
AI芯片:寒武纪--全解析
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
一个风口的行业,只要该行业没有到顶,离顶还有相当距离的情况下,龙头企业再贵都是便宜的。
寒武纪是我国AI芯片行业龙头。8月14日,寒武纪盘中最大涨超14%,总市值一度突破4000亿元,股价创历史新高,成为市场关注焦点。
截至8月15日,公司收盘价为923.7元/股,总市值为3864亿元,成为仅次于茅台的第二高价股,因此也被誉为“寒王”。
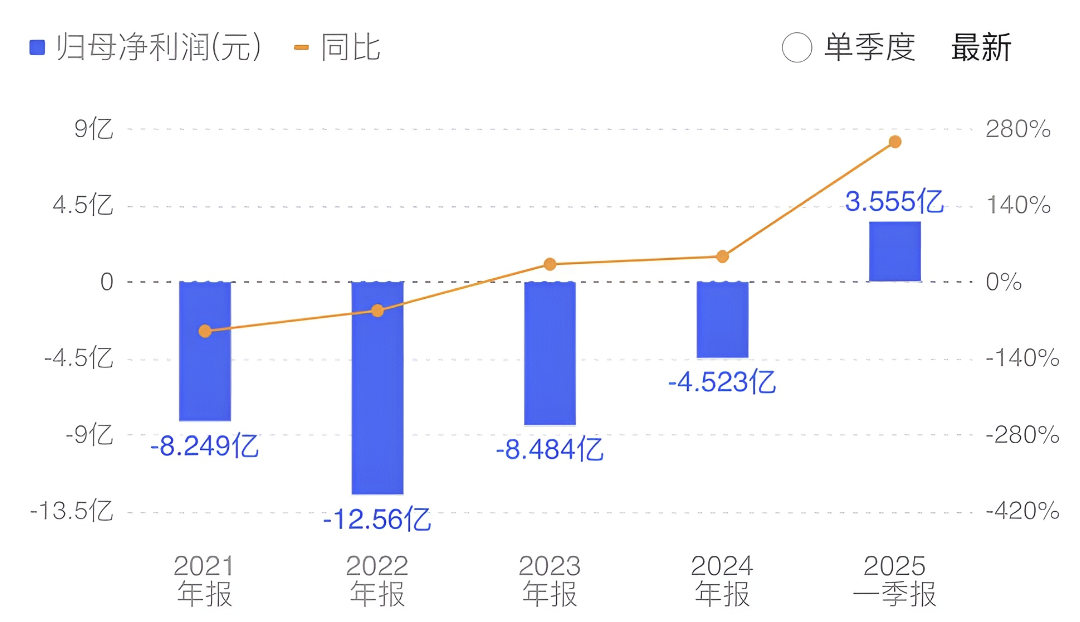
再看寒武纪的财务数据,2025年第一季度营收为11.11亿元,上年同期的营收为2567万元;归母净利为3.55亿元,上年同期为亏损为2.27亿元;公司25年一季度末扭亏为盈,已经连续两个季度实现盈利。
寒王是2020年科创板上市,从64元的发行价,一举最高涨到985元,成为AI芯片第一股。2024年还被纳入上证50指数,但利润却一直年年亏损,如此梦幻的“妖股”,值得单独解析。
下文从:① 寒武纪-溯源;② 核心产品和技术;③ 市场空间与竞对;④ 产业链;⑤“寒王”总结&展望,等5个维度,全面梳理这一中国的英伟达。

添加图片注释,不超过 140 字(可选)
一、寒武纪-溯源
1、公司坐标: 北京
成立时间:2016年3月15日
2、创始人
陈云霁和陈天石两兄弟,目前总经理由弟弟:陈天石担任。
两兄弟来自江西南昌人,哥哥1983年出生,弟弟晚两年出生。两兄弟成长路径相似:哥哥是14岁进入中科大少年班,拿到计算机博士学位,并参与“龙芯”团队。
弟弟是16岁进入中科大少年班,也是计算机博士,后转入中国科学院计算所担任研究员。
读博期间,陈云霁的研究方向是芯片,陈天石主要是做人工智能。2010年,身为龙芯3号主架构师的陈云霁,在北京与弟弟陈天石一拍即合,各取所长,提出研发AI芯片的构想。而2010年,AlphaGo还没击败李世石,英伟达还只是一家显卡厂商。2016年,借助中科院计算所平台和资源,共同设立了北京中科寒武纪科技。
寒武纪成立后,研发出了全球首个能够深度学习的神经网络处理器芯片,改变了中国芯片领域长期空白落后的历史。当年就拿到了上亿元的订单。

添加图片注释,不超过 140 字(可选)
陈天石两兄弟对团队定的铁律是:“芯片是长跑,没有捷径可走。所有捷径都是弯路,真正的好东西,都得拿命熬出来。”
当英伟达CUDA生态已形成垄断,面对差距,陈天石决心让寒武纪补足生态短板,专注于底层硬件和工具链,避免做应用,找到差异化。
当19年,华为自研芯片终止合作,寒武纪失去90%营收来源,陈天石鼓励团队:“依赖输血的企业永远长不大,孩子总要离开父母学会走路”,于是反直觉的砍掉短期盈利的IP授权业务,将资源投向尚未成熟的云端芯片。
