

RabbitMQ 存储机制
一、消息存储机制
不管是持久化的消息还是非持久化的消息都可以被写入到磁盘。持久化的消息在到达队列时就被写入到磁盘,非持久化的消息一般只保存在内存中,在内存吃紧的时候会被换入到磁盘中,以节省内存空间。这两种类型的消息的落盘处理都在 RabbitMQ 的“持久层”中完成。
持久层是一个逻辑上的概念,实际包含两个部分:
(1)队列索引(rabbit_queue_index)
rabbit_queue_index 负责维护队列中落盘消息的信息,包括消息的存储地点、是否已被交付给消费者、是否已被消费者 ack 等。每个队列都有与之对应的一个 rabbit_queue_index。
(2)消息存储(rabbit_msg_store)
rabbit_msg_store 以键值对的形式存储消息,它被所有队列共享,在每个节点中有且只有一个。
从技术层面上来说,rabbit_msg_store 具体还可以分为:
<1>msg_store_persistent:负责持久化消息的持久化,重启后消息不会丢失
<2>msg_store_transient:负责非持久化消息的持久化,重启后消息会丢失。
1. 消息存储
消息(包括消息体、属性和 headers)可以直接存储在 rabbit_queue_index 中,也可以被保存在 rabbit_msg_store 中。默认在 $RABBITMQ_HOME/var/lib/mnesia/rabbit@$HOSTNAME/ 路径下包含 queues、msg_store_persistent、msg_store_transient 这 3 个文件夹,其分别存储对应的信息(不同版本目录位置有所不同):

最佳的配备是较小的消息存储在 rabbit_queue_index 中而较大的消息存储在 rabbit_msg_store 中。这个消息大小的界定可以通过 queue_index_embed_msgs_below 来配置,默认大小为 4096,单位为 B。注意这里的消息大小是指消息体、属性及 headers 整体的大小。当一个消息小于设定的大小阈值时就可以存储在 rabbit_queue_index 中,这样可以得到性能上的优化。
rabbit_queue_index 中以顺序(文件名从 0 开始累加)的段文件来进行存储,后缀为“.idx”,每个段文件中包含固定的 SEGMENT_ENTRY_COUNT 条记录,SEGMENT_ENTRY_COUNT 默认值为16384。每个 rabbit_queue_index 从磁盘中读取消息的时候至少要在内存中维护一个段文件,所以设置 queue_index_embed_msgs_below 值的时候要格外谨慎,一点点增大也可能会引起内存爆炸式的增长。
经过 rabbit_msg_store 处理的所有消息都会以追加的方式写入到文件中,当一个文件的大小超过指定的限制(file_size_limit)后,关闭这个文件再创建一个新的文件以供新的消息写入。文件名(文件后缀是“.rdq”)从 0 开始进行累加,因此文件名最小的文件也是最老的文件。在进行消息的存储时,RabbitMQ 会在 ETS(Erlang Term Storage)表中记录消息在文件中的位置映射(Index)和文件的相关信息(FileSummary)。
2. 消息读取
在读取消息的时候,先根据消息的ID(msg_id)找到对应存储的文件,如果文件存在并且未被锁住,则直接打开文件,从指定位置读取消息的内容。如果文件不存在或者被锁住了,则发送请求由 rabbit_msg_store 进行处理。
3. 消息删除
消息的删除只是从 ETS 表删除指定消息的相关信息,同时更新消息对应的存储文件的相关信息。执行消息删除操作时,并不立即对在文件中的消息进行删除,也就是说消息依然在文件中,仅仅是标记为垃圾数据而已。当一个文件中都是垃圾数据时可以将这个文件删除。当检测到前后两个文件中的有效数据可以合并在一个文件中,并且所有的垃圾数据的大小和所有文件(至少有 3 个文件存在的情况下)的数据大小的比值超过设置的阈值 GARBAGE_FRACTION(默认值为 0.5)时才会触发垃圾回收将两个文件合并。
