[Active Learning] 01 主动学习简介
本文将简单介绍什么是主动学习(Active Learning,AL),为什么需要主动学习,主动学习和监督学习、弱监督学习、半监督学习、无监督学习之间是什么关系。最后再简单介绍主动学习的分类。(这里介绍的主动学习是机器学习的一个子领域。)
什么是主动学习?
主动学习(Active Learning),在统计学领域有时也叫“查询学习”(query learning)、“最优实验设计”(optimal experimental design),是机器学习的一个子领域。
主动学习背后一个关键的假设:
- 一个机器学习算法如果能够自行选择从哪些数据进行学习,通过较少的训练数据,它将表现得更好。
If the learning algorithm can choose the data from which it learns, it will perform better with less training.[1]
主动学习之所以叫主动学习,是因为算法从数据集中主动地选择一些不带标签的数据进行标注,而不是被动地选择。在每一次标注之后,模型重新或者增量地在带标签的数据上训练,然后再主动地选择不带标签数据进行标注,重复这个过程,这就是主动学习的流程。
主动学习 vs. 被动学习
被动学习(passive learning)被认为是从数据集中随机选择(randomly select)数据进行标注。
而主动学习选择要标注的样本时,有一些 criteria 进行指导,这就是主动学习和被动学习的区别。
不过被动学习似乎叫的不多,一般用 random selection 与主动学习的 criteria 比较就好。
为什么需要主动学习?
数据标注的成本高昂,迫使我们想要用更少的标注数据来获得更有效的模型,这就是主动学习产生的原因。
主动学习与监督学习、弱监督学习、半监督学习、无监督学习之间的关系
我们根据训练数据集标签的情况来划分这几者:(欢迎大佬指正)
- 监督学习(Supervised learning)任务中,数据集的标签都是完整而精确的。
- 无监督学习(Unsupervised learning)任务中,数据集是不含标签的。
- 弱监督学习(Weakly-supervised learning)任务中,数据集的标签分为三种情况:(这三种情况可能同时出现)
- 部分数据有标签,部分数据没有标签。一般有标签的数据占少数,大部分数据没有标签。(Incompelet supervison)
- 数据都有标签,但是标签的粒度不够。例如,在图像语义分割中,细粒度的标签应该是 pixel-level 的,但给出的标签仅仅是 image-level 的,这就是标签的粒度不够。(Inexact supervison)
- 数据都有标签,但是标签有很多错误。(Inaccurate supervison)

而主动学习对应弱监督学习的第一种情况,少部分数据含标签,但是大部分数据不含标签。
主动学习和半监督学习是什么关系?两者都可以认为是弱监督学习第一种情况的处理方式,但两者也有不一样的地方,比如主动学习需要人工标注数据,而半监督学习不要。
主动学习的种类
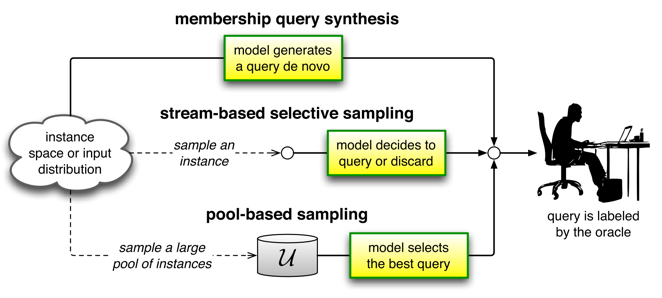
-
第二种是“steam-based selective sampling”,每一次我们能够从数据流得到一个 instance,然后判断其是否要送去 oracle 打标签。
-
第三种是“pool-based sampling”,初始时,我们就有很多 unlabeled data,只需要从这些 unlabeled data 中选择数据送到 oracle 打标签。(这种情况是最常见的。)
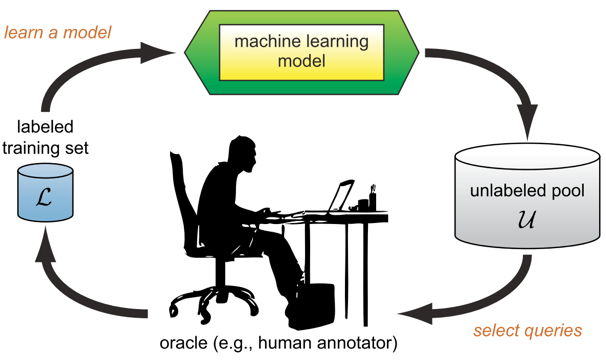
可能会有一个疑问,主动学习中的 oracle 是什么?oracle 可以是一个专家,打标签百分之百正确;也可以是很多拥有不同专业知识的人,打标签不是百分百对,如众包。
主动学习的一个例子
主动学习工具包 ALiPy
ALiPy (Active Learning in Python) [3] 是南京航空航天大学黄圣君老师做的一个开源的主动学习工具包,我们可以很轻松地基于该工具包开发主动学习的程序,强烈推荐。
ALiPy 主页:http://parnec.nuaa.edu.cn/huangsj/alipy/。
ALiPy GitHub:https://github.com/NUAA-AL/ALiPy。
主动学习相关博客
https://blog.csdn.net/Houchaoqun_XMU
References
[1] Burr Settles.(2009). Active Learning Literature Survey. Computer Sciences Technical Report 1648, University of Wisconsin-Madison.
[2] Zhou, Z.-H. (2018). A brief introduction to weakly supervised learning. National Science Review, 5(1), 44–53. https://doi.org/10.1093/nsr/nwx106
[3] Tang, Y.-P., Li, G.-X., & Huang, S.-J. (2019). ALiPy: Active Learning in Python, 1–5. Retrieved from http://arxiv.org/abs/1901.03802

 浙公网安备 33010602011771号
浙公网安备 33010602011771号