
揭秘AI芯片:CPU/GPU/NPU从计算到微架构
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
人工智能和芯片,二者宛如我们这个时代里最耀眼的双胞胎一般,在各个层面上都已然造成了深远的影响,而理解我们这个时代最好的方式,我想,就是抽丝剥茧,以最为基本原理来回答一些“为什么”的问题。这篇文章会从计算任务出发,介绍CPU/GPU以及NPU(华为昇腾 )的微架构设计以及使用思路。 (一)引言 大概在一几年左右,深度学习,这个从名词“AI”诞生后第一次取得了通用应用潜力的概念开始进入公众视野,后来在图像识别,语音识别的战绩已经成了几乎每一篇相关文章都要提一句的背景故事,相关的一些研究也成为了自人类发明“引用量”这个词以来,所有学科里引用最高的一类文献之一,比如ResNet。 我在过去的工作中也尝试过将深度学习应用到机器人控制,自动驾驶里。后来因为各种各样的原因,注意力转向了深层神经网络赖以寄居的各种硬件,比如3090,A100,以及各种各样的其他嵌入式/专用算力芯片和集群中。 在学习基础知识的过程里,关注的问题也从16/17年的:为什么要用卷积,L1正则化等变成了: * 为什么从深度学习时代开始神经网络就要放在GPU上训练? * 一些针对神经网络的专门架构(DSA)如NPU/TPU到底是什么? 诚然,如果在应用层考虑:需求如用python+tensorflow和后来的pytorch跑一跑数据集,看看结果,调一调参数,那么答案自然就是:“快”。毕竟时间,在迭代如此之快的AI行业里还是很宝贵的,所以大家也争相推出算得快的工具。