当20年寒武纪登陆科创板,虽市值破千亿,却被质疑,三年亏损超50亿,研发投入占比高达157%!何时可以盈利?”陈天石的回应清醒得近乎冷酷:“Intel今年52岁,NVIDIA27岁,寒武纪才4岁。罗马不是一天建成的。”
添加图片注释,不超过 140 字(可选)
当22年,美国将寒武纪列入实体制裁清单,陈天石再一次豪赌:将全部筹码押注国产7nm工艺,带领团队攻坚克难300天,研发出比肩英伟达A100的国产制程的“思元590”芯片。
在2025年,这位85后天才以870亿身家登顶江西首富,面对镜头,他却异常平静说:“寒武纪愿做‘墩子’,让更多人踩在我们身上做应用”。
也许,很多人不理解寒武纪。但是,从掌舵人十年磨一剑的毅力,主动断奶学会奔跑的勇气,坚持伟大都是熬过来的定力,宁可烧钱50亿换一颗“中国芯”的魄力,让寒武纪真正可以和英伟达掰手腕。
现在寒武纪全年营收预计10亿至12亿元,虽不及英伟达的千分之一,但国产替代的浪潮、扭亏为盈的业绩拐点、国内强劲的自主可控需求,会推着企业迈向中国AI芯片的新高度。
3、名字寓意
“寒武纪”,Cambrian,是因为寒武纪是距今约6亿年,地球物种多样性大爆发的年代,此后地球进入了生命的新纪元。陈天石希望这家公司能开启AI爆发式发展的新时代,通过自研的AI芯片,成为推动这一科技变革的核心基础支撑和力量。
4、重大事件发展轴
(1)2017年9月,华为在德国IFA展上重磅发布AI手机芯片“麒麟970”,搭载了寒武纪的嵌入式IP,集成了寒武纪的NPU(1A处理器),作为神经网络专用处理单元,并在华为Mate 10手机中投入大规模商用,寒武纪由此声名鹊起。
芯片IP授权业务,虽起步快,但天花板较低,合作关系脆弱。
(2)2018,由于华为开始发布AI芯片昇腾910和昇腾310,自研AI模块,与寒武纪的合作终止,这直接导致寒武纪2019年营收锐减。
(3)从2018年开始,寒武纪转向“云—边—端”全场景布局,推出思元系列云端芯片和MLU边缘加速卡,并为所有产品构建了统一的基础系统软件和工具链Cambricon Neuware平台,寒武纪成为一家具备软硬件全栈系统能力的芯片设计公司。
(4)2020年7月20日,寒武纪在科创板挂牌上市。发行价64.39元,上市首日,开盘价即达250元/股,市值突破千亿元,成为国内AI芯片第一股。但2019-2023年累计亏损超27亿元。
(5)2022年底被美国列入实体清单,台积电断供7nm代工,被迫转投中芯国际14nm工艺,性能损失30%,2023年云端芯片收入暴跌58.7%,市值一度跌破500亿。
(6)2024年至今:AI大模型爆发,成为国产算力的里程牌
2024年思元590芯片量产,算力达512TOPS,性能逼近英伟达A100的80%,适配阿里、字节等千卡级大模型集群,单季度营收暴增533%。
