

java基础(5)-集合类1
集合的由来
数组是很常用的一种数据结构,但假如我们遇到以下这样的的问题:
- 容器长度不确定
- 能自动排序
- 存储以键值对方式的数据
如果遇到这样的情况,数组就比较难满足了,所以也就有了一种与数组类似的数据结构——集合类。即集合是java中提供的一种容器,可用来存储多个数据
数组和集合的区别
1)长度
数组的长度固定
集合的长度可变
2)内容不同
数组存储的是同一种类型元素
集合可存储不同类型的元素
3)元素数据类型
数组可存储基本数据类型,也可存储引用数据类型
集合只能存储引用类型
数组和集合的联系
- 可使用toArray()和Arrays.asList()方法相互转换
集合的集成体系
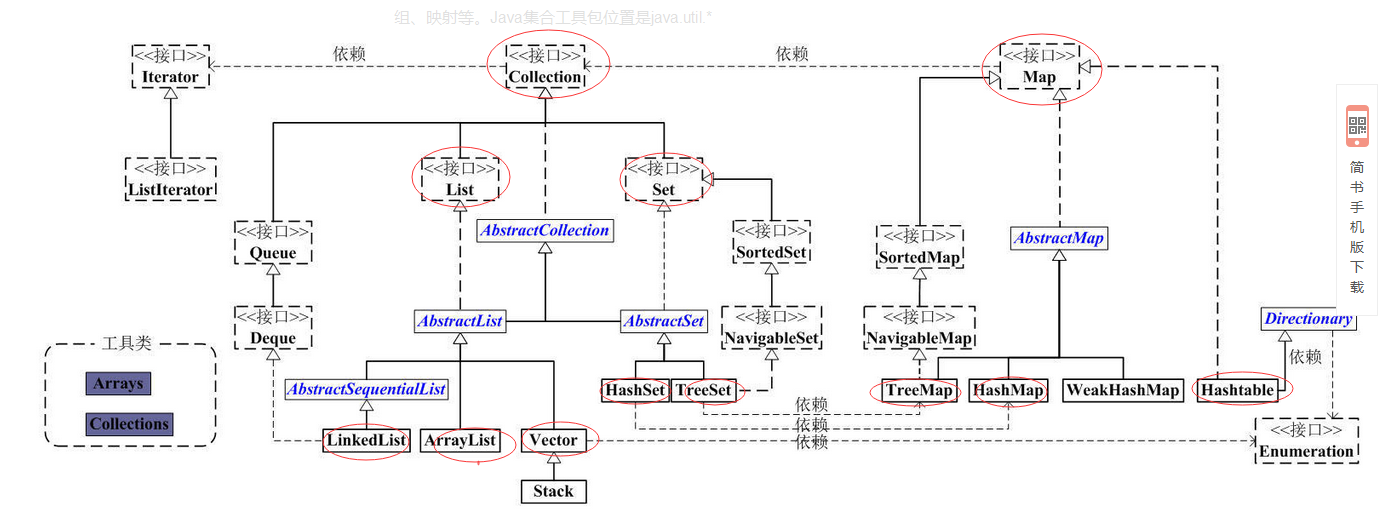
集合按存储结构可以分为单列集合(Collection)和双列集合(Map)
- Collection
Collection:是单列集合的根接口,Collection表示一组对象。两类子接口分别是LIst和Set【还有一类是Queue】
List接口:特点是元素有序,元素可重复。List接口的主要实现类有ArrayList和LinkedList
Set接口:特点是元素无序并且不可重复。Set接口的主要实现类有HashSet(散列存放)和TreeSet(有序存放)
- Map
1)Map提供了一种映射关系,元素是以键值对(key-value)的形式存储的,能够根据key快速查找value,常用子类有Hashtable,HashMap和TreeMap
2)Map中的键值对以Entry类型的对象实例形式存在
3)键(key值)不可重复,value值可以
4)每个建最多只能映射到一个值
5)Map接口提供了分别返回key值集合、value值集合以及Entry(键值对)集合的方法
6)Map支持泛型,形式如:Map<K,V>
Hashtable:底层是哈希表数据结构,不可存入null键null值,给集合是线程同步的。
HashMap:底层是哈希表数据结构,允许使用null键null值,该集合是不同步的
TreeMap:底层是二叉树数据结构,线程不同步,可以用于给map集合中的键进行排序
Map接口与Collection接口的不同
- map是双列的,collection是单列的
- map的键是唯一,collection的子体系set是唯一
- map集合的数据结构只针对键有效,跟值无关,collection集合的数据结构是针对元素有效
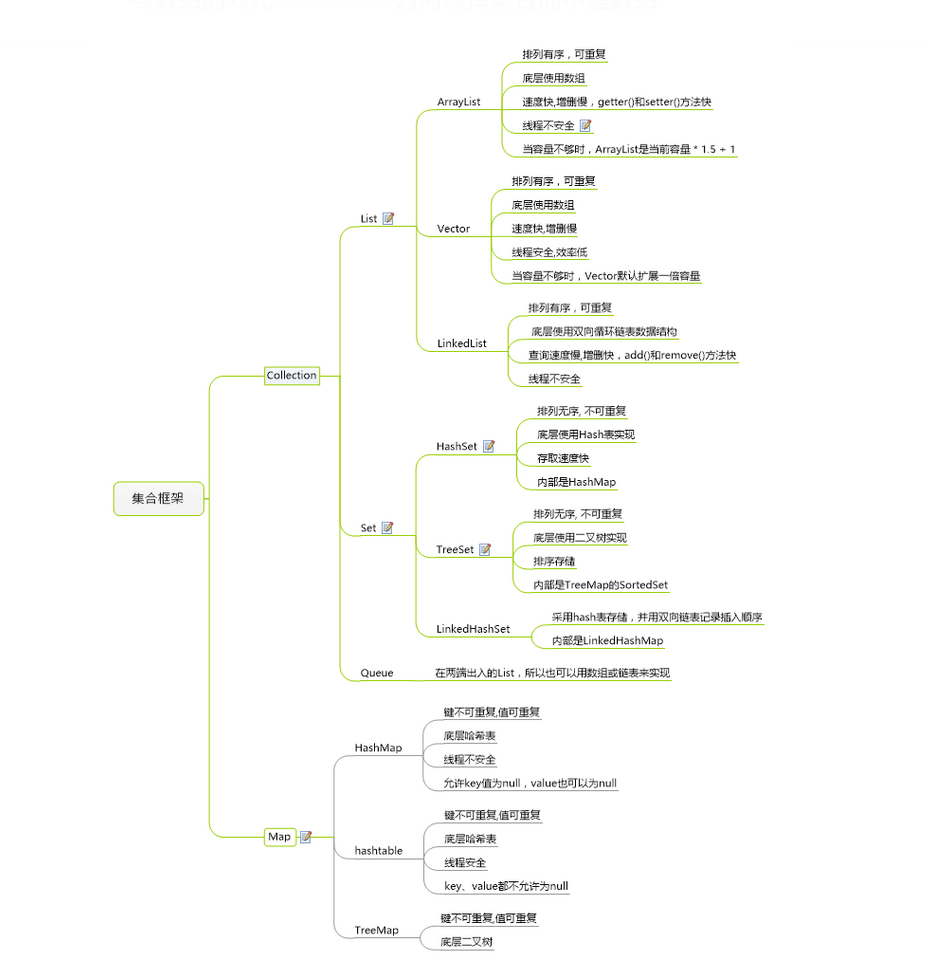
集合框架思维导图
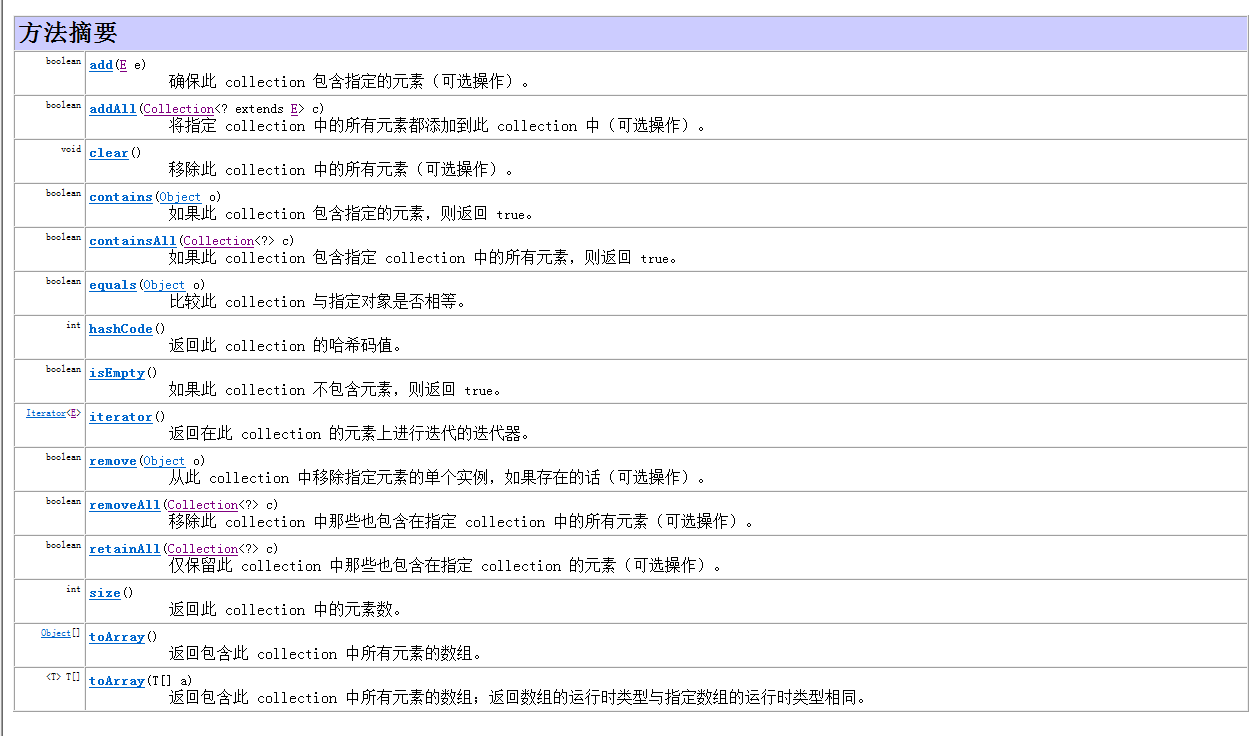
集合中的方法
集合基本功能测试
向集合中添加元素
/*
*向集合中添加一个元素
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo1{
public static void main(String[] args){
//创建集合对象
//Collection c = new Collection();//错误,接口不能实例化,需要找实现类
Collection c = new ArrayList();
//向集合中添加元素:boolean add(Object o);
c.add("10w");
c.add("20w");
c.add("30w");
//输出
System.out.println(c);
}
}
----------------------------------------------
输出结果:[10w, 20w, 30w]
----------------------------------------------
删除集合中所有元素
/*
*删除集合中所有元素
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo2{
public static void main(String[] args){
//创建集合对象
Collection c = new ArrayList();
//向集合中添加元素
c.add("100w");
c.add("200w");
c.add("300w");
System.out.println("删除前:"+c);
//删除集合中所有元素:void clear()
c.clear();
System.out.println("删除后:"+c);
}
}
------------------------------------------
输出结果:
删除前:[100w, 200w, 300w]
删除后:[]
------------------------------------------
删除该集合中指定的元素
/*
