
国产GPU公司发展及典型产品技术
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
GPU以强大的图形处理能力闻名,能够每秒运算数百万个多边形,为游戏和影视创造逼真画面。
在智能汽车领域,GPU除了作为车载智能和交互的汽车图形处理器,它正在成为自动驾驶的"决策大脑"。面对12个高清摄像头、5个毫米波雷达和激光雷达每秒产生的数GB数据,GPU的并行计算优势使其成为处理多传感器融合、实时环境建模和AI决策的关键芯片。
随着智能座舱多屏交互和自动驾驶等级提升,车规级GPU需要同时突破四大技术关卡:4K级实时渲染能力、百TOPS级神经网络运算、功能安全ASIL-D认证,以及耐高温抗振动的车规可靠性。
这正是国产GPU厂商的发力方向--通过自主架构创新,在图形渲染、AI加速、功能安全等维度实现技术突破,逐步构建起覆盖L2到L4自动驾驶的全栈GPU解决方案,加入全球智能汽车选择方案的竞争中。叠加前些日子的美国关税政策调整因素,国产替代进程加速,国产GPU厂商迎来了历史性发展机遇。
昔日GPU“国家队”
CONTENT
景嘉微是国内唯一实现GPU芯片完全自主可控并规模化应用的企业,拥有从架构设计、算法模型到硬件实现的全链条技术能力。
经过多代产品迭代,景嘉微GPU芯片已实现从图形处理到高性能计算的跨越式发展。2014年,景嘉微成功研发了国内首款自主设计的嵌入式芯片JM5400,能够与国产CPU和嵌入式操作系统兼容。JM5400的问世标志着中国在GPU领域实现了从无到有,也为国产GPU奠定了基础。早期JM7200系列主要面向图形渲染需求,而后续JM9系列则成功拓展至科学计算等高性能领域,标志着国产GPU在通用计算能力上的突破。
2024年,景嘉微完成最新一代JM11系列GPU的研发,预计2025年实现规模化商用。该产品的推出将进一步增强公司在高性能计算市场的竞争力,并成为未来业绩增长的重要驱动力。
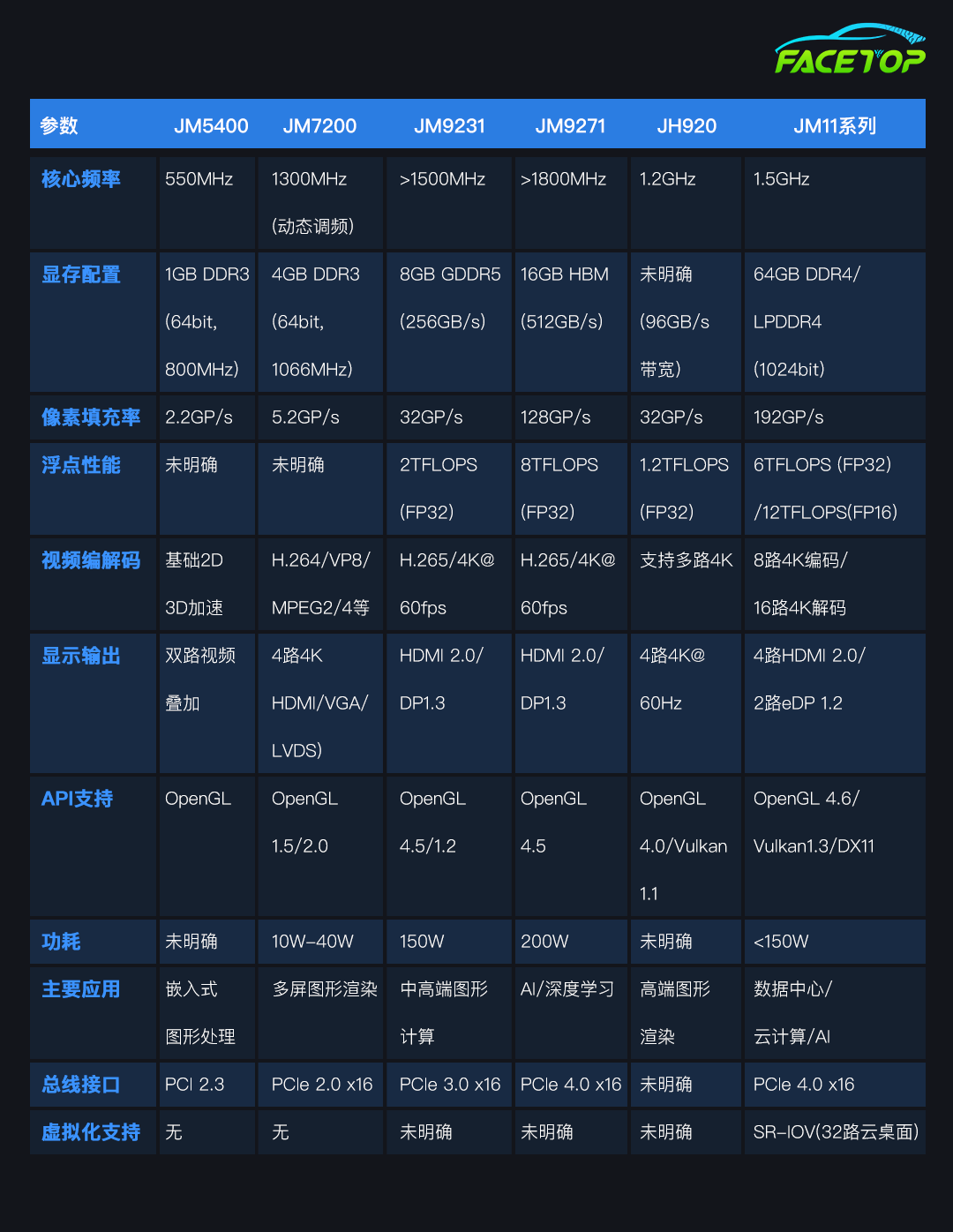
JM5400
