
VLA-RL:以在线强化学习赋能 VLA
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
-
论文标题
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
-
论文链接:
https://arxiv.org/abs/2505.18719
-
代码链接:
https://github.com/GuanxingLu/vlarl
技术细节概要
轨迹级 RL 建模:将机器人的完整操纵轨迹(如 “看到杯子→移动机械臂→抓住杯子→放到桌上”)建模为 “多模态多轮对话”(结合视觉信号、语言指令、动作序列的交互过程),使强化学习能更自然地优化整个任务流程。
解决 “稀疏奖励” 难题:机器人任务中,“奖励”(如 “成功抓握”)往往很稀疏(大部分步骤没有明确反馈)。研究通过微调预训练的视觉 - 语言模型作为 “奖励模型”,利用自动提取的任务片段(如 “抓握动作的关键阶段”)生成 “伪奖励标签”(模拟真实奖励的标注),让模型能在训练中获得更密集的反馈。
研究背景与现有问题
现有机器人模型(VLA 模型)的 “硬伤”
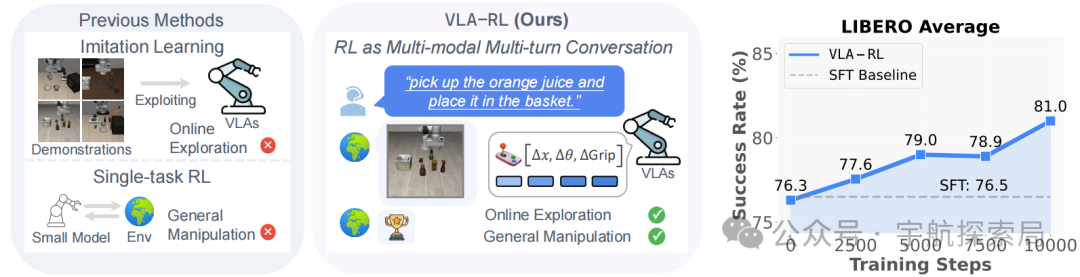
现在的机器人模型(比如 VLA 模型)很厉害,能通过 “模仿人类演示” 在机器人操纵任务中表现出色,学会做很多事,比如抓杯子、放东西。但它们有个致命问题:只会重复学过的内容,不会应对新情况。
这些模型靠 “离线数据” (即训练前收集的固定数据)训练,也就是训练前收集的固定演示视频(比如人演示 100 次抓杯子的动作)。
但现实世界太复杂了,离线数据覆盖的 “状态”(如机器人可能遇到的环境情况、物体位置等)有限,训练数据不可能覆盖所有情况(比如杯子被碰歪了、光线突然变暗),当遇到训练中未见过的 “分布外场景”(如物体摆放位置异常、环境光线变化等)时,模型就会 “懵圈”,比如本来学的是抓桌子中间的杯子,遇到杯子在桌子边缘就抓不住了。
核心解决方案:VLA-RL 框架
为解决上述问题,提出了 VLA-RL 框架,核心思路是引入 “在线强化学习(RL)”:不再仅依赖离线数据,而是让模型在测试时通过实时探索环境、收集新数据,并通过强化学习持续优化自身,从而适应分布外场景。
为什么想到用强化学习(RL)解决?
