作业四
作业一
要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
o 候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
o 输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码:bStockNo……,由同学们自行定义设计表头
部分关键代码
def insert_stock_data(cursor, stock_data):
cursor.execute("""
INSERT INTO stocks (
股票代码, 股票名称, 最新价, 涨跌幅, 涨跌额,
成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (
stock_data['股票代码'], stock_data['股票名称'], stock_data['最新价'], stock_data['涨跌幅'],
stock_data['涨跌额'], stock_data['成交量'], stock_data['成交额'], stock_data['振幅'],
stock_data['最高'], stock_data['最低'], stock_data['今开'], stock_data['昨收']
))
这部分代码用于将爬取到的股票数据按照顺序填入表格
# 爬取所有页的数据
data = []
# 假设页面最多会翻10页,可以根据需要修改
page = 1
while True:
# 获取当前页面的所有股票数据
rows = driver.find_elements(By.XPATH, "//table[@id='table_wrapper-table']/tbody/tr")
# 如果没有数据,停止爬取
if not rows:
print("没有更多数据,停止爬取。")
break
# 遍历每一行,提取股票信息
for row in rows:
cols = row.find_elements(By.TAG_NAME, "td")
if len(cols) > 1:
stock_data = {
'股票代码': cols[1].text, # 股票代码
'股票名称': cols[2].text, # 股票名称
'最新价': float(cols[4].text.replace(",", "")) if cols[4].text else 0.0, # 最新价
