
Elasticsearch(ES)实战
介绍
elasticsearch是elastic下的一个产品。
引用:
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
elastic官网:https://www.elastic.co/cn/
elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch
es跟数据库的对应关系
indices->多个数据库
index->索引库,对应mysql的数据库
type->类型,对应mysql的表
field->column列
document->record一条数据
mappings->字段的属性(字段类型等)
与mysql不同,es一个index库里只能有一个type(表),而且后面版本已经移除了type的概念,index相当于表的概念了。
es默认都有分片和副本,即使只有一个节点,也会有分片和副本。
安装:
es服务器安装
es运行需要jdk1.8以上版本。
下载、解压
地址:
https://www.elastic.co/cn/downloads/elasticsearch
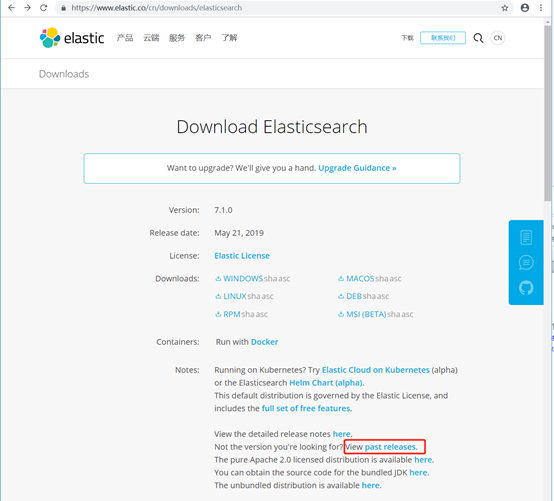
点红框处下载历史版本。
本文档使用6.4.2版本做测试。下载zip包,然后解压
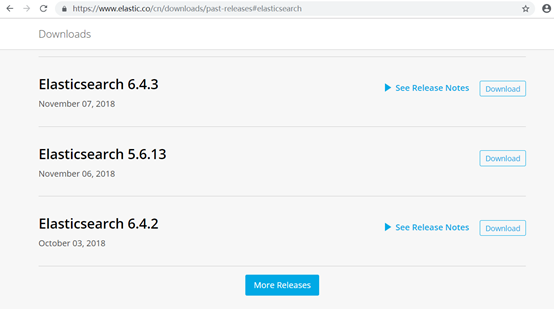
2、启动
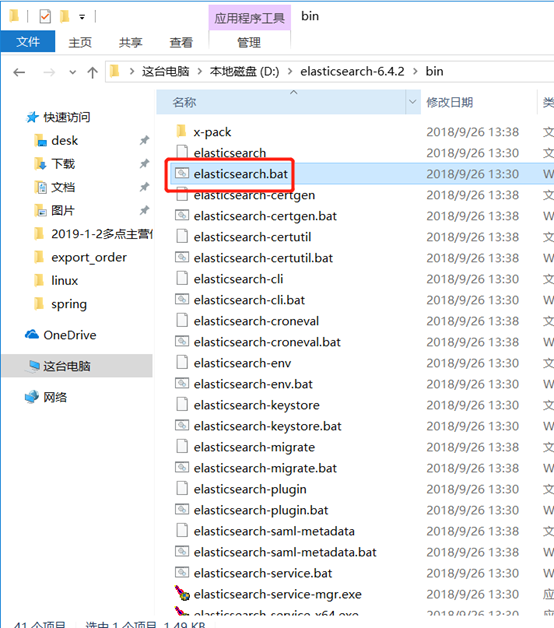
双击elasticsearch-6.4.2/bin/elasticsearch.bat启动
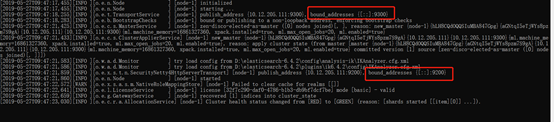
自动绑定了9200和9300端口。
9200:web访问
9300:java访问。
3、测试访问
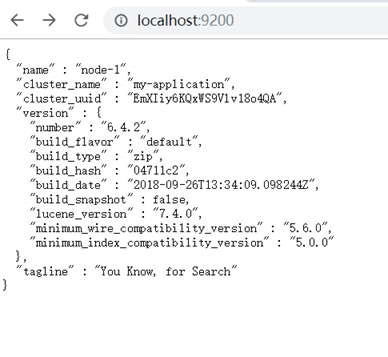
安装head插件
Elasticsearch-head插件是一款es客户端工具,它提供了界面操作es。类似于navicat的mysql客户端工具,不过head是以插件的方式使用的,而不是独立软件工具。
安装head插件需要首先安装nodejs、grunt,然后用grunt命令运行。
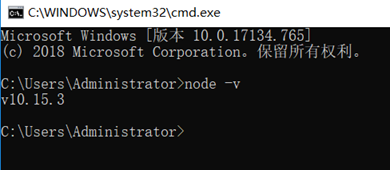
1、安装nodejs
到https://nodejs.org/en/download/下载安装。
装完后node –v可以查看版本号
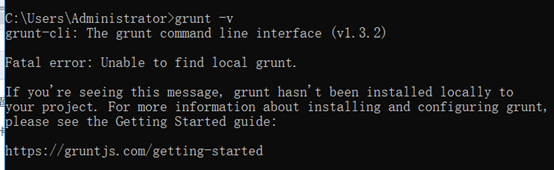
2、安装grunt
执行:
npm install -g grunt-cli
命令安装

安装完成后执行grunt -version查看是否安装成功
3、配置es的节点信息
es主目录的elasticsearch-6.4.2/config/ elasticsearch.yml
文件最后增加:
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
network.host: 0.0.0.0
cluster.name: my-application
node.name: node-1
http.port: 9200
其中后面4个配置是配置文件中已有的,用#注释掉的,配置的时候注意看是有已经被取消注释,不要重复配置。
4、下载head插件,修改配置
https://github.com/mobz/elasticsearch-head
下载zip,解压
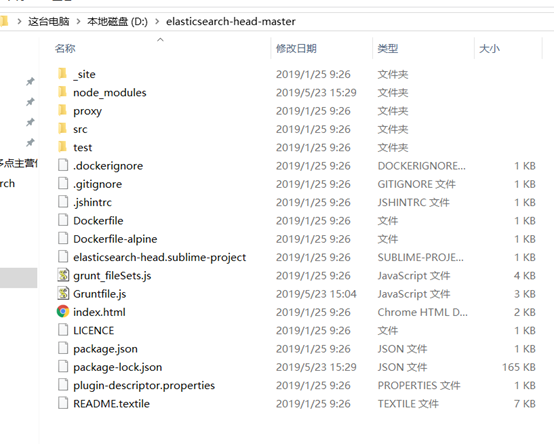
对应位置增加hostname:'*',
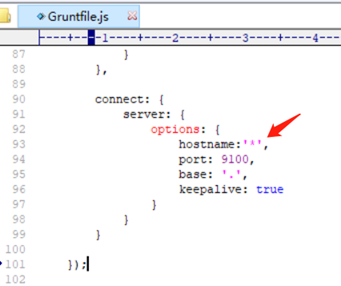
这可以使用的9100端口
5、启动插件:
重启es,然后进入到head主目录,执行grunt server
cd D:\elasticsearch-head-master
grunt server
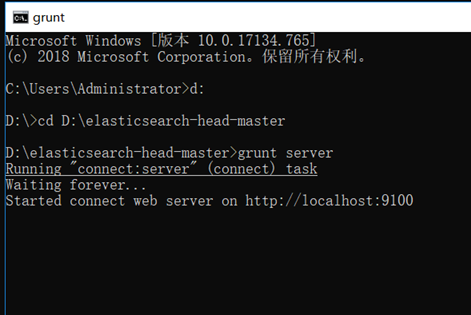
如果运行不成功可以重新安装grunt再试试。
6、访问测试:
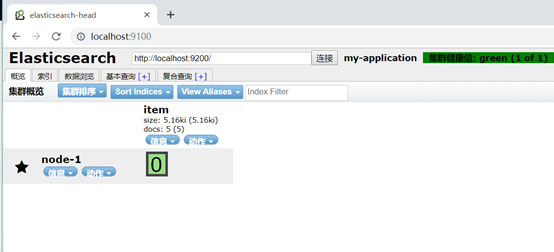
安装IK分词器
es默认的分词器效果很差,可以使用IK分词器。
1、下载:
https://github.com/medcl/elasticsearch-analysis-ik/releases
注意:分词器跟es版本必须一致,否则无法使用。
2、解压,重命名成ik6.4.2,放到elasticsearch-6.4.2/plugins目录下
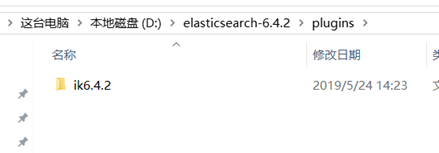
3、重启es
