
大规模 GPU 集群运维实践:假装万卡 GPU 集群经验
一、背景 最近几年,随着大规模深度学习模型(尤其是大语言模型)的快速发展,大规模 GPU 集群已成为支撑大规模模型训练的核心基础设施。大规模集群中往往会包含数千甚至上万张 GPU、涉及复杂的硬件配置、分布式计算框架及多维度的监控和调度体系。 在实际使用时,如何确保大规模 GPU 集群的高效稳定运行已成为一项核心挑战。GPU 硬件故障、网络抖动、通信瓶颈、资源调度不均、训练任务异常中断等问题均可能对大规模训练产生严重影响,导致资源浪费和模型训练效率下降。因此,深入理解和掌握大规模 GPU 集群的常见问题及其解决方案,对保障高效训练、提升系统稳定性具有重要意义。 为了假装构建、运维、使用过万卡 GPU 集群,我们之前已经整理过一系列相关文章,比如 “万卡 GPU 集群互联:硬件配置和网络设计” 和 “万卡 GPU 集群实战:探索 LLM 预训练的挑战” 等。本文中,我们基于小规模 GPU 集群的运维经验,系统梳理了在大规模训练中常见的硬件异常、通信故障、性能瓶颈、任务调度与资源利用、OOM(Out of Memory)等问题,并针对每类问题提供了相应的说明和示例。 相关介绍可以参考我们之前的文章:
二、引言 2.1 集群刻画 2.1.1 集群概览与任务分布 对于一个公司内的大规模 GPU 集群而言,通常需要同时支持多种任务类型,而非专用于单一任务。以 Meta 在论文 [2410.21680] Revisiting Reliability in Large-Scale Machine Learning Research Clusters [1] 中的描述为例:其集群中超过 90% 的任务规模小于一个节点(8 个 GPU),但这类小型任务仅消耗不到 10% 的 GPU 时间,剩余计算资源主要被少数大型任务占据。 针对这种“少量大型任务 + 大量小型任务”的任务分布模式,集群调度策略通常需要进行相应的设计与优化。常见的做法是:
-
大型任务采用节点粒度调度,通常直接分配多个节点,以保障训练性能和通信效率。
-
小型任务采用 GPU 粒度调度,允许多个小型任务共享同一节点,充分利用计算资源,避免 GPU 空闲或碎片化问题。
由于任务分布具有动态性,集群调度需要具备一定的灵活性,能够根据当前任务负载在节点粒度与 GPU 粒度之间进行动态平衡,以提高资源利用率。 2.1.2 主流训练任务与框架 当前大规模训练集群通常执行 CV 或 NLP 这类稠密模型任务,随着大模型的快速发展,训练集群也承担了越来越多的大模型预训练、监督微调(SFT)、强化学习(RL)、评估等任务。这些任务普遍会使用 PyTorch 作为核心训练框架,底层通过 NCCL(NVIDIA Collective Communication Library) 通信(很多公司还会在 NCCL 上魔改,提供内部版本)。 在 PyTorch 的基础上,经常会使用 Huggingface Transformer、DeepSpeed、Megatron-LM、Nemo 等框架,涉及视频生成还可能使用 OpenSORA(Colossal AI) 等。 2.1.3 硬件与网络架构 目前主流的大规模训练集群以 NVIDIA A100/A800 和 H100/H800 GPU 为主,单节点通常配置 8 张 NVL GPU,依托于 NVLink 和 NVSwitch 构建 GPU 间的全互联拓扑,确保节点内部的高带宽、低延迟通信(DeepSeek 的万卡 A100 集群是 PCIe GPU)。 每个节点通常配置 4 个或 8 个 IB/RoCE 网卡(A100 对应 200 Gbps,H100 对应 400 Gbps)用于跨节点的 GPU 通信,然后这些网卡通常会通过多机交换机构建无收敛的告诉后向网络。 2.2 关键信息 2.2.1 监控 监控中需要包含常见的监控指标,比如 CPU、内存、GPU、网卡、NVLink 等信息。这些指标可以有效辅助定位异常、分析性能。比如:
-
根据 Host 内存、GPU 显存使用量推测 OOM 的风险。
-
根据 GPU Utilization、SM Active、Tensor Active 推测性能:
-
Util 很低,可以看是否 CPU 相关处理占比过高,没有充分发挥 GPU 算力。
-
Util 很高,SM 很低,考虑是否通信占比很高。
-
Util 一直是 100%,而 SM 很低,考虑是不是 NCCL 通信阻塞。
-
Util 和 SM 很高,Tensor 很低,可以考虑是否模型中非矩阵计算占比过高。
-
如果 Tensor Active 很高,超过 50%,那么大概率任务的吞吐已经很高,比较难太大提升。
-
根据不同 GPU 的指标判断是否存在负载不均。
-
根据 CNP Slow Restart 判断是否有网络拥塞的风险。
-
根据监控指标的趋势识别首先出现异常的 Worker。
2.2.2 日志 除了监控指标之外,另一种非常有用的信息是日志,包括但不限于: 用户日志:用户任务打印的实时日志,比如训练进度信息,关键节点的锚点信息,以及一系列对于追踪任务进度和排查任务有帮助的信息。 节点日志:通常可以辅助排查问题,或者查看一些没有在用户日志中体现的信息。常见的方式是使用 dmesg 查看异常信息,比如 GPU 的 Xid Error,Host OOM 导致的进程被 Kill,以及 PCIe Link 降级,网卡抖动/Down 等等。可以重点关注任务异常时间附近的日志信息。除此之外,也可以在 syslog 中查看更细粒度的日志,比如 kubelet 的执行日志,可以查看 Pod 的相关操作记录。 操作日志:如果是 K8S 集群,其会包含丰富的 Event 信息,记录了与 Pod 生命周期相关的关键事件。可用于诊断 Pod 的状态变化或异常行为,比如 Pod 的 Start 和 Stop 时间,Pod 是否被驱逐,节点是否异常,Pending 的原因等。 插桩日志:为了实现用户无感、更细力度的追踪和监控,通常也会基于 NCCL 或者 eBPF 插桩,以便记录关键的操作或函数调用。比如新版本 NCCL 也专门提供的 NCCL Profiler Plugin [2],以便用户更好的从 NCCL 提取性能数据,并将其用于调试和分析。 TIPS:
-
GPU OOM 的异常通常不会在 dmesg 信息中,而是在用户侧日志中。
-
我们早期的大规模任务中会基于用户日志是否在持续更新来识别任务是否阻塞(比如 NCCL Hang)。具体来说,当前时间 - 用户日志上次更新时间 > 5min 时发出告警,提示任务存在 Hang 的风险。
2.2.3 告警&干预 基于监控和日志信息定制相应的告警和自动干预机制是非常常见的运维手段,比如识别到 GPU 故障需要自动屏蔽节点;除此之外,也可以添加自动的重启与验收机制,防止导致任务的频繁异常。常见的报警包括:
-
节点异常(Down、PCIe 链路降级等)。
-
GPU 异常(Lost,部分 Xid 错误、降速等)。
-
网卡异常(Down、降速、频繁抖动等)。
通常还会将硬件异常与任务相关联,比如检测到 GPU 异常后自动告知使用该 GPU 的用户。并进行相应的容错处理,比如迁移相应 Worker 或者触发任务重启等。当然,这里也会有些 Trick,比如单个 GPU 异常可能需要整个节点维护,此时需要考虑是禁止调度并等其他任务执行完成,或者是同样执行驱逐操作。 2.3 一些实践经验 2.3.1 锚点 在日志中添加相关锚点对于定位问题非常有帮助,比如在每个关键逻辑块的起始和终止位置打印相应可识别的日志;在 Train 和 Validation 的每个 Step 打印相应的信息等。 比如可以通过 “NCCL INFO Bootstrap” 关键字来判断 NCCL 初始化的开始。通过 “NCCL INFO xxx Init COMPLETE” 关键字来判断 NCCL 初始化完成。 TIPS:基于不同 Worker 中这些日志的时间戳可以大致判断各个 Worker 的执行进度。 2.3.2 可复现性/随机性 随机性是训练中常见的现象,有些是预期中的,有些是预期外的,有时排查问题也需要排除这些随机性。常见的有几类:
-
预处理的随机性:比如 CV 预处理中常见的随机裁剪、旋转等,通常可以固定随机种子来保证确定性。
-
模型算子的随机性:模型底层算子不可避免的会引入一些 none-deterministic 行为,可以通过相应的配置尽可能避免这些的问题。
PyTorch 中也提供了相应的文档介绍可复现性方法,可以参考:Reproducibility — PyTorch 2.6 documentation [3]。 TIPS:
-
二分法简单粗暴,往往是获得最小可复现 Codebase 以便协助排查问题的有效手段;
-
随机输入有些时候反而影响排查问题,可以考虑保存真实数据的中间状态作为下一阶段的输入,比如直接保存模型的输入并剥离前后处理以便排查模型问题。
2.3.3 Checkpointing 对于规模比较大或者时间比较长的任务,定时保存 Checkpoint 可以有效避免各种异常导致的无效训练。
-
需要考虑保存 Checkpoint 的耗时和存储空间占用。可以通过分布式保存缩短保存时间,或者异步保存等方式减少对训练进度的干扰。
-
如果训练资源规模比较大,那么整个任务因某个 GPU 或节点异常导致失败的概率会非常高,可以适当缩短 Checkpointing 间隔。比如很多公司的大模型预训练会将 Checkpointing 间隔保持在 30min 甚至 5min。
2.3.4 锁定异常 Worker 当任务涉及的 Worker 比较多时,逐个排查日志或监控信息非常耗时,此时快速定位异常 Worker 显得至关重要。如果整个任务已经异常,通常可以基于 Worker 的状态快速识别;如果任务 Hang 住,或者异常 Worker 没有太多有效信息,可以尝试从监控中排查异常 Worker。 比如,可以尝试找到监控中首先出现异常的 Worker。通常表现为监控数据首先降为 0,或者没有相应数据。如下图所示,红框处 Worker 的监控指标首先消失(通常意味着 Worker 首先被终止)。
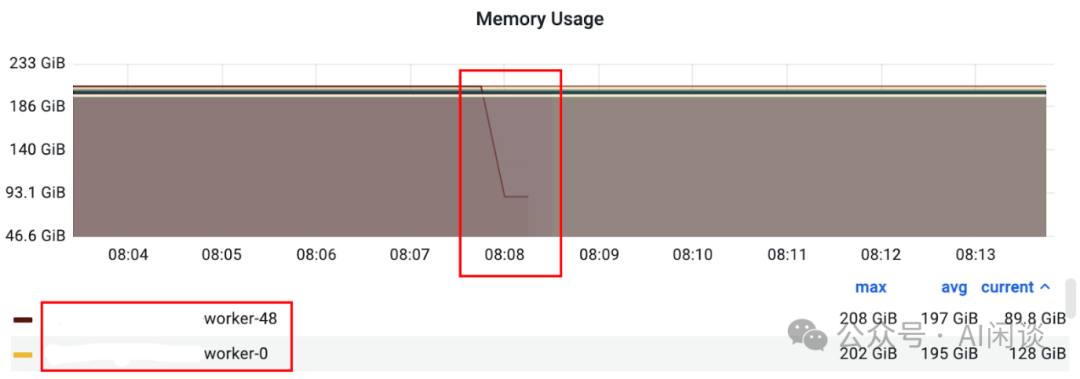
添加图片注释,不超过 140 字(可选)
TIPS:可以使用 PromQL 的 count_over_time 指标来协助快速识别异常 Worker。count_over_time 主要用于计算给定时间区间内某个指标的样本数量,可以帮助分析一段时间内事件的发生次数。如下图所示,某个 Worker 首先出现异常,数据点开始丢失,其对应的 count_over_time 指标就会首先出现下降趋势,进而可以直接定位出现异常的 Worker:

添加图片注释,不超过 140 字(可选)
三、GPU 利用率指标 通过 GPU 利用率指标,在不用深入业务代码的情况下即可对任务的性能有个初步的认知,对于同样的任务也可以基于这些指标来了解任务的相对吞吐是否有变化。 3.1 GPU Utilization 对应 DCGM 的 DCGM_FI_PROF_GR_ENGINE_ACTIVE,表示在一个时间间隔内 Graphics 或 Compute 引擎处于 Active 的时间占比。Active 时间比例越高,意味着 GPU 在该周期内越繁忙。该值比较低表示一定没有充分利用 GPU,比较高通常意味着 GPU 硬件繁忙,但不代表计算效率高。如下图所示,表示几个 GPU 的 Utilization 到了 80%-90% 左右:

添加图片注释,不超过 140 字(可选)
其实更早之前的 Utilization 指标为 DCGM_FI_DEV_GPU_UTIL,只是因为其局限性现在往往会使用 DCGM_FI_PROF_GR_ENGINE_ACTIVE,更多说明也可以参考:Question about DCGM fields · Issue #64 [4]。 3.2 GPU SM Active 对应 DCGM 的 DCGM_FI_PROF_SM_ACTIVE,表示一个时间间隔内,至少一个 Warp 在一个 SM 上处于 Active 的时间占比,该值表示所有 SM 的平均值,对每个 Block 的线程数不敏感。该值比较低表示一定未充分利用 GPU。如下为几种 Case(假设 GPU 包含 N 个 SM):
-
Kernel 在整个时间间隔内使用 N 个 Block 运行在所有的 SM 上,对应 100%。
-
Kernel 在一个时间间隔内运行了 N/5 个 Block,该值为 20%。
-
Kernel 有 N 个 Block,在一个时间间隔内只运行了 1/4 时间,该值为 25%。
如下图所示为几个 GPU 的 SM Active,可见只有 60% 左右,还有一定提升空间:

添加图片注释,不超过 140 字(可选)
3.3 GPU SM Occupancy 对应 DCGM 的 DCGM_FI_PROF_SM_OCCUPANCY,表示一个时间间隔内,驻留在 SM 上的 Warp 与该 SM 最大可驻留 Warp 的比例。该值表示一个时间间隔内的所有 SM 的平均值,该值越高也不一定代表 GPU 使用率越高。 如下图所示为几个 GPU 的 SM Occupancy,只有 20% 多:

添加图片注释,不超过 140 字(可选)
3.4 GPU Tensor Active 对应 DCGM 的 DCGM_FI_PROF_PIPE_TENSOR_ACTIVE,表示一个时间间隔内,Tensor Core 处于 Active 的时间占比,该值表示的是平均值,而不是瞬时值。如下所示是几种 Case(假设 GPU 包含 N 个 SM):
-
整个时间间隔内,N/2 个 SM 的 Tensor Core 都以 100% 的利用率运行,该值为 50%。
-
整个时间间隔内,N 个 SM 的 Tensor Core 都以 50% 的利用率运行,该值为 50%。
-
整个时间间隔内,N/2 个 SM 的 Tensor Core 都以 50% 的利用率运行,该值为 25%。
-
整个时间间隔的 80% 时间内,N/2 的 SM 的 Tensor Core 都以 50% 的利用率运行,该值为 20%。

添加图片注释,不超过 140 字(可选)
四、GPU 异常 4.1 Xid Error 概览 Xid Error 是 NVIDIA GPU 在运行过程中遇到的一种硬件或驱动层面的错误。Xid Error 通常会出现在 NVIDIA Driver 的日志中,并带有一个特定的错误代码。此错误码可以通过 DCGM 的 DCGM_FI_DEV_XID_ERRORS 获取,表示一段时间内,最后发生的 Xid 错误码。 如下图所示为一些常见的通常由用户应用程序导致的错误:

添加图片注释,不超过 140 字(可选)
如下图所示为一些常见的通常由硬件导致的错误,往往需要重置 GPU 或者报修:

添加图片注释,不超过 140 字(可选)
TIPS:这些异常通常会在 dmesg 中,可以通过监控 dmesg 日志实现一系列的自动运维机制。 4.2 Xid Error 31 Xid Error 31 表示 GPU Memory Page Fault,通常是应用程序的非法地址访问,极小概率是驱动或者硬件问题。

添加图片注释,不超过 140 字(可选)
在节点侧的日志中体现为 “MMU Fault”、“Fault is of type FAULT_PDE ACCESS_TYPE_VIRT_READ” 等信息;用户侧通常展示为 “CUDA error: an illegal memory access was encountered” 等信息。 虽然 Xid Error 31 绝大部分都是业务代码的问题,但也有比较小的概率是硬件或驱动问题。如下所示,曾在一台比较老的 V100 机器上遇到一个 Case,使用 cuda-sample 中的 matrixMul 都会报 cudaErrorIllegalAddress,在机器上也有 Xid 31 的错误;除此之外,使用 CUDA-GDB 调试也会导致相应进程 Hang 住,NvDebugAgent 变为僵尸进程;然而,在同一台机器上的其它 GPU 上执行并未出现错误. 4.3 Xid Error 79 Xid Error 79 表示 GPU has fallen off the bus,意味着 GPU 出现了严重的硬件问题,无法从总线上检测到,也就是常说的掉卡。

添加图片注释,不超过 140 字(可选)
在节点侧的日志中经常展示为 “GPU has fallen off the bus”。同时使用 nvidia-smi -L 也可以看到相应的 “Unable to determine the device handle for gpu xxx: Unknown Error”。此问题也可能会伴随着 NVSwitch 的错误(Sxid Error)一起出现,比如出现:“SXid(PCI:xxx): 24007, Fatal, Link 44 sourcetrack timeout error (First)”。 用户侧通常会展示为 “RuntimeError: No CUDA GPUs are available” 或 “CUDA error: unknown error”。 4.4 Xid Error 48/63/94 Xid Error 48 表示 GPU 出现了不可纠正的 ECC Error,通常是硬件问题,需要终止 GPU 上的相关进程并重置 GPU。也经常会与 63/64 和 94/95 一起出现:
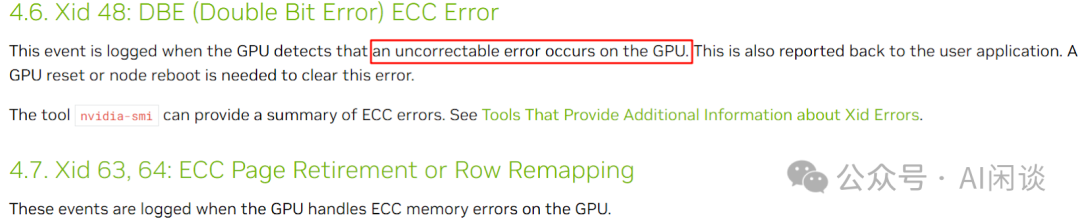
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
在节点侧的日志中经常展示为 “An uncorrectable double bit error” 或 “Row Remapper”;在用户侧通常也会展示相应信息 “CUDA error: uncorrectable ECC error encountered”。 4.5 Xid Error 109/119/120 Xid Error 119/120 表示 GSP RPC Timeout / GSP Error,通常是 GPU 的 GSP(GPU System Processor)组件运行状态异常,也可能会和 Xid Error 109 一起出现:

添加图片注释,不超过 140 字(可选)
可以选择关闭 GSP,避免 GSP 出现的一系列问题。使用 nvidia-smi 可以查看是否关闭 GSP。如下图所示,如果有对应版本号则表示开启,如果对应为 N/A 则表示已经关闭:
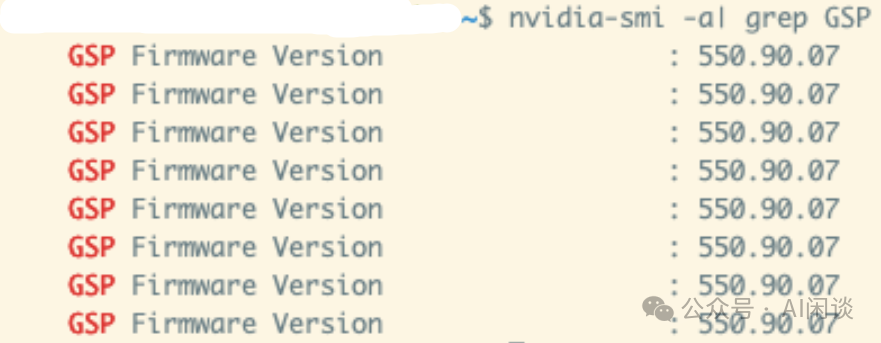
添加图片注释,不超过 140 字(可选)
在节点侧的日志中经常展示为 “Timeout after 6s of waiting for RPC response from GPUx GSP!”,与此同时也可能伴随 Xid Error 109;在用户侧的日志中经常展示为 “CUDA error: unspecified launch failure” 等。 当然,并不意味着关闭 GSP 就不会出现 Xid Error 109 的问题,关闭 GSP 后个别情况下还是会有单独出现 Xid Error 109 的情况。在节点侧日志中会有 “errorString CTX SWITCH TIMEOUT” 信息,而在用户侧同样会有 “CUDA error: unspecified launch failure”。 五、其他硬件异常 5.1 PCIe 降速(网卡降速) PCIe 降速是非常常见但又容易被忽略的问题,其相应的也可能导致网卡降速,影响整体的训练性能。因为只是降低了速度而并不会中断,因此容易被忽略,此时一个正确的性能基线显得尤为重要。 在节点侧日志中通常会展示类似如下信息:“PCIe 16x Link -> 2x Link”,可能还会有相应的速度提示,比如从 252.048 Gb/s 降低到 31.506 Gb/s。 相应的 PCI 总线配置中也可以看到异常网卡的 LnkSta 与正常网卡有明显区别,并且存在 “(downgraded)” 信息。 此时也可能会对应网卡的 CNP Slow Restart 数量增多。CNP Slow Restart 指标可以参考 roce_slow_restart_cnps:
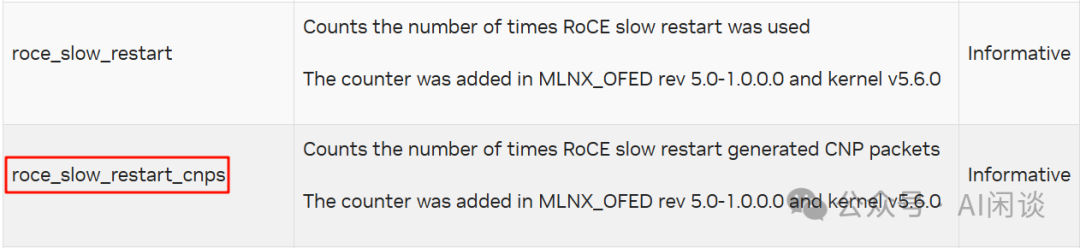
添加图片注释,不超过 140 字(可选)
5.2 网卡抖动 有些时候网卡也会出现偶尔的抖动,节点侧表现为短暂的 “Link down” 和 “Link up”。 与此同时,用户侧的 NCCL 日志用也会出现 “port error” 和 “port active” 信息,如果发生的时间比较短,重试成功后任务会继续执行,也可能会看到 GPU Tensor Active 等指标会有个短暂的下降并快速恢复的过程。 5.3 网卡 Down 有些时候网卡会频繁 “Link down” 和 “Link up” 甚至不可用。这种情况往往会导致 NCCL 通信的 Timeout,出现 “Connection closed by localRank”、“Timeout(ms)=1800000”、“Some NCCL operations have failed or timed out” 等信息。 TIPS:需要说明的是,1800000 timeout 是 NCCL 默认的 30 分钟超时时间。有时为了快速结束异常,可能会缩短 Timeout 间隔,但是太低的间隔也会导致网络抖动直接触发退出。 5.4 GPU 降频 GPU 降频也是一个常见的问题,可以通过 GPU SM CLOCK 指标观察,可能由于电源供应不足或者温度过高导致。 其通常会对性能造成极大的影响,比如我们曾遇到过 PSU 问题导致 GPU SM CLOCK 从正常的 2 GHz 降低到 500 MHz,从而导致整个任务的性能降低到原来的 1/4。 TIPS:此时也可能会出现同一任务中,降频后的 GPU 的 SM Active 指标比较高,而正常 GPU 的 SM Active 比较低。 5.5 慢节点 除了 PCIe 降速、GPU 降频会导致训练任务降速之外,慢节点导致降速更难被发现。比如说,我们在一个训练任务中遇到相同任务的相同配置下,多次启动时训练速度会有一定的差距,MFU 相对差距达到 10% 以上,甚至超过一些优化方案所能带来的收益。最终发现是存在慢节点导致,在排除慢节点后性能非常稳定。 如下图 Figure 6 所示,字节在 [2402.15627] MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs [5] 中也提到过慢节点的问题。当然其也提到有些慢节点不是一直导致任务降速,而是在训练中逐渐降速。
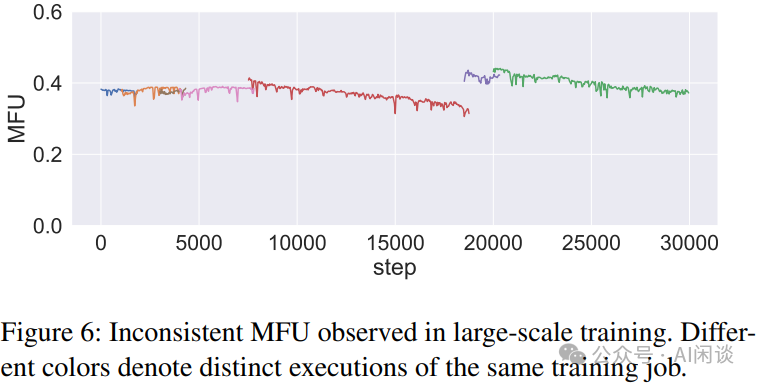
添加图片注释,不超过 140 字(可选)
可以使用 Prometheus + Node Exporter 收集 CPU、GPU、PCIe 带宽指标,定位慢节点,但是可能很不显著。也可以结合 “通信时间分布图” (比如 NCCL 中的 send/recv) 来发现潜在的慢节点。 5.6 节点 Down 节点 Down 也会导致任务的异常,在 K8S Event 日志中会有 “NodeNotReady” 等信息。随后节点上的任务会被驱逐,也可能会出现 “TaintManagerEviction”。 出现该问题的可能比较多,不过通常比较直观,容易被发现并及时终止任务,相比空转或性能下降要更好。除了在 Event 中有相关信息外,监控机制也会及时发现这类异常并及时上报。 5.7 频繁异常节点 相比慢节点而言,故障节点更容易定位,但是频繁故障的节点对于集群整体的有效利用率也是致命的。对于大规模任务而言,频繁故障的节点会明显增加训练任务的中断率,从而导致重启以及未来得及保存 Checkpoint 而出现的计算浪费(故障与上次 Checkpoint 之间的计算)。 Meta 在 [2410.21680] Revisiting Reliability in Large-Scale Machine Learning Research Clusters [6] 中将其称为 Lemon 节点,指那些作业失败率显著高于平均水平的节点。Meta 在集群中通过识别出 Lemon 节点,使得大规模作业(512+ GPU)的失败率降低 10%,从 14% 降低至 4%。 我们在新集群的起始阶段也遇到过类似问题,具体来说,我们发现某些节点的 GPU 频繁出现 Xid Error 而导致任务异常,当将这些节点驱逐后发现任务稳定性明显提升。 如下图所示,通常来说,一个集群在其整个生命周期中的故障率(蓝色)变化呈现出 “浴缸曲线(Bathtub Curve)” 的形式,包括 3 个阶段:
-
故障率下降阶段(早期):集群的初期阶段,各系统之间可能都还未磨合好,一些频繁异常的节点也未被识别出来,故障会非常频繁。主要故障对应红色曲线。
-
故障率稳定阶段(中期):随着时间推移,故障率会稳定下来,进入一个恒定阶段,此阶段的故障往往比较随机。主要故障对应绿色直线。
-
故障率上升阶段(晚期):当集群接近其生命周期末期时,由于系统中组件逐渐磨损、老化,导致故障更加频繁,这个阶段也通常称为“磨损故障”期。主要故障对应橙色曲线。
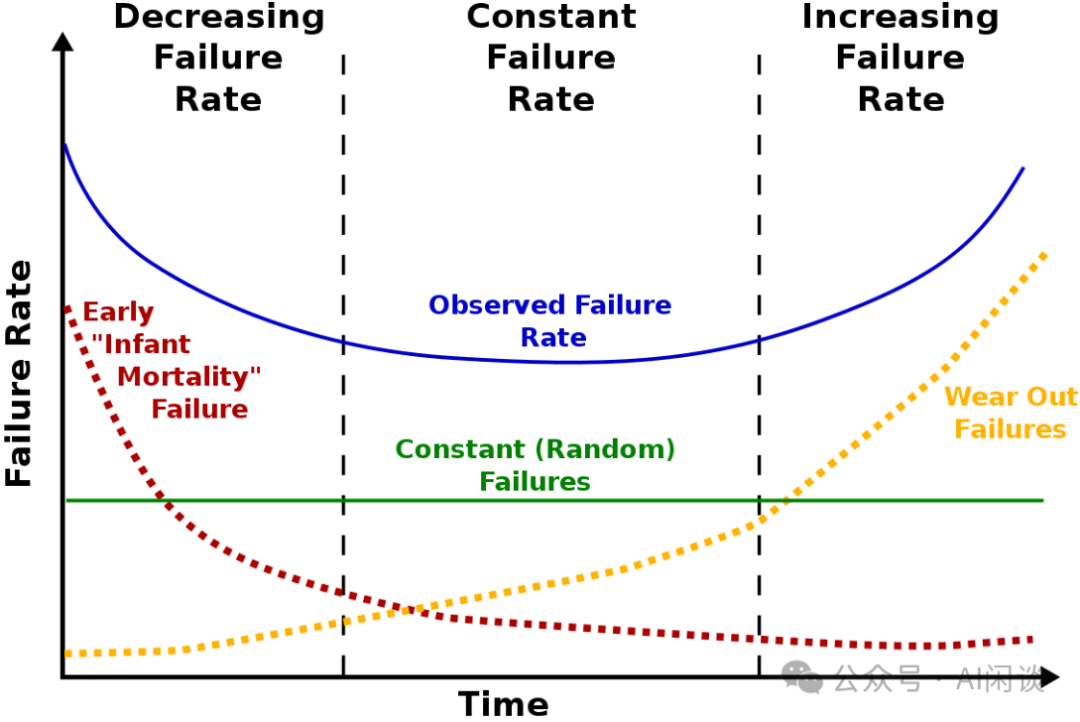
添加图片注释,不超过 140 字(可选)
六、性能问题 6.1 概述 上述提到的 PCIe 降速(或网卡降速)、GPU 降频都会导致非常明显的训练降速问题,比如可能导致训练任务降速 2-8 倍,如果有明确的基线通常比较容易发现此问题。相对而言,慢节点可能只是稍微影响训练速度,比如 10% 左右,对于大规模训练任务更需要关注,而在小规模任务经常被忽略。 除此之外,也有一些其他容易影响性能的因素,这里简单介绍。 6.2 周期性降速 我们遇到过任务周期性降速的问题,起初怀疑过 DataLoader 和 Checkpointing 的问题,也怀疑过节点有周期性任务导致,依次都被排除;也进一步排查了 CPU、GPU、网络等均未发现明显问题;最终发现某个 Rank 中 Python 的垃圾回收机制会导致一直持有 GIL,进而导致当前 Rank 成为 Straggler,拖累整个训练任务。当任务规模比较大时,多个 Rank 在一段时间内陆续成为 Straggler,进而放大该问题的影响范围:
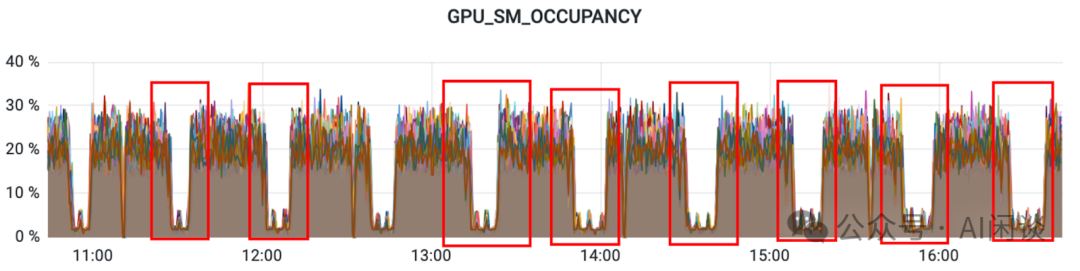
添加图片注释,不超过 140 字(可选)
解决上述问题的方法也比较简单粗暴,比如 Megatron-LM 中有主动 GC(Garbage Collect) 的选项(Megatron-LM/megatron/training/training.py [7])。如下图所示,可以在一定的 Step 后所有 Rank 同时主动 GC,这样就可以将所有 Rank 的 GC 放在同一时间,降低对整个任务的影响:

添加图片注释,不超过 140 字(可选)
6.3 调度问题导致降速 按 GPU 的细粒度调度方式也可能会导致性能问题。比如,我们遇到过一个 8 GPU 任务两次执行速度差一倍的情况,排查后发现其使用了 TP(Tensor Parallelism) + DP(Data Parallelism) 的方式:
-
快的任务:正好调度到 1 台 8 GPU 机器上,可以充分利用 NVLink + NVSwitch 通信,速度很快。
-
慢的任务:被调度到 2 台机器,导致 TP 需要跨机通信,影响整体训练速度。
TIPS:TP 的通信量比较大,在有条件的情况下都会将 TP 通信限制在一个节点内,充分利用 NVLink + NVSwitch,这也是为什么在大规模训练中往往 TP 的大小不会超过 8。 6.4 网络配置导致降速 这个可能的原因比较多,比如是否启用 ZRT-RTTCC(具有往返时间拥塞控制的缩放零接触RoCE 技术 [8])、是否使用流量隔离(DeepSeek 在 A100 Infra 文章和 DeepEP 开源库中都有提到,通过为不同类型流量分配不同的 Service Level,以避免流量之间的干扰)。 TIPS:集群的交付验收阶段通常会有一系列的准入测试,比如使用 ib_write_bw、ib_read_bw、nccl-tests 等工具验证,可以很好的发现和解决类似问题。即使有漏网之鱼,也往往会在交付之后的早期阶段被发现。 6.5 任务抢占导致降速 如果采用按 GPU 粒度的调度方式,那么一个节点上的多个 GPU 可能属于不同的任务。此时,如果 GPU 隔离方式不彻底,用户强制修改使用的 GPU 会导致影响被抢占 GPU 对应的任务(比如实际分配了 7 号 GPU,但通过修改配置使用 0 号 GPU)。 如下图所示,在早期阶段,我们发现一个多 GPU 的任务性能不符合预期,在查看监控后发现只有一个 GPU 的 SM Active 比较高,其他 GPU 对应的 SM Active 比较低。定位后发现用户强制使用了非分配的 GPU,出现抢占问题,驱逐相应任务后速度恢复正常。
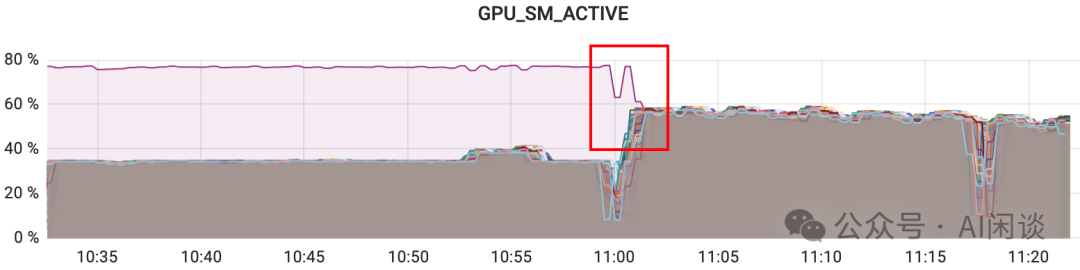
添加图片注释,不超过 140 字(可选)
TIPS:通常会使用 CUDA_VISIBLE_DEVICES 和 NVIDIA_VISIBLE_DEVICES 来限制进程或容器中 GPU 的可见性;也可以通过 NVIDIA_DRIVER_CAPABILITIES 环境变量精细化控制容器内可以使用的 GPU 功能,比如如果设置不当可能导致 GPU 进行视频编解码的异常。 七、OOM 问题 7.1 Shared Memory OOM 训练任务通常需要一定的 Shared Memory 来执行进程间通信,如果 Shared Memory 不足可能会出现问题。如下所示的 “Bus error: nonexistent physical address” 是其中一种常见的问题。 在 https://github.com/huggingface/transformers-bloom-inference/issues/16 [9] 也有提到类似问题:

添加图片注释,不超过 140 字(可选)
7.2 GPU OOM - 任务自身问题 GPU OOM 是训练中非常常见的问题,并且由于监控采集存在一定间隔(比如 10s 一个数据点),导致监控中可能无法体现这个问题。 为此,可以尝试从日志中查看,如下图所示,PyTorch 会打印比较详细的 OOM 日志,通常包含 “OutofMemoryError: CUDA out of memory” 信息,并且显示当前进程已经使用了多少显存(“this process has 79.24GiB memory in use”),尝试申请多少显存(“Tried to allocate 3.38 GiB”)等信息:

添加图片注释,不超过 140 字(可选)
当然,偶尔也会对应 NCCL 的 OOM,对应 “NCCL WARN CUDA failure 2 ‘out of memory’” 信息。如果是在保存 Checkpoint 这种明确的位置,可以适当的添加 torch.cuda.empty_cache() 来规避。 7.3 GPU OOM - 抢占问题 除了用户自身问题导致的 GPU OOM 外,如果隔离不彻底,也会有极小的概率存在资源抢占导致的 OOM。和抢占导致任务降速的原因一样,都是因为某些任务错误使用了非分配的 GPU。 TIPS:如果任务中某个 GPU 的 GPU_MEM_USED 获取他指标明显高于其他 GPU,并且是任务刚启动就占用比较高,很有可能是有问题的。 7.4 GPU OOM - CUDNN_STATUS_NOT_INITIALIZED 有些时候 OOM 并不会输出明确的 out of memory 信息,比如 PyTorch 会采用 lazy Init 的方式初始化 cuDNN。然而,如果 PyTorch 已经使用完所有 GPU 显存,就会导致初始化 cuDNN 时没有足够显存,出现类似 “cuDNN error: CUDNN_STATUS_NOT_INITIALIZED” 的错误。 7.5 GPU OOM - PyTorch 显存优化 如果使用 PyTorch 训练,当 GPU 显存占用比较高时,可以尝试使用 PYTORCH_CUDA_ALLOC_CONF 环境变量来优化显存的占用,相关文档可以参考 CUDA semantics — PyTorch 2.6 documentation [10]。 一种比较典型的 Case 是设置 PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True" 来降低显存碎片化问题。具体来说,对于频繁改变显存分配大小的场景,比如,模型输入 Shape 频繁变化(图像 Shape、序列长度等),此配置允许创建可扩展的 CUDA 内存段,避免因微小分配变化导致的内存碎片问题。当然,此功能可能会影响分配性能。 7.6 Host OOM 为了实现按 GPU 细粒度调度,有时会将 Host Memory 按照 GPU 数量平均切分,就可能导致分给每个 GPU 的 Host Memory 不是特别多。此时,对于那些在 Master 中进行全量 Checkpoint 保存或加载的任务可能会出现 OOM。对于加载 Checkpoint 而言,其 Master 进程将整个 Checkpoint 加载到内存,然后切片后传输到相应的 GPU 显存,并释放相应空间;保存 Checkpoint 与其相反。 TIPS:相对 GPU 的 OOM 而言,Host Memory 的 OOM 通查更容易发现和定位,比如通常 dmesg 日志中会有相应信息。 八、PyTorch 训练常见问题 8.1 PyTorch 初始化端口占用 PyTorch 的分布式训练中,任务初始化阶段 Master 会占用一个端口,以便其他 Worker 与其通信,对应 MASTER_ADDR 和 MASTER_PORT。如果端口已经被占用,则会出现绑定失败的问题。相关环境变量如下所示,可以参考 Distributed communication package - torch.distributed — PyTorch 2.6 documentation [11]:

添加图片注释,不超过 140 字(可选)
如果未正确使用指定的 MASTER_PORT,则可能出现端口占用的问题,出现 “The server socket has failed to bind to [::|::xxx]”、“Address already in use” 等信息。 在 PyTorch 的分布式训练中,Master 负责绑定端口,其他 Worker 与其建立连接。比如使用 HuggingFace accelerate 启动任务,由于使用方式问题,导致其他 Worker 也去尝试绑定 MASTER_PORT,则会出现 “ConnectionError: Tried to launch distributed communication on port xxx, but another process is utilizing it.” 相关信息。