JM5400采用65nm CMOS工艺,搭载创新架构设计,专为高可靠性图形处理需求开发。该芯片集成1GB DDR3存储器,支持双路视频处理(开窗/缩放/旋转/叠加),提供完整OpenGL驱动支持,完美适配国产CPU及操作系统。其核心性能表现为:550MHz主频,4条渲染管线,像素填充率达2.2G pixels/s,并配备64位DDR3内存接口(800MHz),全面兼容PCI 2.3标准。
JM7
JM7系列以JM7200为例,其采用28nm CMOS工艺,具备高性能图形处理能力。该芯片支持动态调频,内核时钟最高1300MHz,配备两组32位DDR3内存(最大4GB容量,带宽17GB/s),兼容PCIe 2.0 x16接口。
其图形性能表现突出:4条渲染管线实现5.2GP/s像素生成率和10.4GT/s纹理填充率,支持OpenGL 1.5/2.0规范,并具备双GPU交火能力。视频处理方面支持H.264/VC-1/VP8/MPEG2/4硬件解码,集成多路显示输出(4路4K显示,含HDMI/VGA/LVDS/DVO接口)。整机功耗控制在10W-40W范围,满足高性能图形应用需求。
添加图片注释,不超过 140 字(可选)
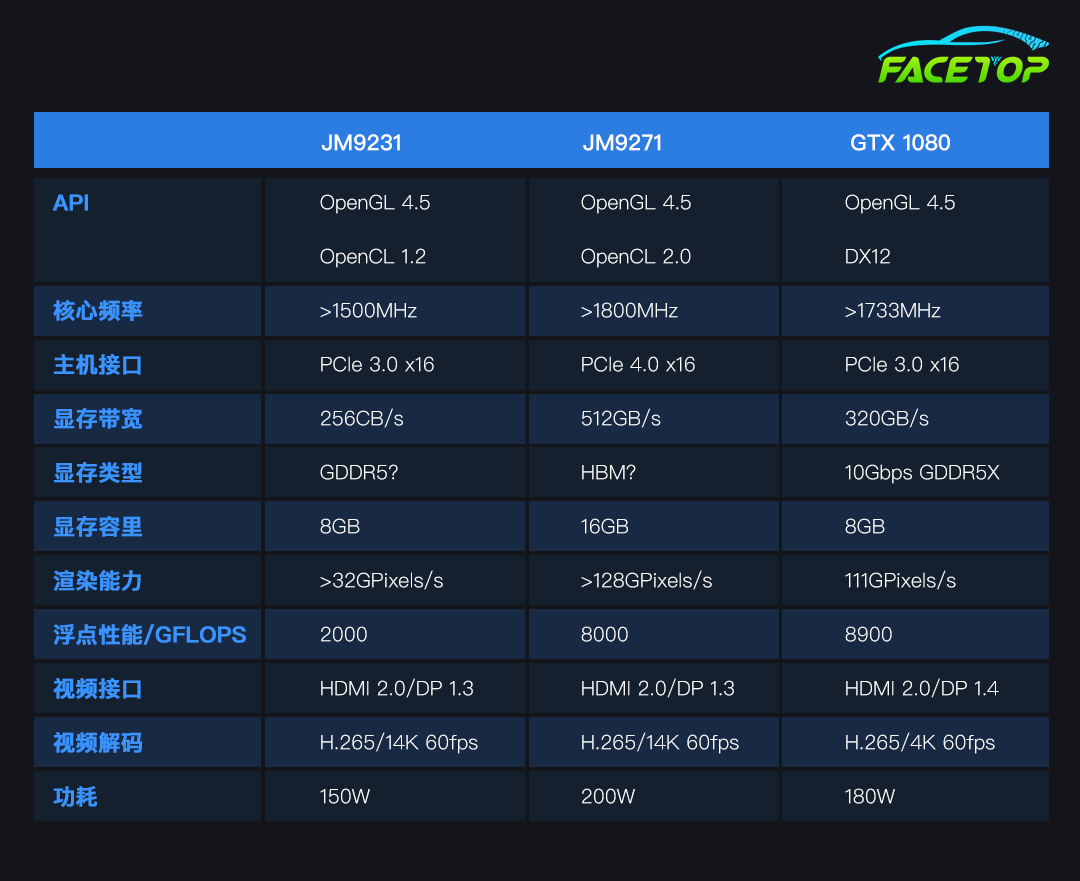
JM9231高性能GPU规格参数
JM9231采用统一渲染架构,核心频率超过1500MHz,通过PCIe 3.0 x16总线接口提供高效数据传输。该芯片配备8GB GDDR5显存,实现256GB/s的超高带宽,像素渲染能力突破32GP/s,浮点运算性能达2TFLOPS。视频输出支持HDMI 2.0和DisplayPort 1.3接口,完美实现H.265/4K@60fps解码。支持OpenGL 4.5/1.2图形API,整卡功耗控制在150W,性能较前代JM7200提升数十倍。
JM9271旗舰级GPU规格参数
JM9271在JM9231架构基础上全面升级,核心频率提升至1800MHz以上,采用PCIe 4.0 x16新一代总线。配备16GB HBM显存,带宽高达512GB/s,像素渲染能力达128GP/s,浮点性能8TFLOPS,接近GTX 1080水平(111GP/s、8.9TFLOPS)。
