
ICCV 2025 | 浙大等提出 SGCDet:自适应3D体素构建,重新定义多视图室内3D检测
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
多视图室内3D目标检测是实现场景理解、增强现实和机器人导航的关键技术。然而,如何高效且准确地将多张2D图像信息“提升”到3D空间,一直是该领域的瓶颈。传统方法通常采用固定的投影方式构建3D体素(Voxel),这不仅计算冗余,而且限制了特征的表达能力。
近日,一篇被计算机视觉顶级会议ICCV 2025接收的论文《Boosting Multi-View Indoor 3D Object Detection via Adaptive 3D Volume Construction》提出了一种全新的解决方案。该研究由浙江大学、浙大宁波理工学院和香港城市大学的研究者们共同完成,他们提出了一个名为SGCDet的新型框架。该框架通过自适应3D体素构建,巧妙地解决了上述难题,在ScanNet、ScanNet200和ARKitScenes等多个权威数据集上均取得了SOTA(State-of-the-Art)的性能。

添加图片注释,不超过 140 字(可选)
-
论文标题: Boosting Multi-View Indoor 3D Object Detection via Adaptive 3D Volume Construction
-
作者团队: Runmin Zhang, Zhu Yu, Si-Yuan Cao, Lingyu Zhu, Guangyi Zhang, Xiaokai Bai, Hui-Liang Shen
-
所属机构: 浙江大学、浙大宁波理工学院、香港城市大学
-
论文地址: https://arxiv.org/pdf/2507.18331v1
-
项目地址: https://github.com/RM-Zhang/SGCDet
-
录用会议: ICCV 2025
研究背景与意义
在多视图3D目标检测任务中,核心步骤是将从不同2D视角拍摄的图像特征,转换并融合到统一的3D空间中,形成所谓的“3D体素(3D Volume)”。过去的许多方法,如ImVoxelNet,通常是将3D空间中的每个体素中心点,直接投影回2D图像的固定位置来提取特征。
这种方法的弊端显而易见:
-
感受野受限: 一个3D体素只能从2D图像上的一个固定点采样特征,忽略了该点周围丰富的上下文信息。
-
计算冗余: 无论是物体表面还是空无一物的自由空间,所有体素都被同等对待,导致大量计算资源被浪费在无效区域。
SGCDet正是为了解决这两个核心痛点而设计的。
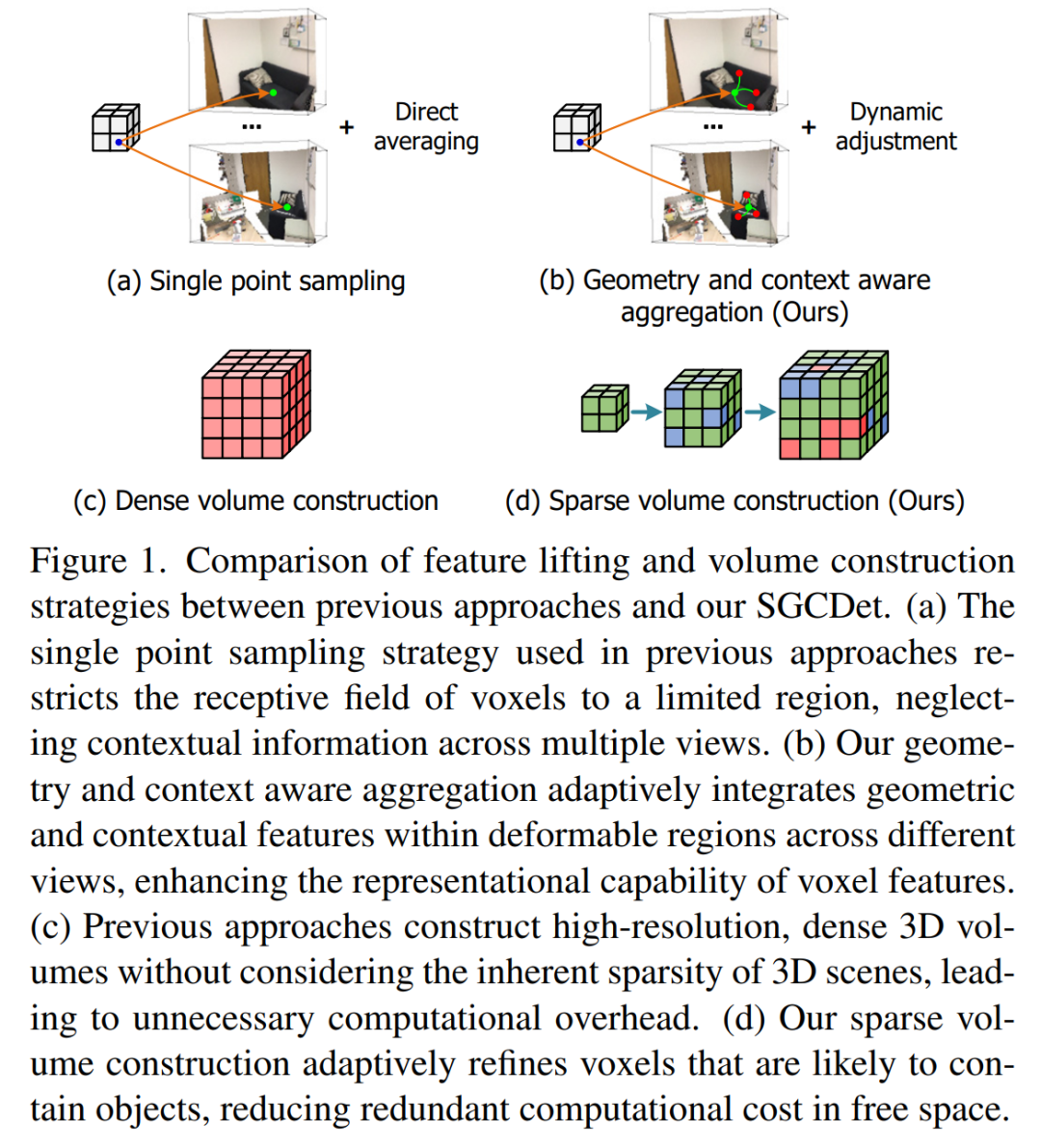
传统稠密体素构建(c)与SGCDet的稀疏体素构建(d)对比
核心方法:SGCDet
