
第二次作业:卷积神经网络 part 2
问题总结
最近的学习中代码练习有很多问题,对很多语法不熟悉,比如transforms.Compose dataload 每次都需要很多时间搜索学习,有时候还是理解不清楚。老师我应该找资料系统学习好还是每次用到了再去了解
代码练习
MobilenetV1
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
# Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
# Pointwise 卷积,1*1 的卷积核
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
100%
170188800/170498071 [00:02<00:00, 86315344.47it/s]
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
class MobileNetV1(nn.Module):
# (128,2) means conv planes=128, stride=2
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
# 网络放到GPU上
net = MobileNetV1().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.333
Epoch: 1 Minibatch: 101 loss: 1.807
Epoch: 1 Minibatch: 201 loss: 1.598
Epoch: 1 Minibatch: 301 loss: 1.353
Epoch: 2 Minibatch: 1 loss: 1.437
Epoch: 2 Minibatch: 101 loss: 1.410
Epoch: 2 Minibatch: 201 loss: 1.197
Epoch: 2 Minibatch: 301 loss: 1.227
Epoch: 3 Minibatch: 1 loss: 1.132
Epoch: 3 Minibatch: 101 loss: 1.128
Epoch: 3 Minibatch: 201 loss: 1.006
Epoch: 3 Minibatch: 301 loss: 1.165
Epoch: 4 Minibatch: 1 loss: 1.043
Epoch: 4 Minibatch: 101 loss: 1.001
Epoch: 4 Minibatch: 201 loss: 0.958
Epoch: 4 Minibatch: 301 loss: 1.026
Epoch: 5 Minibatch: 1 loss: 0.935
Epoch: 5 Minibatch: 101 loss: 0.973
Epoch: 5 Minibatch: 201 loss: 0.810
Epoch: 5 Minibatch: 301 loss: 0.823
Epoch: 6 Minibatch: 1 loss: 0.668
Epoch: 6 Minibatch: 101 loss: 0.734
Epoch: 6 Minibatch: 201 loss: 1.058
Epoch: 6 Minibatch: 301 loss: 0.836
Epoch: 7 Minibatch: 1 loss: 0.673
Epoch: 7 Minibatch: 101 loss: 0.521
Epoch: 7 Minibatch: 201 loss: 0.961
Epoch: 7 Minibatch: 301 loss: 0.622
Epoch: 8 Minibatch: 1 loss: 0.667
Epoch: 8 Minibatch: 201 loss: 0.522
Epoch: 8 Minibatch: 301 loss: 0.662
Epoch: 9 Minibatch: 1 loss: 0.611
Epoch: 9 Minibatch: 101 loss: 0.570
Epoch: 9 Minibatch: 201 loss: 0.589
Epoch: 9 Minibatch: 301 loss: 0.577
Epoch: 10 Minibatch: 1 loss: 0.441
Epoch: 10 Minibatch: 101 loss: 0.509
Epoch: 10 Minibatch: 201 loss: 0.545
Epoch: 10 Minibatch: 301 loss: 0.644
Finished Training
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 77.89 %
Mobilenet V2
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
# 通过 expansion 增大 feature map 的数量
planes = expansion * in_planes
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
# 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes))
# 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入
if stride == 1 and in_planes == out_planes:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
# 步长为1,加 shortcut 操作
if self.stride == 1:
return out + self.shortcut(x)
# 步长为2,直接输出
else:
return out
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
# 通过 expansion 增大 feature map 的数量
planes = expansion * in_planes
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
# 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes))
# 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入
if stride == 1 and in_planes == out_planes:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
# 步长为1,加 shortcut 操作
if self.stride == 1:
return out + self.shortcut(x)
# 步长为2,直接输出
else:
return out
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
170500096/? [00:20<00:00, 32711040.55it/s]
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
# 网络放到GPU上
net = MobileNetV2().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.341
Epoch: 1 Minibatch: 101 loss: 1.563
Epoch: 1 Minibatch: 201 loss: 1.374
Epoch: 1 Minibatch: 301 loss: 1.329
Epoch: 2 Minibatch: 1 loss: 1.136
Epoch: 2 Minibatch: 101 loss: 1.134
Epoch: 2 Minibatch: 201 loss: 1.051
Epoch: 2 Minibatch: 301 loss: 1.093
Epoch: 3 Minibatch: 1 loss: 0.957
Epoch: 3 Minibatch: 101 loss: 0.956
Epoch: 3 Minibatch: 201 loss: 0.859
Epoch: 3 Minibatch: 301 loss: 0.786
Epoch: 4 Minibatch: 1 loss: 0.755
Epoch: 4 Minibatch: 101 loss: 0.765
Epoch: 4 Minibatch: 201 loss: 0.715
Epoch: 4 Minibatch: 301 loss: 0.701
Epoch: 5 Minibatch: 1 loss: 0.698
Epoch: 5 Minibatch: 101 loss: 0.709
Epoch: 5 Minibatch: 201 loss: 0.749
Epoch: 5 Minibatch: 301 loss: 0.590
Epoch: 6 Minibatch: 1 loss: 0.510
Epoch: 6 Minibatch: 101 loss: 0.684
Epoch: 6 Minibatch: 201 loss: 0.479
Epoch: 6 Minibatch: 301 loss: 0.557
Epoch: 7 Minibatch: 1 loss: 0.503
Epoch: 7 Minibatch: 101 loss: 0.435
Epoch: 7 Minibatch: 201 loss: 0.692
Epoch: 7 Minibatch: 301 loss: 0.479
Epoch: 8 Minibatch: 1 loss: 0.566
Epoch: 8 Minibatch: 101 loss: 0.466
Epoch: 8 Minibatch: 201 loss: 0.392
Epoch: 8 Minibatch: 301 loss: 0.434
Epoch: 9 Minibatch: 1 loss: 0.357
Epoch: 9 Minibatch: 101 loss: 0.384
Epoch: 9 Minibatch: 201 loss: 0.470
Epoch: 9 Minibatch: 301 loss: 0.483
Epoch: 10 Minibatch: 1 loss: 0.556
Epoch: 10 Minibatch: 101 loss: 0.522
Epoch: 10 Minibatch: 201 loss: 0.501
Epoch: 10 Minibatch: 301 loss: 0.359
Finished Training
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 81.54 %
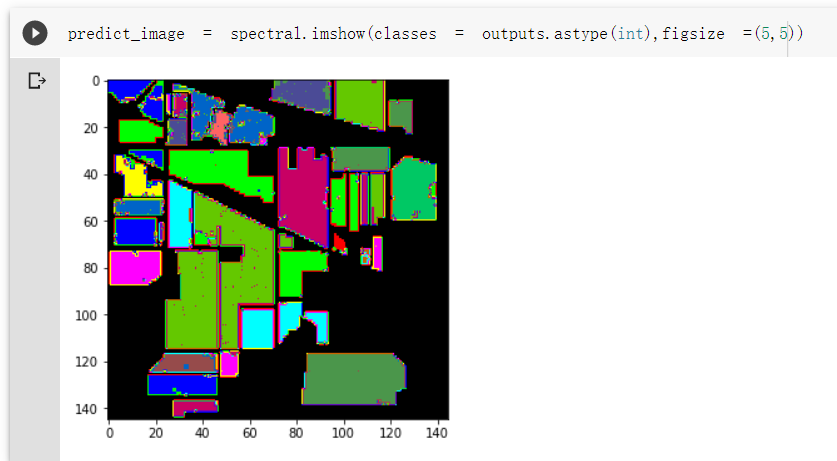
HybridSN
- HybridSN
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.L = 30
self.S = 25
self.conv1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0)
self.conv2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0)
self.conv3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0)
inputX = self.get2Dinput()
inputConv4 = inputX.shape[1] * inputX.shape[2]
self.conv4 = nn.Conv2d(inputConv4, 64, kernel_size=(3, 3), stride=1, padding=0)
num = inputX.shape[3]-2
inputFc1 = 64 * num * num
self.fc1 = nn.Linear(inputFc1, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, class_num)
self.dropout = nn.Dropout(0.4)
def get2Dinput(self):
with torch.no_grad():
x = torch.zeros((1, 1, self.L, self.S, self.S))
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
return x
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(x.shape[0], -1, x.shape[3], x.shape[4])
x = F.relu(self.conv4(x))
x = x.view(-1, x.shape[1] * x.shape[2] * x.shape[3])
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
- 测试
x = torch.randn(1, 1, 30, 25, 25)
net = HybridSN()
y = net(x)
print(y.shape)
torch.Size([1, 16])
3.训练
[Epoch: 1] [loss avg: 21.8448] [current loss: 2.6747]
