
华为昇腾 910C 实测效率超 H100,AI Infra软硬件协同亮剑万亿大模型时代
随着LLM在参数规模、架构复杂度和上下文处理能力上的持续突破,传统AI数据中心正面临前所未有的挑战。算力瓶颈、带宽限制与延迟问题日益凸显,仅靠堆叠硬件已难以为继,亟需一场软硬协同的系统性革新。
在此背景下,华为与耀途资本天使轮项目——硅基流动联合发表重磅论文,首次完整披露其面向LLM时代打造的新一代AI数据中心架构:Huawei CloudMatrix。首个生产级CloudMatrix384配合DeepSeek-R1万亿参数MoE模型,在昇腾910C NPU上展现出超越NVIDIA H100/H800的推理性能。
过去一年,硅基流动成为国内增长最快的第三方 MaaS 平台,SiliconCloud平台已集成包括通义千问 Qwen3、DeepSeek-R1、DeepSeek-V3 在内的百余款主流开源大模型,服务了超 600 万用户与数千家企业客户。
本文将深入解析这一技术突破背后的设计理念与性能实测,探讨未来AI基础设施的发展方向。以下为原文:
万亿参数、混合专家(MoE)架构、百万级上下文窗口……大语言模型(LLM)的狂飙突进,正将传统 AI 数据中心推向极限。
算力告急、带宽触顶、延迟飙升,这些昔日的「天花板」,如今已成为亟待突破的「铁壁」。尤其是在真实生产环境中,面对多变、突发的业务请求,以及严苛的服务等级目标(SLO),传统 AI 集群的捉襟见肘之态尽显。
仅仅堆砌硬件已无法解决问题,业界亟需一次硬件和软件的深度协同设计革命。
近期,华为联手耀途天使轮项目硅基流动发表重磅论文,首次完整揭秘其为应对 LLM 时代挑战而打造的新一代 AI 数据中心架构:Huawei CloudMatrix。
这不仅仅是一个概念。基于该架构的首个生产级实现 CloudMatrix384,已经携手 DeepSeek-R1 这样的万亿参数 MoE 模型,交出了一份惊人的性能答卷。
测试结果显示,在昇腾 910C NPU 上运行的 CloudMatrix-Infer 服务方案,计算效率(tokens/s/TFLOPS)在 Prefill 和 Decode 两个阶段均已超越了业界顶尖的 NVIDIA H100 和 H800 的公开数据。
华为和硅基流动是如何携手重塑 AI 基础设施?这背后隐藏着怎样的技术革新?
01万亿模型「三大趋势」带来的四大挑战
要理解华为 CloudMatrix 的设计哲学,首先要看清它试图解决的问题。当前 LLM 发展呈现出三大核心趋势:
-
