
谈谈大模型推理优化
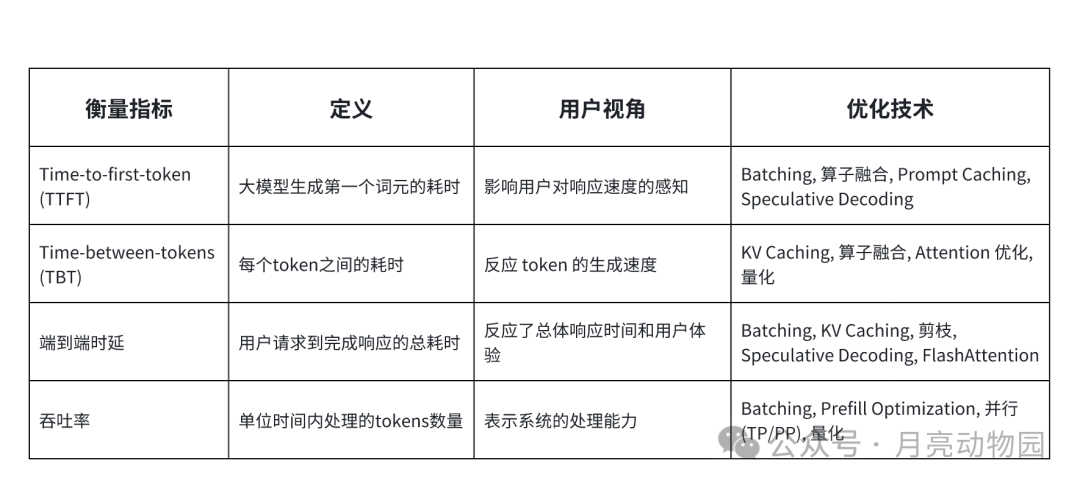
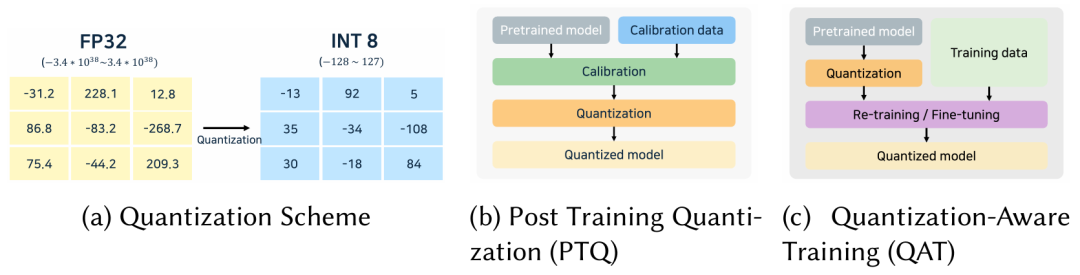
大模型推理引擎采用了多种定制化的优化技术,针对预填充和解码阶段进行优化。大多数引擎都使用了 KV Caching 避免解码阶段的重复计算,使用缓存的上下文,只计算最新一个 token。引入连续批处理和混合批处理,进一步优化解码阶段性能;对多个请求的分组预填充、分组解码可以更好利用GPU资源。解码阶段使用算子融合和硬件特有的加速计算核,减少每个token生成的开销。算子融合, 比如, 将 LayerNorm, 矩阵乘, 激活函数 融合成一个算子, 减少访存和 Kernel Launch 的开销。量化是另一个主要的优化方法。用 8比特或4比特整型,替换16比特或32比特浮点类型,对内存使用和带宽需求降低, 尤其是在解码阶段。量化模型可以缓存更多的 tokens , 处理更多的并发请求,提升计算速度。
添加图片注释,不超过 140 字(可选)
通常 caching, batching, 算子优化, 量化是优化大模型推理服务的 token 吞吐、减少时延的基础方法。在推理引擎中支持这些技术对交付高质量大模型方案非常关键。
添加图片注释,不超过 140 字(可选)