保持HDMI 2.0/DP1.3视频输出能力,支持4K@60fps解码,功耗200W。专为AI训练、深度学习等高性能计算场景优化,配套开发专用运算库和高性能计算平台,整体性能达到2017年国际中高端产品水准。
JH920-重大突破标志
作为景嘉微第三代自研GPU产品,JH920采用14nm先进制程工艺,像素填充率达32G Pixels/s,核心频率达1.2GHz,单精度浮点运算性能优化后稳定在1.2TFlops(初期1.5TFlops)。该芯片配备高带宽显存系统,提供96GB/s的显存带宽,完美支持4路4K@60Hz超高清显示输出。
在软件兼容性方面,JH920全面支持OpenGL 4.0和Vulkan 1.1等主流图形API标准,标志着国产GPU在图形处理能力上的重大突破。相比前两代产品,JH920在运算性能、显示输出和能效比等方面实现跨越式提升,特别适用于高端图形渲染和高分辨率多屏显示等专业应用场景。
JM11系列作为景嘉微新一代高性能GPU
制程工艺未具体披露(14nm/7nm)采用PCIe 4.0 x16高速接口,核心频率达1.5GHz,配备1024bit位宽DDR4/LPDDR4显存,最大容量64GB,提供强大的数据吞吐能力。其图形渲染性能突出,像素填充率高达192GPixel/s,支持OpenGL4.6、Vulkan1.3、DirectX11等主流图形API,并具备FP32 6TFLOPS及FP16 12TFLOPS的运算能力。
在视频处理方面,JM11系列支持8路4K@60fps H.265/H.264编码或32路1080P@60fps编码,同时可解码16路4K@60fps或64路1080P@60fps视频流,覆盖H.265、H.264、MPEG2/4等格式。此外,该芯片集成4路HDMI 2.0、2路eDP1.2和1路VGA显示输出,最高支持3840x2160@60Hz分辨率,并采用SR-IOV硬件虚拟化技术,可扩展32路云桌面或64路云游戏场景。整卡功耗控制在150W以内,兼顾高性能与能效,适用于数据中心、云计算、AI推理及多屏协同等高端应用领域。
添加图片注释,不超过 140 字(可选)
品牌发展状态
