用哪一个实参即可,代码如下:
def test(x,y):
print(x)
print(y)
print("--------互换前------")
test(x=1,y=2)
print("--------互换后------")
test(y=2,x=1)
#输出
--------互换前------
1
2
--------互换后------
1
2
但是,这是又有小伙伴要问了,那我可不可以位置参数和关键字参数结合起来用呐?接下来,我们就来探讨一下。
①位置参数在前,关键字参数在后
def test(x,y):
print(x)
print(y)
test(1,y=2)
#输出
1
2
我擦这样是可以的,那我试试这种情况,我把后面关键字不传给y,我传给x,代码如下:
def test(x,y):
print(x)
print(y)
test(1,x=2)
#输出
Traceback (most recent call last):
File "D:/PycharmProjects/pyhomework/day3/函数_带参数.py", line 8, in <module>
test(1,x=2)
TypeError: test() got multiple values for argument 'x' #给x形参传的值过多
报错的意思是:给形参x传的值过多。这种报错的原因是:实参1已经传给了形参x,后面的x=2又传了一次,所以报错。
②关键字在前,位置参数在后
def test(x,y):
print(x)
print(y)
test(y=2,1)
#输出
File "D:/PycharmProjects/pyhomework/day3/函数_带参数.py", line 8
test(y=2,1)
^
SyntaxError: positional argument follows keyword argument # 关键字参数在位置参数的前面
我去,看来这样不行。那我位置参数放前面,中间放关键字参数总行了吧!代码如下:
def test(x,y,z):
print(x)
print(y)
test(1,y=2,3)
#输出
File "D:/PycharmProjects/pyhomework/day3/函数_带参数.py", line 8
test(1,y=2,3)
^
SyntaxError: positional argument follows keyword argument
还是一样的错误,我去,那我只能把关键字参数放最后试试!
def test(x,y,z):
print(x)
print(y)
print(z)
test(1,2,z=3)
#输出
1
2
3
那我最后两个用关键字参数呐?
def test(x,y,z):
print(x)
print(y)
print(z)
test(1,z=2,y=3)
#输出
1
3
2
这样也是可以的,所以,得出一个结论:关键字参数是不能写在位置参数前面的。
总结:
- 既有关键字,又有位置参数时,是按位置参数的顺序来
- 关键字参数是不能写在位置参数的前面的
六、默认参数
默认参数指的是,我们在传参之前,先给参数制定一个默认的值。当我们调用函数时,默认参数是非必须传递的。
def test(x,y=2):
print(x)
print(y)
print("-----data1----")
test(1) #没有给默认参数传值
print("-----data2----")
test(1,3) #给默认参数传位置参数
print("-----data3----")
test(1,y=3) #给默认参数传关键字参数
#输出
-----data1----
1
2
-----data2----
1
3
-----data3----
1
3
默认参数用途:
- 安装默认软件(def test(x,soft=True))
- 传递一下默认的值(定义mysql的默认端口号:def count(host,port=3306))
七、参数组(非固定参数)
之前我们传参数,都是传一个固定参数,不能多也不能少,但是如果说我们需要非固定参数怎么办呢?好吧,于是就衍生出了,以下两种传参方式:
- 非固定位置参数传参(*args)
- 非固定关键字传参(**kwargs)
下面我们就来说说这两种方式传参:
1、非固定位置参数传参
①功能:接收N个位置参数,转换成元组的形式。
②定义,代码如下:
def test(*args): #形参必须以*开头,args参数名随便定义,但是最好按规范来,定义成args
print(args)
test(1,2,3,4,5) #输入多个位置参数
#输出
(1, 2, 3, 4, 5) #多个参数转换成元组
这边不禁的有个疑问,你这是传入的都是N个位置参数,那我要传入一整个列表咋办,我要完全的获取这个列表的值。
③传入列表
def test(*args):
print(args)
print("-------data1-----")
test() #如果什么都不传入的话,则输出空元组
print("-------data2-----")
test(*[1,2,3,4,5]) #如果在传入的列表的前面加*,输出的args = tuple([1,2,3,4,5])
print("-------data3-----")
test([1,2,3,4,5]) #如果再传入的列表前不加*,则列表被当做单个位置参数,所以输出的结果是元组中的一个元素
