
DeepSeek对AI架构硬件杂谈
DeepSeek的论文《Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures》
总体来说挺及时的一篇文章, 关于ScaleOut和ScaleUP融合的观点以及内存语义的分析基本上和我的观点是完全一致的, 而同时工业界还在各种乱搞吵架中, 从一个业务方视角的一篇论文有助于整个工业界收敛...
其实这篇文章很大的一个价值是从模型层到算子再到通信最后到芯片全栈拉通的分析, 而很多大厂各种部门墙导致中间各种信息丢失, 算法/Infra和基础设施是完全割裂的, 因此各种KPI局部最优导致的工程上的shi上雕花...例如隔壁友商《谈谈以太网GPU Scale-UP的工作EthLink》既要复刻BRCM的ScaleUP支持LD/ST,又要在上面画蛇添足搞RDMA....然后关于Memory Model的问题一字不谈..这篇文章对于隔壁友商技术扶贫有很高的参考价值.
1. DeepSeek模型设计原则
原文第二章阐述了一些模型的设计原则, 原文主要分三块: 内存效率/MoE/推理速度, 其实本质问题就是模型结构上的Attn/MLP稀疏化的问题, 在内存容量/带宽/算力/网络通信几者间的平衡.
注: 其实我觉得这篇论文可能有一些部分还可以继续展开一下, 例如hidden_dim的选择, 模型层数的约束, MoE 专家数配比等, 专家的MLP的大小, 计算和通信本身的Overlap的时序约束, 这些也是在设计模型架构的时候就可以充分考虑的. 例如为什么Hidden-dim要选那个值, 然后恰好MLA的计算时间和Combine的通信时间可以很好的Overlap一类的话题.
我尝试着去理解他们的设计原则, 于是做了一些ShallowSim的东西去通过仿真探索模型的设计参数空间.
1.1 内存效率
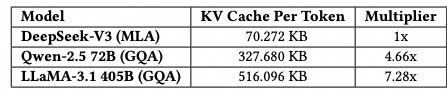
采用低精度模型, MLA降低KV Cache, 然后还提及了MQA/GQA这些共享KV的做法, window based KV的做法, 以及一些量化压缩的方法. 然后还有一些本来transformer attn 复杂读的问题需要处理, 例如Mamba/Lightning attn这些平衡计算成本并提供线性时间的替代方案. 然后也引用了自家的NSA的论文, 做一些稀疏性的激活方法.
添加图片注释,不超过 140 字(可选)
1.2 MoE
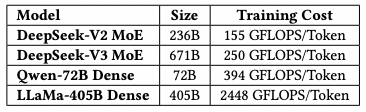
从减少训练的激活以及个人部署/本地私有化部署谈了一下MoE的优势.
添加图片注释,不超过 140 字(可选)
1.3 提高推理速度
一方面是microbatch做一些overlap提高吞吐, 另一方面简单估计了一下MoE模型的推理性能上界. 谈到了大带宽的互联(NVL72)在EP时的通信延迟会下降很多. 理论上带宽打满可以做到1200 tokens/s的性能.
注: 实际上这种算法只考虑了动态的传输延迟, 没有考虑一些静态延迟的影响, 并且是perfect overlap的情况基于网络带宽bound的一个测试值, 而实际用ShallowSim仿真过, 即便是NVL72 只会在一些较短的seq下有收益, TPS最多估计也就到200左右...
然后另一方面谈了一下MTP. 然后还结合了现在Reasoning Modle和Test-Time Scaling谈了一下需要快速的推理用于生成大量的样本用于RL训练.
1.4 验证方法
原文2.4章节(Technique Validation Methodology), 可以看到DeepSeek团队应该是在成立之初就有过这样的分析. MLA省KVCache, FP8混合精度训练, MoE在几代模型之间逐渐调整成型, 最后一代一代的积累成了DeepSeek-V3.
2. 低精度设计
关于低精度训练, 一方面是DeepSeekV3论文中所讲的一些FP8混合精度相关的内容, 然后提了两个建议, 一个是Accumulation的精度提升到FP32, 另一方面是原生支持一些细粒度的量化.
