Lucene介绍
信息检索
从信息集合中找出与用户需求相关的信息。被检索的信息除了文本外,还有图像、音频、视频等多媒体信息,我们只讨论文本的检索。
信息检索分为:全文检索、数据检索、知识检索
全文检索
把用户的查询请求和全文中的每一个词进行比较,不考虑查询请求与文本语义上的匹配。在信息检索工具中,全文检索是最具通用性和实用性的。
知识检索:强调的是基于知识的、语义上的匹配
信息检索与数据库比较
- 匹配效果:ant搜索plant不应出现
2、查询结果没有相关度排序
3、数据库搜索速度慢
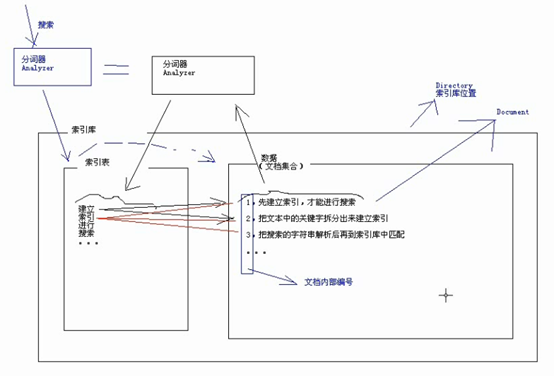
全文检索流程
首先从信息源中采集信息,加工(对信息集合中的信息建立一个索引,实质是分词器首先将文本进行分词,然后对词建立索引),放入信息集合(也叫索引库)。
查询时首先分词,然后在索引中查询,再从索引库中的文档集合中取出信息。
索引库由索引表也叫词汇表(存放索引(即每个词在哪些文档中出现,词和文档内部编号的对应关系))和数据(文档集合,每个文档都有一个"文档内部编号")
Lucene中:索引库是一组文件的集合,索引库的位置用Directory表示,可以是硬盘位置,也可以是内存位置。里面的每一条数据,是一个Document(即文档集合的每个文档)

Lucene
Lucene主页
Lucene配置和使用
1、添加jar包
lucene-core-2.9.4.jar
lucene-analyzers-2.9.4.jar
lucene-highlighter-2.9.4.jar
2、确定信息源和索引库的位置
如:

3、创建索引和搜索文档示例
HelloWorld.java内容
package com.citti.lucene.helloworld;
import java.io.IOException;
import junit.framework.TestCase;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import com.citti.lucene.utils.File2Document;
public class HelloWorld extends TestCase{
// 信息源的文件路径
private String filePath = "D:\\workspace\\wlw\\LuceneDemo1\\LuceneDatasource\\IndexWriter addDocument's javadoc.txt";
// 索引库位置
private String indexPath = "D:\\workspace\\wlw\\LuceneDemo1\\luceneIndex";
// 分词器
private Analyzer analyzer = new StandardAnalyzer();
/**
* 创建索引
* 操作索引用IndexWriter(增、删、改)
* @throws IOException
* @throws CorruptIndexException
*/
public void testCreateIndex() throws CorruptIndexException, IOException {
Document doc = File2Document.file2Docoument(filePath);
// file --> doc
IndexWriter indexWriter = new IndexWriter(indexPath, analyzer, true, MaxFieldLength.UNLIMITED);
// true表示每次都删除以前创建的索引,重新创建;没有该参数表示如果有就不创建,没有就创建;false表示不管有没有都不创建索引
// MaxFieldLength.LIMITED表示最多分出前10000个词,UNLIMITED表示没有限制分词个数,也可以是new MaxFieldLength(10000)等
indexWriter.addDocument(doc);
indexWriter.close();
}
/**
* 进行搜索
* 搜索用IndexSearcher
* @throws Exception
*/
public void testSearch() throws CorruptIndexException, Exception {
String queryString = "document";
// 1、把要搜索的文本解析为 Query
QueryParser queryParser = new MultiFieldQueryParser(new String[] {"name", "content"}, analyzer);
// 只在标题和内容中查询
Query query = queryParser.parse(queryString);
// 进行查询
IndexSearcher indexSearcher = new IndexSearcher(indexPath);
Filter filter = null;//过滤器,查询结果再进行过滤,比如某些机密的不让显示
TopDocs topDocs = indexSearcher.search(query, filter, 1000);// 10000表示一次查询1000个文档(默认50),用于提高效率
//打印结果,TopDocs包含了总条数和查询结果
System.out.println("总共包含【" + topDocs.totalHits + "】条记录");
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
int docSn = scoreDoc.doc; // 文档内部编号
Document doc = indexSearcher.doc(docSn); // 根据文档内部编号取出文档,类似于hibernate的get方法
File2Document.printDocumentInfo(doc);
}
}
}
File2Document.java内容
package com.citti.lucene.utils;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
public class File2Document {
// 文件:name, content, size, path
