
HashMap原理分析
数据存储方式和查询效率
内存数据的组织方式有很多,如:
- 数组:
采用开辟连续空间的方式存储。
优点:通过下标查询的时候可以计算出偏移量,立即定位到元素,查询速度很快。
缺点:
1:插入或删除元素时,往往需要移动元素位置,开销很大。
2:只有通过下标查询效率才高,如果需要通过元素内容查询,也需要遍历比较。(对于元素内容已经排序的数组,可以通过二分查找等方式提高效率,但避免不了比较)
思考:ArrayList是否通过这种方式存储,数组中存储的是什么,是不是对象引用?
- 链表
开辟非连续空间存储。
每一个元素额外存储下一个元素的地址(单向链表)。每一个元素额外存储下一个元素和上一个元素的地址(双向链表)
第一个元素的上一个元素地址为空,最后一个元素的下一个元素地址为空。
优点:插入或删除元素时,不需要移动其他元素位置,只需要修改链表下一个(上一个)元素地址即可,不需要连续的内存空间。
缺点:无论通过下标还是通过元素内容查找,都需要遍历比较。
- 采用哈希的方式。
为了让每次根据元素内容查询的时候不需要进行比较,必然需要查询时根据传入的内容直接找到存储地址,然后定位到存储地址一次性取出元素。而这个根据传入内容找存储地址的过程就是哈希算法,也叫散列算法,满足哈希查找的数据表也叫哈希表。这经常用在key-value存储的情况。
用公式表示就是:
存储地址=f(key)
f:哈希函数,key:查询的关键字
分为两步:
- 放入:将key-value表示的对象通过key做哈希算法算出一个地址,然后将value放到该地址。
2、查询,通过key查询时,用哈希算法算出一个地址,然后到该地址即可取出对应的value,不需要遍历比较。
ps:哈希算法不可逆,常用的有MD5、SHA-1等,存在碰撞问题。
java中hash表的应用
在java的Set、Map中这些容器中,需要快速根据key找到元素,如Set的contains方法,Map的get方法,都是通过key去查找。而这些容器确定元素唯一性都是通过回调元素的equals方法。
但这样每次都需要遍历所有元素去回调equals,效率很低。因此通常都用Hash的方式实现,如: HashSet、HashMap。
以HashSet为例(这里使用的是HashSet理想模型,并不是HashSet源码分析,实际上HashSet内部实现依赖了HashMap):
在HashSet中add元素时,它会回调元素的hashCode计算出位置,然后将元素放到该位置。查找元素时,它也会回调hashCode计算位置,到该位置上去找元素,如果找到,再回调equals看是否返回true,返回true就认为元素存在。HashMap的put和get也是同理,回调key的hashCode计算位置,存取value。
碰撞的处理:
HashSet存元素时,如果该位置已存在元素,则会将该位置的所有元素以单向链表的形式存放,取的时候遍历该链表,找到equals返回true的元素。HashMap也是同理。
所以最终确定元素唯一性的是equals方法,而hashCode方法是找元素位置。但如果hashCode不相同,即使equals返回ture也认为是不同元素,因为hashCode是找元素的第一步,没有找到就没机会调用equals了。
