
2025 年,Agent 大爆发,直接封神
有人问,Agent是大趋势吗?是该追的风口吗?答曰:是。尤其在DeepSeek爆发后,Agent成为各行业刚需建设项,预计不久将全面渗透基础设施、软硬件平台、各类服务,市场空间巨大,生意机会肉眼可见。
更重要的是,Agent门槛低,还有降低应用开发门槛、简化流程复杂度两大优势,不仅好出成果,也方便我们开发落地项目。谷歌还为此发布过最新的321个Agent落地案例,都是全球顶尖企业,涵盖了6大核心场景,想做相关项目的科研人必看!
为帮助大家了解前沿,系统构建Agent开发的知识体系,我特别整理了117篇论文,包含19篇开发必读(建议按基础架构→训练优化→应用与Agent顺序学习)、40篇顶会必读(CVPR25、ICLR25)。再加上部分综述以及Agent构建、应用、评估类论文,无偿分享给大家~
部分顶会论文解析:
mutil-agent
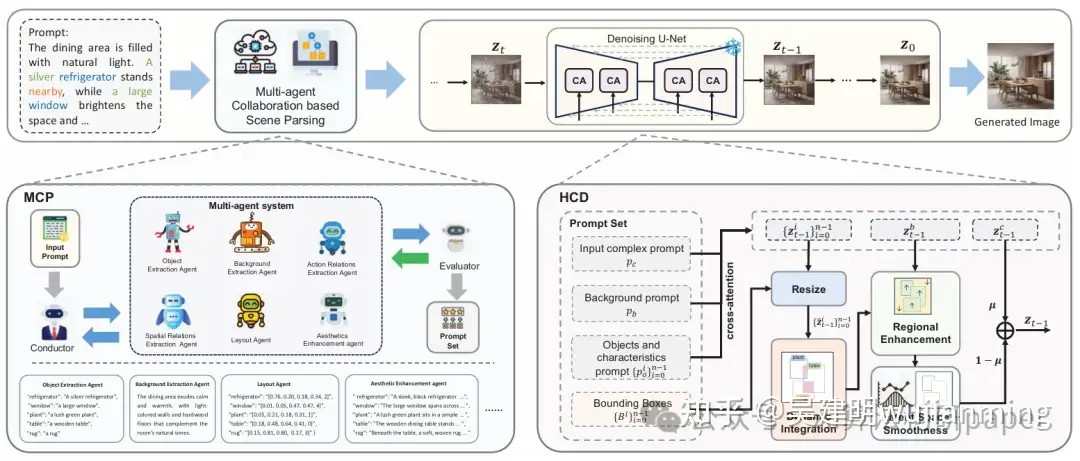
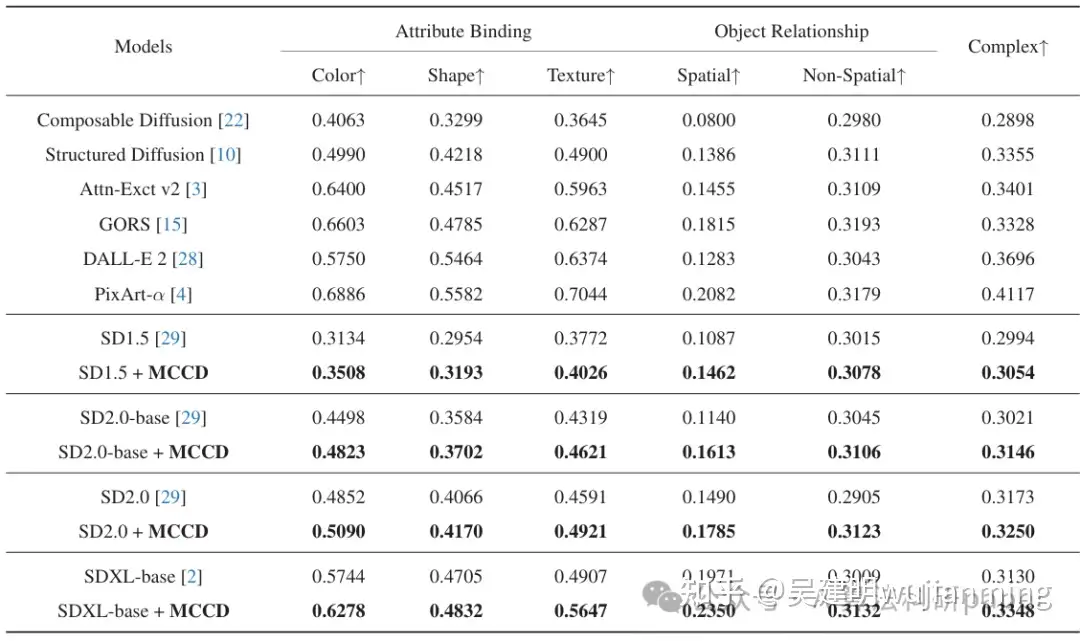