2024年营收11.74亿元(+65.56%),2025年Q1营收11.11亿元(同比暴增4230%),首次单季盈利3.55亿元,市值突破4000亿,两年涨幅超10倍。
5、 商业模式
(1)业务模式
采用 Fabless 模式,聚焦芯片设计、研发与IP 授权,将晶圆制造委托台积电、中芯国际代工,封装测试或委托长电科技、通富微等大厂完成。2024 年晶圆采购成本占营业成本78%。
(2)客户结构
主要服务于互联网大厂(阿里、腾讯字节等、运营商(移动、联通)、服务器厂商(浪潮、联想)、金融机构、交通、能源等行业客户,以及政府主导的智能计算集群项目,客户集中度较高,需逐步拓展多元化客户资源。
寒武纪较为依赖单一客户,近三年,公司前五大客户的销售金额合计占营业收入比例分别为84.94%、92.36%和94.63%。其中2024年第一大客户的销售占比就高达79.15%,寒武纪表示该客户为公司长期合作伙伴,并在本期增加采购。但是,客户集中度过高将会是未来寒武纪的主要风险之一。
(3)盈利模式
直销为主通过自有销售团队直接对接客户,参与公开招标或商务谈判,提供定制化解决方案,减少中间环节,增强客户粘性。
通过高研发投入推动技术迭代,依托国产替代需求扩大市场份额,同时借助智能驾驶、大模型推理等新兴场景提升盈利能力。
(4)合作伙伴
寒武纪与华为,阿里巴巴,腾讯,字节跳动等科技巨头均保持合作,另外 ,还与商汤科技、旷视科技共建联合实验室,推出行业解决方案(如金融风控、智能制造)。
二、核心产品和技术
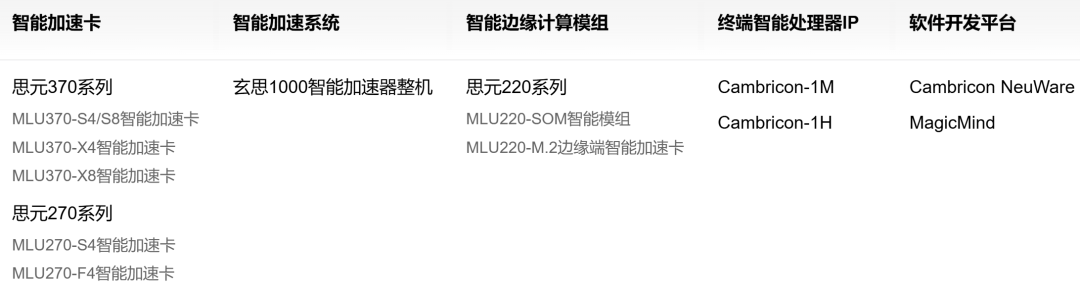
1、产品三大板块:云端-边缘端-IP授权
添加图片注释,不超过 140 字(可选)
寒武纪业务,按产品线划分,主要涵盖云端、边缘端产品线及 IP 授权及软件三大块。其中,云端产品线占营收的99.40%;边缘产品线占营收的0.56%;IP授权及软件占营收的0.04%。

添加图片注释,不超过 140 字(可选)
(1)云端产品:主云端智能芯片及加速卡和训练整机--占比99%
① 主要产品:思元MLU系列芯片(如MLU370、MLU590)
② 产品发布时间:
-
21 年,发布思元 290 智能芯片及加速卡 MLU290-M5,为公司首颗训练用芯片,采用台积电 7nm 工艺,集成寒武纪自研的 MLU-Link 多芯互联技术,可以高效执行多芯多卡训练和分布式推理任务。
-
22 年,发布基于思元 370 芯片的新款训练加速卡——MLU370-X8,为双思元 370 芯片配置,首款采用chiplet技术的AI芯片,集成了390亿个晶体管,最大算力高达256TOPS(INT8)集成 MLU-Link多芯互联技术,主要面向训练任务。
-