1. 参数规模的指数级增长:从 Llama 4 的近 2 万亿参数,到 DeepSeek-V3 的 6710 亿参数,再到 Pangu Ultra MoE 的 7180 亿参数,模型规模的膨胀对计算能力和内存容量提出了前所未有的要求。
-
2. MoE 架构的广泛采用:为了控制成本,通过「稀疏激活」实现容量与计算解耦的 MoE 架构已成主流。无论是 Mixtral、DBRX,还是 DeepSeek-V3、Qwen3,都采用了 MoE 设计。但这引入了新的系统级难题:海量专家(Experts)之间的高效路由和同步,对网络通信提出了极致要求。
-
3. 上下文长度的急剧扩展:从几万 tokens 到上百万 tokens,长上下文窗口在增强模型能力的同时,也让注意力计算和 KV Cache 存储的压力倍增。如何高效分发、存储和访问 KV Cache,成为关键瓶颈。
这三大趋势共同将压力传导至底层基础设施,带来了四大系统级挑战:
-
• 挑战一:通信密集型并行的扩展。张量并行和专家并行需要频繁、细粒度的低延迟通信,传统 RDMA 网络在跨节点扩展时力不从心,限制了并行规模。
-
• 挑战二:异构 AI 负载下的高利用率。训练、推理、数据预处理等任务资源需求各异。固定的节点配置难以适配,导致资源浪费或利用率低下。
-
• 挑战三:AI 与数据密集型负载的融合。AI 工作流与数据摄取、分析、模拟等操作交织。传统数据中心难以同时满足两类负载的严苛需求。
-
• 挑战四:内存级的存储性能。PB 级数据集、TB 级模型权重以及大规模 KV Cache 和 RAG 应用,都要求存储具备内存级的带宽、延迟和 IOPS,传统存储体系已成瓶颈。
正是为了系统性地解决这些根本性难题,华为提出了 CloudMatrix 架构。
02CloudMatrix 架构:一切皆可池化、平等互联
华为 CloudMatrix 的核心愿景,是构建一个「万物皆可池化、平等对待、自由组合」的 AI 原生数据中心。
它彻底颠覆了传统以 CPU 为中心的层级式设计,通过一个统一的、超高性能的网络,将 NPU、CPU、内存、网卡等所有资源完全解耦,形成可以独立扩展的资源池。
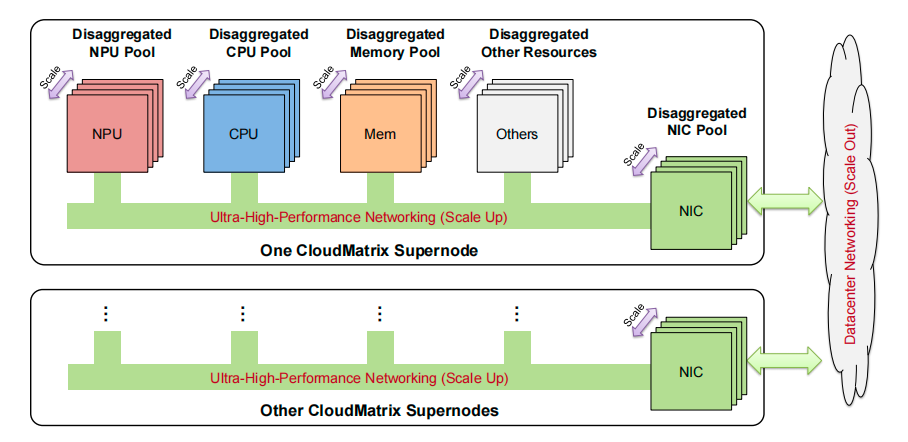
添加图片注释,不超过 140 字(可选)
华为 CloudMatrix 架构愿景,实现各类资源的完全对等解耦与池化
而实现这一愿景的脉络,就是一条统一总线(Unified Bus, UB)。这条超高带宽、超低延迟的「数据高速公路」连接了超级节点内的所有组件,实现了真正意义上的对等(Peer-to-Peer)全互联。