引入强化学习的 “探索能力” 可能是破局的关键。这是因为强化学习的核心是 “试错学习”:机器人自己在环境里尝试,成功了就 “奖励”,失败了就 “惩罚”,慢慢学会应对各种情况,而不是只靠别人教。
这种方法在大型语言模型(比如 ChatGPT 这类)上已经被证明有效:光靠模仿人类文本有上限,用强化学习让模型 “自己跟自己对话、纠错”,性能会提升很多。
那机器人领域能不能照搬这个思路?让机器人在实际操作中自己探索,不断优化动作,而不是只依赖固定的演示数据?这就是研究的出发点。
传统强化学习的 “坑”,以及 VLA-RL 的解决思路
以前不是没人给机器人用强化学习,但效果不好,主要因为两个 “坑”:
首先就是太费数据,太麻烦:传统强化学习要 “从零开始学”,机器人得试成千上万次才能学会一个简单动作,还需要人工设计 “奖励规则”(比如 “抓住杯子加 10 分”),成本太高。
其次是只能学简单任务:以前的研究大多局限在单一任务(比如只学抓球),或者简单环境(比如固定位置的物体),换个任务就不行了。
而新提出的 VLA-RL 框架,就是为了避开这些 “坑”:
添加图片注释,不超过 140 字(可选)
首先,避免重复造轮子,而是将所有的工作建立在 “巨人的肩膀上”,是用已经预训练好的 VLA 模型(比如 OpenVLA-7B)当基础,再用强化学习微调。这些预训练模型已经懂很多通用知识(比如 “杯子是圆的,要抓边缘”),能大幅减少学习难度。
其次,巧妙地将机器人动作变成 “对话”:将机器人的整个操作过程(看图像→听指令→动胳膊)建模成 “多轮对话”,就像人和机器人聊天一样,让强化学习能更自然地优化整个流程。
最后,也是最关键的,就是解决 “奖励稀疏” 的问题:机器人操作中,“成功” 的奖励很少(比如只有最后把杯子放进篮子才算成功),中间步骤没反馈。VLA-RL 专门训练了一个 “奖励模型”,能给中间步骤打分(比如 “胳膊快碰到杯子了,加 2 分”),让学习更高效。
VLA-RL 的效果:真的有用吗?
实验表明,在 40 个复杂任务(比如 “把黑碗从架子上放到盘子里”)的测试中,用 VLA-RL 优化后的 OpenVLA-7B,比单纯模仿学习的模型成功率高 4.5%,甚至快赶上商用的顶级模型了。
更重要的是,机器人 “学的时间越长,表现越好”:测试时让机器人多探索、多优化一会儿,成功率会持续上升。这暗示未来可能像训练大语言模型一样,只要给够时间,机器人性能能不断提升 —— 这在机器人领域是个新发现。
Related Work(相关工作):
机器人基础模型:“能模仿,但不会变通”
目前由很多 “机器人基础模型”(比如 OpenVLA-7B)。
这些模型就像 “机器人界的学霸”,通过学习海量的人类演示数据(比如成千上万次抓东西、放东西的视频),能学会做很多任务,而且能举一反三(比如学会抓杯子后,也能抓瓶子)。其中 OpenVLA-7B 很有代表性,它把机器人的动作(比如 “移动 3 厘米”)转换成类似文字的 “token”,就像用语言描述动作,泛化能力很强。
但这些模型本质是 “模仿秀”—— 只能学已有的演示,遇到没见过的情况就歇菜。比如训练时学的是 “在平整桌面抓杯子”,如果杯子放在凹凸不平的垫子上,就可能抓不住。这是因为它们依赖 “离线数据”,没覆盖到所有场景。
机器人领域的强化学习:“想试错,但起点太低”