23 年,发布最新一代芯片思元 590,性能相比思元 370 有翻倍以上的提升,综合性能对标英伟达 A100,处于国内领先水平。
③ 训练整机加速系统:通常集成多颗 AI 芯片,以玄思1000 智能加速器为例,它在 2U 机箱内集成了4 颗思元290 智能芯片,2 台玄思1000 加速器与 CPU 服务器可组成一套包括 8 张加速卡的整机系统,可实现 AI 算力多向扩展,满足性能、扩展性、灵活性、稳定性的要求。
(2)边缘产品线:边缘智能芯片&加速卡,占营收0.56%
① 主要产品:思远220系列,包括:MLU220 芯片 MLU220-SOM 模组 MLU220-M2 加速卡。 自发布以来,累计销量突破百万片。
思元220是寒武纪专门用于深度学习的SoC边缘加速芯片,采用TSMC 16nm工艺 。具有高算力、低功耗和丰富的I/O接口,在物联网领域发挥重要作用,如智能交通中的车辆识别和监测、工业制造中的产品质量检测等场景,能够在边缘端实现高效的AI推理,减少数据传输压力和延迟。
(3)IP 授权及软件:终端智能处理器 IP 和基础系统软件平台,占0.04%
① 终端智能处理器:
是终端设备中支撑 AI 处理运算的核心器件,例如近年来各品牌旗舰级手机上与图像视频、语音、自然语言相关的智能应用均依靠终端智能处理器提供计算能力支撑。为了提升性能降低功耗,同时节省成本,终端智能处理器通常不是以独立芯片的形式存在,而是作为一个模块集成于终端设备的 SoC 芯片当中。公司的终端智能处理器 IP 产品主要有 1A、1H 和 1M系列。
寒武纪智能处理器 IP 产品已集成于超过 1 亿台智能手机及其他智能终端设备中。
② 基础系统软件平台:
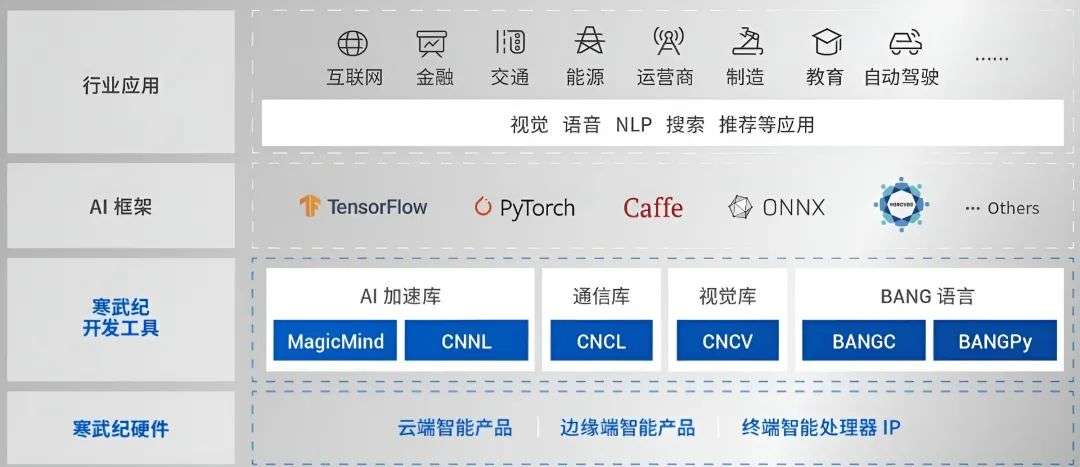
方面公司主要提供统一的平台级基础系统软件Cambricon Neuware(包含软件开发工具链等),效仿07年英伟达推出的CUDA 并行计算框架和编程模型,构筑起的坚实软硬件协同壁垒。
打破不同场景之间的软件开发壁垒,整合了训练和推理的全部底层软件栈,包括硬件驱动、AI 加速算子库(CNNL),通信库(CNCL),开发语言 BANG 等,同时将该软件平台与 Tensorflow、Pytorch 等 AI 框架深度融合,实现训推一体,让开发者可以非常方便地完成从云到端,从模型训练到推理部署的全部流程,提升 AI 算法的开发效率。
下图:寒武纪的“CUDA”——Cambricon NeuWare生态
添加图片注释,不超过 140 字(可选)
2、技术优势
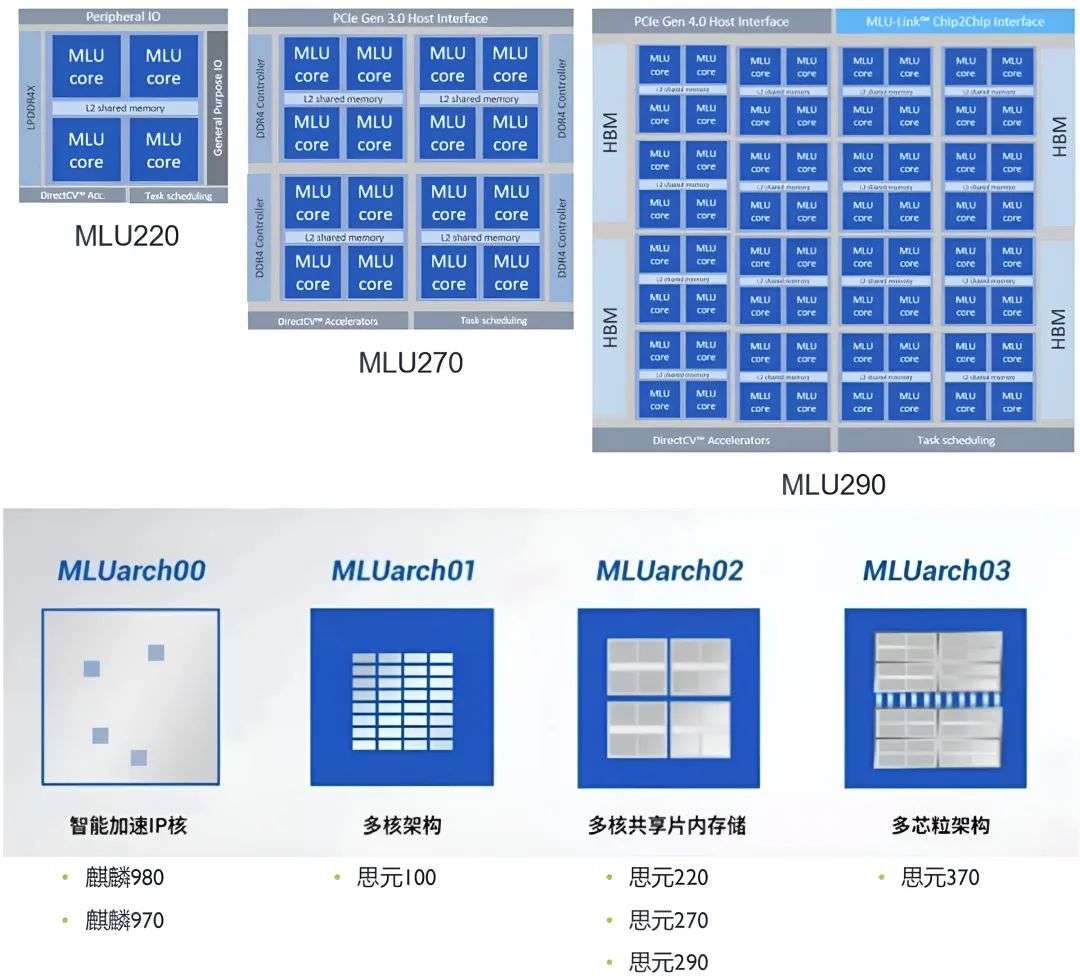
(1)自主可控的MLU arch架构