'涨跌幅': float(cols[5].text.replace("%", "")) if cols[5].text else 0.0, # 涨跌幅
'涨跌额': float(cols[6].text.replace(",", "")) if cols[6].text else 0.0, # 涨跌额
'成交量': parse_volume(cols[7].text), # 使用parse_volume函数处理成交量
'成交额': parse_amount(cols[8].text), # 使用parse_amount函数处理成交额
'振幅': float(cols[9].text.replace("%", "")) if cols[9].text else 0.0, # 振幅
'最高': float(cols[10].text.replace(",", "")) if cols[10].text else 0.0, # 最高
'最低': float(cols[11].text.replace(",", "")) if cols[11].text else 0.0, # 最低
'今开': float(cols[12].text.replace(",", "")) if cols[12].text else 0.0, # 今开
'昨收': float(cols[13].text.replace(",", "")) if cols[13].text else 0.0 # 昨收
}
data.append(stock_data)
# 将数据插入到数据库
insert_stock_data(cursor, stock_data)
# 等待翻页按钮可点击
try:
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//a[@class='next']"))
)
# 点击翻页按钮,加载下一页数据
next_button = driver.find_element(By.XPATH, "//a[@class='next']")
next_button.click()
# 等待页面加载
time.sleep(3)
page += 1
if page > 10: # 假设只爬取前10页
print("爬取结束,已到达最大页数。")
break
except Exception as e:
print(f"翻页失败或超时: {e}")
break # 如果发生任何异常则停止翻页
这部分代码用于爬取网站的相关股票数据
结果展示
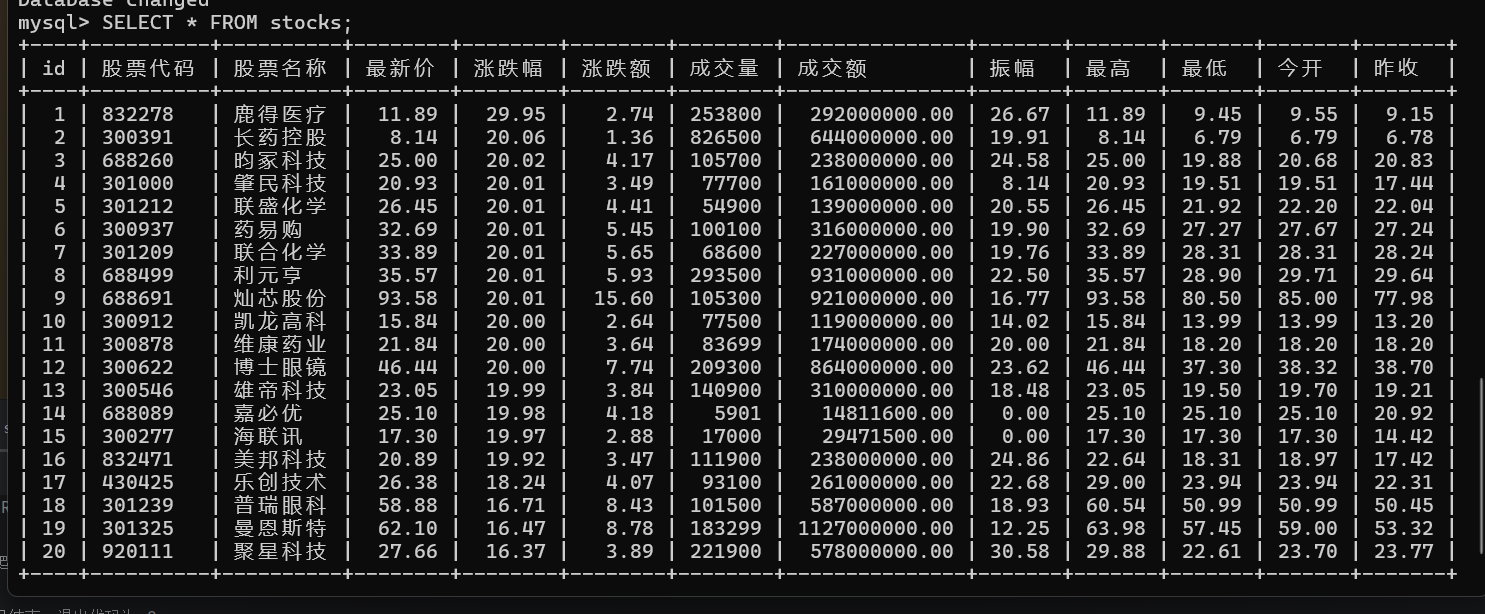