传统思路的问题:强化学习的核心是 “试错”(比如机器人自己尝试抓杯子,抓对了加分,抓错了扣分),但以前的方法太 “笨”:
要么 “从零开始学”:机器人连基本的 “怎么动胳膊” 都要自己试,效率极低,还需要人工设计复杂的 “评分规则”(比如 “碰到杯子加 1 分,抓住加 10 分”),成本很高;
要么 “依赖固定数据”:就算用了预训练模型,也得一直拿着完整的离线数据集反复学,不能自己在新环境中探索;
要么 “任务太简单”:只能学单一任务(比如只学抓球),用简单的模型结构(比如 MLP),换个任务就不行了。
VLA-RL 则不同,直接用已经 “学过很多知识” 的大型机器人基础模型当 “起点”,再用强化学习微调。就像让一个会做饭的人学做新菜,比教一个完全不会做饭的人快得多。这些基础模型的 “知识” 能帮机器人少走弯路,更快学会复杂动作。
大型语言模型的强化学习:“能推理,可借鉴”
大语言模型的成功经验:比如 ChatGPT,光靠模仿人类文本是不够的,后来用强化学习让它 “自己跟自己对话、纠错”,推理能力(比如解数学题、逻辑分析)大幅提升。这里有两个关键方法:
“过程奖励”:不光看最终答案对不对,还看中间思考步骤(比如解数学题时,公式列对了也给分);
“多轮对话优化”:把对话当成一个连续过程,不断优化每一轮的回应。
VLA-RL将这些经验借鉴到机器人领域,把机器人的整个操作过程(看图像→听指令→动胳膊)当成 “多模态对话”(就像机器人 “说” 出动作,环境 “回应” 结果),用类似大语言模型的强化学习方法优化。这样机器人不光能完成任务,还能像人一样 “思考中间步骤”,比如 “先调整胳膊角度,再抓杯子”。
VLA-RL 框架“用大型机器人基础模型当起点 + 借鉴大语言模型的强化学习方法”—— 正好能填补目前业界的短板和空白。
添加图片注释,不超过 140 字(可选)
图 1:以往的 VLA 模型侧重于利用离线演示数据的模仿学习,而 VLA-RL 则探索通过可扩展的强化学习来改进高容量 VLA 模型。在评估中,通过训练 OpenVLA-7B 以掌握 LIBERO 中的 40 项具有挑战性的机器人操纵任务,并展示出其相对于模仿学习基线的显著且稳定的提升。
VLA-RL技术说明书
“原料”(3.1 预备知识)
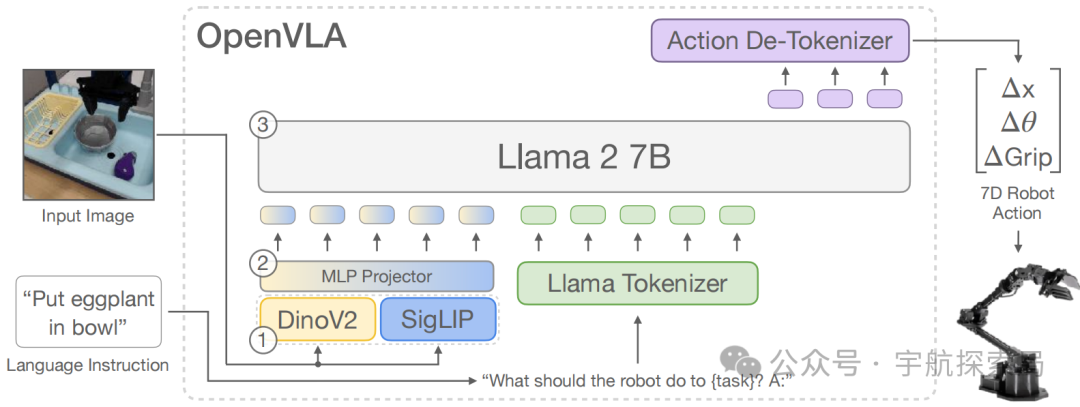
VLA-RL 不是从零造模型,而是 “站在巨人肩膀上”—— 以现有的 OpenVLA-7B 模型为基础。OpenVLA-7B是业界领先的开源 VLA 模型,以Llama-2-7B为核心,搭配由预训练的 SigLIP 和 DinoV2 模型组成的双流视觉编码器。
添加图片注释,不超过 140 字(可选)
在每个时间步t,模型接收相机捕捉的图像和人类指令作为输入,输出动作 token 序列,其中每个动作 token 代表机器人动作空间某一维度的离散区间。最终的机器人动作通过后处理函数f从该序列中提取。优化自回归 VLA 模型在算法和系统层面都面临挑战,包括通用操纵任务的强化学习设计、奖励稀疏问题以及大规模评估与优化等。
OpenVLA-7B模型的特点是能 “看懂图像”(通过双流视觉编码器)、“理解文字指令”(比如 “把杯子放进篮子”),并 “输出机器人动作”(比如机械臂移动的具体参数)。
但它有个弱点:靠模仿人类演示学习,遇到新情况容易出错。VLA-RL 要做的就是给它加上 “自主学习” 的能力。
整体流程:VLA-RL 是个 “流水线”(3.2 整体流程)