MLU架构是寒武纪为AI芯片设计的专用架构,全称为Machine Learning Unit Architecture,即机器学习单元架)。它是为高效处理人工智能任务(如深度学习、神经网络计算等)而定制的硬件架构,可广泛应用于云计算、边缘计算、智能安防、自动驾驶等领域。
官方公布的名称分为 MLU00 MLU01 MLU02 MLU03,分别对应于 1A、1H、1M、以及官方尚未公布型号的 MLU370 的处理器内核。具有以下特点和优势:
添加图片注释,不超过 140 字(可选)
① 端云一体可扩展性
MLU架构支持从端侧(如边缘设备)到云侧(数据中心)的灵活扩展。端侧芯片可选择单个核心(TP架构)或单个集群(MTP架构),云侧芯片则通过多个集群(MTP架构)实现高算力并行,支持单机单卡或多机多卡集群加速。
② 核心架构设计
对应单个IPU核心,可独立执行单个任务。由多个IPU核心组成集群,支持并行执行复杂任务。不同代际的MLU架构(如MLUv03、MLUv05)在IPU数量和算力配比上有所差异,但通过硬件兼容性确保程序可二进制兼容运行。
③ 存储与通信优化
存储层次上:包括片上SRAM、L2缓存、片外DDR/HBM等,通过多级缓存和高速互联技术(如MLU-Link)提升数据传输效率。
通信机制上:支持集群内和集群间的数据传输,通过专用通道(如Cluster-DMA)实现低延迟、高带宽通信。
(2)全栈式AI工具链NeuWare
Cambricon NeuWare软件栈是寒武纪芯片的重要支撑。它支持TensorFlow、PyTorch等主流框架 ,提供CUDA代码迁移工具,降低开发者迁移成本,与华为MindSpore、百度PaddlePaddle等国产框架深度适配。
① 开发工具层
MLU架构配套的编程模型为“Cambricon Bang”,提供Host-Device异构并行编程接口,支持C/C++等语言开发,简化AI应用的移植和优化。自动优化算子融合(如Conv+ReLU)、内存复用,编译效率达CUDA的90%。
② 运行时与框架适配
NeuWare Runtime:低延迟任务调度,达到μs级,支持PyTorch/TensorFlow/MindSpore等主流框架零代码迁移。
分布式训练加速库CNCL:万卡集群通信延迟<2μs(对标NCCL),线性加速比达0.93(千卡规模)。
(3)多芯片互联&推理加速引擎
2021 年,公司在发布思元 290 智能芯片时,首次推出自研的 MLU-Link 多芯互联技术,对标英伟达的 NVLink,帮助算力集群执行高效的多芯多卡训练和分布式推理任务。
2022 年,公司发布 MLU370 X8 算卡,搭载了 MLU-Link,为每颗芯片提供 200GB/s 的额外跨芯片通讯能力,带宽是 PCIe 4.0 标准的 3 倍。公司为多卡系统专门设计了 MLU-Link 桥接器,可实现 4 张双芯 MLU370 X8 算卡的互联。