景嘉微的核心竞争力不仅来自于全军武器装备采购目录唯一GPU供应商,产品应用于歼击机、预警机等主战装备的身份,还成功将机载图形处理技术应用于车载AR-HUD领域。JM9271芯片更是荣获ASIL-D认证,浮点性能高达8TFLOPS。JM9系列在信创市场市占率从2023年15%升至2024年30%。

添加图片注释,不超过 140 字(可选)
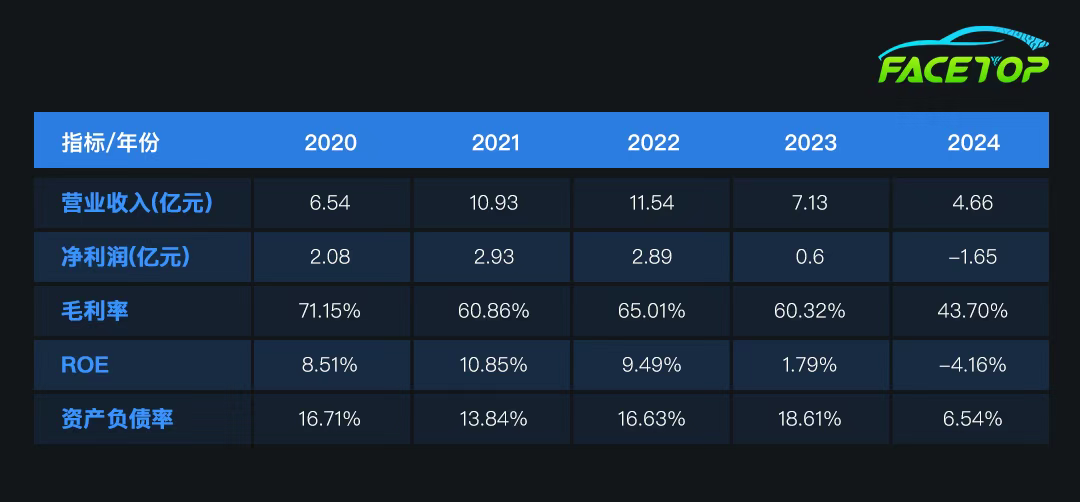
然而,根据公司财务报表来看,ROE从2020年8.51%降至2024年-4.16%,公司造血能力很差,盈利能力有所削弱,主营获利能力削弱非常明显。2024年的营收和净利润大幅下跌。2025年Q4,景嘉微将量产7nm JM10系列流片(支持光追,性能对标RTX 3060)。同时与比亚迪合作开发智能座舱芯片,2025年装车测试,这支昔日的国家队也在力图自救。
壁仞科技BR100
引领国产算力新时代
CONTENT
BR100采用自主原创架构,采用7nm工艺制程,集成Chiplet技术和2.5D CoWoS封装。支持PCIe 5.0和CXL协议,双向带宽达128GB/s。显存配置64GB HBM2E,带宽2.3TB/s。其核心算力包括2048 TOPS INT8整型运算能力,以及1024 TFLOPS(BF16)、512 TFLOPS(TF32+)和256 TFLOPS(FP32)的浮点性能,全面覆盖从AI训练到科学计算的精度需求。
存储方面配备64GB HBM2E高带宽内存和超300MB片上缓存,显著降低数据延迟,同时提供2.3 TB/s的外部I/O带宽,满足多芯片互联与高速数据吞吐。视频处理能力强大,支持64路编码和512路解码,适用于超大规模视频分析场景。BR100的正式发布,标志着全球通用GPU算力纪录第一次由一家中国企业创造,中国的通用GPU芯片正式迈入“每秒千万亿次计算”新时代。

添加图片注释,不超过 140 字(可选)
平安科技、浪潮信息、万国数据等行业巨头已与壁仞科技携手合作。同时,壁仞科技还与全球多所顶尖高校建立了合作关系,在技术研究、人才培养、科研成果转化等方面将进一步提升。
寒武纪-国产替代政策
+AI算力爆发驱动