#输出
-------data1-----
()
-------data2-----
(1, 2, 3, 4, 5)
-------data3-----
([1, 2, 3, 4, 5],)
④位置参数和非固定位置参数
def test(x,*args):
print(x) #位置参数
print(args) #非固定参数
test(1,2,3,4,5,6)
#输出
1
(2, 3, 4, 5, 6)
从上面看出,第1个参数,被当做位置参数,剩下的被当做非固定位置参数。
⑤关键字和非固定位置参数
def test(x,*args):
print(x)
print(args)
test(x=1,2,3,4,5,6)
#输出
File "D:/PycharmProjects/pyhomework/day3/非固定参数/非关键字参数.py", line 21
test(x=1,2,3,4,5,6)
^
SyntaxError: positional argument follows keyword argument #位置参数在关键字参数后面
很显然报错了,因为x=1是关键字参数,*args是位置参数,而关键字参数不能再位置参数前面的,所以报错。
2、非固定关键字传参
①功能:把N个关键字参数,转换成字典形式
②定义,代码如下:
def test(**kwargs): #形参必须以**开头,kwargs参数名随便定义,但是最好按规范来,定义成kwargs
print(kwargs)
test(name="qigao",age=18) #传入多个关键字参数
#输出
{'name': 'qigao', 'age': 18} #多个关键字参数转换成字典
③传入字典
def test(**kwargs):
print(kwargs)
test(**{"name":"qigao","age":18}) #传入字典时,一定要在字典前面加**,否则就会报错
#输出
{'name': 'qigao', 'age': 18}
然而,有些小伙伴说,我就不信,难道不加**,就会报错,那为啥非固定位置参数不加*,为啥就不报错呐?下面我们就用事实说话,代码如下:
def test(**kwargs):
print(kwargs)
test({"name":"qigao","age":18})
#输出
Traceback (most recent call last):
File "D:/PycharmProjects/pyhomework/day3/非固定参数/非固定关键字参数.py", line 9, in <module>
test({"name":"qigao","age":18})
TypeError: test() takes 0 positional arguments but 1 was given #报类型错误,传入的是位置参数
因为传入的字典被当做位置参数,所以被报类型错误,所以小伙伴们千万要记住:传字典,加**
④配合位置参数使用
def test(name,**kwargs):
print(name)
print(kwargs)
print("------data1-----")
test("qigao") #1个位置参数
print("------data2------")
test("qigao",age=18,sex="M") #1个位置参数,两个关键字参数
print("------data3------")
test(name="qigao",age=18,sex="M") #3个关键字参数
#输出
------data1-----
qigao #输出1个位置参数
{} #没有输入关键字参数,所以输出空字典
------data2------
qigao #第1个位置参数
{'age': 18, 'sex': 'M'} #剩下关键字参数,转换成1个字典
------data3------
qigao #第1个关键字参数
{'age': 18, 'sex': 'M'} #剩下的关键字参数,转换成1个字典
⑤位置参数、关键字和非固定关键字参数
提示:参数组一定要往最后放
def test(name,age=18,**kwargs):
print(name)
print(age)
print(kwargs)
print("----------data1--------")
test("qigao",sex='M',hobby='tesl')
print("----------data2--------")
test("qigao",34,sex='M',hobby='tesl')
print("----------data3--------")
test("qigao",sex='M',hobby='tesl',age=34) #age关键字参数放到最后,也可以的
#输出
----------data1--------
qigao
18 #不传,显示默认参数
{'sex': 'M', 'hobby': 'tesl'}
----------data2--------
qigao
34 #传位置参数
{'sex': 'M', 'hobby': 'tesl'}
----------data3--------
qigao
34 #关键字参数,放在前后并没有影响
{'sex': 'M', 'hobby': 'tesl'}