[Epoch: 2] [loss avg: 21.1496] [current loss: 2.5167]
[Epoch: 3] [loss avg: 20.5864] [current loss: 2.3510]
[Epoch: 4] [loss avg: 20.1528] [current loss: 2.3459]
[Epoch: 5] [loss avg: 19.8083] [current loss: 2.2369]
[Epoch: 6] [loss avg: 19.4326] [current loss: 2.2062]
[Epoch: 7] [loss avg: 19.0586] [current loss: 2.0749]
[Epoch: 8] [loss avg: 18.7155] [current loss: 2.0027]
[Epoch: 9] [loss avg: 18.3859] [current loss: 1.8841]
[Epoch: 10] [loss avg: 17.9850] [current loss: 1.8558]
[Epoch: 11] [loss avg: 17.5288] [current loss: 1.5630]
[Epoch: 12] [loss avg: 17.0166] [current loss: 1.1573]
[Epoch: 13] [loss avg: 16.5001] [current loss: 1.2243]
[Epoch: 14] [loss avg: 15.9667] [current loss: 0.9239]
[Epoch: 15] [loss avg: 15.4194] [current loss: 0.8939]
[Epoch: 16] [loss avg: 14.8903] [current loss: 0.7463]
[Epoch: 17] [loss avg: 14.3821] [current loss: 0.8279]
[Epoch: 18] [loss avg: 13.8649] [current loss: 0.5666]
[Epoch: 19] [loss avg: 13.3476] [current loss: 0.4071]
[Epoch: 20] [loss avg: 12.8552] [current loss: 0.3478]
[Epoch: 21] [loss avg: 12.3743] [current loss: 0.3782]
[Epoch: 22] [loss avg: 11.9218] [current loss: 0.3691]
[Epoch: 23] [loss avg: 11.4866] [current loss: 0.2409]
[Epoch: 24] [loss avg: 11.0808] [current loss: 0.2728]
[Epoch: 25] [loss avg: 10.7035] [current loss: 0.1954]
[Epoch: 26] [loss avg: 10.3435] [current loss: 0.1404]
[Epoch: 27] [loss avg: 10.0003] [current loss: 0.0792]
[Epoch: 28] [loss avg: 9.6835] [current loss: 0.0762]
[Epoch: 29] [loss avg: 9.3801] [current loss: 0.0869]
[Epoch: 30] [loss avg: 9.1069] [current loss: 0.2103]
[Epoch: 31] [loss avg: 8.8435] [current loss: 0.1958]
[Epoch: 32] [loss avg: 8.5880] [current loss: 0.0586]
[Epoch: 33] [loss avg: 8.3513] [current loss: 0.1098]
[Epoch: 34] [loss avg: 8.1271] [current loss: 0.1432]
[Epoch: 35] [loss avg: 7.9127] [current loss: 0.1552]
[Epoch: 36] [loss avg: 7.7056] [current loss: 0.0744]
[Epoch: 37] [loss avg: 7.5112] [current loss: 0.1547]
[Epoch: 38] [loss avg: 7.3232] [current loss: 0.0093]
[Epoch: 39] [loss avg: 7.1485] [current loss: 0.0458]
[Epoch: 40] [loss avg: 6.9819] [current loss: 0.1608]
[Epoch: 41] [loss avg: 6.8187] [current loss: 0.0492]
[Epoch: 42] [loss avg: 6.6645] [current loss: 0.0430]
[Epoch: 43] [loss avg: 6.5184] [current loss: 0.0813]
[Epoch: 44] [loss avg: 6.3787] [current loss: 0.0982]
[Epoch: 45] [loss avg: 6.2421] [current loss: 0.0812]
[Epoch: 46] [loss avg: 6.1161] [current loss: 0.0271]
[Epoch: 47] [loss avg: 5.9938] [current loss: 0.0364]
[Epoch: 48] [loss avg: 5.8730] [current loss: 0.0320]
[Epoch: 49] [loss avg: 5.7591] [current loss: 0.0561]
[Epoch: 50] [loss avg: 5.6522] [current loss: 0.0609]
[Epoch: 51] [loss avg: 5.5485] [current loss: 0.0096]
[Epoch: 52] [loss avg: 5.4479] [current loss: 0.0720]
[Epoch: 53] [loss avg: 5.3521] [current loss: 0.0175]
[Epoch: 54] [loss avg: 5.2571] [current loss: 0.0424]
[Epoch: 55] [loss avg: 5.1641] [current loss: 0.0240]
[Epoch: 56] [loss avg: 5.0763] [current loss: 0.0051]
[Epoch: 57] [loss avg: 4.9890] [current loss: 0.0103]