CONTENT
思元370
思元370系列加速卡包含两款产品:面向高密度部署的MLU370-S4(半高半长,75W)和追求极致性能的MLU370-X4(全高全长,150W)。该系列基于7nm思元370芯片和MLUarch03架构打造,采用chiplet(芯粒)技术,较上代实现显著提升:MLU370-X4在优化后的ResNet-50v1测试中性能高达30204fps,同时MLU370-S4以75W功耗提供3倍于同级GPU的解码能力。
全系支持192TOPS(INT8)算力和307.2GB/s内存带宽,配备LPDDR5显存(24/48GB),兼具8K视频处理与132路1080P解码能力,通过PCIe 4.0接口为云端AI推理提供高能效解决方案。

添加图片注释,不超过 140 字(可选)
思元590
思元新一代590芯片采用7nm工艺制程,搭载MLUarch05全新架构,集成2个ARM Cortex-A76和4个Cortex-A55 CPU核心,以及1个Mali-G77 MC9 GPU。该芯片在实测训练性能上较当前旗舰产品有显著提升,不仅提供更大的内存容量和更高的内存带宽,其IO接口和片间互联技术也较上一代实现重大升级,为AI计算任务带来更强大的处理能力和更高的能效表现。
品牌发展状态
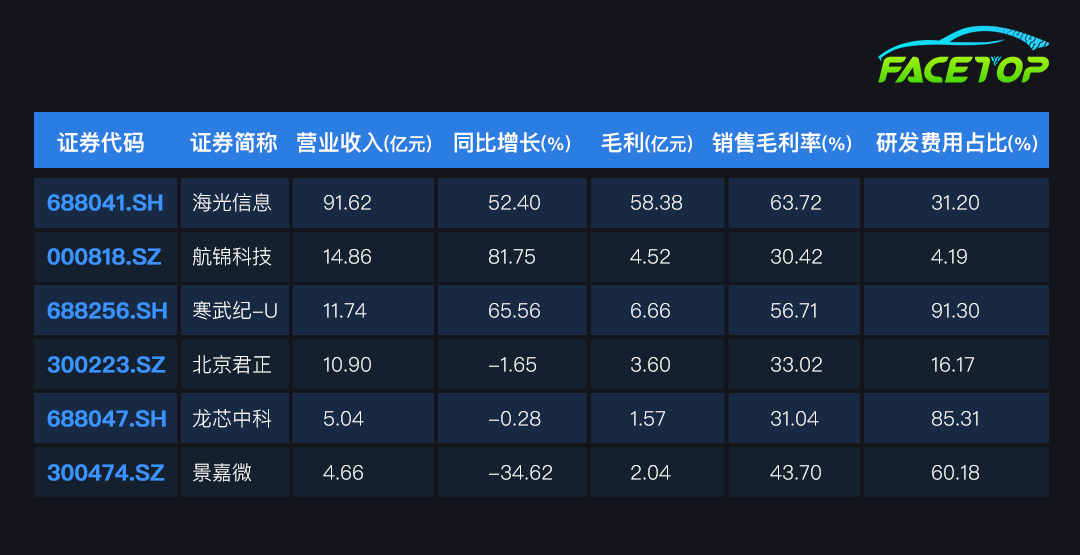
寒武纪作为中国AI芯片领域的先行者,其市场份额为7%,其思元590芯片在性能上已接近英伟达A100的80%,被视为A100的有力国产替代品 。2024年,寒武纪以11.74亿元的营业收入在统计企业中排名第三,同比增长65.56%,增速位列第二,展现出强劲的市场需求与业务扩张能力。其毛利润达6.66亿元,毛利率为56.71%,均排名第二,凸显产品的高附加值和市场定价能力。
然而,寒武纪的研发费用占比高达91.30%,远超行业中位数(45.69%),反映其“技术驱动”战略下对创新的高度重视,但也可能对短期盈利造成压力。尽管技术实力和增长潜力突出,但其营收规模仅为行业龙头海光信息的约1/8,市场覆盖和商业化能力仍有提升空间。
添加图片注释,不超过 140 字(可选)