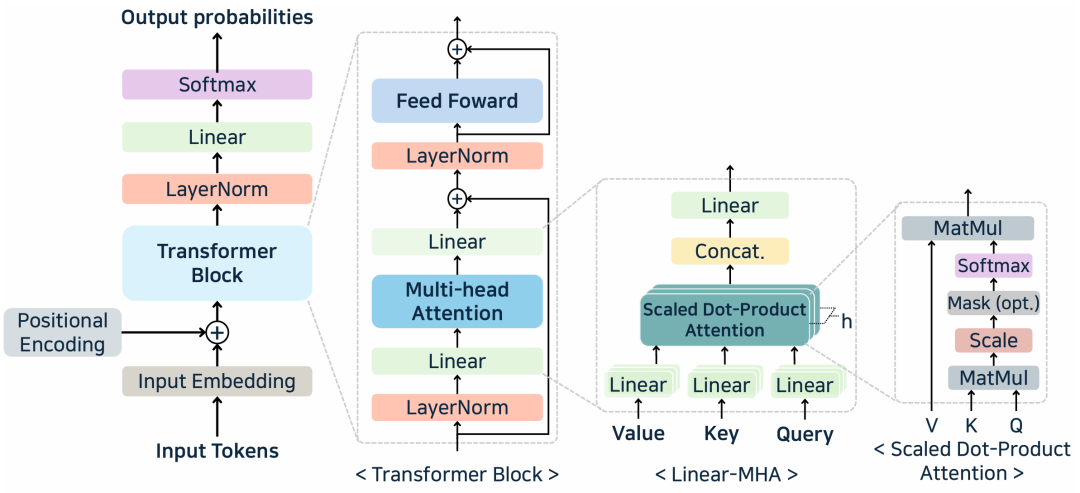
Transformer Decoder
添加图片注释,不超过 140 字(可选)
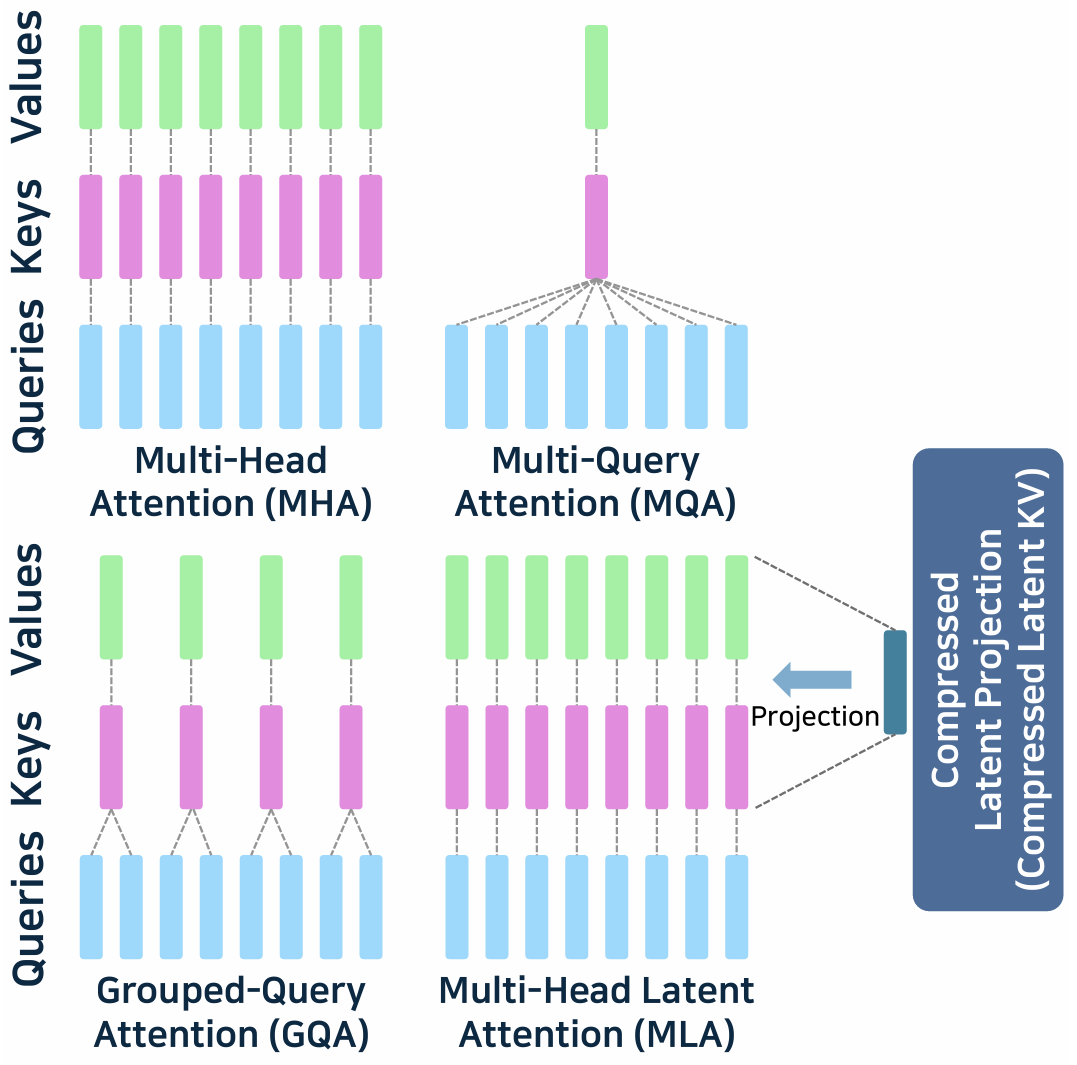
注意力机制模块
添加图片注释,不超过 140 字(可选)
大模型推理流程
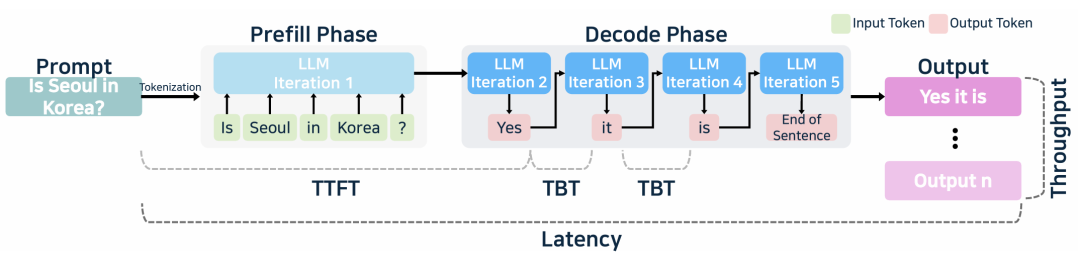
添加图片注释,不超过 140 字(可选)
大模型推理和服务流程
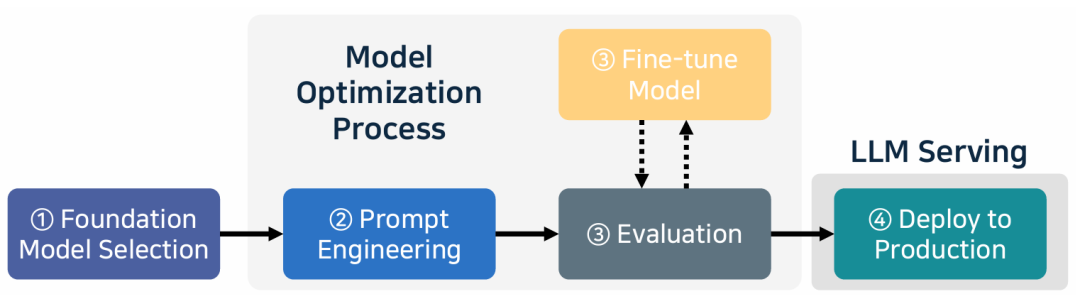
添加图片注释,不超过 140 字(可选)
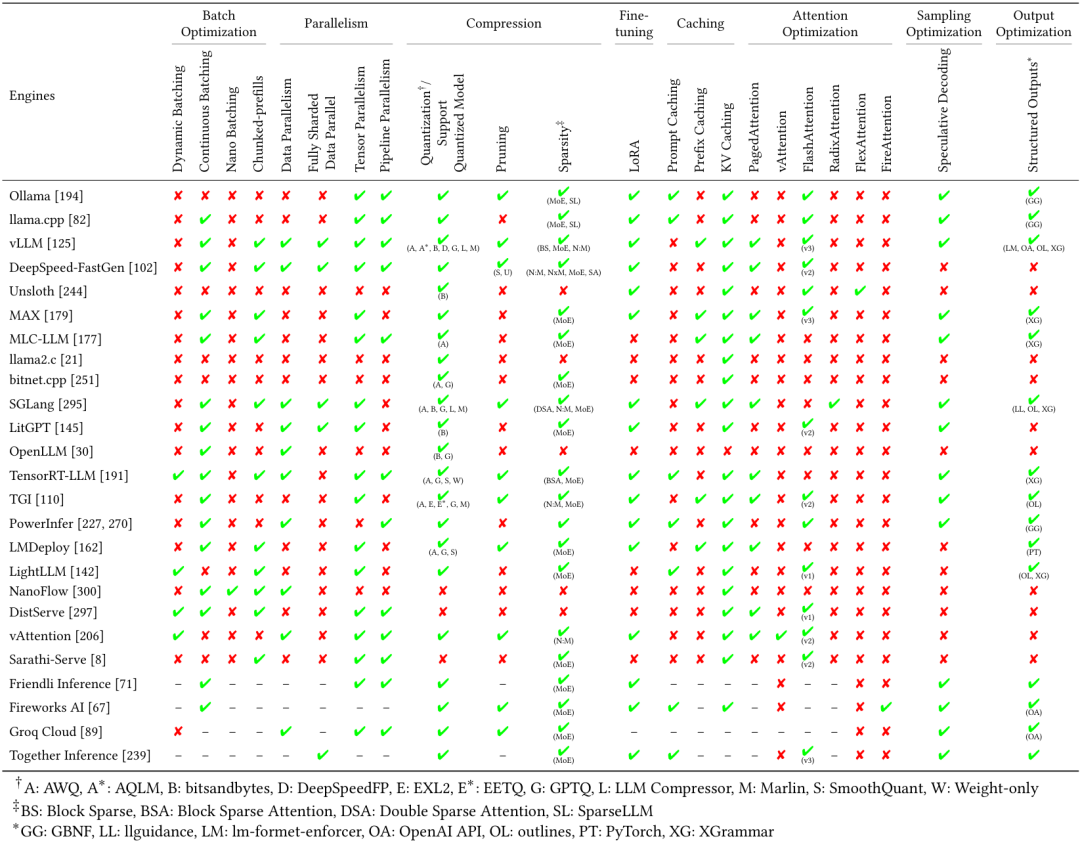
大模型推理引擎对比
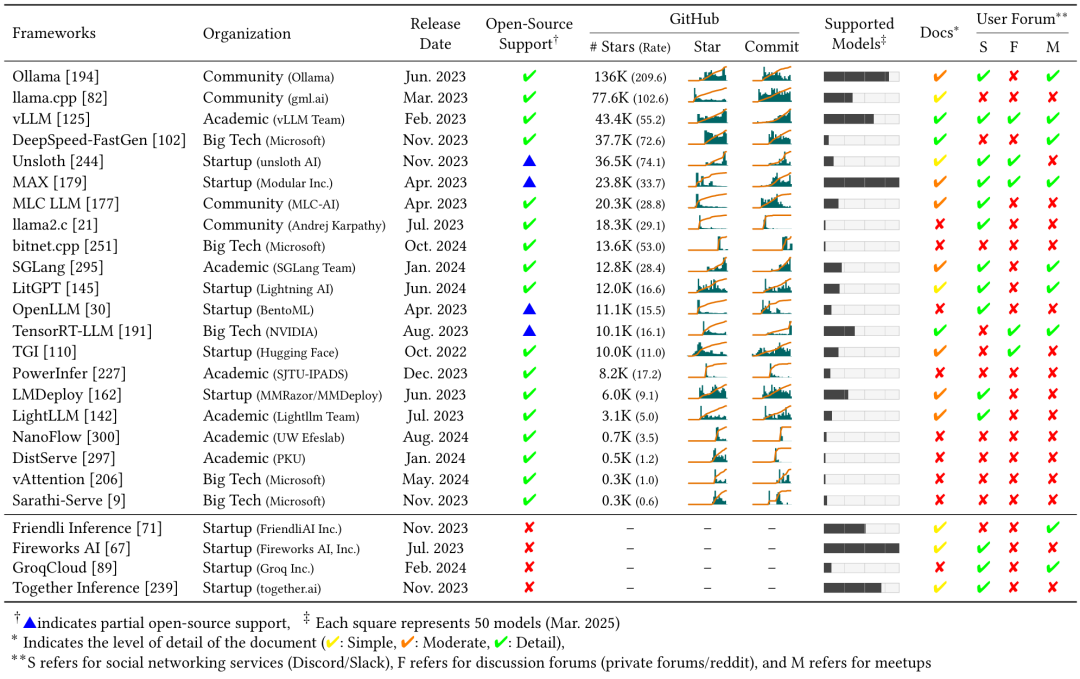
添加图片注释,不超过 140 字(可选)
大模型推理引擎后端硬件支持
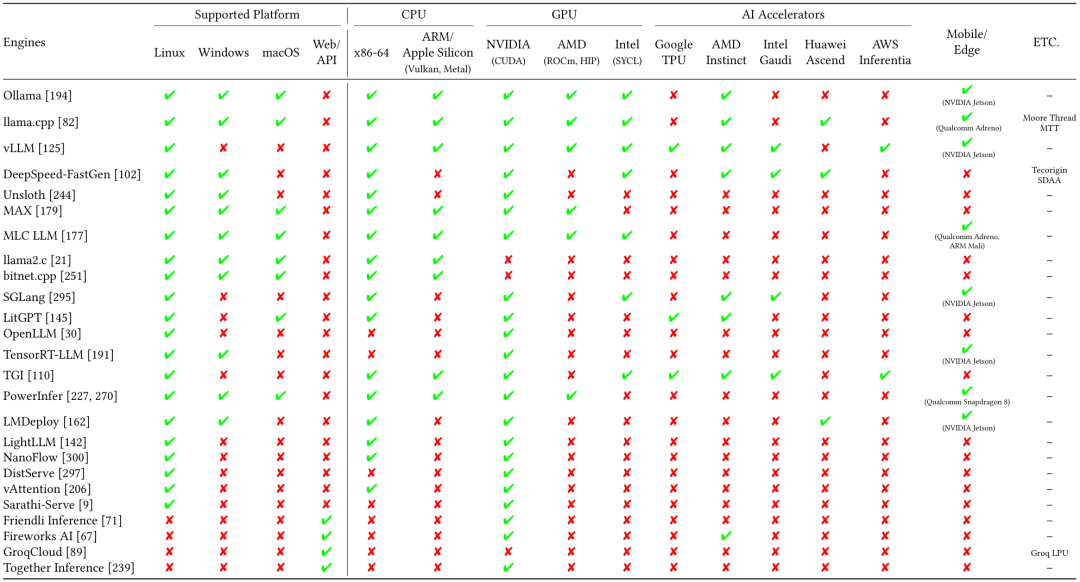
添加图片注释,不超过 140 字(可选)
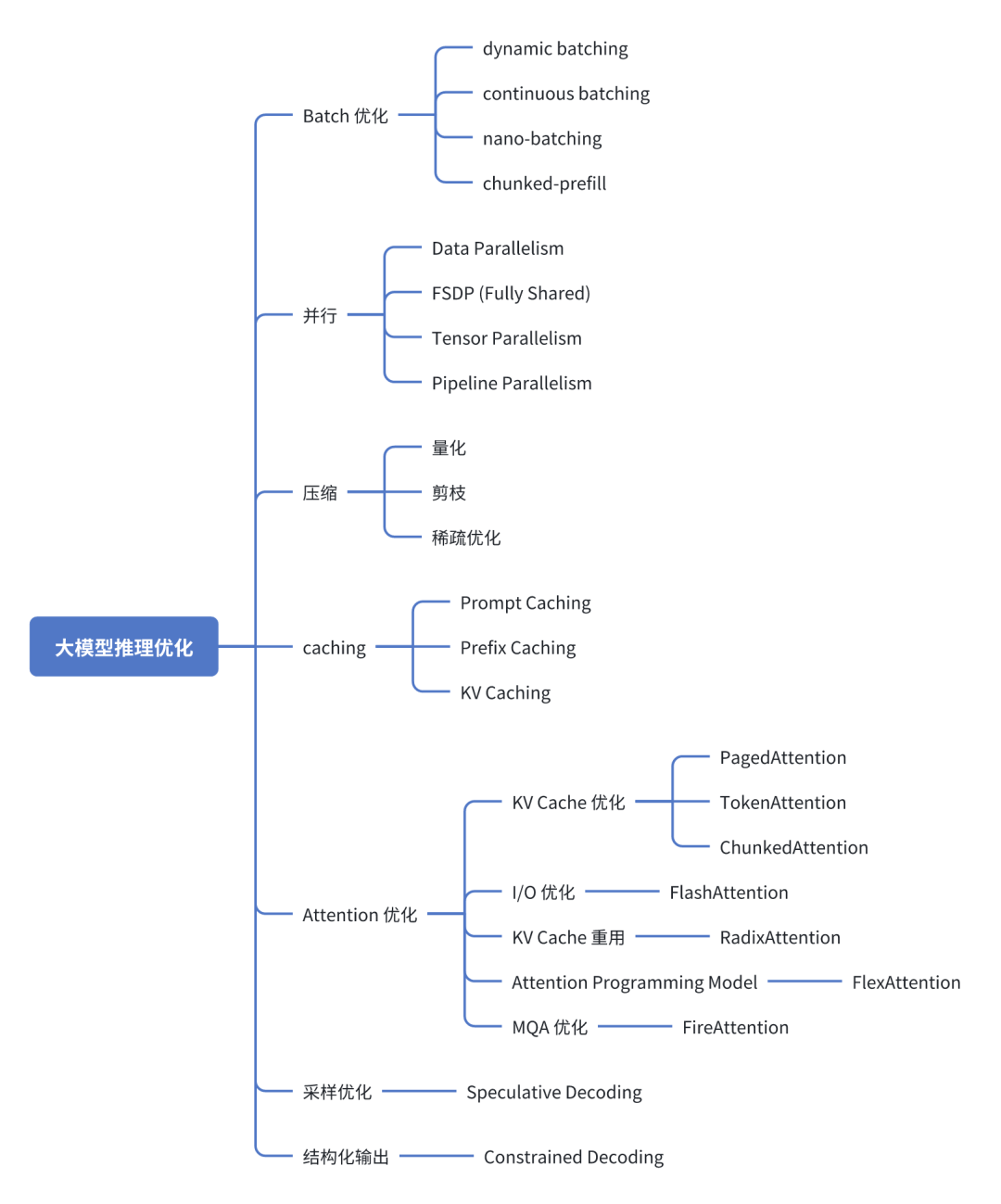
大模型推理引擎使用的优化方法
添加图片注释,不超过 140 字(可选)
1Batching 优化