* 删除该集合中指定元素
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo3{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//向集合中添加元素
c.add("10w");
c.add("30w");
c.add("50w");
System.out.println("删除前:"+c);
//删除该集合中中指定的元素:boolean remove(Object o)
c.remove("30w");
System.out.println("删除后:"+c);
}
}
---------------------------------------------
输出结果:
删除前:[10w, 30w, 50w]
删除后:[10w, 50w]
----------------------------------------------
判断该集合中是否包含某个元素
/*
*判断该集合中是否包含某个元素
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo4{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//添加元素
c.add("hadoop");
c.add("spark");
c.add("storm");
System.out.println(c);
//判断该集合中是否包含某个元素:boolean contains(Object o)
System.out.println("判断有没有spark:"+c.contains("spark"));
System.out.println("判断有没有data:"+c.contains("data"));
}
}
---------------------------------------------
输出结果
[hadoop, spark, storm]
判断有没有spark:true
判断有没有data:false
------------------------------------------------
判断集合是否为空
/*
*判断集合是否为空
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo5{
public static void main(String[] args){
//创建集合
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
//向集合2中添加元素
c2.add("java");
c2.add("scala");
c2.add("python");
//判断集合是否为空:boolean isEmpty()
System.out.println("判断集合c1是否为空:"+c1.isEmpty());
System.out.println("判断集合c2是否为空:"+c2.isEmpty());
}
}
---------------------------------------------
输出结果
判断集合c1是否为空:true
判断集合c2是否为空:false
-------------------------------------------
获取该集合中元素的个数
/*
*判断该元素的个数
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo6{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//添加元素
c.add("wujiadogn");
c.add("jiangrui");
c.add("sunqiangkun");
c.add("xuqingyu");
//获取该集合的元素个数: int size()
System.out.println(c.size());
}
}
-------------------------------------
输出结果
4
-------------------------------------
将指定集合的所有元素添加到该集合中
/*
*将指定集合的所有元素添加到该集合中
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo7{
public static void main(String[] args){
//创建集合
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
//添加元素
c1.add("hadoop");
c1.add("spark");
c1.add("storm");
c2.add("wujiadong");