MCCD:Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Generation
方法:论文提出了一种名为MCCD的方法,用于复杂场景的文本到图像生成。它通过多智能体协作解析文本提示中的对象、关系和布局等信息,然后利用层次化扩散模型进行图像生成,确保生成的图像更符合文本描述且具有高真实感和美学效果。
创新点:
- 提出多智能体协作的场景解析模块,通过不同任务的智能体精确解析文本中的复杂场景元素。
- 设计层次化组合扩散模块,利用动态融合、区域增强和平滑技术生成高质量复杂图像。
- 无需训练即可显著提升基线模型在复杂场景生成中的性能。
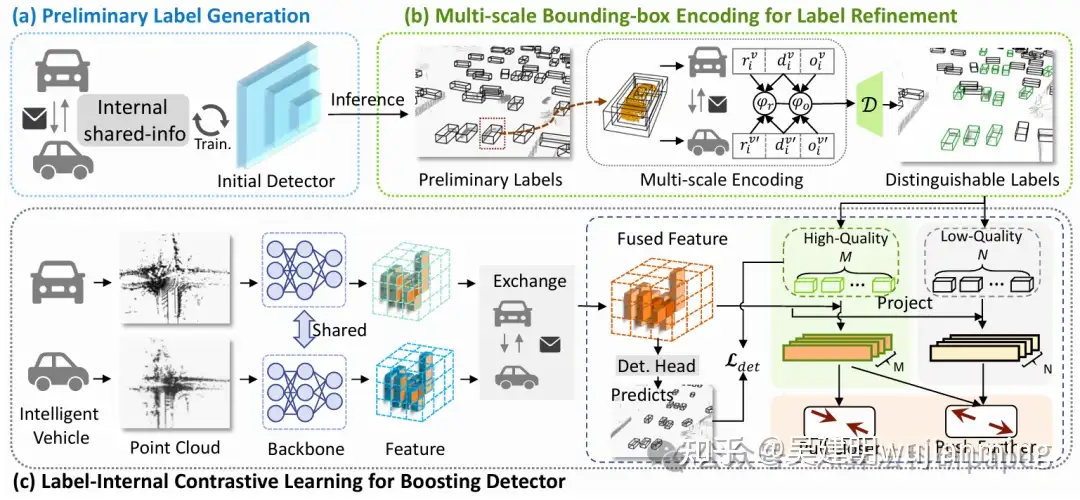
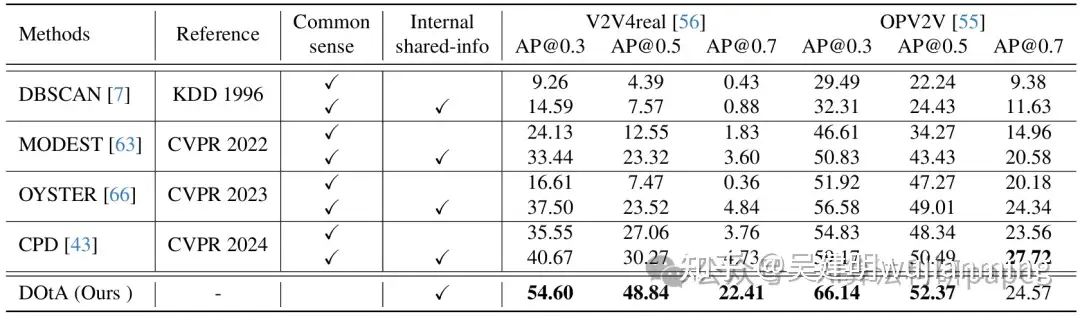
Learning to Detect Objects from Multi-Agent LiDAR Scans without Manual Labels
方法:论文提出了一种名为DOtA的方法,用于无监督的3D目标检测。它通过多智能体协作,利用共享信息生成高质量的伪标签,并通过对比学习优化特征学习,从而提高检测性能。