添加图片注释,不超过 140 字(可选)
8.2 PyTorch 初始化 Timeout PyTorch 初始化阶段除了端口被占用外,另一个常见的问题是 “torch.distributed.DistStoreError: Socket Timeout”。此问题通查意味着节点间通信受阻,需逐一排查网络、配置、资源及同步问题。 如下图所示,PyTorch 分布式训练中,起始阶段其他 Worker 与 Master 建立连接的默认超时时间是 300 秒:
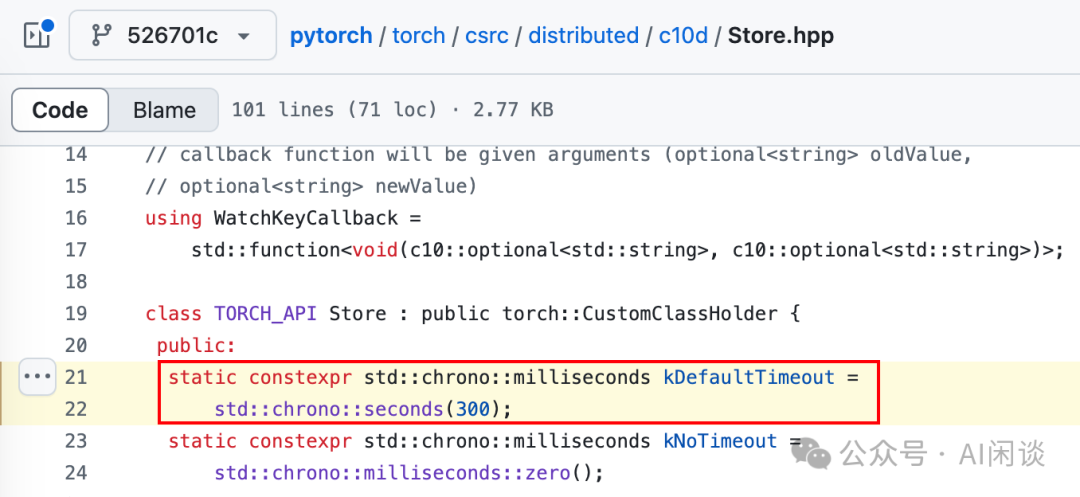
添加图片注释,不超过 140 字(可选)
可以通过 PyTorch 的 dist.init_process_group 来控制,如下图所示,不过有些框架中可能没有暴露这个接口:

添加图片注释,不超过 140 字(可选)
这一问题常见有如下几个原因:
-
Pod 启动不同步:如果在启动 Pod 之前还有启动初始化操作,比如巡检或者镜像下载,则可能出现 Pod 启动不同步的问题。
-
torchrun 启动不同步:常见原因是 Warmup 阶段不同步,比如所有 Worker 都在调用 torchrun 之前安装依赖包,尤其是需要编译的某些包。则可能由于网络等原因导致完成时间不太统一,启动 torchrun 的时间可能会间隔 5 分钟以上,进而导致上述 socket timeout 的问题。
TIPS:为了更好的定位此类问题,可以在调用 torchrun 之前打印唯一的、比较明确的日志信息。比如,在调用 torchrun 之前打印了 “RANK: xxx…” 信息,根据这个信息可以推测每个 Worker 调用 torchrun 的时间戳,进而判断启动是否同步,甚至某个 Worker 是否执行到 torchrun。 九、PyTorch 训练常见问题 9.1 NCCL 2.20.x 版本 Bug(Message truncated) 我们多次遇到用户使用 PyTorch 训练时出现类似如下的错误,日志中有 “Message truncated” 异常:
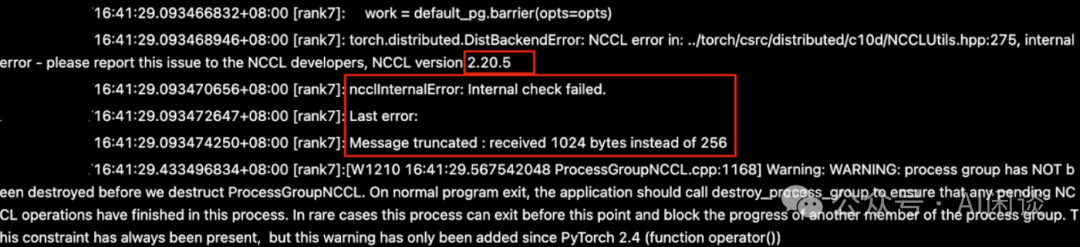
添加图片注释,不超过 140 字(可选)
这个是 NCCL 2.20.x 版本的 Bug,已经在 2.21+ 版本修复,具体可以参考:[BUG] NCCL2.20.5 meets "Message truncated : received 1024 bytes instead of 256" error while 2.18.5 not · Issue #1273 · NVIDIA/nccl · GitHub 9.2 NCCL 异常 在容器环境下,还可能出现 “Cuda failure ‘invalid device context’” 和 “ncclIUnhandedCudaError: Call to CUDA function failed” 的异常,NCCL 从 2.21 版本开始修复了这个问题,升级 NCCL 版本可以解决。 9.3 NCCL Hang & Timeout 9.3.1 现象 训练中 NCCL Hang 住或 Timeout 的问题也是非常常见的问题。如下图所示,NCCL Hang 住的典型特征是 GPU_Util 为 100%,而 GPU_SM_Active 或 GPU_Tensor_Active 指标接近于 0。
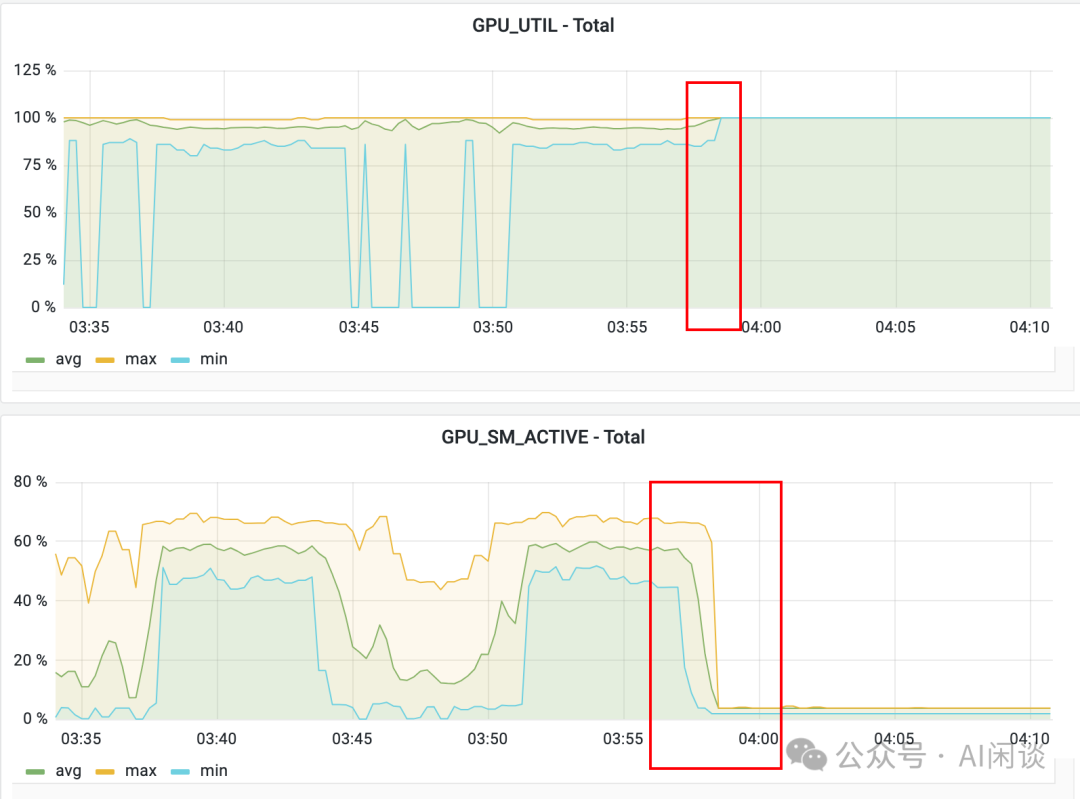
添加图片注释,不超过 140 字(可选)
NCCL 通信的默认 Timeout 为 30min 中,上述问题通查会在 30min 后异常退出,如下图所示:
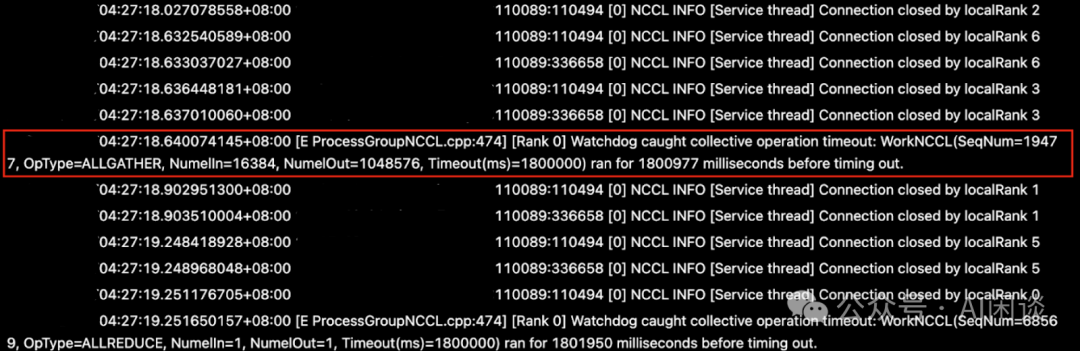
添加图片注释,不超过 140 字(可选)
9.3.2 NCCL 初始化 Hang 住 NCCL 初始化阶段 Hang 住出现的概率比较低,可能和 nvidia-fabricmanager 组件有关(当然,也可能是其他原因,比如网络环境异常,导致节点无法正确建立 P2P 通信)。Fabric Manager负责配置 NVSwitch 内存结构,以在所有参与的 GPU 之间形成一个统一的内存结构,并监控支持该结构的 NVLink。从较高层次来看,FM 承担以下职责:
-
配置 NVSwitch 端口之间的路由;
-
与 GPU 驱动程序协调,初始化GPU;
-
监控结构中的 NVLink 和 NVSwitch 错误。
NCCL 在 2.17+ 版本开始支持 NVLink Sharp,这个也是在 H100 的 NVSwitch 才支持的。当用户设置 NCCL_ALGO=NVSL 以及 NCCL_NVLS_ENABLE(默认),需要启动对应的 nvidia-fabricmanager。