public static Document file2Docoument(String path) throws IOException {
File file = new File(path);
Document doc = new Document();
doc.add(new Field("name", file.getName(), Store.YES, Index.ANALYZED));
doc.add(new Field("content", readFileContent(file), Store.YES, Index.ANALYZED));
doc.add(new Field("size", String.valueOf(file.length()), Store.YES, Index.NOT_ANALYZED));
doc.add(new Field("path", file.getPath(), Store.YES, Index.NO));
// Stroe表示该字段是否存储(COMPRESS表示压缩之后再存;NO表示不存,例如某些pdf很大,不存可以节省空间)
// Index表示该字段是否建立索引
// NO:不建立索引,如网页的网址就只需要存,不需要建立索引
// 因为如果知道网址,就不需要搜索了,不会通过网址来搜索
// 进行索引分为"分词后索引(ANALYZED)"和"不分词直接索引(NOT_ANALYZED,把整个值当成一个关键词)"
// 例如yyyy-mm-dd的时间就不需要分词
return doc;
}
/**
* 读取文件内容
* @param file
* @return
* @throws IOException
*/
public static String readFileContent(File file) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
StringBuffer returnString = new StringBuffer();
for (String line = null; (line = reader.readLine()) != null; ) {
returnString.append(line);
}
return returnString.toString();
}
/**
* 打印文档内容
* @param doc
*/
public static void printDocumentInfo(Document doc) {
// Field f = doc.getField("name");
// System.out.println(f.stringValue());
System.out.println(doc.get("name"));
System.out.println(doc.get("content"));
System.out.println(doc.get("size"));
System.out.println(doc.get("path"));
}
}
Directory
Directroy表示索引库的位置,在
IndexWriter indexWriter = new IndexWriter(indexPath, analyzer, MaxFieldLength.UNLIMITED);
中,默认用indexPath创建了一个Directory,相当于
Directory directory = FSDirectory.getDirectory(indexPath);
IndexWriter indexWriter = new IndexWriter(directory, analyzer, MaxFieldLength.UNLIMITED);
FSDirectory和RAMDirectory
FSDirectory将索引放到文件,可以保存到硬盘
RAMDirectory将索引放到内存中,访问速度快
因此,一般是在程序启动时用FSDirectory读取磁盘索引,再放到RAMDirectory中,搜索时用RAMDirectory,速度快,程序退出时用FSDirectory保存到磁盘。
Directory fsDirectory = FSDirectory.getDirectory(indexPath);
//1、启动时读取
Directory ramDirectory = new RAMDirectory(fsDirectory);
//此时已经将硬盘索引读取到了ramDirectory中
//2、程序运行时操作ramDirectory
IndexWriter ramIndexWriter = new IndexWriter(ramDirectory, analyzer, MaxFieldLength.LIMITED);
//2.1、添加document
Document document = File2Document.file2Docoument(filePath);
ramIndexWriter.addDocument(document);
ramIndexWriter.close();//此处必须关闭,清空缓存
//3、退出时保存
IndexWriter fsIndexWriter = new IndexWriter(fsDirectory, analyzer, true , MaxFieldLength.LIMITED);
fsIndexWriter.addIndexesNoOptimize(new Directory[] {ramDirectory});
fsIndexWriter.close();
优化
fsIndexWriter.optimize();
//优化,合并文件,减少文件个数
分词器
英文分词
分词过程,,如
IndexWriter addDocument's a javadoc.txt
- 切分词
IndexWriter
addDocument's
a
javadoc.txt
2、排除停用词
IndexWriter
addDocument's
javadoc.txt
3、形态还原
IndexWriter
addDocument
javadoc.txt
4、转为小写
indexwriter
adddocument
javadoc.txt
中文分词
过程:切分词-排除停用词
单字分词
如:StandardAnalyzer
二分法分词
如:CJKAnalyzer
词典(词库)分词
如:MMAnalyzer(极易分词,需要加入je-analysis-1.5.3.jar)、庖丁分词
测试分词器