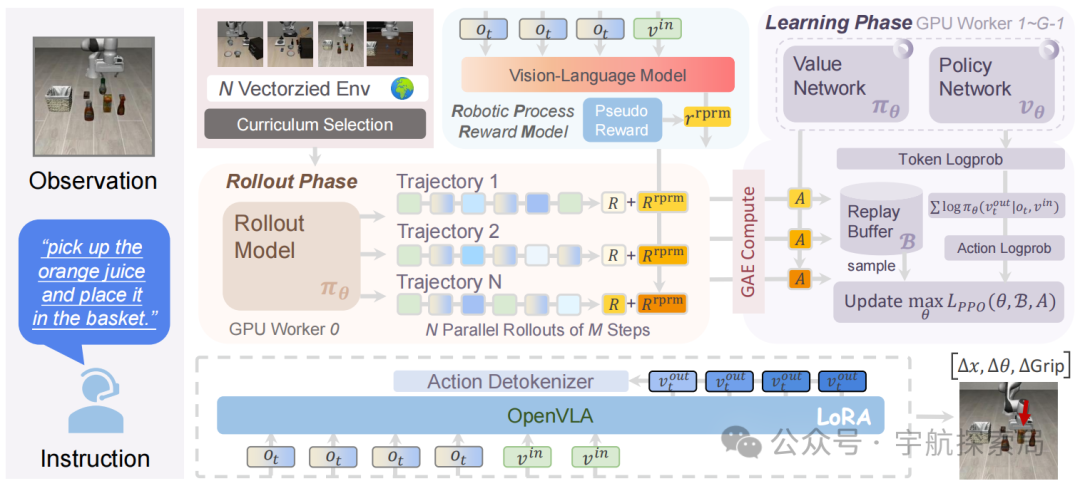
添加图片注释,不超过 140 字(可选)
VLA-RL 的整体流程,由基于 Transformer-based policy、homogeneous value model、frozen robotic process reward model和vectorized environments构成
想象 VLA-RL 是一个让机器人 “不断进步” 的流水线,主要有三个核心部件:
• 策略模型:负责 “做决定”,比如 “下一步机械臂往哪动”。
• 价值模型:负责 “评好坏”,判断当前动作的潜在收益(比如 “这个动作有 80% 概率能抓到杯子”)。
• 机器人过程奖励模型:负责 “给反馈”,在任务完成前就告诉机器人 “做得怎么样”(比如 “快碰到杯子了,加 2 分”)。
这三个模型配合向量化环境(多个虚拟场景并行训练),让机器人在大量场景中快速试错、学习,效率比单个场景训练高得多。
核心创新 1:把 “抓杯子” 变成 “聊天”(3.3 多模态多轮对话建模)
传统机器人学中,强化学习通常只优化 “单步动作”(比如 “这一秒往哪动”),但 VLA-RL 的关键是优化 “整个过程”。它把机器人操纵的完整轨迹(从 “看到杯子” 到 “放进篮子”)当成一场 “多模态对话”:
“视觉输入”(图像)是 “环境说的话”,“文字指令” 是 “人类说的话”,“机器人动作” 是 “机器人的回应”。
这样一来,强化学习就能像优化对话连贯性一样,优化整个操纵过程的流畅性(比如 “先移动到杯子上方,再闭合 gripper” 比 “乱晃机械臂” 更合理)。
同时,用 PPO 算法控制学习节奏,避免机器人 “学太猛”(比如突然大幅改变动作模式导致出错),确保稳定进步。
算法细节如下:

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
采样阶段:首先将更新后的 LoRA 权重与原始检查点合并,并广播到推理引擎。然后智能体根据当前策略与环境交互,生成状态、动作和奖励序列(即轨迹)。在自回归模型中,动作序列的对数概率可分解为 token 级对数概率的总和,其中(|A|=7)是 OpenVLA 动作空间的自由度。:
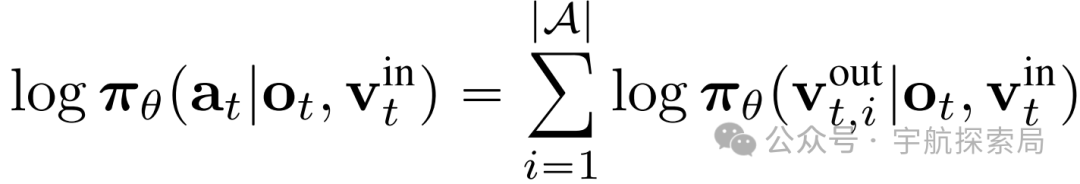
添加图片注释,不超过 140 字(可选)
学习阶段:PPO 目标函数使用带裁剪的重要性采样确保稳定更新:
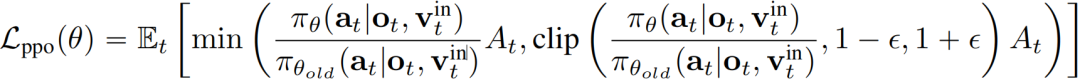
添加图片注释,不超过 140 字(可选)
其中epsilon是裁剪参数,限制新旧策略的比率,防止过度更新。每个状态的优势At通过广义优势估计(GAE)计算。整体过程总结于算法 1。

添加图片注释,不超过 140 字(可选)
核心创新 2:给机器人 “实时打分”(3.4 机器人过程奖励模型)
机器人学的一大难题是 “奖励太少”:比如 “把杯子放进篮子”,只有最后成功了才给 10 分,中间步骤(比如 “碰到杯子”“抓起杯子”)都没分,机器人很难知道 “哪步做得对”。
VLA-RL 的解决办法是造一个 “过程裁判”,机器人过程奖励模型需满足:(1)在自然稀疏反馈的环境中提供密集奖励;(2)避免奖励欺骗(智能体以非预期方式利用奖励函数)。
怎么打分?