论文中首次亮相的 CloudMatrix384,正是这一愿景的生产级落地。
它是一个集成了 384 颗昇腾 910C NPU 和 192 颗鲲鹏 CPU 的庞大超级节点。其最关键的设计,就是对等、全互联的硬件架构。
与传统架构中「节点内高速、节点间低速」的巨大鸿沟不同,CloudMatrix384 借助 UB 网络,让跨节点通信性能几乎与节点内持平。数据显示,其跨节点带宽下降不足 3%,延迟增加小于 1 微秒。这意味着整个超级节点在逻辑上可以被视为一个紧密耦合的、统一的计算实体。
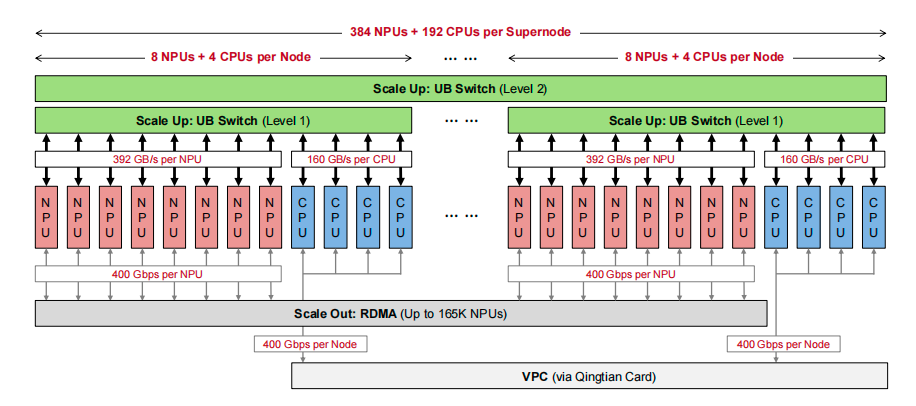
添加图片注释,不超过 140 字(可选)
CloudMatrix384 超级节点硬件架构,展示 UB、RDMA 和 VPC 三个网络平面
为了支撑不同的流量模式,CloudMatrix384 设计了三个互补的网络平面:
-
1. UB 平面:核心的 Scale-Up 网络,以全互联(All-to-All)拓扑连接所有 NPU 和 CPU。每颗昇腾 910C 贡献超过 392 GB/s 的单向带宽。它专为 TP、EP 等细粒度并行以及内存池的快速访问而设计。
-
2. RDMA 平面:用于超级节点间的 Scale-Out 通信,采用 RoCE 协议,确保与现有生态兼容。NPU 是该平面的唯一参与者,用于 KV Cache 在 Prefill 和 Decode 节点间的传输、分布式训练等。
-
3. VPC 平面:通过华为自研的擎天卡连接到数据中心网络,负责管理、控制、访问持久化存储等。
这套架构的核心硬件,是 2024 年旗舰级 AI 加速器——昇腾 910C NPU。它采用双 Die 封装,每个 Die 提供约 376 TFLOPS (BF16/FP16) 的算力,整个芯片算力高达 752 TFLOPS。同时,它也支持 INT8 数据类型,单 Die 算力可达 752 TFLOPS (INT8),整颗芯片则为 1504 TFLOPS (INT8)。
在内存方面,昇腾 910C 集成了 128 GB 封装内存,带宽高达 3.2 TB/s。而在网络接口上,每个 Die 都同时接入 UB 平面(196 GB/s 单向)和 RDMA 平面(200 Gbps 单向),为三平面网络提供了硬件。
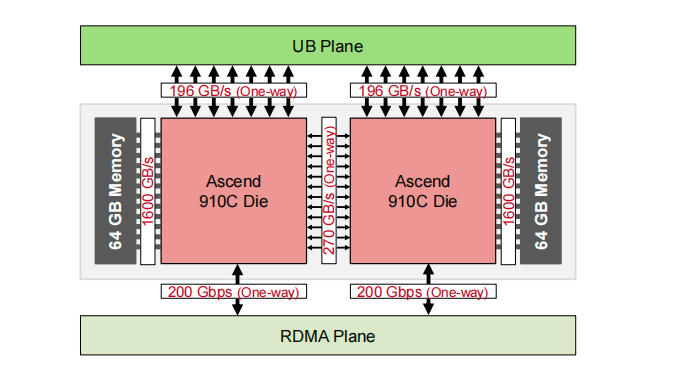
添加图片注释,不超过 140 字(可选)