SGCDet的创新之处在于其“自适应”的体素构建方式,它包含两个核心模块:几何与上下文感知聚合模块,以及稀疏体素构建策略。
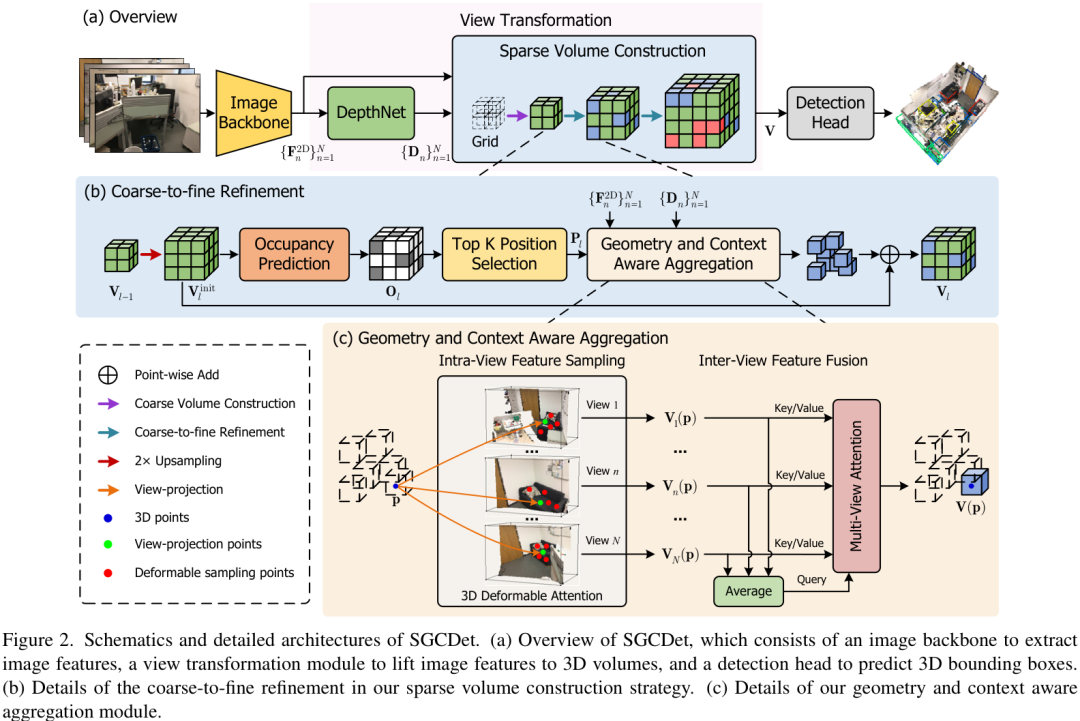
SGCDet框架概览图
1. 几何与上下文感知聚合模块 (Geometry and Context Aware Aggregation)
为了解决感受野受限的问题,研究者设计了这个模块,它包含两个关键部分:
-
帧内特征采样(Intra-view Feature Sampling): 传统方法将3D体素投影到2D图像的一个固定点,而SGCDet则引入了可变形注意力机制(Deformable Attention)。这使得每个3D体素在投影到2D图像后,能够自适应地在投影点周围的多个位置进行采样。这就像让体素拥有了“主动观察”的能力,可以根据需要去“看”周围的上下文信息,从而获得更丰富、更具代表性的特征。

帧内特征采样示意图:绿色点为固定投影点,红色点为自适应的采样点
-
多视图注意力(Multi-view Attention): 对于同一个3D体素,不同视角的图像对其可见性、清晰度都不同。该模块能动态地评估并调整来自不同视图的特征贡献权重,让信息更可靠的视图拥有更高的话语权,从而优化最终融合的体素特征。
2. 稀疏体素构建策略 (Sparse Volume Construction)