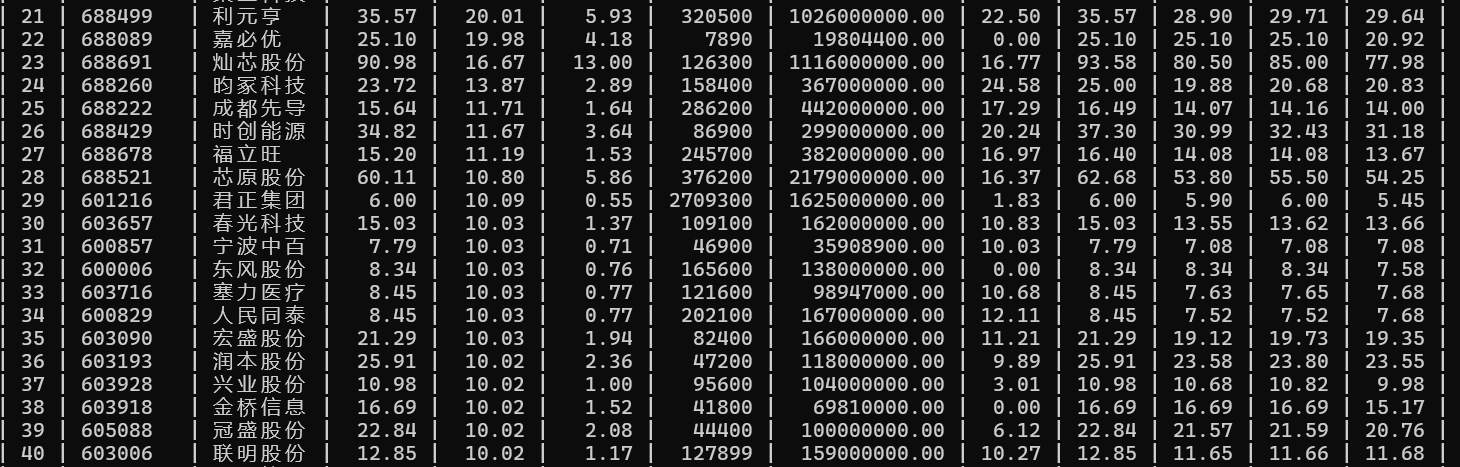
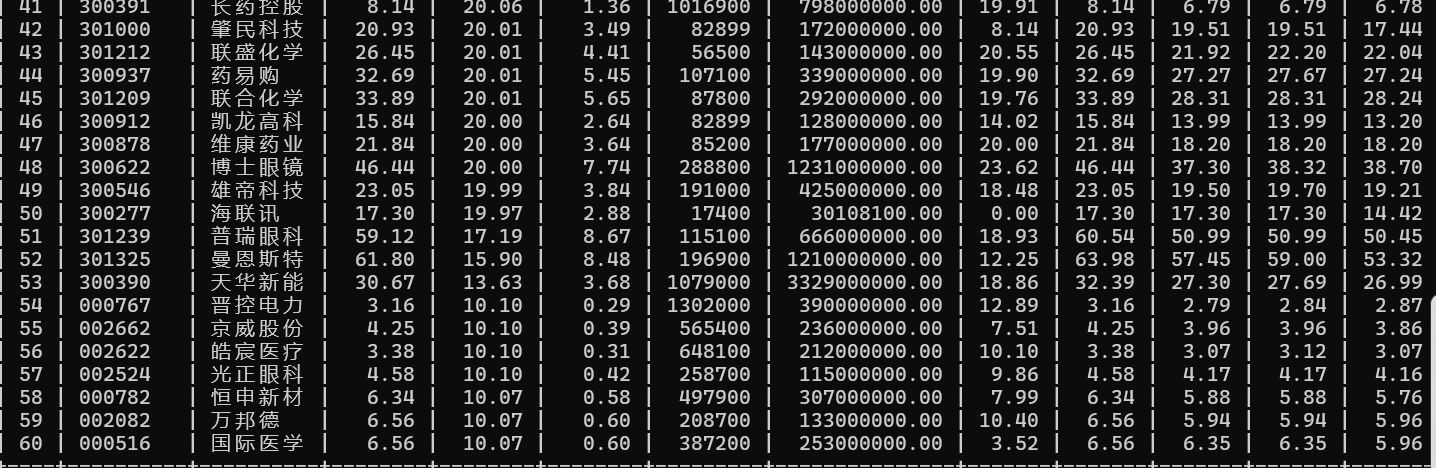
心得体会
在这次数据爬取和数据库存储的过程中,我学到了很多关于如何使用 Selenium 和 MySQL 进行数据抓取和管理的知识。通过使用 Selenium,能够模拟浏览器操作,自动化地从网页上提取数据,这对处理大量网页内容和需要频繁更新的数据尤为重要。此外,使用 MySQL 来存储数据,不仅提高了数据的持久性,还方便了后续的数据分析和处理。通过设置字符集为 utf8mb4,确保了中文数据的正确存储和显示。
在处理页面翻页时,利用 WebDriverWait 和 EC.element_to_be_clickable 等 Selenium 技巧,提高了程序的稳定性和效率。对成交量和成交额等数据的处理,也通过自定义函数进行转换和解析,使得数据能够符合数据库存储的标准。这次实践让我对如何处理网页抓取、数据解析、数据库操作有了更深入的了解。
同时,在设计数据库时,采用中文列名,使得数据更加易于理解和管理。尽管过程中遇到了一些挑战,如翻页失败和超时问题,但通过不断调试和优化,最终顺利完成了任务。总体来说,这次经历不仅让我加深了对数据抓取技术的理解,也提高了我在实际项目中应用技术的能力。
作业二
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
部分核心代码展示
# 打开 iCourse163 网站
driver.get('https://www.icourse163.org/')
time.sleep(1)
# 定位并点击登录按钮
button = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
button.click()
time.sleep(1)
# 切换到登录 iframe
frame = driver.find_element(By.XPATH, "//div[@class='ux-login-set-container']//iframe")
driver.switch_to.frame(frame)
这部分用于模拟用户登录到mook平台
# 获取课程链接元素列表
link_list = driver.find_elements(By.XPATH, '//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]')
# 遍历课程链接元素列表
for link in link_list:
# 获取课程名称
course_name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text
# 获取学校名称
school_name = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text
# 获取主讲老师
teacher = link.find_element(By.XPATH, './/a[@class="f-fc9"]').text
try:
# 获取教师团队成员
team_member = link.find_element(By.XPATH, './/span[@class="f-fc9"]/span').text
team_member = teacher + ' 、' + team_member
except Exception:
team_member = 'none'
# 获取参加人数并去除'参加'字样
attendees = link.find_element(By.XPATH, './/span[@class="hot"]').text.replace('参加', '')
# 获取课程进度
process = link.find_element(By.XPATH, './/span[@class="txt"]').text
# 获取课程简介
introduction = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text
# 将数据插入 MySQL 数据库
cursor.execute('''
INSERT INTO courses (课程名称, 学校名称, 老师, 教师团队, 参加人数, 课程进度, 课程简介)
VALUES (%s, %s, %s, %s, %s, %s, %s)
''', (course_name, school_name, teacher, team_member, attendees, process, introduction))
conn.commit()
这部分用于爬取mook的课程内容
运行结果
心得体会
在进行数据库操作和使用 Selenium 自动化抓取网页数据的过程中,我深入体会到了编程与实际应用结合的重要性。首先,在进行数据抓取时,我意识到网页结构的复杂性和动态加载内容的挑战,使用 Selenium 时切换 iframe 和等待元素加载是非常关键的步骤。这让我对网页的 DOM 结构和网络请求有了更深的理解。