昇腾 910C 芯片逻辑概览,采用双 Die 架构
这些昇腾 910C 芯片与鲲鹏 CPU,则通过精密的板上设计,共同构成了一个 CloudMatrix384 的基本计算单元——昇腾 910C 节点。
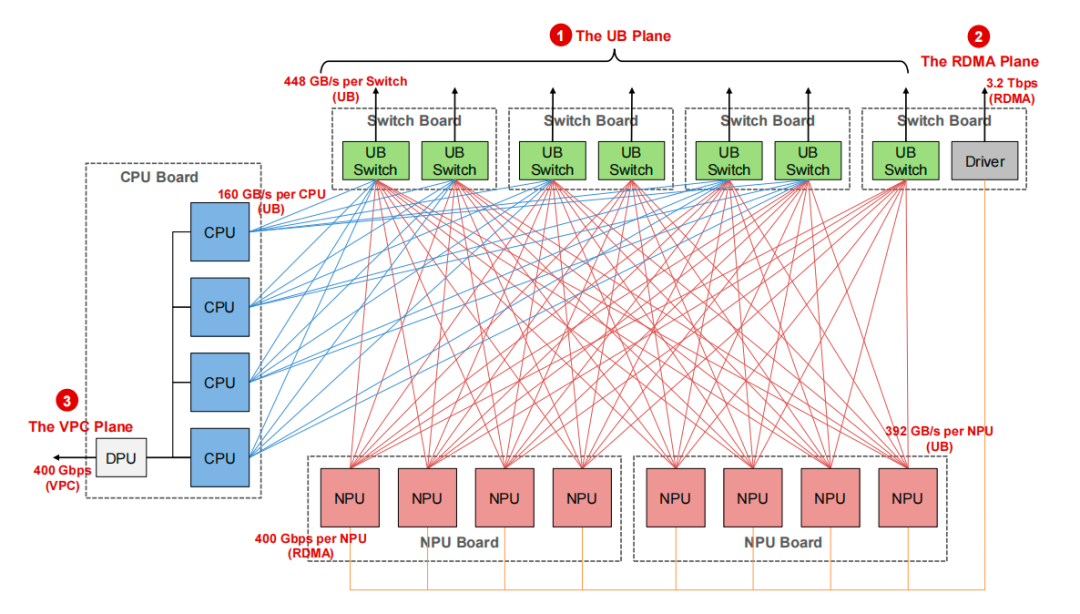
添加图片注释,不超过 140 字(可选)
CloudMatrix384 中单个昇腾节点的逻辑概览
这些强大的硬件,通过复杂的两级 UB 交换系统被组织起来,构成了一个无阻塞的、庞大的计算集群,为上层软件的创新提供了坚实的地基。
03CloudMatrix-Infer:为驾驭万亿 MoE 模型而生的服务引擎
拥有了强大的硬件底座,如何才能将其潜力完全释放?为此,华为提出了一个专门为大规模 MoE 模型(如 DeepSeek-R1)设计的综合性 LLM 服务解决方案——CloudMatrix-Infer。
CloudMatrix-Infer 的核心是一套跨越算法、服务引擎、CANN 库和云服务的全栈优化。

添加图片注释,不超过 140 字(可选)
CloudMatrix-Infer 在 AI 软件栈不同层次的优化技术概览
其架构设计的最大亮点,是基于 Prefill-Decode-Caching (PDC) 解耦的对等服务架构。
1. 颠覆传统:从「以 KV Cache 为中心」到「PDC 对等」
传统 LLM 服务系统(如 NVIDIA Dynamo、Mooncake)大多采用「以 KV Cache 为中心」的设计。请求的调度与 KV Cache 的物理位置紧密耦合。一个请求必须被路由到存储着其历史 KV Cache 的计算节点上,否则远程读取 KV Cache 的巨大网络开销将严重拖累性能。这种设计虽然避免了数据迁移,但大大增加了调度复杂性,并容易导致负载不均。
CloudMatrix-Infer 则利用 CloudMatrix384 的 UB 网络优势,彻底颠覆了这一模式。
它将系统分解为三个独立、对等、可弹性伸缩的功能集群:
-
• Prefill 集群:专门处理输入 prompt,生成首个 token 和初始 KV Cache。
-
• Decode 集群:负责自回归生成后续 tokens。
-
• Caching 集群:基于一个由所有节点 CPU 内存构成的解耦式内存池,提供全局的上下文缓存(Context Caching)和模型缓存(Model Caching)服务。
-
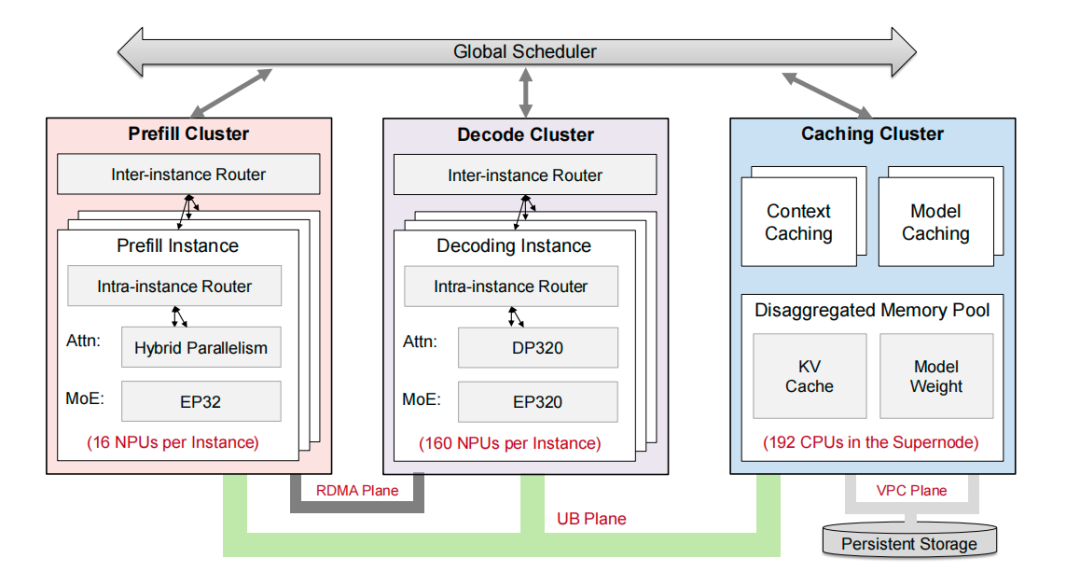
添加图片注释,不超过 140 字(可选)
