
路由正则匹配
一. 不带/的匹配
以下为此时的路由
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^wushen', views.wushen),
re_path(r'^wushenadd', views.wushenadd)
]
视图函数为:
def wushen(request): return HttpResponse('wushen') def wushenadd(request): return HttpResponse('wushenadd')
当匹配wushen的路由为:
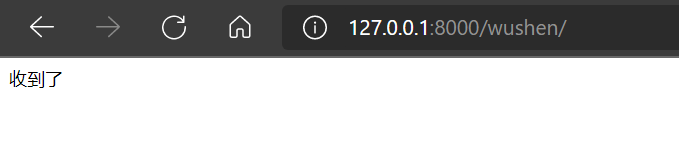
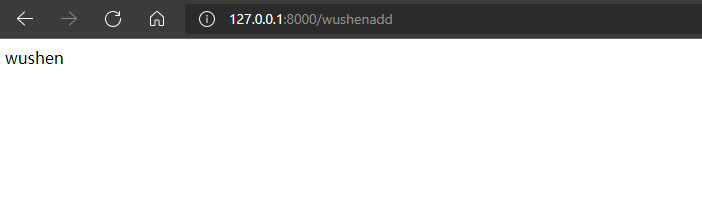
当匹配wushenadd的路由为:
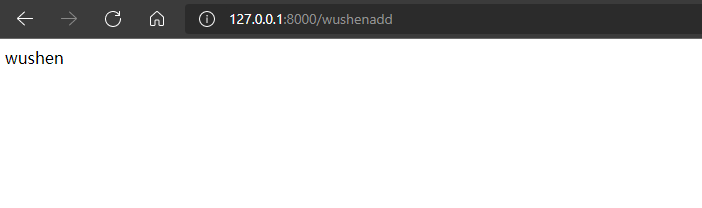
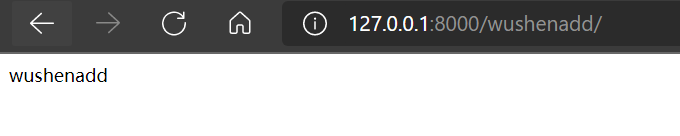
如果输入以下内容,也可以得到结果(正则表达式就一个wushen,里面有wushen就能匹配):
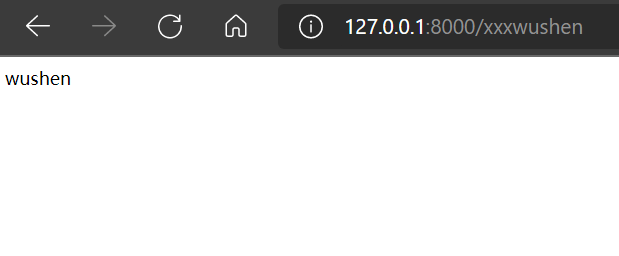
结论:由此得出路由从上往下一次匹配,路由一旦匹配就不再走下面路由匹配关系了
二.带/的匹配
当此时的代码为(在对用的路由后面加一个’/‘则可以阻止此类事情的发生):
urlpatterns = [
re_path(r'^$', views.home),
re_path(r'^wushen/', views.wushen),
re_path(r'^wushenadd/', views.wushenadd),
]
如图:
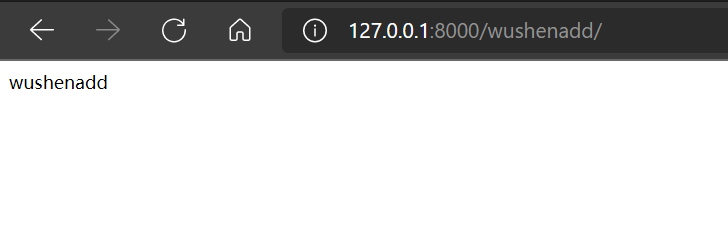