而如果要回答为什么快,这个问题,就需要深入到神经网络的结构与其运行于上的硬件里了。 (二)软件驱动的硬件设计 硬件设计终究是为软件计算服务的,所以稍微展开一点软件层面,从多层感知器到深度学习再如今的大模型,其实这类用神经网络的AI,其计算序列基本都是线性的:前一层算出来结果传递到下一层,以此类推。计算任务的绝大部分操作也基本都是矩阵的加乘法,加上一些特殊函数(激活函数等),以及其他操作(一些非线性的,带递归的操作可以展开成线性序列,特殊算子也可以分解成矩阵运算等,此类主题这里不详细描述了)。 硬件层面,从芯片设计的角度,在芯片尺寸不变的条件下,将一部分面积分配给缓存-分支预测,那么势必会挤压用来实现计算的面积,如前所述,由于神经网络的计算序列是基本线性的,计算操作也可以归类到固定的几种,所以对神经网络做优化的思路自然是: 1)砍掉缓存-分支预测。 2)增大芯片尺寸/提高晶体管密度。3)将已有单元为计算任务做专门电路设计。(此处的分类比较粗糙,也有一些更先进的技术也可以提高芯片性能,这里不做展开)。 砍掉缓存-分支预测,这一点在CPU上是不可行的,因为CPU的目的就是做一些通用的计算-从运行操作系统的内核,调度进程,到日常办公,上网冲浪。这些任务的特征为处理数据量小,但流程复杂,即分支很多。后来CPU厂商,也针对一些数据处理任务,如多媒体,扩展了专用的指令集,针对线性代数的一些从神经网络到有限元分析等领域都密集出现的操作,也做了单独的硬件电路和相关指令。CPU厂商推出了各种各样的指令集,各种软件和硬件支持,也需要有相应的编译器进行自动和手动优化,使用起来较为复杂,并且可迁移性较差。 