注:就是说,如果遇到一个关键字传参和非固定关键字传参,前后放的位置是不影响传参的,但是我们一般还是按顺序来。
⑥位置参数、关键字参数、非固定位置参数和非固定关键字参数
def test(name,age=18,*args,**kwargs):
print(name)
print(age)
print(args)
print(kwargs)
print("-------第1种传参--------")
test("qigao",19,1,2,3,4,sex="m",hobby="tesla")
print("-------第2种传参--------")
test("qigao",19,*[1,2,3,4],**{'sex':"m",'hobby':"tesla"})
#输出
-------第1种传参--------
qigao #传name位置参数
19 #给age传位置参数
(1, 2, 3, 4) #非固定位置参数,以转换成元组
{'sex': 'm', 'hobby': 'tesla'} # 非固定关键字参数,转换成字典
-------第2种传参---------
qigao
19
(1, 2, 3, 4) #以列表的形式传入,在列表前加*
{'sex': 'm', 'hobby': 'tesla'} #以字典的形式传入,在字典前加**
那么问题来了,上面的age传参传的是位置参数,那我能不能传关键字参数呐?现在我们就来看看,代码如下:
def test(name,age=18,*args,**kwargs):
print(name)
print(age)
print(args)
print(kwargs)
test("qigao",age=19,1,2,3,4,sex="m",hobby="tesla")
#输出
File "D:/PycharmProjects/pyhomework/day3/非固定参数/非固定关键字参数.py", line 55
test("qigao",age=19,1,2,3,4,sex="m",hobby="tesla")
^
SyntaxError: positional argument follows keyword argument #语法错误,位置参数在关键字参数前面
看来是不可以的,为什么?因为age=19是关键字参数,而后面的*args是非固定位置参数,说白了不管*args传入几个字,它的本质都是位置参数,上面我们提到关键字参数是不能再位置参数的前面,所以报错了。
看来上面的情况是不可以的,那能不能非固定关键字参数在非固定位置参数前面呢?来,我们带着疑问一起来试一下。代码如下:
def test(name,age=18,*args,**kwargs):
print(name)
print(age)
print(args)
print(kwargs)
test("qigao",19,sex="m",hobby="tesla",1,2,3,4,5)
#输出
File "D:/PycharmProjects/pyhomework/day3/非固定参数/非固定关键字参数.py", line 57
test("qigao",19,sex="m",hobby="tesla",1,2,3,4,5)
^
SyntaxError: positional argument follows keyword argument #语法错误,关键字参数在位置参数前面
我擦咧,也是不可以的,经我仔细研究发现,非固定关键字参数,本质也是关键字参数,是不能放在非固定位置参数的前面的。
总结
- 参数分为位置参数、关键字参数、默认参数、非固定位置参数和非固定关键字参数
- 位置参数之前传参,位置是不能调换的,多一个或者少一个参数都是不可以的。
- 关键字参数是不能放在位置参数前面的。
- 函数传参的位置一次是,位置参数,默认参数、非固定位置参数、非固定关键字参数(def test(name,age=18,*args,**kwargs))
- 关键字传参,可以不用考虑位置的前后问题
八、作用域、局部变量、全局变量
我们之前写代码,都需要声明变量,但是我们思考过变量的作用范围吗?今天我们就来讲讲变量的作用范围,这个作用范围又叫作用域。首先我们根据变量的作用范围把变量分为:局部变量和全局变量,即:
- 局部变量
- 全局变量
我们先做一个小实验:一个函数体内部调用另外一个函数,代码如下:
def test(name,age=18,**kwargs):
print(name)
print(age)
print(kwargs)
logger("test") #调用logger函数
def logger(sounce):
print("from %s"%sounce)
①logger函数之后执行
def test(name,age=18,**kwargs):
print(name)
print(age)
print(kwargs)
logger("test")
def logger(sounce):
print("from %s"%sounce)
test("qigao",age=23,sex="m",hobby="tesla") #在logger函数之后调用
#输出
qigao
23
{'hobby': 'tesla', 'sex': 'm'}
from test
ok,很完美,一点问题都没有,那么还有一种情况,就是在logger函数之前调用呐?