另一个话题是LogFMT-nBits的通信压缩, 按照一个Tile进行压缩和解压缩, 计算方法如下, 例如一个向量, 求最大最小值min/max, 然后最小值编码为S.000...01,最大值为S.11...11, Step=.
在LogFMT-8Bit时表现出更好的精度, 而LogFMT-10Bit和BF16 Combine的精度类似. 但是LogFMT在通用GPU上存在编解码时期的算力开销和寄存器压力过大的问题. 因此建议在通信阶段进行压缩和解压缩的操作...特别是在MoE训练时...
其实对于通信上的量化压缩, 2年前在内网就有一些分析
添加图片注释,不超过 140 字(可选)
对于LogFMT我持有一定的怀疑态度, 从算法团队的角度来看, LogFMT-10Bits相对于BF16节省了接近40%的带宽, 但是从芯片实现来看, 压缩和解压缩增加的延迟和DieSize的占用以及功耗的开销平衡来看, 可能会有些得不偿失, 其实还有一些更简单粗暴的办法...(涉密打哑谜了....
3. 互联驱动的设计
3.1 当前硬件架构
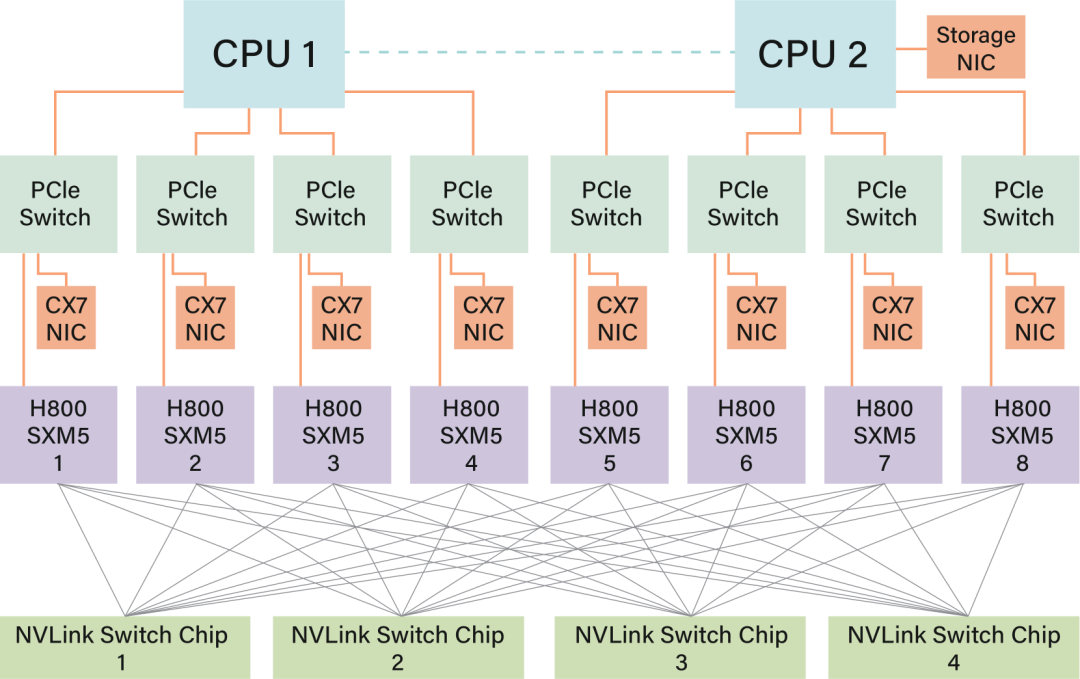
描述了一下当前8卡Hopper的架构, 介绍了一下ScaleUP和ScaleOut网络的一些背景.
添加图片注释,不超过 140 字(可选)
3.2 硬件感知的并行
DeepSeek针对H800被阉割了NVLink做了一些处理 , 训练时避免了TP并行挤兑NVLink的带宽, 支持了DualPipe的PP并行, 并将MoE的计算和通信很好的Overlap. 然后alltoall支持了DeepEP这样的优化.
