
MLA计算流全图解&吸收矩阵对比分析
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
当分析LLM模型的MLA时,需要细节图来辅助理解和讨论问题,本文用DeepseekV3的配置参数绘制了一版细节丰富的计算流图,标记了每一步相关的权重值W与激活值T。
本文还分析了:
-
MLA跟MHA的对比。
-
MLA为什么要分两个版本,差异如何?什么情况下用哪个版本?
-
MLA两个版本的权重加载一样吗?显存差异如何?
先上图,后讲解计算与显存的差异以及其应用场景。
MLA非吸收矩阵版本

添加图片注释,不超过 140 字(可选)
MLA吸收矩阵版本

添加图片注释,不超过 140 字(可选)
图片中符号含义:直角长方形表示计算或者操作;圆角长方形表示数据T(Tensor)。
有矩阵乘的位置标记了W(Weight),满足Tensor_n = T x W,计算包括:
-
Q、K、V的下采样线性计算
-
Q上采样运算
-
KV上采样运算(吸收与非吸收两种形态)
-
attention计算
-
O线性运算
MLA非吸收矩阵版本的关键特点:KV的cache后面会接一个上采样计算;
MLA吸收矩阵版本:KV上采样的计算矩阵拆成两个,分别移动到了Q运算之后和O运算之前。
两个版本的算力消耗存在差异,与输入序列长度seq_len、KV cache长度cache_len相关,两个版本的算力差值图如下所示(图中红线表示差值=0):

添加图片注释,不超过 140 字(可选)
根据算力图可知:Prefill阶段采用MLA非吸收矩阵版本,Decode阶段采用MLA吸收矩阵版本,后面会对计算过程进行详解。
1
MLA
MLA(Multi-Head Latent Attention)是在MHA的基础上改进的一种架构,主要的变化是QKV的映射计算发生变化,达到以算换存的目的。不同点:QKV的计算存在上、下投影,QK有位置编码运算,相同点:Attention运算,RoPE(初代的MHA没有)运算。架构图的对比:
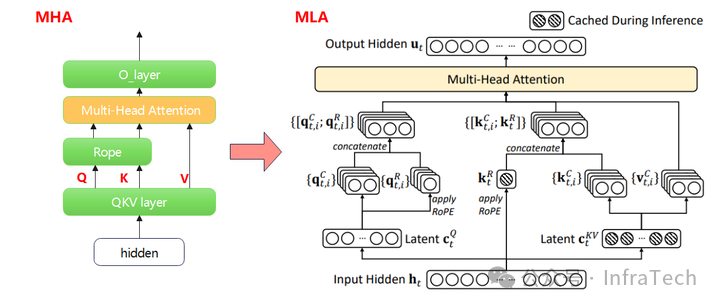
MHA vs MLA
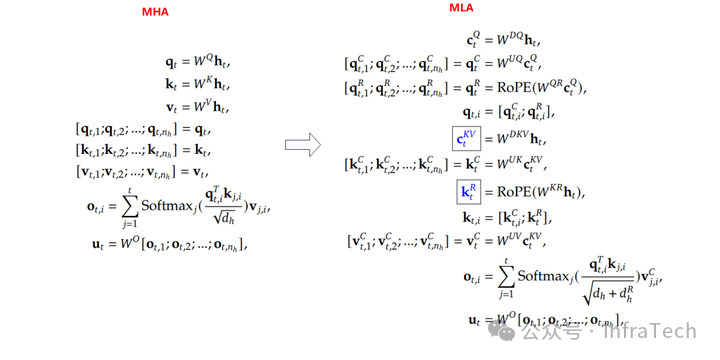
MLA可以看成对MHA的Q、K、V矩阵都进行了低秩分解。以K矩阵为例,它拆解成了K和Sk两个矩阵。

添加图片注释,不超过 140 字(可选)
简述一下低秩分解的好处。数学上将一个大矩阵Amn分解为 Bmr和Crn满足:
Amn=Bmr×Crn,
一般让r << m,n,元素的个数从m x n降到(m + n) x r,省了存储空间。
进一步拆分公式对比如下所示,MHA到MLA的变化点:
-
原计算矩阵拆分成了两个子矩阵W_D和W_U。其中字母D是向下投影,U是向上投影,R表示位置编码计算;
-
K和V的投影运算结合在一起计算;
-
KV cache缓存变为k_pe和compress_kv;
-
softmax计算的分母作了调整;
添加图片注释,不超过 140 字(可选)
2
MLA的两个版本
针对推理场景应用中,MLA的两种形态:吸收(absorb)矩阵与非吸收矩阵版本,两者在公式上面推导是数学等价的。在deepseekV2的报告中有如下说明:

添加图片注释,不超过 140 字(可选)
吸收矩阵形态实际上是把KV的上采样计算移动到Q和O的计算位置。
这样做的好处:在推理中可根据阶段的特征来选择形态,因为序列的变化会让两种计算形态的计算量、显存占用量不一样! 序列的变化包括每次输入MLA的序列长度,以及历史的KV cache长度。
prefill阶段的输入序列长度就是提问的prompt长度,而decode阶段的输入序列长度为1;而KV cache的长度取决于特性开启,比如prefix-cache、chunk等。
接下来对比各个通道数据流差异,其中非吸收矩阵取prompt=2048,KV cache长度为0;吸收矩阵input_token = 1, KV cache长度为1023。
2.1
Q通道对比
主要差异点:吸收矩阵的q_nope后面多了一个矩阵乘法运算。

添加图片注释,不超过 140 字(可选)
2.2
KV通道对比
主要差异点:非吸收形态要经过上采样后再进行attention计算,而吸收形态不用。
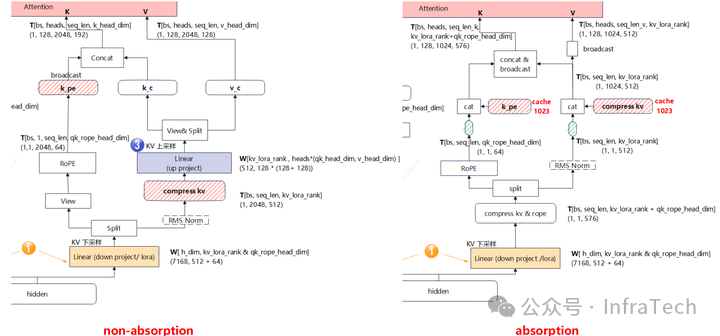
添加图片注释,不超过 140 字(可选)
2.3
O通道对比
主要差异点:吸收矩阵MLA的O线性层计算前多了一个V转移过来的矩阵乘法。
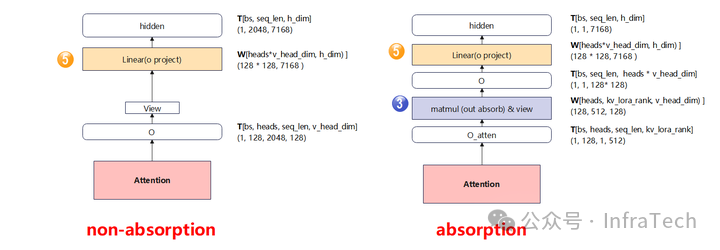
添加图片注释,不超过 140 字(可选)
3
MLA的计算量与显存
3.1
计算量对比
根据MLA公式,构建了一个吸收矩阵与非吸收矩阵的MLA的计算量的对比(假设attention未开causal_mask)。
MLA非吸收矩阵计算量:
# Q的下采样 + Q的上采样
MLA吸收矩阵计算量:
# Q的下采样 + Q的上采样 + 吸收矩阵运算
参数配置(参考DeepSeekV3):
bs = 1
另外两个关键变量:seq_len是输入长度,cache_len是KV cache存储的长度。这两个变量的变化应用于不同场景,比如:
-
Prefill:seq_len=x ,cache_len=0
-
Decode:seq_len=1 ,cache_len=y
-
Prefill & prefix cache: seq_len=x ,cache_len=y
接下来看一下这三个场景下,非吸收矩阵与吸收矩阵计算差距:
diff = mla_non_absorb_flops - mla_absorb_flops
在Prefill阶段:seq_len=x,cache_len=0,让x连续增长打印Tflops。可以看到,非吸收矩阵的计算量更小,而且序列越长越明显。所以Prefill阶段一般用non absorption。

添加图片注释,不超过 140 字(可选)
在Decode阶段:seq_len=1,cache_len=y,让y连续增长打印Tflops。可以看到,Decode阶段absorption算力消耗更少。