②logger函数之前执行
def test(name,age=18,**kwargs):
print(name)
print(age)
print(kwargs)
logger("test")
test("qigao",age=23,sex="m",hobby="tesla") #在logger函数之前调用
def logger(sounce):
print("from %s"%sounce)
#输出
qigao
23
{'hobby': 'tesla', 'sex': 'm'}
Traceback (most recent call last):
File "D:/PycharmProjects/pyhomework/day3/局部变量和全局变量/test.py", line 12, in <module>
test("qigao",age=23,sex="m",hobby="tesla")
File "D:/PycharmProjects/pyhomework/day3/局部变量和全局变量/test.py", line 10, in test
logger("test")
NameError: name 'logger' is not defined #命名错误:logger没有被定义
很显然是出错的,为什么呢?我不是定义了logger函数了吗?喔。。。。。。原来在logger函数之前执行,logger函数还没有被读到内存中,所以报错。
1、局部变量
局部变量:顾名思义,指在局部生效,定义在函数体内的变量只能在函数里面生效,出个这个函数体,就不能找到它,这个函数就是这个变量的作用域。
下面我们就用事实说话吧,请看如下代码:
def test(name):
print("before change:",name)
name = "qigao" #局部变量name,只能在这个函数内生效,这个函数就是这个变量的作用域
print("after change:",name)
name = "alex"
print("-----调用test-----")
test(name)
print("------打印name----")
print(name)
#输出
-----调用test-----
before change: alex
after change: qigao #局部变量生效
------打印name----
alex
2、全局变量
有了局部变量,那就肯定有全局变量,那什么是全局变量呐?全局变量又改怎么定义呢?
全局变量:指的是在整个程序中都生效的变量,在整个代码的顶层声明。
代码如下:
school = "leidu edu" #定义全局变量
def test_1():
print("school:",school)
def test_2():
school = "qigao linux "
print("school:",school)
print("------test_1----")
test_1()
print("------test_2----")
test_2()
print("----打印school--")
print("school:",school)
#输出
------test_1----
school: leidu edu #打印的是全局变量
------test_2----
school: qigao linux #打印局部变量
----打印school--
school: leidu edu #打印全局变量
从上面的例子可看出全局变量的优先级是低于局部变量的,当函数体内没有局部变量,才会去找全局变量。但是有的同学会问了,那我需要在函数体内修改全局变量咋办呢?
①函数里面修改全局变量
- 改前用global先声明一下全局变量
- 将全局变量重新赋值
school = "leidu edu" #定义全局变量
def test():
global school #用global关键字声明全局变量
school = "qigao linux " #将全局变量重新赋值
print("school:",school)
print("------test_2----")
test()
print("----打印school--")
print("school:",school)
#输出
------test_2----
school: qigao linux
----打印school--
school: qigao linux #全局变量被改掉
②只在函数里面声明全局变量
def test():
global school #只在里面定义全局变量
school = "qigao linux"