华为昇腾
为自主创新提供技术保障
CONTENT
华为昇腾芯片作为国产GPU领域的标杆产品,其市场表现彰显了中国AI芯片的崛起实力:全球市场份额约5%,国内市场占有率更高达23%,稳居行业第二。这一成就源于华为坚持自主创新的技术路线,特别是在美国技术封锁的严峻形势下,昇腾系列的成功研发有力支撑了中国AI计算基础设施的自主化进程,为国内人工智能产业发展提供了关键的技术保障。
华为昇腾910系列
该产品是目前国内可出货的性能较高的一款芯片,于2019年正式发布。截至2025年,昇腾系列已迭代至910D型号,性能预计超越英伟达H100芯片,并计划向客户交付超80万枚昇腾910B和910C芯片。
以华为昇腾910C为例,其采用中芯国际7nm工艺制程(集成530亿晶体管),通过创新的双die封装Chiplet技术和达芬奇架构3.0,在国产工艺基础上实现了国际领先的性能表现。该芯片单卡FP16算力达800 TFLOP/s,内存带宽3.2TB/s,在NLP推理场景中性能达到H100的60%,而成本仅为H100的40%。特别值得一提的是,凭借3D Cube计算单元的精妙设计,其单位面积算力密度反超市面主流4nm工艺芯片15%,展现了华为在芯片架构设计上的深厚功力。
在供应链安全方面,华为通过CoAsia的异构封装方案成功突破HBM限制,储备1300万颗HBM,构建了从芯片设计(海思)、代工(中芯国际)到封装测试(长电科技)的全栈国产化生态,实现85%的国产化率。
系统级优化上,搭载自研HCCS高速互联芯片(240Gbps带宽)的CloudMatrix 384超节点总算力达200 PFLOPS,较英伟达同类方案提升25%,在自动驾驶等场景训练效率提升40%。配合MindSpore框架,在金融风控等实际应用中实现97.4%的成本优化,彰显了从底层芯片到上层应用的全栈创新能力。
昇腾920
昇腾920采用中芯国际6nm工艺技术和创新的Chiplet 3D堆叠技术,将计算、存储和网络模块垂直集成,实现高达1.2TB/s的片内互连带宽,算力提升至900TFLOPs,该芯片配备192GB HBM3e高带宽内存,提供819GB/s的带宽,完全满足大模型训练对海量参数的实时调用需求。