通俗解释是 “过程裁判”会看机器人的动作序列,预测 “下一步该做什么才对”(类似猜下一个词的概率),做得对就加分。
具体而言就是作为下一个 token 预测的奖励建模:利用预训练视觉 - 语言模型的自回归特性,将奖励建模重构为下一个 token 预测问题。给定状态和动作轨迹,机器人过程奖励模型(RPRM)预测成功动作序列的可能性。训练目标是最大化有前景的动作 token 的对数似然,并以指示任务完成进度的伪奖励信号为权重:
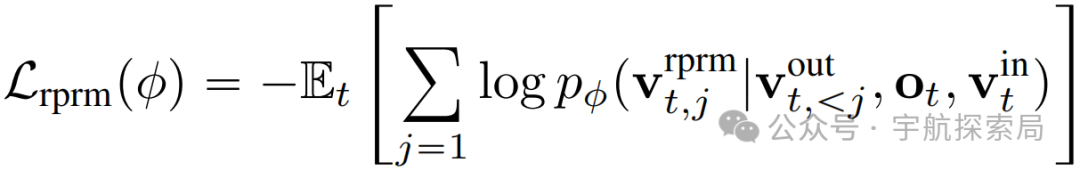
添加图片注释,不超过 140 字(可选)
分从哪来?
通俗解释是从成功案例中 “自动学”:比如从 100 次成功抓杯子的视频中,找出关键步骤(比如 “gripper 刚好碰到杯子时速度变慢”),给这些步骤打 “伪奖励分”,不用人工标注。
具体而言,开发了自动标签生成流程,以方便在无需大量人工标注的情况下有效训练机器人过程奖励模型,从成功轨迹中创建高质量伪奖励标签:(1)里程碑分割:收集来自专家演示和模型先前运行的多样化成功轨迹数据集,根据 gripper 开合度的显著变化将轨迹分割为子任务(这些变化通常标志着功能步骤的完成);(2)进度标注:在每个分割的子任务中,识别机器人末端执行器速度接近零的关键帧(这些点通常对应稳定状态或细粒度运动的完成),为导致这些关键帧的 VLA 动作序列分配正伪奖励。
这样,机器人每走一步都能得到反馈,学习效率大大提高。
实用技巧(3.5 VLA-RL 系统)
VLA-RL 开发了四个tricks以确保系统高效稳定:
• 从易到难学(课程选择策略):按难度梯度选择训练任务,逐步提升模型能力。先捡成功率 50% 左右的任务(比如 “抓大杯子”)训练,再挑战难的(比如 “抓小勺子”),避免机器人 “挫败感太强”。
• 先学 “评价” 再学 “做事”(评论者预热):让价值模型先单独练习 “判断动作好坏”,让其成为一名合格的“评论者”,再联合训练策略模型,让策略模型成为一名 “执行者”,避免一开始 “瞎评价” 误导决策。这是因为从零开始训练价值模型(评论者),其初始价值估计不准确,可能在训练早期误导模型。
• 多 GPU 分工(GPU 平衡的向量化环境):多个 GPU 各管一批虚拟场景,互不抢内存,同时开工收集数据,速度翻倍。
• 精打细算用资源(基础设施):用高效的计算格式和分布式训练工具,同时处理多个动作序列的解码,让大模型在有限 GPU 内存中跑起来。
VLA-RL 部分的核心是:通过 “多模态对话建模” 让强化学习能优化完整操纵过程,通过 “过程奖励模型” 解决反馈稀疏问题,再用一系列工程技巧确保系统能跑、跑得快。最终目标是让机器人从 “只会模仿” 变成 “能自主探索、持续进步”。
Experiments
为了验证 VLA-RL 的有效性,该团队设计了系统实验,实验结果回答了如下四个核心问题:VLA-RL 到底好不好用?是否计算量越高越好用?为什么比传统模型更稳健?每个组件是否必要?