为了解决计算冗余的问题,SGCDet采用了一种由粗到精(Coarse-to-Fine)的稀疏构建策略。
-
占用概率预测: 首先,网络会初步构建一个粗糙的3D体素,并训练一个占用预测网络(Occupancy Prediction Network)来判断每个体素是属于“自由空间”还是“可能被物体占据”。
-
聚焦精炼: 然后,网络会只选择那些占用概率高的体素,集中计算资源对它们进行特征精炼(即执行更复杂的几何与上下文感知聚合)。
通过这种方式,大量的计算被从空旷区域中解放出来,使得模型能够更高效地运行,同时将“算力”用在刀刃上。
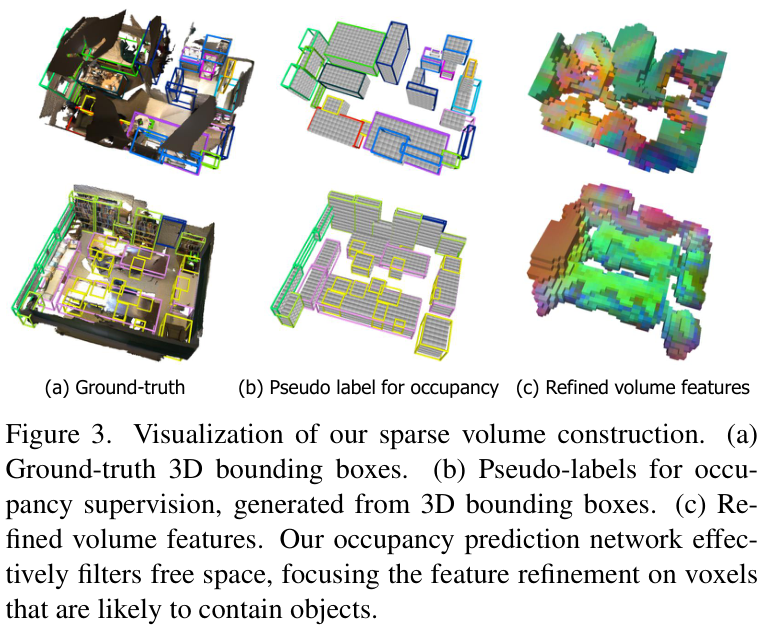
稀疏体素构建可视化:模型能有效过滤掉自由空间,聚焦于物体所在的区域进行特征细化
更值得一提的是,整个网络的监督仅需3D边界框(Bounding Box)真值,无需依赖难以获取的场景几何(如稠密深度图)真值,这大大增强了其在实际应用中的便利性。
实验结果与分析
SGCDet在多个主流室内3D目标检测数据集上都展现了卓越的性能。
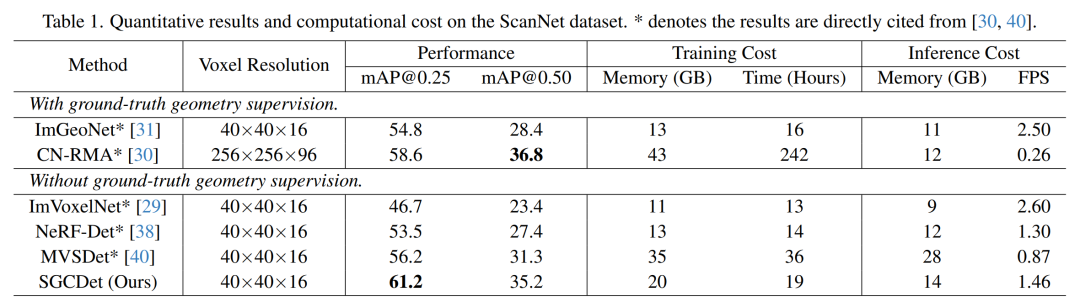
ScanNet数据集的定量结果和计算成本
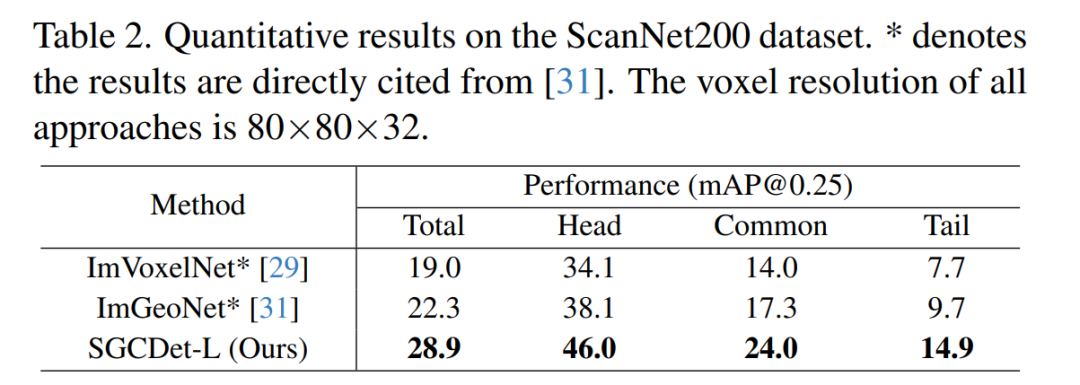
ScanNet200数据集的定量结果
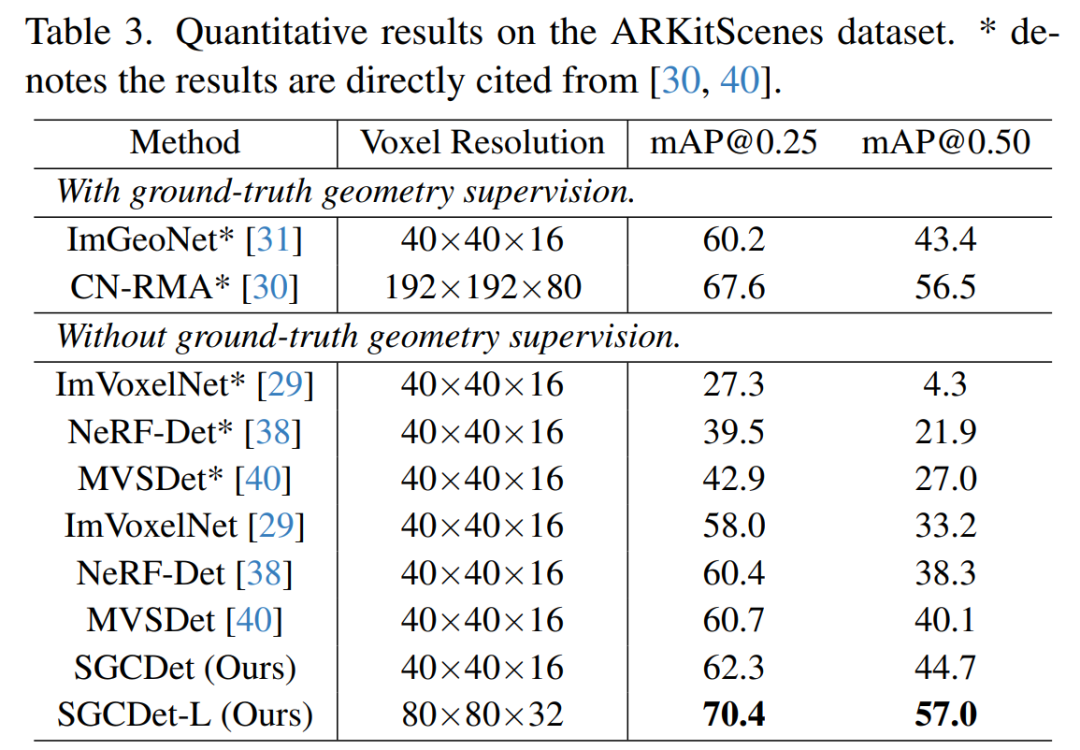