推理请求把多个输入请求分组打包同时处理,提升硬件利用率和吞吐率。除了批大小外,调度方法也会显著影响推理性能。static batching 处理固定数量的请求,新请求需要等待当前批请求完成后,才能开始推理,增加了推理时延。dynamic batching, continuous batching 实时自适应批请求,可以减少推理时延、提升效率。

添加图片注释,不超过 140 字(可选)
Dynamic Batching, 在新请求进来的时候,和现有批进行合并或添加到正在处理的进程中,优化资源利用率。实现动态批处理需要优化几个参数,最大等待时间、最小批大小、最大批大小。可能会由于动态改变批大小而引入开销,请求的提示词如果变动很大,或输出 token 长度变动很大,性能会下降。
Continuous Batching 与 Dynamic Batching 相似,但新请求加入的时候不会中断正在处理的批样本,减少了推理时延。请求会连续地插入,最大化GPU和显存利用率。Continuous Batching 要求复杂的调度机制,新请求加入时不中断现有处理流程。高效的 KV Cache 管理也非常关键,经常和 PagedAttention 一起使用。推理引擎 llama.cpp, DeepSpeed-FastGen, vLLM 都使用了 Continuous Batching, 该方案来源于 Orca。
添加图片注释,不超过 140 字(可选)