添加图片注释,不超过 140 字(可选)
具体来说,我们发现多机分布式训练时 Pytorch 在初始化节点会 Hang 住,甚至用 NCCL 的 AllReduce 测试也会 Hang,但设置 NCCL_ALGO=Ring 则可以正常执行。最终发现是节点上 nvidia-fabricmanager 异常退出导致的,通过重启 nvidia-fabricmanager 可以解决(有些时候也需要重启机器 NCCL 2.18 / Cuda 12.2 fails on H100 system with transport/nvls.cc:165 NCCL WARN Cuda failure 'invalid argument' · Issue #976 · NVIDIA/nccl · GitHub [12])。

添加图片注释,不超过 140 字(可选)
9.3.3 通信操作不 match 导致 NCCL Timeout PyTorch 训练中出现 NCCL Timeout 很多是因为通信操作不匹配导致的。比如,代码中有逻辑判断,只有一个 Rank[0] 在执行 AllReduce 操作,其他 Rank 都在执行 AllGather 操作,导致通信阻塞并 Timeout。

添加图片注释,不超过 140 字(可选)
TIPS:这类问题通常会伴随 “[Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=xx, OpType::YYY, Numelln=xxx, NumelOut=xxx, Timeout(ms)=60000)” 日志信息,可以通过所有 Worker 的 OpType 来判断在执行什么通信操作,根据 Numellm 和 NumelOut 判断通信量。 9.3.4 GPU OOM 导致任务通信 Hang 这个问题与上述 GPU Util 全部变为 100% 的现象稍有不同,如下图红框所示,Max 值一直是 100%,而 Min 值一直是 0%。
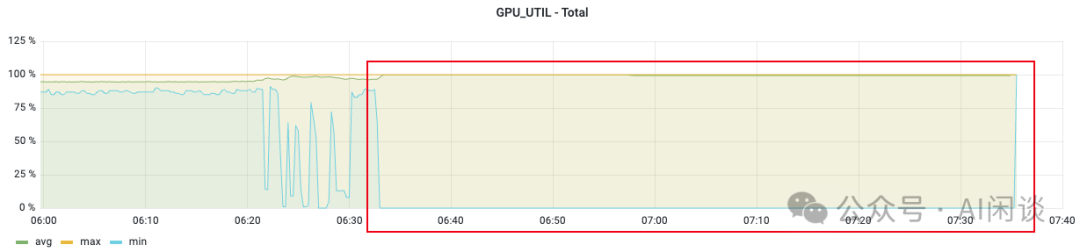
添加图片注释,不超过 140 字(可选)
这个问题很可能是个别 Worker 出现 “torch.OutOfMemoryError: CUDA out of memory”,影响了 NCCL 通信,当前 Worker 退出,但是其他 Worker 没有感知到。
十、参考链接
-
https://arxiv.org/abs/2410.21680
-
https://github.com/NVIDIA/nccl/tree/master/ext-profiler
-
https://pytorch.org/docs/stable/notes/randomness.html
-
https://github.com/NVIDIA/DCGM/issues/64
-
https://arxiv.org/abs/2402.15627
-
https://arxiv.org/abs/2410.21680
-
https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/training/training.py
-
https://developer.nvidia.com/zh-cn/blog/scaling-zero-touch-roce-technology-with-round-trip-time-congestion-control/
-
https://github.com/huggingface/transformers-bloom-inference/issues/16
-
https://pytorch.org/docs/stable/notes/cuda.html#optimizing-memory-usage-with-pytorch-cuda-alloc-conf
-
https://pytorch.org/docs/stable/distributed.html
-
https://github.com/NVIDIA/nccl/issues/1273
-
https://github.com/NVIDIA/nccl/issues/976#issuecomment-1697103183
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号