3.3 模型协同设计
基于硬件上ScaleUP和ScaleOut带宽比4:1设计了专门的Group-Gating, 以及针对性的处理了EP并行和负载均衡, 以前专门详细写了一篇文章解释
4. ScaleUp和ScaleOut融合
大概讲了一下当前两套网络的限制, 需要占用大量的SM资源进行通信处理. 例如在两个网络之间搬移数据, 然后RDMA网络中的QP和WQE这些处理, Completion的处理, 数据分块的内存管理, Reduce操作, 数据类型转换等. 然后有一个建议, 需要ScaleUP和ScaleOut统一的框架, 并且有专用的协处理器来处理网络流量.
然后谈了一下UEC/UAL都有望推动ScaleUP和ScaleOut的发展, 并且谈到了华为的UB提供了一种新的ScaleUP和ScaleOut融合机制. 然后提出了几个建议:
首先是Unified Network Adapter, 能够连接到统一的ScaleUP和ScaleOut的NIC或者I/O芯片, 支持基本的交换功能, 同时还支持策略路由. 然后需要专用的通信协处理器来处理网络流量. 并且能够支持灵活的转发/广播和Reduce能力. 最后需要支持一些细粒度的硬件同步源语. 例如基于acquire/release机制的内存语义通信, 避免RDMA这些软件机制带来的复杂度..
5. 带宽争抢和延迟
本质上是在说现在的主机内总线没有很好的QoS机制, KVCache传输会导致GPU同时进行EP并行时的Dispatch/Combine出现干扰. 然后有几个建议:NVLink和PCIe需要有优先级的控制, 然后需要将NIC作为I/O Die chiplet和GPU集成. 并且GPU和CPU要集成到同一个ScaleUP Domain中.