添加图片注释,不超过 140 字(可选)
结合上述两张图可大致判断出,差值diff和seq_len是非线性关系,与cache_len是线性关系。
Prefill & Prefix cache场景: seq_len=x ,cache_len=y。Prefix cache开启时,y值可能大于零,假设prefix cache命中使得y=20,让x变化,计算对应的diff。可以看到随着x增长,diff数值由正变为负,且存在某个序列长度x,让diff=0,即吸收矩阵与非吸收矩阵算力相等。
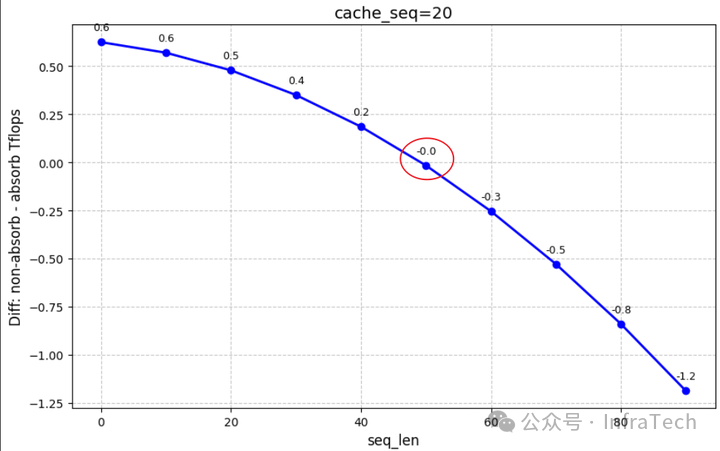
添加图片注释,不超过 140 字(可选)
对于固定的参数y,总能构建出 non absorb flops > absorb flops的条件,然而y是变化的。若观测吸收矩阵与非吸收矩阵MLA哪个算力消耗更小,可提取出一个计算式:
# step1 消除相同部分:
若seq_len=x 、cache_len=y、diff=z,并去除公共乘数,则公式变为:
z=131072*y-768*x2-768*x*y
131072∗y−768∗x2−768∗x∗y
z是x*y,y,x^2。因x,y均大于零,取变化范围从0到1000,绘制一个diff的图如下:

添加图片注释,不超过 140 字(可选)
根据数据可知:
-
当seq_len 大于某个数值时,cache_len无论如何变化diff都是负数,此时非吸收矩阵更省算力。
-
seq_len比较小时,diff> 0,吸收矩阵计算更省算力。
上述例子中,除了seq_len和cache_len,其它参数也可以调整,感兴趣的读者可在此基础上继续探索不同参数下MLA两个版本的特点,比如开启causal_mask曲线会发生明显变化。本人写了一个notebook示例代码供参考:
https://github.com/CalvinXKY/mfu_calculation/blob/main/MLA_absorb_mfu.ipynb
3.2
显存对比
显存对比主要是分析:静态显存--权重,以及动态显存--激活值。
静态显存比较:通过前面的计算流图,可以看到两种形态下,权重的大小是不会发生变化的,仅KV上采样的权重W形状需要调整。这也回答前面的问题,MLA的两种形态下加载的权重参数相同。

添加图片注释,不超过 140 字(可选)
激活值的比较,需找出所有计算阶段中的最大值,用两者的最大值算差值。步骤上先除去相同的计算,后仅对比有差异的位置,并忽略一些MLA中低量级参数的显存占用量。
非吸收矩阵MLA的峰值显存计算:
kv_up_proj = (bs * seq_len * kv_lora_rank +
吸收矩阵MLA的峰值显存计算:
q_absorb_mem = bs * heads * seq_len * (qk_head_dim + kv_lora_rank + qk_rope_head_dim)
两者的最大值均出现在attention阶段,代入设置的模型参数计算公式变为:
qkv_o_absorb_mem = 128 * seq_len * (512 + 64) + \
可知,吸收矩阵的激活值峰值始终大于非吸收矩阵的激活值峰值,序列越长差值越大。

16K的请求差异,计算代码文末
开启并行策略情况下显存与算力的比较会不一样,具体请参考下文自行推导。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
参考内容:
-
https://arxiv.org/pdf/2405.04434
-
https://zhuanlan.zhihu.com/p/26107304514
-
https://arxiv.org/pdf/2412.19255
过程中计算代码:
https://github.com/CalvinXKY/mfu_calculation/blob/main/MLA_absorb_mfu.ipynb
作者知乎主页:
https://www.zhihu.com/people/xky7
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号