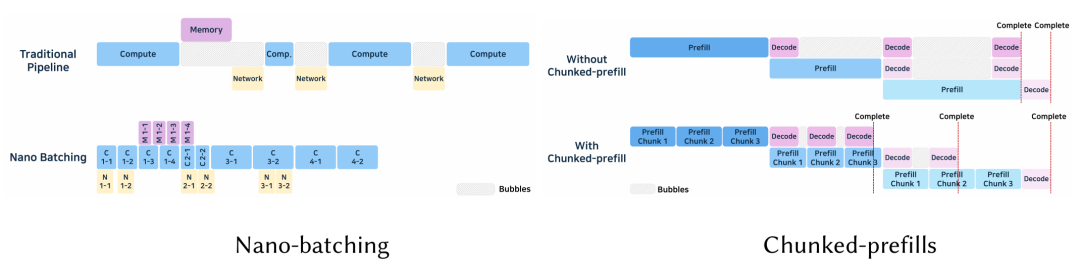
Nano-Batching 由 NanoFlow 引入, 对算子级别切分,单卡上并行 计算、访存、网络通信操作, 最大化利用资源和提高吞吐率。算子粒度分为 attention、KV 生成、GEMM、多卡同步集合通信。动态调整 nano-batch 大小,优化每类资源,调度算法基于硬件资源和算子优化,合并了拓扑排序和贪婪搜索。nano-batching 并发处理可以提升资源利用率,增加了吞吐率,但调度复杂,会导致额外的开销,尤其是多卡处理的时候。
Chunked-prefill 在多卡环境中,内存约束的解码过程存在idle 状态,处理长提示词的时候,可能会增加时延,延误了较短的提示词请求。Chunked-Prefill 把长提示词拆分成多个片段,增量式处理。第一个片段开始解码的同时,后续的片段也可以进行预填充,两个截断可以并发计算,增强了资源利用率。Chunked-Prefill 也引入了调度的复杂度,需要进行更细粒度的批管理。KV Cache 的使用会激增,尤其是在预填充和解码同时计算的时候。比如,DeepSpeed-FastGen 切分提示词生成 tokens, 调度算法就会立即获取新请求,消除了等待时间。
2并行优化
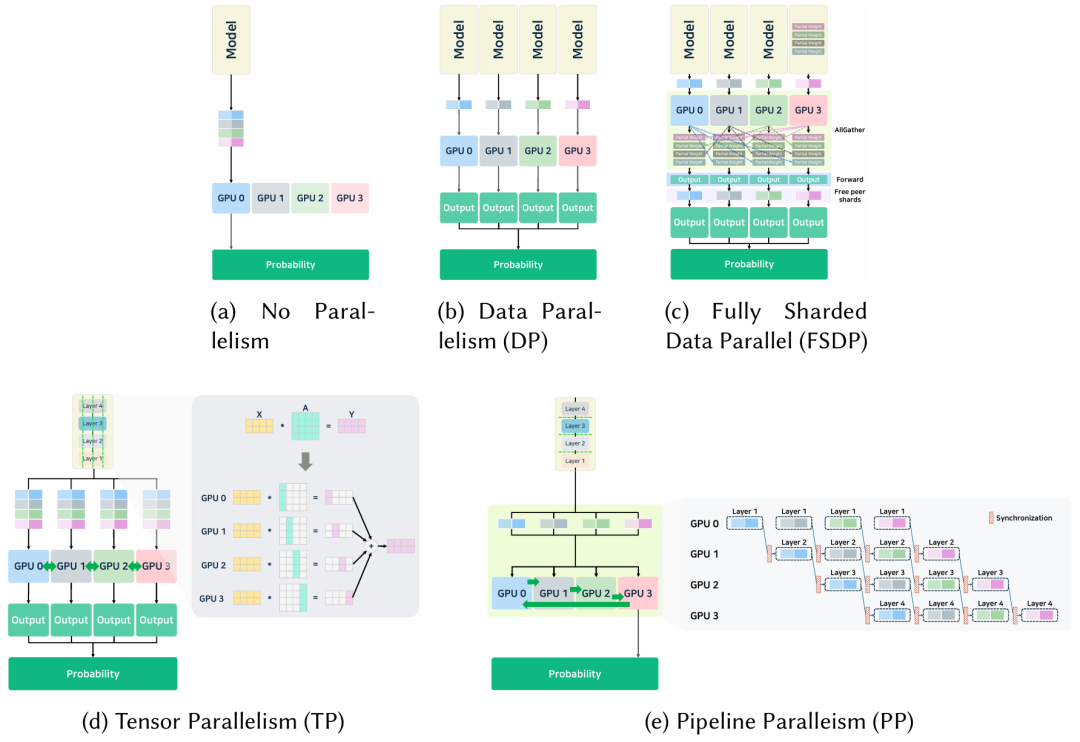