在能效方面,昇腾920搭载智能DVFS 2.0技术,支持10W-300W动态功耗调节,边缘场景下功耗可低至10W以下,并采用先进液冷散热方案,使数据中心PUE值降至1.1以下,较传统风冷节能40%。昇腾920C针对大模型训练优化,支持1024卡集群扩展,在Llama2-70B模型训练中并行效率达92.5%,较A100提升18个百分点;昇腾920D则聚焦边缘计算,在智能安防场景实现200TOPS算力下放,功耗仅为英伟达Jetson Xavier的1/3。
品牌发展状态
2024年的GPU 市场中,尽管英伟达受出口管制影响,仅能供应相对低端的 H20 芯片,但其凭借强大的 CUDA 生态优势,仍以 70% 的市场份额占据主导地位。华为昇腾表现亮眼,凭借强大研发实力以23%的国内市场份额形成国产替代主力,并在政府主导的智算中心建设中占据超60%份额。
摩尔线程
全功能GPU领域鳌头
CONTENT
2024年胡润全球独角兽榜中,摩尔线程位列第261名,成为国产GPU设计公司的领头羊,其技术进展和市场动向受到广泛关注。各代芯片架构主要规格参数如下所示:
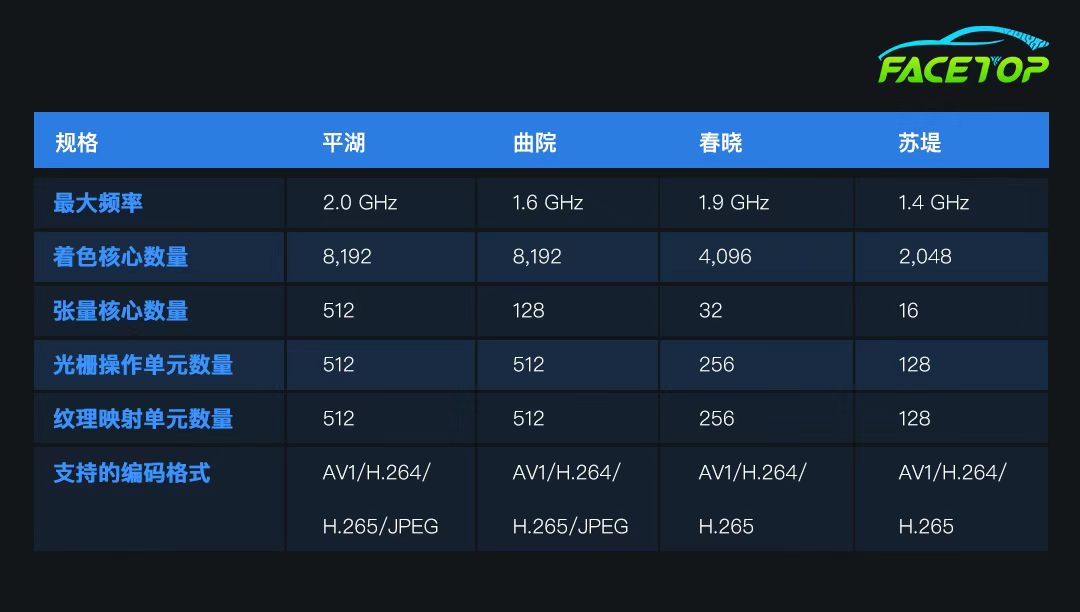
添加图片注释,不超过 140 字(可选)
图源芯智讯
"平湖"
其中最新的第四代GPU架构"平湖"采用7nm制程工艺,峰值频率达2GHz,集成8192个统一着色器核心、512个张量核心及512个ROPs/TMUs。其突破性技术包括:单卡48GB显存与768GB/s带宽,MTLink2.0实现60%带宽优势;零中断容错技术使集群训练效率超99%,资源利用率提升15%。相较英伟达H100,其FP32算力达23.5TFLOPS且能效比提升20.6%,FP8混合精度训练实现83%算力利用率。通过800GB/s片间互联和80GB显存支持,配合新增的FP8精度,显著提升了AI训练与推理性能。
"长江"
摩尔线程第一代SoC“长江”集成了“全功能 GPU + CPU + NPU +VPU”等异构算力单元的片上系统芯片,用8核CPU设计,主频最高达2.65GHz,集成MUSA架构GPU,提供3 TFLOPS(FP32)、12 TFLOPS(FP16)及50 TOPS(INT8)的多元算力,满足高性能计算与AI推理需求。