print("school:",school)
print("--------test-------")
test()
print("-----打印school----")
print("school:",school)
#输出
--------test-------
school: qigao linux
-----打印school----
school: qigao linux
也是可以的,但是我们最好不要用以上2种情况,也就是说最好不要用global这个关键字,因为你用了,其他人调你的函数时,就乱套了,而且还不好调试,说不定还冒着被开除的危险,所以请大家忘记它吧,只是知道有这么一个东西就行了。
③修改列表
names = ['alex',"qigao"] #定义一个列表
def test():
names[0] = "金角大王"
print(names)
print("--------test-----")
test()
print("------打印names--")
print(names)
#输出
--------test-----
['金角大王', 'qigao'] #函数内的names输出
------打印names--
['金角大王', 'qigao'] #函数外的names输出
从上面的例子可以看出,列表names被当做在函数中全局变量,重新赋值了,是可以被修改的。
小结:1、只有字符串和整数是不可以被修改的,如果修改,需要在函数里面声明global。2、但是复杂的数据类型,像列表(list)、字典(dict)、集合(set),包括我们后面即将要学的类(class)都是可以修改的。
总结
- 在子程序(函数)中定义的变量称为局部变量,在程序一开始定义的变量称为全局变量。
- 全局变量的作用域是整个程序,局部变量的作用域是定义该变量的子程序(函数)。
- 当全局变量和局部变量同名时:在定义局部变量的子程序内,局部变量起作用;在其他地方,全局变量起作用。
九、匿名函数、eval()函数
1.匿名函数
也叫 lambda 表达式
a.匿名函数的核心:一些简单的需要用函数去解决的问题,匿名函数的函数体只有一行
b.参数可以有多个,用逗号隔开
c.返回值和正常的函数一样可以是任意的数据类型
d.匿名函数不支持复杂的逻辑判断
e.一般跟其他函数搭配使用,如map()、filter()
#这段代码
def calc(x,y):
return x**y
print(calc(2,5))
#换成匿名函数
calc = lambda x,y:x**y
print(calc(2,5))
#输出
32
你也许会说,用上这个东西没感觉有毛方便呀, 。。。。呵呵,如果是这么用,确实没毛线改进,不过匿名函数主要是和其它函数搭配使用的呢,如下
res = map(lambda x:x**2,[1,5,7,4,8])
for i in res:
print(i)
#输出
1
25
49
16
64
2.eval()函数
在我们使用一些类似于字典的字符串时,虽然它看起来很像字典,但是在它的最外层多了引号,说明它是字符串,但是我们如何把它转换成字典呐,这就用到了eval()函数,看看eval()函数是如何把字符串转换成字典的,下面就来看看见证奇迹的时刻:
#定义一个类似于字典的字符串,把值赋给arg
>>> arg = '''{
'backend': 'www.oldboy.org',
'record':{
'server': '100.1.7.9',
'weight': 20,
'maxconn': 30
}
}'''
#这边根据键取值报错,说明它是一个字符串,不是字典
>>> arg["backend"]
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: string indices must be integers
#通过eval()函数把字符串转成字典
>>> arg = eval(arg)
#显示的类型是字典
>>> type(arg)
<class 'dict'>
>>> arg
{'record': {'server': '100.1.7.9', 'weight': 20, 'maxconn': 30}, 'backend': 'www.oldboy.org'}
#通过键能获取对应的值,说明字符串成功转成字典
>>> arg["backend"]
'www.oldboy.org'
十、递归
定义:递归调用是函数嵌套调用的一种特殊形式,如果一个函数在内部直接或间接调用自身,这个函数就是递归函数。
场景:用10不断除以2,直到除不尽为止,打印每次结果。
思路:
# 10/2=5 # 5/2=2.5 # 2.5/2=1.25 # ...
用while循环实现:
n = 10
while True:
n = int(n/2)
print(n)
if n == 0:
break
#输出
5
2
1
0
非递归方式实现:
def calc(n):
n = int(n/2)
return n
r1 = calc(10)
r2 = calc(r1)
r3 = calc(r2)
r4 = calc(r3)
print(r1)
print(r2)
print(r3)
print(r4)
#输出
5
2
1
0
用递归实现:
def calc(n):
print(n)
if int(n/2) == 0: #结束符
return n
return calc(int(n/2)) #调用函数自身
m = calc(10)
print('----->',m)
#输出
10
5
2
1
-----> 1 #最后返回的值
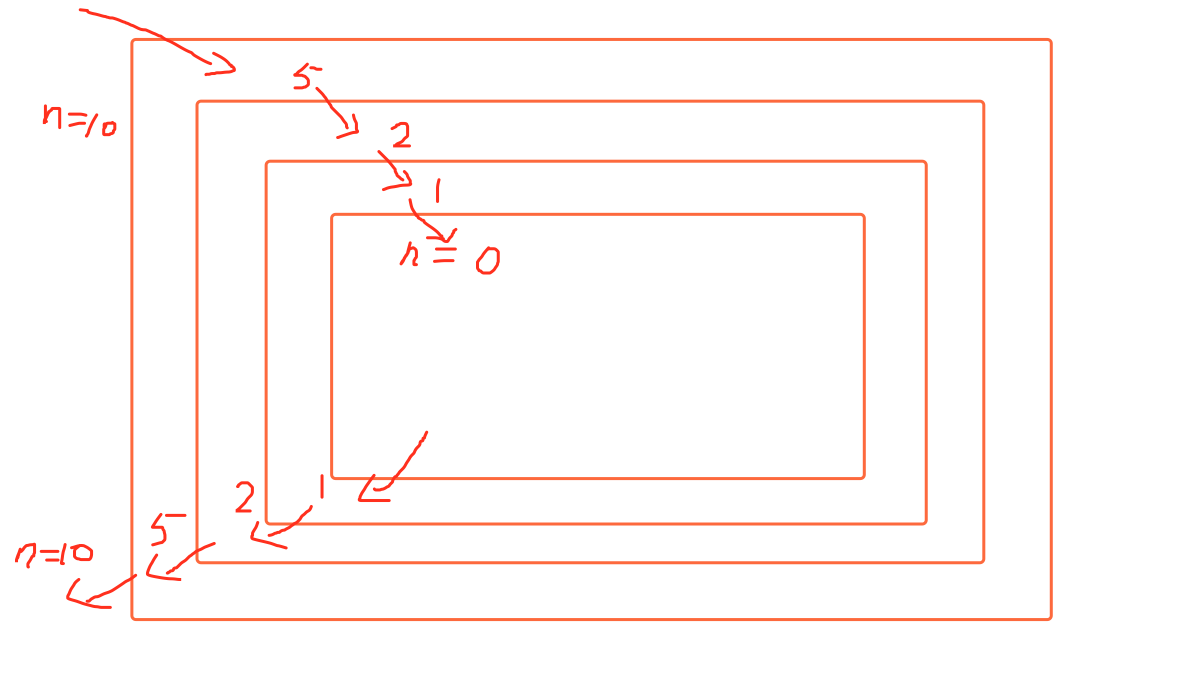
来看实现过程,我改了下代码
def calc(n):
v = int(n/2)
print(v)
if v > 0:
calc(v)
print(n)
calc(10)
#输出
5
2
1
0
1
2
5
10
为什么输出结果是这样?
递归层数:
import sys print(sys.getrecursionlimit()) # 默认递归限制层数 sys.setrecursionlimit(1500) # 修改递归层数
尾递归优化:
调用下一层时候退出。(解决栈溢出的问题,每次只保留当前递归的数据),在C语音里有用,Python中没用。
def recursion(n):
print(n)
return recursion(n+1)
recursion(1)
递归特性:
(1)递归就是在过程或者函数里调用自身
(2)在使用递归策略时,必须有一个明确的结束条件,称为递归出口
(3)每次进入更深一层递归时,问题规模相比上次递归都应有所减少(问题规模:比如你第1次传进的是10,第2次递归应该是9...依次越来越少,不能越来越多)。
(4)递归算法解题通常显得很简洁,但递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出),所以一般不倡导使用递归算法设计程序。
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
递归有什么用呢?下面讲几个实例
1.用递归实现1+2+3...+100
def calc(n):
if n > 0:
return n + calc(n-1)
if n == 0:
return 0
print(calc(100))
2.用递归实现阶乘(就是大于等于1的自然数相乘,1*2*3*4*5*...)