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
//将指定集合中所有元素添加到该元素中:boolean addAll(Collection c)
c1.addAll(c2);//将c2添加到c1中
System.out.println("将集合c2元素添加到c1后的c1:"+c1);
System.out.println("将集合c2元素添加到c1后的c2:"+c2);
}
}
---------------------------------------
输出结果
c1:[hadoop, spark, storm]
c2:[wujiadong]
将集合c2元素添加到c1后的c1:[hadoop, spark, storm, wujiadong]
将集合c2元素添加到c1后的c2:[wujiadong]
---------------------------------------
删除指定集合中的所有元素
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo8{
public static void main(String[] args){
//创建集合
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
//添加元素
c1.add("hadoop1");
c1.add("hadoop2");
c1.add("hadoop3");
c2.add("spark1");
c2.add("spark2");
c2.add("spark3");
c2.add("hadoop1");
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
System.out.println("c1删除c2的元素");
c1.removeAll(c2);
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
}
}
----------------------------------------
输出结果
c1:[hadoop1, hadoop2, hadoop3]
c2:[spark1, spark2, spark3, hadoop1]
c1删除c2的元素
c1:[hadoop2, hadoop3]
c2:[spark1, spark2, spark3, hadoop1]
---------------------------------------------
判断该集合中是否包含指定集合的所有元素
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo8{
public static void main(String[] args){
//创建集合
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();
Collection c3 = new ArrayList();
//添加元素
c1.add("hadoop1");
c1.add("hadoop2");
c1.add("hadoop3");
c2.add("spark1");
c2.add("spark2");
c2.add("spark3");
c2.add("hadoop1");
c3.add("hadoop1");
c3.add("hadoop2");
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
System.out.println("c3:"+c3);
System.out.println("c1是否包含c2:"+c1.containsAll(c2));
System.out.println("c1是否包含c3:"+c1.containsAll(c3));
System.out.println("retainAll()返回值表示c1是否发生过改变:"+c1.retainAll(c2));
System.out.println("c1:"+c1);
System.out.println("c2:"+c2);
}
}
注释:
boolean retainAll(Collection c):两个集合都有的元素
假假设有两个集合A和B,A和B做交集,最终的结果保存在A中,B不变;返回值表示的是A是否发过生改变
--------------------------------
输出结果
c1:[hadoop1, hadoop2, hadoop3]
c2:[spark1, spark2, spark3, hadoop1]
c3:[hadoop1, hadoop2]
c1是否包含c2:false
c1是否包含c3:true