而GPU,在诞生之初就不需要考虑分支预测,毕竟CPU彼时已经承担了大部分的日常任务。GPU一开始的定位是图形计算,也只需要针对纹理,渲染等做专用的优化,这两类任务符合前面讲的计算序列线性,操作固定的特点。其硬件的实现思路也非常简单直观,一块芯片负责一块图形(区域),之后将结果合并。后来有研究人员发现在上面做微分方程的求解,如有限元/有限体积法,只需要将任务分割,并转化成类似纹理渲染的方式,就可以获得极大的并行性。 简而言之,在CPU上的循环计算可以直接在GPU上展开铺平,以此来获得非常惊人的加速比。 最后,针对第二点,抛开摩尔定律是否失效不谈,但其显然跟不上算力需求增长的scaling law了,所以多块芯片的高速互联,也是非常关键的一类技术体系。 (三)架构演进 著名的GPU厂商,NVIDIA,按照通用GPU的理念,硬件架构配合软件生态,从一开始使用起来“sometimes akward”的架构演进到基于流处理器的费米架构,进而有了今天的H100/H200等GPUs:
添加图片注释,不超过 140 字(可选)
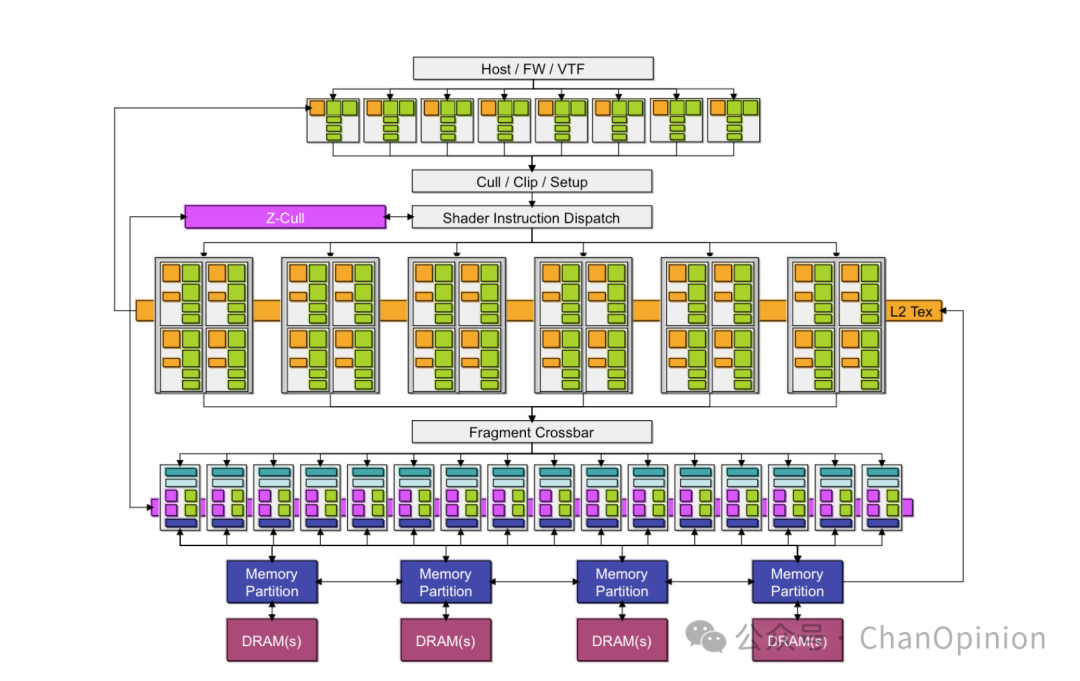
上图为GeForce 7800的微架构,可以看出其思路仍然是类似CPU的流水线:一“块”负责一个“阶段”/“任务”,串联起来完成整个计算流。
添加图片注释,不超过 140 字(可选)
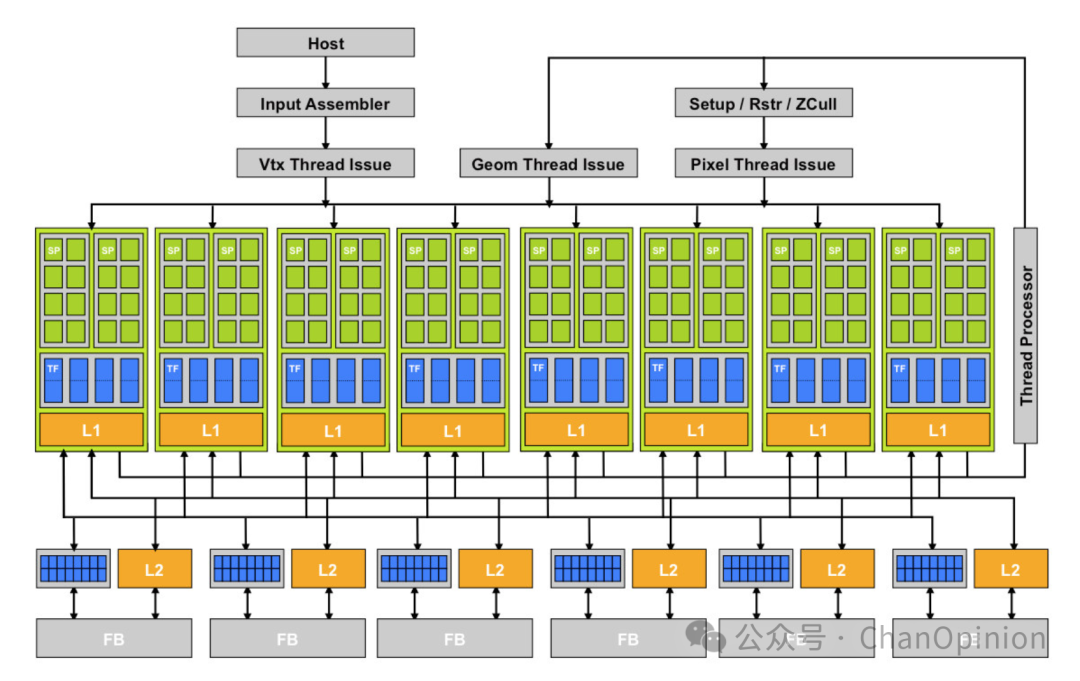