PDC 解耦的对等服务架构。所有 NPU 都能通过 UB 网络统一访问共享的 Caching 集群
在这个架构中,所有 NPU,无论属于 Prefill 还是 Decode 集群,都可以通过 UB 网络以统一的带宽和延迟直接访问 Caching 集群中的共享内存池。这相当于拉平了内存层级,消除了本地与远程访问的性能鸿沟。
这种设计的优势是显而易见的:
-
• 调度解耦:请求可以被分发到任何可用的 NPU 实例,无需考虑数据局部性,极大简化了调度逻辑,并改善了负载均衡。
-
• 资源池化:汇集了所有节点的 DRAM,形成了一个统一、弹性的缓存池,提高了内存利用率和缓存命中率。
2. 深度优化之一:为「解码」打造的大规模专家并行 (LEP)
为了在解码(Decode)阶段实现极致的低延迟,CloudMatrix-Infer 针对 MoE 模型设计了大规模专家并行(Large-scale Expert Parallelism, LEP)策略。在 DeepSeek-R1 的部署中,并行度高达 EP320,即动用 320 个 NPU Die,每个 Die 仅承载一个专家。
这虽然会带来巨大的通信开销,但 CloudMatrix384 的 UB 网络确保了通信延迟是可控的,不会成为瓶颈。
为了实现高效的 LEP,论文介绍了一系列硬件感知的优化:
-
• 融合通信算子:设计了 FusedDispatch 和 FusedCombine 两个算子,将原本需要多次 All-to-All 通信的专家路由和结果合并过程,替换为更高效的点对点 send-receive 原语。
-
• AIV-Direct 通信:这是一种创新的通信机制,允许 NPU 上的 AI 向量核(AIV)直接将数据写入远程 NPU 的内存,完全绕过了高延迟的系统 DMA(SDMA)路径,极大地降低了通信启动开销。
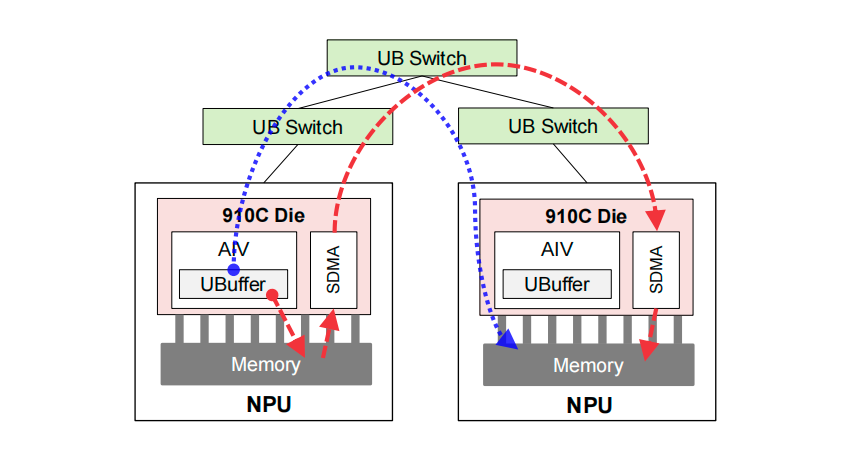
添加图片注释,不超过 140 字(可选)
AIV-Direct (蓝线) vs. 传统 SDMA (红线) 通信路径
-
• 微批次解码流水线 (Microbatch-based Decode Pipeline):为了进一步隐藏通信延迟,CloudMatrix-Infer 设计了精巧的流水线。它将解码过程分为两条流(Stream),一条处理计算密集的 Attention 部分,另一条处理通信密集的 MoE 部分。通过不对称地分配 NPU 内部的 AIC(AI Core)和 AIV 资源,使得两条流的处理时间几乎相等(约 600 微秒),从而实现两个微批次的完美重叠,最大化资源利用率。