c1和c2都有的元素retainAll():true
c1:[hadoop1]
c2:[spark1, spark2, spark3, hadoop1]
-------------------------------------
集合的遍历
集合的使用步骤
1)创建集合对象
2)创建元素对象
3)把元素添加到集合
4)遍历集合
a:通过集合对象获取迭代器对象
b:通过迭代器对象的hasNext()方法判断是否有元素
c:通过迭代器对象的next()方法获取元素并移动到下一个位置
方法一:通过转换成数组进行遍历
/*
*通过将集合转换成数组进行遍历
*/
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo1{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//向数组中添加元素
c.add("hadoop");
c.add("spark");
c.add("storm");
//Object[] toArray():将集合转换成数组,可以实现集合的遍历
Object[] objs = c.toArray();
for(int i=0;i<objs.length;i++){
System.out.println(objs[i]);
}
}
}
----------------------------------------
输出结果
hadoop
spark
storm
---------------------------------------
练习:用集合存储5个学生对象,并把学生对象进行遍历
import java.util.Collection;
import java.util.ArrayList;
public class CollectionDemo2{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
//创建学生对象
Student s1 = new Student("wwww",20);
Student s2 = new Student("jjj",21);
Student s3 = new Student("ddd",22);
Student s4 = new Student("sss",23);
Student s5 = new Student("qqq",24);
//将对象存储到集合中
c.add(s1);
c.add(s2);
c.add(s3);
c.add(s4);
c.add(s5);
//把集合转成数组
Object[] objs = c.toArray();
for(int i=0;i<objs.length;i++){
System.out.println(objs[i]);
}
}
}
class Student{
//成员变量
private String name;
private int age;
//构造方法
public Student(){
super();
}
public Student(String name,int age){
this.name = name;
this.age = age;
}
//getXxx()和setXxx()方法
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return age;
}
public String toString(){
return "Student [name="+name+",age="+age+"]";
}
}
---------------------------------
输出结果
Student [name=wwww,age=20]
Student [name=jjj,age=21]
Student [name=ddd,age=22]
Student [name=sss,age=23]
Student [name=qqq,age=24]
--------------------------------
方法二:集合专用遍历方式:迭代器
import java.util.Collection;
import java.util.ArrayList;
import java.util.Iterator;
public class ObjectArrayDemo3{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
c.add("hadoop");
c.add("spark");
c.add("storm");
// Iterator iterator();迭代器,集合的专用遍历方式
Iterator it = c.iterator();//实际返回的子类对象,这里是多态
/*