执行合并的两个文件一定是逻辑上相邻的两个文件。执行合并时首先锁定这两个文件,并先对前面文件中的有效数据进行整理,再将后面文件的有效数据写入到前面的文件,同时更新消息在 ETS 表中的记录,最后删除后面的文件。
二、队列结构实现
1. 队列结构
通常队列由两部分组成:
(1)rabbit_amqqueue_process
rabbit_amqqueue_process 负责协议相关的消息处理,即接收生产者发布的消息、向消费者交付消息、处理消息的确认(包括生产端的 confirm 和消费端的 ack)等。
(2)backing_queue
backing_queue 是消息存储的具体形式和引擎,并向 rabbit_amqqueue_process 提供相关的接口以供调用。
如果消息投递的目的队列是空的,并且有消费者订阅了这个队列,那么该消息会直接发送给消费者,不会经过队列这一步。而当消息无法直接投递给消费者时,需要暂时将消息存入队列,以便重新投递。
消息存入队列后,不是固定不变的,它会随着系统的负载在队列中不断地流动,消息的状态会不断发生变化。RabbitMQ 中的队列消息可能会处于以下4种状态:
(1)alpha:消息内容(包括消息体、属性和 headers)和消息索引都存储在内存中。
(2)beta:消息内容保存在磁盘中,消息索引保存在内存中。
(3)gamma:消息内容保存在磁盘中,消息索引在磁盘和内存中都有。
(4)delta:消息内容和索引都在磁盘中。
对于持久化的消息,消息内容和消息索引都必须先保存在磁盘上,才会处于上述状态中的一种。而 gamma 状态的消息是只有持久化的消息才会有的状态。
RabbitMQ 在运行时会根据统计的消息传送速度定期计算一个当前内存中能够保存的最大消息数量(target_ram_count),如果 alpha 状态的消息数量大于此值时,就会引起消息的状态转换,多余的消息可能会转换到 beta 状态、gamma 状态或者 delta 状态。区分这 4 种状态的主要作用是满足不同的内存和 CPU 需求。alpha 状态最耗内存,但很少消耗 CPU。delta 状态基本不消耗内存,但是需要消耗更多的 CPU 和磁盘 I/O 操作。delta 状态需要执行两次 I/O 操作才能读取到消息,一次是读消息索引(从 rabbit_queue_index 中),一次是读消息内容(从 rabbit_msg_store 中);beta和 gamma 状态都只需要一次 I/O 操作就可以读取到消息(从 rabbit_msg_store 中)。
对于普通的没有设置优先级和镜像的队列来说,backing_queue 的默认实现是 rabbit_variable_queue,其内部通过 5 个子队列 Q1、Q2、Delta、Q3 和 Q4 来体现消息的各个状态。整个队列包括 rabbit_amqqueue_process 和 backing_queue 的各个子队列:

其中 Q1、Q4 只包含 alpha 状态的消息,Q2 和 Q3 包含 beta 和 gamma 状态的消息,Delta 只包含 delta 状态的消息。一般情况下,消息按照 Q1→Q2→Delta→Q3→Q4 这样的顺序步骤进行流动,但并不是每一条消息都一定会经历所有的状态,这取决于当前系统的负载状况。
2. 消息状态流转