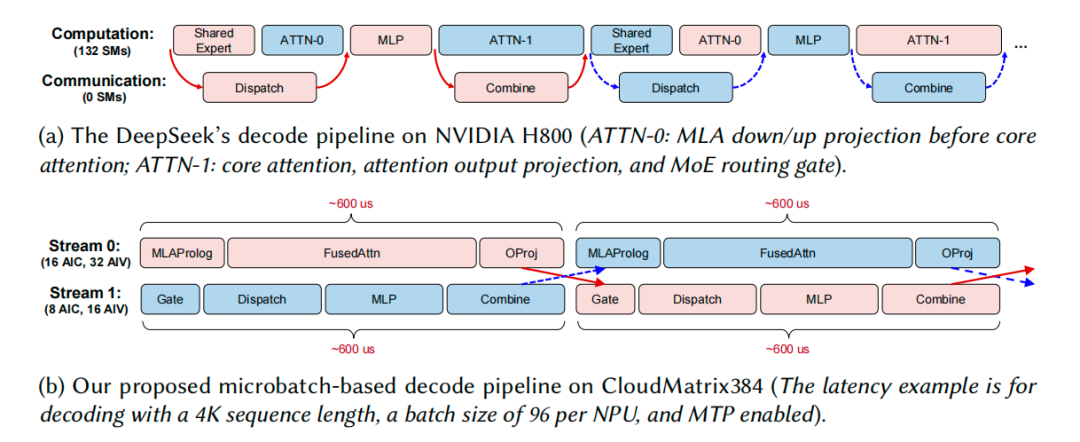
添加图片注释,不超过 140 字(可选)
CloudMatrix384 上的微批次解码流水线,通过两条流的交错执行隐藏延迟
-
• 无 CPU 介入的 MTP 支持:针对 DeepSeek 的多令牌预测(MTP)技术,CloudMatrix-Infer 将原本需要 CPU 介入的元数据初始化和采样过程,全部移至 NPU 内部完成,消除了耗时的 CPU-NPU 同步,实现了无中断的流水线执行。
3. 深度优化之二:为「预填充」设计的混合并行
预填充(Prefill)阶段的效率决定了首个 token 的生成时间(TTFT)。纯粹的数据并行(DP)在处理长度不一的输入序列时,会因负载不均而导致 NPU 闲置。
为此,CloudMatrix-Infer 提出了一种分阶段的混合并行策略。它将 MLA(Multi-head Latent Attention)计算分解为三个阶段:
-
• 阶段 1 和 3:对于 down_proj 和 o_proj 等计算,采用序列并行(SP),将所有请求的序列拼接打包后,再切分给各个 NPU,从而实现完美的负载均衡。
-
• 阶段 2:对于核心的 Attention 计算,采用张量并行(TP),将 Attention 头均匀分配给各个 NPU,保证计算负载均衡。
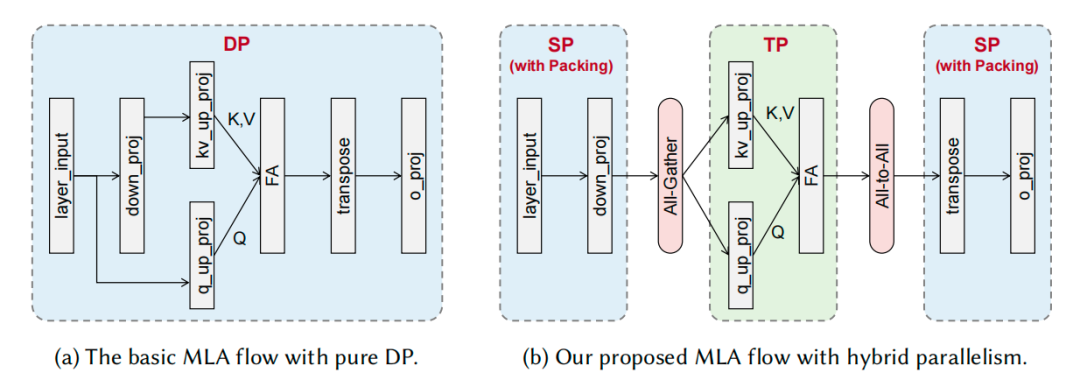
添加图片注释,不超过 140 字(可选)
混合并行 (b) vs. 纯数据并行 (a),SP-TP-SP 策略显著改善负载均衡
虽然这引入了两次额外的集体通信(All-Gather 和 All-to-All),但在 CloudMatrix384 的 UB 平面上,这点开销是完全值得的,并且其影响被最小化了。
4. 深度优化之三:UB 驱动的分布式缓存
高效的缓存是 LLM 服务的生命线。CloudMatrix-Infer 基于华为云的弹性内存服务(Elastic Memory Service, EMS),构建了强大的分布式缓存能力。
EMS 的核心,就是利用 CloudMatrix384 中所有节点的 CPU 内存,构建了一个统一的、解耦式的内存池。NPU 可以通过 UB 网络,像访问本地内存一样高速访问这个巨大的远程 DRAM 池。
基于这个内存池,EMS 提供了两大关键服务:
-
