
HBM带宽限令:对AI算力芯片影响分析
2024年 12月,美国进一步修订管制条例,将技术参数从传统的技术节点(nm)细化升级,限制存储单元面积小于 0.0019µm²或存储密度大于 0.288Gb/mm²的 DRAM,从而控制本身就是多个DRAM 通过 TSV 工艺堆叠封装的 HBM。2025 年 1 月,美国发布新一轮禁令,涵盖HBM2e、HBM3、HBM3e等尖端规格,基本封锁了中国获取最新 HBM 技术的渠道,同时加强供应链管控,限制使用美国技术的海外企业(如三星、SK 海力士)向中国供货。

添加图片注释,不超过 140 字(可选)
H20 应用广泛&重要性高,新限令凸显美国 AI 战略
今年以来国产厂商积极采购,美国迅速禁用以限制中国 AI 进展。H20 是从英伟达H200 裁剪而来,保留了 NVLink4.0 和 NVSwitch3.0 的 900GB/s 的卡间高速互联带宽,并支持 128GB/s 双向带宽的 PCIe Gen5。相较于英伟达 A800、H800 等,H20 在 FP8 算力、显存配置、卡间互联带宽、PCIe 连接等方面都有显著优势。2025 年前三个月,受DeepSeek 低成本 AI 模型需求旺盛推动,H20 订单量激增,包括字节跳动和阿里巴巴在内的中国科技公司已大规模订购英伟达 H20 服务器芯片,总金额高达 160 亿美元,用于人工智能模型的训练与推理。由此可见,美国 HBM 限令聚焦中国云厂商的 AI 训练及推理,未来 HBM 限令可能因为国内厂商使用的高性能 AI 芯片变化而进一步升级,无论是国产还是海外进口 AI 芯片。
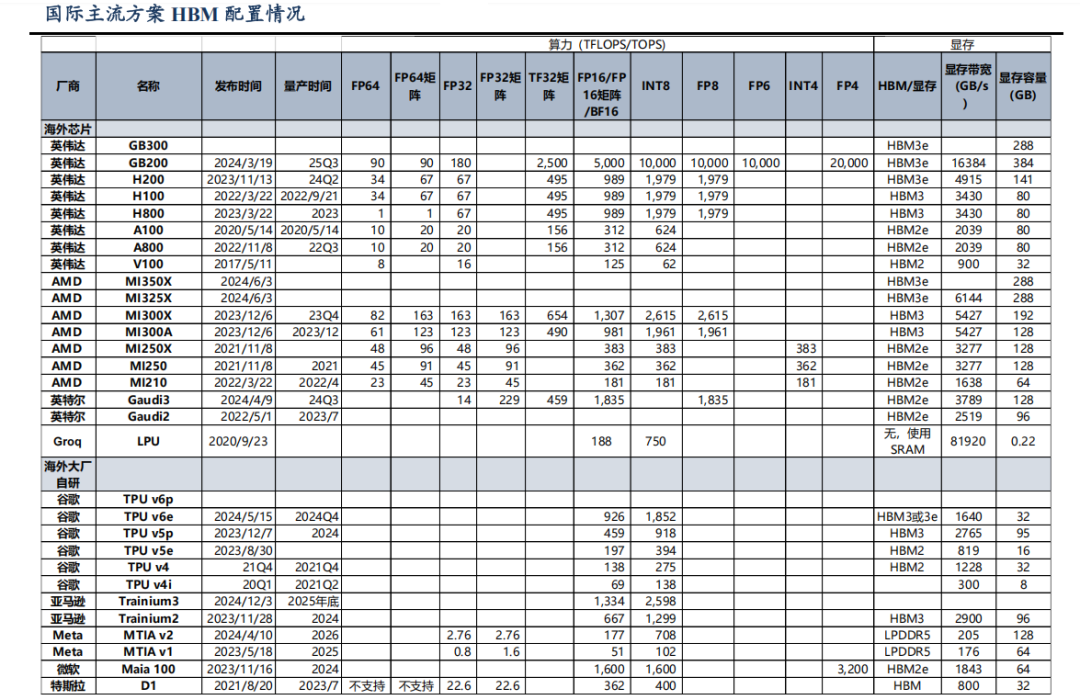
主流 AI 芯片 HBM 配置
