

算法:时间复杂度+二分查找法(Java/Go/Python)实现
导读
曾几何时学好数据结构与算法是我们从事计算机相关工作的基本前提,然而现在很多程序员从事的工作都是在用高级程序设计语言(如Java)开发业务代码,久而久之,对于数据结构和算法就变得有些陌生了,由于长年累月的码砖的缘故,导致我们都快没有这方面的意识了,虽然这种论断对于一些平时特别注重学习和思考的人来说不太适用,但的确是有这样的一个现象。
而在要出去面试找工作的时候,才发现这些基础都快忘光光了,所以可能就“杯具”了!实际上,对于数据结构和算法相关的知识点的学习,是程序员必须修炼的一门内功,而要掌握得比较牢靠除了需要在写代码的时候时刻保持这方面的意识外,也需要日常的训练,换一个目前比较流行的词叫刻意练习。
这就像打乒乓球一样,虽然大家都会打,但是要打得好,打出水准就得经常训练。而学习算法的过程也是这样,因为大部分人的脑容量有限,对于学过的算法知识虽然之前理解过,但是因为时间的关系和算法本身就是比较抽象的一种知识,所以容易忘记。那么有没有什么好的练习工具呢?
在这里给大家推荐一个练习数据结构和算法编程的网站:
https://leetcode.com(因为墙的原因,你可能需要搭个梯子,或者也可以访问中文版的网站)这是一个目前很多硅谷的公司或程序员在学习或者招聘时都在使用的在线练习网站。上面有很多数据结构和算法的题,可以选择不同的编程语言实现,还支持代码社交,你提交的代码可以被全世界的程序员看到并被评论,从而得到相应地反馈。
以本文将要讲述的二分查找算法为例,在给大家的代码示例中作者就在这个网站上使用Java/Go/Python三种语言进行了实现,如👇图所示:
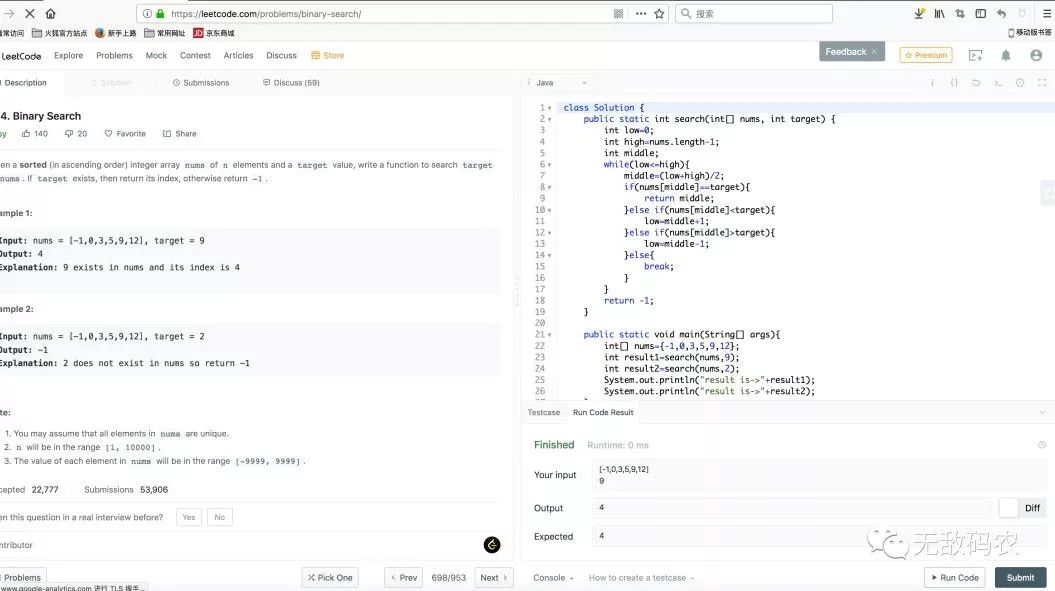
算法复杂度
因为小码农是想做一个比较系统的总结,所以在给大家分享具体的算法内容之前,需要先和大家一起回顾下什么是算法复杂度?
在编程的过程中,特别是写一些比较基础的逻辑代码时,我们经常会讨论说这段代码的时间复杂度是多少,空间复杂度是多少之类的术语。而这两项指标就是我们衡量我们写的代码(任何代码片段都可以视为算法)好坏最主要的两个标准了,时间复杂度是说我们写的这段代码的运行时间,而空间复杂度则是在说这段代码运行所占用的内存空间大小。
一般来说,我们在选择算法、编写相应的代码时都应该尽量选择运行时间最快,内存空间占用最少的方式。然而作为衡量算法好坏的标准,关于时间复杂度、空间复杂度如何衡量?目前是通过大O表示法来表示的,也就是我们经常说的O(xx),例如O(1)、O(n)之类。
以下是我们常见的一些大O运行时间的表示(从快到慢):
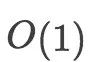
这是一种常数级的复杂度,这种复杂度的算法运行效率是最高的。例如,我们要计算“1+2+3+...+n”的和(假设n=100)?