其实这么多需求要整合到一起, 实现到一颗硬件的I/O Die里还是很有挑战的, 我不确定DeepSeek是否自己脑补过硬件实现... 其实只要稍微变一点魔术, 就可以变得相对容易一些了...
你会发现DeepSeek的这些需求和建议加在一起不就是2021年我们就实现过的NetDAM么?
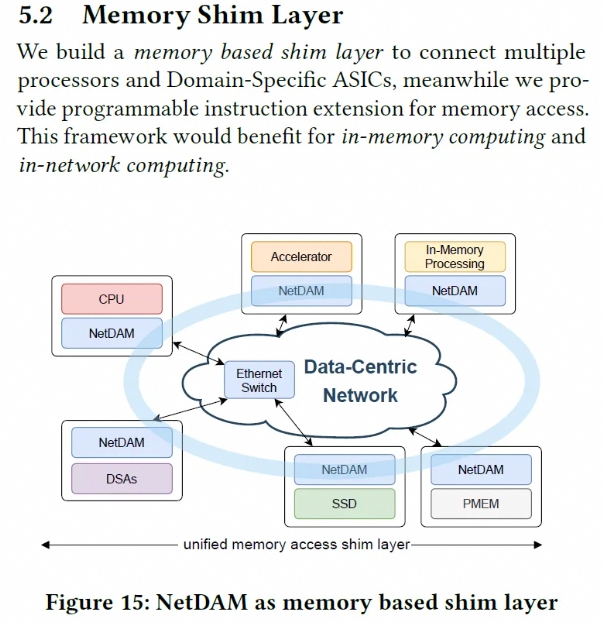
添加图片注释,不超过 140 字(可选)
NetDAM设计之初就是要同时连接ScaleUP和ScaleOut网络, 并且提供CHI这些总线作为Chiplet连接的选择, 对外统一实现了基于Ethernet的互联, 然后内置了一些可编程逻辑可以用来处理网络流量
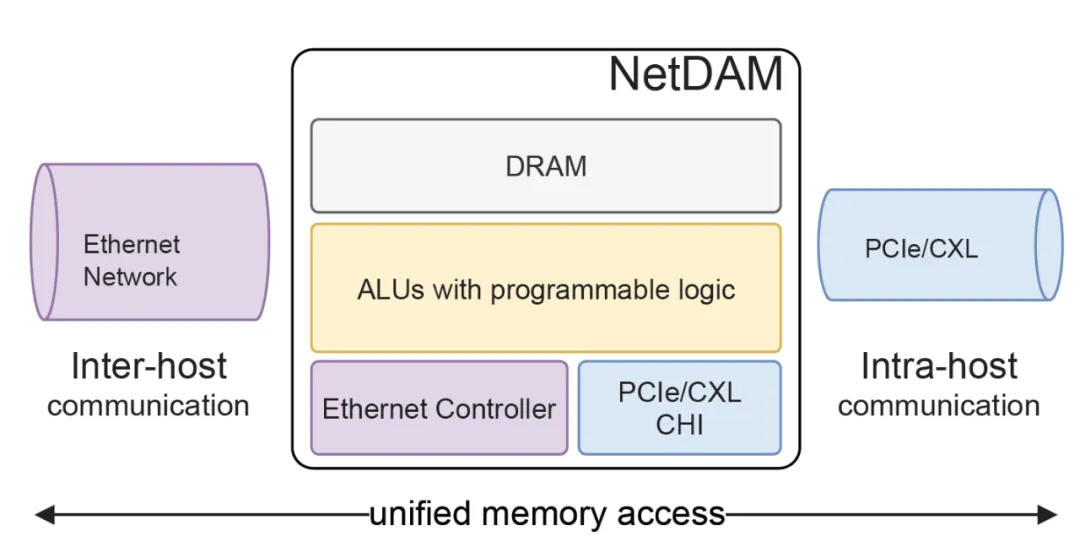
添加图片注释,不超过 140 字(可选)
同时当年就考虑过CPU和GPU在同一个ScaleUP domain, bypass一些PCIe的限制等.. 并且当年就完全实现过Bcast/reduce的处理..
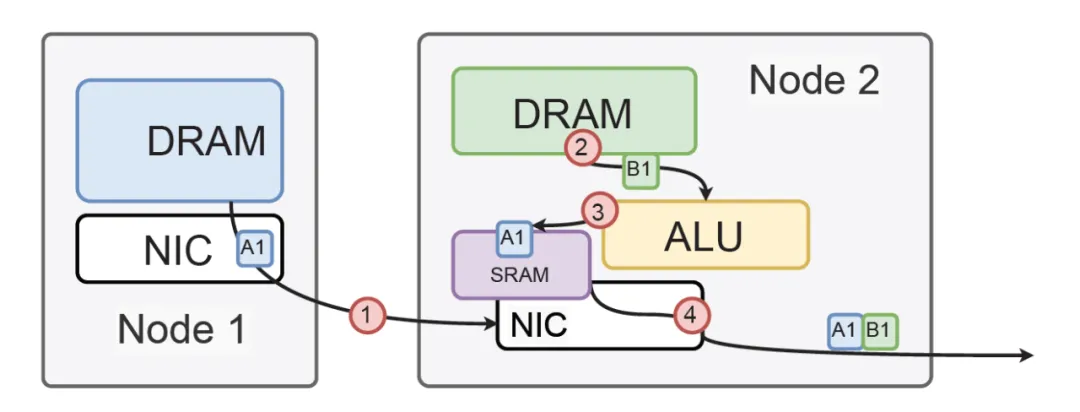
添加图片注释,不超过 140 字(可选)
至于细粒度的硬件同步源语, 这是一个哑谜...我会给你说Nvidia现在GPU是怎么做的, 我怎么做的确实涉密要等到产品发布的那一天才能说出来...
如果要说真心话, 告诉你RDMA那玩意根本就不适合在ScaleUP待着, 甚至连ScaleOut用IBGDA也是一个痛苦的事情....真不明白隔壁友商为啥都有了博通Eth ScaleUP套壳了, 还要在上面再套一个RDMA...大无语....