创新点:
- 提出了一种无监督的多智能体3D目标检测方法DOtA,利用智能体间的共享信息初始化检测器,无需外部标签。
- 设计了多尺度边界框编码模块,通过多智能体的互补观测筛选高质量标签。
- 引入标签内部对比学习方法,利用高质量标签引导正确的特征学习,提升检测性能。
单agent
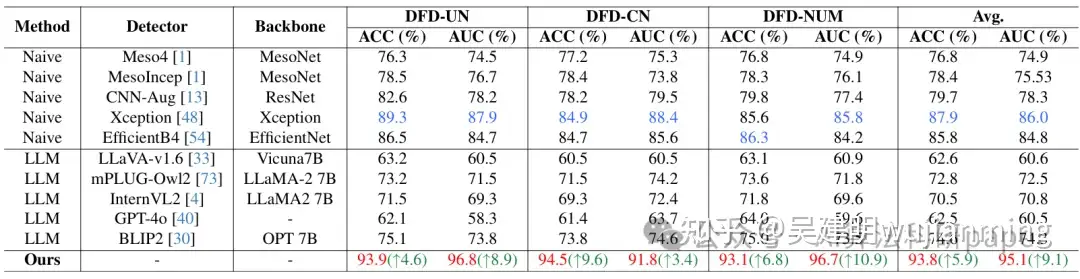
Font-Agent: Enhancing Font Understanding with Large Language Models
方法:论文提出了一种名为Font-Agent的智能体,基于VLM,通过增加EAT模块和D-DPO策略,专门用于字体质量评估和解释字体内容。它使用大规模多模态数据集进行训练,能高效评估字体质量并解释问题,表现优于现有方法。
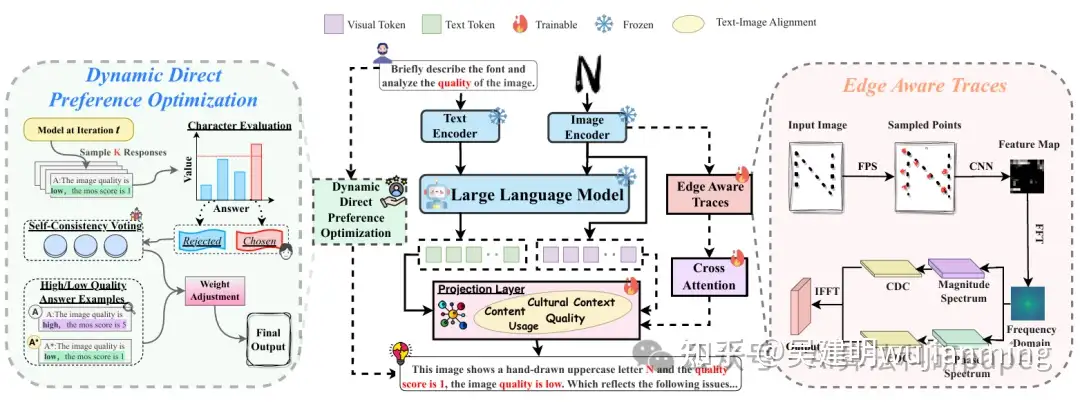
创新点:
- 构建多语言字体评估数据集DFD,含135,000手动标注样本,为研究提供基础。