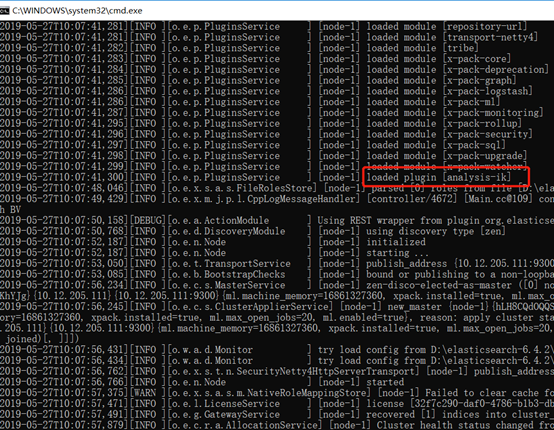
启动日志可以看出分词器插件加载情况
整合spring boot:
java客户端原生可以操作es,不过比较不方便,使用spring boot提供的spring data elasticsearch操作,方便很多。
官网:
https://spring.io/projects/spring-data-elasticsearch
文档地址
配置:
1、创建spring boot工程,加入es依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2、application.yml配置:
spring:
data:
elasticsearch:
cluster-name: my-application
cluster-nodes: 127.0.0.1:9300
其中的配置跟es的config/elasticsearch.yml里面的配置对应
3、创建实体类Item.java
package com.example.demo.domain;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Document(indexName = "item",type = "docs", shards = 1, replicas = 0)
public class Item {
/**
* @Description: @Id注解必须是springframework包下的
* org.springframework.data.annotation.Id
*/
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title; //标题
@Field(type = FieldType.Keyword)
private String category;// 分类
@Field(type = FieldType.Keyword)
private String brand; // 品牌
@Field(type = FieldType.Double)
private Double price; // 价格
@Field(index = false, type = FieldType.Keyword)
private String images; // 图片地址
public Item() {
}
public Item(Long id, String title, String category, String brand, Double price, String images) {
this.id = id;
this.title = title;
this.category = category;
this.brand = brand;
this.price = price;
this.images = images;
}
public Long getId() {
return id;
}
@Override
public String toString() {
return "Item{" +
"id=" + id +
", title='" + title + '\'' +
", category='" + category + '\'' +
", brand='" + brand + '\'' +
", price=" + price +
", images='" + images + '\'' +
'}';
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
public String getImages() {
return images;
}
public void setImages(String images) {
this.images = images;
}
}
其中@Document(indexName = "item",type = "docs", shards = 1, replicas = 0)
定义了索引名(库名)为item,类型名(表名)为docs,分片数1,副本数0
@Id表示主键id,跟mysql的类似,更新记录的时候可以根据id更新
@Field(type = FieldType.Keyword)表示字段,
其中的type是个枚举:
(以下说明引用自其他文章):
type:字段类型,是枚举:FieldType,可以是text、long、short、date、integer、object等
text:存储数据时候,会自动分词,并生成索引
keyword:存储数据时候,不会分词建立索引
Numerical:数值类型,分两类
基本数据类型:long、interger、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
