
聚簇索引和非聚簇索引
1. 根据索引找数据,读取的page少,IO次数少。
2.对比
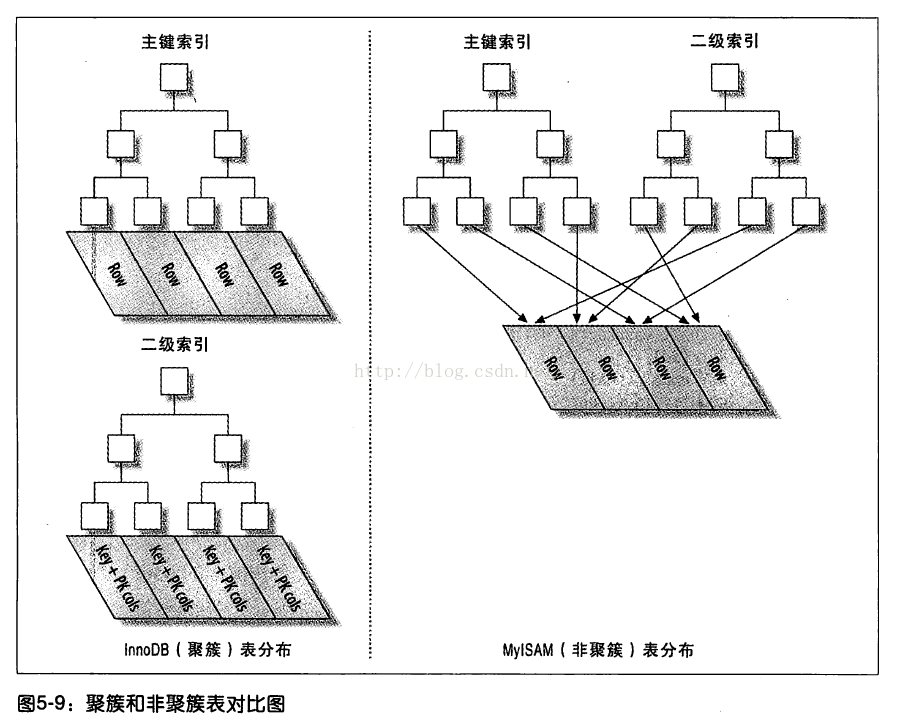
①聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页中。表中数据存在BTREE的叶子节点中。
因为无法同时把数据行存放在两个不同的对方,所以一个表只能有一个聚簇索引。
②聚集的数据有一些重要的优点:
数据访问更快,聚簇索引将索引和数据保存在同一个B-Tree中,因此从簇聚索引中获取数据通常比在非聚簇索引中查找要快。
同时,簇聚索引也有一些缺点:
更新簇聚索引列的代价很高,因为会强制InnoDB将每个被更新的列移动到新的位置;(可能有页分裂问题,也就是树的变动)
③可以看到innoDB主索引是聚集索引,辅助索引是非聚集,存储的是主键值
myIsam是非聚集索引,辅助索引和主索引都是存的数据行地址
④覆盖索引
通常大家设计索引都会根据查询的WHERE条件来创建合适的索引,不过这只是索引优化的一个方面。
设计优秀的索引应该考虑整个查询,而不单单是WHERE条件部分。
如果一个索引中包含了所需要查询的字段的值,我们就称为“覆盖索引”,
覆盖索引能够极大的提高性能,覆盖索引带来的好处有:
(1)索引条目远小于数据行大小,能够极大地提高性能,所以如果只需要读取索引,那么MySQL就会极大地减少数据访问量
⑤B-Tree: 如果一次检索需要访问4个节点,数据库系统设计者利用磁盘预读原理,把节点的大小设计为一个页,
