

第七章学习小结
整理一下本章学到的知识
一、基本概念
列表:由同一类型的数据元素(或记录)构成的集合,可利用任意数据结构实现。
关键字:数据元素的某个数据项的值,用它可以标识列表中的一个或一组数据元素。如果一个关键字可以唯一标识列表中的一个数据元素,则称其为主关键字,否则为次关键字。 当数据元素仅有一个数据项时,数据元素的值就是关键字。
查找:根据给定的关键字值,在特定的列表中确定一个其关键字与给定值相同的数据元素,并返回该数据元素在列表中的位置。若找到相应的数据元素,则称查找是成功的,否则称查找是失败的,此时应返回空地址及失败信息,并可根据要求插入这个不存在的数据元素。
静态查找:在查找过程中只是对数据元素进行查找
动态查找:在实施查找的同时,插入找不到的元素,或从查找表中删除已查到的某个元素,即允许表中元素变化
平均查找长度(ASL):为确定数据元素在列表中的位置,需和给定值进行比较的关键字个数的期望值,称为查找算法在查找成功时的平均查找长度(ASL)。
由于查找算法的基本运算是关键字之间的比较操作,所以可用平均查找长度来衡量查找算法的性能。
二、基于线性表的查找
顺序表查找法:
顺序查找法的特点是,用所给关键字与线性表中各元素的关键字逐个比较,直到成功或失败。
存储结构通常为顺序结构,也可为链式结构。虽说顺序查找算法简单,但时间效率太低。
折半查找法:
先给数据排序(升序),形成有序表。将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表。如果中间位置记录的关键字大于查找关键字, 则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
分块查找法:
数据分成若干块,块内数据不必有序,但块间必须有序。
对索引表使用折半查找法(因为索引表是有序表);确定了待查关键字所在的子表后,在子表内采用顺序查找法(因为各子表内部是无序表)。
三、基于树表的查找:
二叉排序树
二叉排序树又称为二叉查找树,它是一种特殊的二叉树。
其定义为:二叉树排序树或者是一棵空树,或者是具有如下性质的二叉树:
(1)左子树的所有结点均小于根的值;
(2)右子树的所有结点均大于根的值;
(3)它的左右子树也分别为二叉排序树。
二叉排序树的存储结构同二叉树,使用二叉链表作为存储结构。
二叉排序树的创建
假若给定一个元素序列,我们可以利用逐个插入结点算法创建一棵二叉排序树。因此, 实现建立二叉排序树包括创建树与插入结点两个算法。
若二叉排序树是空树,则 key 成为二叉排序树的根
若二叉排序树非空,则将 key 与二叉排序树的根进行比较
如果 key 的值等于根结点的值,则停止插入
如果 key 的值小于根结点的值,则将 key 插入左子树
如果 key 的值大于根结点的值,则将 key 插入右子树。
二叉排序树的插入算法的时间复杂度为 O(log2n)。
二叉排序树的查找
若二叉排序树为空,则查找失败,否则,先拿根结点值与待查值进行比较:
若相等,则查找成功;若根结点值大于待查值,则进入左子树重复此步骤,否则进入右子树重复此步骤。
若在查找过程中遇到二叉排序树的叶子结点时,还没有找到待查结点,则查找不成功。
平衡二叉树(AVL树)
一棵平衡二叉排序树或者是空树,或者是具有下列性质的二叉排序树:
左子树与右子树的高度之差的绝对值小于等于1
左子树和右子树也是平衡二叉排序树。
引入平衡二叉排序树的目的,是为了提高查找效率,其平均查找长度为O(log2n)。
引入平衡因子(balancefactor)这一概念,其定义为:结点的左子树深度与右子树深度之差。
显然,对一棵平衡二叉排序树而言,其所有结点的平衡因子只能是-1、0、或1。当我们在一个平衡二叉排序树上插入一个结点时,有可能导致失衡,即出现平衡因子绝对值大于1。
四、哈希查找法
哈希表:即散列存储结构。
散列法存储的基本思想:建立关键码字与其存储位置的对应关系,或者说,由关键码的值决定数据的存储地址。查找速度极快(O(1)),查找效率与元素个数n无关!