index:是否索引,布尔类型,默认是true
store:是否存储,布尔类型,默认是false
analyzer:分词器名称,这里的ik_max_word即使用ik分词器
4、创建Repository类ItemRepository.java,继承ElasticsearchRepository
package com.example.demo;
import com.example.demo.domain.Item;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
List<Item> findByPriceBetween(double price1, double price2);
}
这里继承了ElasticsearchRepository。
其中定义的方法findByPriceBetween是为了测试between的自定义查询的,关于自定义查询,参见下面"常规操作"中的自定义查询部分。
使用时注入ItemRepository即可。
常用操作
ElasticsearchRepository继承树:
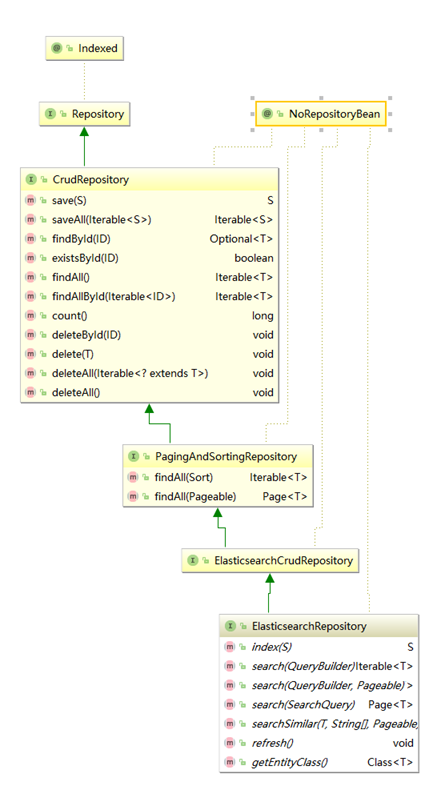
CrudRepository提供了基本crud操作方法,ElasticsearchRepository提供了强大的search方法。
测试文件源码:

1、创建index
/**
* 创建索引,会根据Item类的@Document注解信息来创建
*/
@Test
public void testCreateIndex() {
elasticsearchTemplate.createIndex(Item.class);
}
效果:
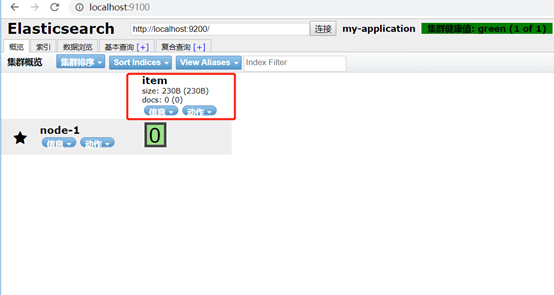
创建了索引,名为item,docs数量为0,即还没有记录。
2、删除index
/**
* 删除索引
*/
@Test
public void testDeleteIndex() {
elasticsearchTemplate.deleteIndex(Item.class);
}
3、新增或更新数据
/**
* 新增或更新数据
*/
@Test
public void insert() {
Item item = new Item(1L, "小米手机7", " 手机",
"小米", 3499.00, "http://image.baidu.com/13123.jpg");
item.setTitle(null);
item.setCategory(null);
itemRepository.save(item);
}
id不存在,则新增; id已存在,则更新
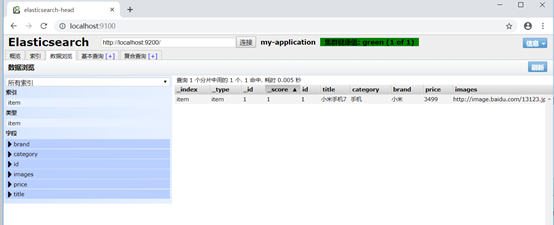
界面查看;
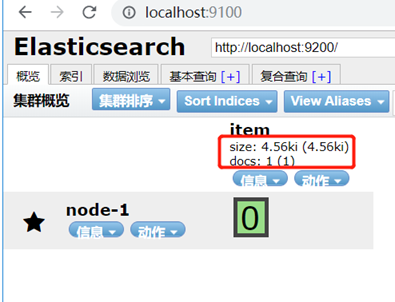
_
4、批量新增或更新数据
/**
* 批量新增或更新数据
*/
@Test
public void insertList() {
List<Item> list = new ArrayList<>();
list.add(new Item(2L, "坚果手机R1", " 手机", "锤子", 3699.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(3L, "华为META10", " 手机", "华为", 4499.00, "http://image.baidu.com/13123.jpg"));
// 接收对象集合,实现批量新增
itemRepository.saveAll(list);
}
5、删除数据
/**
* 删除数据
*/
@Test
public void delete() {
Item item = new Item();
item.setId(1L);
itemRepository.delete(item); // 也是根据id删除。
// 也有以下几种删除方式
// itemRepository.deleteById(1L);
// itemRepository.deleteAll();
// itemRepository.deleteAll(iterable);
}
6、findAll查询(排序)
/**
* findAll查询(排序)
*/
@Test
public void testQueryAll() {
// 按price降序
Iterable<Item> list = this.itemRepository.findAll(Sort.by("price").descending());
for (Item item : list) {
System.out.println(item);
}
}
7、自定义查询(如:between查询)
在自己写的Repoitory接口中自定义方法,只要符合命名规则,就可以被自动实现,如:
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
List<Item> findByPriceBetween(double price1, double price2);
}
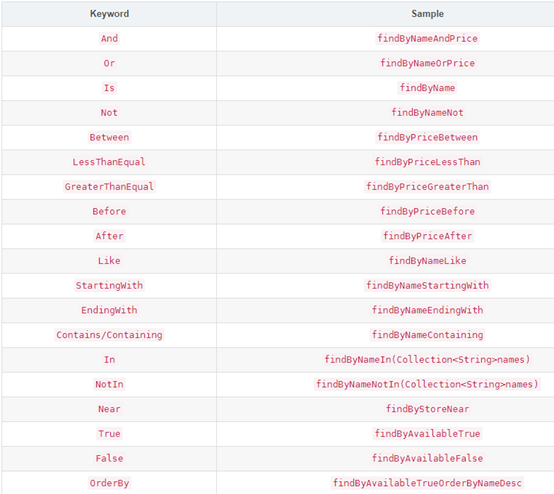
测试自定义between查询:
/**
* 自定义查询(如:between查询)
*/
@Test
public void queryByPriceBetween() {
List<Item> list = this.itemRepository.findByPriceBetween(3500.00, 4300.00);
for (Item item : list) {
System.out.println("item = " + item);
}
}
查询price在3500到4300之间的记录
输出:

search查询
1、search的matchQuery查询
以下示例都用如下数据:
itemRepository.deleteAll();
List<Item> list = new ArrayList<>();
list.add(new Item(1L, "小米手机7", "手机", "小米", 3299.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(2L, "坚果手机R1", "手机", "锤子", 3699.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(3L, "华为META10", "手机", "华为", 4499.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(4L, "小米Mix2S", "手机", "小米", 4299.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(5L, "荣耀V10", "手机", "华为", 2799.00, "http://image.baidu.com/13123.jpg"));
// 接收对象集合,实现批量新增
itemRepository.saveAll(list);
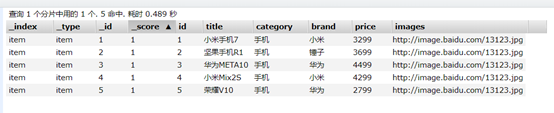
/**
* search的matchQuery查询
*/
@Test
public void testMatchQuery() {
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本分词查询
queryBuilder.withQuery(QueryBuilders.matchQuery("title", "小米手机"));
// 搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 总条数
long total = items.getTotalElements();
System.out.println("total = " + total);
for (Item item : items) {
System.out.println(item);
}
}
输出:
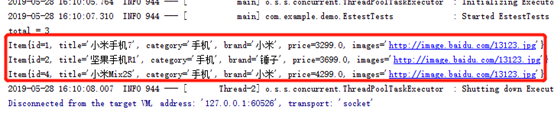
记录在存储到es的时候,title就已经被分词器拆分成单个词存下来,如"小米手机"被拆成"小米"和"手机"2个单词。
使用matchQuery查询时,查询传入的字符串"小米手机"也会首先被分词,这里"小米手机"被分成了"小米"和"手机"2个词,然后到5条记录的分词结果里进行匹配有"小米"或者"手机"的记录,最终匹配到了3条
2、search的termQuery查询
/**
* search的termQuery查询
*/
@Test
public void testTermQuery() {
// 创建对象
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 在queryBuilder对象中自定义查询
//matchQuery:底层就是使用的termQuery
queryBuilder.withQuery(QueryBuilders.termQuery("title", "小米手机"));
//查询,search 默认就是分页查找
Page<Item> page = this.itemRepository.search(queryBuilder.build());
//获取数据
long totalElements = page.getTotalElements();
System.out.println("获取的总条数:" + totalElements);