大模型过大,单卡上可能放不下。多卡多节点分布式并行处理,可以减少时延、增加利用率。并行算法受可用卡数量、互联带宽、访存层级、算力影响。主要方法有 张量并行 TP、数据并行 DP、FSDP、流水线并行。当然也可以采用混合并行。
添加图片注释,不超过 140 字(可选)
数据并行 DP在多卡或多节点上复制相同的模型,每个独立使用单独的数据推理。计算完成后,结果或权重搜集到一张卡上产生最后的结果。但如果使用的硬件性能有明显差异,整个系统性能就可能成为瓶颈。
FSDP在多卡上切分模型权重、梯度、优化器。删除了重复的内存占用。在某一网络层执行之前,汇聚该层所有参数。使用时才临时加载这层所有参数,用完之后就删除。它不是切分算子,所以执行简单,与模型兼容。每次计算之前都会进行 all-gather 操作,引入了通信开销。推理时性能下降。另外,如果某个网络层要求的内存特别大,大到单卡放不下的时候,运行就有困难。训练的时候,FSDP切分了激活和权重,节省了内存。但推理的时候,没有梯度和激活的重计算,内存节省有限。那推理的时候i就取决于模型的大小。vLLM, DeepSpeed-FastGen, SGLang 是支持FSDP的。