哈希方法:选取某个函数,依该函数按关键字计算元素的存储位置,并按此存放;查找时,由同一个函数对给定值k计算地址,将k与地址单元中元素关键码进行比较,确定查找是否成功。
哈希函数:哈希方法中使用的转换函数称为哈希函数。
哈希表:按上述思想构造的表称为哈希表。
冲突:通常关键码的集合比哈希地址集合大得多,因而经过哈希函数变换后,可能将不同的关键码映射到同一个哈希地址上,这种现象称为冲突。
在哈希查找方法中,冲突是不可能避免的,只能尽可能减少。
所以,哈希方法必须制定一个好的解决冲突的方案:
主要有以下三种:
线性探测法
二次探测法
伪随机探测法
下面以二次探测法为例:
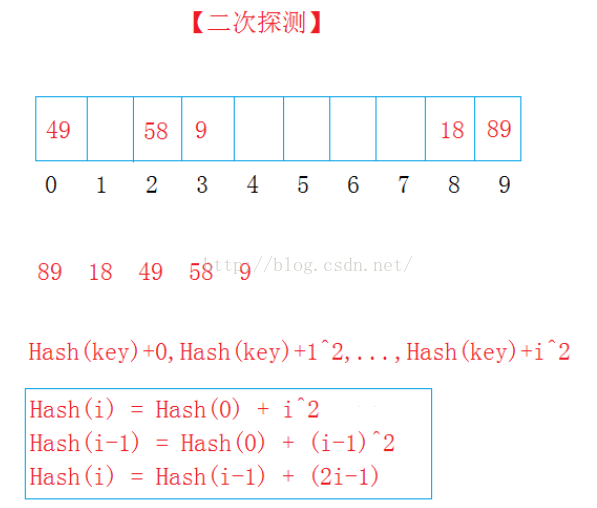
Hash(key) = key % 10(表长);
89放入9的位置;18放入8的位置;49与89冲突,加1^2,到0的位置;58与18冲突,加1^2,到了9的位置,有数继续加2^2到2的位置;9与89冲突,加1^2,在0的位置,继续加2^2,到3的位置放入。
Hash(key)+ i^2(i= 1、2、3……不算第一放入的数)
现在把PTA上的Hashing编程题摆上来:
The task of this problem is simple: insert a sequence of distinct positive integers into a hash table, and output the positions of the input numbers. The hash function is defined to be ( where TSize is the maximum size of the hash table. Quadratic probing (with positive increments only) is used to solve the collisions.
Note that the table size is better to be prime. If the maximum size given by the user is not prime, you must re-define the table size to be the smallest prime number which is larger than the size given by the user.
Input Specification:
Each input file contains one test case. For each case, the first line contains two positive numbers: MSize (≤) and N (≤) which are the user-defined table size and the number of input numbers, respectively. Then Ndistinct positive integers are given in the next line. All the numbers in a line are separated by a space.
Output Specification:
For each test case, print the corresponding positions (index starts from 0) of the input numbers in one line. All the numbers in a line are separated by a space, and there must be no extra space at the end of the line. In case it is impossible to insert the number, print "-" instead.
Sample Input:
4 4
10 6 4 15
Sample Output:
0 1 4 -
最开始是申请一个数组A[],对该数组进行初始化,全部赋值为0,之后通过散列映射到数组中去,若此时下标对应的值为0,则将其赋值为输入的值,若否之,则遍历正向的二次探测。若循环到TableSize时仍无法插入,则输出‘-’。
其中需要实现获取输入大于等于TableSize的最小素数的算法,思路是:先判断其是否为素数,否之则依次加一直至找到大于等于该值的最小素数。


#include <iostream> #include <math.h> using namespace std; int prime(int m)//验证一个数是不是素数 { if(m == 1) return 0; int i = 2, n; n = sqrt(m)+1; //n的平方数+1 while(i < n) { if(m%i==0) //整除,直接返回函数值0 return 0; i++; } if(i==n) //非整除退出循环,i肯定等于n return 1; } int GetNextPrime(int x) { //先判断是否为素数,不是则+1,以此循环 int i = x; while(1) { if(prime(i)) //若是素数,退出循环 break; i++; } return i; } int Hash(int key, int TableSize) { // 获取映射 return key % TableSize; } int main() { int TableSize, N, pos, tempos; cin >> TableSize >> N; TableSize = GetNextPrime(TableSize); int A[TableSize], Data[N]; for(int i=0; i<TableSize; i++)//先将A数组内所有值赋为0 A[i] = 0; for(int i=0; i<N; i++)//输入数值 cin >> Data[i]; for(int i=0; i<N; i++) { if(i != 0)//控制好空格的输出 cout << " "; pos = Hash(Data[i], TableSize); tempos = pos;//先将pos值付给tempos if(A[pos] == 0) {//如果未被访问 A[pos] = Data[i]; cout << pos; } else {//如果已被访问 int j, flag=0; for(j=1; j<TableSize; j++) { pos = Hash(tempos+j*j, TableSize); if(A[pos] == 0) { flag = 1;//做好标志 A[pos] = Data[i]; cout << pos; break; } } if(flag == 0) cout << "-"; } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号