其次,在使用 MySQL 存储抓取的数据时,我发现数据库设计的重要性。通过合理的表结构和数据类型的选择,不仅能保证数据存储的效率,还能提高后续查询和管理的便捷性。我还意识到,面对不同数据库(如 MySQL 和 SQLite)时,连接方式、查询语法和权限管理会有些许差异,因此需要根据实际需求灵活调整。
此外,通过实际操作,我对编程中常见的问题和错误有了更多的应对经验。例如,遇到库或驱动版本不匹配时,如何快速定位问题并解决,如何调试程序的每一步操作,这些经验对于提高开发效率非常有帮助。
总的来说,通过实践,我不仅提高了编程技能,还对如何高效地从网页抓取数据并进行存储和分析有了更深的理解。这将为未来更多的项目和挑战打下坚实的基础。
作业三
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
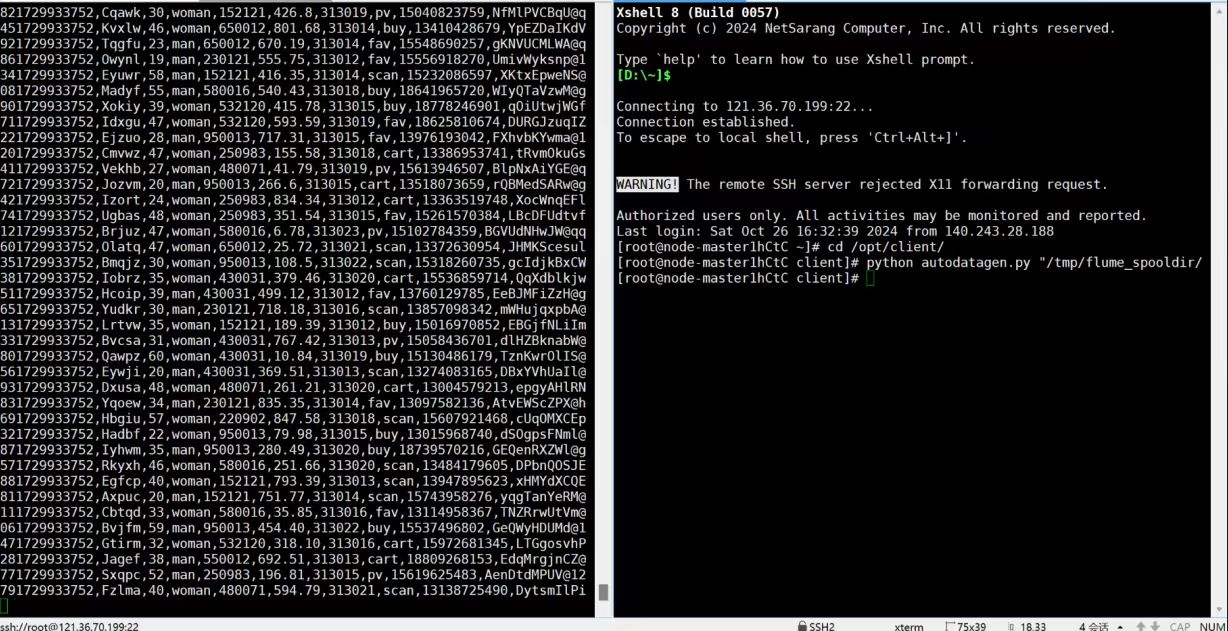
任务一:Python脚本生成测试数据
创建并进入/opt/client/目录,使用vi命令编写Python脚本:autodatagen.py
执行Python命令,测试生成100条数据
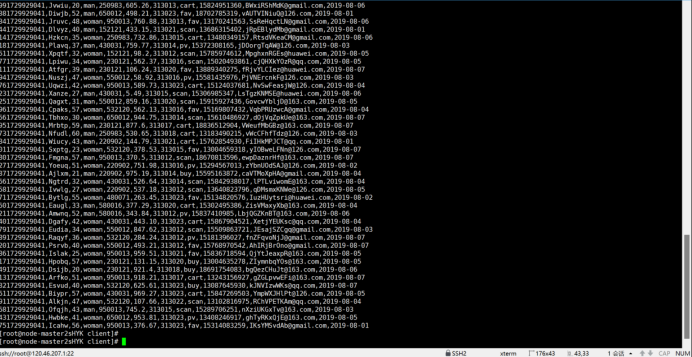
任务二:下载安装并配置Kafka
使用PuTTY登录到master节点服务器上,进入/tmp/FusionInsight-Client/目录。

安装Kafka运行环境,解压“MRS_Flume_ClientConfig.tar”文件。
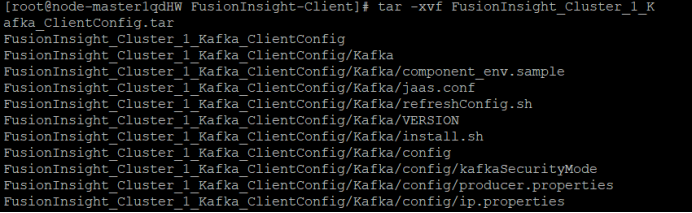
安装客户端运行环境到目录“/opt/Kafka_env”(安装时自动生成目录)。
sh FusionInsight_Cluster_1_Kafka_ClientConfig/install.sh /opt/Kafka_env
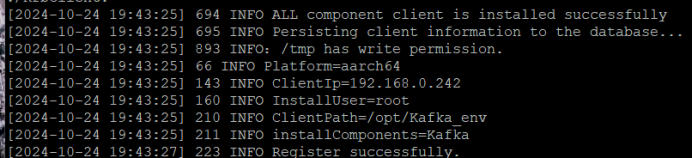
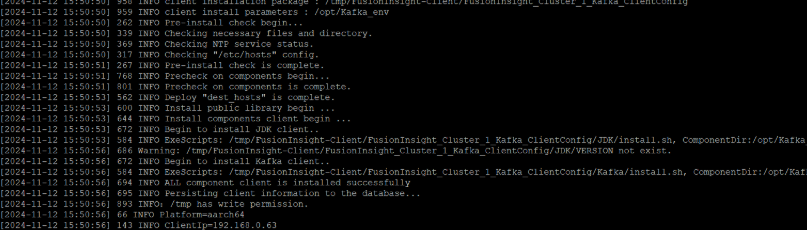
任务三:安装Flume客户端
安装Flume客户端
任务四:配置Flume采集数据
心得体会
我感受到了数据生成的灵活性和重要性。这些数据是后续分析的基础,其质量和准确性直接关系到分析结果的可靠性。Flume和Kafka的组合则展示了数据采集的高效与稳定,它们能够轻松应对大量数据的实时传输,确保了数据的及时性和完整性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号