海外旗舰 AI 芯片普遍配置最新 HBM3e,算力快速增长驱动 HBM 代际升级,带来带宽跃升。以英伟达旗舰产品 GB200 为例,其采用 HBM3e 显存,实现 16384 GB/s 的超高带宽和 384GB 容量,较 H100(HBM3 3430 GB/s)带宽提升近 4 倍,容量增加 3.8倍,下一代 GB300 预计将延续这一技术路线。类似地,AMD MI350X 也搭载 HBM3e,其 6144 GB/s 带宽较前代 MI300X(HBM3,5427 GB/s)提升显著。带宽的跃升式发展在历代 HBM 产品对比中更为明显:从 HBM2(如 V100 的 900 GB/s)到 HBM2e(A100的 2039 GB/s),再到 HBM3/HBM3e,每代技术迭代都带来 50%-100%的带宽提升,从HBM2 的 1000 GB/s 左右大幅跃升至 HBM3e 的 5000 GB/s 以上;显存容量也从 HBM2时代的 32-80GB 大幅提升至 HBM3e 时代的 288-384GB,更好地满足了 LLM 等内存密集型应用需求。AI 芯片算力增长推动 HBM 配置不断升级迭代,通过高多层堆叠等技术创新,在单位面积带宽密度上实现突破,从而带来整体 HBM 带宽的跃升。
添加图片注释,不超过 140 字(可选)
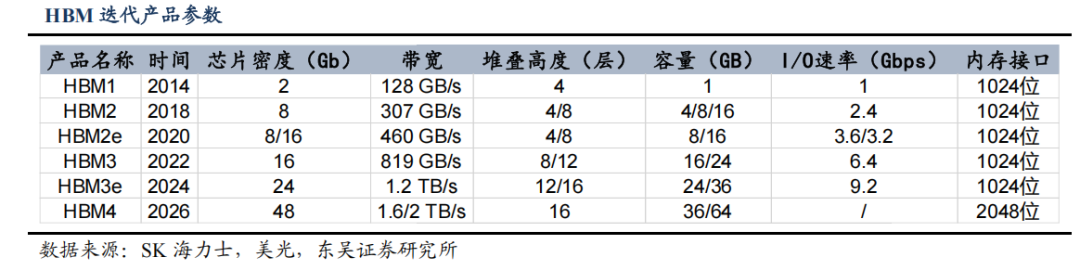
国际先进 HBM 持续迭代升级,主流 AI 芯片配置继续提升。随着大模型对算力和存储带宽的需求激增,下一代 HBM 技术正迎来关键升级,主要聚焦于带宽提升、容量扩展、能效优化三大方向。HBM4 标准于 2025 年 4 月 17 日正式发布,其带宽显著提升。HBM4 支持 2048 位接口,传输速度高达 8 Gb/s,总带宽可达 2 TB/s,可满足 10 万亿参数模型需求。代工方面,SK 海力士采用台积电 3nm 工艺(原计划 5nm),三星用4nm 工艺。三星已成功试产 16 层 HBM3 样品,计划用于 HBM4 量产。
添加图片注释,不超过 140 字(可选)
HBM 显存带宽需求如何测算?