从 Q1 至 Q4 基本经历内存到磁盘,再由磁盘到内存这样的一个过程,如此可以在队列负载很高的情况下,能够通过将一部分消息由磁盘保存来节省内存空间,而在负载降低的时候,这部分消息又渐渐回到内存被消费者获取,使得整个队列具有很好的弹性。消费者获取消息也会引起消息的状态转换。当消费者获取消息时,首先会从 Q4 中获取消息,如果获取成功则返回。如果 Q4 为空,则尝试从 Q3 中获取消息,系统首先会判断 Q3 是否为空,如果为空则返回队列为空,即此时队列中无消息。如果 Q3 不为空,则取出 Q3 中的消息,进而再判断此时 Q3 和 Delta 中的长度,如果都为空,则可以认为 Q2、Delta、Q3、Q4 全部为空,此时将 Q1 中的消息直接转移至 Q4,下次直接从 Q4 中获取消息。如果 Q3 为空,Delta 不为空,则将 Delta 的消息转移至 Q3 中,下次可以直接从 Q3 中获取消息。在将消息从 Delta 转移到 Q3 的过程中,是按照索引分段读取的,首先读取某一段,然后判断读取的消息的个数与 Delta 中消息的个数是否相等,如果相等,则可以判定此时 Delta 中已无消息,则直接将 Q2 和刚读取到的消息一并放入到 Q3 中;如果不相等,仅将此次读取到的消息转移到 Q3。消息数据大致流向如下:
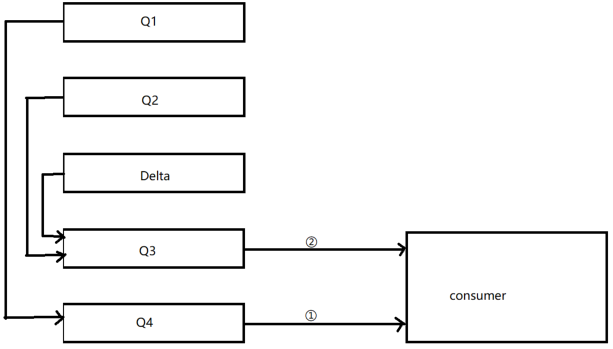
即: Q1 消息最终会流向 Q4,Q2、Delta 消息最终会流向 Q3,消费者优先从 Q4 中读取消息,若 Q4 为空再从 Q3 中读取,若 Q3、Q4 都为空,则可认为当前消息队列为空。
通常在负载正常时,如果消息被消费的速度不小于接收新消息的速度,对于不需要保证可靠不丢失的消息来说,极有可能只会处于 alpha 状态。对于 durable 属性设置为 true 的消息,它一定会进入 gamma 状态,并且在开启 publisher confirm 机制时,只有到了 gamma 状态时才会确认该消息已被接收,若消息消费速度足够快、内存也充足,这些消息也不会继续走到下一个状态。
当系统负载较高,消息堆积较多,处理每个消息的平均开销增大时,可以有以下 3 种措施进行应对:
(1)增加 prefetch_count 的值,即一次发送多条消息给消费者,加快消息被消费的速度;
(2)采用 multiple ack,降低处理 ack 带来的开销;
(3)流量控制。
三、惰性队列
RabbitMQ 从 3.6.0 版本开始引入了惰性队列(Lazy Queue)的概念。惰性队列会尽可能地将消息存入磁盘中,而在消费者消费到相应的消息时才会被加载到内存中,它的一个重要的设计目标是能够支持更长的队列,即支持更多的消息存储。当消费者由于各种各样的原因(比如消费者下线、宕机,或者由于维护而关闭等)致使长时间内不能消费消息而造成堆积时,惰性队列就很有必要了。
默认情况下,当生产者将消息发送到 RabbitMQ 的时候,队列中的消息会尽可能地存储在内存之中,这样可以更加快速地将消息发送给消费者。即使是持久化的消息,在被写入磁盘的同时也会在内存中驻留一份备份。当 RabbitMQ 需要释放内存的时候,会将内存中的消息换页至磁盘中,这个操作会耗费较长的时间,也会阻塞队列的操作,进而无法接收新的消息。
惰性队列会将接收到的消息直接存入文件系统中,而不管是持久化的或者是非持久化的,这样可以减少了内存的消耗,但是会增加 I/O 的使用,如果消息是持久化的,那么这样的 I/O 操作不可避免,惰性队列和持久化的消息可谓是“最佳拍档”。注意如果惰性队列中存储的是非持久化的消息,内存的使用率会一直很稳定,但是重启之后消息一样会丢失。惰性队列和普通队列相比,只有很小的内存开销。
队列具备两种模式:default 和 lazy。lazy 模式即为惰性队列的模式,可以通过调用 channel.queueDeclare 方法的时候在参数 x-queue-mode 中设置,也可以通过 Policy 的方式设置,如果一个队列同时使用这两种方式设置,那么 Policy 的方式具备更高的优先级。
发送消息时,惰性队列性能比普通队列好,出现性能偏差的原因是普通队列会由于内存不足而不得不将消息换页至磁盘。如果有消费者消费时,惰性队列会耗费将近 40MB 的空间来发送消息。
如果要将普通队列转变为惰性队列,那么我们需要忍受同样的性能损耗,首先需要将缓存中的消息换页至磁盘中,然后才能接收新的消息。反之,当将一个惰性队列转变为普通队列的时候,和恢复一个队列执行同样的操作,会将磁盘中的消息批量地导入到内存中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号