6. 大规模网络设计
6.1 多平面拓扑
DeepSeek-V3的ScaleOut设计容量是16384个GPU, 使用了64端口的IB交换机并采用2层FatTree构建, 但实际上最终只部署了2000多卡, 采用了多平面部署, 并且机头CPU那张卡有一个独立的存储网络
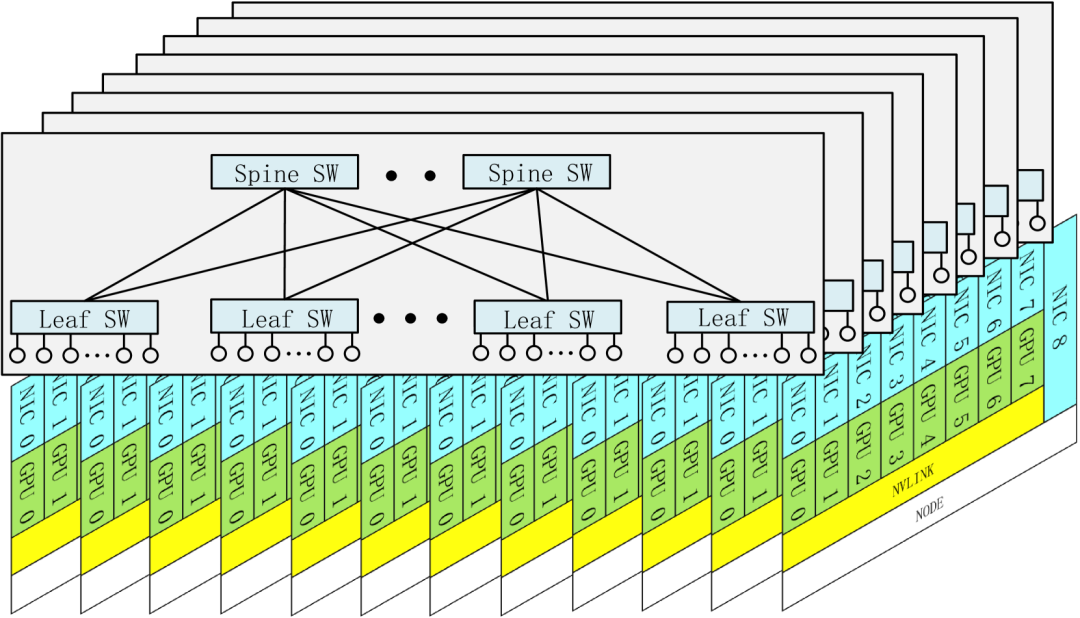
添加图片注释,不超过 140 字(可选)
然后跨平面的流量必须要使用PCIe转发到另一个NIC或者类似于PXN那样节点内转发. 其实我有一个疑问,这样的每个GPU rank独立的平面, 在集群中的Decoding EP时, LowLatency Kernel 跨平面转发是如何做的?
然后DeepSeek的同学描述了一下一个理想的架构
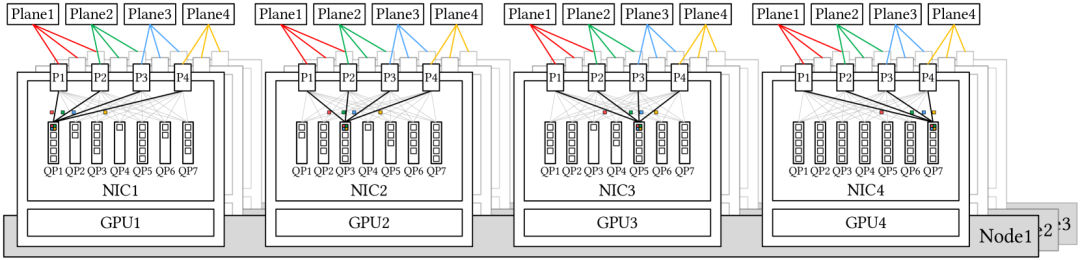
添加图片注释,不超过 140 字(可选)
悄悄的说, 这个图受到了Nvidia CX8的一些误导, 简单的说一下吧, 当前的NV网卡很蠢, 即便有双网口的版本, 单个QP只能选择一个端口转发, 要在网卡侧做packet spray 才行, 而逻辑上要对GPU呈现出一个单独的设备, 于是NV有搞了一些VF over PF Bond的东西出来, 总之非常脏的一些解决办法, AR开启后, 接收端的ReOrder处理也比较弱, 都没解决干净...