如果我们采用如👇方式实现,那么100的累加和的计算,这段代码需要执行100次,1000累加和则需要执行1000次。
public static void main(String args[]) {
int y = 0;
for (int i = 0; i <= 100; i++) {
y = i + y;
}
System.out.println(y);
}
而如果我们换种方式如👇
public static void main(String args[]) {
int y = 0;
y = 100 * (100 + 1) / 2;
System.out.println(y);
}
那么无论多少的累加和,10000、100000、100000?上面这段程序都是需要执行一次,此时我们就可以说这段代码的时间复杂度是O(1)了。
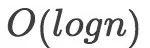
这是一种对数级的复杂度。可能上学的时候是因为体育老师教数学的缘故小码农已经忘记什么是对数了,在这里和大家一起复习下,假如你忘记了对数的概念,但是幂的概念你一定还是记得的log8相当于在问“将多少个2相乘的结果为8”,正常来说log对数还有个下标,因为我们在讨论算法复杂度时通常默认对数的下标为2,如2x2x2=8,所以log8=3。
那么什么样的算法的时间复杂度是对数级的呢?后面我们即将讨论的第一种算法(二分查找法)的时间复杂度就是对数级的,关于这块的代码示例,大家可以直接参考后面的示例。
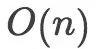
O(n)是一种线性的时间复杂度,如前面我们在说0(1)时,如果计算累加和的操作采用第一种方式,那么100的累加和需要执行100次,1000的累加和就需要执行1000次,以此类推,这样的时间复杂度就称之为O(n)。
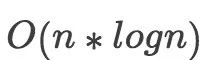
O(n*logn)是O(logn)、O(n)两种复杂度的一种组合,在后续的文章中要给大家介绍的“快速排序算法”(一种速度较快的排序算法),其时间复杂度就是O(n*logn),这里大家可以暂时先放一下,等后面具体讲述此算法时,可以体会下相应的代码示例。
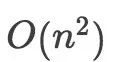
平方级的复杂度,在后续要介绍的算法中,“选择排序算法”(一种速度较慢的算法)的时间复杂度就是这个级别的。如👇
public static void main(String args[]) {
int[] arr = new int[]{4, 1, 3, 2, 6, 7, 8};
for (int i = 0; i < arr.length; i++) {
int m = i;
for (int j = i + 1; j < arr.length; j++) {
//如果第j个元素比第m个元素小,将j赋值给m
if (arr[j] < arr[m]) {
m = j;
}
}
//交换m和i两个元素的位置
if (i != m) {
int t = arr[i];
arr[i] = arr[m];
arr[m] = t;
}
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]);
System.out.print(",");
}
}
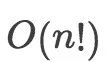
阶乘级的复杂度表示,时间复杂度为O(n!)的算法是一个非常慢的算法,例如斐波那契数列问题。如👇
public static int fib(int num) {
if (num == 1 || num == 2) {
return 1;
} else {
return fib(num - 2) + fib(num - 1);
}
}
public static void main(String[] args) {
for (int i = 1; i <= 6; i++) {
System.out.print(fib(i) + "\t");
}
}
以上就是我们在讨论算法复杂度时大部分的表示方法了,需要说明的是算法的速度并非单单指时间,而是操作数的增速,说的是随着输入的增加,其运行时间将以什么样的速度增加,例如O(log n)比O(n)快,当需要搜索的元素越多时,O(log n)比O(n)快得越多。
二分查找法
在了解算法复杂度后,我们来介绍一个相对基础的算法“二分查找法”!其输入是一个有序的元素列表(必须有序),如果查找的元素包含在这个有序列表中,二分查找就会返回其位置,否则返回-1。
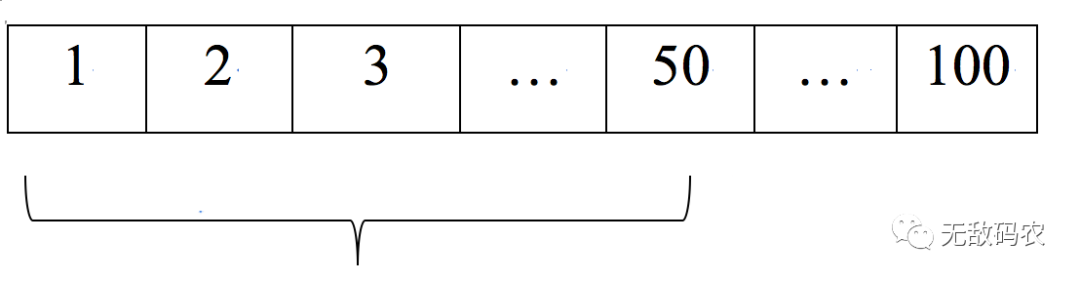
假设有一个1~100的数字:
|
1 |
2 |
3 |
