

ES--Kibana相关操作创建索引和Mapping
Kibana控制台命令:
1.创建索引infomation并创建映射mapping (一步搞定)
PUT information { "mappings": { "record":{ "properties": { "ip":{"type": "text"}, "count":{"type": "long"}, "create_type":{"type": "date"}, "i_type":{"type": "text"} } } } } 2.插入一条数据
PUT information/record/1 { "ip":"10.192.168.4", "count":"1455112", "create_type": "2018-03-07", "i_type":"IP数据" }
3.再插入一条数据 PUT information/record/2 { "ip":"10.192.168.12", "count":"1455112", "create_type": "2018-03-08", "i_type":"IP数据" }
4.查看所有数据 GET information/_search
5.查看索引配置 GET information/_settings 6.得到所有索引信息 GET information
7.更新第一条索引信息(相当于覆盖!!!)
PUT information/record/1
{
"ip":"10.192.168.4",
"count":"6666",
"create_type": "2018-03-07",
"i_type":"1111数据"
}
实际案例:
{
"from": 0,
"size": "20",
"query": {
"function_score": {
"query": {
"bool": {
"should": [{
"wildcard": {
"work_name": {
"wildcard": "**"
}
}
}, {
"term": {
"work_name": {
"term": ""
}
}
}, {
"match": {
"work_name_ik": {
"query": "",
"boost": 0.3,
"minimum_should_match": "30%"
}
}
}, {
"wildcard": {
"labels": {
"wildcard": "**"
}
}
}, {
"wildcard": {
"classify_1_name": {
"wildcard": "**"
}
}
}, {
"wildcard": {
"classify_2_name": {
"wildcard": "**"
}
}
}, {
"wildcard": {
"classify_3_name": {
"wildcard": "**"
}
}
}],
"minimum_should_match": 1,
"filter": {
"bool": {
"must": [{
"term": {
"classify_2_name.keyword": {
"term": "\u5e73\u9762"
}
}
}, {
"term": {
"status": {
"term": 2
}
}
}, {
"term": {
"is_del": {
"term": 0
}
}
}],
"must_not": []
}
}
}
},
"functions": [{
"script_score": {
"script": {
"lang": "painless",
"source": "if(doc['timestamp'].value !=0){def create_time=0;if(params.gender-doc['timestamp'].value>2592000){create_time = 0;}else{create_time=(2592000+doc['timestamp'].value-params.gender)*30\/2592000}
def level=0;if(doc['recommend_diff'].value==4){level=30}else if(doc['recommend_diff'].value==3){level=22.5}else if(doc['recommend_diff'].value==2){level=15}else if(doc['recommend_diff'].value==1){level=7.5}else if(doc['recommend_diff'].value==0){level=0}
def comment_num=0;if(doc['comment_num'].value<=100){if(params.gender-doc['timestamp'].value<=2592000 && params.gender-doc['timestamp'].value>23*24*3600){comment_num=(doc['comment_num'].value\/5)*0.6}
else if(params.gender-doc['timestamp'].value>259200 &¶ms.gender-doc['timestamp'].value<=7*24*3600){comment_num=(doc['comment_num'].value\/5)*1.8}