hashCode和equals
在Object中默认的hashCode返回的是根据对象的地址计算出的唯一数字,每个对象一个。
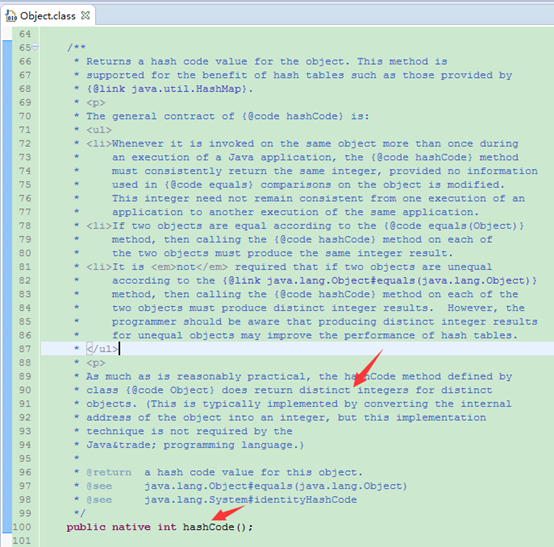
而默认的equals方法则是比较对象地址是否相等,也就是是否同一个对象。
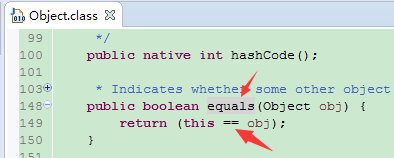
这样Object的hashCode跟equals其实是等价的,只有同一个对象的hashCode才相等,并且equals返回true。
因此如果重写了equals方法,让不同对象也可能equals,则需要重写hashCode,保证equals返回ture时,hashCode也相等。
如果2个对象equals返回了true,而hashCode没有重写,则会使用的默认的Object提供的那个,也就是每个对象的hashCode都不同。而在HashSet、HashMap中会首先去比较hashCode,发现不同,则认为不是同一个元素,而实际上他们是equals的。
如:

虽然2个对象equals,但HashSet却把它们当成了不同元素,存了2个,因为它会先调用hashCode去找元素。
重写hashCode后的效果:
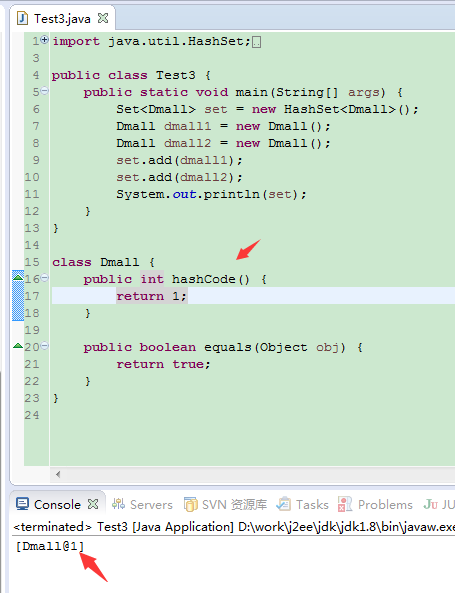
hashCode相同,equals也返回true,才认为是同一个元素。
但仅仅这样做还不够,因为hashCode即使不同,在Set或者HashMap内部的元素数组中也可能在同一个位置,因而需要在equals里面也加入对hashCode的判断
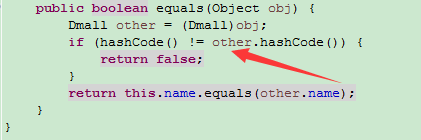
通常重写equals方法后,考虑重写hashCode都是对equals内部的元素进行分组,如:

这里hashCode是equals的基础。
只有name长度的奇偶性相同,2个name才有可能相同。也就是如果name相同,则name长度的奇偶性一定相同。
反之name长度的奇偶性不同,2个name就不可能相同。(一个奇数不可能等于一个偶数)。
HashMap原理
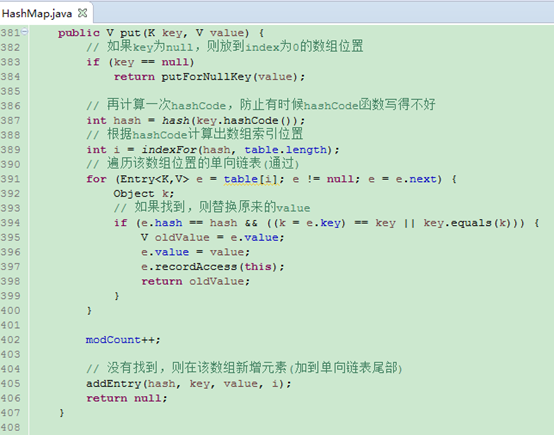
HashMap也是用上述原理,它内部会维护一个数组,在put元素时,会回调hashCode取得数字,然后将该数字转换为数组索引,将元素的key、value封装成一个Entry对象放到对应数组位置上,如果该位置已经存在元素,则比较key的equals,如果相同,则覆盖原Entry,如果不相同,则放到该单项链表的尾部。可见HashMap是采用了数组+单向链表组合的方式存储数据。
get时,也是先通过回调hashCode,在转换为数组索引找元素,遍历该位置的单项链表取出Entry。
构造函数初始化
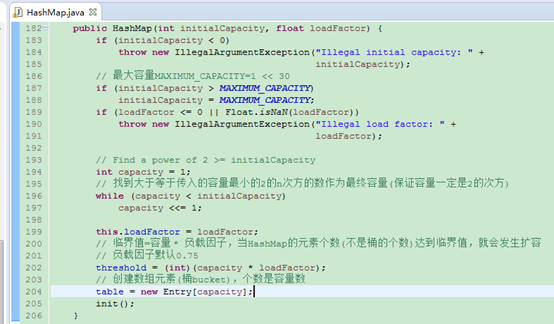
初始分配容量指分配数组元素(桶)的个数,默认是16.