实验核心目标:搞清楚 VLA-RL 到底行不行
研究者设计实验主要想回答四个问题:
• VLA-RL 在主流机器人任务上表现如何?
• 测试时给它更多计算资源(比如让它多 “思考” 一会儿),性能会提升吗?
• 为什么 VLA-RL 比传统 “模仿学习”(SFT)更能应对新情况?
• 框架里的每个技术(如奖励模型、课程策略)是不是都必不可少?
实验 “舞台”
为了公平对比,实验用了一个叫 LIBERO 的主流机器人测试集,该测试集聚焦于如下四类任务:
• 空间任务(LIBERO-Spatial),聚焦空间关系,比如 “把杯子放在盘子左边”;
• 物体任务(LIBERO-Object),聚焦物体类别,比如 “抓起黑色的碗”;
• 目标任务(LIBERO-Goal),聚焦目标对象,比如 “把果汁放进篮子”;
• 长序列任务(LIBERO-Long),聚焦扩展序列挑战,比如 “先放汤盒,再放奶酪盒”。
每个任务都测试 500 次,确保结果可靠。
关键结果 1:VLA-RL 性能远超传统模型
对比了多种主流方法后,VLA-RL 表现突出:
VLA-RL 使 OpenVLA-7B 在 SFT 和 DPO 基础上分别提升了 4.5% 和 1.8%,证明了在线强化学习和所提 VLA-RL 框架的有效性。并且,VLA-RL仅经过 48 GPU 小时的强化学习训练,微调后的 OpenVLA-7B 就达到了先进商用模型 π₀-FAST(基于高质量 SFT 数据训练)的性能水平,且性能仍呈持续上升趋势。
这说明 VLA-RL 的 “在线强化学习” 思路确实有效 —— 机器人通过自己试错,比只靠模仿学得更好。
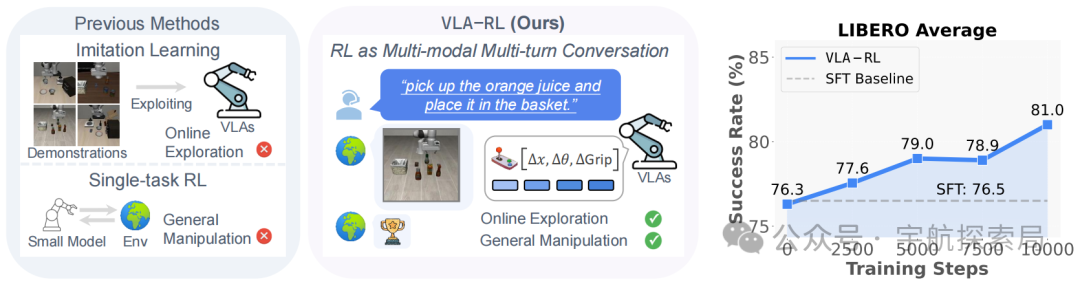
关键结果 2:计算量越多,性能越好(测试时缩放)
实验发现一个重要现象:VLA-RL 在测试时 “算得越久”(比如多试几次、多优化几步),成功率越高。比如在长序列任务中,训练步数从 0 增加到 10000,成功率从 53.7% 涨到 59.8%。
这暗示机器人领域可能存在 “推理缩放定律”—— 就像大语言模型 “参数越多越聪明”,机器人模型 “测试时计算量越多,表现越好”,为未来性能提升指明了方向。
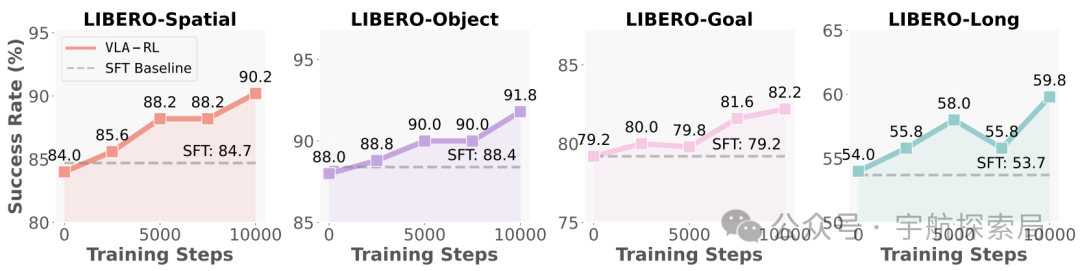
添加图片注释,不超过 140 字(可选)
Test-time Scaling曲线。每2500个训练步骤对微调后的OpenVLA-7B模型在完整任务套件上进行评估,并统计平均任务成功率。
关键结果 3:关键指标
可以通过如下四个关键指标,来 “透视” VLA-RL 是如何学习的,以及为什么能学好:
1. episode 长度:机器人越来越 “高效”
episode 长度可以理解为完成一个任务需要的 “步骤数”。比如抓杯子,一开始可能需要 10 步(移动、调整角度、再移动……),后来可能 5 步就搞定了。
实验发现VLA-RL 训练过程中,episode 长度越来越短。这说明机器人学会了更简洁的动作序列,不用 “绕弯路” 了。