在ARKitScenes数据集上的性能对比
大量的消融实验也验证了SGCDet中各个创新模块的有效性。例如,实验证明,同时使用可变形注意力和多视图注意力,比单独使用任何一个的效果都要好。稀疏体素构建策略也被证明能够在不牺牲甚至提升精度的前提下,有效提高模型的运行效率。
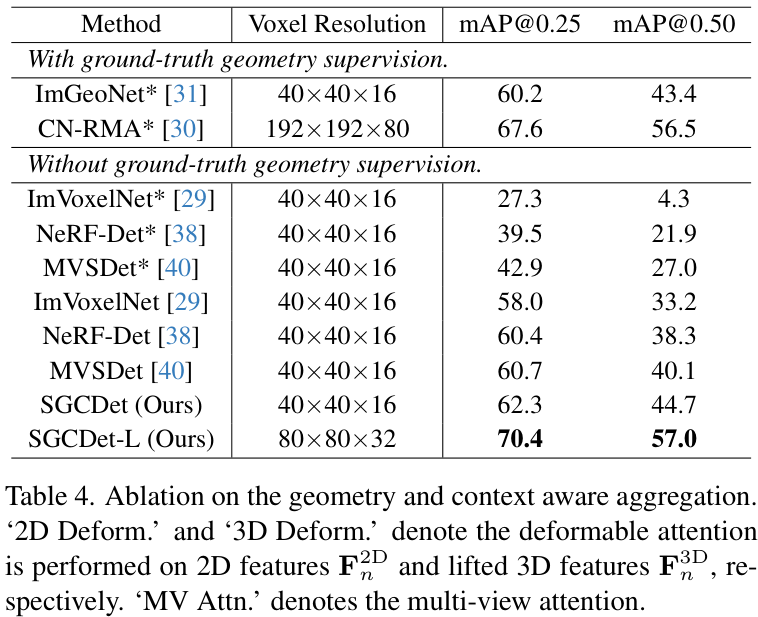
几何与上下文感知聚合模块的消融实验
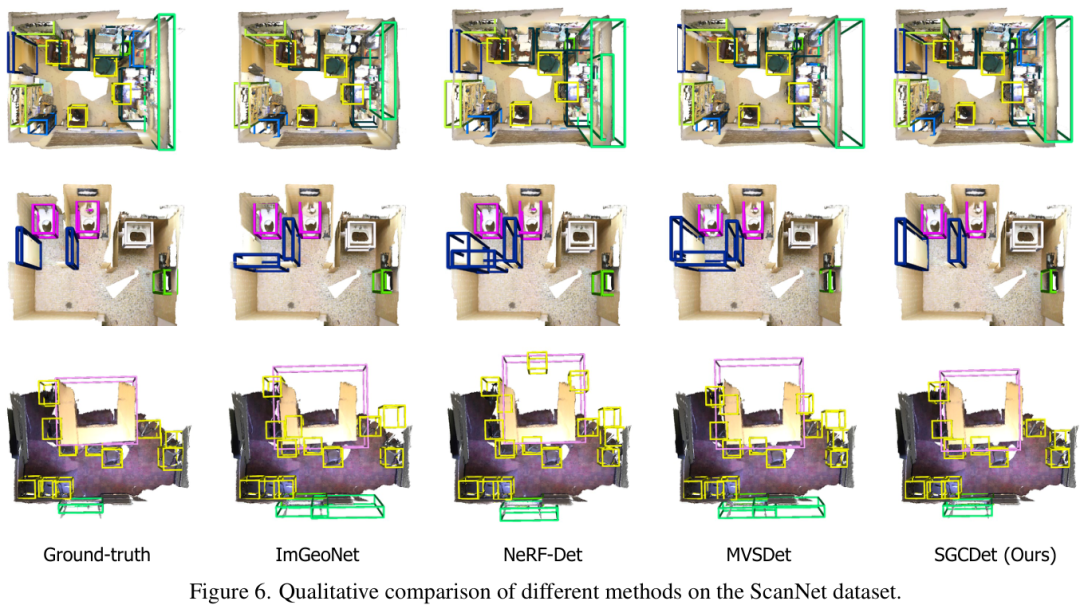
不同方法的定性结果对比,SGCDet能更准确地检测出物体
论文贡献与价值
SGCDet的提出,为多视图室内3D目标检测领域带来了显著的推动作用:
-
范式创新: 提出了一个全新的自适应3D体素构建框架,打破了传统固定感受野的限制。
-
有效且高效: 通过几何与上下文感知聚合模块提升了特征质量,通过稀疏体素构建策略提升了计算效率,实现了“鱼与熊掌兼得”。
-
SOTA性能: 在三大权威基准上均取得了当前最佳性能,为该领域树立了新的标杆。
-
实用性强: 仅需3D Bbox监督,降低了对数据标注的要求,且代码已开源,便于社区研究和应用。
总而言之,SGCDet通过其精巧的自适应设计,为如何从多视图2D图像中高效、准确地构建3D世界表征,提供了一个极具启发性的答案。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号