但是这样会出现另一种情况“在路由后面再添加一个还是可行的:
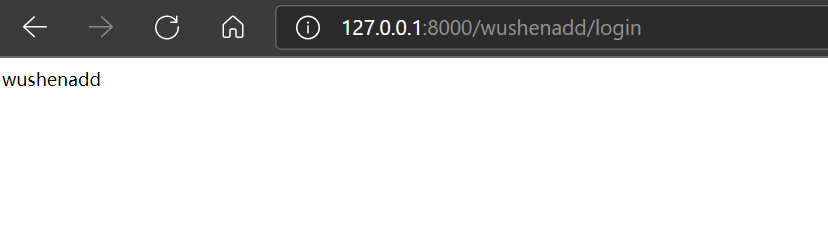
这时候可以在’/‘后面加一个$符号阻止这种情况
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^wushen/$', views.wushen),
re_path(r'^wushenadd/$', views.wushenadd),
]
如图:
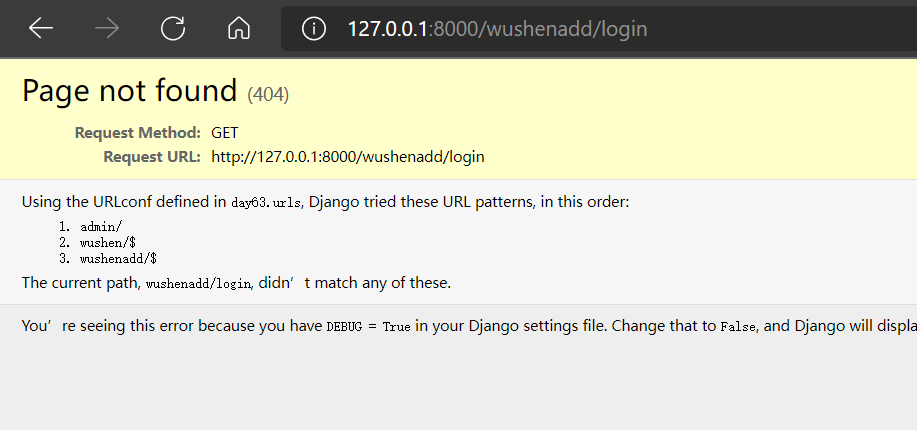
三.路由增加首页的方式and路由增加尾页的方式
1.增加首页
此时增加后的代码为(注意:$后面不要再添加‘/’):
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^$', views.home),
re_path(r'^wushen/$', views.wushen),
re_path(r'^wushenadd/$', views.wushenadd),
]
如图:
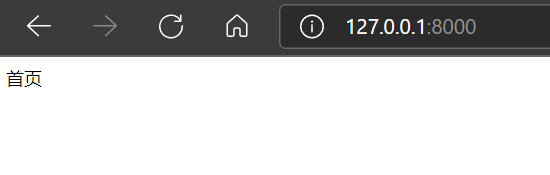
2.增加尾页
此时的代码为:
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^$', views.home),
re_path(r'^wushen/$', views.wushen),
re_path(r'^wushenadd/$', views.wushenadd),
re_path(r'', views.error)
]
如图:
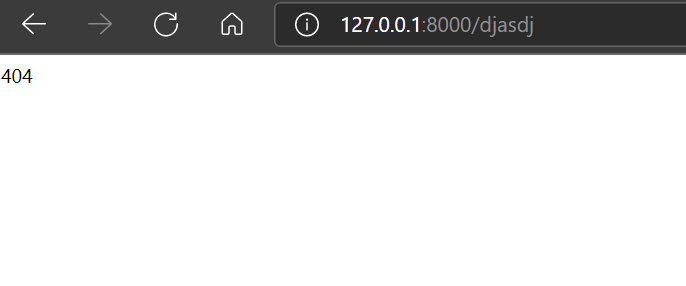

 浙公网安备 33010602011771号
浙公网安备 33010602011771号