当然这不妨碍DeepSeek的同学提出了MPFT(多平面FatTree)的优势:
一个是Nvidia提出的多轨道和PXN的通信方式. 另一个是相对的成本优势, 再就是每个平面独立的通信, 然后相对于3层网络更低的延迟, 最后多平面提供了更高的稳定性.
其实这种观点是相对片面的, 首先稳定性的问题来看, 多平面势必要在第一跳接入的地方用光, 相对于铜缆的MTBF, 光模块和光纤的稳定性要差很多, 因此引入了Robust的需求, 同时又进一步引入了单网卡多平面的需求, 因为CX7断掉一个口就流量减半... 另外就是拥塞控制和多路径转发自己没做好而引入的一系列问题, 需要Traffic Isolation啥的...
其实当你第一跳用了铜, 然后端侧有一个恰当的算法去解决网络拥塞的问题和多路径转发问题, 至于延迟本身,FT2和FT3的问题, 加一跳根本就没啥影响..实际上的问题是在内存同步语义之上如何避免一个RTT的问题.. 点到为止...
然后来谈成本, MPFT vs FT3, 其实这里讨论少了一种可能性, 即带有一定收敛比的FT3的网络, 可惜NV的网卡和当今工业界的拥塞控制算法还做不到...
6.2 低延迟网络
谈论了大规模EP下AlltoAll的Dispatch/Combine所需要的延迟, 在400Gbps网络下,理想情况下需要120us. 然后结论是微秒级的静态延迟会严重影响性能. 然后有一些讨论: IB更贵, 延迟更低, 但是RoCE交换机的Radix更大, 可以更好的用于大规模部署. 因此DeepSeek的作者们对RoCE提出了一些改进的建议:
一方面是专用的低延迟交换机, 例如BRCM的TF1这样的低延迟以太网交换机, 以及ScaleUP上定义的AIFH等... 但是说实话这些大概只能节省几百个ns, 是否真的值得去做呢?
另一方面是优化策略路由, 即需要Adaptive Routing这样的能力, 而以太网上虽然Spectrum-X也支持AR, 但是又被迫要打开PFC. 能够多路径Lossy转发并完全解决干净的实现并不多...
然后提出改进的流量隔离和拥塞控制策略, 为了解决incast提出需要VOQ的交换机, 或基于RTTCC实现交换机和网卡协同等...
其实问题的关键在什么地方? 静态延迟过一个交换机也就3us, 其实最关键的是有一个RTT的同步延迟需要处理掉. 参见后面一章.
另外DeepSeek的同学可能没有考虑到一个问题, 当前面大量协处理器相关的功能加上后, 延迟还会进一步增加, 拥塞控制还会引入一些队列延迟, 其实降低静态延迟是否真的有价值, 或者更显著的做法是想办法增加网络带宽来降低传输延迟. 点到为止...
其实本质的问题还是需要解决多路径转发的问题, 同时避免incast需要改进拥塞控制. 还要平衡考虑很多网卡微架构的事情.
还是那句话, 唯一能够在Lossy上做到多路径和拥塞控制, 并且incast做到QP间完全公平的全球就一家, 但是很抱歉不是Nvidia.
6.3 IBGDA
其实就是讲DeepEP支持IBGDA有很大的性能提升, 大家都来搞呀, 但另一方面其实和前面的ScaleUP/ScaleOut统一是矛盾的, 本质上应该有更好的一种实现方式..
7. DeepSeek对未来硬件的讨论和见解
这一章算是一个总结吧..
7.1 稳定性
首先是一些稳定性的讨论, 链路的间歇性失效, 单个硬件的故障, 数据静默错误等...