for (Item item : page) {
System.out.println(item);
}
}
结果:
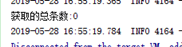
termQuery的不同之处在于,不会对传入的字符串再进行分词,直接将它作为分词结果去匹配,而5条记录里的title分词结果没有"小米手机",只有"小米"和"手机",因此匹配不到记录,这里如果传入"小米"或者"手机"就能匹配到记录。
matchQuery的底层也是termQuery实现的,只不过对传入查询字符先分词,然后每个单词都才用termQuery去匹配,最后合并查询结果返回。
3、search的booleanQuery查询
BooleanQuery有must、mustNot、should,如果有多个子条件,它会把所有should放到一起作为or,然后把所有must、mustNot作为必须条件。如:
/**
* search的booleanQuery查询
*/
@Test
public void testBooleanQuery() {
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withQuery(
QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("title", "b"))
.mustNot(QueryBuilders.matchQuery("category", "c"))
.should(QueryBuilders.matchQuery("brand", "d"))
.should(QueryBuilders.matchQuery("price", 5d))
);
// 相当于
// (brand = 'd' or price = 5d) and title = 'b' and category != 'c'
//获取数据
Page<Item> page = this.itemRepository.search(builder.build());
long totalElements = page.getTotalElements();
System.out.println("获取的总条数:" + totalElements);
for (Item item : page) {
System.out.println(item);
}
}
4、search的FuuzyQuery模糊查询
/**
* search的FuuzyQuery模糊查询
*/
@Test
public void testFuzzyQuery() {
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withQuery(QueryBuilders.fuzzyQuery("title", "小米"));
Page<Item> page = this.itemRepository.search(builder.build());
long totalElements = page.getTotalElements();
System.out.println("获取的总条数:" + totalElements);
for (Item item : page) {
System.out.println(item);
}
}
5、search的分页查询
/**
* search的分页查询
*/
@Test
public void searchByPage() {
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机"));
// 分页:
int page = 0;
int size = 2;
queryBuilder.withPageable(PageRequest.of(page, size));
// 搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 总条数
long total = items.getTotalElements();
System.out.println("总条数 = " + total);
// 总页数
System.out.println("总页数 = " + items.getTotalPages());
// 当前页
System.out.println("当前页:" + items.getNumber());
// 每页大小
System.out.println("每页大小:" + items.getSize());
for (Item item : items) {
System.out.println(item);
}
}
输出:

6、search的排序查询
/**
* search的排序查询
*/
@Test
public void searchAndSort() {
