浅析JVM模型以及java代码运行流程
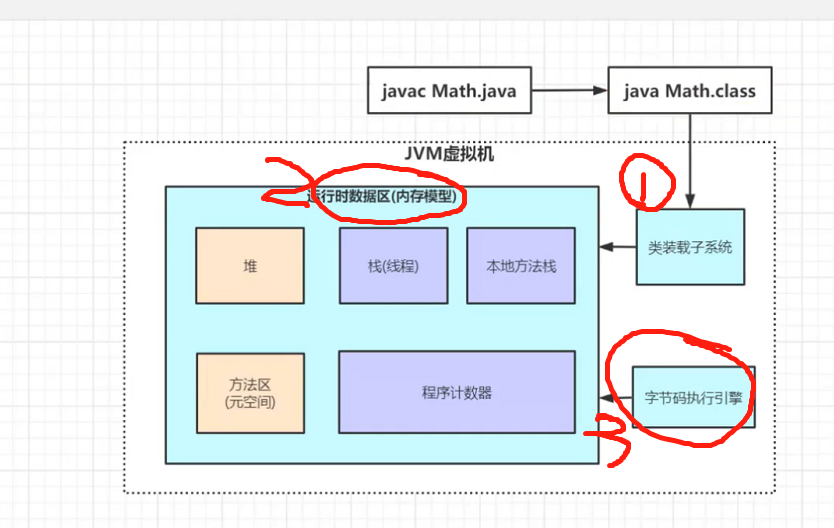
在一段代码被运行启动的时候:
1.java文件被jdk编译成为后缀为.class的文件
2. .class文件会通过我们的类装载子系统 加载 到 我们的运行时数据区
3. 通过字节码执行引擎 运行我们的.class 文件。
而 堆、栈(线程)、程序计数器、本地方法栈、方法区(元空间) 这五个从本质意义上来说 都是 内存。 没错 ,本质上都是JVM内存的一部分。
1.栈(线程) 本质上来说存放的就是我们的局部变量。 什么是局部变量 比如 String a = "1"; 这句代码里 你可以理解为a 就是存放在栈中; 当我的程序 比如
public int car(){
int b =1;
}
public static void main(String args[]){
String a = "1";
}
这段代码运行的时候 我的JVM内存中 栈 这块区域 就会单独开辟一个线程栈 给这个线程使用。
先解释一个名词 栈桢 : 一个方法对应一个栈桢内存区域。
每一个方法都可以理解为在栈中拥有一块属于自己的栈桢空间,每一个局部变量就存在他所在的方法体分配的栈桢内。
栈还有一个特点就是先进后出。
什么是先进后出 为什么是先进后出?
我们的java程序在运行的时候 一定是先执行主方法 也就是main方法。 这个时候main方法先入栈。 先进
当main方法运行时调用子方法的时候 子方法也入栈了, 当子方法运行完毕的时候 子方法里的局部变量就会被销毁 ,也就是b会被销毁。 只有当整个程序执行完 main方法才会被销毁。这就是我们所说的 先进后出 就是这个道理
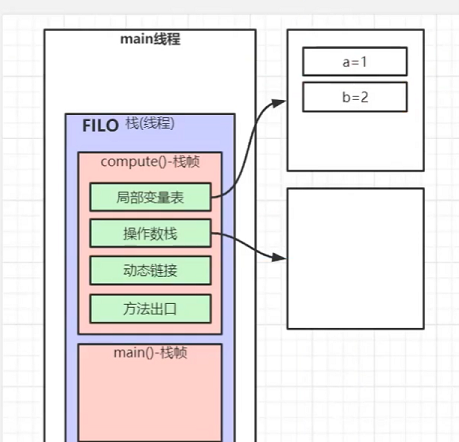
而栈中其实存放了 包括 局部变量表 操作数栈 动态链接 方法出口。
2.堆 , a存放在栈中,那么 "1" 存放的就是在堆中, 讲深一点就是 堆存放的是具体的值, 堆从物理的角度上来说 就是一个物理地址 010XX 类似这样的地址。这个地址存放的就是 "1" 这个值。 而栈存放的变量a 实际上就是你的物理地址。
也就是 a(物理地址) -》 1(物理地址存放1这个值) 不知道我这样说大家能不能理解。
3.方法区(元空间) 这个其实存放的是 我们的一些声明的static的常量 变量 。 尤其是变量 静态变量实例化的时候, 其实也是有一根指针指向 堆
在JDK8的版本中,方法区被移除,取而代之的是metaspace(元数据空间)。
4.程序计数器 首先我们要搞清楚JVM的多线程实现方式。JVM的多线程是通过CPU时间片轮转(即线程轮流切换并分配处理器执行时间)算法来实现的。也就是说,某个线程在执行过程中可能会因为时间片耗尽而被挂起,而另一个线程获取到时间片开始执行。当被挂起的线程重新获取到时间片的时候,它要想从被挂起的地方继续执行,就必须知道它上次执行到哪个位置,在JVM中,通过程序计数器来记录某个线程的字节码执行位置。因此,程序计数器是具备线程隔离的特性,也就是说,每个线程工作时都有属于自己的独立计数器。
5.本地方法栈 看过源代码的都知道,其实JDK最底层的实现 在linux平台使用部署 都是调用的linux的核心内核函数 linux的核心内核函数都是用C语言去实现的
当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。本地方法可以通过本地方法接口来访问虚拟机的运行时数据区,但不止如此,它还可以做任何它想做的事情。
本地方法本质上时依赖于实现的,虚拟机实现的设计者们可以自由地决定使用怎样的机制来让Java程序调用本地方法。
任何本地方法接口都会使用某种本地方法栈。当线程调用Java方法时,虚拟机会创建一个新的栈帧并压入Java栈。然而当它调用的是本地方法时,虚拟机会保持Java栈不变,不再在线程的Java栈中压入新的帧,虚拟机只是简单地动态连接并直接调用指定的本地方法。
以上文章一些内容也是本人百度的 因为我发现说的比我好得多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号