System.out.println(it.next());
System.out.println(it.next());
System.out.println(it.next());
*/
while(it.hasNext()){
String s = (String) it.next();
System.out.println(s);
}
}
}
-------------------------------------
输出结果
hadoop
spark
storm
---------------------------------------
练习:用集合存储5个对象,并把学生对象进行遍历,用迭代器遍历
import java.util.Collection;
import java.util.ArrayList;
import java.util.Iterator;
public class ObjectArrayDemo4{
public static void main(String[] args){
//创建集合
Collection c = new ArrayList();
Student s1 = new Student("www",21);
Student s2 = new Student("jjj",22);
Student s3 = new Student("ddd",23);
Student s4 = new Student("sss",24);
Student s5 = new Student("qqq",25);
c.add(s1);
c.add(s2);
c.add(s3);
c.add(s4);
c.add(s5);
Iterator it = c.iterator();
while(it.hasNext()){
// System.out.println(it.next());
Student s = (Student) it.next();
System.out.println(s);
}
}
}
class Student{
//成员变量
private String name;
private int age;
//无参构造方法
public Student(){
super();
}
//有参构造方法
public Student(String name,int age){
this.name = name;
this.age = age;
}
//getXxx方法和setXxx方法
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age = age;
}
public int age(){
return age;
}
//为什么需要这个方法,没有这个方法输出结果过就是地址值
public String toString(){
return "Student [name="+name+",age="+age+"]";
}
}
-------------------------------------------
输出结果
Student [name=www,age=21]
Student [name=jjj,age=22]
Student [name=ddd,age=23]
Student [name=sss,age=24]
Student [name=qqq,age=25]
--------------------------------------------
练习:存储字符串并遍历
import java.util.Collection;
import java.util.ArrayList;
import java.util.Iterator;
public class ObjectArrayDemo5{
public static void main(String[] args){
//创建集合对象
Collection c = new ArrayList();
//向集合添加元素
c.add("wu");
c.add("sun");
c.add("jiang");
c.add("xu");
c.add("haha");
//通过集合对象获取迭代器对象
Iterator it = c.iterator();
//通过迭代器对象的hasNext()方法判断有没有元素
while(it.hasNext()){
//通过迭代器对象的next()方法获取元素
String s = (String) it.next();
System.out.println(s);
}
}
}
-----------------------------------
输出结果
wu
sun
jiang
xu
haha
------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号