- 出Font-Agent框架,结合VLM和EAT模块,提升字体质量评估准确性。
- 引入D-DPO策略,优化训练,增强模型对细节的敏感性和评估可靠性。
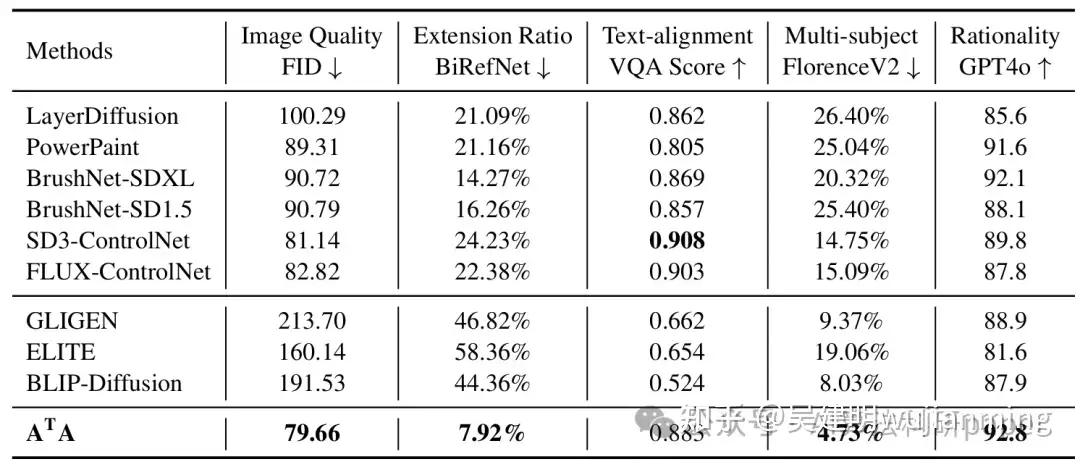
ATA: Adaptive Transformation Agent for Text-Guided Subject-Position Variable Background Inpainting
方法:论文提出ATA智能体,用于文本引导的主体位置可变背景修复。通过PosAgent预测位移,RDT模块转换特征图防变形,及位置切换嵌入控制主体位置,生成和谐修复图像。
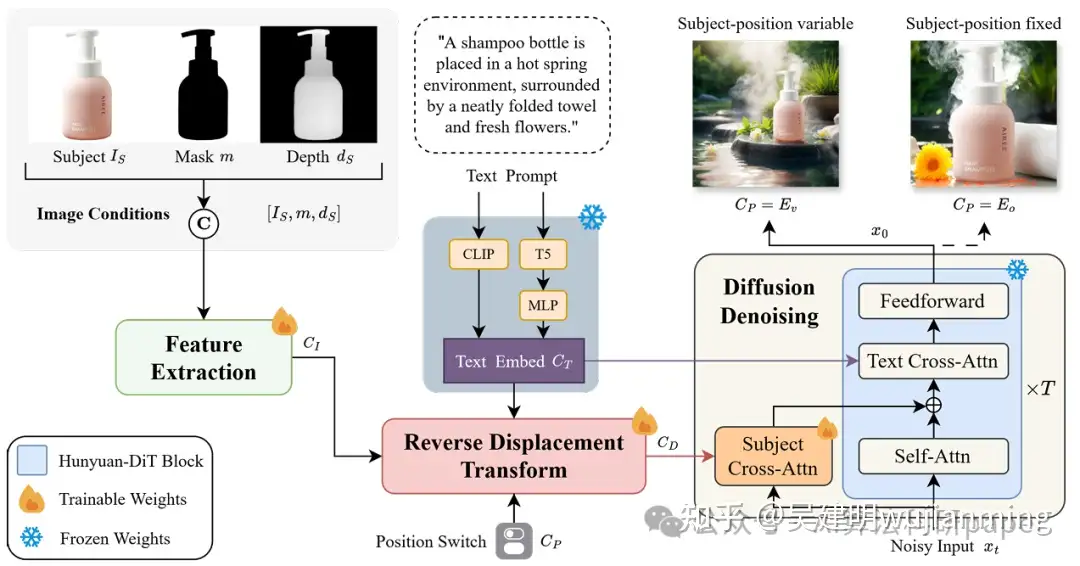
创新点:
- 提出“文本引导的主体位置可变背景修复”新任务,动态调整主体位置以匹配背景。
- 设计ATA框架,包含PosAgent模块预测位移和RDT模块反向转换特征图,避免主体变形。
- 引入位置切换嵌入,灵活控制主体位置动态调整或固定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号