size: HashMap的所有元素个数
threshold :临界值,HashMap的元素个数(不是桶的个数,桶的个数是固定的)达到临界值,需要扩容。
loadFactor:负载因子:0.75,是个经验值。
modCount:修改次数,HashMap被修改或者删除的次数总数,通常用在多线程并发判断脏数据的情景。
Entry:实体,HashMap存储对象的实际实体,由Key,value,hash,next组成。
HashMap的hash方法
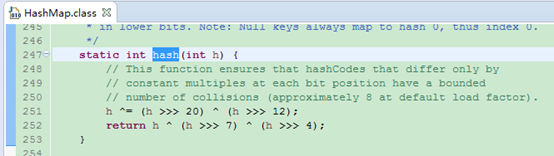
通过一系列位运算最大程度打散原信息。使用它的最大意义在于,如果对象的原hashCode被用户重写,并且只有几个固定的返回值,则直接用indexFor计算出来的位置也会是固定的几个,会导致分配不均,严重影响性能。这里再hash打散一次,会分配更均匀。
参考:String的hashCode实现:
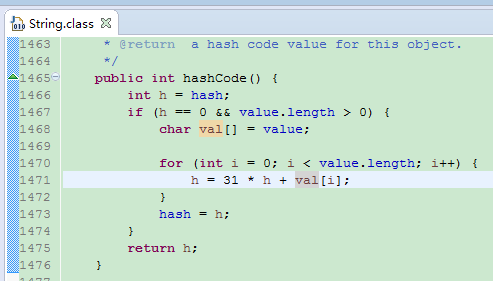
字符串为空串时,value.length=0,hashCode()也返回0.
字符串内部存了一个int hash默认为0,第1次调用会计算hash赋值给它,以后就直接取,不再重新计算。
计算hash的方法是通过遍历字符串的每个字符,取出ASCII码参与计算,如:
for循环每次h的值:
第1次循环:h = val[0];
第2次循环:h = val[0] * 31 + val[1]
第3次循环:h = (val[0] * 31 + val[1]) * 31 + val[2]= val[0] * 31^2 + val[1] * 31 + val[2]
第4次循环:h = val[0] * 31^3 + val[1] * 31^2 + val[2] * 31 + val[3]
归纳出来就是:
h = val[0]*31^(n-1) + val[1]*31^(n-2) + ... + val[n-1]
也就是:
h = s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
(这里的^不是异或,而是次方)
用常数31的原因是31 * i = 32 * i - i = (i << 5) – i,这样计算起来比较快。
引用:
31一个奇素数,如果它做乘法溢出的时候,信息会丢失,可以最大程度的打散原信息。
indexFor方法
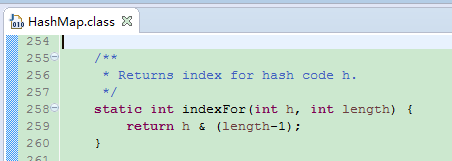