下图:寒武纪的“NVLink”——MLU-Link
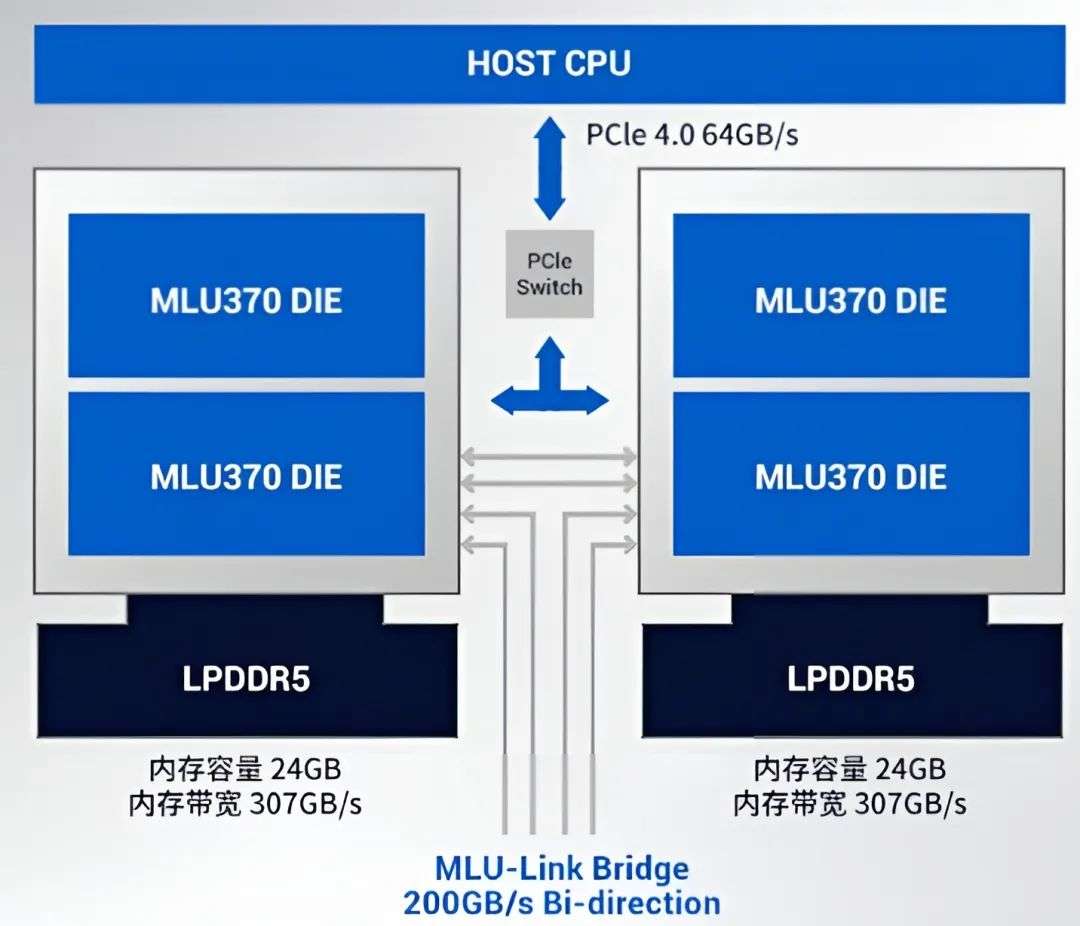
添加图片注释,不超过 140 字(可选)
推理加速引擎技术:拥有业内首个基于MLIR图编译技术达到商业化部署能力的推理引擎MagicMind,用户仅需投入极少的开发成本,即可将推理业务部署到寒武纪全系产品上,并获得颇具竞争力的性能。
(4)战略差异化,垂直行业解决方案
① 定制化IP授权模式
提供芯片-算法协同设计服务,允许客户根据业务需求定制计算单元(如增加特定算子),对比英伟达的通用GPU方案,更贴合垂直场景需求。
在同等算力下,寒武纪加速卡价格约为英伟达A100的60%-70%,且提供本地化技术支持团队,响应速度更快(如48小时内现场调试
② 垂直行业解决方案
在智慧城市领域,寒武纪与海康威视、商汤科技合作,优化视频分析模型的端云协同推理效率。
在自动驾驶领域,其MLU370芯片支持多传感器融合计算,已进入部分车企的云端训练平台供应链。
受益于“东数西算”工程和信创政策,寒武纪被纳入多地智算中心采购名单(如北京、上海人工智能算力平台),替代国际厂商份额。
三、市场空间与竞对
1、 市场空间:算力供需缺口巨大
需求端:2025年中国企业AI算力投入约1200亿美元,50%资金用于AI芯片采购,预计需求300万-400万张卡(按每卡10万元估算)。
供给端:英伟达H20芯片受限(实际到货仅50万张),叠加华为等国产产能不足,全年存在150万-200万张卡的缺口,2026年缺口或扩大至200万张以上。
寒武纪的替代空间:凭借下一代训练芯片(如思元590/690)性能提升70%-80%,2025年产能规划翻倍,有望承接超30%的国产替代需求。
2024年全球AI芯片市场份额,英伟达、AMD、英特尔三家共占比91%,其中,英伟达一家就高达80%,寒武纪市场占比约1%。
下图:全球2024年AI芯片市场份额
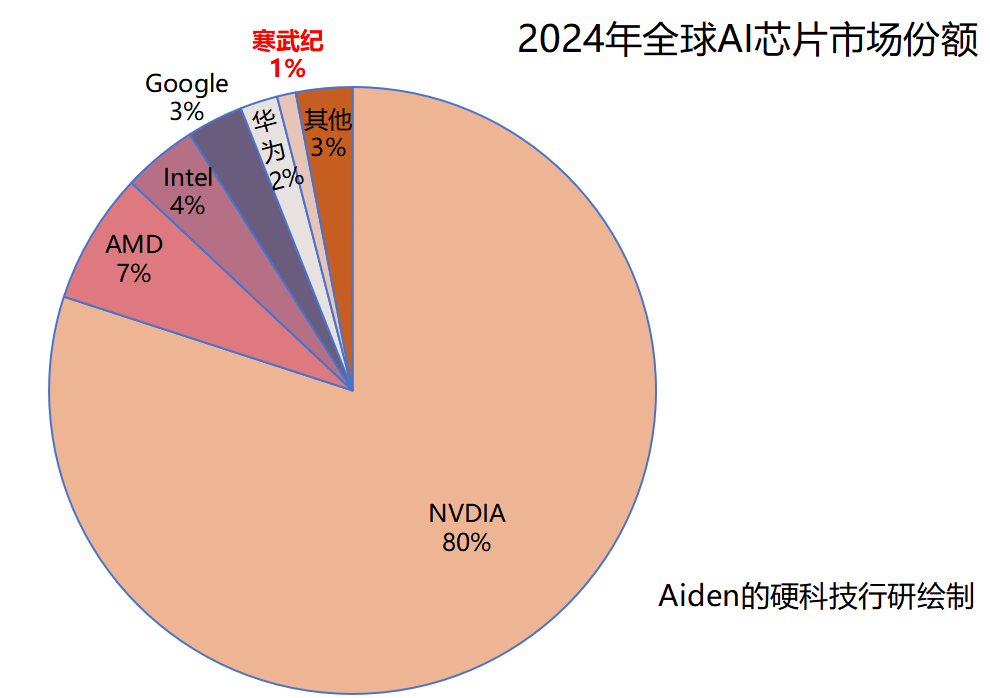
添加图片注释,不超过 140 字(可选)
2、政策与生态催化
美国对华芯片管制升级,H20特供芯片性能仅为高端型号的20%,且可能预埋“远程自毁”功能。 中国监管层限制英伟达低端芯片在敏感领域使用,推动寒武纪在互联网、政企市场中份额提升。
另外,借力国产AI框架(如DeepSeek)构建替代生态,逐步削弱CUDA垄断壁垒。
3、竞争对手格局
国际巨头英伟达的生态霸权 :CUDA生态垄断全球近90%AI软件开发。 寒武纪思元590,采用7nm制程,其整体性能约为英伟达A100的80%,而A100本身性能弱于H100。这意味着思元590与H100(4nm制程)相比甚远。
下图:国内外主要竞对:
另外,沐曦集成:全国产化GPU,自研GPGPU架构,支持PyTorch、TensorFlow等框架,实现“端到端”任务调度,直接对标英伟达高端芯片,且获国资背景基金加持,在技术和资金方面都有一定实力。
壁仞科技:其首款通用GPU芯片BR100系列采用7nm制程,集成770亿颗晶体管,单芯片峰值算力达PFlops级别,FP32算力超1000TFlops,INT8算力超2000TOPS,性能对标国际旗舰产品,峰值算力是英伟达A100的3倍以上。
同时阿里等互联网厂商也在使用自研芯片,这些都对寒武纪构成了竞争压力。
四、产业链
AI 芯片产业链上游:主要包括 芯片EAD设计工具、AI 算法与IP授权;
中游:晶圆制造、代工和封测环节;
下游:应用包括但不限于 AI大模型、云计算、智能驾驶、智慧医疗、智能穿戴、智能机器人等。
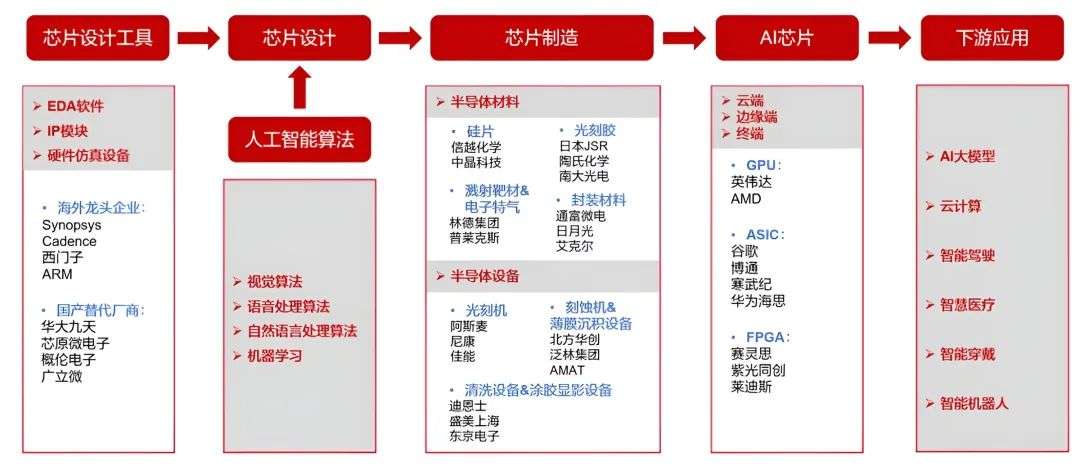
添加图片注释,不超过 140 字(可选)
1、上游:芯片设计和IP授权等
(1)芯片设计与IP授权
AI 算法主要包括视觉算法、语言处理算法、自然语言处理算法、机器学习等,芯片设计工具主要涵盖 EDA 软件、IP 模块与硬件仿真设备。
设计公司:寒武纪专注于AI芯片设计,提供云端(如思元系列)、边缘端芯片及IP授权。
EDA工具与IP供应商:华大九天(EDA工具)、芯原股份(IP授权)等,为寒武纪芯片设计提供技术支持。
2、中游:芯片制造&封装
(1)半导体材料与设备
材料:沪硅产业(硅片)、江丰电子(靶材)、晶瑞电材(光刻胶)等,为芯片制造提供基础材料。
设备:中微公司、北方华创、拓荆科技、华海清科等,提供光刻、刻蚀、薄膜沉积、CMP设备等关键设备,支撑芯片制造工艺。
(2)晶圆制造
① 代工厂:中芯国际(14/7nm工艺)、华虹公司(28nm及以上工艺),负责寒武纪芯片的晶圆制造。
② 封装测试:封测企业,长电科技、通富微电、华天科技等,完成芯片封装与测试环节,确保芯片性能稳定。
3、下游:应用
AI 芯片按照应用场景的不同可分为云端、边缘端及终端 AI 芯片,下游应用包括但不限于 AI大模型、云计算、智能驾驶、智慧医疗、智能穿戴、智能机器人等。
(1)AI服务器:浪潮信息(全球市占率领先)、中科曙光(国产服务器龙头),新华三等,集成寒武纪芯片用于智能计算设备或数据中心。
(2)互联网:字节跳动、腾讯、阿里等互联网大厂企业采购寒武纪芯片用于AI训练与推理。
-
(3)金融能源和安防等应用:银行、证券机构利用寒武纪芯片进行风险评估、智能投顾等;海康威视等企业可能采用寒武纪芯片提升视频分析能力;国家电网等企业用于智能电网监测与优化。
五、“寒王”总结&展望
寒武纪作为中国AI芯片领域的英伟达,近年以业绩拐点与股价狂飙成为市场焦点,但繁花之下,其崛起与隐忧交织。