我们知道n! = n *(n-1)! 那么我们可以用递归来实现阶乘,下面计算一下5的阶乘
def factorial(n):
if n == 1:
return 1
return n * factorial(n-1)
print(factorial(5))
#输出
120
3.二分查找


#!/usr/bin/env python # -*- coding:utf-8 -*- """ @Version: v1.0 @Author: wushuaishuai @Contact: 434631143@qq.com @File: 2018-06-20.py @Time: 2018/06/20 15:06 """ """ 1.二分查找练习,所用知识点,函数、递归、高亮显示文字 (1).首先判断列表长度是否>1,>1的情况下再去设置一个变量mid为列表总长度的1/2长度,mid=int(len(dataset)/2) (2).设置完mid后,比较列表的中间的数字(dataset[mid])和要查找的数字(find_num)的关系 (3).data[mid] == find_num时,返回查找的数字 data[mid] > find_num时,返回列表在data[mid]的左边,并return binary_search(dataset[0:mid],find_num) data[mid] < find_num时,返回列表在data[mid]的右边,并return binary_search(dataset[mid+1:],find_num) (4).dataset列表经过上面的不断递归,列表越来越短,最终列表长度变成1,设置会变成空列表,此时先判断dataset是否为空 为空时返回查找的数字不在列表中,再判断dataset[0] == find_num, 当相等时,返回查找的数字,否则返回查找的数字不在列表中。 """ data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35] def binary_search(dataset, find_num): """ :param dataset: 检索的数据集合,eg.列表 :param find_num: 查找的数字 eg.32 :return: 数字查找过程以及最终数字 """ if len(dataset) > 1: mid = int(len(dataset) / 2) # 注意浮点数要转为int # print("mid",mid) # print("len(dataset)",len(dataset)) # print("dataset",dataset) if dataset[mid] == find_num: print("你要查找的数字是%s" % (find_num)) elif dataset[mid] > find_num: print("\033[31;1m你要查找的数字在%s左边\033[0m" % (dataset[mid])) # 31是红色 return binary_search(dataset[0:mid], find_num) # 递归查找,顾头不顾尾,此处mid不用加1 else: print("\033[32;1m你要查找的数字在%s右边\033[0m" % (dataset[mid])) # 32是绿色 return binary_search(dataset[mid + 1:], find_num) # 顾头不顾尾,mid要加1,不包含mid本身 else: # dataset列表通过上面的不断递归,列表越来越短,最终列表长度会变成1,甚至变为空列表 if not dataset: # dataset为空 print("没的分了,你要的数字%s不在这个列表中" % (find_num)) elif dataset[0] == find_num: print("你要查找的数字是%s" % (find_num)) else: print("没的分了,你要的数字%s不在这个列表中" % (find_num)) num = int(input("请输入你要查找的数字>>>")) # input接收的都是字符串,要int一下 binary_search(data, num)
递归算法一般用于解决三类问题:
(1)数据的定义是按递归定义的。(比如Fibonacci函数)
(2)问题解法按递归算法实现。(回溯)
(3)数据的结构形式是按递归定义的。(比如树的遍历,图的搜索,二分法查找等)
十一、内置函数
Python的len为什么你可以直接用?肯定是解释器启动时就定义好了

内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
几个刁钻古怪的内置方法用法提醒
#compile
f = open("函数递归.py")
data =compile(f.read(),'','exec')
exec(data)
#print
msg = "又回到最初的起点"
f = open("tofile","w")
print(msg,"记忆中你青涩的脸",sep="|",end="",file=f)
# #slice
# a = range(20)
# pattern = slice(3,8,2)
# for i in a[pattern]: #等于a[3:8:2]
# print(i)
#
#
#memoryview
#usage:
#>>> memoryview(b'abcd')
#<memory at 0x104069648>
#在进行切片并赋值数据时,不需要重新copy原列表数据,可以直接映射原数据内存,
import time
for n in (100000, 200000, 300000, 400000):
data = b'x'*n
start = time.time()
b = data
while b:
b = b[1:]
print('bytes', n, time.time()-start)
for n in (100000, 200000, 300000, 400000):
data = b'x'*n
start = time.time()
b = memoryview(data)
while b:
b = b[1:]
print('memoryview', n, time.time()-start)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号