由于length只能是2的n次方减1,因此length-1的二进制一定是一个高位全0,低位全1的形式。
在和h做与运算时,h的高位全返回0,低位全返回h的原数。因此h & (length -1)一定小于等于length-1,大于等于0,正好是数组的下标范围。而且此时它其实就是h % length。
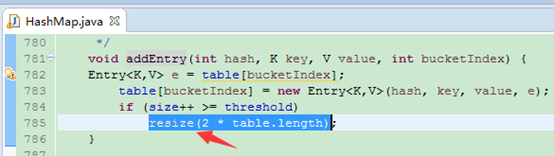
put操作
get操作
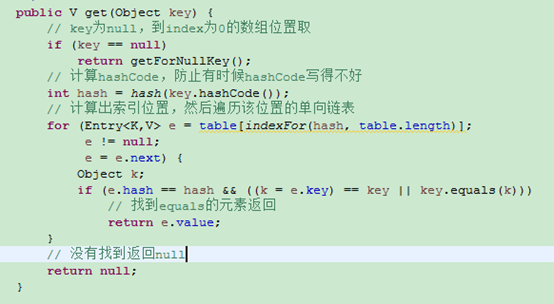
get这里存在并发问题,如果一个线程在get,另一个线程删除了元素,就会导致死循环。
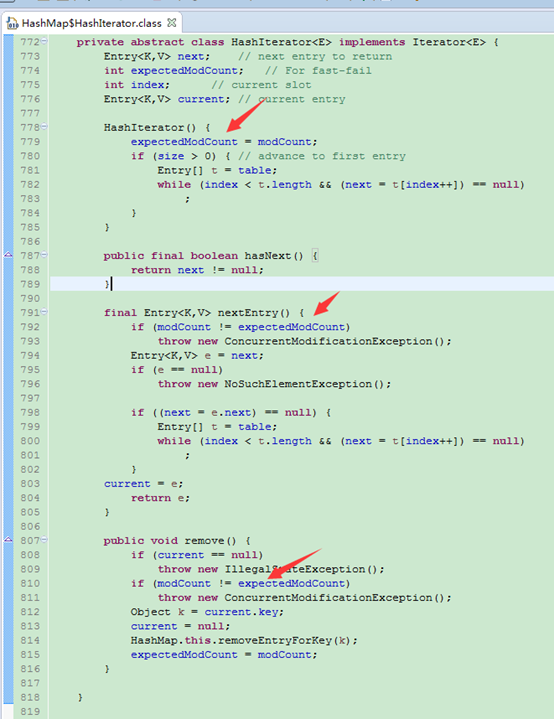
modCount的判断
modCount记录修改次数,用在多线程并发时判断原对象有没有改动,如Iterator中,当有改动时,抛出ConcurrentModificationException异常:
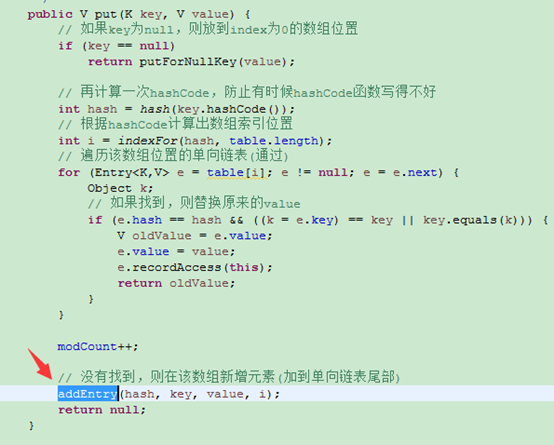
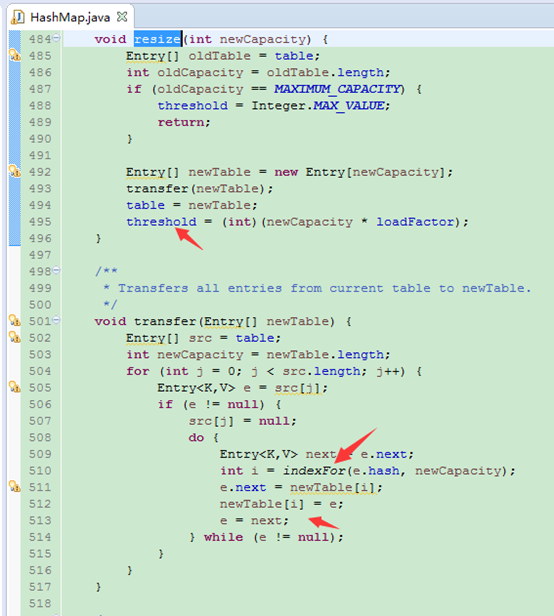
HashMap的扩容
当数组元素达到临界值,就会调用resize扩容,扩容为原数组长度2倍。此时会重新计算新的临界值,遍历原数据重新调用indexFor计算新位置放入。(由于需要重新放元素,因此扩容是有一定开销的,在初始化HashMap时指定合适的初始容量是很有必要的)
HashMap的size
hashMap不实时计算size,而是维护了一个变量,当增加或删除元素时,修改它的值(空间换时间的做法),因此是线程不安全的。
HashMap测试实验
Country.java:
import java.util.HashMap;
/**
* Country
* @author Administrator
*
*/
public class Country {
String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Country(String name) {
this.name = name;
}
@Override
public int hashCode() {
// 根据name属性长度的奇偶性返回2个不同hashCode
if (this.name.length() % 2 == 0) {
return 35;
}
else {
return 95;
}
}
@Override