• 上下文缓存 (Context Caching):存储和复用历史 KV Cache。当一个新请求到来时,系统可以从 EMS 中快速加载匹配前缀的 KV Cache,跳过大量的 Prefill 计算,从而显著降低 TTFT,提升 Prefill 吞吐。
-
• 模型缓存 (Model Caching):将模型权重缓存在 EMS 中,实现模型的快速加载和切换。加载一个 671B 的 INT8 模型,从 OBS 存储加载需要超过 5 分钟,而从 EMS 的 DRAM 缓存加载,仅需约 5 秒,极大地提升了服务的灵活性和响应速度。
5. 深度优化之四:无损性能的 INT8 量化
为了在不牺牲精度的前提下最大化性能,CloudMatrix-Infer 采用了一套精细的层级化 INT8 量化方案。
它并非简单地将所有部分都量化为 INT8,而是采用了混合精度策略:对 FFN、Attention 等计算密集型操作使用 INT8,而对数值敏感的Normalization、Gating 等部分保留 BF16 或 FP32 精度。
此外,通过自适应尺度搜索、离群值抑制等技术,在离线校准阶段就找到了最优的量化参数,确保了量化后的模型在 16 个不同基准测试中,其准确率与官方的 DeepSeek-R1 API 表现相当。
04性能实测:计算效率全面超越 NVIDIA H100/H800
理论的先进最终要靠实践来检验。论文在 CloudMatrix384 上对 CloudMatrix-Infer 进行了全面的性能评测,并与 DeepSeek 在 NVIDIA H800 和 SGLang 在 NVIDIA H100 上的公开数据进行了对比。
Prefill 阶段性能:
在理想的专家负载均衡(Perfect EPLB)条件下,CloudMatrix-Infer 在昇腾 910C 上实现了 6,688 tokens/s 的单卡吞吐。更关键的指标是计算效率(吞吐/TFLOPS),CloudMatrix-Infer 达到了 4.45 tokens/s/TFLOPS,显著高于 SGLang on H100 的 3.75 和 DeepSeek on H800 的 3.96。
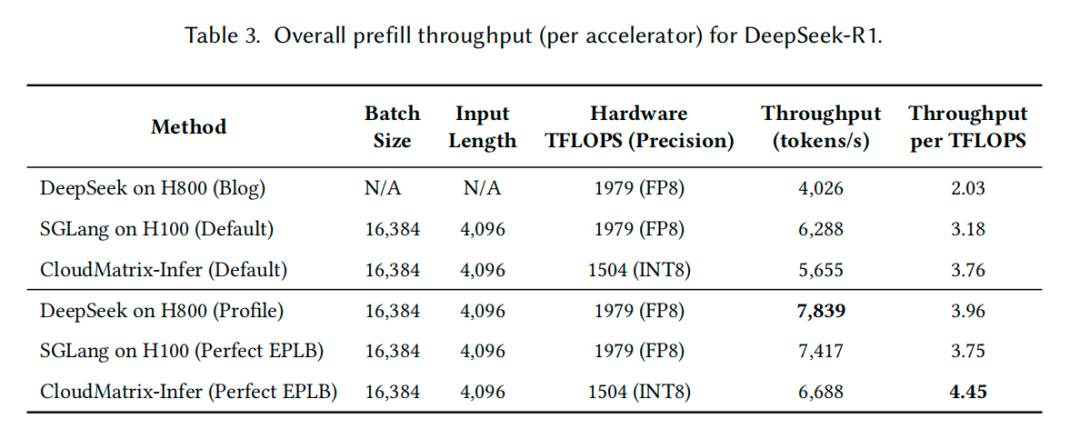
添加图片注释,不超过 140 字(可选)
Decode 阶段性能:
在满足低于 50ms TPOT(Time-Per-Output-Token)的延迟约束下,CloudMatrix-Infer 的单卡吞吐达到了 1,943 tokens/s。