张量并行,也就是模型并行或模型切分,主要是多卡切分 矩阵乘、Attention、全连接(矩阵乘)。每卡切到1个片段,后续合并中间结果。图示中把模型切到4卡上。比如矩阵乘 X*A=Y。A矩阵切分到多卡上,按行或列切分,集合通信算子汇聚结算结果,All-Reduce 或 All-Gather。每卡不需要保存所有权重,但有通信开销,切得不好也会降低效率。为了处理张量并行的通信瓶颈,尤其是TTFT时的性能下降,提出了新方法压缩通信数据,减少开销,提升推理性能。
流水线并行,把大模型不同网络层分配给不同卡。输入数据切分成 micro-batch , 遍历 网络层流水线。每卡一层。
3压缩
量化: 主要是节省内存、增加推理速度。推理引擎需要选择合适的计算核,运行量化模型。KV Cache 量化 在长上下文中减少内存使用。
添加图片注释,不超过 140 字(可选)
大模型推理引擎支持的数据类型
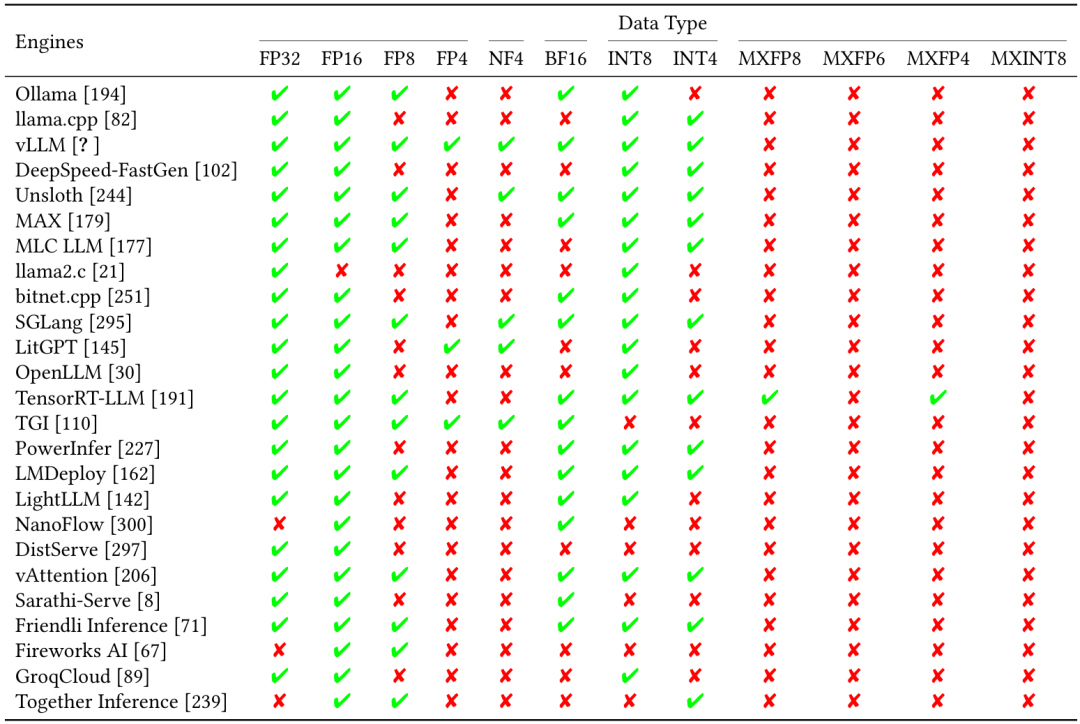
添加图片注释,不超过 140 字(可选)
4Caching
Prompt Caching : 大模型的提示词通常包含复用文本,比如系统信息、通用指令,在对话系统,编程助手、文档处理中多次出现。优化这种同样内容的技术就是 Prompt Caching, 存储了常用文本的 attention states 片段,只计算新的片段,因此可以加速推理。但由于位置编码的存在,每次片段需要出现在相同的位置上。PML(Prompt Markup Language)定义了提示词的结构,识别出可以重用的片段,分配唯一的位置 ID 。