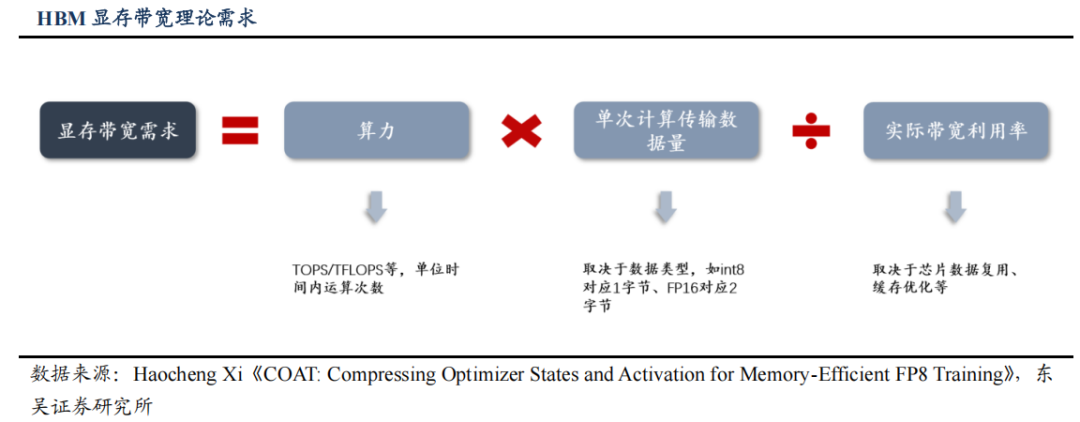
AI 芯片显存带宽需求可由算力及带宽利用率计算得出大致范围。从算力利用的角度看,AI 芯片所需要的 HBM 带宽可以简化为计算单元需要的数据吞吐量÷实际有效带宽利用率,需要确保在数据吞吐量达到峰值且实际带宽利用率处于较低水平时带宽仍能够喂饱计算单元,避免因 HBM 带宽不足而闲置算力。
其中,数据吞吐量可以进一步分解为算力(TOPS)×每次计算传输数据量,数据传输量主要取决于数据类型,如 INT8=1字节,FP16=2 字节,而实际带宽利用率代表计算单元实际需要从 HBM 读取的数据比例,主要受到数据复用率影响。
因此,AI 芯片所需 HBM 显存带宽主要受到两个变量影响:1)芯片所能达到的算力峰值,与所需带宽成正比;2)芯片数据复用、缓存优化情况,与所需带宽成反比。
添加图片注释,不超过 140 字(可选)
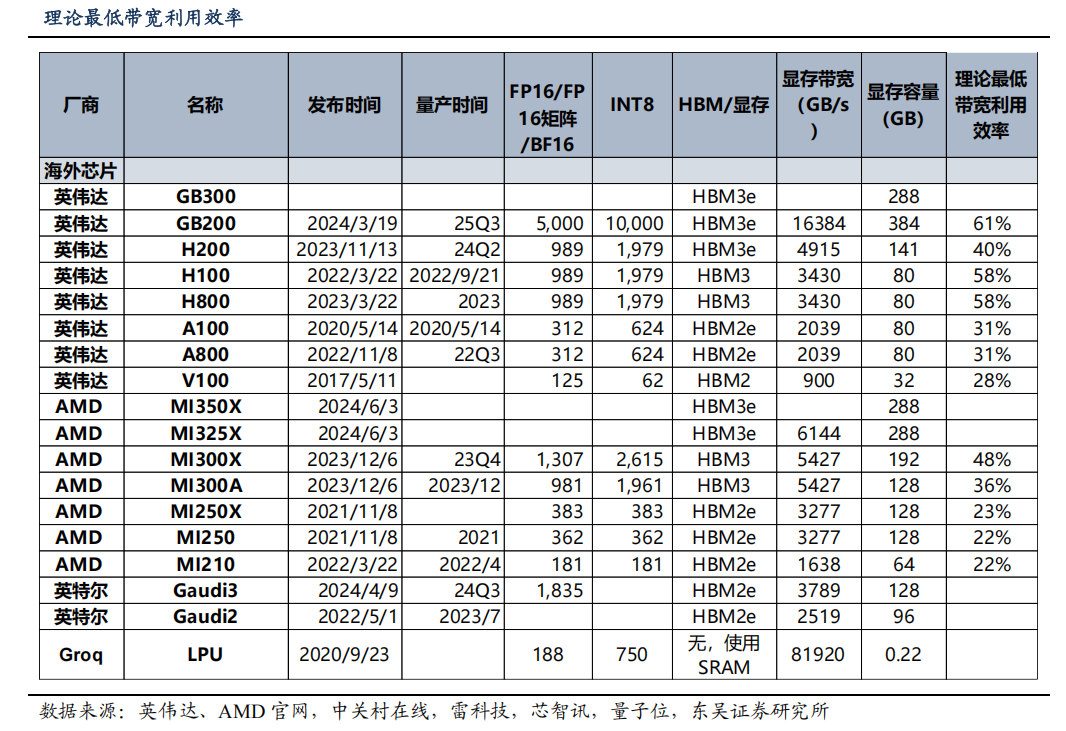
以英伟达A100芯片为例,其FP16算力达到312 TFLOPS,假设其最低带宽利用率在 30-40%区间,因此对于显存带宽需求在 1560-2080 GB/s 区间,其使用的 HBM 带宽需要满足上述带宽要求。假设带宽需求取中值 1820 GB/s,对应 4 颗HBM2e 或 3 颗 HBM3。
添加图片注释,不超过 140 字(可选)
限令影响 AI 训练/推理效果,国产厂商如何应对?