而到了GeForce 8800,微架构变得规整了许多:引入了可编程的微小计算单元,不同任务以可编程的方式并行的运行。这样做的好处一是增强了芯片的易用性,再也不用把科学计算任务转化成图形编程了,并且新的硬件也可以用“堆料”的方式简单扩展。 这些微小的计算单元,自费米架构起被称作流处理单元(SM):
添加图片注释,不超过 140 字(可选)
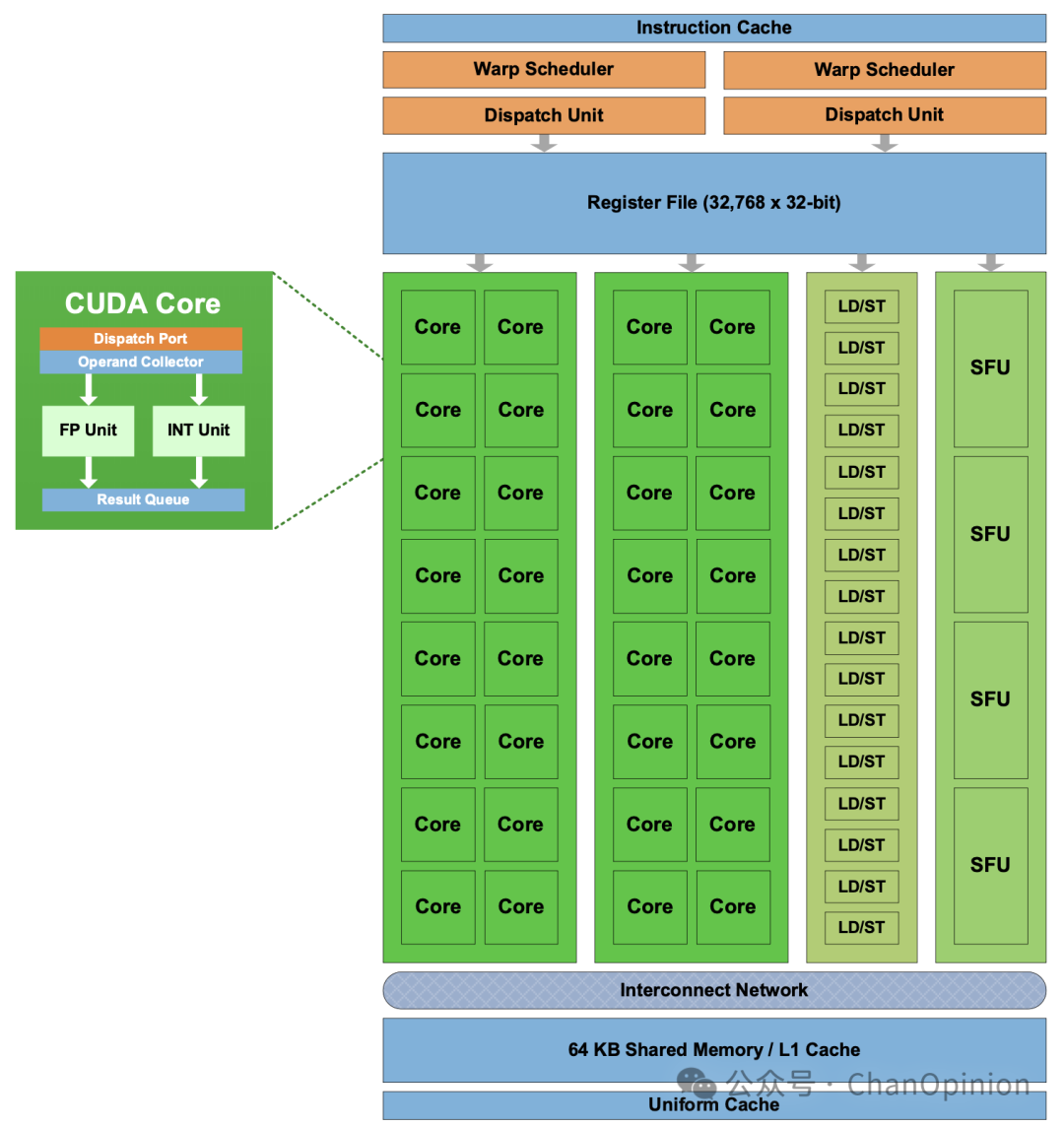
上图为SM的微结构:一个SM中有指令缓存,通过warp scheduler 和dispatch unit发射指令。指令或者到cuda core中进行整形或浮点运算,或者到LD/ST负责搬运内存,或者SFU为特殊函数进行计算。 到了后面,NVIDIA又引入了tensor core进行矩阵运算。对于大型计算任务,需要在多个计算卡上进行部署的场景,则引入了NVLink等高速互联技术,极大地增加了系统的整体吞吐量。最新的架构又多了很多新奇的设计,可以参考英伟达的官网。AMD的GPU也采用了类似的设计,所以不过多展开了。 有关GPU编程,可以看我之前写过的一些文章 揭秘GPU编程3:CUDA C++入门 揭秘GPU编程2:面向硬件的算法设计 揭秘GPU编程1: 计算模型与内存模型 除去编程的细节,由于前文所述GPU砍掉了针对分支进行优化的能力,所以在计算任务的分解与合并上最好是采用固定的拓扑来完成,比如warp级别的蝶式交换,thread级的树形规约,多GPU的集合通信等。任务划分配合通信拓扑进行优化,加上各个粒度的流水线,也是我之前主要在做,现在仍在学习的主题,最近也有很多新的硬件/软件体系,有时间我也许会专门写一下这方面的内容。 最后,有关NPU,或者说叫专用架构:DSA,我个人理解,任务划分的粒度介于CPU的多进程(MPMD)以及通用GPU(GPGPU)的SIMD模式间,以华为昇腾为例,其采用SPMD:
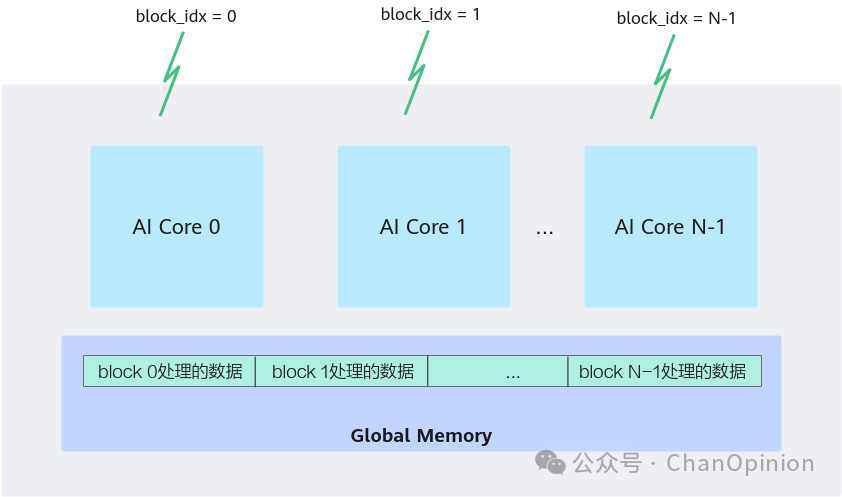
添加图片注释,不超过 140 字(可选)
根据华为的官方文档可以看到,其粒度就是定义在线程组(block)上的。不同的计算被指派到scalar/vector/cube单元进行计算。整体思路是很清晰的,也很方便使用多卡直连等方式直接提高性能,如最近的384超节点:
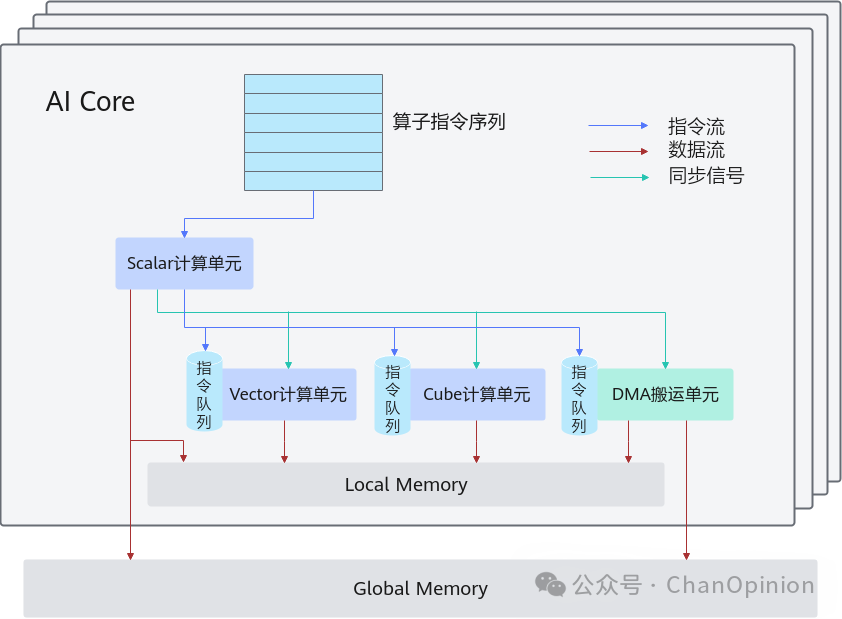
添加图片注释,不超过 140 字(可选)
其他的一些进展,如光芯片,光通信技术相信只要关注过相关领域的同学也早有耳闻,并且已经取得了一些商业上的成功,在计算效率,通信效率的提升上上会有一定的帮助。也许有朝一日量子计算技术成熟,能够大规模应用后,会成为解决一切计算效率和通信延迟问题的真正方案吧量子计算。 (四)结论 在写了这么多芯片的设计思路,微架构,如何在上面进行编程的大概原理后,我在想,有朝一日,对于AI的种种,不论是算法,还是软硬件结合,互联,或算力芯片的设计,制造,封装等,都会如视频编解码等领域,成为也许仍然活跃但绝不再是主流的过去时。但或多或少的参与进时代的潮流,这也是每一个普通人可以获得成就感的最简单直接的方式。所以也希望能以包括此文在内的工作,为知识的传播,创新,应用,做一点点微不足道的贡献吧!
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号