PML使用模块级位置和层级。改善 Prompt Caching 准确率的一个方法是 embedding 相似度。使用 余弦相似度计算 prompt embeddings, 这需要训练一个模型来对比这个相似度。
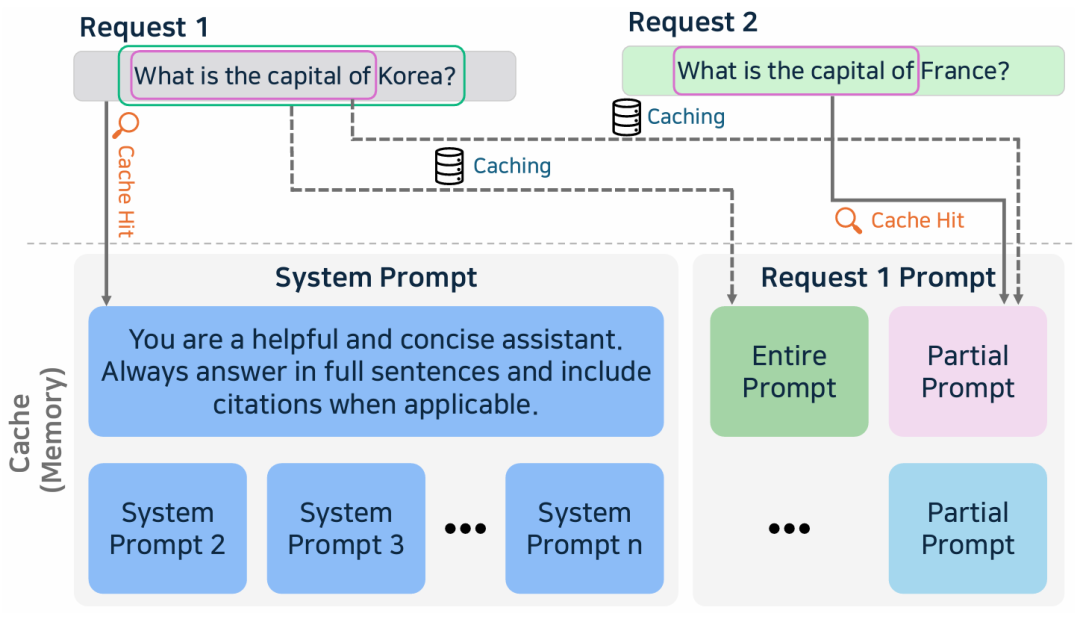
添加图片注释,不超过 140 字(可选)
Prefix Caching 与 Prompt Caching 有点相似,但主要关注的是缓存多个请求间相同的 prefix 片段, 不是整个提示词。
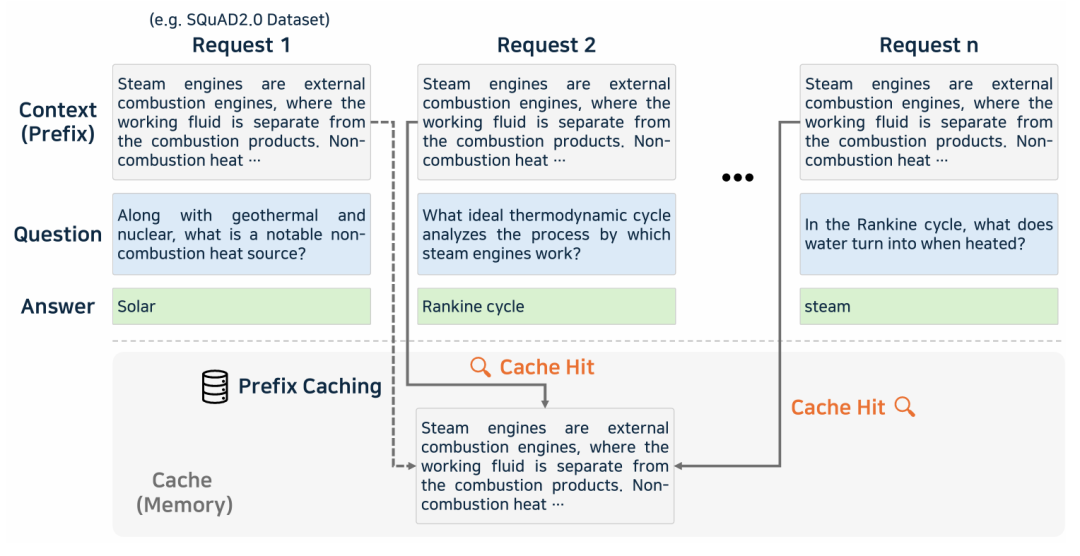
添加图片注释,不超过 140 字(可选)
KV Caching
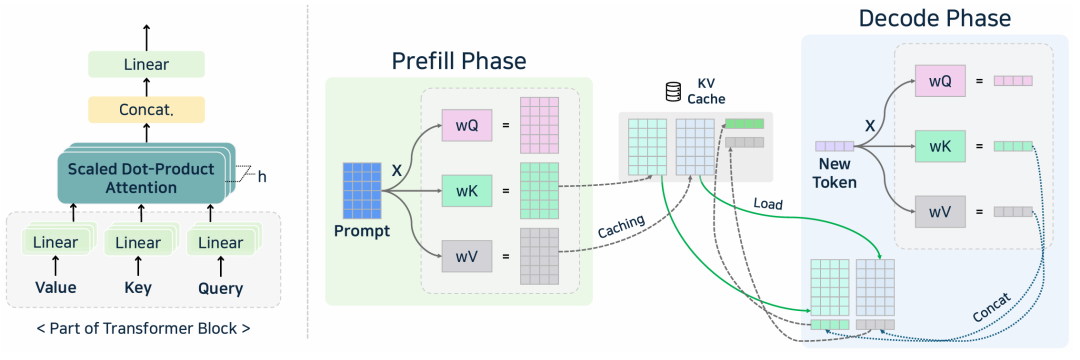
添加图片注释,不超过 140 字(可选)
5Attention 优化
PagedAttention: 把 KV cache 切分成页表机制中的小片段,把逻辑块映射成物理块。
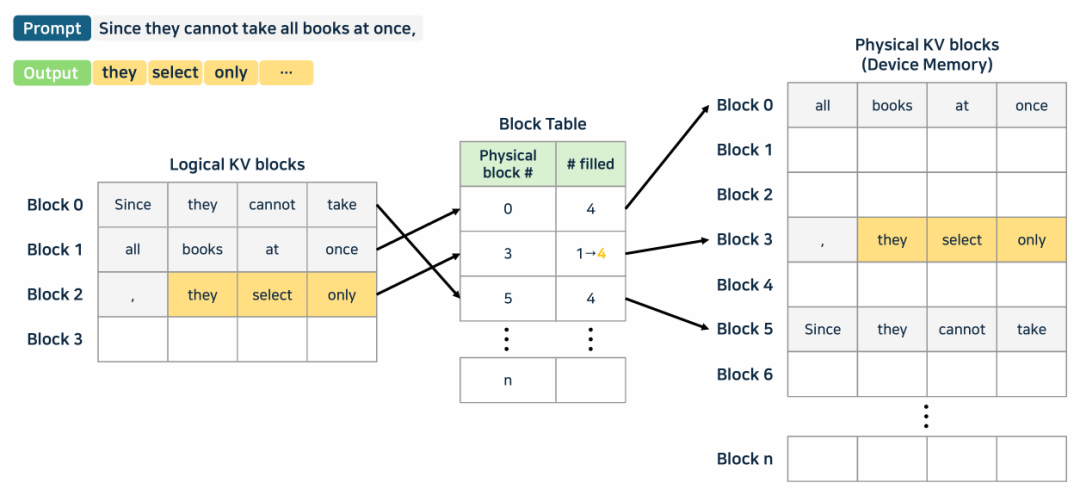
添加图片注释,不超过 140 字(可选)
TokenAttention: 管理 token级别的 KV cache,使用 token 表格管理每个 token 的存储位置。