硬件方面,可使用 Chiplet 封装等技术实现技术跃升。由于美国 HBM 新一轮禁令主要限制显存带宽和互联带宽及其总和,要求均不得达到 H20 的参数,故国内厂商可以通过降低单芯片 HBM 数量、减配、减少互联接口数量等措施应对。
具体而言,主要有三种可能的应对方式:1)减少 HBM3e 的数量,从而降低单芯片的显存带宽;2)减少I/O 接口数量,从而降低接口总带宽;3)将 HBM3e 替换为较低版本的 HBM2,降低总显存带宽。
另外,同样可以使用特殊封装技术以制造先进 AI 芯片,Chiplet 技术是一种利用先进封装方法将不同工艺/功能的芯片进行异质集成的技术。核心思想是先分后合,即先将单芯片中的功能块拆分出来,再通过先进封装模块将其集成为大的单芯片。不同芯粒可以根据需要来选择合适的工艺制程分开制造,再通过先进封装技术进行组装。
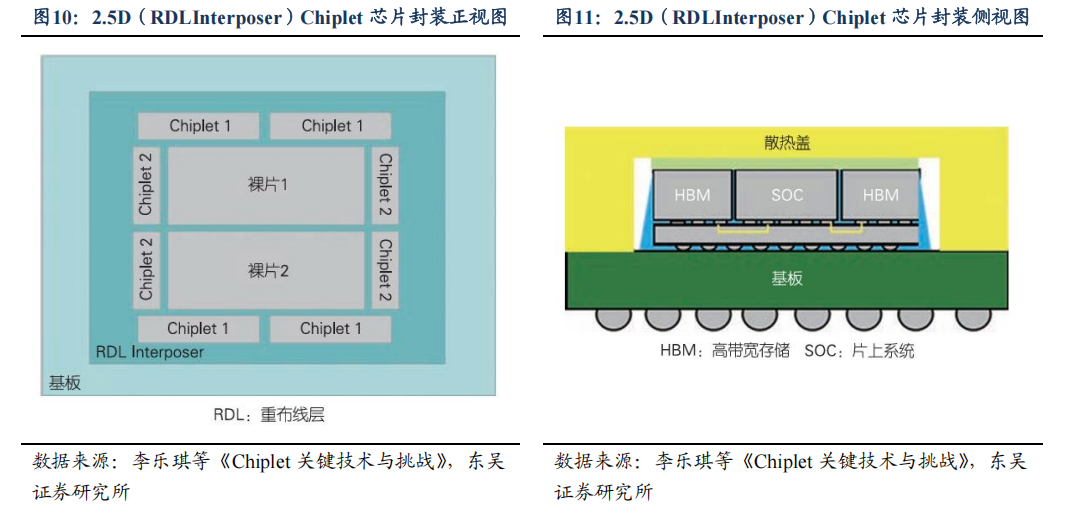
添加图片注释,不超过 140 字(可选)
软件优化方面,国内云厂商可能选择转向低参数模型+分布式训练模式,以缓解算力瓶颈。低参数模型硬件对存储和计算资源的需求较低,更适合在现有硬件条件下运行,同时训练速度更快,能够在有限的硬件资源下更快地完成训练任务,对于需要快速迭代和优化的 AI 应用场景尤为重要,阿里最新发布天问 3.0 大模型参数量仅 2350 亿。
另外,分布式训练将训练任务分解并分配到多个计算节点上共同完成,从而充分利用算力资源、提高训练速度和效率,从而能够训练更大、更复杂的模型,提高模型的精度和性能。
另外,以英伟达为代表的海外厂商可能采取降规降价的方式应对。未来海外厂商可能推出更多降规版 AI 芯片以符合 HBM 限令要求,具体方式可能有使用非 HBM 内存,如 GDDR 等进行替代,或可用于 AI 推理,减轻国内云厂商算力不足的压力。应对限令冲击,英伟达计划推出降规版 Blackwell 芯片特供中国。
据路透社消息,英伟达计划推出中国特供版 Blackwell 芯片,价格在 6500-8000 美金,低于 H20 的 10000-12000 美金。此款芯片将基于英伟达 RTX Pro 6000D,并使用 GDDR7 内存,以此配合美国对 HBM 的出口管制要求,另外新款芯片不会采用台积电 CoWoS 先进封装技术。
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号