public boolean equals(Object obj) {
// name相同的Country就认为是同一个元素
// (这里没有判断hashCode,因为name相同,name长度的奇偶性必定相同)
Country other = (Country) obj;
if (name.equals((other.name))) {
return true;
}
return false;
}
public static void main(String[] args) {
Country india = new Country("India");
Country japan = new Country("Japan");
Country france = new Country("France");
Country russia = new Country("Russia");
HashMap<Country, String> countryCapitalMap = new HashMap<Country, String>();
countryCapitalMap.put(india, "india");
countryCapitalMap.put(japan, "japan");
countryCapitalMap.put(france, "france");
countryCapitalMap.put(russia, "russia");
System.out.println("end");
}
在这一行打断点
System.out.println("end");
观察countryCapitalMap
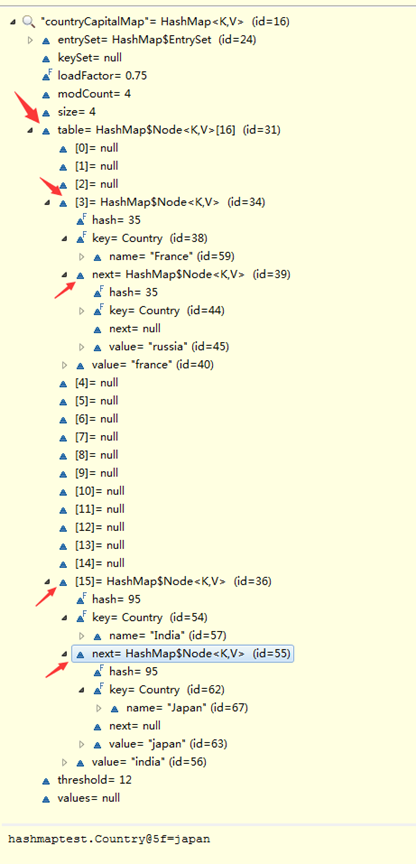
可以发现
1、HashMap内部的元素数组名是table,它默认有16个元素。
其中France、russia放在第3号位置,Japan、india放在第15号位置。
2、由于France、russia的字母个数都是6个,根据hashCode函数计算出的值都是35,因此它们的元素位置必定相同。同理,Japan、india都是5个字母,hashCode都是95,计算出的元素位置相同。

3、在india、japan的单向链表中,india在表头,japan在表尾,因为india比japan先加入。同理,france在表头而russia在表尾。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号