… |
100 |
目标是以最少的次数从这个100个数字中找到指定的数字。通常思路是,我们需要从1开始一个一个比较,如果指定的数字是100,那么用这种傻找的方式需要找100次。如果范围扩大到1000,查找1000,那么相应地就需要找1000次,依次类推。
很显然,这种方式不是很靠谱。那么有没有更好的方法呢?这就是我们要说的二分查找法了,它的思路是先从元素的中间开始查找,如直接查找第50(第一次)个元素,比较中间元素与目标元素之间的大小。
如果我们还是查找100的话,那么50比100小,这样我们就可以一次性排除前50个元素了,因为已经很明确的知道了前50个元素都比目标元素小了,这些元素也就没有必要继续参与比较了。
第二次,我们从51~100之间再取中间元素进行判断,取75进行判断,75依然比100小,那么51~75这一段的数字也就直接排除掉了。
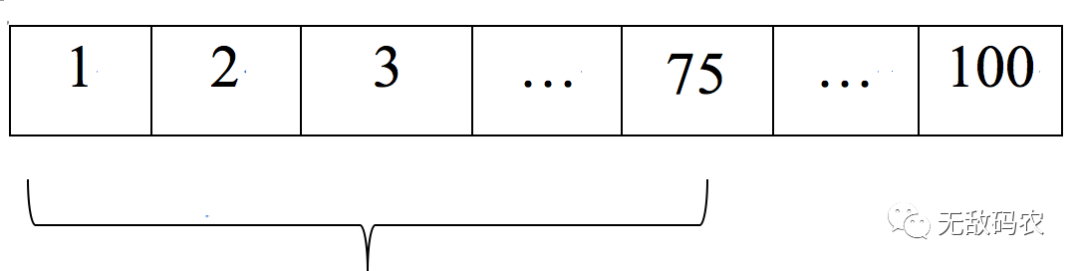
第三次,我们从76~100之间取中间元素,88,88<100;第四次,继续查找取89~100之间的中间元素95,95<100;第五次,继续取96~100中间元素98,98<100;第六次,继续取99~100之间的中间元素100,100=100,完成查找。
通过这种方式,我们总共运行了6次就完成了查找动作,相比之前的100次查找要靠谱,而这就是二分查找算法的基本原理了。
按照这种方式,即使列表中包含40亿个有序元素,最多也只需要32次就能完成查找。所以如果用前面描述的大O表示法,表示二分查找算法的时间复杂度是O(log n)。
好了,到这里就讲完二分查找算法的基本原理了,那么在具体的程序代码中,二分查找算法应该如何实现呢?以下为大家准备了Java/Go/Python三种版本的实现,大家可以在leetcode上尝试自己实现下。
#Java
public class Solution {
public static int search(int[] nums, int target) {
int low = 0;
int high = nums.length - 1;
int middle;
while (low <= high) {
middle = (low + high) / 2;
if (nums[middle] == target) {
return middle;
} else if (nums[middle] < target) {
low = middle + 1;
} else{
high = middle - 1;
}
}
return -1;
}
public static void main(String[] args) {
int[] nums = {-1, 0, 3, 5, 9, 12};
int result1 = search(nums, 9);
int result2 = search(nums, 2);
System.out.println("result is->" + result1);
System.out.println("result is->" + result2);
}
}
#Go
package main
import (
"fmt"
)
func main() {
nums := []int{-1, 0, 3, 5, 9, 12}
result := search(nums, 2)
fmt.Println(result)
}
func search(nums []int, target int) int {
low, high, middle := 0, len(nums)-1, -1
for low <= high {
middle = (low + high) / 2
if nums[middle] == target {
return middle
} else if nums[middle] < target {
low = middle + 1
} else {
high = middle - 1
}
}
return -1
}
#Python
class Solution:
def search(result,nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: int
"""
low,high,middle=0,len(nums)-1,-1
while low<=high:
middle=(low+high)//2
if nums[middle]==target:
return middle
elif nums[middle]<target:
low=middle+1
else:
high=middle-1
return -1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号