public class AnalyzerTest extends TestCase {
private String enText = "IndexWriter addDocument's javadoc.txt";
private String zhText = "中文分词测试";
private Analyzer en1 = new StandardAnalyzer();
private Analyzer en2 = new SimpleAnalyzer(); //这个分词器可以按照"."拆分,但没排除停用词
private Analyzer zh1 = new CJKAnalyzer(); // 二分法分词
private Analyzer zh2 = new MMAnalyzer(); // 词库分词(极易分词,需要加入je-analysis-1.5.3.jar)
public void test() throws Exception {
analyze(zh2, zhText);
}
public void analyze(Analyzer analyzer, String text) throws Exception {
System.out.println("分词器:" + analyzer.getClass());
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
for (Token token = null; (token = tokenStream.next()) != null;) {
System.out.println(token);
}
}
}
高亮器
高亮的作用:1、生成摘要信息。2、搜索文字高亮
用法:
public void testSearch() throws Exception{
String queryString = "绿色软件";
// 1、把要搜索的文本解析为 Query
QueryParser queryParser = new MultiFieldQueryParser(new String[] {"name", "content"}, analyzer);
// 只在标题和内容中查询
Query query = queryParser.parse(queryString);
// 进行查询
IndexSearcher indexSearcher = new IndexSearcher(indexPath);
Filter filter = null;//过滤器,查询结果再进行过滤,比如某些机密的不让显示
TopDocs topDocs = indexSearcher.search(query, filter, 1000);// 10000表示一次查询1000个文档(默认50),用于提高效率
//打印结果,TopDocs包含了总条数和查询结果
System.out.println("总共包含【" + topDocs.totalHits + "】条记录");
// 准备高亮器
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>", "</font>");//设置高亮的前缀和后缀
Scorer scorer = new QueryScorer(query);
Fragmenter fragmenter = new SimpleFragmenter(50);//设置显示多少个字符
Highlighter highlighter = new Highlighter(formatter, scorer);
highlighter.setTextFragmenter(fragmenter);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
int docSn = scoreDoc.doc; // 文档内部编号
Document doc = indexSearcher.doc(docSn); // 根据文档内部编号取出文档,类似于hibernate的get方法
// 高亮
String hc = highlighter.getBestFragment(new MMAnalyzer(), "content", doc.get("content"));
if (hc == null) {
// 如果内容中没有找到需要高亮文字,就截取前50个字符
hc = doc.get("content").substring(0, 50);
}
doc.getField("content").setValue(hc);
File2Document.printDocumentInfo(doc);
}
}
查询
Query的构建:
1、直接用字符串构建
String queryString = "绿色软件";
QueryParser queryParser = new MultiFieldQueryParser(new String[] {"name", "content"}, analyzer);
Query query = queryParser.parse(queryString);
查询对象构建的query.toSting()可以得到对应的查询字符串。
2、用TermQuery对象构建(关键词查询):
对应查询字符串:name:abc
Term term = new Term("name", "abc");
Query query = new TermQuery(term);
在name字段中搜索abc字符串,搜索的字符串全为小写,大写不可能搜索到。
3、用RangeQuery对象构建(范围查询):
对应查询字符串:size:[0000000000002s TO 000000000000dw]
Term lowerTerm = new Term("size", "100");
Term upperTerm = new Term("size", "500");
Query query = new RangeQuery(lowerTerm, upperTerm, true);
//true表示包含边界
默认都是字符串比较,例如200到1000之间不会包含500。
如果需要比较数字,需要用到NumberTools,搜索时:
Term lowerTerm = new Term("size", NumberTools.longToString(100));
Term upperTerm = new Term("size", NumberTools.longToString(500));
创建索引时:
doc.add(new Field("size", NumberTools.longToString(file.length()), Store.YES, Index.NOT_ANALYZED));
NumberTools转的数字是14位,它用36禁止存储,为了节省长度空间。第一位是正负号位。实际13位
DateTools.dateToString(new Date(), Resolution.Day));
可以转换日期,Resolution.Day表示精确到天
4、WildcardQuery构建(通配符查询)
对应查询字符串:content:绿*
PrefixQuery前缀查询也类似
/**
* 通配符查询
* ?代表1个,*代表0个或多个
*/
public void testWildcardQuery() throws Exception {
Term term = new Term("content", "绿*");
Query query = new WildcardQuery(term);
indexDao.search(query);
}
5、PhraseQuery构建(短语查询)
对应查询字符串:content:"? 因此 ? 需要"~5
/**
* 短语查询
* @throws Exception
*/
public void testPhraseQuery() throws Exception {
PhraseQuery phraseQuery = new PhraseQuery();
phraseQuery.add(new Term("content", "因此"), 1);
phraseQuery.add(new Term("content", "需要"), 3);
indexDao.search(phraseQuery);
}
其中1和3代表关键词的相对位置,中间间隔的关键词。例如有关键词的顺序是"因此"、"如果"、"需要",则可以查出结果。同10和12等等都一样。
如果去掉这个参数,变成:
phraseQuery.add(new Term("content", "因此"));
phraseQuery.add(new Term("content", "需要"));
则忽略位置关系,只要两个都有就会查出来。
如果加上:
phraseQuery.setSlop(5);
表示两个关键词之间相隔不到5个关键词才会查出来。
如果同时设置了相对位置参数,也有setSlop,则以setSlop为准
6、BooleanQuery(布尔查询(逻辑查询))
对应查询字符串:+content:绿* +content:"因此 需要"~5
Query query1 = new WildcardQuery(new Term("content", "绿*"));
PhraseQuery query2 = new PhraseQuery();
query2.add(new Term("content", "因此"));
query2.add(new Term("content", "需要"));
query2.setSlop(5);
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.add(query1, Occur.MUST);
booleanQuery.add(query2, Occur.MUST);
booleanQuery可以组合多个查询的逻辑关系,有
Occur.MUST(必须符合条件)、Occur.MUST_NOT(必须不符合条件)、OCCUR.SHOULD(符不符合都可以)三种
1、MUST和MUST,取交集
2、MUST和MUST_NOT,MUST的必须符合且MUST_NOT的必须不符合
3、SHOULD和SHOULD,取并集
特殊情况:
1、MUST和SHOULD,此时SHOULD相当于没有
2、MUST_NOT和MUST_NOT,无意义,检索无结果
3、MUST_NOT和SHOULD,此时SHOULD相当于MUST,变成了MUST和MUST_NOT
4、单独使用SHOULD,相当于MUST
5、单独使用MUST_NOT,无意义,检索无结果
排序
排序分为"相关度排序"和"自定义排序"
相关度排序
查询结果默认按照相关度(关键词出现的频率、位置等因素)计算得分,按相关度得分排序。
相关度排序中,可以指定boost(权重),分为
搜索时指定Field的boost
索引时指定Document的boost
默认boost都是1.0f
1、指定Field的boost
Map<String, Float> boosts = new HashMap<String, Float>();
boosts.put("name", 3f);
//boosts.put("content", 1.0f);//默认就是1.0f
QueryParser queryParser = new MultiFieldQueryParser(new String[] {"name", "content"}, analyzer, boosts);
2、指定Document的boost
Document doc = File2Document.file2Docoument(filePath);
doc.setBoost(3f);
自定义排序
按照某个字段进行排序,此时相关度排序就无效了
Sort sort = new Sort(new SortField("name"));//默认升序,false也是升序,true降序
//Sort sort = new Sort(new SortField("name", true));//降序
TopDocs topDocs = indexSearcher.search(query, filter, 1000, sort);
// 查询结果按照"name"字段值进行排序
过滤器
过滤器可以过滤查询结果(例如需要让一些机密的内容不显示),但它会极大降低效率,不建议使用。
Filter filter = new RangeFilter("size", "200", "1000", true, true);
//过滤器,查询结果再进行过滤,比如某些机密的不让显示,此处为查询size是200到1000的,后面两个逻辑类型分别表示是否包含下边界和上边界
TopDocs topDocs = indexSearcher.search(query, filter, 1000, sort);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号