[Epoch: 58] [loss avg: 4.9099] [current loss: 0.0129]
[Epoch: 59] [loss avg: 4.8302] [current loss: 0.0136]
[Epoch: 60] [loss avg: 4.7513] [current loss: 0.0153]
[Epoch: 61] [loss avg: 4.6757] [current loss: 0.0282]
[Epoch: 62] [loss avg: 4.6033] [current loss: 0.0182]
[Epoch: 63] [loss avg: 4.5348] [current loss: 0.0038]
[Epoch: 64] [loss avg: 4.4694] [current loss: 0.0302]
[Epoch: 65] [loss avg: 4.4057] [current loss: 0.0124]
[Epoch: 66] [loss avg: 4.3573] [current loss: 0.1474]
[Epoch: 67] [loss avg: 4.2991] [current loss: 0.1071]
[Epoch: 68] [loss avg: 4.2401] [current loss: 0.0436]
[Epoch: 69] [loss avg: 4.1821] [current loss: 0.0546]
[Epoch: 70] [loss avg: 4.1237] [current loss: 0.0096]
[Epoch: 71] [loss avg: 4.0682] [current loss: 0.0054]
[Epoch: 72] [loss avg: 4.0160] [current loss: 0.0621]
[Epoch: 73] [loss avg: 3.9628] [current loss: 0.0286]
[Epoch: 74] [loss avg: 3.9107] [current loss: 0.0356]
[Epoch: 75] [loss avg: 3.8603] [current loss: 0.0030]
[Epoch: 76] [loss avg: 3.8102] [current loss: 0.0251]
[Epoch: 77] [loss avg: 3.7614] [current loss: 0.0023]
[Epoch: 78] [loss avg: 3.7140] [current loss: 0.0099]
[Epoch: 79] [loss avg: 3.6680] [current loss: 0.0066]
[Epoch: 80] [loss avg: 3.6227] [current loss: 0.0007]
[Epoch: 81] [loss avg: 3.5796] [current loss: 0.0039]
[Epoch: 82] [loss avg: 3.5374] [current loss: 0.0007]
[Epoch: 83] [loss avg: 3.4961] [current loss: 0.0130]
[Epoch: 84] [loss avg: 3.4555] [current loss: 0.0228]
[Epoch: 85] [loss avg: 3.4175] [current loss: 0.0612]
[Epoch: 86] [loss avg: 3.3802] [current loss: 0.0028]
[Epoch: 87] [loss avg: 3.3469] [current loss: 0.1513]
[Epoch: 88] [loss avg: 3.3111] [current loss: 0.0277]
[Epoch: 89] [loss avg: 3.2757] [current loss: 0.0231]
[Epoch: 90] [loss avg: 3.2413] [current loss: 0.0200]
[Epoch: 91] [loss avg: 3.2086] [current loss: 0.1346]
[Epoch: 92] [loss avg: 3.1788] [current loss: 0.0240]
[Epoch: 93] [loss avg: 3.1473] [current loss: 0.0570]
[Epoch: 94] [loss avg: 3.1164] [current loss: 0.0053]
[Epoch: 95] [loss avg: 3.0853] [current loss: 0.0046]
[Epoch: 96] [loss avg: 3.0553] [current loss: 0.0064]
[Epoch: 97] [loss avg: 3.0253] [current loss: 0.0228]
[Epoch: 98] [loss avg: 2.9959] [current loss: 0.0043]
[Epoch: 99] [loss avg: 2.9674] [current loss: 0.0022]
[Epoch: 100] [loss avg: 2.9388] [current loss: 0.0031]
Finished Training
- 分类报告
precision recall f1-score support
0.0 0.8947 0.8293 0.8608 41
1.0 0.9527 0.9556 0.9542 1285
2.0 0.9479 0.9505 0.9492 747
3.0 0.9628 0.8498 0.9027 213
4.0 0.8808 0.9678 0.9222 435
5.0 0.9922 0.9711 0.9815 657
6.0 0.9474 0.7200 0.8182 25
7.0 0.9924 0.9163 0.9528 430
8.0 0.6875 0.6111 0.6471 18
9.0 0.9786 0.9429 0.9604 875
10.0 0.9637 0.9959 0.9795 2210
11.0 0.9114 0.8858 0.8984 534
12.0 0.9503 0.9297 0.9399 185
13.0 0.9818 0.9921 0.9869 1139
14.0 0.9343 0.9020 0.9179 347
15.0 0.6947 0.7857 0.7374 84
accuracy 0.9556 9225
macro avg 0.9171 0.8878 0.9006 9225
weighted avg 0.9562 0.9556 0.9554 9225

 浙公网安备 33010602011771号
浙公网安备 33010602011771号