在计算效率上,CloudMatrix-Infer 再次拔得头筹,达到了 1.29 tokens/s/TFLOPS,超过了 SGLang on H100 的 1.10 和 DeepSeek on H800 的 1.17。
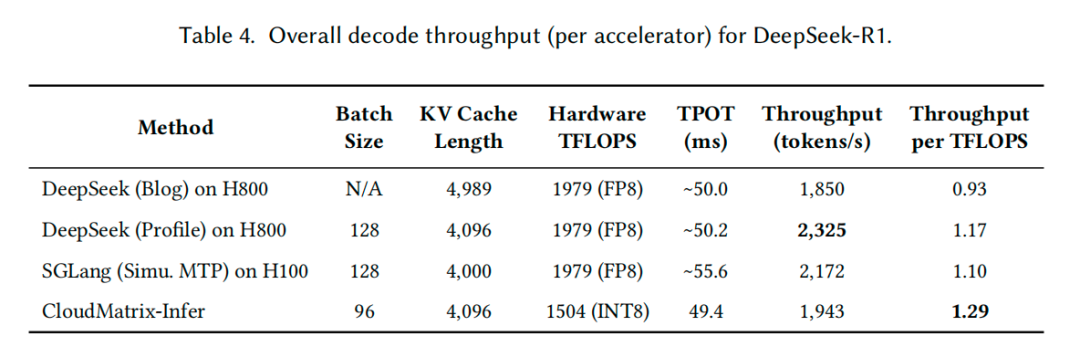
添加图片注释,不超过 140 字(可选)
这些数据无可辩驳地证明,通过软硬件的深度协同设计,华为 CloudMatrix 平台在运行大规模 MoE 模型时,已经实现了业界领先的硬件利用效率。
此外,系统还能灵活地在吞吐和延迟之间进行权衡。在严苛的 15ms TPOT 约束下,系统依然能保持 538 tokens/s 的吞吐,展示了其在不同服务等级下的强大适应性。
05未来展望:走向更大规模、更深度的解耦
CloudMatrix384 只是一个开始。论文最后还展望了未来的发展方向:
-
• 更大规模的超级节点:随着模型规模的持续膨胀,更大的超级节点(例如扩展到上千 NPU)将是必然趋势。仿真数据显示,更大的资源池能显著提高 NPU 的分配率,减少碎片化。
-
• CPU 资源的物理解耦:未来将从逻辑解耦走向物理解耦,构建由纯 NPU 节点和纯 CPU/内存节点组成的超级节点,允许数据中心根据负载按需、独立地扩展不同类型的资源。
-
• 更细粒度的组件级解耦:将 LLM 推理过程进一步拆分为 Attention、MoE 等可独立部署和扩展的微服务,并根据其特性映射到最合适的硬件上,实现极致的资源利用率。
从根本上重塑 AI 基础设施,以应对大模型时代带来的颠覆性挑战——这便是华为 CloudMatrix 架构的核心思想。
通过创新的全互联 UB 网络、软硬件协同的 CloudMatrix-Infer 服务引擎,以及一系列针对性的优化技术,华为不仅构建了一个能够高效承载万亿参数 MoE 模型的强大平台,更在核心的计算效率指标上展现了其领先的技术实力。
这不仅是华为在 AI 算力棋局上落下的一枚关键棋子,也为整个行业探索下一代 AI 数据中心的设计提供了极具价值的参考范本。
万亿模型的星辰大海,需要更强大的船舰来承载,而华为 CloudMatrix,无疑会是一艘引人注目的旗舰。
引用链接:
Serving Large Language Models on Huawei CloudMatrix384: https://arxiv.org/abs/2506.12708
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号