2025年第一季度,寒武纪营收同比暴增4230%至11.11亿元,净利润3.55亿元,实现上市以来首次连续季度盈利。这一里程碑式突破,源于思元590芯片在大模型训练场景的规模化落地——其性能对标英伟达A100,支撑阿里、腾讯等巨头的算力需求,推动云端业务收入占比达99.3%。供应链端,中芯国际14nm工艺良率提升,下半年月产能有望翻倍至3-4万颗,彻底扭转“有单无货”的困局。政策东风下,国产替代加速,寒武纪在政府智算中心市占率已达28%,成为“东数西算”工程的核心参与者。
资本市场对寒武纪的热捧,是技术突破与产业逻辑的双重映射。2024年股价涨幅387%,2025年市值一度突破4000亿元,背后是三重驱动:
其一、技术代差弥合:思元590在Transformer模型训练效率上达业界领先水平,新一代思元690送测数据显示性能逼近H100的80%;其二、国产替代刚需:英伟达H20芯片安全漏洞、性能缩水(仅为高端型号20%),叠加审批延迟,使寒武纪成为互联网大厂唯一可规模化采购的高性能算力供应商;其三、生态价值重估:与DeepSeek合作开源FlashMLA技术,降低大模型推理成本,推动开发者社区从10万向百万级跃迁。
尽管光芒耀眼,寒武纪仍需跨越三重险滩:
首先,是客户集中度之困:2024年第一大客户贡献79.15%营收,过度依赖头部企业的采购周期,若该企业等自建算力集群,业绩可能断崖式下跌。
其次,是研发投入之惑:虽然2024年研发占比达91.3%,但研发人员从2022年的1205人锐减至752人,技术迭代速度面临压力。
然后,就是生态构建之难:英伟达CUDA开发者超500万,而寒武纪MLU生态尚处襁褓,仅10万左右开发者,软件适配成本高企制约商业化进程。
至于估值是否存在大泡沫,或许仁者见智。目前动态PE超280倍,已差不多将透支2026年的业绩;若产能(中芯7nm良率75%)或生态(算子覆盖率85%)不及预期,恐引发估值重构。不过,这轮国产替代的东风,背后的隐秘力量,也是值得深思和警惕!

添加图片注释,不超过 140 字(可选)
总之,站在AI算力革命的十字路口,寒武纪既是国产替代的先锋,也是技术长征的先行者。其未来的价值,不仅在于芯片性能的突破,更在于能否构建起媲美英伟达的“硬件+软件+开发者”生态帝国。
正如寒武纪在财报中所言:“我们始终相信,人工智能的未来,属于那些敢于在算力荒原中播撒火种的拓荒者。”
在这场没有硝烟的科技战中,寒武纪能否从“国产替代者”蜕变为“全球定义者”,中国的AI芯片能否不再被卡脖子?答案或许就藏在思元芯片闪烁的晶体管里,写在开发者社区一行行代码中,亦或镌刻在每一位科技奋斗者,坚定的眉宇间!
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号