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机"));
// 排序
queryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.ASC));
// 搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 总条数
long total = items.getTotalElements();
System.out.println("总条数 = " + total);
for (Item item : items) {
System.out.println(item);
}
}
输出:

返回结果按price升序排列。
7、search的聚合查询
/**
* search的聚合查询(如:按照品牌brand进行分组)
*/
@Test
public void testAgg() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(AggregationBuilders.terms("brands").field("brand"));
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List<StringTerms.Bucket> buckets = agg.getBuckets();
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称和桶中的文档数量
System.out.println(bucket.getKeyAsString() + ":" + bucket.getDocCount());
}
}
输出:

8、search的嵌套聚合,求平均值
/**
* search的嵌套聚合,求平均值
*/
@Test
public void testSubAgg() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms("brands").field("brand")
.subAggregation(AggregationBuilders.avg("priceAvg").field("price")) // 在品牌聚合桶内进行嵌套聚合,求平均值
);
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List<StringTerms.Bucket> buckets = agg.getBuckets();
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称 3.5、获取桶中的文档数量
System.out.println(bucket.getKeyAsString() + ",共" + bucket.getDocCount() + "台");
// 3.6.获取子聚合结果:
InternalAvg avg = (InternalAvg) bucket.getAggregations().asMap().get("priceAvg");
System.out.println("平均售价:" + avg.getValue());
}
}
输出:
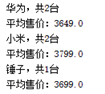
9、指定返回字段
可以指定返回哪些Field,不返回的都是null,如:
/**
* 指定返回字段
*/
@Test
public void searchReturnFields() {
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机"));
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{"title", "brand"}, new String[]{"title"}));
// 搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 总条数
long total = items.getTotalElements();
System.out.println("总条数 = " + total);
for (Item item : items) {
System.out.println(item);
}
}
输出:

这里使用了FetchSourceFilter构造返回字段的includes列表和excludes列表,
不在includes列表内或者在excludes列表内的field都不会返回。这里只返回了brand字段,其他都是null。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号