语言模型(如 ChatGPT)强化学习时,生成的文本越长可能越聪明(比如推理步骤更详细);但机器人不一样,动作越简洁说明越熟练,这符合实际操作逻辑。
2. 奖励动态:机器人 “进步稳定”
这里的奖励指的是机器人做动作时得到的 “分数”(比如靠近杯子加 2 分,抓住加 10 分)。
实验发现奖励分数整体一直在涨,但中间会有 “平台期”(比如停在某个分数一段时间不动)。这些平台期往往对应着 “课程切换”—— 比如从简单任务(抓大杯子)切换到难任务(抓小勺子),机器人需要适应一下才能继续进步。
奖励涨得好,且和实际成功率(比如真的抓住杯子的次数)高度相关,说明设计的 “机器人过程奖励模型” 很靠谱,给的分数能真实反映机器人的进步。
3. 策略的采样熵:机器人 “既敢试又不乱试”
VLA的熵可以理解为 “动作的随机性”。熵太高,机器人就会 “瞎动”(比如机械臂乱晃);熵太低,机器人会 “不敢动”(只会重复同一个动作)。
实验发现:VLA-RL 的熵一开始适中(允许机器人多尝试不同动作),随着训练逐渐降低(慢慢找到最优动作,减少瞎试)。这种 “先探索后收敛” 的模式,让机器人既能发现新方法,又能稳定掌握熟练动作。
4. 时间分析:算力花在 “刀刃上”
时间成本分布就是训练时,时间都花在哪些环节(比如模拟环境、模型计算、数据处理等)。
实验发现通过 “GPU 平衡的向量化环境” 和 “vLLM 加速” 这两个技术,模拟环境和生成动作的时间大大减少。现在主要时间花在 “模型训练” 上(比如更新神经网络参数)。
这说明系统优化得很好,把算力集中在了最能提升性能的 “训练阶段”。未来只要再优化训练效率,整体性能还能再上一个台阶。
关键结果 4:每个组件都 “缺一不可”(消融实验)
研究者还做了 “消融实验”,去掉 VLA-RL 的某个组件,看性能会不会下降。结果很明显:
• 去掉 “机器人过程奖励模型”(中间步骤打分):成功率从 90.2% 降到 85.8%—— 证明中间反馈很重要;
• 去掉 “课程策略”(从易到难学任务):成功率降到 88.0%—— 说明循序渐进学更高效;
• 不做 “评论者预热”(先训练价值模型):成功率暴跌到 80.0%—— 可见初期准确评估很关键。
这说明 VLA-RL 的每个设计都是经过验证的,少一个都不行。
为什么 VLA-RL 更稳健?动作覆盖更广
对比传统模仿学习(SFT)和 VLA-RL 的动作分布发现:
• SFT 模型的动作很 “死板”,集中在人类演示过的 “安全区”(比如总在桌子中间抓东西);
• VLA-RL 的动作分布更 “灵活”,能覆盖整个空间(比如桌子边缘也能抓)。
就像人一样,见过更多情况,自然更能应对突发状况。比如 “抓黑碗” 任务中,VLA-RL 能精准对齐抓取点,而 SFT 模型会抓偏。
综合结论
VLA-RL 通过 “在线试错 + 科学设计”,在机器人操纵任务上实现了显著突破:性能远超传统模型,能应对更多新场景,且计算量增加时性能持续提升。这不仅证明了强化学习对 VLA 模型的价值,也为通用机器人的发展提供了可行路径。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号