其内存子系统支持最高64GB LPDDR5,带宽102GB/s,并配备PCIe 5.0 x16高速接口,确保数据高效传输。多媒体能力突出,支持AV1/AVC/HEVC编解码,可实现2路8K30Hz解码或1路8K30Hz编码;显示接口支持8个4K@60FPS屏幕输出,并通过4组CSI-2接口接入16路摄像头,结合双核ISP(支持24bit HDR和3200万像素处理),适配复杂视觉场景。外设扩展涵盖千兆网络、USB3.1 Gen2及音频接口,功耗控制在28W-45W,兼顾性能与能效平衡。
品牌发展状态
“长江”SoC在汽车智能座舱市场上,其性能规格超越高通量产的智能座舱方案——骁龙 8295。“长江”SoC在图形渲染、内存带宽、端侧大语言模型推理等方面具有一定的优势,能够给用户体验带来明显提升。
自2020年成立以来,摩尔线程就十分重视技术研发。2024年其研发投入13.59亿元,研发费用率高达309.88%。2022-2024年,公司营收从4608.83万元增长至4.38亿元,复合增长率超200%。其AI智算产品收入占比从零提升至2024年的77.63%,达3.36亿元。
尽管AI智算产品贡献了77%的营收,推动公司三年内营收飙升至4.38亿元,印证了政策红利下国产替代的强劲需求,但同期高达50亿元的亏损和310%的研发费用占比,凸显了全功能GPU战略在技术追赶过程中面临的巨大投入与盈利挑战。据新闻预计,其将在2027年盈利。
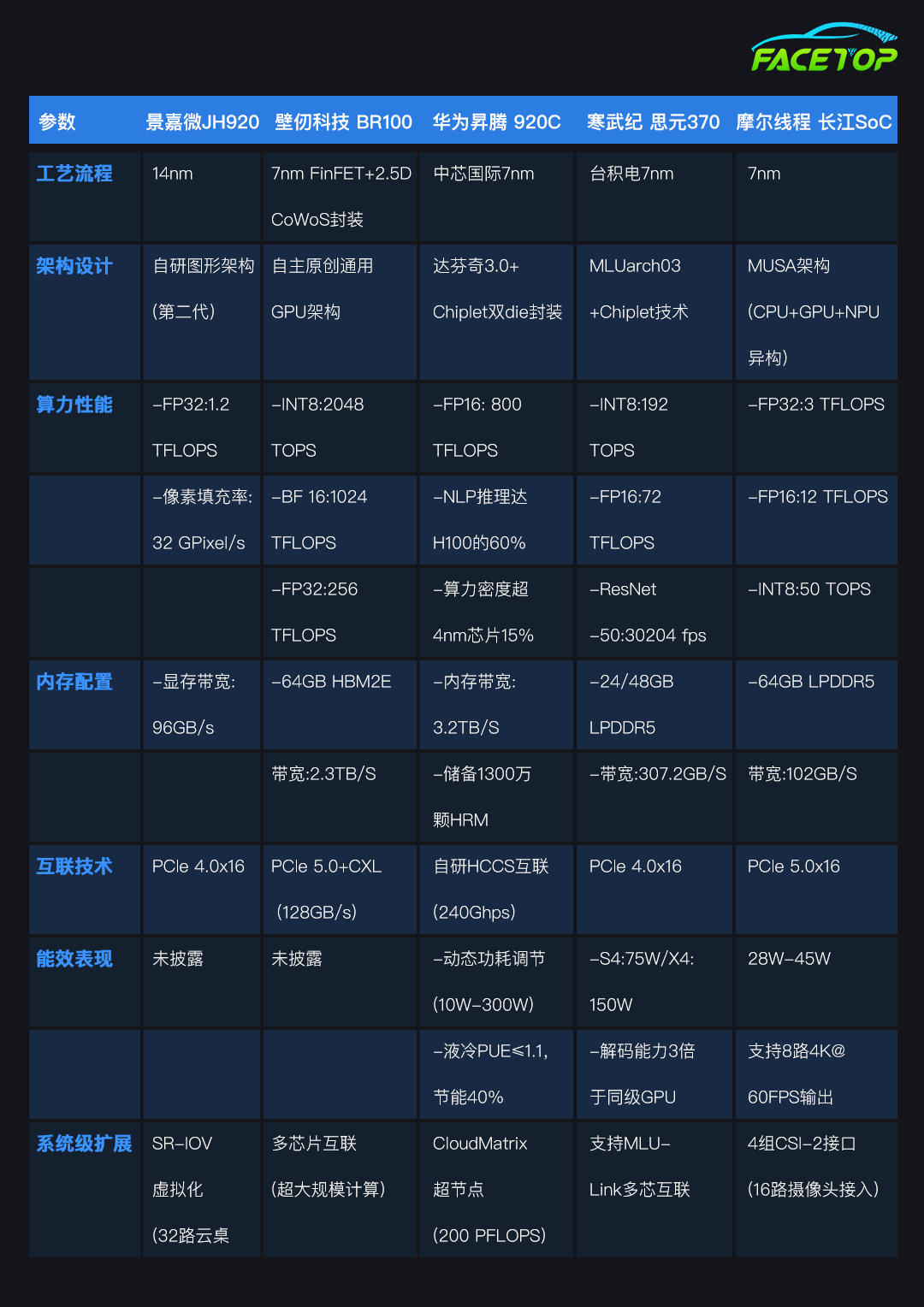
上述国产芯代表综合对比
综上所述,国产GPU在关键性能指标上已取得长足进步,不同产品各有所长。尽管在算力、能效、生态支持等方面仍需持续突破,但未来通过加强研发投入、完善产,国产GPU有望在更多领域实现替代和超越,推动国内电子产业的自主可控,为全球市场贡献更多中国智慧和中国方案。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号