首先对于链路上的间歇性故障, 其实在多路径转发和拥塞控制算法上做一点巧妙的设计就可以很容的实现毫秒级的故障收敛.
然后单个硬件故障, 其实对于云服务提供商而言通常更倾向于采用对称的拓扑, 然后做一些异常调度的能力和快速热迁移的能力才是是关键.
对于数据静默错误, 全链路数据校验时非常有必要的, 可惜NV在这方面积累的经验还是太少了一点.. 笑而不语...
7.2 CPU互联瓶颈
本质上就是要CPU加入到ScaleUP域, 其实DeepSeek可能没讲清楚实质的问题. 本质上是数据路径上ScaleUP域内需要内存节点, 而CPU还需要在控制路径上即可...
7.3 Toward Intelligent Networks for AI
谈了一些CPO, 然后谈了一下需要端侧的CC, 需要Adaptive Routing, 需要快速的故障冗余处理, 需要动态的资源管理(本质是QoS)
抛开CPO, 当前唯一全部做到的只有eRDMA一家. 而我们甚至还可以支持per QP的QoS调度能力:)
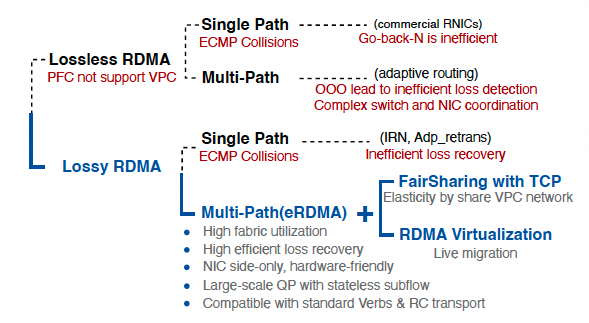
添加图片注释,不超过 140 字(可选)
7.4 关于内存语义和Ordering的问题
就给你们说,现在的实现会导致增加一个RTT的延迟... 而实际上可以很容易的实现一个处理. 作者提供了一种Region Acquire/Release的机制... 其实不一定完全要这样, 还有很多简单的方法可以处理. :)
7.5 在网计算和压缩
其实基于交换机的SHARP或者BRCM的INCA都解决不了一个问题, Combine的时候挺难的.. 作者也没提供答案, 但是其实我们已经有解法了, 继续打个哑谜让大家猜...
7.6 内存为中心的创新
谈了一下3D DRAM Stack和System on Wafer这些东西...
8. 锐评?
总体来看, 由DeepSeek这样的业务方说出这些话来, 比我说管用, 否则我提了很多年的ScaleUP和ScaleOut在以太网上融合, 多路径拥塞控制, 以太网ScaleUP这些事情别人都以为我是基于屁股/利益出发的... 实际上这些都是从业务来的... 至少有一个业务方认同这样的技术路线了.
说实话, DeepSeek这篇文章从模型设计到基础设施中遇到的问题, 分析的还是蛮清楚了, 提出的每个需求都非常中肯, 但是要把这些需求整合起来实现到一块芯片, 无论你称它为NIC或者是I/O Die, 工程上还有大量的问题需要处理, 在我有限的认知内, 无论是BRCM和NV现在的能力是完全无法Handle这些问题的, 特别是NV还要内部ScaleUP和ScaleOut的团队PK一下... 可能能把这个问题完全解决好的, 华子算一个 , 我们算一个 :)
然后关于拓扑的讨论上, 单一租户的环境(AI工厂/IDC)和云环境有很大的不同, 单一租户可能就是同学之间打个招呼就可以把Job停一下重新换个节点再起来, 实现故障时的一些资源调度能力. 而在云环境中, 相对于传统的IDC模式, 对于稳定性的要求和用户无感知的资源调度和热迁移资源整理的需求会更高, 有些时候必要的对称拓扑虽然对成本带来了一定的影响, 但是可以极大的提高资源的弹性和售卖能力, 这是非云的同学可能不了解的业务知识点.
参考资料
[1]
Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures: https://arxiv.org/html/2505.09343v1
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号