else if(params.gender-doc['timestamp'].value<=3*24*3600){comment_num=(doc['comment_num'].value\/5)*3}else{comment_num=0}}else{comment_num = 3}def like_num=0;if(doc['like_num'].value<=100)
{if(params.gender-doc['timestamp'].value<=2592000 && params.gender-doc['timestamp'].value>23*24*3600){like_num=(doc['like_num'].value\/5)*2}else if(params.gender-doc['timestamp'].value>259200 &¶ms.gender-doc['timestamp'].value<=7*24*3600)
{like_num=(doc['like_num'].value\/5)*6}else if(params.gender-doc['timestamp'].value<=3*24*3600){like_num=(doc['like_num'].value\/5)*10}else{like_num=0}}def user_recommend_level=0;if(doc['user_recommend_level_val_alia'].value==4){user_recommend_level=7}
else if(doc['user_recommend_level_val_alia'].value==3){user_recommend_level=7*0.75}else if(doc['user_recommend_level_val_alia'].value==2){user_recommend_level=7*0.5}else if(doc['user_recommend_level_val_alia'].value==1){user_recommend_level=7*0.25}
else if(doc['user_recommend_level_val_alia'].value==0){user_recommend_level=0}def user_fans=0;if(doc['user_fan_nums_alia'].value<=100){if(params.gender-doc['timestamp'].value>30*24*3600){user_fans = 0;}
else{user_fans= doc['user_fan_nums_alia'].value\/100*5}}
else{user_fans=5}return create_time+level+comment_num+like_num+user_recommend_level+user_fans;}else{return 30;}",
"params": {
"gender": 1585107887
}
}
}
}]
}
},
"sort": [],
"min_score": 1
}
params代表搜索时传给来的参数。 score 使用打分的。如果不排序可以写成:
"script_score": {
"script": "_score*1"
}
拓展:
可一次性创建索引和mapping(映射)以及需要做的匹配:
本人实际例子,后来者可以复制本案例,只需修改下面的mapping即可快速创建索引:
PUT information2
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 5,
"analysis": {
"analyzer": {
"str_lowercase":{
"tokenizer":"keyword",
"filter": ["lowercase", "asciifolding"]
}
}
}
},
"mappings": {
"record":{
"properties": {
"ip":{"type": "text"},
"count":{"type": "long"},
"create_type":{"type": "date"},
"i_type":{"type": "text"}
} }
}
}
删除索引 参考
- POST 索引名称/文档名称/_delete_by_query
- {
- "query":{
- "term":{
- "_id":100000100
- }
- }
- }
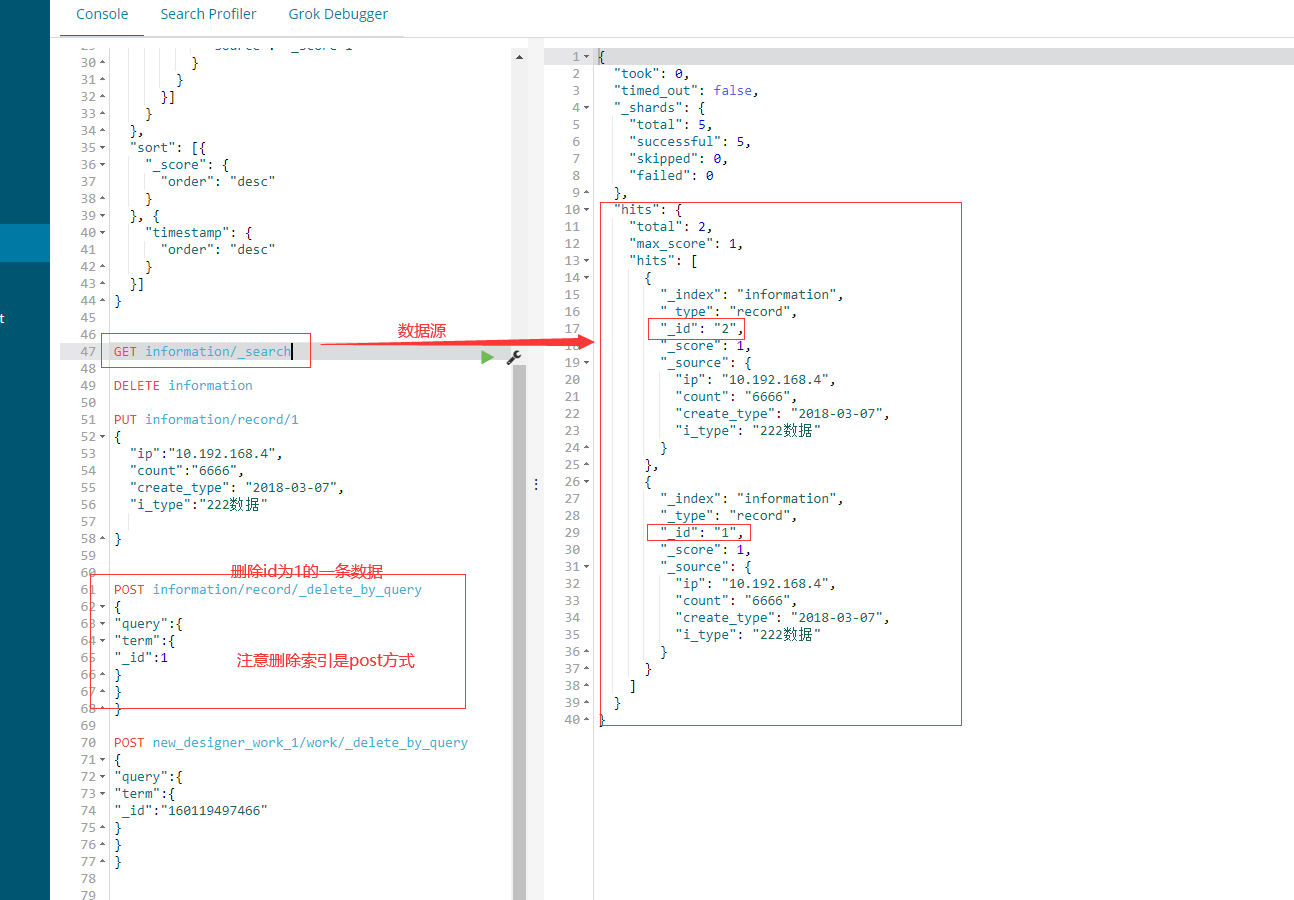
PS: 怎么清空单个索引数据
POST new_designer_work_1/_delete_by_query
{
"query": {"match_all": {}}
}
其中 new_designer_work_1 为索引名称
https://www.cnblogs.com/xionggeclub/p/11959150.html
龙卷风之殇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号