那读取一个节点只需要一次I/O操作,完成这次检索操作, 最多需要3次I/O(根节点常驻内存)。数据记录越小,
每个节点存放的数据就越多,树的高度也就越小,I/O操作就少了,检索效率也就上去了。
B+Tree:非叶子节点只存key,大大减少了非叶子节点的大小,那么每个节点就可以存放更多的记录,树更矮了,I/O操作更少了。
所以B+Tree拥有更好的性能。
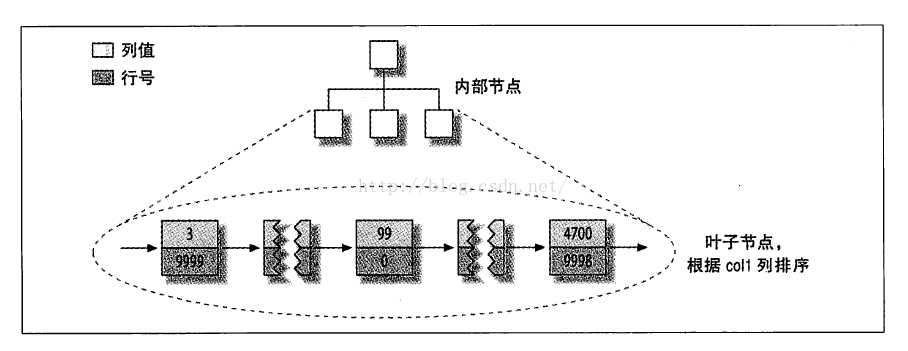
图5-5:MyISAM表layout_test的主键分布
MyIsam按照数据插入的顺序存储在磁盘上。
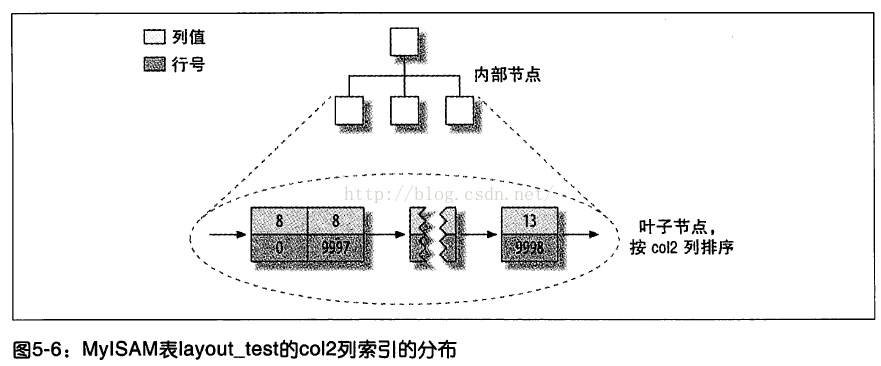
MyIsam的主键索引与其他的索引没有什么不同,主键索引就是一个名为PRIMARY的唯一非空索引。
MyIsam的主键索引和其它列索引存储的都是索引列的值和数据行的物理地址(图中隐藏了页的物理细节)。
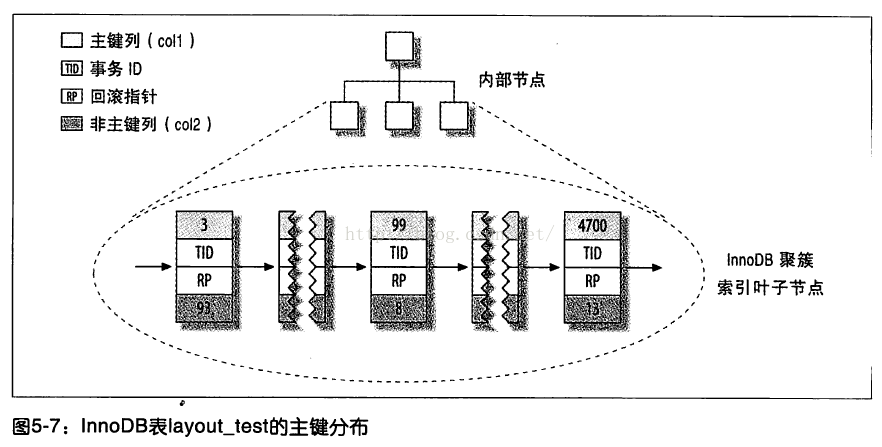
InnoDB的数据分布:
InnoDB实际上是“索引组织表”,因为在InnoDB中,聚簇索引就是表。
聚簇索引的每一个叶子节点包含了主键值、事务ID,用于事务和MVCC的回滚指针以及所有的剩余列。
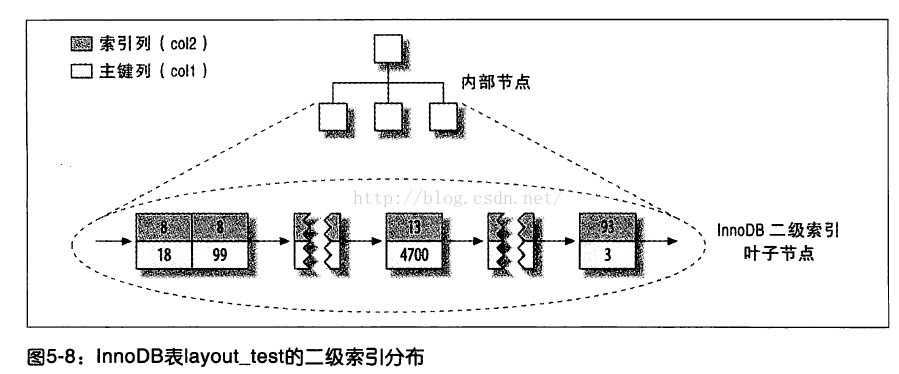
InnoDB的二级索引和聚簇索引有很大不同。
InnoDB二级索引中存储的是主键值而不是行指针。
这样的策略减少了当出现行移动或者数据页分裂时二级索引的维护工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号