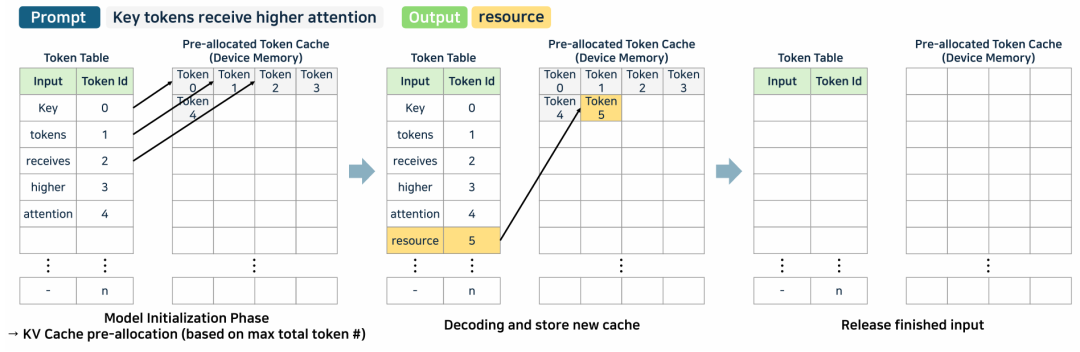
添加图片注释,不超过 140 字(可选)
FlashAttenion: 把 Q, K, V切分成更小的 blocks。按 tile 计算 online softmax, 避免重复写内存。把矩阵乘和softmax 融合成一把计算,减少了计算核反复激活的开销。
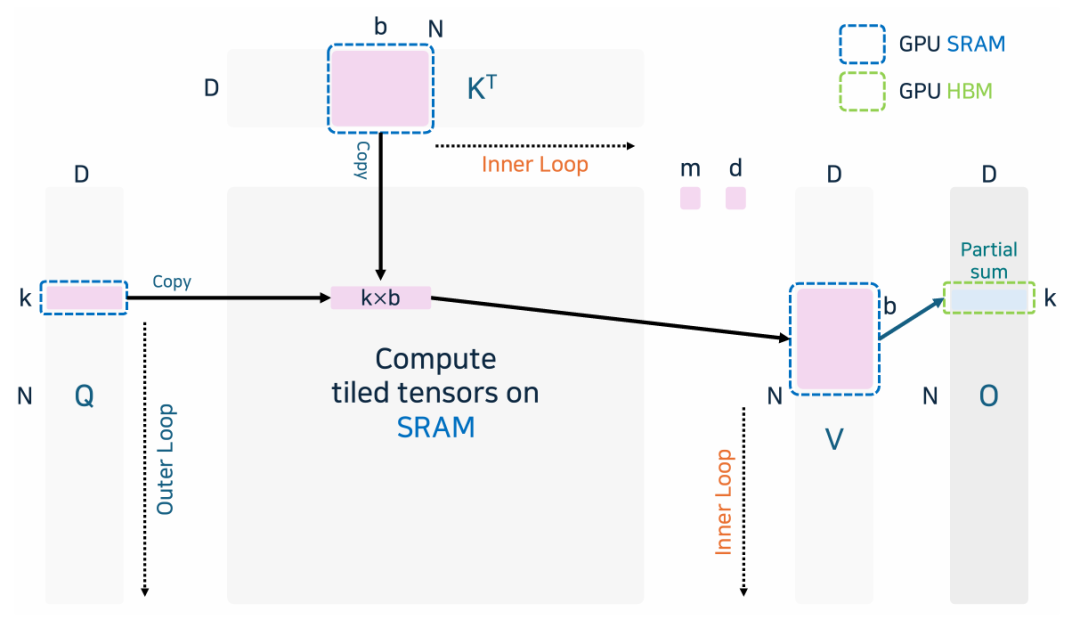
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
6采样优化
推测解码
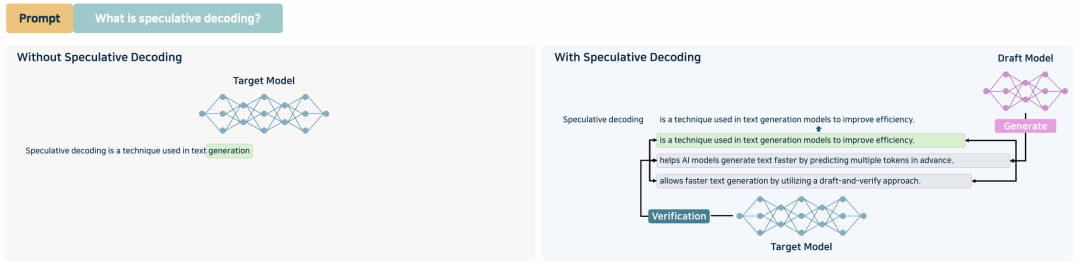
添加图片注释,不超过 140 字(可选)
7结构化输出
非结构化输出和结构化输出
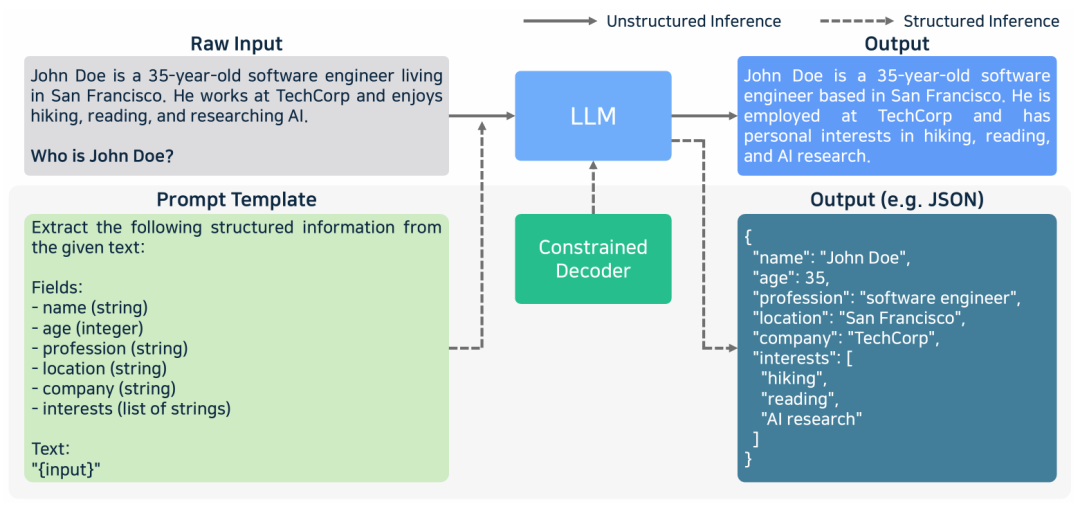
添加图片注释,不超过 140 字(可选)
解码阶段的约束解码
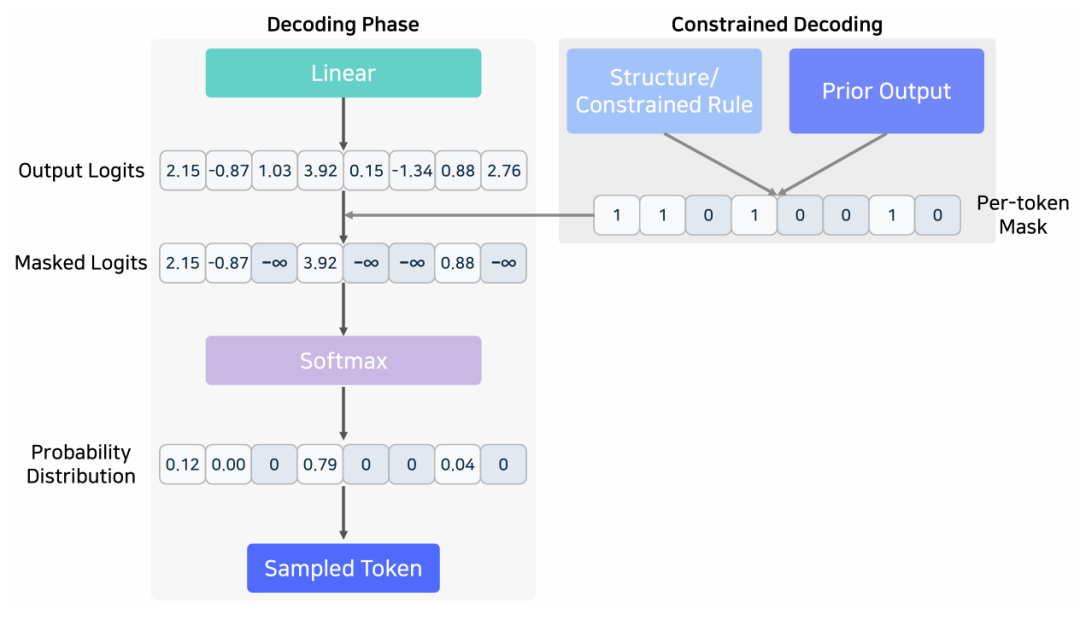
添加图片注释,不超过 140 字(可选)
详细内容参考原文:
https://arxiv.org/pdf/2505.01658v1
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号